---
title: "Data Science for Economists"
# subtitle: "
"
subtitle: "Lecture 4: R language basics"
author: "Grant McDermott"
date: "University of Oregon | [EC 607](https://github.com/uo-ec607)" #"`r format(Sys.time(), '%d %B %Y')`"
output:
xaringan::moon_reader:
css: [default, metropolis, metropolis-fonts]
lib_dir: libs
nature:
highlightStyle: github
highlightLines: true
countIncrementalSlides: false
---
name: toc
```{css, echo=FALSE}
@media print {
.has-continuation {
display: block !important;
}
}
```
```{r setup, include=FALSE}
options(htmltools.dir.version = FALSE)
library(knitr)
opts_chunk$set(
fig.align="center", #fig.width=6, fig.height=4.5,
# out.width="748px", #out.length="520.75px",
dpi=300, #fig.path='Figs/',
cache=F#, echo=F, warning=F, message=F
)
```
# Table of contents
1. [Prologue](#prologue)
2. [Introduction](#intro)
3. [Object-oriented programming in R](#oop)
4. ["Everything is an object"](#eobject)
5. ["Everything has a name"](#ename)
6. [Indexing](#indexing)
7. [Cleaning up](#cleaning)
---
class: inverse, center, middle
name: prologue
# Prologue
---
# Checklist
☑ Pull from the lecture repo to get the latest slides.
☑ Did everyone manage to try the simple shell exercises at the back of our last lecture?
☑ Update your R packages. Do this regularly as a matter of good habit.
--
### Packages that you will need for today.
We're going to work almost exclusively in **base** R today.
- I'll also use the [**dplyr**](https://dplyr.tidyverse.org/) package, but only to demonstrate a few additional considerations for working with non-base libraries. Install/update it now, either through RStudio (recommended) or from your R console (`install.packages("dplyr"), dependencies = TRUE`).
- (P.S. If you're on Linux, I recommend installing the pre-compiled binary version of **dplyr** from [RSPM](https://packagemanager.rstudio.com/client/#/repos/1/overview). This avoids the need to build the package from source, greatly reducing your installation time. See related example [here](https://twitter.com/grant_mcdermott/status/1263951531461603328).)
---
# Agenda
Today and the next lecture are going to be very hands on.
- I'll have slides as per usual, but we're going to spent a lot of time live coding together.
This is deliberate.
- I want you to get comfortable typing R commands yourself — and navigating the RStudio IDE — without resorting to copy+paste.
- Slightly more painful in the beginning, but much better payoff in the long-run.
---
class: inverse, center, middle
name: intro
# Introduction
(Some important R concepts)
---
# Basic arithmetic
R is a powerful calculator and recognizes all of the standard arithmetic operators:
```{r}
1+2 ## Addition
6-7 ## Subtraction
5/2 ## Division
2^3 ## Exponentiation
2+4*1^3 ## Standard order of precedence (`*` before `+`, etc.)
```
---
# Basic arithmetic (cont.)
We can also invoke modulo operators (integer division & remainder).
- Very useful when dealing with time, for example.
```{r}
100 %/% 60 ## How many whole hours in 100 minutes?
100 %% 60 ## How many minutes are left over?
```
---
# Logic
R also comes equipped with a full set of logical operators and Booleans, which follow standard programming protocol. For example:
```{r}
1 > 2
1 > 2 & 1 > 0.5 ## The "&" stands for "and"
1 > 2 | 1 > 0.5 ## The "|" stands for "or" (not a pipe a la the shell)
isTRUE (1 < 2)
```
--
You can read more about logical operators and types here and here. In the next few slides, however, I want to emphasise some special concepts and gotchas...
---
# Logic (cont.)
### Order of precedence
Much like standard arithmetic, logic statements follow a strict order of precedence. Logical operators (`>`, `==`, etc) are evaluated before Boolean operators (`&` and `|`). Failure to recognise this can lead to unexpected behaviour...
```{r}
1 > 0.5 & 2
```
--
What's happening here is that R is evaluating two separate "logical" statements:
- `1 > 0.5`, which is is obviously TRUE.
- `2`, which is TRUE(!) because R is "helpfully" converting it to `as.logical(2)`.
--
**Solution:** Be explicit about each component of your logic statement(s).
```{r}
1 > 0.5 & 1 > 2
```
---
# Logic (cont.)
### Negation: `!`
We use `!` as a short hand for negation. This will come in very handy when we start filtering data objects based on non-missing (i.e. non-NA) observations.
```{r}
is.na(1:10)
!is.na(1:10)
# Negate(is.na)(1:10) ## This also works. Try it yourself.
```
---
# Logical operators (cont.)
### Value matching: `%in%`
To see whether an object is contained within (i.e. matches one of) a list of items, use `%in%`.
```{r}
4 %in% 1:10
4 %in% 5:10
```
--
There's no equivalent "not in" command, but how might we go about creating one?
- Hint: Think about negation...
--
```{r}
`%ni%` = Negate(`%in%`) ## The backticks (`) help to specify functions.
4 %ni% 5:10
```
---
# Logical operators (cont.)
### Evaluation
We'll get to assignment shortly. However, to preempt it somewhat, we always use two equal signs for logical evaluation.
```{r, error=T}
1 = 1 ## This doesn't work
1 == 1 ## This does.
1 != 2 ## Note the single equal sign when combined with a negation.
```
---
# Logical operators (cont.)
### Evaluation caveat: Floating-point numbers
What do you think will happen if we evaluate `0.1 + 0.2 == 0.3`?
--
```{r floating1}
0.1 + 0.2 == 0.3
```
Uh-oh! (Or, maybe you're thinking: Huh??)
--
**Problem:** Computers represent numbers as binary (i.e. base 2) floating-points. More [here](https://floating-point-gui.de/basic/).
- Fast and memory efficient, but can lead to unexpected behaviour.
- Similar to the way that standard decimal (i.e. base 10) representation can't precisely capture certain fractions (e.g. $\frac{1}{3} = 0.3333...$).
--
**Solution:** Use `all.equal()` for evaluating floats (i.e fractions).
```{r floating2}
all.equal(0.1 + 0.2, 0.3)
```
---
# Assignment
In R, we can use either `<-` or `=` to handle assignment.1
.footnote[
1 The `<-` is really a `<` followed by a `-`. It just looks like one thing b/c of the [font](https://github.com/tonsky/FiraCode) I'm using here.
]
--
### Assignment with `<-`
`<-` is normally read aloud as "gets". You can think of it as a (left-facing) arrow saying *assign in this direction*.
```{r}
a <- 10 + 5
a
```
--
Of course, an arrow can point in the other direction too (i.e. `->`). So, the following code chunk is equivalent to the previous one, although used much less frequently.
```{r}
10 + 5 -> a
```
---
# Assignment (cont.)
### Assignment with `=`
You can also use `=` for assignment.
```{r}
b = 10 + 10 ## Note that the assigned object *must* be on the left with "=".
b
```
--
### Which assignment operator to use?
Most R users (purists?) seem to prefer `<-` for assignment, since `=` also has specific role for evaluation *within* functions.
- We'll see lots of examples of this later.
- But I don't think it matters; `=` is quicker to type and is more intuitive if you're coming from another programming language. (More discussion [here](https://github.com/Robinlovelace/geocompr/issues/319#issuecomment-427376764) and [here](https://www.separatinghyperplanes.com/2018/02/why-you-should-use-and-never.html).)
**Bottom line:** Use whichever you prefer. Just be consistent.
---
# Help
For more information on a (named) function or object in R, consult the "help" documentation. For example:
```R
help(plot)
```
Or, more simply, just use `?`:
```R
# This is what most people use.
?plot
```
--
**Aside 1:** Comments in R are demarcated by `#`.
- Hit `Ctrl+Shift+c` in RStudio to (un)comment whole sections of highlighted code.
--
**Aside 2:** See the *Examples* section at the bottom of the help file?
- You can run them with the `example()` function. Try it: `example(plot)`.
---
# Help (cont.)
### Vignettes
For many packages, you can also try the `vignette()` function, which will provide an introduction to a package and it's purpose through a series of helpful examples.
- Try running `vignette("dplyr")` in your console now.
--
I highly encourage reading package vignettes if they are available.
- They are often the best way to learn how to use a package.
--
One complication is that you need to know the exact name of the package vignette(s).
- E.g. The `dplyr` package actually has several vignettes associated with it: "dplyr", "window-functions", "programming", etc.
- You can run `vignette()` (i.e. without any arguments) to list the available vignettes of every *installed* package installed on your system.
- Or, run `vignette(all = FALSE)` if you only want to see the vignettes of any *loaded* packages.
---
# Help (cont.)
### Demos
Similar to vignettes, many packages come with built-in, interactive demos.
To list all available demos on your system:1
```r
demo(package = .packages(all.available = TRUE))
```
.footnote[
1 How would you limit the demos to one particular package?
]
--
To run a specific demo, just tell R which one and the name of the parent package. For example:
```r
demo("graphics", package = "graphics")
```
---
class: inverse, center, middle
name: oop
# Object-oriented programming in R
---
# Motivation
In our very first lecture, I mentioned R's approach to [object-oriented programming](https://en.wikipedia.org/wiki/Object-oriented_programming) (OOP), which is often summarised as:
> **"Everything is an object and everything has a name."**
--
In the next two sections, I want to dive into this idea a little more. I also want to preempt some issues that might trip you up if you new to R or OOP in general.
- At least, they were things that tripped me up at the beginning.
--
The good news, as well see, is that avoiding and solving these issues is pretty straightforward.
- Not to mention: A very small price to pay for the freedom and control that R offers us.
---
# Disclaimer
Okay, this slide is just to let you know that I'm being a little fast and loose with terms.
Most obviously, there are actually _multiple_ OOP frameworks in R.
- **S3**, **S4**, **R6**...
- Hadley Wickham's "Advanced R" provides a [very thorough overview](https://adv-r.hadley.nz/oo.html) of the main ones.
But for our purposes, I think it is much more helpful to think about (a) the shared characteristics of these different systems and (b) the broad implications of OOP in R.
- What we lose in detail, we hopefully gain in perspective.
- But do read Hadley's book if you get the chance. It's incredibly helpful (as are all his books).
---
class: inverse, center, middle
name: eobject
# "Everything is an object"
---
# What are objects?
It's important to emphasise that there are many different *types* (or *classes*) of objects.
We'll revisit the issue of "type" vs "class" in a slide or two. For the moment, it is helpful simply to name some objects that we'll be working with regularly:
- vectors
- matrices
- data frames
- lists
- functions
- etc.
--
Most likely, you already have a good idea of what distinguishes these objects and how to use them.
- However, bear in mind that there subtleties that may confuse while you're still getting used to R.
- E.g. There are different kinds of data frames. We'll soon encounter "[tibbles](https://tibble.tidyverse.org/)" and "[data.tables](https://rdatatable.gitlab.io/data.table/articles/datatable-intro.html#what-is-datatable-1a)", which are enhanced versions of the standard data frame in R.
---
# What are objects? (cont.)
Each object class has its own set of rules ("methods") for determining valid operations.
- For example, you can perform many of the same operations on matrices and data frames. But there are some operations that only work on a matrix, and vice versa.
- At the same time, you can (usually) convert an object from one type to another.
```{r d}
## Create a small data frame called "d".
d = data.frame(x = 1:2, y = 3:4)
d
```
```{r m}
## Convert it to (i.e. create) a matrix call "m".
m = as.matrix(d)
m
```
---
# Object class, type, and structure
Use the `class`, `typeof`, and `str` commands if you want understand more about a particular object.
```{r}
# d = data.frame(x = 1:2, y = 3:4) ## Create a small data frame called "d".
class(d) ## Evaluate its class.
typeof(d) ## Evaluate its type.
str(d) ## Show its structure.
```
--
PS — Confused by the fact that `typeof(d)` returns "list"? See [here](https://stackoverflow.com/questions/45396538/typeofdata-frame-shows-list-in-r).
---
# Object class, type, and structure (cont.)
Of course, you can always just inspect/print an object directly in the console.
- E.g. Type `d` and hit Enter.
The `View()` function is also very helpful. This is the same as clicking on the object in your RStudio *Environment* pane. (Try both methods now.)
- E.g. `View(d)`.
---
name: global_env
# Global environment
Let's go back to the simple data frame that we created a few slides earlier.
```{r}
d
```
--
Now, let's try to run a regression1 on these "x" and "y" variables:
.footnote[
1 Yes, this is a dumb regression with perfectly co-linear variables. Just go with it.
]
```{r, error=T}
lm(y ~ x) ## The "lm" stands for linear model(s)
```
--
Uh-oh. What went wrong here? (Answer on next slide.)
---
# Global environment (cont.)
The error message provides the answer to our question:
```
*## Error in eval(predvars, data, env): object 'y' not found
```
--
R can't find the variables that we've supplied in our [Global Environment](https://www.datamentor.io/r-programming/environment-scope/):
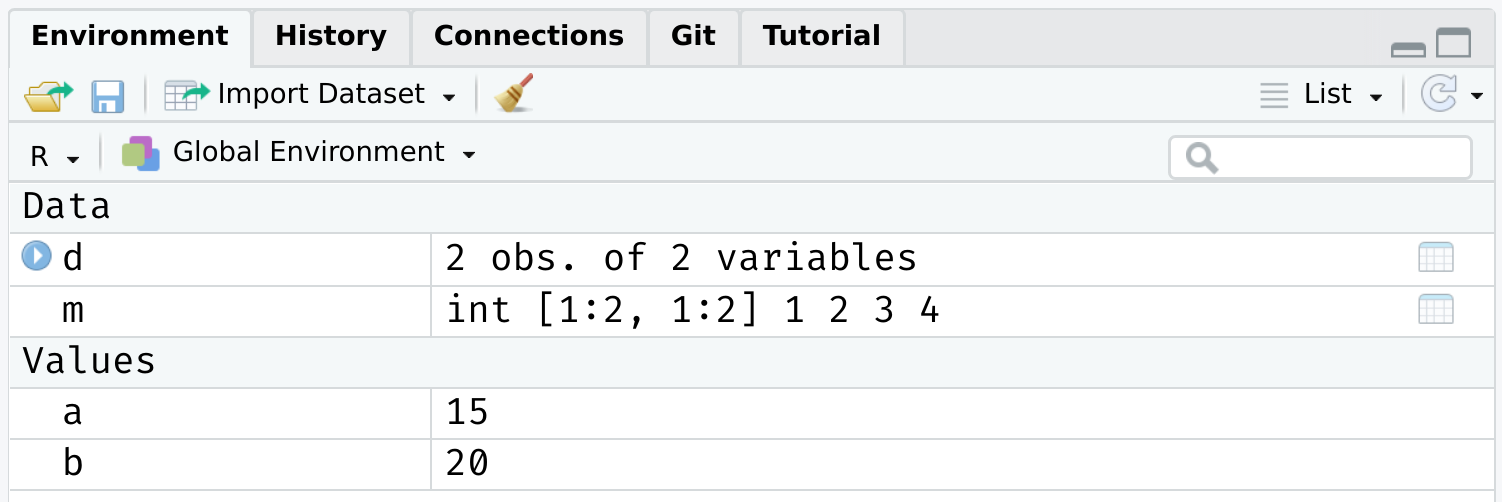
--
Put differently: Because the variables "x" and "y" live as separate objects in the global environment, we have to tell R that they belong to the object `d`.
- Think about how you might do this before clicking through to the next slide.
---
# Global environment (cont.)
There are a various ways to solve this problem. One is to simply specify the datasource:
```{r}
lm(y ~ x, data = d) ## Works when we add "data = d"!
```
--
I wanted to emphasize this global environment issue, because it is something that Stata users (i.e. many economists) struggle with when they first come to R.
- In Stata, the entire workspace essentially consists of one (and only one) data frame. So there can be no ambiguity where variables are coming from.
- However, that "convenience" comes at a really high price IMO. You can never read more than two separate datasets (let alone object types) into memory at the same time, have to resort all sorts of hacks to add summary variables to your dataset, etc.
- Speaking of which...
---
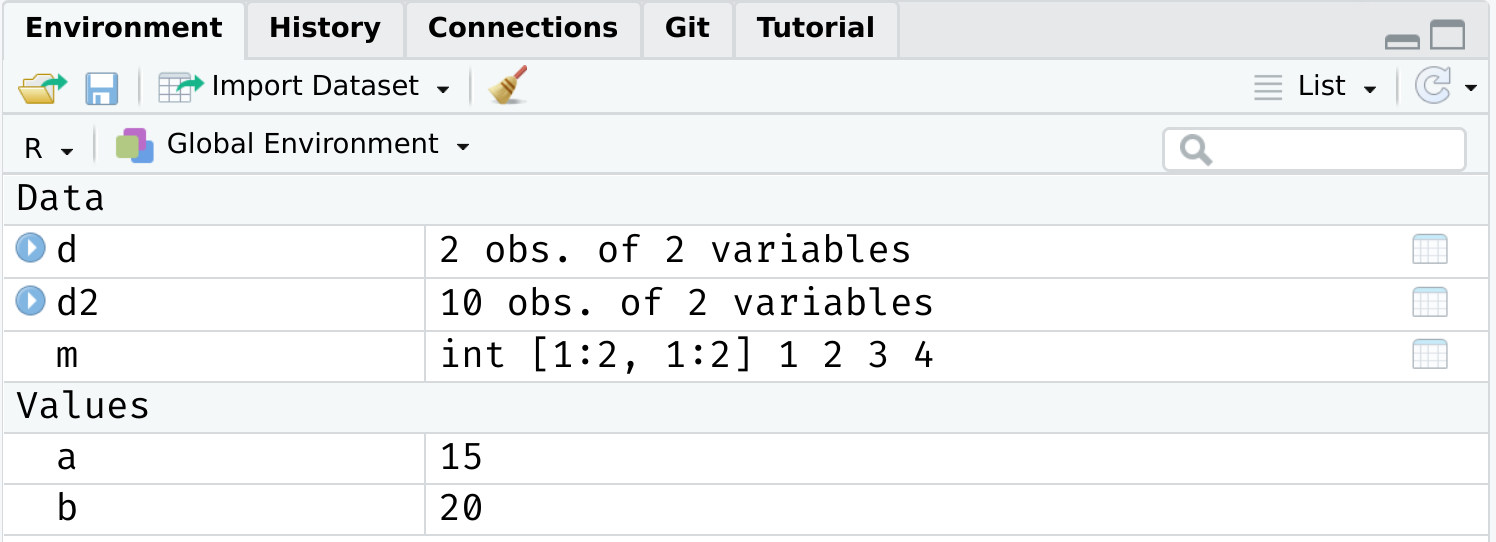
# Working with multiple objects
As I keep saying, R's ability to keep multiple objects in memory at the same time is a huge plus when it comes to effective data work.
- E.g. We can copy an exiting data frame, or create new one entirely from scratch. Either will exist happily with our existing objects in the global environment.
```{r d2}
d2 = data.frame(x = rnorm(10), y = runif(10))
```
---
# Working with multiple objects (cont.)
Again, however, it does mean that you have to pay attention to the names of those distinct data frames and be specific about which objects you are referring to.
- Do we want to run a regression of "y" on "x" from data frame `d` or data frame `d2`?
---
class: inverse, center, middle
name: ename
# "Everything has a name"
---
# Reserved words
We've seen that we can assign objects to different names. However, there are a number of special words that are "reserved" in R.
- These are are fundamental commands, operators and relations in base R that you cannot (re)assign, even if you wanted to.
- We already encountered examples with the logical operators.
See [here](http://stat.ethz.ch/R-manual/R-devel/library/base/html/Reserved.html) for a full list, including (but not limited to):
```R
if
else
while
function
for
TRUE
FALSE
NULL
Inf
NaN
NA
```
---
# Semi-reserved words
In addition to the list of strictly reserved words, there is a class of words and strings that I am going to call "semi-reserved".
- These are named functions or constants (e.g. `pi`) that you can re-assign if you really wanted to... but already come with important meanings from base R.
Arguably the most important semi-reserved character is `c()`, which we use for concatenation; i.e. creating vectors and binding different objects together.
```{r}
my_vector = c(1, 2, 5)
my_vector
```
--
What happens if you type the following? (Try it in your console.)
```R
c = 4
c(1, 2 ,5)
```
???
Vectors are very important in R, because the language has been optimised for them. Don't worry about this now; later you'll learn what I mean by "vectorising" a function.
---
# Semi-reserved words (cont.)
*(Continued from previous slide.)*
In this case, thankfully nothing. R is "smart" enough to distinguish between the variable `c = 4` that we created and the built-in function `c()` that calls for concatenation.
--
However, this is still *extremely* sloppy coding. R won't always be able to distinguish between conflicting definitions. And neither will you. For example:
```{r}
pi
pi = 2
pi
```
--
**Bottom line:** Don't use (semi-)reserved characters!
---
# Namespace conflicts
A similar issue crops up when we load two packages, which have functions that share the same name. E.g. Look what happens we load the `dplyr` package.
```{r}
library(dplyr)
```
--
The messages that you see about some object being *masked from 'package:X'* are warning you about a namespace conflict.
- E.g. Both `dplyr` and the `stats` package (which gets loaded automatically when you start R) have functions named "filter" and "lag".
---
# Namespace conflicts (cont.)
The potential for namespace conflicts is a result of the OOP approach.1
- Also reflects the fundamental open-source nature of R and the use of external packages. People are free to call their functions whatever they want, so some overlap is only to be expected.
.footnote[
1 Similar problems arise in virtually every other programming language (Python, C, etc.)
]
--
Whenever a namespace conflict arises, the most recently loaded package will gain preference. So the `filter()` function now refers specifically to the `dplyr` variant.
But what if we want the `stats` variant? Well, we have two options:
1. Temporarily use `stats::filter()`
2. Permanently assign `filter = stats::filter`
---
# Solving namespace conflicts
### 1. Use `package::function()`
We can explicitly call a conflicted function from a particular package using the `package::function()` syntax. For example:
```{r}
stats::filter(1:10, rep(1, 2))
```
--
We can also use `::` for more than just conflicted cases.
- E.g. Being explicit about where a function (or dataset) comes from can help add clarity to our code. Try these lines of code in your R console.
```R
dplyr::starwars ## Print the starwars data frame from the dplyr package
scales::comma(c(1000, 1000000)) ## Use the comma function, which comes from the scales package
```
???
The `::` syntax also means that we can call functions without loading package first. E.g. As long as `dplyr` is installed on our system, then `dplyr::filter(iris, Species=="virginica")` will work.
---
# Solving namespace conflicts (cont.)
### 2. Assign `function = package::function`
A more permanent solution is to assign a conflicted function name to a particular package. This will hold for the remainder of your current R session, or until you change it back. E.g.
```{r, eval=F}
filter = stats::filter ## Note the lack of parentheses.
filter = dplyr::filter ## Change it back again.
```
--
### General advice
I would generally advocate for the temporary `package::function()` solution.
Another good rule of thumb is that you want to load your most important packages last. (E.g. Load the tidyverse after you've already loaded any other packages.)
Other than that, simply pay attention to any warnings when loading a new package and `?` is your friend if you're ever unsure. (E.g. `?filter` will tell you which variant is being used.)
- In truth, problematic namespace conflicts are rare. But it's good to be aware of them.
---
# User-side namespace conflicts
A final thing to say about namespace conflicts is that they don't only arise from loading packages. They can arise when users create their own functions with a conflicting name.
- E.g. If I was naive enough to create a new function called `c()`.
--
In a similar vein, one of the most common and confusing errors that even experienced R programmers run into is related to the habit of calling objects "df" or "data"... both of which are functions in base R!
- See for yourself by typing `?df` or `?data`.
Again, R will figure out what you mean if you are clear/lucky enough. But, much the same as with `c()`, it's relatively easy to run into problems.
- Case in point: Triggering the infamous "object of type closure is not subsettable" error message. (See from 1:45 [here](https://rstudio.com/resources/rstudioconf-2020/object-of-type-closure-is-not-subsettable/).)
---
class: inverse, center, middle
name: indexing
# Indexing
---
# Option 1: []
We've already seen an example of indexing in the form of R console output. For example:
```{r}
1+2
```
The `[1]` above denotes the first (and, in this case, only) element of our output.1 In this case, a vector of length one equal to the value "3".
--
Try the following in your console to see a more explicit example of indexed output:
```{r, eval=F}
rnorm(n = 100, mean = 0, sd = 1)
# rnorm(100) ## Would work just as well. (Why? Hint: see ?rnorm)
```
.footnote[
[1] Indexing in R begins at 1. Not 0 like some languages (e.g. Python and JavaScript).
]
---
# Option 1: [] (cont.)
More importantly, we can also use `[]` to index objects that we create in R.
```{r}
a = 1:10
a[4] ## Get the 4th element of object "a"
a[c(4, 6)] ## Get the 4th and 6th elements
```
It also works on larger arrays (vectors, matrices, data frames, and lists). For example:
```{r}
starwars[1, 1] ## Show the cell corresponding to the 1st row & 1st column of the data frame.
```
--
What does `starwars[1:3, 1]` give you?
---
# Option 1: [] (cont.)
We haven't covered them properly yet (patience), but **lists** are a more complex type of array object in R.
- They can contain a random assortment of objects that don't share the same class, or have the same shape (e.g. rank) or common structure.
- E.g. A list can contain a scalar, a string, and a data frame. Or you can have a list of data frames, or even lists of lists.
--
The relevance to indexing is that lists require two square brackets `[[]]` to index the parent list item and then the standard `[]` within that parent item. An example might help to illustrate:
```{r my_list, cache=T}
my_list = list(a = "hello", b = c(1,2,3), c = data.frame(x = 1:5, y = 6:10))
my_list[[1]] ## Return the 1st list object
my_list[[2]][3] ## Return the 3rd element of the 2nd list object
```
---
# Option 2: $
Lists provide a nice segue to our other indexing operator: `$`.
- Let's continue with the `my_list` example from the previous slide.
```{r}
my_list
```
---
count: false
# Option 2: $
Lists provide a nice segue to our other indexing operator: `$`.
- Let's continue with the `my_list` example from the previous slide.
```{r, eval=F}
my_list
```
```
*## $a
## [1] "hello"
##
*## $b
## [1] 1 2 3
##
*## $c
## x y
## 1 1 6
## 2 2 7
## 3 3 8
## 4 4 9
## 5 5 10
```
Notice how our (named) parent list objects are demarcated: "$a", "$b" and "$c".
---
# Option 2: $ (cont.)
We can call these objects directly by name using the dollar sign, e.g.
```{r}
my_list$a ## Return list object "a"
my_list$b[3] ## Return the 3rd element of list object "b"
my_list$c$x ## Return column "x" of list object "c"
```
--
**Aside:** Typing `View(my_list)` (or, equivalently, clicking on the object in RStudio's environment pane) provides a nice interactive window for exploring the nested structure of lists.
---
# Option 2: $ (cont.)
The `$` form of indexing also works (and in the manner that you probably expect) for other object types in R.
In some cases, you can also combine the two index options.
- E.g. Get the 1st element of the "name" column from the starwars data frame.
```{r}
starwars$name[1]
```
--
However, note some key differences between the output from this example and that of our previous `starwars[1, 1]` example. What are they?
- Hint: Apart from the visual cues, try wrapping each command in `str()`.
---
# Option 2: $ (cont.)
The last thing that I want to say about `$` is that it provides another way to avoid the "object not found" problem that we ran into with our earlier regression example.
```{r, error=T}
lm(y ~ x) ## Doesn't work
lm(d$y ~ d$x) ## Works!
```
---
class: inverse, center, middle
name: cleaning
# Cleaning up
---
# Removing objects (and packages)
Use `rm()` to remove an object or objects from your working environment.
```{r}
a = "hello"
b = "world"
rm(a, b)
```
You can also use `rm(list = ls())` to remove all objects in your working environment (except packages), but this is [frowned upon](https://www.tidyverse.org/articles/2017/12/workflow-vs-script/).
- Better just to start a new R session.
--
Detaching packages is more complicated, because there are so many cross-dependencies (i.e. one package depends on, and might even automatically load, another.) However, you can try, e.g. `detach(package:dplyr)`
- Again, better just to restart your R session.
---
# Removing plots
You can use `dev.off()` to removing any (i.e. all) plots that have been generated during your session. For example, try this in your R console:
```{r, eval=F}
plot(1:10)
dev.off()
```
--
You may also have noticed that RStudio has convenient buttons for clearing your workspace environment and removing (individual) plots. Just look for these icons in the relevant window panels:

---
class: inverse, center, middle
# Next lecture(s): Data wrangling and cleaning
```{r gen_pdf, include = FALSE, cache = FALSE, eval = TRUE}
infile = list.files(pattern = '.html')
pagedown::chrome_print(input = infile, timeout = 100)
```