
Tengstrand's Blog
The search for simpler code while having fun.
The search for simpler code while having fun.
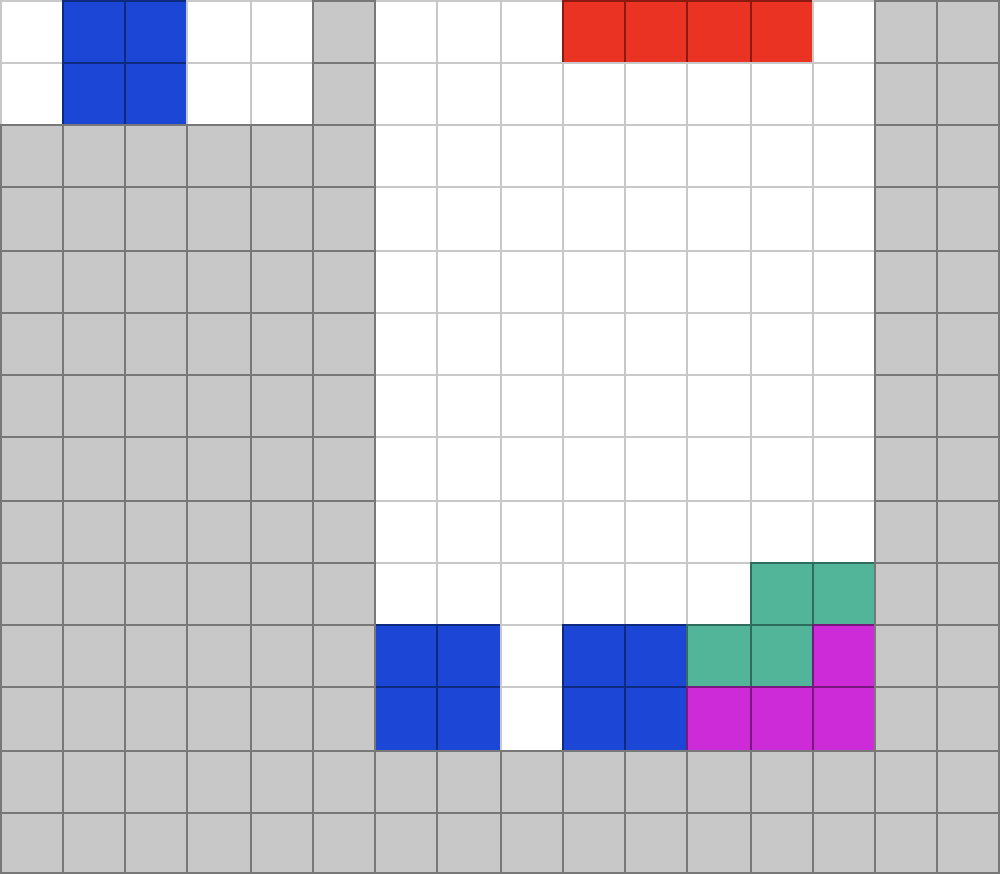
Fokus i denna andra del i bloggserien är att visa på fördelarna med att få snabb återkoppling när du jobbar med kod. Sättet vi gör det på är att implementera borttagning av hela rader när en Tetris-bit placeras på sin plats.
For example, if we rotate the red piece in the image above and place it in the third position, the two bottom rows should be cleared:
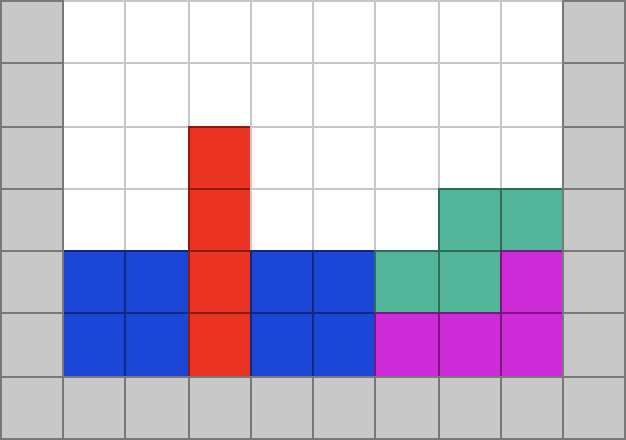
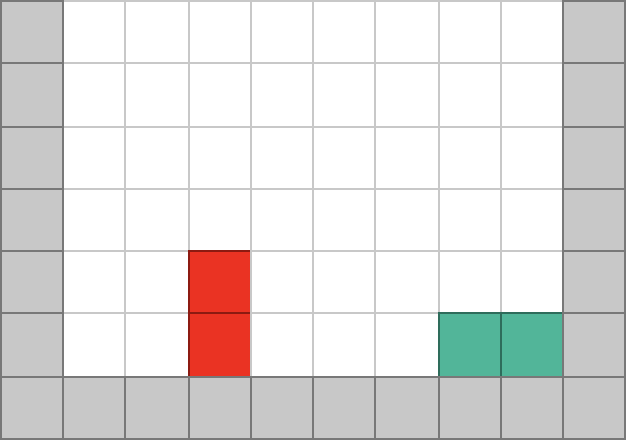
The resulting source code from this second blog post in the series can be found here:
Om du läst del ett i bloggserien, så vet du redan att all kod kommer att implementeras i både Python och Clojure, så låt oss börja med det senare!
Clojure har något som kallas REPL (Read Eval Print Loop) som låter dig skriva koden i små steg, samtidigt som du får snabb återkoppling huruvida koden fungerar eller ej.
Vi börjar med att skapa ett clear-rows namespace i board-komponenten:
▾ tetris-polylith
▸ bases
▾ components
▾ board
▾ src
clear-rows.clj
core.clj
interface.clj
▸ test
▸ piece
▸ development
▸ projects
Där vi lägger till en board row:
(ns tetrisanalyzer.board.clear-rows)
(def row [1 1 1 0 1 1 1 0 1 1])
I Clojure behöver vi bara kompilera den kod som ändrats. Då vi lagt till ett nytt namespace och en row behöver vi därför skicka hela namespacet till REPLn, vanligtvis via en key-shortcut, för att få det kompilerat till Java bytekod.
En komplett rad innehåller inga tomma celler (nollor). Vi kan använda funktionen some för att detektera förekomsten av tomma celler:
(some zero? row) ;; true
Här har minst en tom cell hittats, vilket betyder att raden ej är komplett. Låt oss även testa huruvida vi kan identifiera en komplett rad:
(ns tetrisanalyzer.board.clear-rows)
(def row [1 1 1 1 1 1 1 1 1 1])
(some zero? row) ;; false
Ja, det verkar fungera.
Nu kan vi skapa en funktion av koden:
(ns tetrisanalyzer.board.clear-rows)
(defn incomplete-row? [row]
(some zero? row))
(comment
(incomplete-row? [1 1 1 1 1 1 1 0 1 1]) ;; true
(incomplete-row? [1 1 1 1 1 1 1 1 1 1]) ;; false
#__)
Här har jag lagt till ett comment-block med ett par anropa till funktionen. Från utvecklingsmiljön kan vi nu anropa en funktion i taget och direkt se resultatet, samtidigt som funktionerna inte körs om vi skulle ladda om namespacet. Det är ganska vanligt i Clojure-världen att dessa kommentarsblock lämnas kvar i produktionskoden så att funktioner lätt kan anropas, samtidigt som de fungerar som dokumentation.
Vi städar bort kommentarsblocket och lägger istället till en board så att vi har något att testa mot (kommatecken kan utelämnas):
(ns tetrisanalyzer.board.clear-rows)
(defn incomplete-row? [row]
(some zero? row))
(def board [[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 0 0 1 1]
[1 0 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]])
Nu kan vi räkna fram de rader som ej ska tas bort:
(def remaining-rows (filter incomplete-row? board)) ;; ([0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [1 1 1 1 1 1 0 0 1 1]
;; [1 0 1 1 1 1 1 1 1 1])
Nästa steg är att skapa de två tomma raderna som ska ersätta de borttagna, vilka vi slutligen lägger i empty-rows:
(def board-width (count (first board)))
(def board-height (count board))
(def num-cleared-rows (- board-height (count remaining-rows))) ;; 2
(def empty-row (vec (repeat board-width 0))) ;; [0 0 0 0 0 0 0 0 0 0]
(def empty-rows (repeat num-cleared-rows empty-row)) ;; ([0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0])
Så här ser board:et ut efter att kompletta rader tagits bort och nya tomma ersättningsrader lagts till i början:
(vec (concat empty-rows remaining-rows)) ;; [[0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [1 1 1 1 1 1 0 0 1 1]
;; [1 0 1 1 1 1 1 1 1 1]]
Funktionen concat lägger ihop de två listorna och skapar en ny lista med rader, medan vec därefter gör om listan till en vektor. Notera att både vec och concat returnerar immutable data, vilket är standard för alla datastrukturer i Clojure.
Det slog mig att vi kan förenkla koden något.
Vi börjar med att göra empty-board något mer läsbar genom att lägga till empty-row:
(ns tetrisanalyzer.board.core)
(defn empty-row [width]
(vec (repeat width 0)))
(defn empty-board [width height]
(vec (repeat height (empty-row width))))
Därefter kan vi ersätta:
(def empty-row (vec (repeat board-width 0)))
(def empty-rows (repeat num-cleared-rows empty-row))
Med:
(def empty-rows (core/empty-board board-width num-cleared-rows))
Nu kan vi slutligen använda let för att plockar ihop de olika beräkningsstegen till en funktion:
(ns tetrisanalyzer.board.clear-rows
(:require [tetrisanalyzer.board.core :as core]))
(defn incomplete-row? [row]
(some zero? row))
(defn clear-rows [board]
(let [width (count (first board))
height (count board)
remaining-rows (filter incomplete-row? board)
num-cleared-rows (- height (count remaining-rows))
empty-rows (core/empty-board width num-cleared-rows)]
(vec (concat empty-rows remaining-rows))))
I och med att vi redan testat alla deluttryck, är chansen stor att även funktionen fungerar som förväntat:
(clear-rows board) ;; [[0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [1 1 1 1 1 1 0 0 1 1]
;; [1 0 1 1 1 1 1 1 1 1]]
Och visst, det ser korrekt ut!
Vi avslutar med att skapa ett test i det nya namespacet clear-rows-test:
▾ tetris-polylith
▸ bases
▾ components
▸ board
▸ src
▾ test
clear-rows-test.clj
core-test.clj
▸ piece
▸ development
▸ projects
(ns tetrisanalyzer.board.clear-rows-test
(:require [clojure.test :refer :all]
[tetrisanalyzer.board.clear-rows :as sut]))
(deftest clear-two-rows
(is (= [[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 0 0 1 1]
[1 0 1 1 1 1 1 1 1 1]]
(sut/clear-rows [[0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 0 0 1 1]
[1 0 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]]))))
När vi kör testet visar det grönt och vi kan därmed gå vidare med Python-implementationen. Men först några ord om arbetssättet.
Du kanske lade märke till att vi implementerade koden innan vi skrev testet, och att vi inte skrev hela funktionen i ett enda svep. Istället införde vi ett litet beräkningssteg i taget, som vi först på slutet satte ihop till en hel funktion. Det gjorde att vi kunde justera lösningen vartefter som förståelsen ökade, och att vi inte behövde hålla allt i huvudet. Hjärnan har sina begränsningar och därför är det viktigt att vi hjälper den lite på traven!
I Clojure kompileras endast det som ändrats, vilket oftast går blixtsnabbt. Det gör att du glömmer bort att det faktiskt är ett kompilerande språk. Du kan öppna vilken fil/namespace som helst i kodbasen, och exekvera en funktion, kanske från ett redan existerande kommentars-block, och omedelbart få tillbaka ett svar. Borta är känslan av att något står emellan dig och koden, i form av väntan på att kompilatorn ska bli nöjd.
Det är lätt att bli beroende av denna omedelbara återkoppling och känslan ligger väldigt nära i hur det är att jobba med händerna, t.ex. att dreja:

Kontakten med leran liknar den du har när du jobbar i en REPL, en omedelbarhet som gör att du snabbt kan testa, justera och jobba mot ett tänkt mål, i realtid.
Avsaknaden av statiskt typning gör att kompilatorn bara behöver kompilera den lilla ändring som just gjorts och inget annat, vilket är en förutsättning för detta snabba arbetssätt. Kvalitet uppnås genom att testa koden ofta och i små steg, i kombination med traditionell testning och bibliotek som malli och spec för att validera data.
I språk som kräver mer omfattande kompilering, eller saknar en avancerad REPL, är det mycket vanligt att man börjar med att skriva ett test, som ett sätt att driva koden framåt, men också för att trigga en kompilering av koden. I ett språk som Clojure kan du röra dig framåt i ännu mindre steg, på ett snabbt och kontrollerat sätt.
Nog om detta och låt oss istället växla över till Python!
Vi börjar med att försöka få till en så bra utvecklarupplevelse som möjligt, liknande den vi har i Clojure. Det finns många bra IDE:er, men här kommer jag att använda PyCharm.
c.InteractiveShellApp.exec_lines = ["%autoreload 2"]
c.InteractiveShellApp.extensions = ["autoreload"]
c.TerminalInteractiveShell.confirm_exit = False
~/.ipython/profile_default/ipython_config.pyPyCharm > Settings > Python > Console > Python Console > Starting script och lägg till:%load_ext autoreload
%autoreload 2
%aimport -pydev_umd
%load_ext autoreload laddar IPython-extensionen autoreload, vilket gör att moduler kan laddas om automatiskt när filer ändras.%autoreload 2 aktiverar automatisk omladdning av alla moduler (utom de som är undantagna)%aimport -pydev_umd exkluderar pydev_umd från omladdning, för att få bort fel som annars visas i REPLn.View > Tool Windows > Python Console från menyn, som öppnar en `Python Console'-panel i nedre delen av IDEn.In [1] ska nu visas istället för >>>, vilket indikerar att det är IPython REPLn som kör, och inte standard-REPLn.Pycharm > Settings... > Keymap > Plugins > Python Community Editor för att kunna skicka kod till REPLn på samma sätt som jag är van vid i Clojure.ipython>=8.0.0 till pyproject.toml, och kört uv sync --dev för att ladda biblioteket.Mycket av det som står här kommer från denna bloggpost under rubriken "Easy setup" (tack David Vujic!).
Nu är det hög tid att skriva lite Python-kod, och vi börjar med att skapa modulen clear_rows.py:
▾ components
▾ tetrisanalyzer
▾ board
__init__.py
clear_rows.py
copy.py
▸ piece
▸ test
Därefter lägger vi till raden:
row = [1, 1, 1, 0, 1, 1, 1, 0, 1, 1]
Varefter vi kör snabbkommandot för att skicka hela modulen till REPLn, så att den läses in (output från REPLn):
In [1]: runfile('/Users/tengstrand/source/tetrisanalyzer/langs/python/tetris-polylith-uv/components/tetrisanalyzer/board/clear_rows.py', wdir='/Users/tengstrand/source/tetrisanalyzer/langs/python/tetris-polylith-uv/components/tetrisanalyzer/board')
Nu kan vi markera row i editorn och skicka den till REPLn:
In [2]: row
Out[2]: [1, 1, 1, 0, 1, 1, 1, 0, 1, 1]
Genom REPLn har vi nu ett smidigt sätt att interagera med den kompilerade koden även i Python!
Låt oss översätta följande rad från Clojure till Python:
(some zero? row)
Genom att lägga följande rad till clear_rows.py:
0 in row
Nu kan vi markera raden och skickar den till REPLn, vilket är ett alternativ till att ladda hela modulen:
In [3]: 0 in row
Out[3]: True
Därefter ändrar vi row och testar igen:
row = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
0 in row
In [4]: 0 in row
Out[4]: False
Det verkar fungera! Dags att skapa en funktion av koden, och testköra den:
def is_incomplete(row):
return 0 in row
row = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
is_incomplete(row)
In [5]: is_incomplete(row)
Out[5]: False
Därefter uppdaterar jag row och testar igen:
row = [1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
is_incomplete(row)
In [6]: is_incomplete(row)
Out[6]: True
Det ser ut att fungera!
Nu lägger vi till en board till modulen, så att vi har något att testa mot:
def is_incomplete(row):
return 0 in row
board = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
I clojure kan vi filtrera fram icke kompletta rader så här:
(filter incomplete-row? board)
Detta skrivs enklast så här i Python:
[row for row in board if is_incomplete(row)]
The statement is a list comprehension that creates a new list by iterating over board and keeping only rows where is_incomplete returns True.
Låt oss testköra uttrycket:
In [7]: [row for row in board if is_incomplete(row)]
Out[7]:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1]]
Före for har vi row vilket är vad vi itererar över:
[row for row in board if is_incomplete(row)]
Python tillåter oss även att göra en beräkning för varje row, vilket kan exemplifieras med:
[row + [9] for row in board if is_incomplete(row)]
Som lägger till 9 i slutet av varje rad:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 9],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 9]]
Låt oss återgå till ursprungsversionen och tilldela den till remaining_rows:
def is_incomplete(row):
return 0 in row
board = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
remaining_rows = [row for row in board if is_incomplete(row)]
Innan vi går vidare, låt oss göra samma refaktorering av empty_row i core.py som vi gjorde i Clojure:
def empty_row(width):
return [0] * width
def empty_board(width, height):
return [empty_row(width) for _ in range(height)]
Vi fortsätter med att översätta denna Clojure-kod:
(def width (count (first board)))
(def height (count board))
(def remaining-rows (filter incomplete-row? board))
(def num-cleared-rows (- height (count remaining-rows))) ;; 2
(def empty-rows (core/empty-board width num-cleared-rows) ;; ([0 0 0 0 0 0 0 0 0 0] [0 0 0 0 0 0 0 0 0 0])
(vec (concat empty-rows remaining-rows)) ;; [[0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [0 0 0 0 0 0 0 0 0 0]
;; [1 1 1 1 1 1 1 0 1 1]
;; [1 0 1 1 1 1 1 1 1 1]]
Till Python:
width = len(board[0])
height = len(board)
num_cleared_rows = height - len(remaining_rows) # 2
empty_rows = empty_board(width, num_cleared_rows) # [[0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0]]
empty_rows + remaining_rows # [[0,0,0,0,0,0,0,0,0,0],
# [0,0,0,0,0,0,0,0,0,0],
# [0,0,0,0,0,0,0,0,0,0],
# [0,0,0,0,0,0,0,0,0,0],
# [1,1,1,1,1,1,0,0,1,1],
# [1,0,1,1,1,1,1,1,1,1]]
Jag har medvetet kopierat den funktionella stilen från Clojure till Python, och som ni ser fungerar det utmärkt även i Python, men med en brasklapp.
Vid ett tillfälle såg en del av Clojure-koden ut så här:
(def empty-row (vec (repeat board-width 0)))
(def empty-rows (repeat num-cleared-rows empty-row)])
Vilket jag översatte till:
empty_row = [0 for _ in range(board_width)]
empty_rows = [empty_row for _ in range(num_cleared_rows)]
Problemet med Python-koden är att empty_rows refererar till en och samma empty_row och om den sistnämda ändras, så ändras alla rader i empty_rows, vilket blir ett problem om num_cleared_rows är större än ett.
I den nya lösningen skapar vi i stället helt nya rader i Python, medan vi i Clojure kan dela på samma rad då den är immutable. Att allt är immutable i Clojure är en stor fördel när vi låter datat flöda genom systemet, då det hindrar datat från att sprida sig okontrollerat till andra delar längre ner i flödet.
Låt oss sätta ihop allting till en funktion:
from tetrisanalyzer.board.core import empty_board
def is_incomplete(row):
return 0 in row
def clear_rows(board):
board_width = len(board[0])
board_height = len(board)
remaining_rows = [row for row in board if is_incomplete(row)]
num_cleared_rows = board_height - len(remaining_rows)
empty_rows = empty_rows = empty_board(width, num_cleared_rows)
return empty_rows + remaining_rows
Nu kan vi provköra den. Notera att vi tagit bort board från källkodsfilen, men att REPLn minns den från tidigare, så att den kan användas vid anropet:
clear_rows(board)
In [8]: clear_rows(board)
Out[8]:
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1]]
Det ser korrekt ut!
Innan vi testar, behöver vi exponera funktionen clear_rows i board-interfacet, genom att uppdatera components/tetrisanalyzer/board/__init__.py (och skicka modulen till REPLn):
from tetrisanalyzer.board.clear_rows import clear_rows
from tetrisanalyzer.board.core import empty_board, set_cell, set_piece
__all__ = ["empty_board", "set_cell", "set_piece", "clear_rows"]
Slutligen lägger vi till testet test_clear_rows.py till board-komponenten:
▾ components
▾ tetrisanalyzer
▸ board
▸ piece
▾ test
▾ components
▾ tetrisanalyzer
▾ board
__init__.py
test_clear_rows.py
test_core.py
▸ piece
from tetrisanalyzer import board
def test_clear_rows():
input = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
expected = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1, 1, 1]]
assert expected == board.clear_rows(input_board)
Nu kan vi köra alla tester med uv sync --dev:
============================================ test session starts ============================================
platform darwin -- Python 3.13.11, pytest-9.0.2, pluggy-1.6.0
rootdir: /Users/tengstrand/source/tetrisanalyzer/langs/python/tetris-polylith-uv
configfile: pyproject.toml
collected 3 items
test/components/tetrisanalyzer/board/test_clear_rows.py . [ 33%]
test/components/tetrisanalyzer/board/test_core.py .. [100%]
============================================= 3 passed in 0.01s =============================================
Det fungerar!
Jag har medvetet hållit Python-koden funktionell, dels för att lättare kunna jämföra med Clojure, men också för att jag gillar enkelheten med funktionell programmering. Vi lärde oss också att vi behövde hålla tungan rätt i mun när vi jobbar med mutable data!
Det viktigaste budskapet är dock att det går att jobba snabbare och i mindre steg, när vi tar os mot tänkta mål!
Happy Coding!
Published: 2026-01-08