
Creating a Chatbot with a consistent personality that can replicate human conversational abilities and chat with a user about anything he likes.
The dataset we chose is the Persona Chat dataset, which is a dataset designed specifically to tackle the problem of making a consistent personality for the chatbot model. This dataset is composed of two things: personas and dialogues between these personas. The personas consist of at least 5 profile sentences, which are very simple like “I like football” for example, describing the personality of that specific persona. The dialogues are engaging conversations between the personas that were played by normal people trying to convey their assigned personas.
There are also revised personas, which are basically copies of the original personas but avoid word overlaps with them by trying to be more general than the persona or even more specialized. This makes the model’s task much more challenging by avoiding modeling that takes advantage of trivial word overlap.The dataset contains 1155 personas, setting aside 100 personas for validation and 100 personas for testing. There are also rewritten sets of the original 1155 personas, which are the revised personas. These personas resulted in 162,064 utterances over 10,907 dialogs. 1000 dialogues that had 15,602 utterances are set aside for validation, and 968 dialogues containing 15,024 utterances are set aside for test.
This dataset was perfect for our problem as it contained different personalities in addition to their conversation, this is why we chose this specific dataset. We also believe that it has enough examples to be able to train our model and increase the accuracy of the results.

The input for the Chatbot is a normal text message and the Chatbot should figure out the best way to respond. The chatbot also tries to keep a consistent personality and to get more engaged and ask questions.
In the second Milestone of the project, we discovered that the work of literature that we selected (Personalizing Dialogue Agents: I have a dog, do you have pets too?) was not the state of the art model that trains the "Persona-Chat" Dataset. Our Selected paper used a "KV Profile Memory" model.
The work of litreture that achieved state-of-the-art model "P2 Bot" is titled "You Impress Me: Dialogue Generation via Mutual Persona Perception". You can find the paper in the references section.
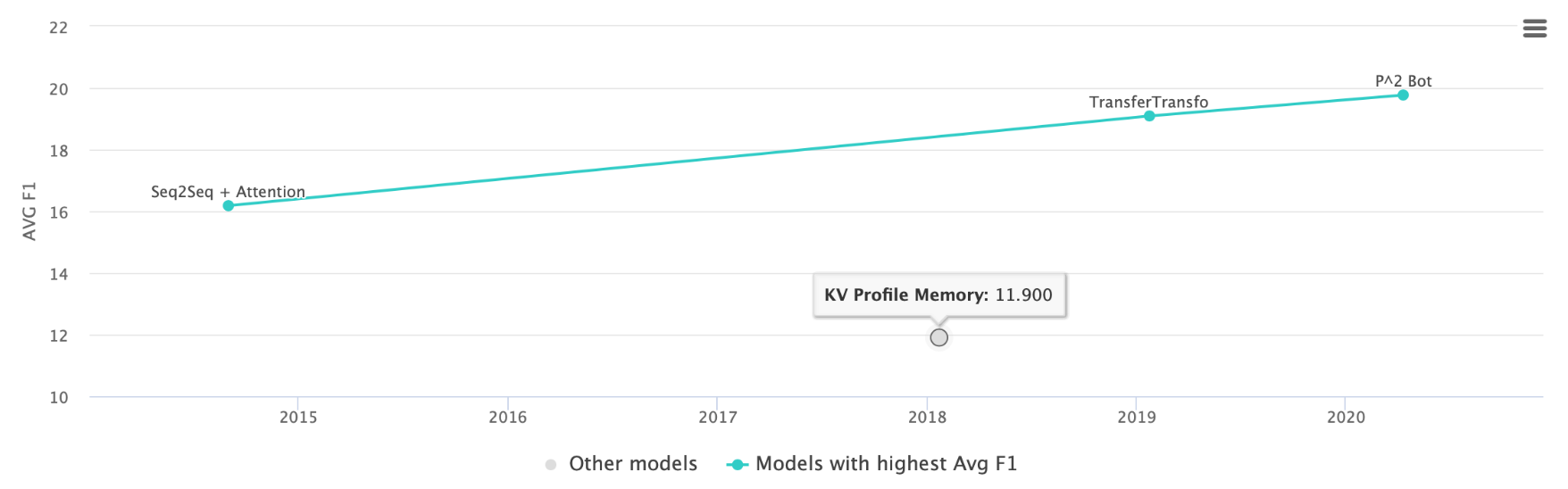
For the "Persona-Chat" dataset, the following diagram illustrates the difference in the F1 score between the state-of-the-art model "P2 Bot" and the work of litreture that we used "KV Profile Memory"
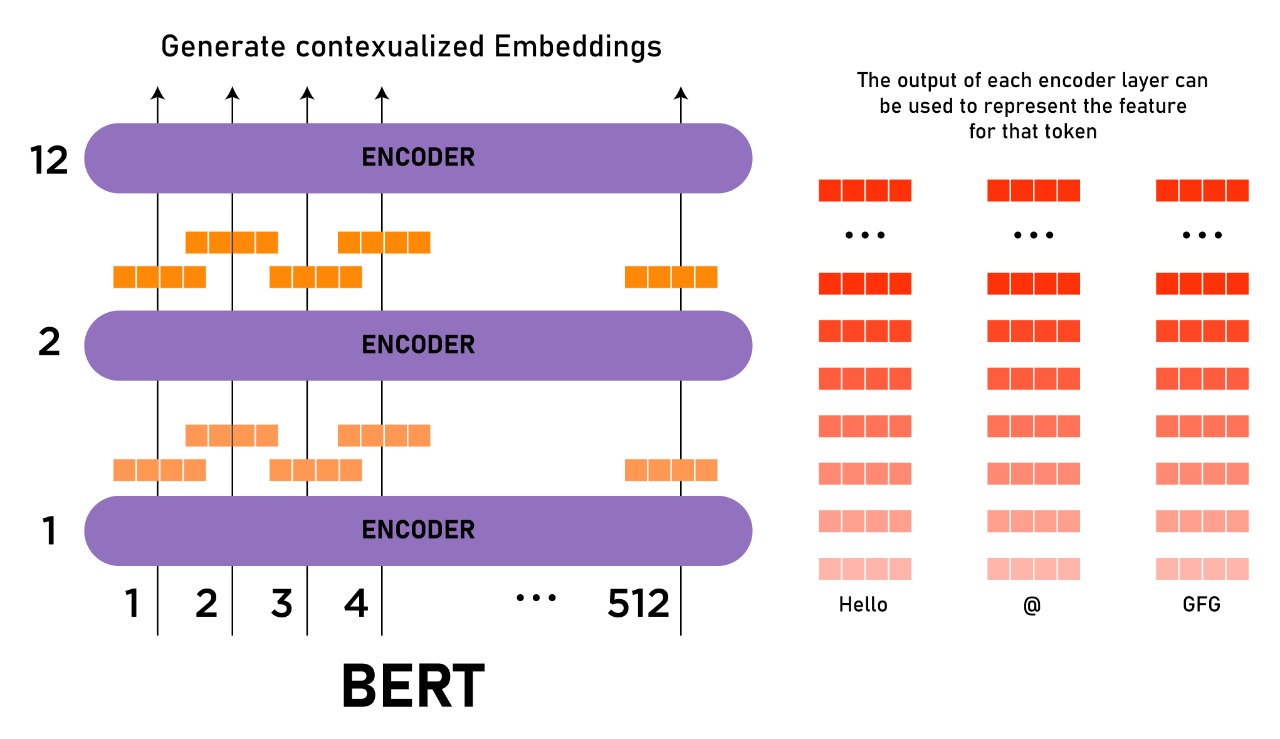
Later in our second Milestone, we discovered that our selected work of literature (Personalizing Dialogue Agents: I have a dog, do you have pets too?) was published in 2018. This is the same year when the BERT Model was first introduced. After researching, we discovered that the BERT model is the current state-of-the-art model for NLP.
In this model, the aim is to make chatbots more engaging by giving them a persistent persona to have a more consistent personality than normal chatbots. The problems of normal chatbots include lack of personality consistency as well as having a tendency for giving non-specific answers like “I don’t know” for example, due to having access to only recent dialogue history (Vinyals and Le, 2015). This model aims to solve these problems by training the model to ask and answer questions on personal topics, and using the dialogue to build a persona for the speaking partner.
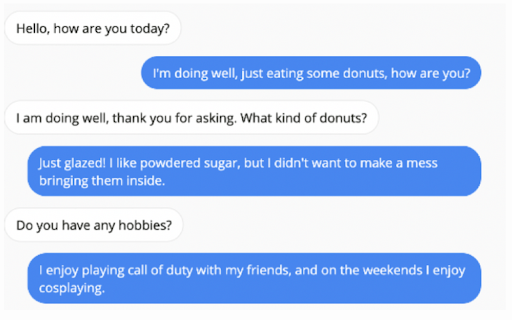
The Persona-Chat dataset was created especially to train these kinds of models and test their consistency as well as their engagement with the speaker compared to normal chatbots. The basic idea was to create some generic personas with general sentences about that personality and getting people to use that personality in an engaging dialogue, which would then be passed to the model in addition to the personas of the speakers for training. An example of two personas along with a dialogue between them is shown below.
After the personas and the dialogues are passed to the model, it is trained using different techniques including ranking and generative models. There were 1155 personas for training, 100 for validation and 100 for testing. These personas generated a dataset of 162,064 utterances over 10,907 dialogs, 15,602 utterances (1000 dialogs) of which are set aside for validation, and 15,024 utterances (968 dialogs) for test. After training the models, they were tested using automated metrics in case of not specifying a persona, giving them an original persona, or giving them a revised persona, which is a persona similar to an original one but without overlapping any words. The results are shown below.
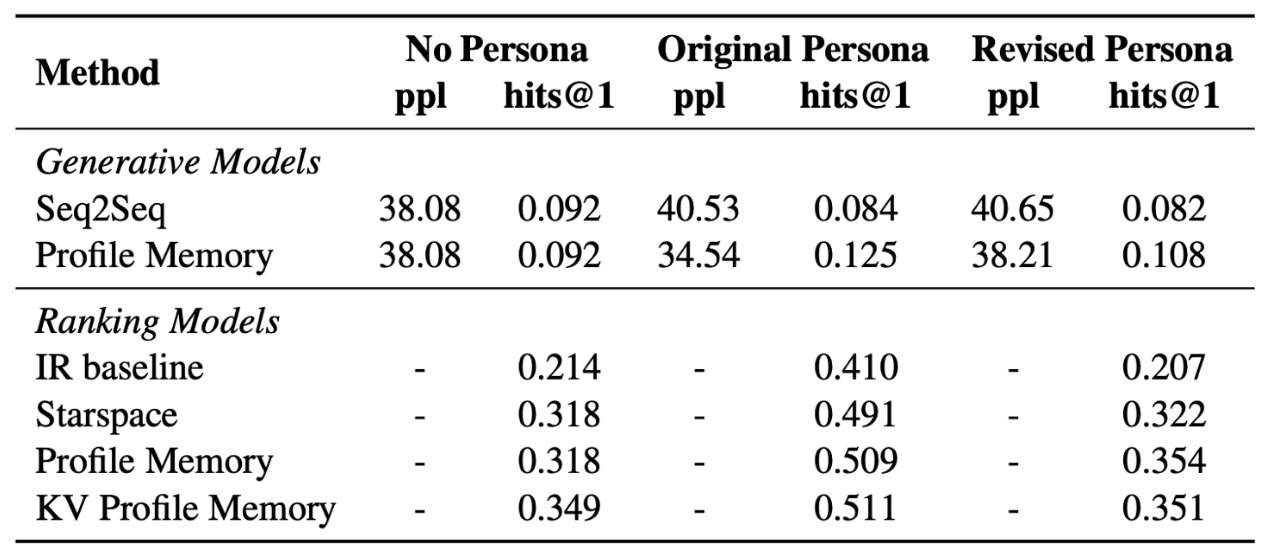
The results show that the Ranking models are better than the Generative models in all types of tests. The best Ranking model was the key-value profile memory model, which uses keys to perform attention and output the values instead of the same keys as the original. Another way to test the models was human evaluation, which is giving a normal person a persona as usual and putting that person in a conversation with a model but that person thinks that the other speaker is a normal person as well. After the dialogue is completed, the participant is asked to evaluate the fluency, engagingness and consistency of the model. The results of the human evaluation tests of the models compared to normal models based on Twitter and OpenSubtitles sources are shown below.
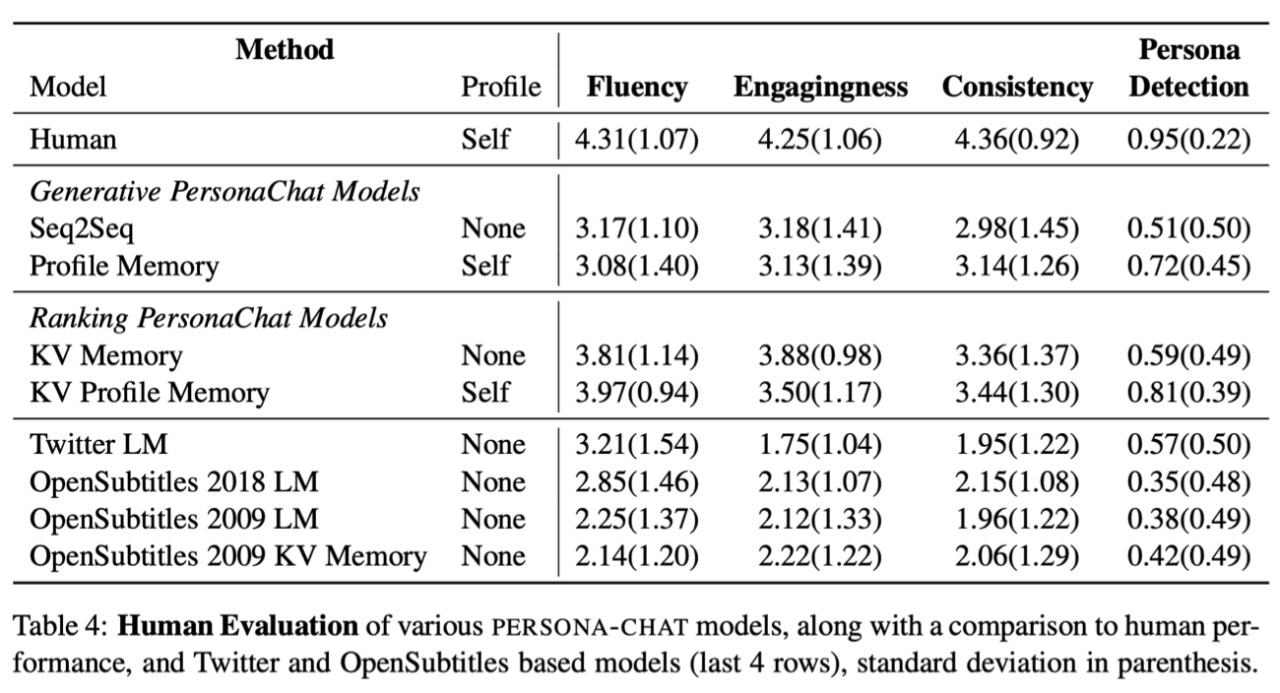
The results show that the models strongly outperform the Twitter and OpenSubtitles based models. Moreover, the Ranking PersonaChat models also continue to outperform the Generative PersonaChat models. The KV profile memory model is still better than the KV memory model. Of course, the human evaluation is still a lot higher than the models, yet there is a clear advance in the test results of the models, and the results are getting closer to the human results.
In conclusion, the models using these techniques outperformed normal models in their consistency, personality-wise, as well as the engagingness. This was a big step towards getting models to have a consistent personality. The next step is to let the model ask questions about the users’ personas, remember the answers, and use them naturally in conversation.

In the initial milestone of the project, we trained the Persona-Chat Dataset on a pretrained models from ParlAI. The model is a transfer-generator model and can be found on ParlAI's website by the name "ZOO:TUTORIAL_TRANSFORMER_ GENERATOR/MODEL".
Note that we did not leave the model train for a lot of time, because most models required a huge amount of time (in the range of days). Accordingaly, when training a model, we constrained the training time to the time we desire.
When we used transfer learning, we were able to obtain better results (lower loss values and the chatbot was responding with very logical answers) in the shortest training time possible.
Fine tuned the hyperparameters including the optimizer and batch size to enhance the performance of the model and get a more consistent personality for the model
We did not find any work of literature using the BERT model on the Persona-Chat dataset. We used the BERT model provided my ParlAI and trained it on the Persona-Chat dataset.
When we trained the persona chat on the Pretrained model "ZOO:TUTORIAL_TRANSFORMER_ GENERATOR/MODEL" for two hours, we got a loss of 2.60
Training the BERT model on the personachat dataset for 6 hours (0.125 ephochs), we achieved a loss of o.92
Here you will detail the details related to training, for example:
Conclusion and future work (including lessons learned and interesting findings
First of all, we found out that using transfer learning and loading the pramaters of an existing model was much better than taining a new seq2seq model from the start
In addition, Using the BERT model was much more efficient and reduced the model loss significantly. Even though we only ran the model on 0.125 epoch and we were training the model from the start, the model loss was lower than that of running the pretrained model
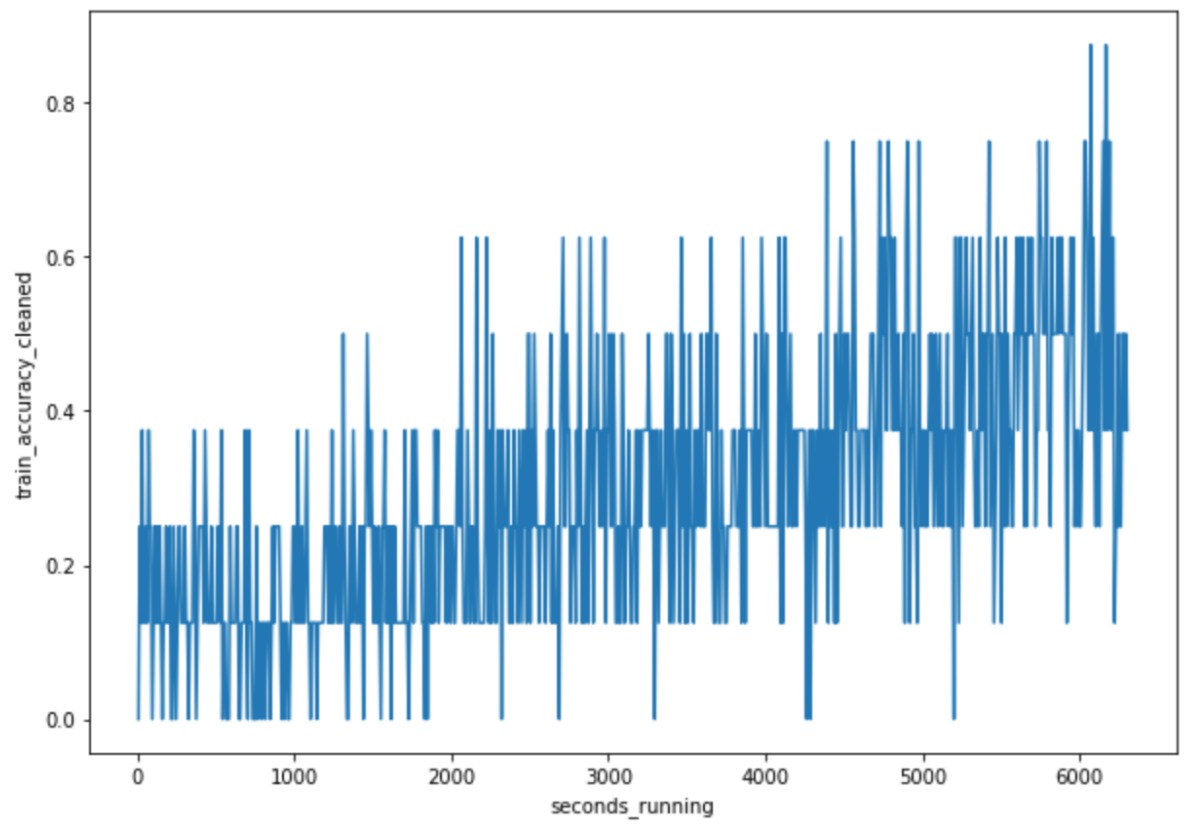
Besides, the diagram below shows that the BERT model,in the 0.125 epoch we ran, had its accuracy increasing.
Note that graph is fluctuating a lot. That's because we could not run the model with a batch size greater than 1, due to the hardware limitations of our laptops. Accordingaly, the model parameters were changed after each batch (which is only 1 sample from the dataset).
Finally, when interacting with the chatbot, the chatbot was not providing sound responses because it did not have a relatively large training time and it was only trained on 1/8 of the dataset, so the model's dictionary is limited.