class: center, middle, inverse, title-slide .title[ # Applied Web Scraping ] .author[ ### Tobias Rüttenauer ] .date[ ### 2023-03-27 ] --- # Introduction ### Course <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:currentColor;overflow:visible;position:relative;"><path d="M352 256C352 278.2 350.8 299.6 348.7 320H163.3C161.2 299.6 159.1 278.2 159.1 256C159.1 233.8 161.2 212.4 163.3 192H348.7C350.8 212.4 352 233.8 352 256zM503.9 192C509.2 212.5 512 233.9 512 256C512 278.1 509.2 299.5 503.9 320H380.8C382.9 299.4 384 277.1 384 256C384 234 382.9 212.6 380.8 192H503.9zM493.4 160H376.7C366.7 96.14 346.9 42.62 321.4 8.442C399.8 29.09 463.4 85.94 493.4 160zM344.3 160H167.7C173.8 123.6 183.2 91.38 194.7 65.35C205.2 41.74 216.9 24.61 228.2 13.81C239.4 3.178 248.7 0 256 0C263.3 0 272.6 3.178 283.8 13.81C295.1 24.61 306.8 41.74 317.3 65.35C328.8 91.38 338.2 123.6 344.3 160H344.3zM18.61 160C48.59 85.94 112.2 29.09 190.6 8.442C165.1 42.62 145.3 96.14 135.3 160H18.61zM131.2 192C129.1 212.6 127.1 234 127.1 256C127.1 277.1 129.1 299.4 131.2 320H8.065C2.8 299.5 0 278.1 0 256C0 233.9 2.8 212.5 8.065 192H131.2zM194.7 446.6C183.2 420.6 173.8 388.4 167.7 352H344.3C338.2 388.4 328.8 420.6 317.3 446.6C306.8 470.3 295.1 487.4 283.8 498.2C272.6 508.8 263.3 512 255.1 512C248.7 512 239.4 508.8 228.2 498.2C216.9 487.4 205.2 470.3 194.7 446.6H194.7zM190.6 503.6C112.2 482.9 48.59 426.1 18.61 352H135.3C145.3 415.9 165.1 469.4 190.6 503.6V503.6zM321.4 503.6C346.9 469.4 366.7 415.9 376.7 352H493.4C463.4 426.1 399.8 482.9 321.4 503.6V503.6z"/></svg> [https://github.com/ruettenauer/Web_Scraping](https://github.com/ruettenauer/Web_Scraping) This course profited a lot from existing materials by .pull-left[ - [Data science for economists](https://github.com/uo-ec607) by Grant McDermott - [Bit by Bit](https://www.bitbybitbook.com/en/1st-ed/preface/) by Matt Salganic - [Digital Trace Data](https://sicss.io/2022/oxford/schedule) by Ridhi Kashyap ] .pull-right[ - [Webscraping Introduction](https://github.com/theresagessler/warwick_scraping/blob/master/gessler_slides.pdf) by Theresa Gessler - [Computational Social Science](https://bookdown.org/paul/2021_computational_social_science/) by Paul Bauer - [SICSS materials](https://sicss.io/) ] -- ### Me <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:currentColor;overflow:visible;position:relative;"><path d="M384 0H96C60.65 0 32 28.65 32 64v384c0 35.35 28.65 64 64 64h288c35.35 0 64-28.65 64-64V64C448 28.65 419.3 0 384 0zM240 128c35.35 0 64 28.65 64 64s-28.65 64-64 64c-35.34 0-64-28.65-64-64S204.7 128 240 128zM336 384h-192C135.2 384 128 376.8 128 368C128 323.8 163.8 288 208 288h64c44.18 0 80 35.82 80 80C352 376.8 344.8 384 336 384zM496 64H480v96h16C504.8 160 512 152.8 512 144v-64C512 71.16 504.8 64 496 64zM496 192H480v96h16C504.8 288 512 280.8 512 272v-64C512 199.2 504.8 192 496 192zM496 320H480v96h16c8.836 0 16-7.164 16-16v-64C512 327.2 504.8 320 496 320z"/></svg> [Tobias Rüttenauer](https://ruettenauer.github.io/) <svg aria-hidden="true" role="img" viewBox="0 0 512 512" style="height:1em;width:1em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:currentColor;overflow:visible;position:relative;"><path d="M464 64C490.5 64 512 85.49 512 112C512 127.1 504.9 141.3 492.8 150.4L275.2 313.6C263.8 322.1 248.2 322.1 236.8 313.6L19.2 150.4C7.113 141.3 0 127.1 0 112C0 85.49 21.49 64 48 64H464zM217.6 339.2C240.4 356.3 271.6 356.3 294.4 339.2L512 176V384C512 419.3 483.3 448 448 448H64C28.65 448 0 419.3 0 384V176L217.6 339.2z"/></svg> [t.ruttenauer@ucl.ac.uk](mailto:t.ruttenauer@ucl.ac.uk) <svg aria-hidden="true" role="img" viewBox="0 0 640 512" style="height:1em;width:1.25em;vertical-align:-0.125em;margin-left:auto;margin-right:auto;font-size:inherit;fill:currentColor;overflow:visible;position:relative;"><path d="M623.1 136.9l-282.7-101.2c-13.73-4.91-28.7-4.91-42.43 0L16.05 136.9C6.438 140.4 0 149.6 0 160s6.438 19.65 16.05 23.09L76.07 204.6c-11.89 15.8-20.26 34.16-24.55 53.95C40.05 263.4 32 274.8 32 288c0 9.953 4.814 18.49 11.94 24.36l-24.83 149C17.48 471.1 25 480 34.89 480H93.11c9.887 0 17.41-8.879 15.78-18.63l-24.83-149C91.19 306.5 96 297.1 96 288c0-10.29-5.174-19.03-12.72-24.89c4.252-17.76 12.88-33.82 24.94-47.03l190.6 68.23c13.73 4.91 28.7 4.91 42.43 0l282.7-101.2C633.6 179.6 640 170.4 640 160S633.6 140.4 623.1 136.9zM351.1 314.4C341.7 318.1 330.9 320 320 320c-10.92 0-21.69-1.867-32-5.555L142.8 262.5L128 405.3C128 446.6 213.1 480 320 480c105.1 0 192-33.4 192-74.67l-14.78-142.9L351.1 314.4z"/></svg> Lecturer in Quantitative Social Science (Environmental Sociology) --- # Table of contents 1. [Digital Trace Data](#trace) 2. [Web Scraping](#scraping) 3. [APIs](#api) 4. [Practical Exercise](https://raw.githack.com/ruettenauer/Web_Scraping/main/02_Exercise/02_Exercise.html) --- class: inverse, center, middle name: trace # Digital Trace Data --- # Digital Trace Data ### Social transformation: - Digital technologies permeate social, economic, political life. - A lot of social interactions happen in the digital world. ### Data revolution: - The digitalisation of our lives creates data by-products: digital trace data. - Data that require __repurposing__ because they were not intentionally collected for research. - Existing data may require a lot of thoughts and work to fit your purpose. -- ### Research revolution: - Ask the right questions! - Huge amounts of (big) data, but: __What things are worth counting?__ --- # Digital Trace Data .pull-left[ ### Strenghs of Trace Data - Big - Always on - Actual behaviour - Non-reactive - Captures social relations - Mergable (e.g. geo-coordinates) .pull.left[  [Dodds et al, ArXiv](https://arxiv.org/pdf/2008.07301.pdf) ] ] -- .pull-right[ ### Weaknesses of Trace Data - Incomplete & Inaccessible - Non-representative & Selective - Drifting - Algorithmically confounded - Dirty - Sensitive to privacy issues .pull.left[  [Lazer et al, Science](https://www.science.org/doi/10.1126/science.1248506#F2) ] ] --- # Digital Trace Data ### Social research data in a digital age  --- # Examples ### The Decline and Persistence of the Old Boy: Private Schools and Elite Recruitment  [Reeves et al., American Sociological Review](https://journals.sagepub.com/doi/10.1177/0003122417735742) --- # Examples ### Matthew Effect & Cumulative Status Bias in NBA All-Star Elections - based on 1.2 million game logs from the 3,300 players ([www.basketball-reference.com/](https://www.basketball-reference.com/)) .pull-left[  ] .pull-right[  ] [Biegert et al., American Sociological Review](https://journals.sagepub.com/doi/10.1177/00031224231159139) --- # Examples ### Estimating Migrant Stocks Using Digital Traces and Survey Data  [Rampazzo et al., Demography](https://doi.org/10.1215/00703370-9578562) --- # Examples .pull-left[ ### Population Studies: Authors and topics over the past 75 years  ] .pull-right[ ###  ] [Mills & Rahal, Population Studies](https://www.tandfonline.com/doi/full/10.1080/00324728.2021.1996624) --- # Examples ### Increase in Discrimination Against Arabs and Muslims on AirBnB after Paris Attacks 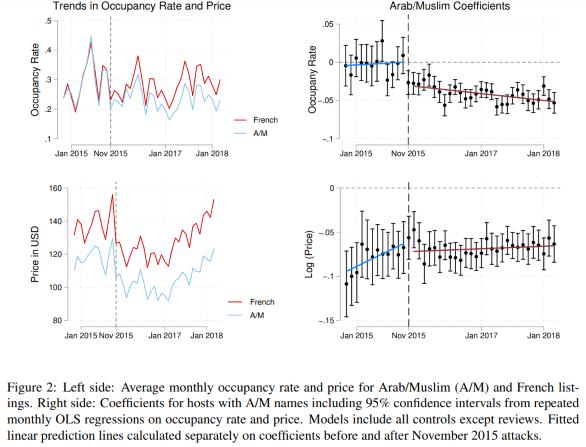 [Wagner & Petev, Working Paper](https://crest.science/RePEc/wpstorage/2019-22.pdf) --- # Accessing Digital Trace Data ### 1) Web (Screen) scraping ### 2) Data from application programming interfaces (APIs) ### 3) Archives or data sharing platforms - e.g. [Google Trends](https://trends.google.com/home), [IPUMS](https://www.ipums.org/), [Our World in Data](https://ourworldindata.org/), [London Datastore](https://data.london.gov.uk/) ### 4) Data sharing agreements with data owners - e.g. [UK Data Service](https://ukdataservice.ac.uk/), or commercial platforms --- class: inverse, center, middle name: scraping # Web Scraping --- # What is webscraping? ### Extracting data from webpages - Anything from university webpage and geographic information to social media - Lots of different techniques - Process unstructured (messy) data and make structured (data.table) - __ ~ Automated copy & paste__ -- ### Types of scraping - Gathering as diverse information as possible from different pages vs. - Very specific scrapers - Fully automated scrapers to half-automated scripts - Single-use scraping vs. regular data collection -- ### Sofware for scraping - Python - R & Rstudio --- # Current debates about scraping ### Is scraping legal? - Read the website’s Terms of Service: are you allowed to do this? - Larger websites like Facebook, Instagram, NY Times do not allow these practices - However, a recent [LinkedIn court case in th US](https://en.wikipedia.org/wiki/HiQ_Labs_v._LinkedIn) allows webscraping - Just because you can scrape it, doesn’t mean you should -- ### Is scraping ethical? - Are the data sensitive? - Could the use of the data harm in some way? - Freely accessible content vs. commercial content --- # The rules of the game ### Respect the hosting site’s wishes - Check if an API exists or if data are available for download - Keep in mind where data comes from and give credit (and respect copyright if you want to republish the data!) - Some websites disallow automated scraping -- ### Limit your bandwidth use - Wait one or two seconds after each hit - Scrape only what you need, and just once (e.g. store the file on disk, and then parse it) - …otherwise you’ll get a visit from the IT guys! -- ### Respect data protection - Secure storage vs. deletion of data - Anonymization of users --- # Browsing vs. scraping ### Browsing - You click on something - Browser sends request to server that hosts webpage - Server returns resource (e.g. HTML document) - Browser interprets HTML and renders it in a nice fashion -- ### Scraping with R - You manually specify a resource - R sends request to server that hosts website - Server returns resource - R parses HTML (i.e., interprets the structure), but does not render it in a nice fashion - You tell R which parts of the structure to focus on and what to extract -- First step is to __understand some HTML__ --- # HTML: a primer ### HTML is text with marked-up structure, defined by __tags__: ```html <!DOCTYPE html> <html> <body> <h1>My First Heading</h1> <p>My first paragraph.</p> </body> </html> ``` -- ### Some common tags: - Document elements: `<head>`, `<body>`, `<footer>`… - Document components: `<title>`, `<h1>`, `<p>`, `<div>`… - Text style: `<b>`, `<i>`, `<strong>`… - Hyperlinks: `<a href="url">` ### General structure - `<tagname>Content goes here...</tagname>` --- # Inspect your website ### CSS - Cascading Style Sheets (CSS): describes formatting of HTML components - _Properties_. CSS properties are the “how” of the display rules. These are things like which font family, styles and colours to use, page width, etc. - _Selectors_. CSS selectors are the “what” of the display rules. They identify which rules should be applied to which elements. E.g. Text elements that are selected as “.h1” (i.e. top line headers) are usually larger and displayed more prominently than text elements selected as “.h2” (i.e. sub-headers). - The key point is that if you can identify the CSS selector(s) of the content you want, then you can isolate it from the rest of the webpage content that you don’t want. This where SelectorGadget comes in. ### SelectorGadget - [SelectorGadget](https://selectorgadget.com/) as Chrome Extension - Inspect option in Chrome --- # Inspect your website ### Wikipedia Example - [https://en.wikipedia.org/wiki/List_of_countries_by_life_expectancy](https://en.wikipedia.org/wiki/List_of_countries_by_life_expectancy) 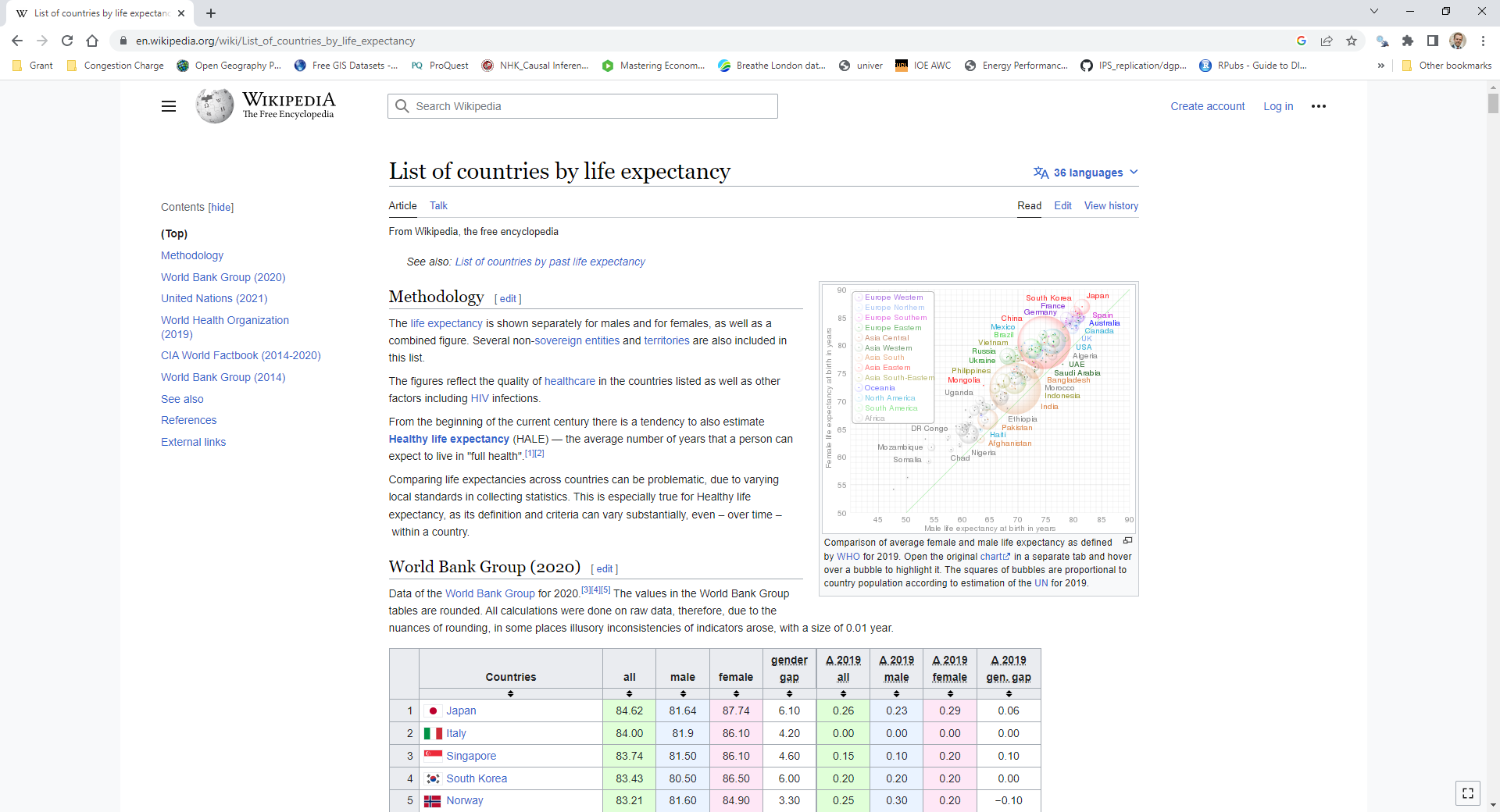 --- # Inspect your website ### Wikipedia Example - Use inspect option to select table - copy Xpath - In this case: `//*[@id="mw-content-text"]/div[1]/table[1]` 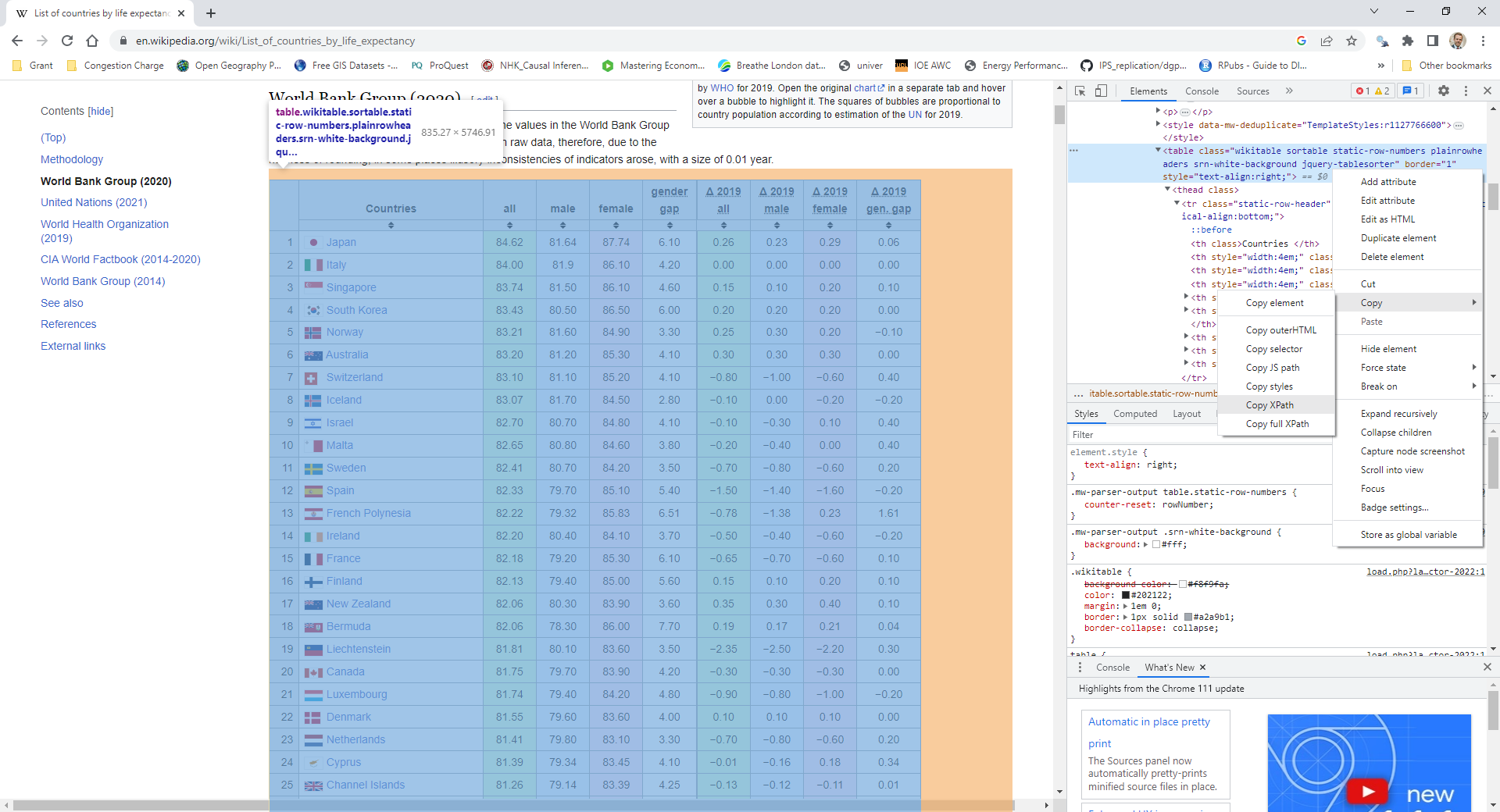 --- # Scrape the website ### R Package `rvest` - Package for parsing and scraping - Covers most frequent use cases - but relatively simple: no dynamic webpages [rvest Vignette](https://cran.r-project.org/web/packages/rvest/vignettes/rvest.html) ### Some important commands - `read_html()` - `html_nodes()` - `html_elements()` - `html_text2()` - `html_table()` - `html_attrs()` --- # Example 1: Wiki ### Parsing the url of the website ```r library(rvest) library(xml2) url <- "https://en.wikipedia.org/wiki/List_of_countries_by_life_expectancy" parsed <- read_html(url) ``` This returns an xml object that contains all the information of the website. ```r parsed ``` ``` ## {html_document} ## <html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-enabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-enabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled" lang="en" dir="ltr"> ## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ... ## [2] <body class="skin-vector skin-vector-search-vue mediawiki ltr sitedir-ltr ... ``` --- # Example 1: Wiki ### Extract the information we need - we use the xpath that we have extracted above ```r # Select the desired element parsed.sub <- html_element(parsed, xpath = '//*[@id="mw-content-text"]/div[1]/table[1]') # Convert to table table1.df <- html_table(parsed.sub) head(table1.df) ``` ``` ## # A tibble: 6 × 9 ## Countries all male female gendergap `Δ 2019all` Δ 201…¹ Δ 201…² Δ 201…³ ## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> ## 1 "" NA NA NA NA "" "" "" "" ## 2 "Japan" 84.6 81.6 87.7 6.1 "0.26" "0.23" "0.29" "0.06" ## 3 "Italy" 84 81.9 86.1 4.2 "0.00" "0.00" "0.00" "0.00" ## 4 "Singapore" 83.7 81.5 86.1 4.6 "0.15" "0.10" "0.20" "0.10" ## 5 "South Korea" 83.4 80.5 86.5 6 "0.20" "0.20" "0.20" "0.00" ## 6 "Norway" 83.2 81.6 84.9 3.3 "0.25" "0.30" "0.20" "−0.10" ## # … with abbreviated variable names ¹`Δ 2019male`, ²`Δ 2019female`, ## # ³`Δ 2019gen. gap` ``` --- # Example 1: Wiki ### Some cleaning - it always makes sense to clean the columns names ```r library(janitor) # clean names names(table1.df) <- janitor::make_clean_names(names(table1.df)) # Delete empty rows empt <- apply(table1.df, 1, FUN = function(x) all(is.na(x) | x == "")) table1.df <- table1.df[which(!empt), ] head(table1.df) ``` ``` ## # A tibble: 6 × 9 ## countries all male female gendergap d_2019all d_2019male d_2019…¹ d_201…² ## <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> ## 1 Japan 84.6 81.6 87.7 6.1 0.26 0.23 0.29 0.06 ## 2 Italy 84 81.9 86.1 4.2 0.00 0.00 0.00 0.00 ## 3 Singapore 83.7 81.5 86.1 4.6 0.15 0.10 0.20 0.10 ## 4 South Korea 83.4 80.5 86.5 6 0.20 0.20 0.20 0.00 ## 5 Norway 83.2 81.6 84.9 3.3 0.25 0.30 0.20 −0.10 ## 6 Australia 83.2 81.2 85.3 4.1 0.30 0.30 0.30 0.00 ## # … with abbreviated variable names ¹d_2019female, ²d_2019gen_gap ``` --- # Example 2: Starwars ### Wiki Example - Wikipedia pages have a specific structure - Data is stored in tables - We can extract these tables ### Real world - Websites are often "unstructured" - See for instance [https://rvest.tidyverse.org/articles/starwars.html]("https://rvest.tidyverse.org/articles/starwars.html") - We need to use some generic selectors to structure the data --- # Example 2: Starwars ```r starwars <- read_html("https://rvest.tidyverse.org/articles/starwars.html") # Extracting each section films <- html_elements(starwars, "section") films ``` ``` ## {xml_nodeset (7)} ## [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1999 ... ## [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: 20 ... ## [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: 200 ... ## [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-25\n ... ## [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleased: ... ## [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1983 ... ## [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 2015- ... ``` ```r # We have a structure now, but we need to extract the elements # Extract titles (which are all headings order 2 -> h2) titles <- html_elements(films, "h2") titles <- html_text2(titles) # Transform into plain text ``` --- # Example 2: Starwars - Extract titles and dates using [CSS rules](https://www.w3.org/TR/2011/REC-css3-selectors-20110929/) - Use [regular expressions](https://cran.r-project.org/web/packages/stringr/vignettes/regular-expressions.html) to select correct lines ```r # Extract dates # we can select the paragraph after heading 2 dates <- html_text2(html_elements(films, "h2 + p")) # Alternatively, subset to lines beginning with "Released" dates <- html_text2(html_elements(films, "p")) dates <- dates[grepl("^Released", dates)] dates <- gsub("^Released: ", "", dates) # clean text head(data.frame(titles, dates)) ``` ``` ## titles dates ## 1 The Phantom Menace 1999-05-19 ## 2 Attack of the Clones 2002-05-16 ## 3 Revenge of the Sith 2005-05-19 ## 4 A New Hope 1977-05-25 ## 5 The Empire Strikes Back 1980-05-17 ## 6 Return of the Jedi 1983-05-25 ``` --- # CSS selector rules ### Simple rules .small[ |Basic selector | Kind | Description| |--------|----------------|---------------------------| |* | Universal selector | Matches all elements| |name | Type selector | For any given name, matches all elements with that tag name.| |.name | Class selector | Matches all elements whose class attribute includes the word name.| |#name | ID selector | Matches all elements whose id attribute is exactly name.| |[attr] | Attribute selector | Matches all elements having an attribute named attr.| |[attr=value] | Attribute selector | Matches all elements having an attribute named attr whose value is value.| |[attr="value"] | Attribute selector | Same. With quotes around value, it may contain spaces and punctuation.| |:nth-child(n) | Pseudo-class | Matches all elements that are child number n (ignoring text and attribute nodes) under their parent.| |:nth-of-type(n) | Pseudo-class | Matches all elements that are child number n of that same tag name under their parent.| ] --- # CSS selector rules ### Rule combinations .small[ |Selector combination | Name | Description| |------|------|-------------------------------| |C > T | Child | Only match T when it is a child of an element matched by C.| |C T | Descendant | Only match T when it is a descendant of an element matched by C.| |C + T | Adjacent sibling | Only match T when it immediately follows C as C’s sibling.| |C ~ T | Sibling | Only match T when it is a sibling of C (regardless of order).| ] See more [CSS rules here](https://www.w3.org/TR/2011/REC-css3-selectors-20110929/) --- # Why scraping? .container[.content[__Why scraping? I could just copy and paste this!__]] --- # for() loops ### for() loops let you - run the same code along a series of indices `i` - run the same code across the elements of a vector (e.g. names / dates / urls) - repeat the same (scraping) task for multiple pages in seconds ```r for(i in c(1:3)){ pi <- paste0("https://nonsense/p", i) print(pi) Sys.sleep(2) # Sleep for 2 seconds before next task } ``` ``` ## [1] "https://nonsense/p1" ## [1] "https://nonsense/p2" ## [1] "https://nonsense/p3" ``` - If you scrape inside a loop, __don't overwhelm the server side!__ - use `Sys.sleep()` to __pause between tasks!__ --- # Web Scraping Summary ### Extracting data from webpages - Anything from university webpage and geographic information to social media - Lots of different techniques - Huge amounts of (big) data, Ask the right questions! - Respect the rules of the game -- ### Limits - Simple examples. Often web pages are complex with many different elements. - Yielding messy data - A lot of trial and error - Web / Screen scraping can be frustrating or unfeasible. What then? * For complex web pages, crowd worker platforms (e.g. Mechanical Turk) could be an option. * Some web data can be accessed via APIs. --- class: middle, center, inverse name: api # APIs --- # APIs ### What is an API? - Application programming interfaces or APIs are a software intermediary that allows two applications to talk to each other. - Web APIs allow one computer (a client) to ask another computer (a server) for some resource over the internet. - APIs provide a structured way to access data that are stored in databases and continuously updated. -- ### Advatages - Modern APIs adhere to standards that make data exchange programmatically accessible, safe and structured - Contrast with web scraping - Two important concepts when using APIs * Credentialling * Rate limiting --- # APIs - how it works - Let's get some [World Bank Data](https://databank.worldbank.org/home.aspx) 1) Search for indicators you want ```r library(WDI) # Search GDP per capita WDIsearch("GDP.*capita.*constant") ``` ``` ## indicator name ## 717 6.0.GDPpc_constant GDP per capita, PPP (constant 2011 international $) ## 11431 NY.GDP.PCAP.KD GDP per capita (constant 2015 US$) ## 11433 NY.GDP.PCAP.KN GDP per capita (constant LCU) ## 11435 NY.GDP.PCAP.PP.KD GDP per capita, PPP (constant 2017 international $) ## 11436 NY.GDP.PCAP.PP.KD.87 GDP per capita, PPP (constant 1987 international $) ``` ```r # Search GDP per capita WDIsearch("CO2.*capita") ``` ``` ## indicator ## 6032 EN.ATM.CO2E.PC ## 6048 EN.ATM.METH.PC ## 6059 EN.ATM.NOXE.PC ## name ## 6032 CO2 emissions (metric tons per capita) ## 6048 Methane emissions (kt of CO2 equivalent per capita) ## 6059 Nitrous oxide emissions (metric tons of CO2 equivalent per capita) ``` --- # APIs - how it works 2) Query the indicators ```r # Define countries, indicators form above, and time period wd.df <- WDI(country = "all", indicator = c('population' = "SP.POP.TOTL", 'gdp_pc' = "NY.GDP.PCAP.KD", 'co2_pc' = "EN.ATM.CO2E.PC"), extra = TRUE, start = 2019, end = 2019) ``` 3) Clean the data if necessary and plot ```r # Drop all country aggregrates wd.df <- wd.df[which(wd.df$region != "Aggregates"), ] ``` ```r library(ggplot2) pl <- ggplot(wd.df, aes(x = gdp_pc, y = co2_pc, size = population, color = region)) + geom_smooth(aes(group = 1), show.legend = "none") + geom_point(alpha = 0.5) + theme_minimal() + scale_y_log10() + scale_x_log10(labels = scales::dollar_format()) + labs(y = "CO2 emissions per capita", x = "GDP per capita") ``` --- # The Environmental Kuznet "curve" ```r pl ``` <img src="01_Intro_files/figure-html/unnamed-chunk-13-1.png" style="display: block; margin: auto;" /> --- # APIs - other examples ### Twitter API - Ideologies of protesters  [Barrie and Frey, PLOS One](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0259972) --- # APIs - other examples ### Twitter API See [academictwitteR](https://github.com/cjbarrie/academictwitteR) for Twitter API  --- # APIs - other examples ### Post-API Age ? - Companies restrict access to their data - Companies share only selective data ### However, the availability of data still incraeses - See a huge [collection of social media APIs](https://bookdown.org/paul/apis_for_social_scientists/), including: * Facebook Ads * Google Trends * Reddit * Open Street Map - More and more high-qaulity administrative data, e.g. [IPUMS](https://www.ipums.org/), [UK Census](https://www.nomisweb.co.uk/sources/census), [London Datastore](https://data.london.gov.uk/) - Several sources come with information that can be merged across different sources (e.g. geo-codes)