Bayesian Model Averaging of (a)symmetric IRT Models in Small Samples
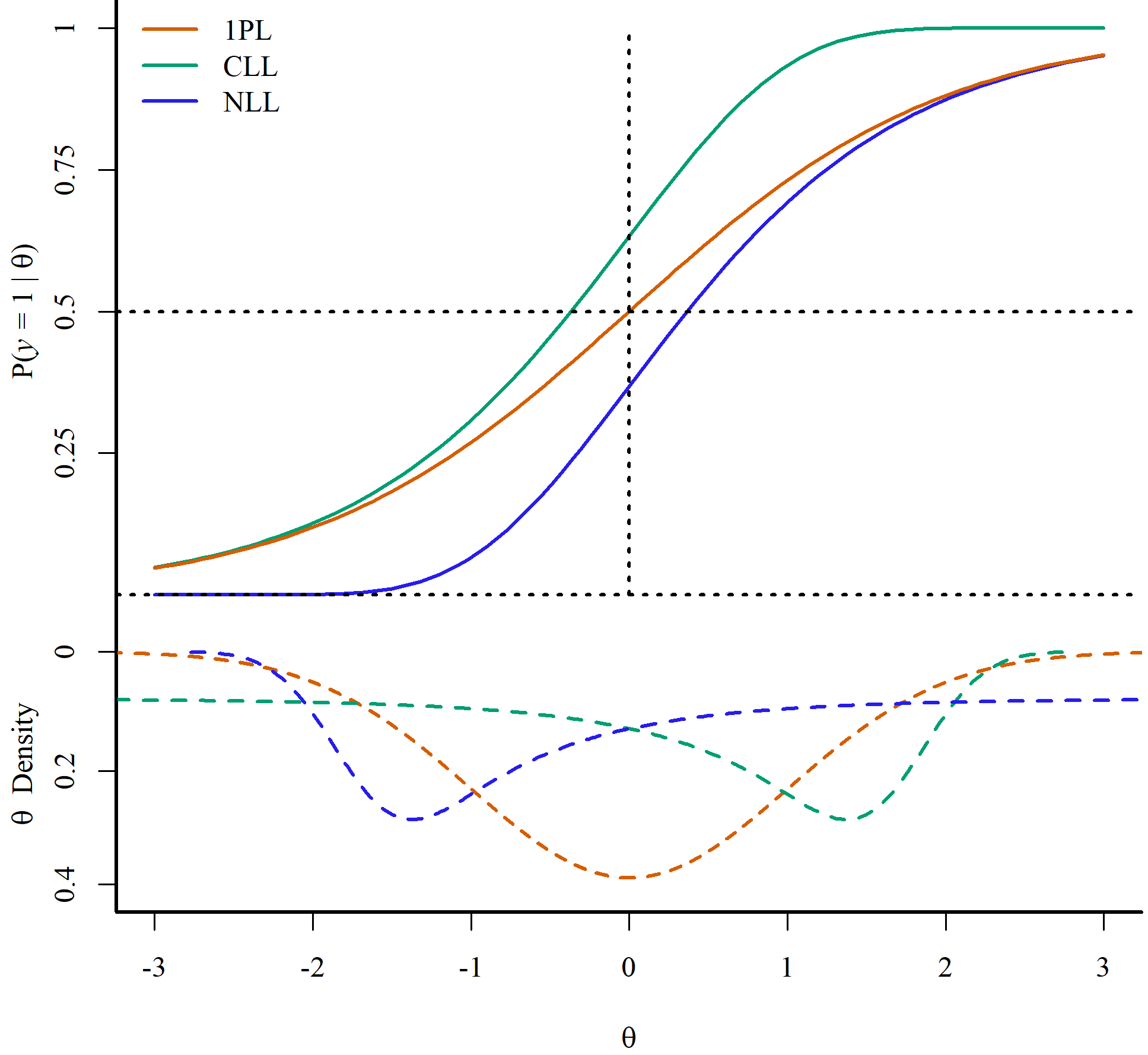
Simple Asymmetric IRT Models
Most asymmetric models include asymmetry parameters that are hard to estimate in small sample sizes (e.g., Gonçalves et al., 2023; Lee & Bolt, 2018; Verkuilen & Johnson, 2024) Two recently proposed asymmetric IRT models (Shim et al., 2023a, 2023b) may help address this issue:
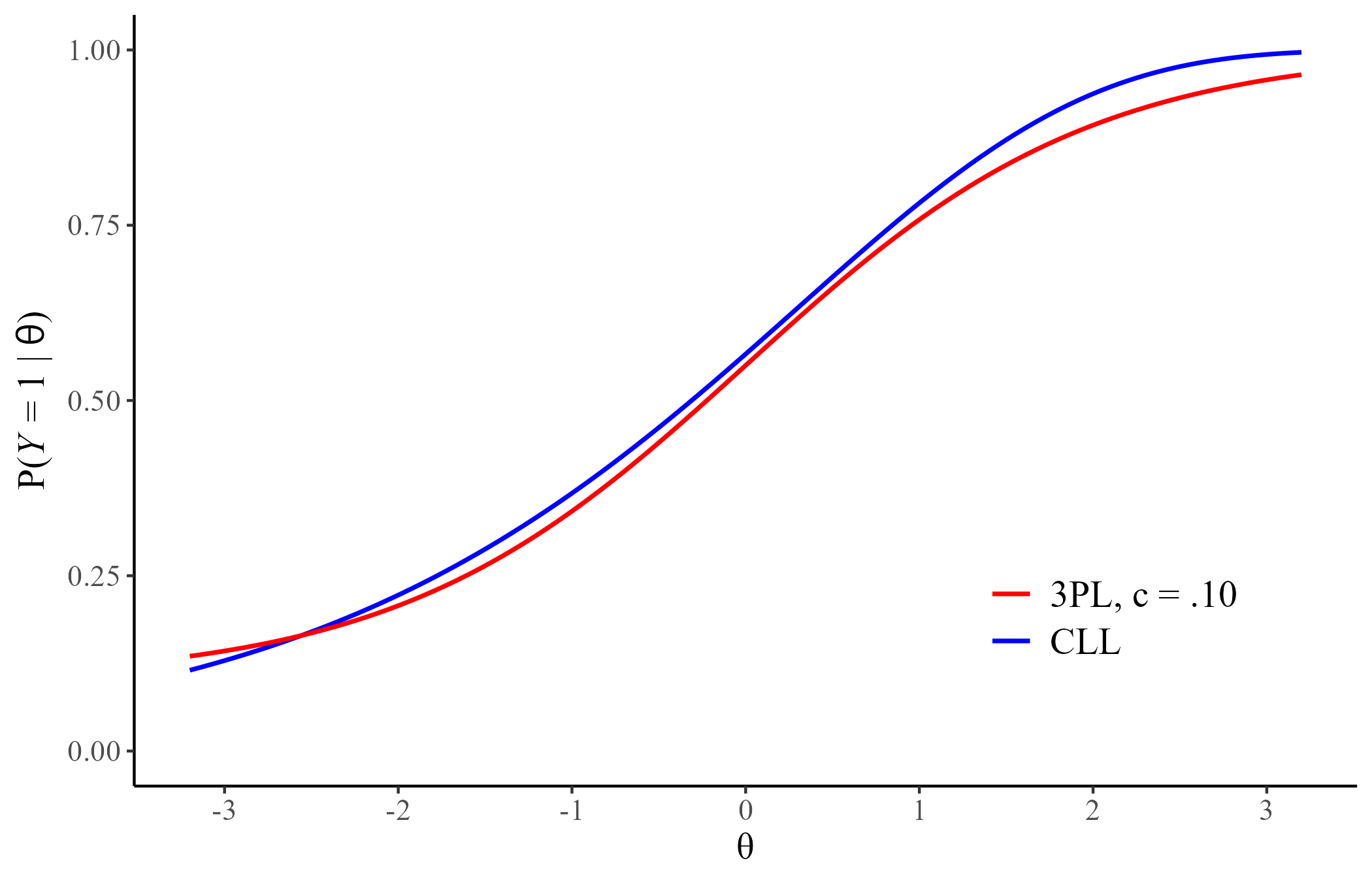
Complementary Log-Log (CLL)
\[ P(Y = 1| \theta) = 1 - \exp[-\exp[a(\theta - b)]]\]
Negative Log-Log (NLL)
\[ P(Y = 1| \theta) = \exp[-\exp[-a(\theta - b)]]\] 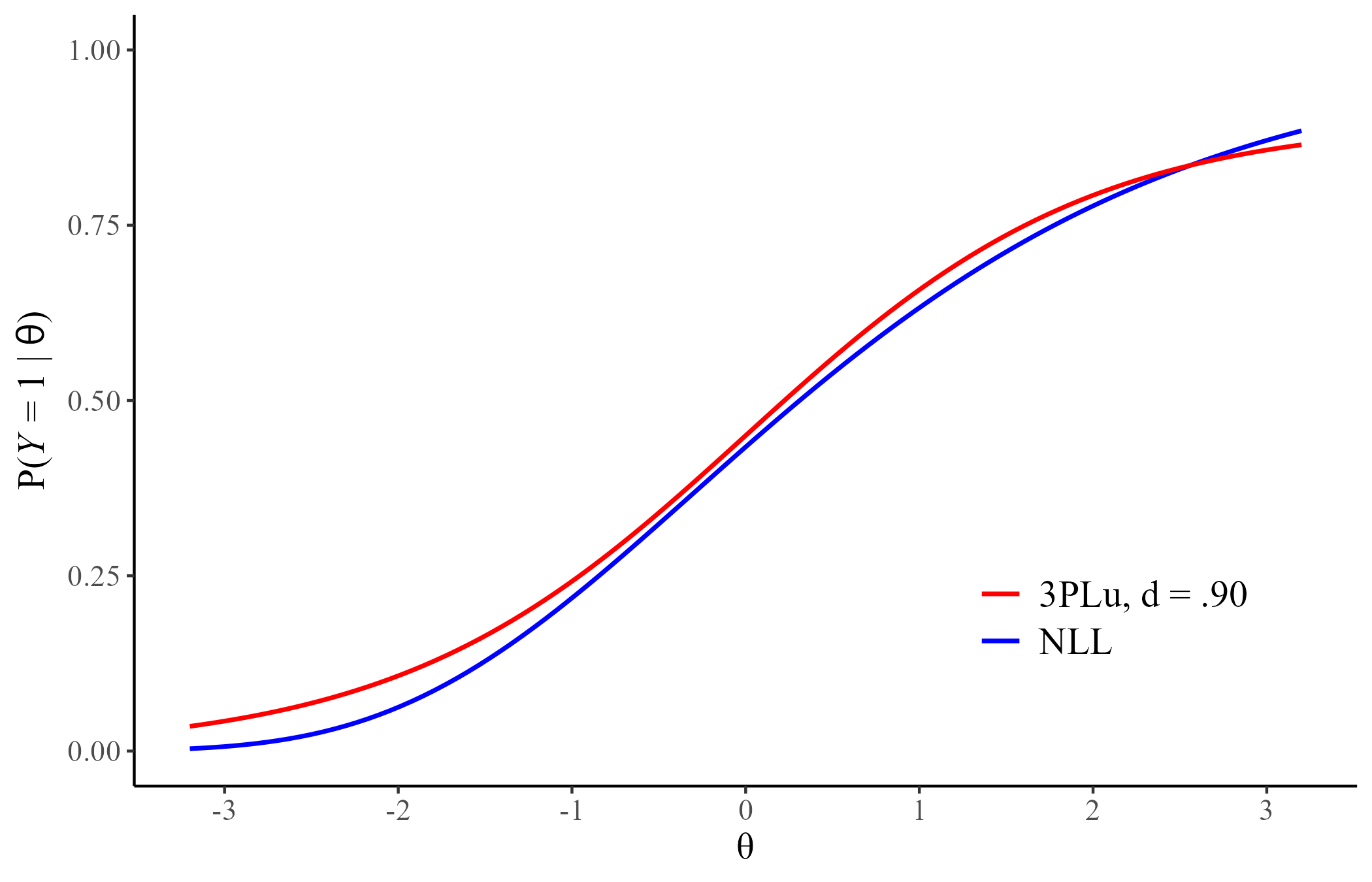
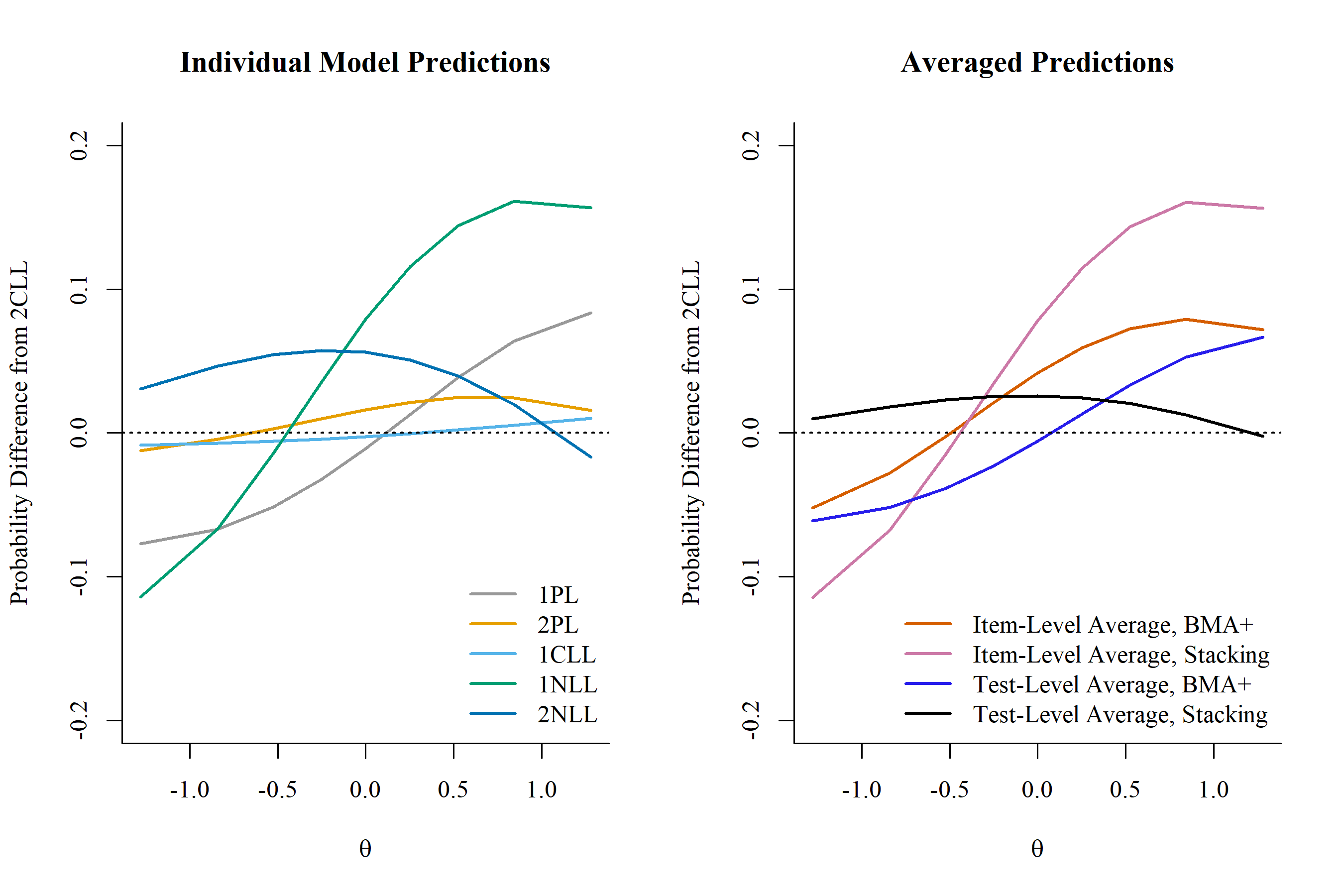
Averaging Predicted Probability of Keyed Responses
estimate \(P(Y = 1|\theta)\) by averaging along a common \(\theta\) continuum. Assumes a common \(\theta\) scale across models.
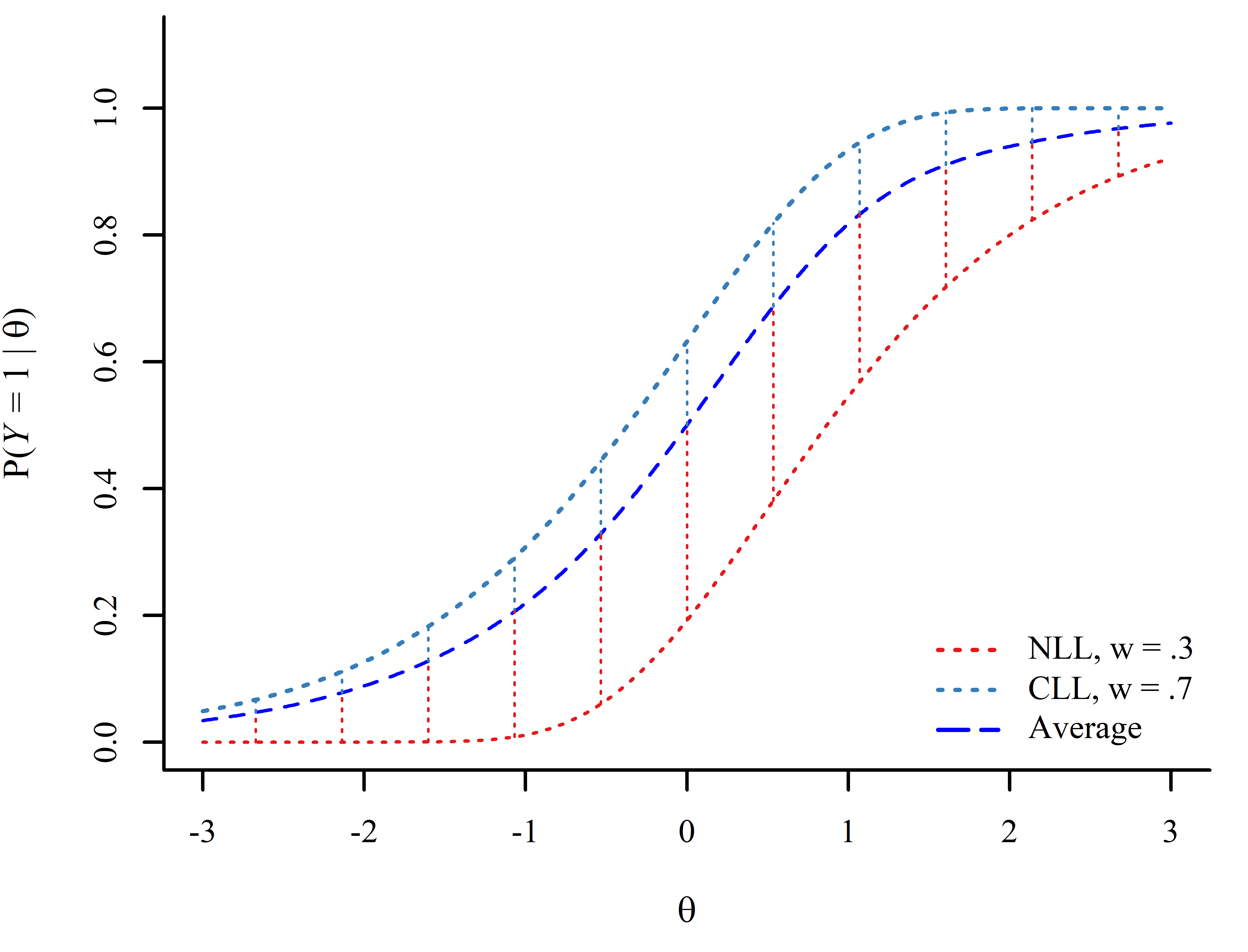
estimate \(P(Y = 1|\theta)\) by averaging along a common empirical \(\theta\) continuum. Can accommodate different \(\theta\) scales.
Empirical Example
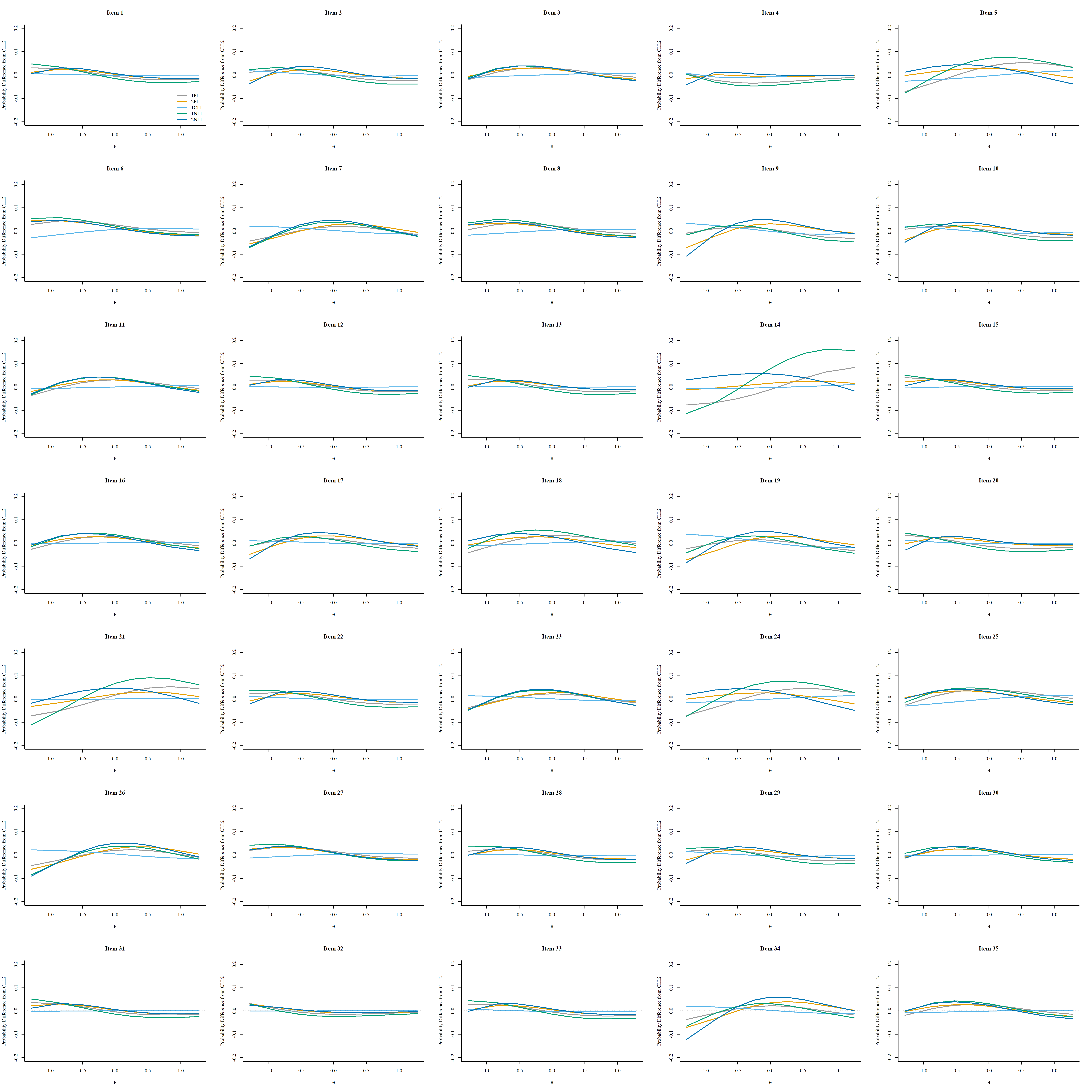
We fit the 1PL, 2PL, 1CLL, 2CLL, 1NLL, 2NLL with the brms package (Bürkner, 2017) to the Bond’s Logical Operations Test (BLOT; Bond & Fox, 2007) dataset from the PsychTools package (Revelle, 2024), which includes 150 participants and 35 items.
Simulation
Most data generating condition purposely introduced some type of model misspecification. There were 4 data generating conditions:
2PL: \(\frac{\exp[a(\theta - b)]}{1 + \exp[a(\theta - b)]}\)
2MPL: \(\frac{1}{1 +\exp[-(a_{1}\theta_{1} + a_{2}\theta_{2} + d)]}\)
GLLla and GLLua (Zhang et al., 2022)
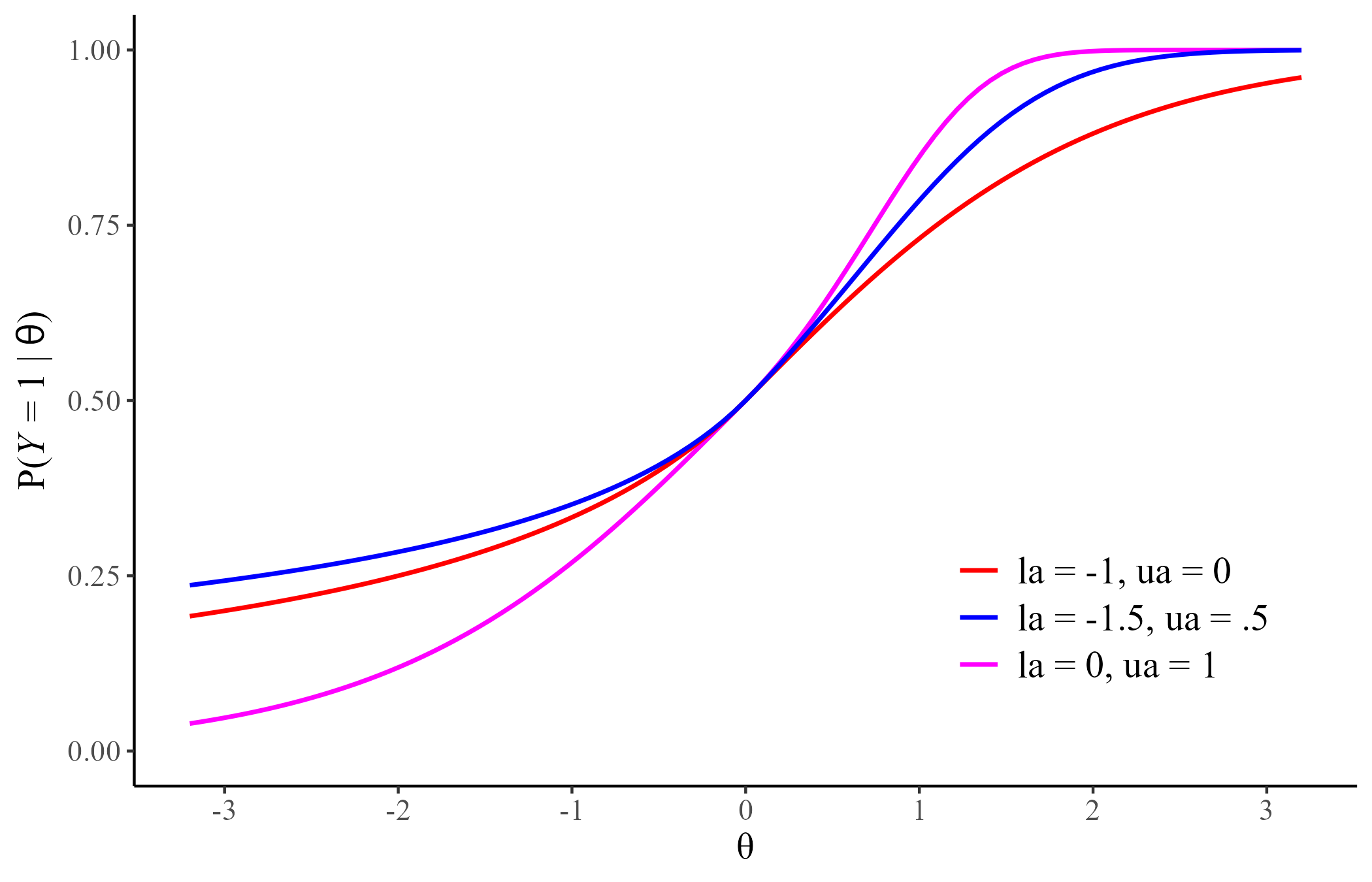
- 4 data-generating models (2PL, 2MPL, GLLla, GLLua)
- 2 sample sizes (N = 100, 250)
- 2 test lengths (I = 10, 20)
- 100 replications (R)
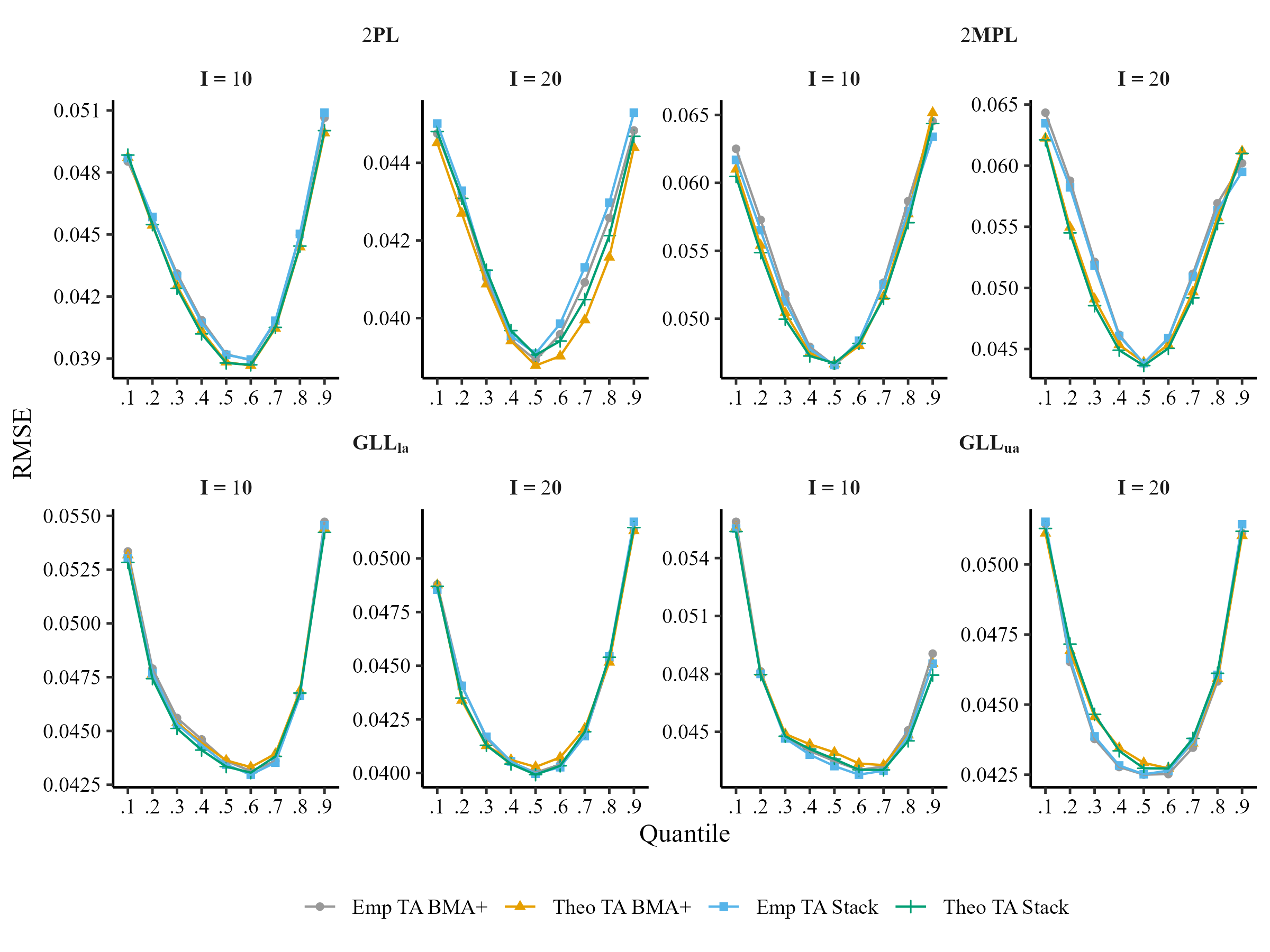
- 9 quantiles (q = .10,…,.90)
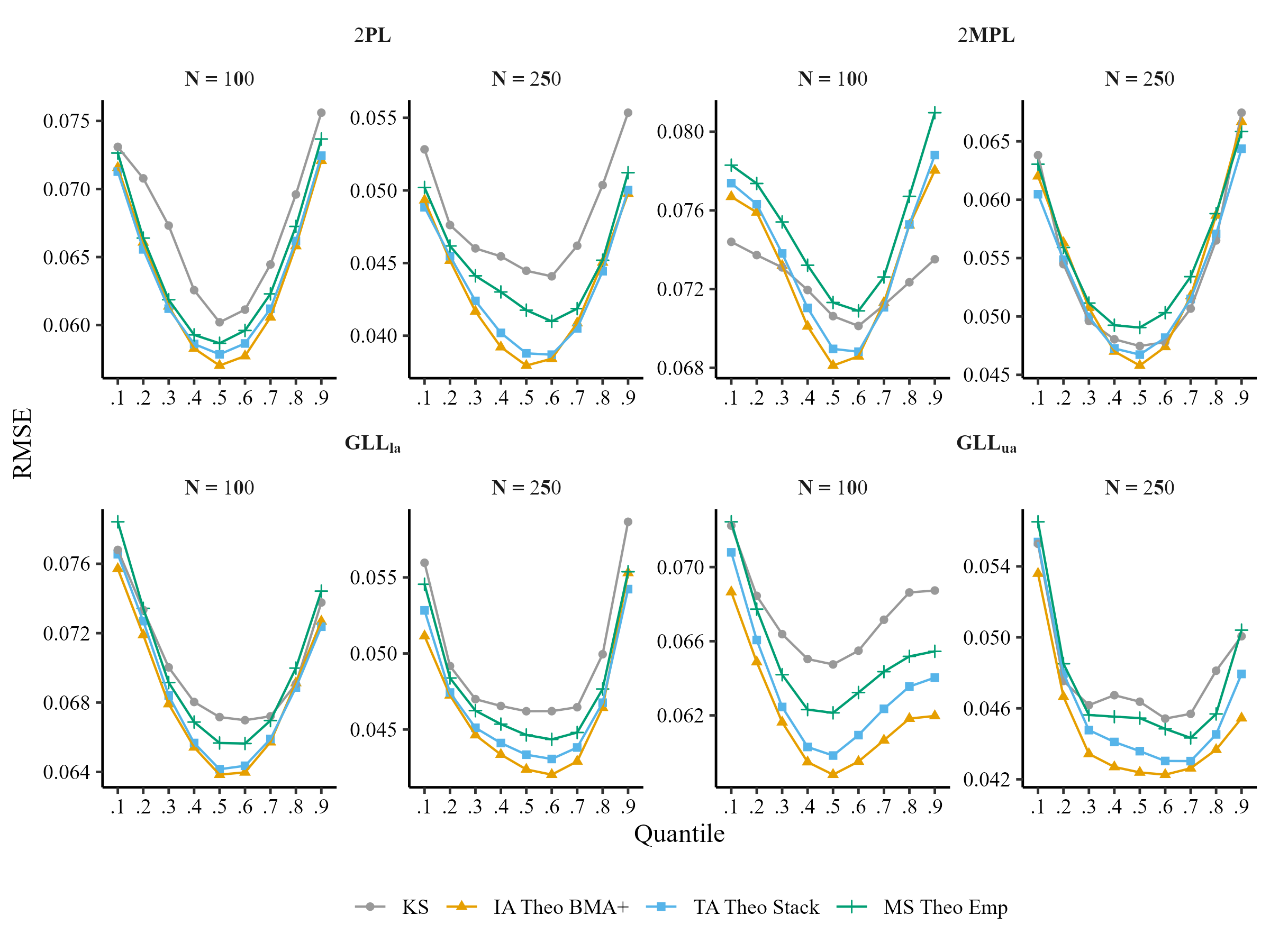
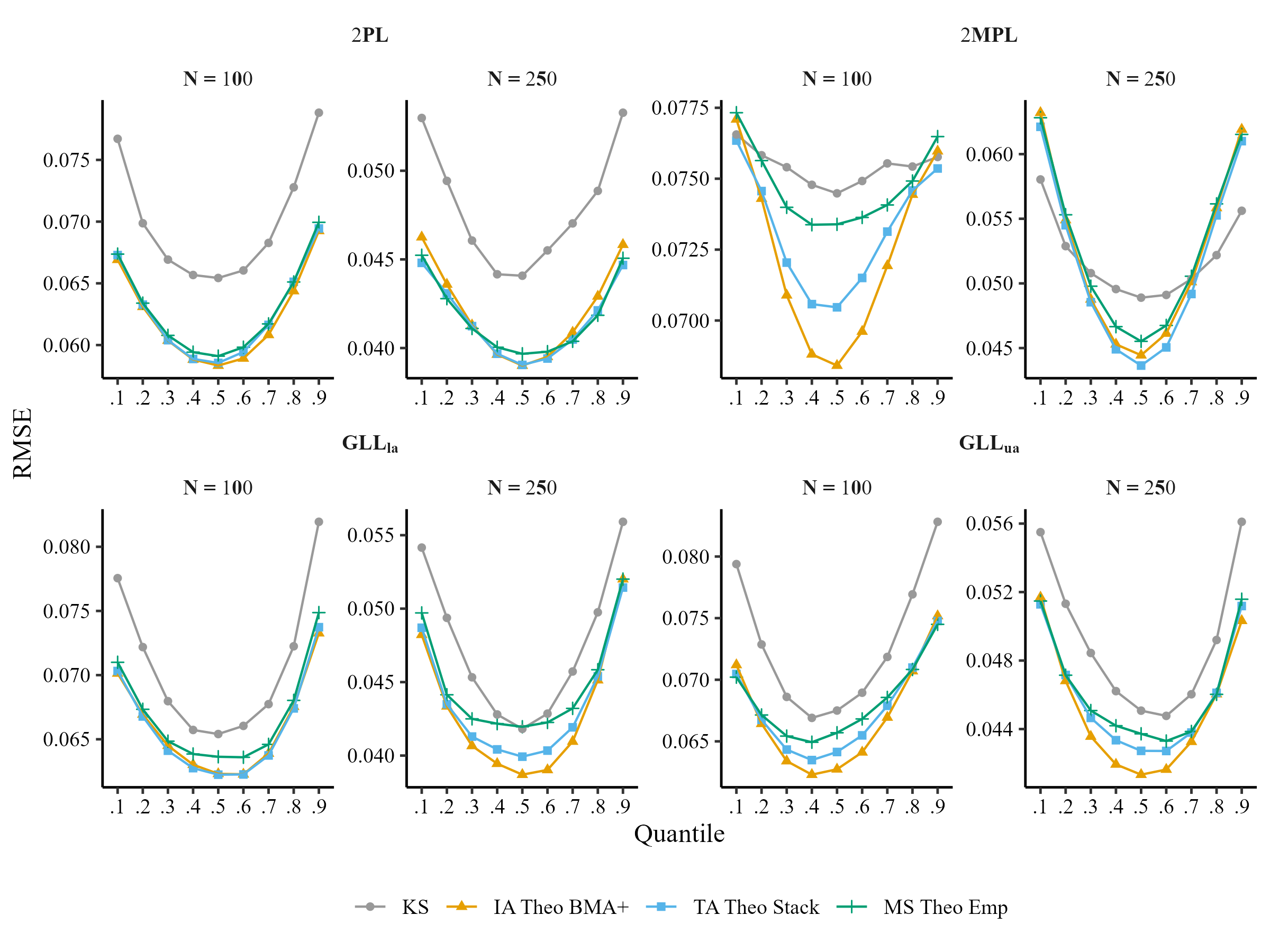
We will compare the performance of model selection (MS), test averaging (TA), item averaging (IA), and kernel smoothing IRT (KS):
\[RMSE_{q} = \sqrt{\frac{1}{100}\sum_{r=1}^{100}\frac{1}{I}\sum_{i = 1}^{I}[P_r(y_{in} = 1|\theta_{q}) - \hat{P}_r(y_{in} = 1|\tilde{\theta}_{q})]^{2}}\]
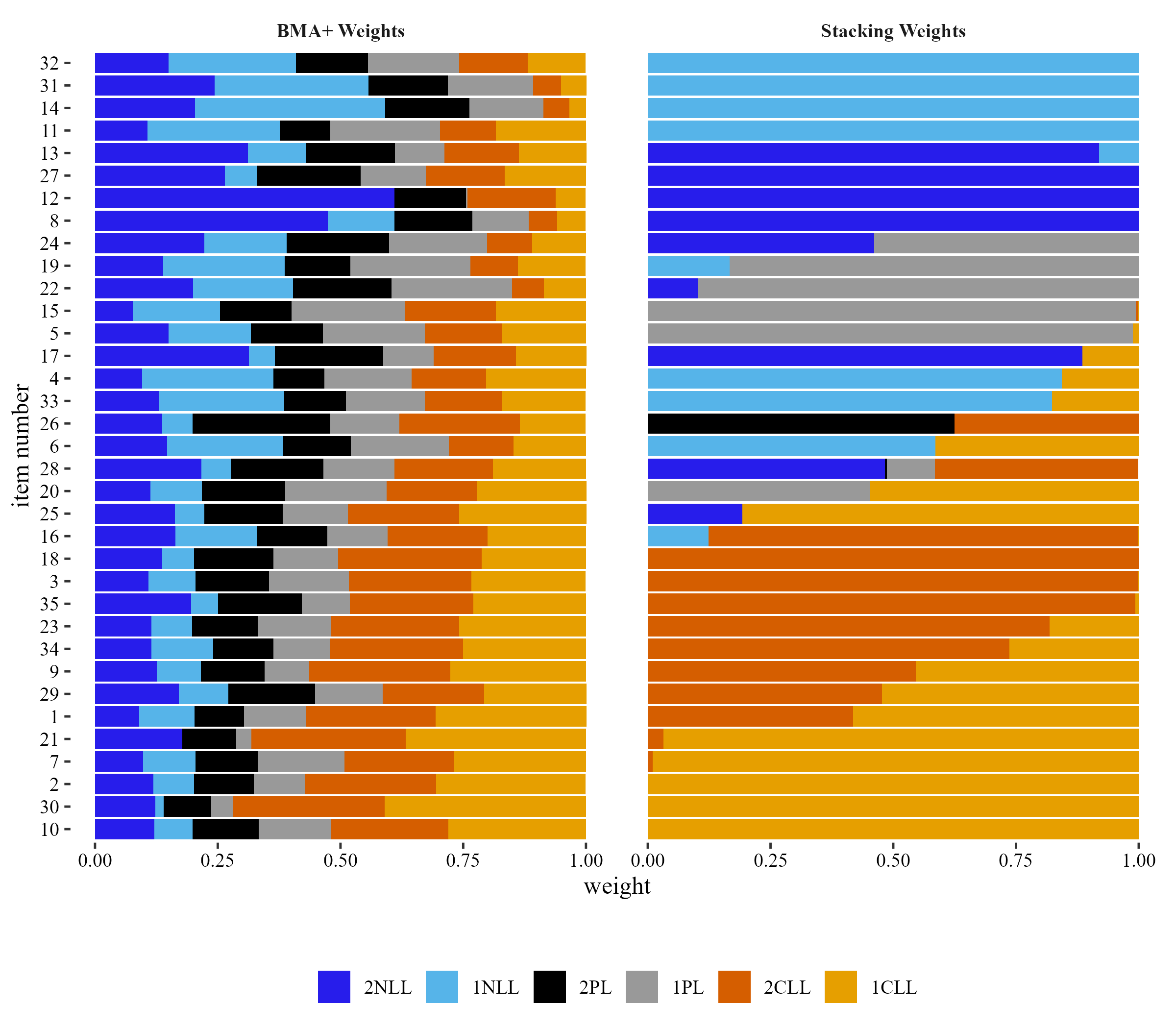
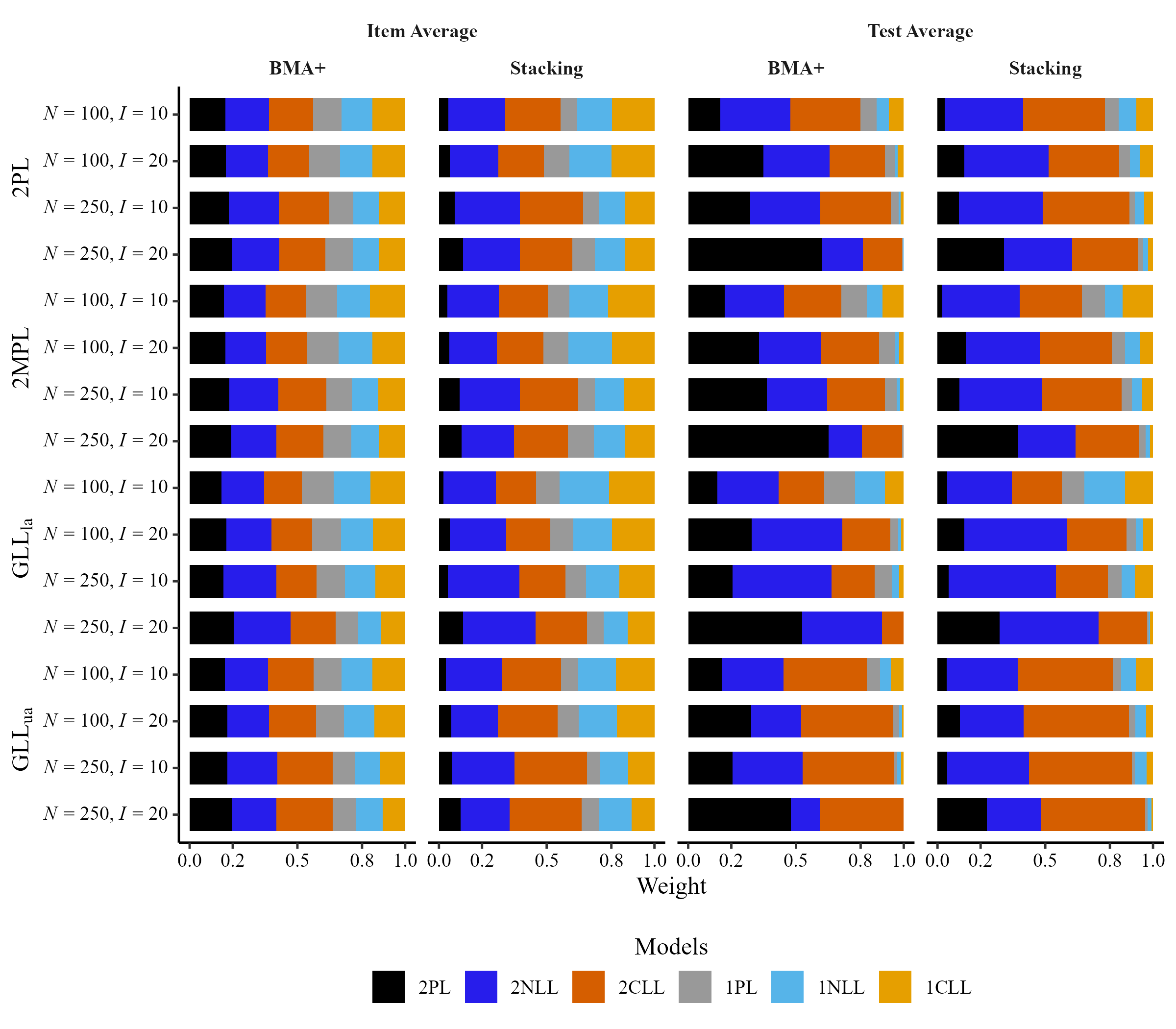
Distribution of Test and Item Weights
Performance of BMA+ Over Stacking Weights
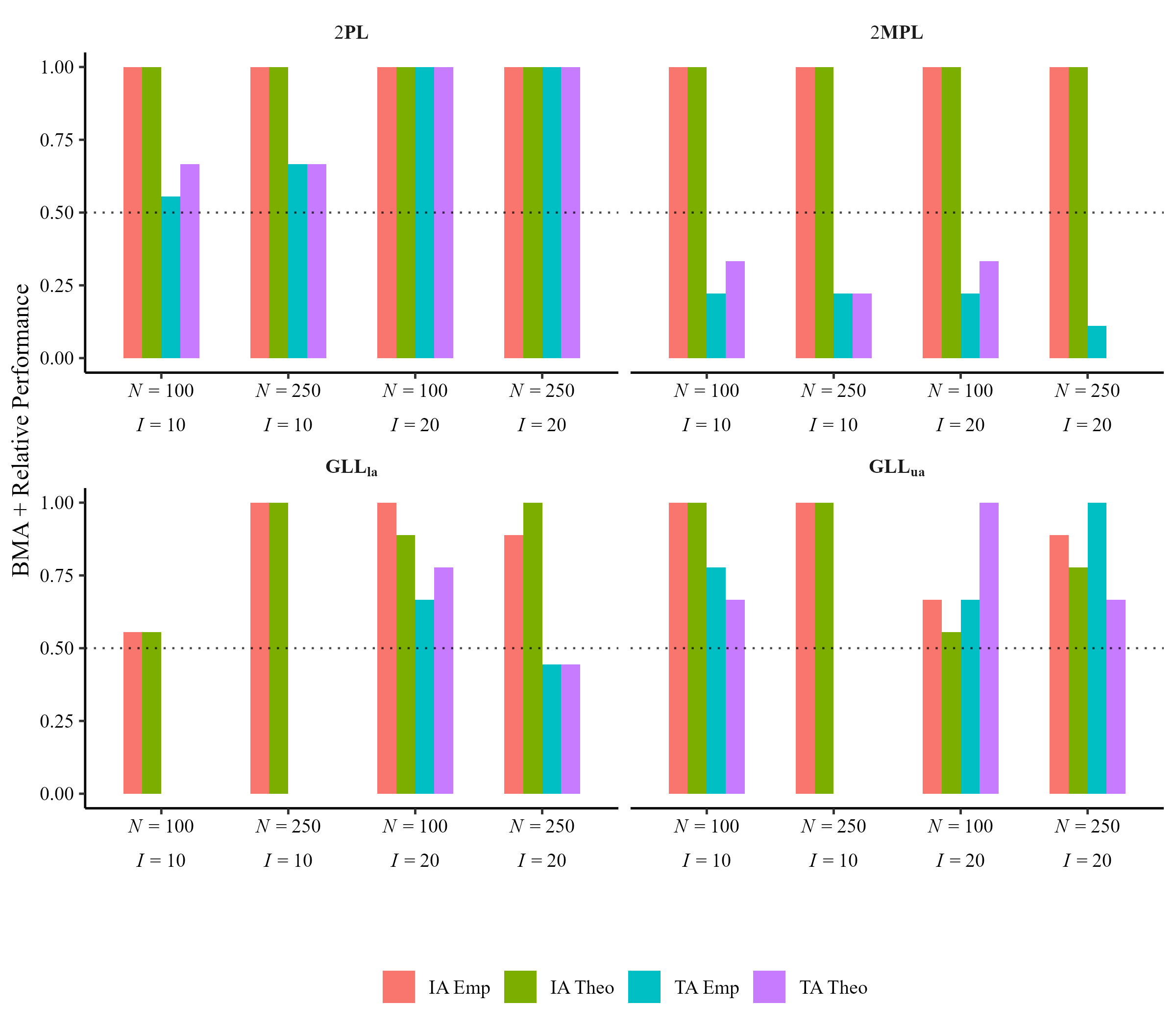
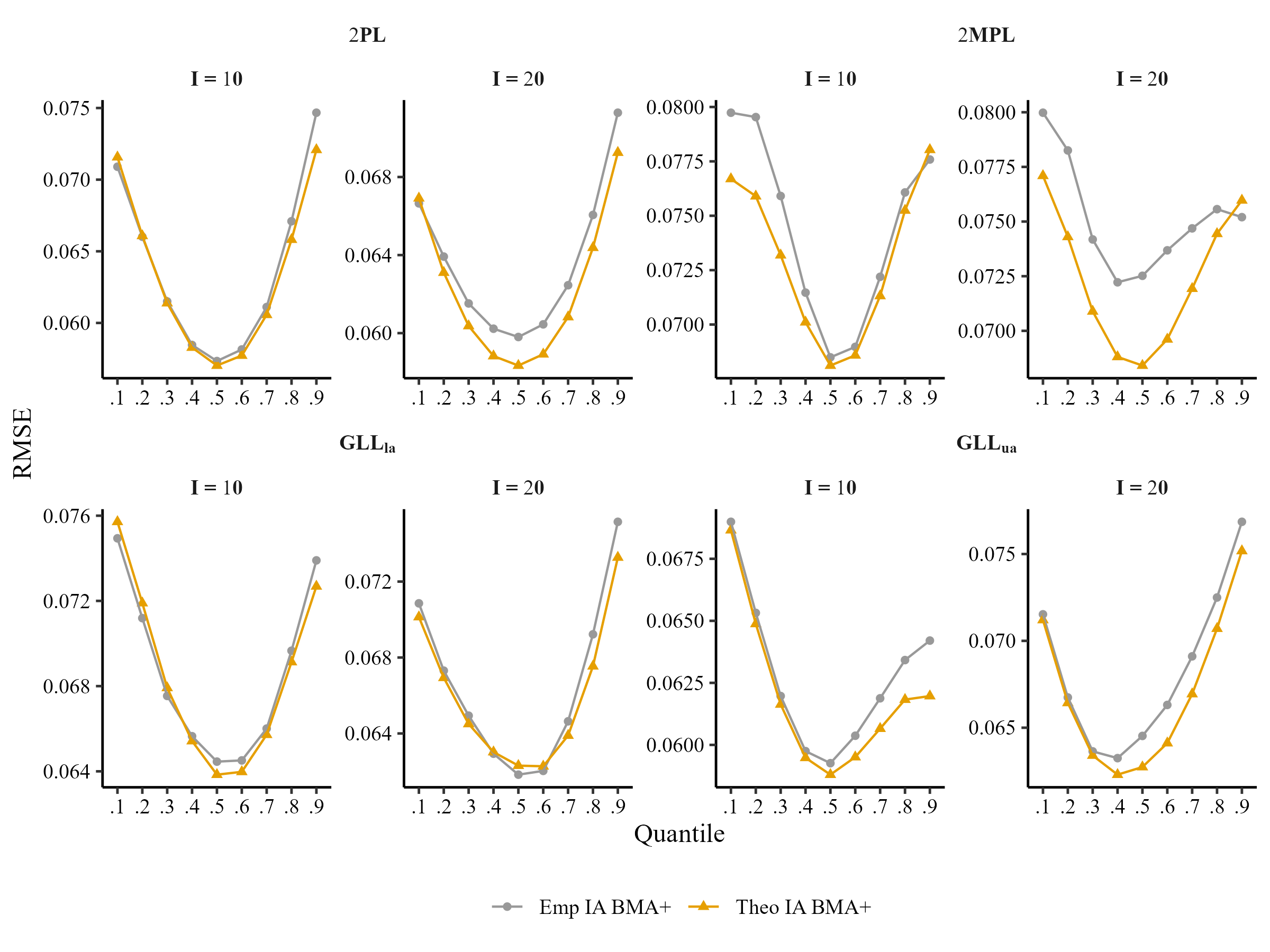
Comparison of Item Averaging at Theoretical and Empirical Quantiles (N = 100)
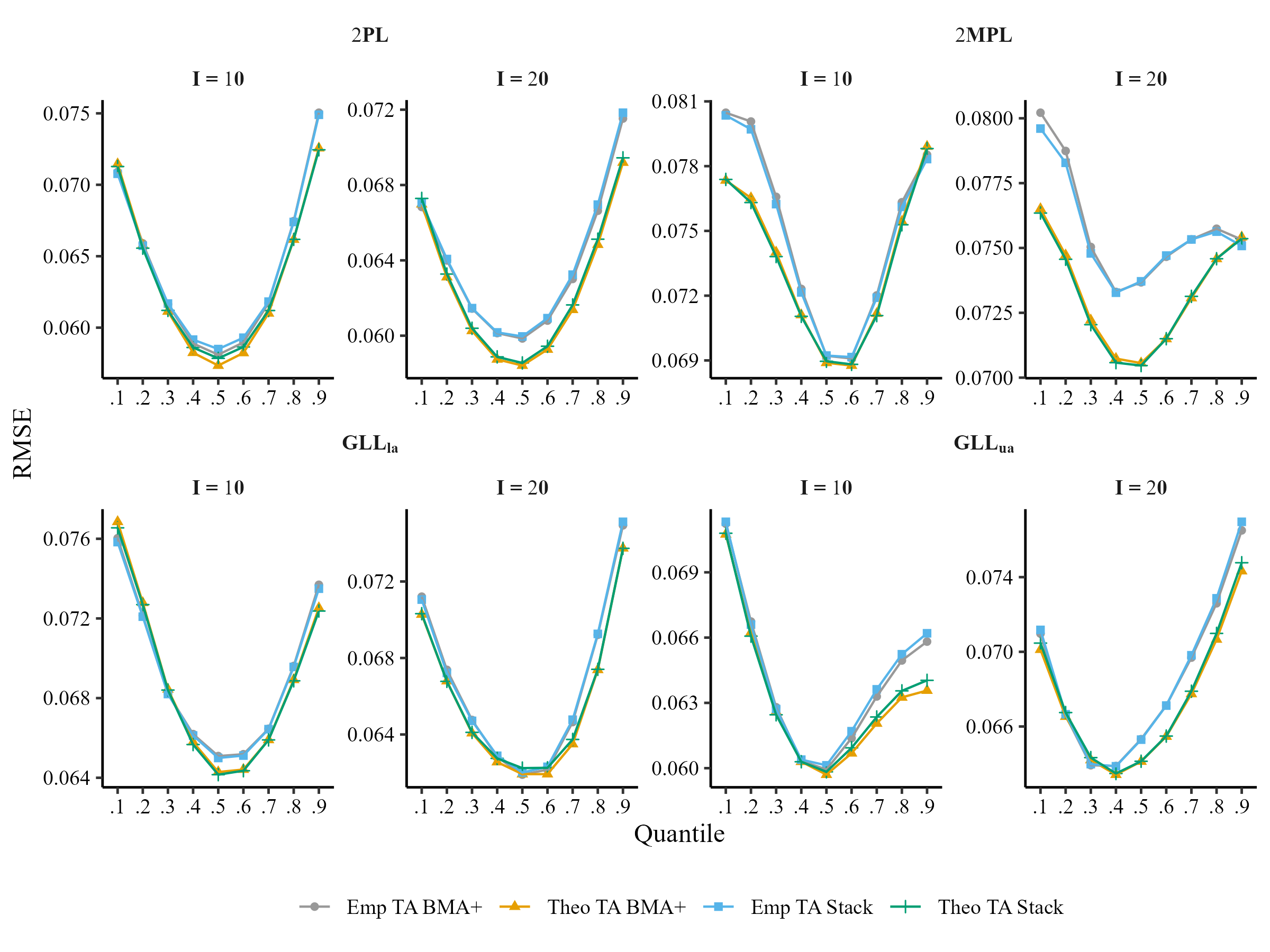
Comparison of Test Averaging at Theoretical and Empirical Quantiles (N = 100)
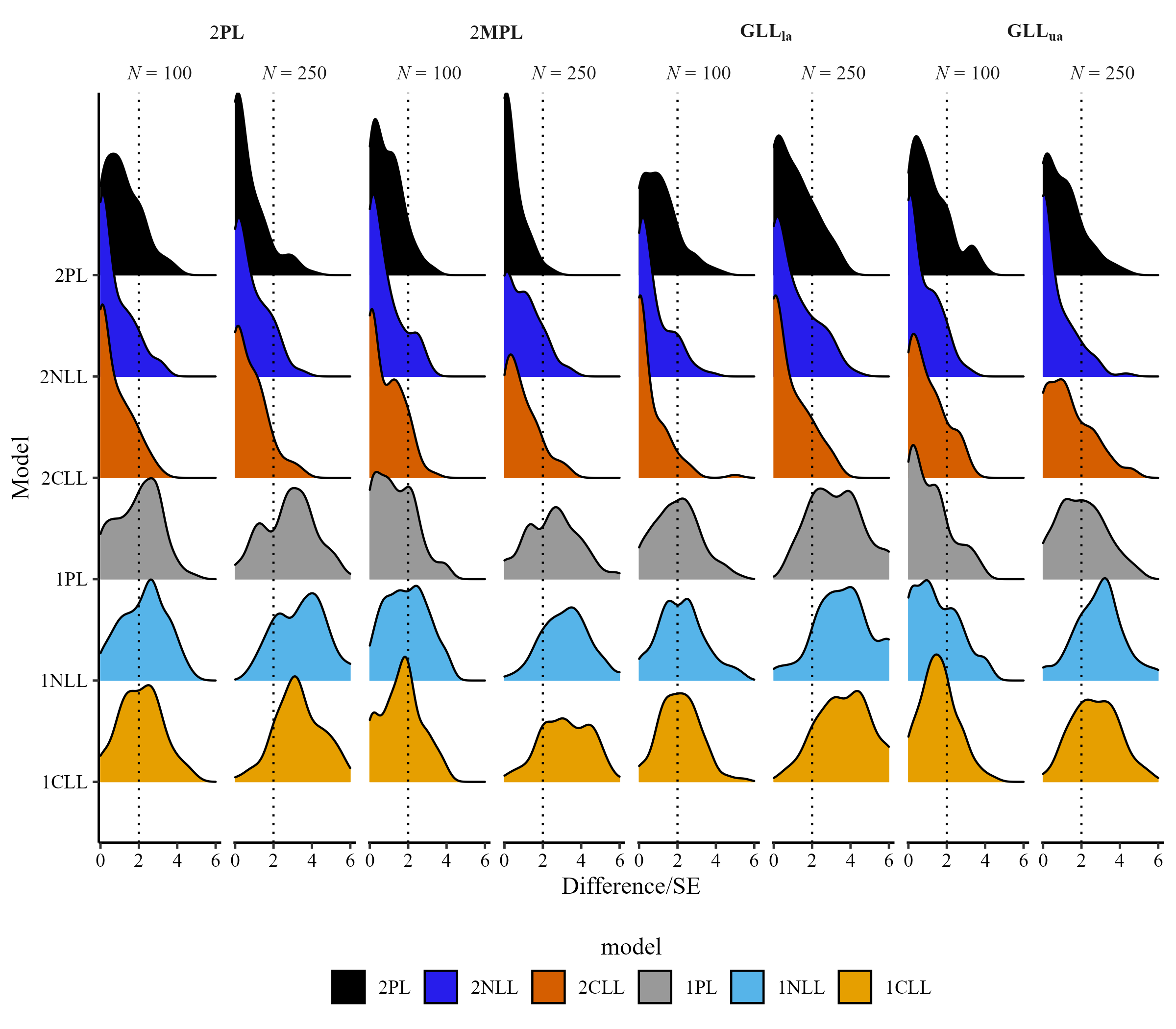
Comparison of Averaging Methods, Model selection (MS), Kernel Smoothing (KS) for I = 10
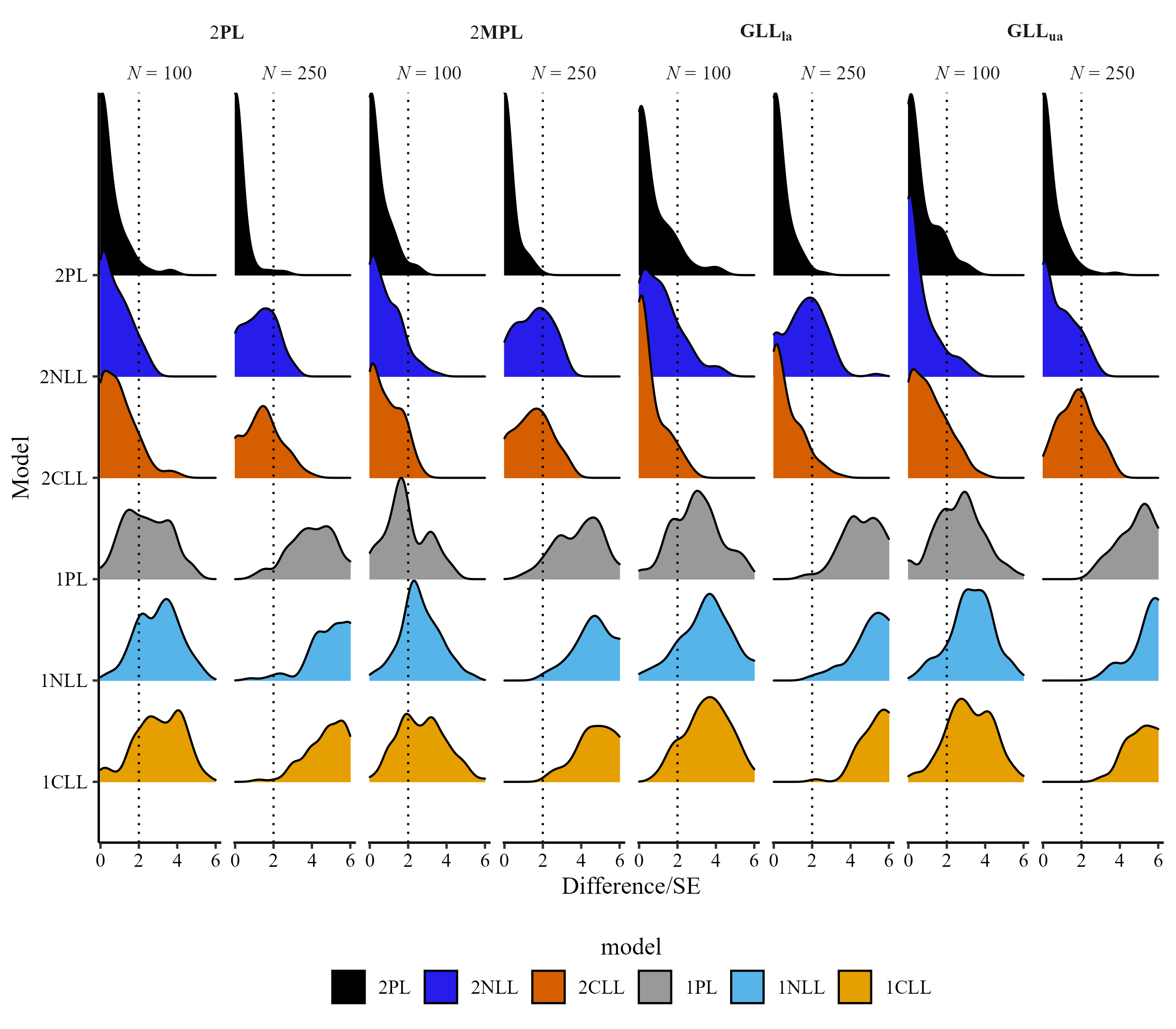
Comparison of Averaging Methods, Model selection (MS), Kernel Smoothing (KS) for I = 20
Acknowledgement & Contacts
- My advisor: Leah Feuerstahler (leah@fordham.edu)
- Fordham’s High Performance Computing team, especially Andrew Angelopoulos (aangelopoulos@fordham.edu)

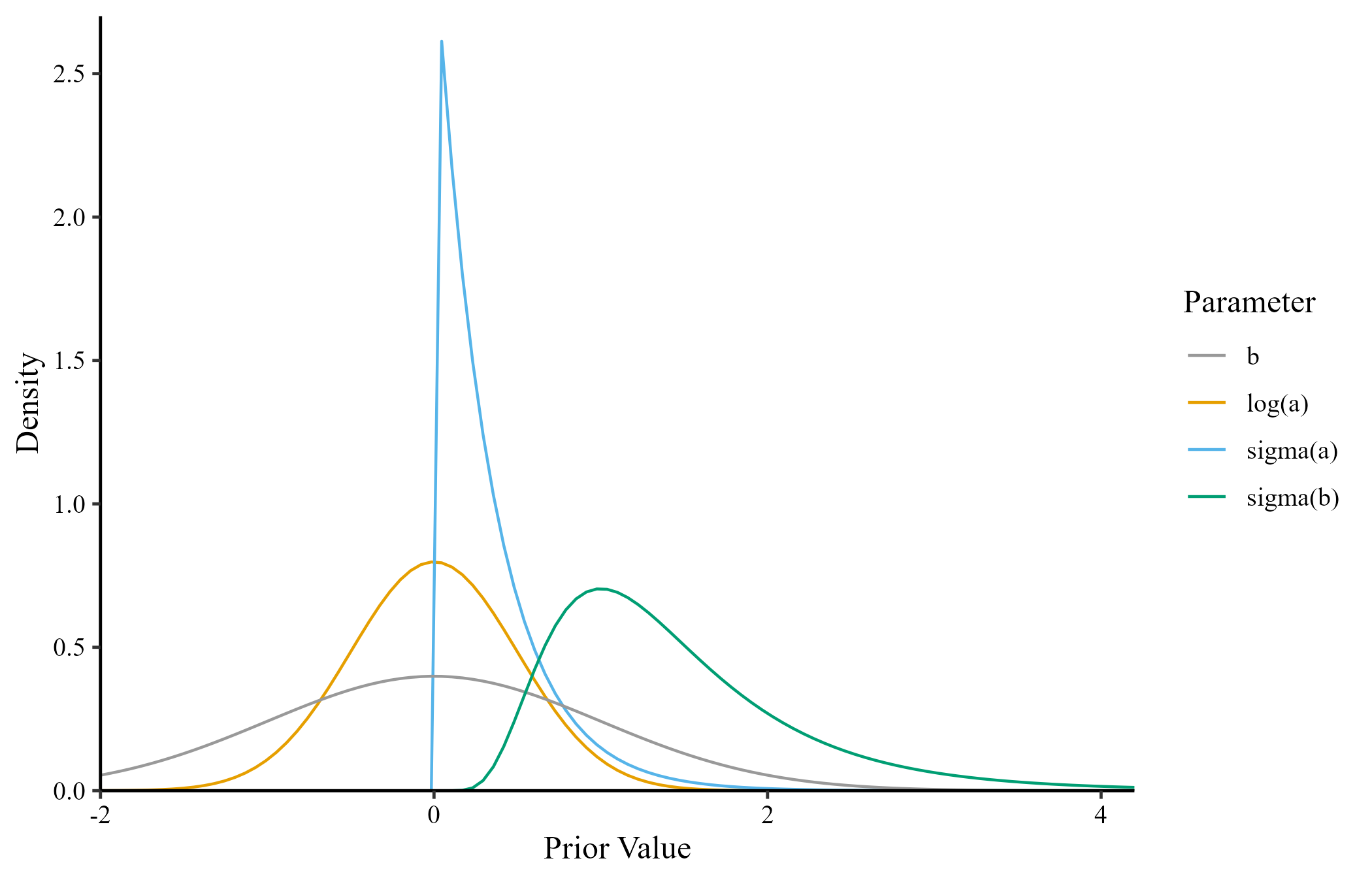
Model Priors
Model estimation used the partial pooling approach in the estimation of model parameters (i.e., random intercepts/slopes)
\(log(\bar{a}) = N(0, .5)\)
\(\sigma_{log(\bar{a})} = \mathrm{Exponential}(3)\)
\(\bar{b} = N(0, 1)\)
\(\sigma_{\bar{b}} = \mathrm{Lognormal}(.25, .5)\)
\(\bar{\theta} = 0\)
\(\sigma_\bar{\theta} = 1\)
All BLOT items Predictions
Parameter Generating Distributions for Simulation
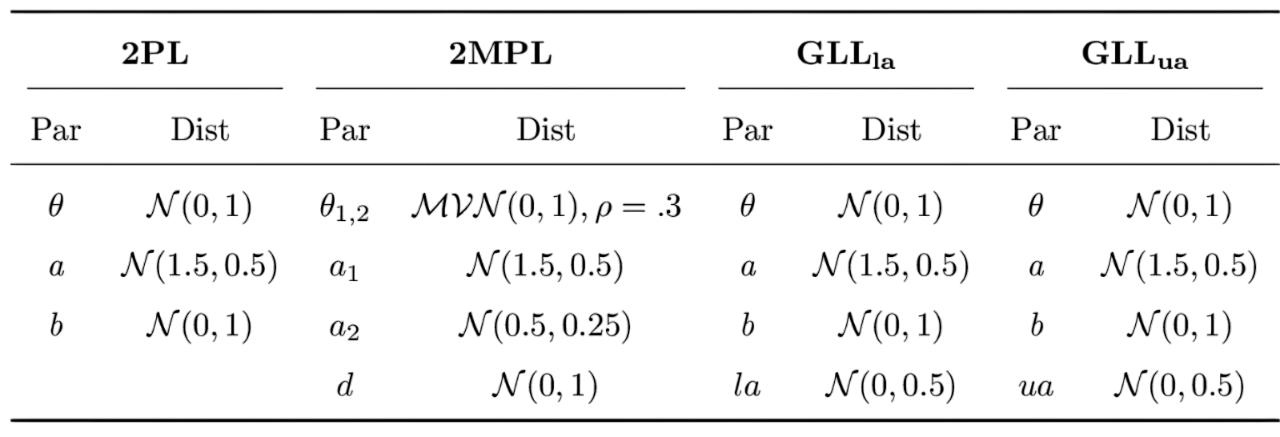
LOO diffrence/SE for I = 10
LOO diffrence/SE for I = 20
Comparison of Item Averaging at Theoretical and Empirical Quantiles (N = 250)
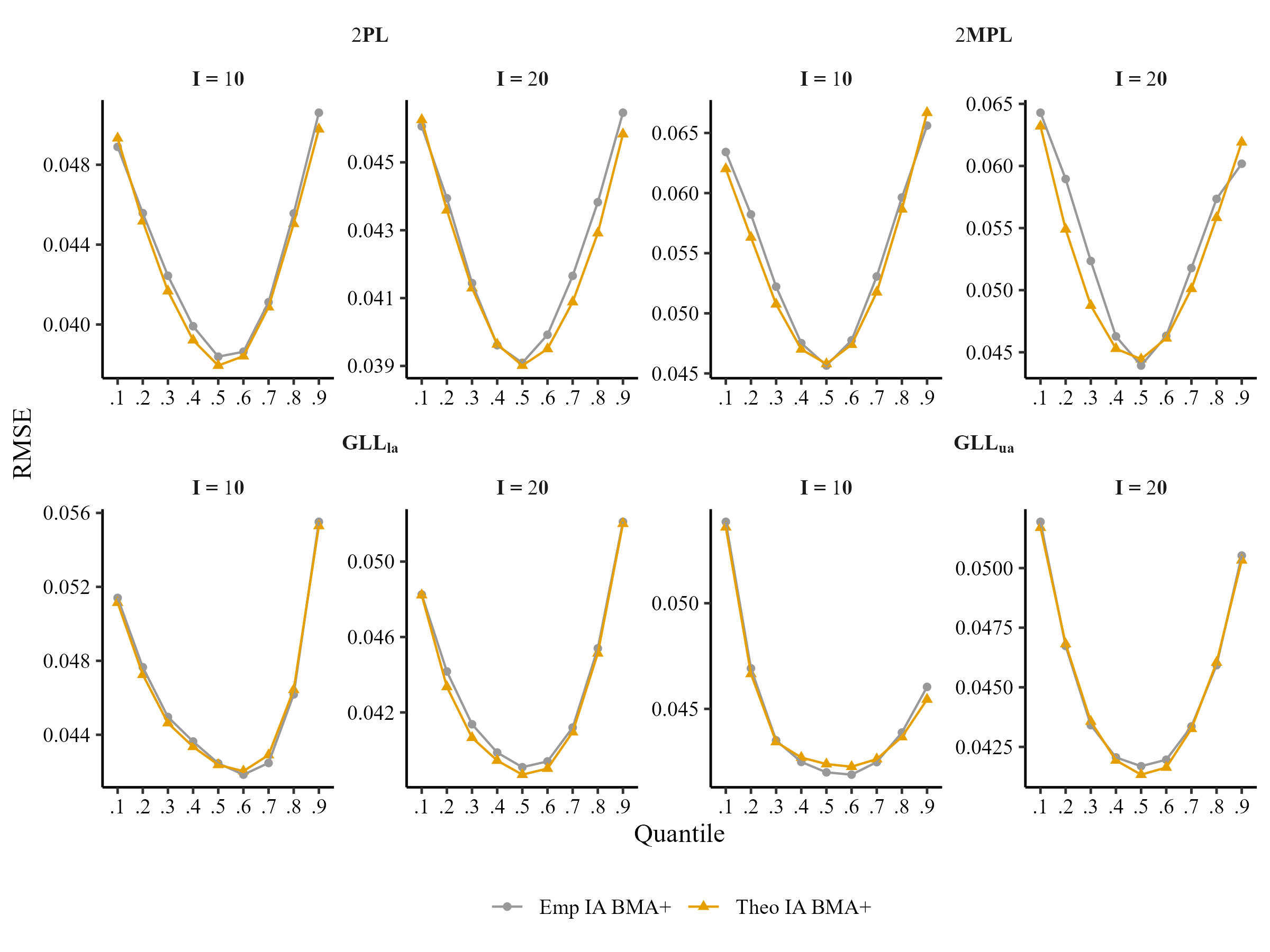
Comparison of Test Averaging at Theoretical and Empirical Quantiles (N = 250)