Measuring Forecasting Proficiency: An Item Response Theory Approach
Quantile Forecasts
The Forecasting Proficiency Test (FPT; Himmelstein et al., 2024) is a test developed to measure forecasting proficiency. The FPT uses quantile forecast items:
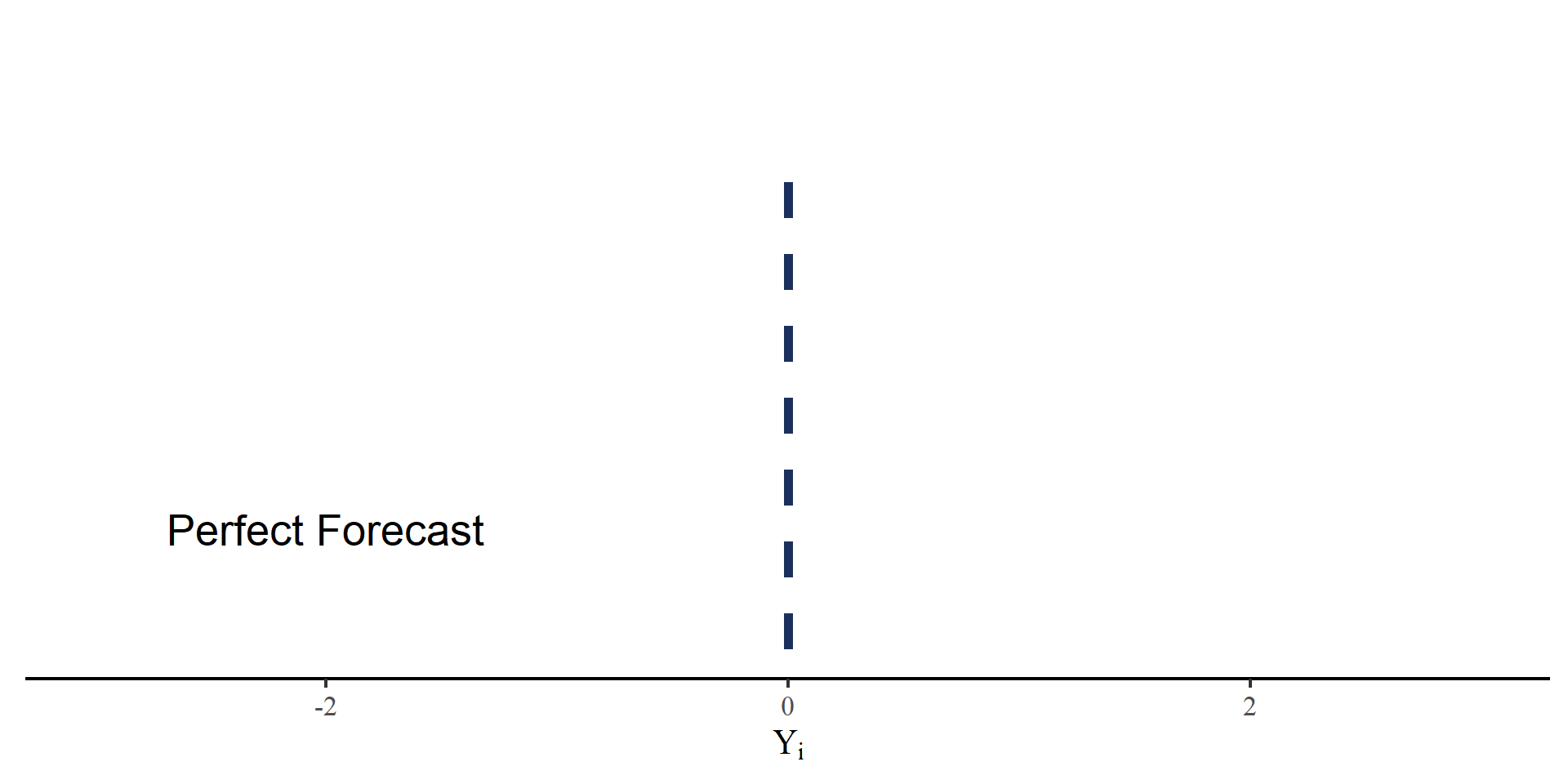
Quantile forecast items are designed to elicit an individual’s subjective cumulative distribution function (CDF) regarding a future continuous outcome
Each individual provides 5 monotonically increasing responses
Responses are unbounded
Forecast accuracy is the measure of interest
GOAL: in IRT fashion, modeling forecast accuracy by positing a statistical model that accounts for both person and item features
Defining Forecast Accuracy
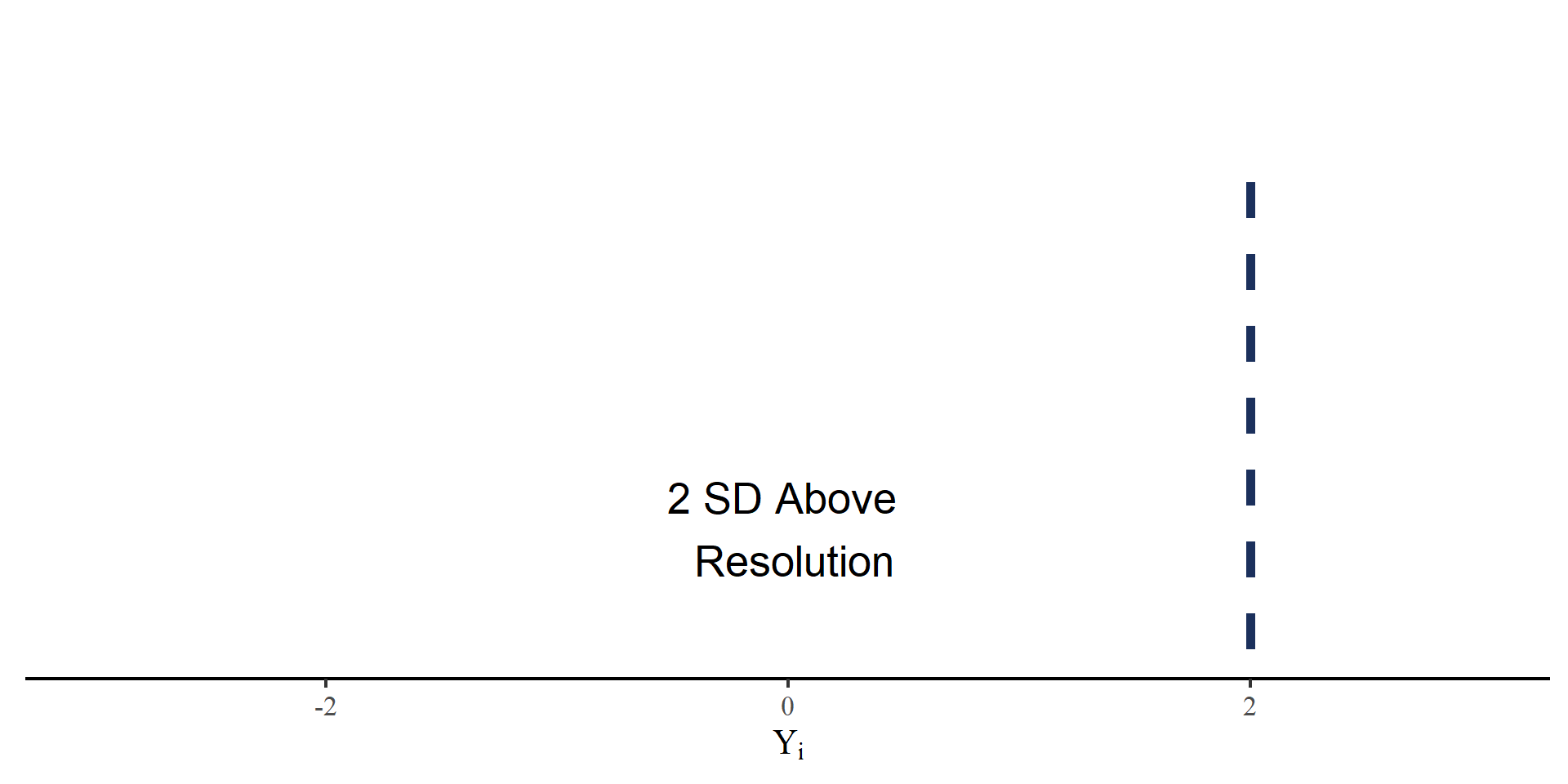
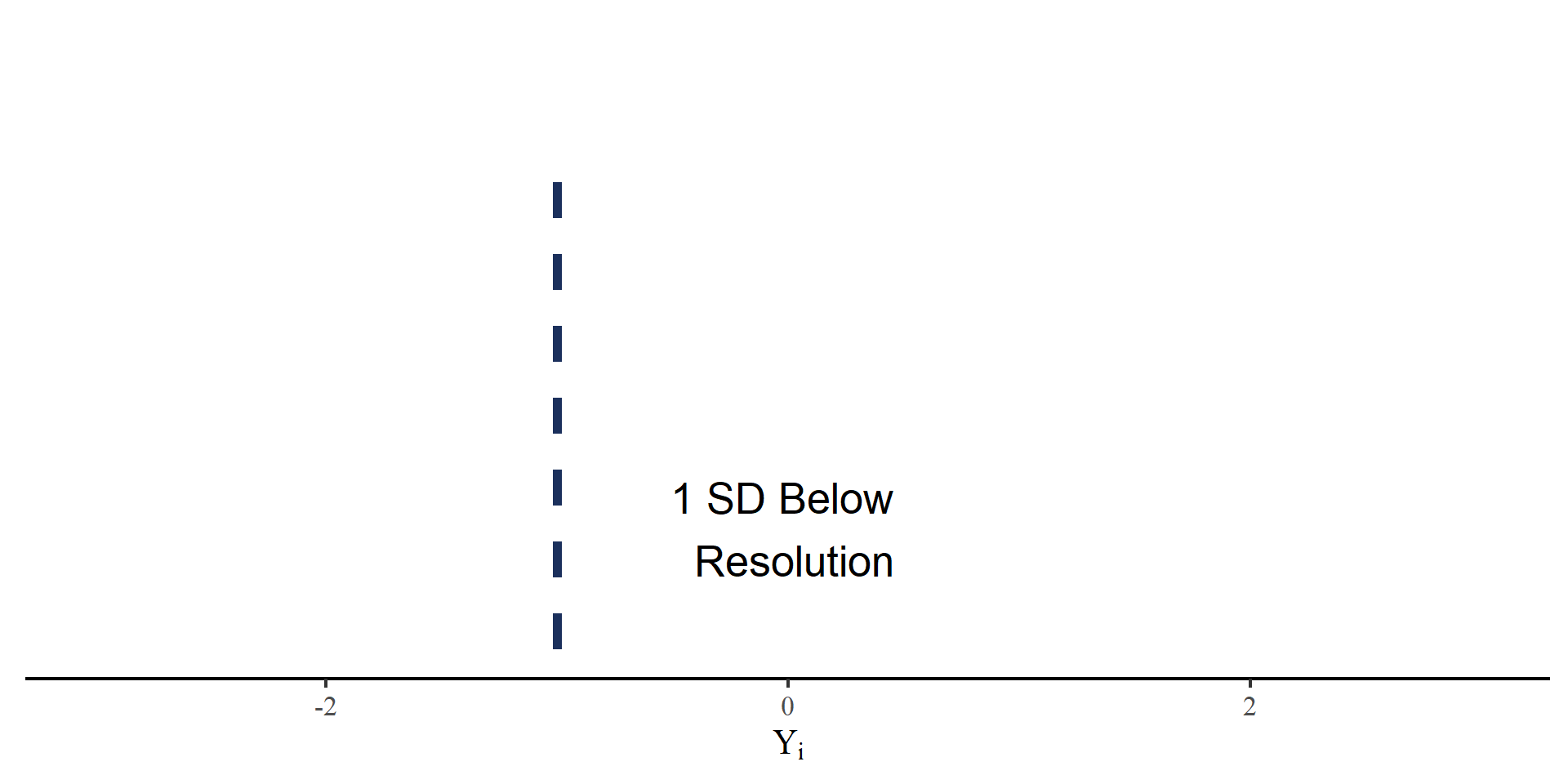
Responses to FPT quantile forecast items are on very different scale (e.g. dollars/gallon, thousands of dollars, percentages,…). We define the outcome measure, historically scaled accuracy, as
\[ Y_i = \frac{\hat{Y}_i - Y_{\mathrm{res},i}}{SD_{Y_{\mathrm{hist},i}}} \]
- \(\hat{Y}_i\): Reported forecast for item \(i\) at any quantile.
- \(Y_{\mathrm{res},i}\): The resolution for item \(i\).
- \(SD_{Y_{\mathrm{hist},i}}\): The \(SD\) of the historical time series of item \(i\).
\(Y_i\): SD units away from the resolution.
Data Collection
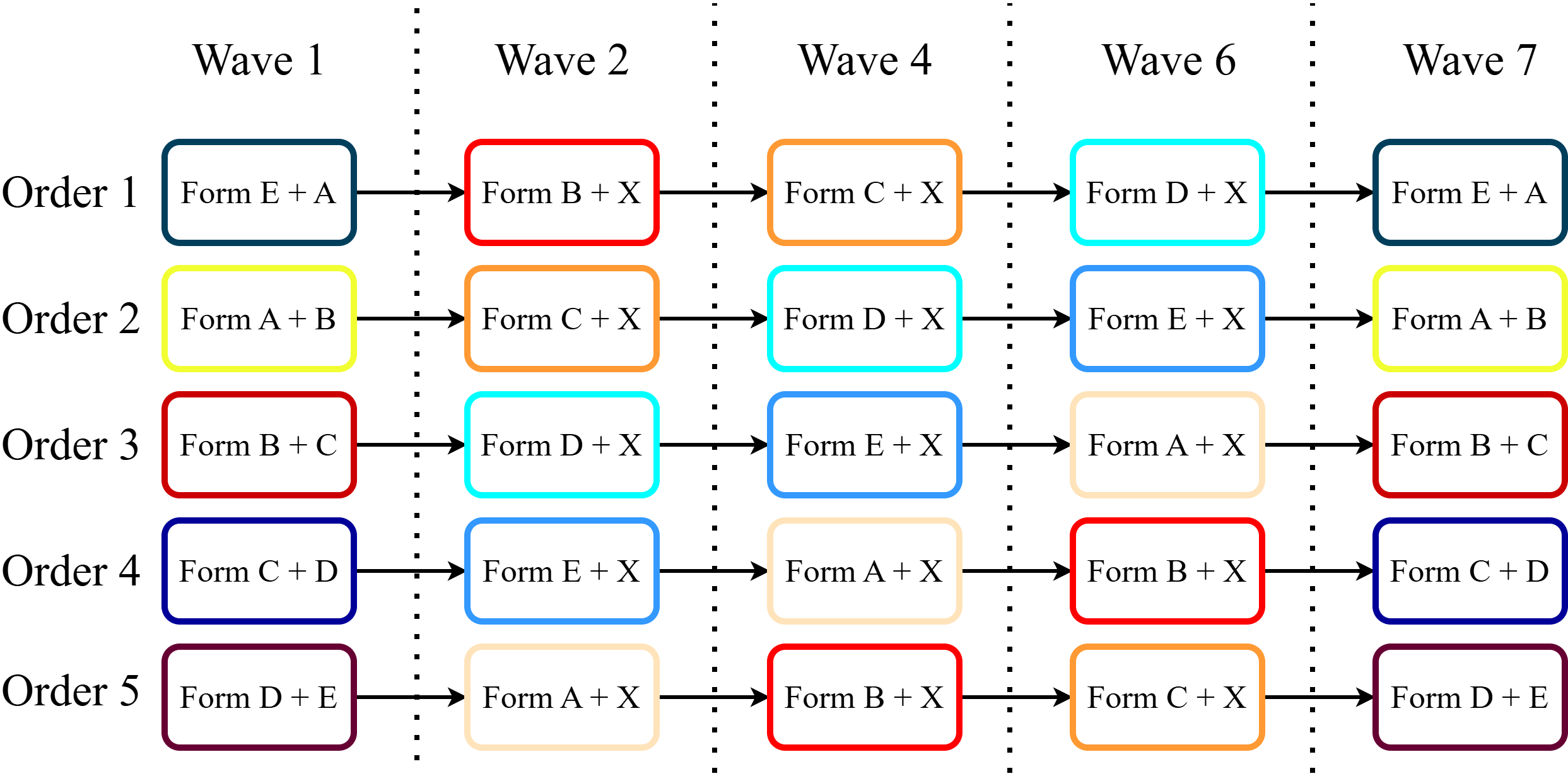
Item forecasts were collected across 5 waves of a 7 Wave study.
- 32 items divided across 6 forms (A, B, C, D, E, X) and 1194 participants
- Diverse item domains: Financial, political, technology, energy…
- 1 week interval between waves, and 1 month from resolution at wave 7
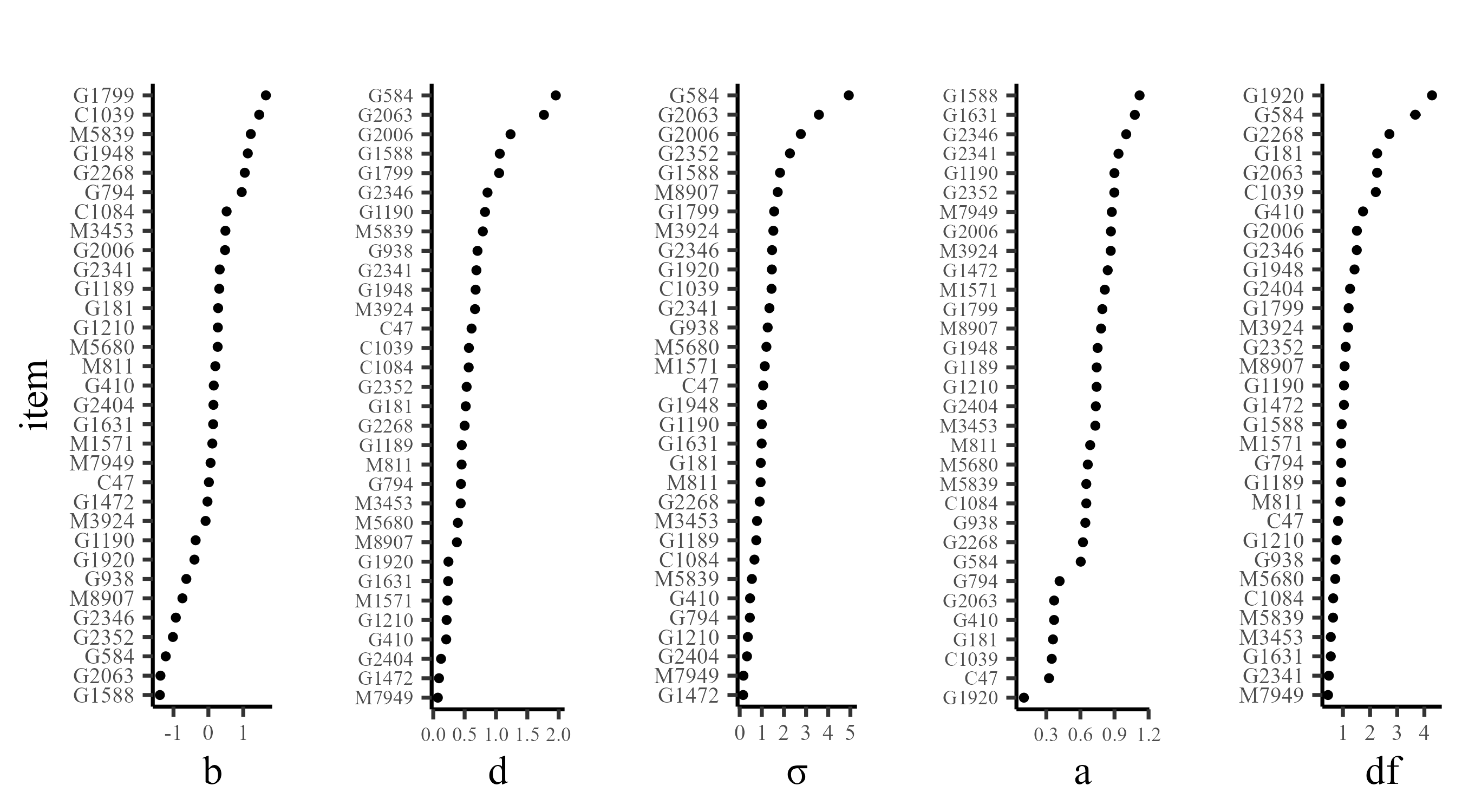
Model Estimation and Item Parameters
All models were estimated in PyMC (Abril-Pla et al., 2023) using Markov Chain Monte Carlo (MCMC) estimation (warmup = 1000, draws = 5000, ~ 40 minutes). All Rhats \(\leq 1.01\).
Person Parameter: \(\theta\)
Distribution of \(\theta\) for the 1194 forecasters (better forecasters have higher \(\theta\) values).
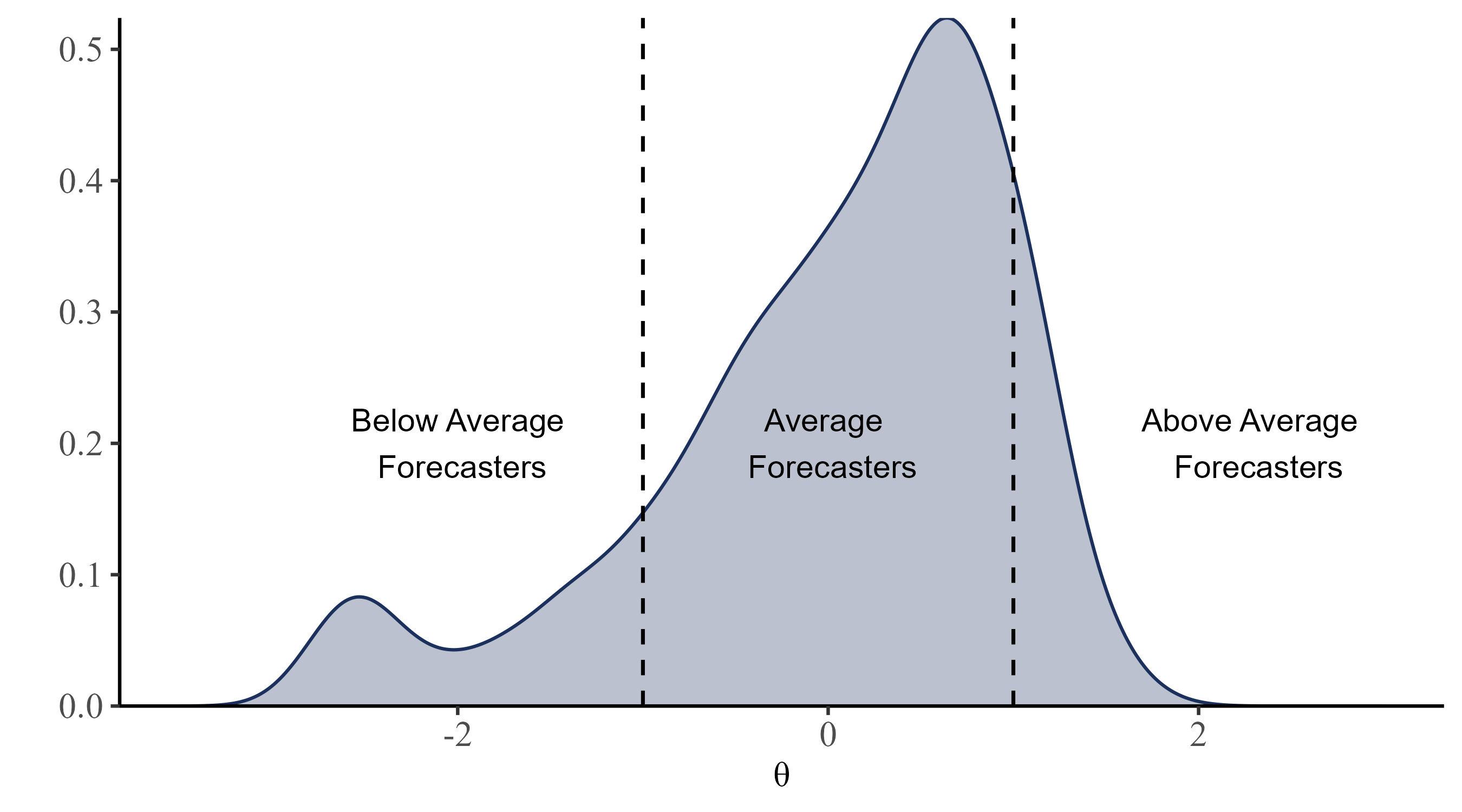
note. The scale \(\theta\) parameter was identified by enforcing a standard normal prior.
Who gets Higher \(\theta s\)?
Forecasters who consistently approach the expected forecasts are rewarded
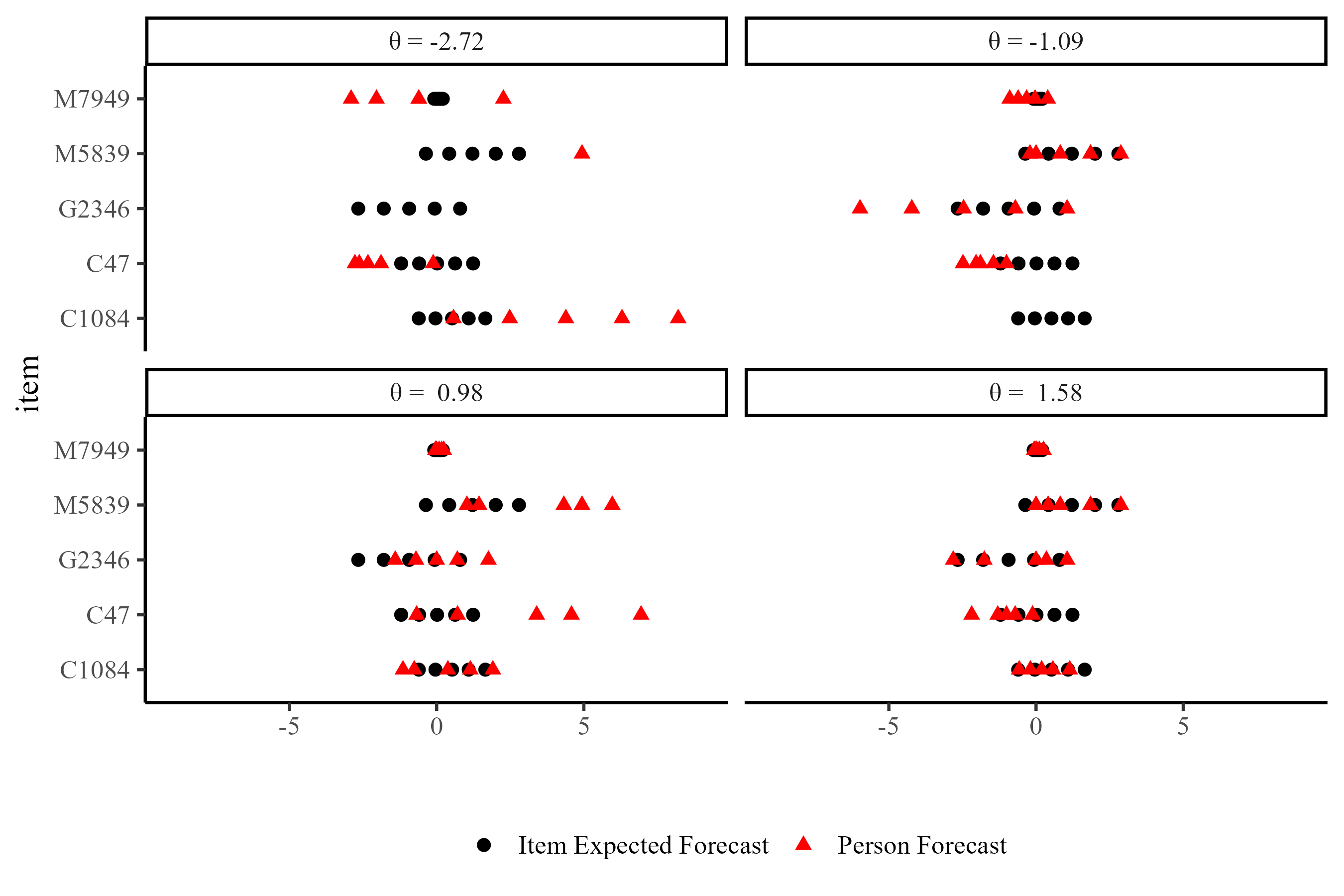
note. In the case of the two top panels, missing person forecast were outside the \(Y_{jiq} = [-9; 9]\) range.
Predicting Out of Sample Accuracy
As per the study pre-registration, Waves 1 and 7 responses were treated as outcome and Waves 2,4, 6 were treated as predictors.
S-scores (SS): A proper scoring rule that is normally used to score quantile forecasts (smaller SS, better forecast)
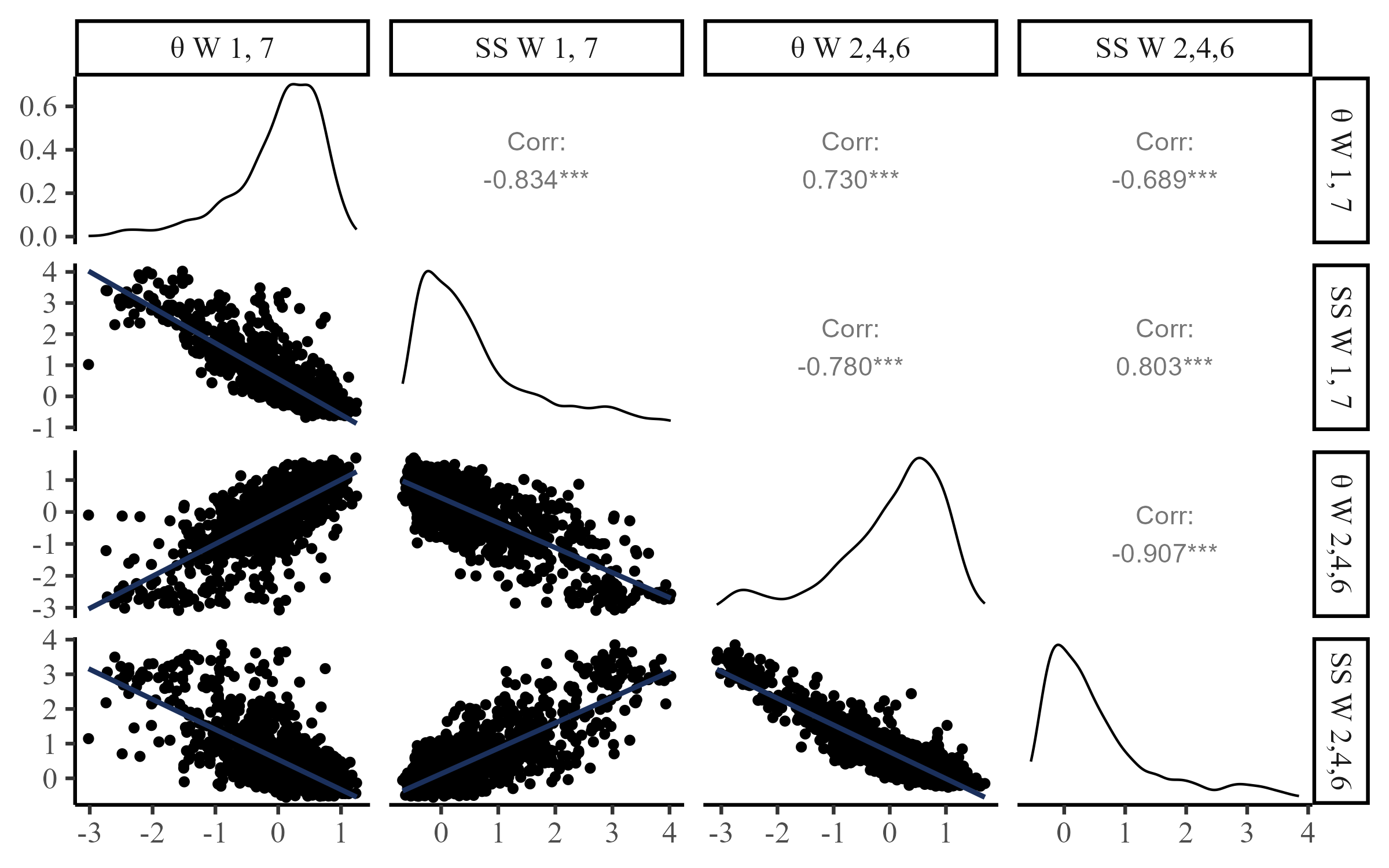
Stability of Parameters
Given the complexity of the FPT items, item parameters are likely to change depending on many factors. Still, there seems to be reasonable stability even after a month between Wave 1 and Wave 7 (test-retest):
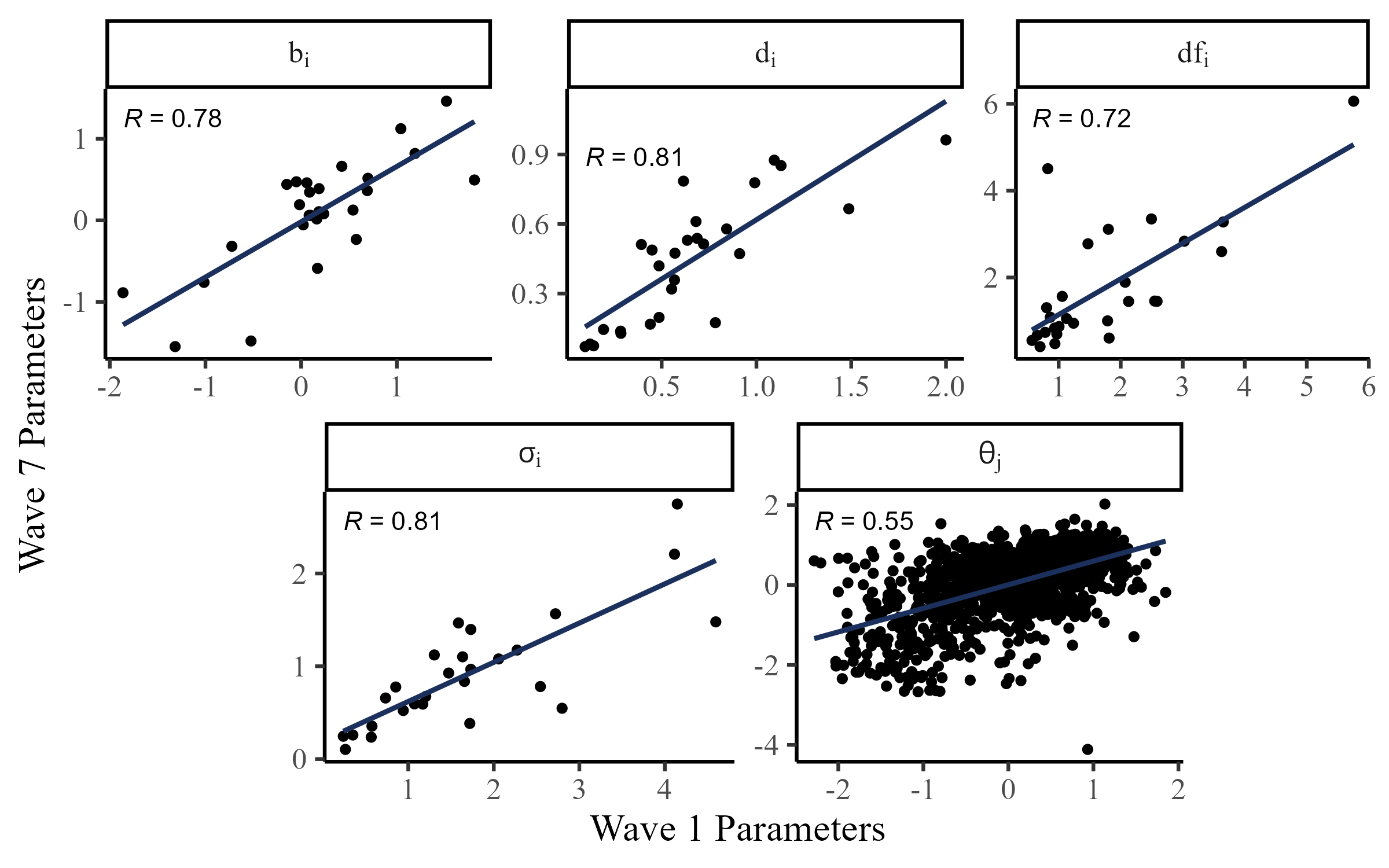
note. Only items from Waves 1 and 7. The \(a_i\) parameter requires higher sample sizes to stably estimate, so it was fixed to 1.
Takeaways
- The current approach captures meaningful difference across FPT items (i.e., bias, difficulty, discrimination,…)
- The \(\theta\) metric is easily understood and viable for scoring individuals
- Item information can be calculated, although the practical uses are not as straightforward as conventional testing scenarios
Acknowledgments


![]()




References And Contacts
Abril-Pla, O., Andreani, V., Carroll, C., Dong, L., Fonnesbeck, C. J., Kochurov, M., Kumar, R., Lao, J., Luhmann, C. C., Martin, O. A., Osthege, M., Vieira, R., Wiecki, T., & Zinkov, R. (2023). PyMC: A modern, and comprehensive probabilistic programming framework in Python. PeerJ Computer Science, 9, e1516. https://doi.org/10.7717/peerj-cs.1516
Himmelstein, M., Zhu, S. M., Petrov, N., Karger, E., Helmer, J., Livnat, S., Bennett, A., Hedley, P., & Tetlock, P. (2024, November 18). The Forecasting Proficiency Test: A General Use Assessment of Forecasting Ability. https://doi.org/10.31234/osf.io/a7kdx
Zhu, S. M., Budescu, D., Petrov, N., Karger, E., & Himmelstein, M. (2024, November 19). The Psychometric Properties of Probability and Quantile Forecasts. https://doi.org/10.31234/osf.io/2m4ya
Contact: fsetti@fordham.edu

Slides and More
