
- Blog
- Forum
- Site
- Page
- « Pangeo Gallery
- Deployment Se... »
Interoperability, extensibility, and portability are core concepts defining the Pangeo technical architecture. Rather than designing and creating a single monolithic application, our vision is an ecosystem of tools that can be used together. We want you to be able to easily build your own Pangeo, whatever that means to you.
In large part, Pangeo began as a group of Xarray users and developers that were working on various big-data geoscience problems. The typical software and hardware stack we envisioned for Pangeo is shown in the figure below.
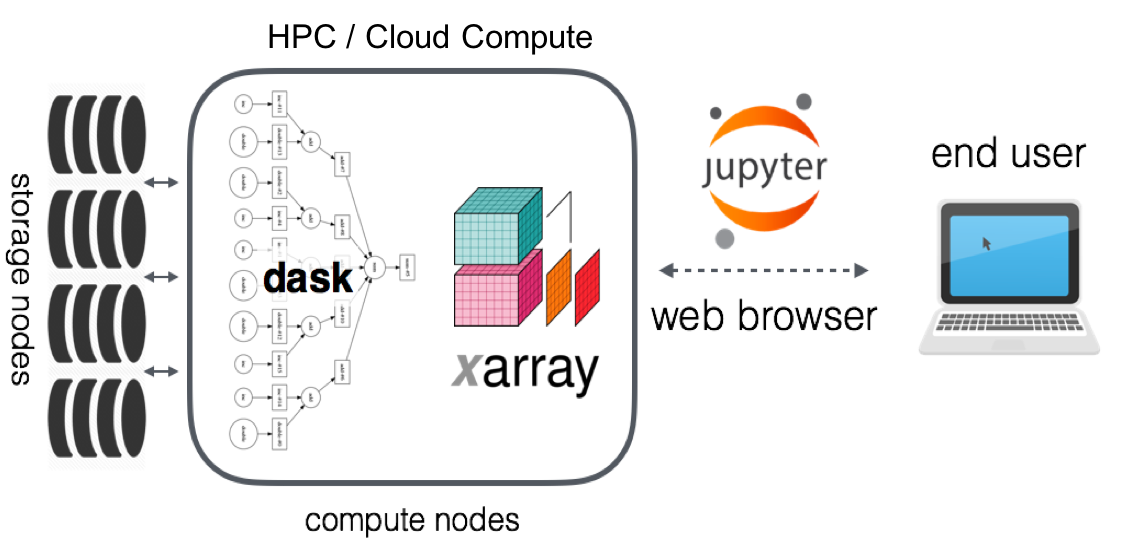
The key concepts and tools we envisioned in the Pangeo ecosystem were:
Ability to use high-level data models (e.g. Xarray)
Ability to leverage distributed parallel computing (e.g. Dask) on HPC systems or on cloud computing systems
Ability to work interactively (e.g. Jupyter) or using batch processing
Although we originally envisioned Pangeo’s focus to be on improving the integration of Xarray, Dask, and Jupyter on HPC systems, the scope of the project has grown substantially.
Pangeo’s ecosystem of interoperable tools allows users to pick and choose from a collection of related but independent packages and approaches. This facilitates portability and customization in user workflows. The illustration below highlights some of the interchangeable components within Pangeo.
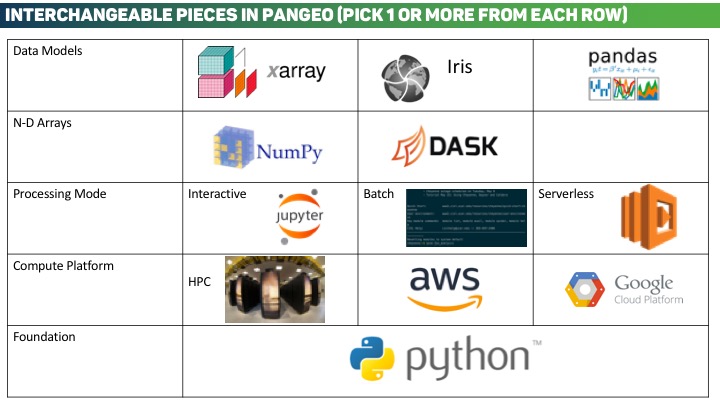
The Pangeo software stack a collection of Python libraries that when used together facilitate scalable analysis. The packages themselves are described in more detail in the Packages section.
The Python programming is quickly becoming the standard language in the open-source data science world. The core packages in the Pangeo stack are all built using Python.
Pangeo utilizes advanced self-describing data models. Examples of these data models are Pandas and Xarray. These data models, coupled with their built in toolkits, allow for expressive high-level data analysis on complex datasets.
N-dimensional arrays of numbers are ubiquitous throughout the computational sciences. In Python, the most common array format is provided by the NumPy library. NumPy provides homogeneous in memory arrays is has been widely adopted throughout the PyData ecosystem. Dask is a library for parallel computing in Python and provides a chunked-lazy NumPy-like array API. Xarray and Pandas both support both NumPy and Dask arrays internally.
Large homogeneous high-performance computing clusters are the most common big-data computing platform in the geosciences today. They often offer many compute nodes, fast interconnects, and parallel file systems - all of which can be used to facilitate rapid scientific analysis.
Commercial Cloud Computing offers the scientific community a fundamentally new model for doing data science. A specific focus of Pangeo is the development of scalable, flexible, and configurable cloud deployments. Detailed information about deploying Pangeo on the cloud can be found at https://github.com/pangeo-data/pangeo-cloud-federation/.
Pangeo currently operates an experimental service called Pangeo Cloud.
The Hierarchical Data Format (HDF) and the Network Common Data Format (NetCDF) are two of the most common on-disk storage layers across the geosciences. The ability to read and write datasets in these common formats in a scalable manor, in conjunction with the rest of the Pangeo stack, is an ongoing focus.