Collocation and keyword analysis on India-related text of Natural History
Abstract
This paper presents a comprehensive analysis of textual collocations and keywords related to “India” in a corpus of Natural History, the earliest known encyclopedia written by Pliny the Elder in the 1st century AD. By analyzing these word associations and significant terms, this study seeks to identify the main themes and topics related to the Indian region within the text. The investigation of how Pliny depicts India in Natural Hisotry could potentially contribute to the discussion of the spatial representation and imagination in the work.
1 Introduction1
Pliny the Elder’s Natural History is widely recognized as the earliest encyclopedia in the world. Written around AD 77, the work is thematically divided into 37 books, covering a diverse range of subjects including astronomy, geography, zoology, botany, medicine, and more. Driven by a pioneering attempt to catalog all human knowledge from his era, Pliny made a comprehensive reference to a wide range of Greek and Roman scholarships, and interwove his own literary interpretation or comments to the narratives in the work.
Natural History stands as a seminal work in the history of encyclopedias, serving as a gateway to understanding the knowledge and worldview of ancient Rome. Beyond its role as a compendium of diverse subjects, the text provides a captivating glimpse into the knowledge, cultural, and merchandize exchange (Dodd 2021) between the Roman Empire and other regions (Gibson & Morello 2011).
As pointed out by Beagon (2011), differentiating from his predecessors, Pliny showed a “terrestrial curiosity” in Natural History, emphasizing recognition of the physical, material world. Drawing from the long-established topographical and ethnographic traditions, Pliny connects volumes dedicated to geography (books 3-6) with broader natural elements, human activities, and cultural, historical, and societal contexts (Roller 2022), exemplified in his description of plants, tribe habitats, imperial expeditions, and trade products. In this regard, this study aims to analyse the text of Natural History in a spatial scope, as geographical names mentioned in the text plays a pivotal role in distributing information, knowledge, and discussions throughout the work.
Natural History is originally in Latin. An English translation by Henry T. Riley (1816-1878) and John Bostock (1773-1846), first published in 1855, is utilized for this study. The translated text is obtained in a digitized version from the TOPOSText project, having been sourced from the Perseus Project and governed by a Creative Commons Attribution-Share-Alike 3.0 U.S. License.
In addition to the digitized textual content of Natural History, the place names mentioned in the text are annotated with their corresponding coordinates on TOPOSText. Since the annotations are available in an HTML format, they are scraped and restructured into a dataset of geographical-related text in Natural History with Beautiful Soup library in Python2. The dataset structure, corpus scraping procedure and and corpus extension will be further explained in Corpus Description section (Section 3).
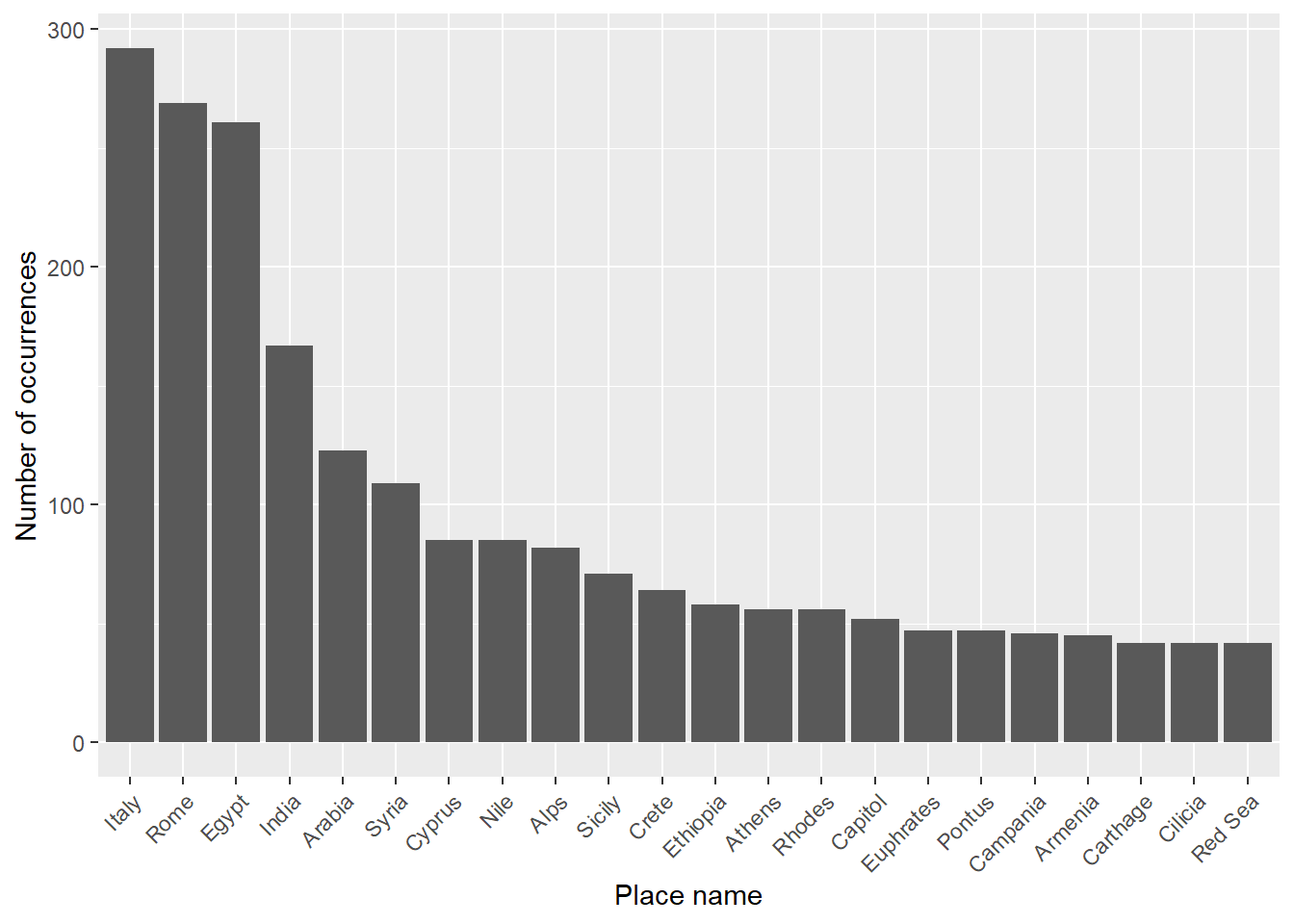
As a starting point of this study, Figure 1 reveals the 20 most frequently mentioned geographical names within the text.
Additionally, Figure 2 depicted the times of each place name found mentioned in the work on a map. The individual places are represented by distinct dots, and its occurring times in the text are represented by the size of the dots. The larger the dot size, the more frequent it is appeared in the context.
An intriguing observation from these figures is that India seems being prominently mentioned in the work despite locating outside the Mediterranean.
Based on this observation, the focus of the study is narrowed down to India-related texts in the Natural History to investigate how India is described in the work. By delving into the themes associated with the Indian region using the methods of collocation and keyword analysis, this study aims to examine Pliny the Elder’s portrayal of India, which may shed light on the spatial perception and imagination of the representative writers and scholars of ancient Rome.
The following sections provide a detailed explanation of the methodology and corpus used, an interpretation and discussion of the results of the collocation and keyword analysis, and an overall conclusion in response to the research questions.
2 Methodology
To investigate the prominent themes in the India-related content discussed in Natural History, the study generally employs methods of collocation analysis and keyword analysis in corpus linguistics, and is conducted in R environment (R Core Team 2022). The discussions are based on the mclm::assoc_scores objects returned with mclm (Speelman & Montes 2022) package. In addition, tidyverse (Wickham 2023), leaflet (Cheng, Karambelkar & Xie 2023) and kableExtra (Zhu 2021) packages are used for data manipulation and visualization.
In the Data Analysis section (Section 4), both of the collocation and keyword analysis are examined using three measures of association, namely absolute frequency, PMI and signed \(G^2\) to discuss the potential theme it inferred with an integration of a close reading of the text.
Absolute frequency refers to the simple count of each single type (distinct word) observed in the text. In the case of collocation analysis, it shows how often a type collocates with the target word. While in the case of keyword analysis, it shows how often a type occurs in the target corpus. As a basic counting measure, absolute frequency provide an general view of the word distribution.
PMI (Pointwise Mutual Information) is one of effect size measures for association. It compares the observed co-occurring frequency of two outcomes to the probability of either of them occurring independently. It can be applied to observe word association, and the association between words and context categories as well (Bestvater & Shah 2022). As the PMI value increases by one, the probability becomes twice as high. High PMI values indicates strong associations.
\(G^2\) refers to the log-likelihood ratio for measuring the strength of statistical evidence of the observasion (Blume 2017). In the context of this study, it indicates how significant the association between the two factors (either for two words or for keywords associating with a target corpus) is. Specificly, the signed \(G^2\) score returned by mclm::assoc_scores shows the strength of evidence for attraction, i.e. co-occurrence. High signed \(G^2\) values suggest that the co-occurrence is unlikely to occur by chance.
Since a PMI score higher than two indicates a four times higher probability of association, and a signed \(G^2\) score higher than 3.84 indicates a significant association at a 95% confidence level (Montes 2022), a filter of “PMI >= 2 & signed \(G^2\) >= 3.84” is applied to the returned objects of mclm::assoc_scores for both methods to obtain strong and significant association results for further discussion.
2.1 Collocation Analysis
Collocation analysis is a technique used in corpus linguistics to identify words that frequently occur together in a given text. This technique is based on the idea that certain words tend to occur together more often than they would by chance.
This study examines the textual co-occurrence of the word “India” in Natural History. Lists of highly frequent words co-occurring with “India” in context are obtained and sorted by scores of different measures. The potential themes of India-related content in the work can be discussed based on the outputs of textual collocation of word “India”.
2.2 Keyword Analysis
Keyword analysis is a statistical method used in corpus linguistics to identify words that occur more frequently in a target corpus than in a reference corpus. The words that have a higher association with the target corpus compared to their frequency in the reference corpus are considered to be the “keyword” of the target corpus.
In this study, the target corpus includes all paragraphs in Natural History that mention place names in Indian regions, and the reference corpus includes all other paragraphs in the work. Lists of words with relatively higher frequency in the target corpus are obtained and sorted by the different measurements. The “keywords” found in the India-related text in Natural History provide more descriptive information about the topics and elements related to “India” in Pliny’s narrative.
By combining the two methods and integrating them with a close reading of the text, this study aims to gain insights into how “India” is discussed and represented in Natural History.
3 Corpus Description
As mentioned, an English translation by Henry T. Riley (1816-1878) and John Bostock (1773-1846) of the original Latin text of Natural History is employed in the study.
The digitized text is available in paragraphs with geographical annotations on TOPOSText website as two parts, book 1-11 and book 12-37, both of which are in HTML format. Extracting all “place” classes in the HTML files, information of all annotated place names in the work, the URI and corresponding coordinates of the place, the book/chapter/paragraph number where it is mentioned, as well as the coordinating textual content is structured as a dataset of geographical-related text in Natural History. This dataset is used for an initial exploration of the prominent places mentioned in the text.
The initial observation shown in Figure 1 and Figure 2 leads to a focus on the India-related text for this study. With a reference to Barrington Atlas of the Greek and Roman World (Talbert 2000a; b), the approximate geographical coordinates defining the Indian region during the time of Natural Hisoty are as follows3:
Latitude: 5-35 degrees North
Longitude: 65-95 degrees East
The records in geographical-related text dataset with corresponding coordinates that fall within the specified range are extracted as the India-related text dataset.
Each distinct paragraph in the India-related text dataset is extracted and stored in TXT format as separate files within a corpus folder, comprising a total of 146 files as the target corpus. The file names contain information about the book, chapter, and paragraph number of the text. This target corpus contains 37489 tokens and 6003 types, with the type-token ratio of 0.16.
The full text of the entire work, separated in paragraphs, are also scraped and stored in TXT format as a general corpus. This general corpus of 3493 files contains 710117 tokens and 31380 types, with the type-token ratio of 0.04.
Excluding those in target corpus from the general corpus, the other parts of the work contain 3347 files, serve as a reference corpus. The reference corpus contains 672628 tokens and 30294 types, with the type-token ratio of 0.05.
The general corpus is employed for the collocation analysis and the target corpus and reference corpus are used in the keywords analysis.
During the extraction process of the corpus files, the texts are already converted to lower case. In addition, the closing quotation mark “’”, which ranks high while provides limited information in the initial observation of the returned frequency lists, is replaced by an empty string for a more informative return for further discussions.
4 Data Analysis
4.1 Textual collocating word with “India” in Natural History
Collocation analysis traces the frequent occurrence of certain words or phrases in close proximity to each other within a given context. Unlike surface collocation, which considers the collocating span, i.e., the specific words to the left and right of the target word (Evert 2009), the span in textual collocation refers to the textual unit around the target word. Setting “India” as the target word for tracing in the corpus of all paragraphs in Natural History, the mclm::text_cooc() function returns the frequency of words appearing in the context of “India”. As mentioned in the Methodology section (Section 2), the returned results are filtered with a statistical criterion to obtain a list of the most frequently collocated words with the word “India” with strong evidence.
The prominent textual collocates of “India” identified with this approach suggest the potential themes about the Indian region in the narrative of Pliny.
Table 1, Table 2 and Table 3 show the top 20 textual collocates associated with the word “India”, sorted by absolute frequency, signed \(G^2\) and PMI scores in decsending order.
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| arabia | 28 | 3.06 | 82.6 |
| indian | 23 | 3.40 | 78.9 |
| hundred | 21 | 2.25 | 37.4 |
| ethiopia | 15 | 3.06 | 42.7 |
| alexander | 14 | 2.08 | 21.3 |
| numerous | 13 | 2.15 | 20.9 |
| elephants | 12 | 3.09 | 34.4 |
| rock-crystal | 11 | 3.59 | 40.2 |
| luxury | 10 | 2.13 | 15.6 |
| closely | 10 | 2.15 | 15.8 |
| gems | 10 | 2.98 | 26.9 |
| gum | 9 | 2.07 | 13.3 |
| valuable | 9 | 2.51 | 18.3 |
| pearls | 9 | 2.95 | 23.8 |
| indians | 9 | 3.54 | 32.0 |
| ganges | 9 | 4.09 | 41.1 |
| shadow | 9 | 2.41 | 17.2 |
| bright | 9 | 2.09 | 13.6 |
| thousand | 9 | 2.41 | 17.2 |
| bearing | 8 | 2.05 | 11.6 |
| indus | 8 | 3.44 | 27.0 |
| juba | 8 | 2.40 | 15.1 |
| resemblance | 8 | 2.13 | 12.4 |
| transparent | 8 | 2.58 | 17.0 |
| elephant | 8 | 2.78 | 19.2 |
| resemble | 8 | 2.27 | 13.8 |
| cappadocia | 8 | 2.87 | 20.2 |
| deserts | 8 | 2.47 | 15.8 |
| caspian | 8 | 3.02 | 21.9 |
| blue | 8 | 2.62 | 17.4 |
| gem | 8 | 3.66 | 30.0 |
| sail | 8 | 2.70 | 18.2 |
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| arabia | 28.0 | 3.06 | 82.6 |
| indian | 23.0 | 3.40 | 78.9 |
| ethiopia | 15.0 | 3.06 | 42.7 |
| ganges | 9.0 | 4.09 | 41.1 |
| rock-crystal | 11.0 | 3.59 | 40.2 |
| hundred | 21.0 | 2.25 | 37.4 |
| elephants | 12.0 | 3.09 | 34.4 |
| megasthenes | 5.5 | 4.69 | 33.6 |
| indians | 9.0 | 3.54 | 32.0 |
| gem | 8.0 | 3.66 | 30.0 |
| lustre | 7.0 | 3.94 | 29.7 |
| identical | 6.0 | 4.09 | 27.3 |
| 'smaragdus | 6.0 | 4.09 | 27.3 |
| indus | 8.0 | 3.44 | 27.0 |
| gems | 10.0 | 2.98 | 26.9 |
| gemstone | 7.0 | 3.55 | 24.9 |
| pearls | 9.0 | 2.95 | 23.8 |
| onesicritus | 5.0 | 4.15 | 23.3 |
| mart | 4.0 | 4.51 | 22.0 |
| caspian | 8.0 | 3.02 | 21.9 |
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| megasthenes | 5.5 | 4.69 | 33.6 |
| thorn-bush | 3.5 | 4.62 | 20.5 |
| carnelian | 3.5 | 4.62 | 20.5 |
| obsidian | 3.5 | 4.62 | 20.5 |
| cophes | 3.5 | 4.62 | 20.5 |
| merchandize | 3.5 | 4.62 | 20.5 |
| mart | 4.0 | 4.51 | 22.0 |
| expeditions | 3.0 | 4.41 | 15.7 |
| patala | 3.0 | 4.41 | 15.7 |
| arii | 3.0 | 4.41 | 15.7 |
| ichthyophagi | 3.0 | 4.41 | 15.7 |
| pursuits | 3.0 | 4.41 | 15.7 |
| vermilion | 4.0 | 4.24 | 19.4 |
| biggest | 4.0 | 4.24 | 19.4 |
| onesicritus | 5.0 | 4.15 | 23.3 |
| identical | 6.0 | 4.09 | 27.3 |
| ganges | 9.0 | 4.09 | 41.1 |
| engrave | 3.0 | 4.09 | 13.6 |
| 'smaragdus | 6.0 | 4.09 | 27.3 |
| honey-coloured | 4.0 | 4.02 | 17.5 |
| reflects | 4.0 | 4.02 | 17.5 |
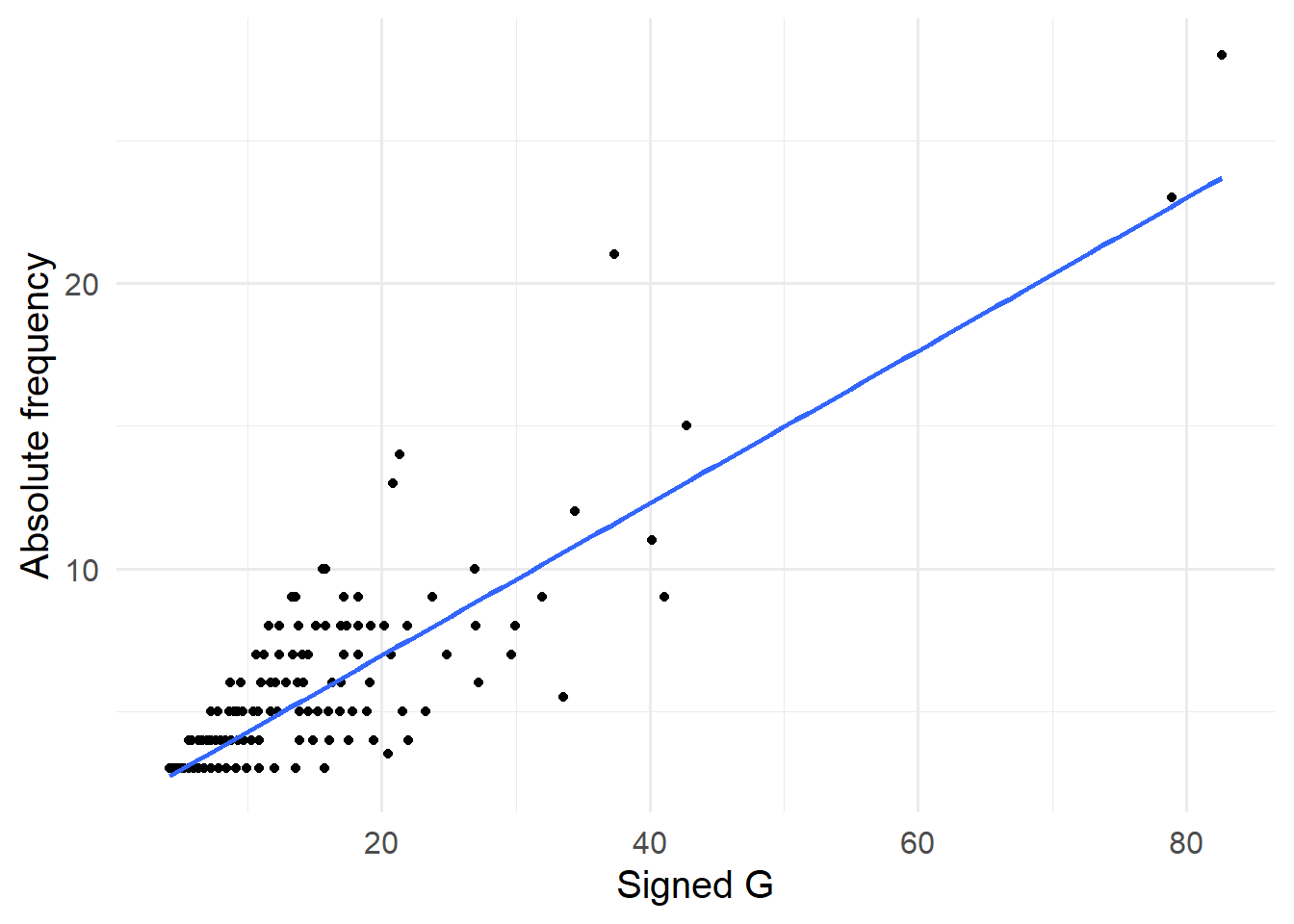
The top 20 ranking word lists of absolute frequency and signed \(G^2\) score have a 11/20 overlapping outputs. As shown in Figure 3, there is a positive correlation between the signed \(G^2\) score and absolute frequency in textual collocation analysis.
The high-ranking words collocating with “India”, sorted by their absolute frequency and signed \(G^2\) score, are categorized as follows. Those without specifying the association measures (“A” stands for “absolute frequency” and “G” stands for “signed \(G^2\) score”) are the overlapped ones. The overlapped words are considered having the strongest evidence of frequently collocating with “India” in the context.
Geographical connections: arabia, indian, ethiopia, ganges, indus(G)
Animal/Plant: elephants, gum(A), lustre(G)
Precious stone: stones, rock-crystal, gems, gem(G), gemstone(G), pearls, smaragdus(G)
Historical figure: alexander(A), megasthenes(G), onesicritus(G)
Merchandise exchange: mart(G)
Descriptive expression: hundred, thousand(A), whole(A), numerous(A), luxury(A), closely(A), valuable(A), bright(A), identical(G)
Others: shadow(A), year(A)
These categories indicate that the “India” narrative in Natural History covers three major dimensions. The first dimension is its geographical information, including its connection to other places (primarily Arabia and Ethiopia), the two major rivers in the region, Ganges and Indus, and the animals, plants and precious stones originating from it. And it is frequently mentioned with historical figures, some related to the conquest history of the Roman Empire (in the case of alexander, referring to Alexander the Great, who conducted several expeditions to Indian subcontinent), and some related to the referencing scholarship Pliny consulted in the work. Moreover, the term mart and the descriptive phrases such as luxury and valuable, highlights the merchandise exchanges introduced in the discussion of India.
In the mclm::text_cooc() function, the given text will be separated as target context (text surrounding the target node) and reference context (text not surrounding the target node). The normalized frequency of the top ranking words with the highest frequency and strongest evidence in the target context are at least 20 times higher than that of the reference context, as shown in Table 4.
| Type | Target_Nrm_Frequency | Reference_Nrm_Frequency |
|---|---|---|
| arabia | 2276 | 198.81 |
| indian | 1870 | 115.73 |
| hundred | 1707 | 308.61 |
| stones | 1545 | 344.21 |
| ethiopia | 1220 | 106.83 |
| elephants | 976 | 83.09 |
| rock-crystal | 894 | 44.51 |
| gems | 813 | 77.15 |
| pearls | 732 | 71.22 |
| indians | 732 | 38.58 |
| ganges | 732 | 17.80 |
| indus | 650 | 38.58 |
| gem | 650 | 29.67 |
| gemstone | 569 | 29.67 |
| lustre | 569 | 17.80 |
| identical | 488 | 11.87 |
| 'smaragdus | 488 | 11.87 |
| onesicritus | 407 | 8.90 |
| megasthenes | 407 | NA |
| mart | 325 | 2.97 |
When examining the normalized frequency of the top 20 list sorted by PMI score, as presented in Table 5, all of the results exhibit a higher frequency than that of the reference context as well.
| Type | Target_Nrm_Frequency | Reference_Nrm_Frequency |
|---|---|---|
| ganges | 732 | 17.80 |
| identical | 488 | 11.87 |
| 'smaragdus | 488 | 11.87 |
| onesicritus | 407 | 8.90 |
| megasthenes | 407 | NA |
| honey-coloured | 325 | 8.90 |
| reflects | 325 | 8.90 |
| vermilion | 325 | 5.93 |
| biggest | 325 | 5.93 |
| mart | 325 | 2.97 |
| expeditions | 244 | 2.97 |
| thorn-bush | 244 | NA |
| patala | 244 | 2.97 |
| arii | 244 | 2.97 |
| engrave | 244 | 5.93 |
| carnelian | 244 | NA |
| obsidian | 244 | NA |
| cophes | 244 | NA |
| ichthyophagi | 244 | 2.97 |
| merchandize | 244 | NA |
| pursuits | 244 | 2.97 |
As the PMI sorting identifies the words of the strongest attraction with the word “India” in the context, the listed words provides additional descriptive information about the themes relating to India in the work. Most of them can be classified into the aforementioned categories set for the results of absolute frequency and signed \(G^2\) score, some of the words contribute to a new category relating to the existing ones. The top ranking words sorted by PMI are grouped as follows:
Geographical connections: cophes, patala, ganges
Animal/Plant: thorn-bush
Precious stone: carnelian, obsidian, ’smaragdus
Historical figure: megasthenes, onesicritus
Merchandise exchange: merchandize, mart
Descriptive expression: vermilion, biggest, identical, honey-coloured
Others: reflects
Activity (new category): expeditions, pursuits, engrave
Ethnic group (new category): arii, ichthyophagi
Except for displaying more specific geographic connections, plant and gemstone names, the descriptive expressions in the list pertain to the description of stones (such as vermilion and honey-coloured) and the special traits of natural creatures originating in India (such as biggest and identical) in Natural History. The words in the new categories relate to the existing categories. For example, the terms in “Activity” refer to Alexander the Great’s expedition to the Indian subcontinent, the necessity for exchange of merchandise (pursuits), and the processing of gemstones (engrave). The terms in “Ethnic group” pertain to the human communities living in India and its surrounding regions. This additional information reinforces the conclusion that when “India” is mentioned in the work, Pliny tended to focus his discussion on its geographical conditions and trade relations with the Roman Empire.
The observations from the top ranking “India”-collocating word lists of the three measures highlight how the narrative of Natural History underscores India’s geographical interconnection and its important role in merchandise and cultural exchange.
4.2 Keywords in India-related text in Natural History
Additionally, in order to examine the significant phrases, i.e. “keywords”, in the India-related content in the work, a keyword analysis for the India-related text is employed as a comparison and complement to the conclusion of the textual collocation analysis.
The word frequency and their association scores in the target corpus (India-related texts) and reference corpus (other parts of Natural History excluding the India-related texts) are obtained with the mclm::assoc_scores() function. Similar to the collocation analysis, the returned scores are filtered with a criterion of PMI >= 2 and signed \(G^2\) >= 3.84 to ensure that the words selected for further discussion have a strong attraction to the target corpus with statistical significance (Montes 2022).
The following tables show the top 20 keywords in India-related texts as compared to the total texts in Natural History. They are sorted by their absolute frequency (Table 6), signed \(G^2\) score (Table 7) and PMI score (Table 8) in descending order.
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| india | 169.5 | 4.24 | 991.1 |
| hundred | 95.0 | 2.69 | 221.8 |
| stones | 56.0 | 2.02 | 79.9 |
| arabia | 43.0 | 2.68 | 99.5 |
| indian | 38.0 | 3.00 | 106.6 |
| alexander | 37.0 | 2.34 | 68.2 |
| amber | 32.0 | 3.39 | 111.3 |
| thousand | 31.0 | 2.75 | 75.1 |
| elephants | 27.0 | 2.64 | 60.9 |
| indus | 25.0 | 4.19 | 138.7 |
| glass | 24.0 | 2.92 | 64.3 |
| thence | 24.0 | 2.70 | 56.2 |
| ganges | 22.5 | 4.21 | 127.6 |
| rock-crystal | 19.0 | 3.32 | 63.8 |
| ethiopia | 18.0 | 2.53 | 37.8 |
| fifty | 18.0 | 2.11 | 27.7 |
| pepper | 17.0 | 2.47 | 34.3 |
| tribe | 16.0 | 2.63 | 35.8 |
| indians | 15.0 | 3.40 | 52.5 |
| sail | 15.0 | 2.51 | 31.0 |
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| india | 169.5 | 4.24 | 991.1 |
| hundred | 95.0 | 2.69 | 221.8 |
| indus | 25.0 | 4.19 | 138.7 |
| ganges | 22.5 | 4.21 | 127.6 |
| amber | 32.0 | 3.39 | 111.3 |
| indian | 38.0 | 3.00 | 106.6 |
| arabia | 43.0 | 2.68 | 99.5 |
| stones | 56.0 | 2.02 | 79.9 |
| beryls | 13.5 | 4.19 | 75.2 |
| thousand | 31.0 | 2.75 | 75.1 |
| alexander | 37.0 | 2.34 | 68.2 |
| glass | 24.0 | 2.92 | 64.3 |
| rock-crystal | 19.0 | 3.32 | 63.8 |
| elephants | 27.0 | 2.64 | 60.9 |
| thence | 24.0 | 2.70 | 56.2 |
| indians | 15.0 | 3.40 | 52.5 |
| taprobane | 8.5 | 4.16 | 46.2 |
| ichthyophagi | 7.5 | 4.15 | 40.4 |
| megasthenes | 7.5 | 4.15 | 40.4 |
| ethiopia | 18.0 | 2.53 | 37.8 |
| Type | Frequency | PMI | Signed $G^2$ |
|---|---|---|---|
| india | 169.5 | 4.24 | 991.1 |
| ganges | 22.5 | 4.21 | 127.6 |
| beryls | 13.5 | 4.19 | 75.2 |
| indus | 25.0 | 4.19 | 138.7 |
| taprobane | 8.5 | 4.16 | 46.2 |
| ichthyophagi | 7.5 | 4.15 | 40.4 |
| megasthenes | 7.5 | 4.15 | 40.4 |
| obsidian | 6.5 | 4.14 | 34.7 |
| bdellium | 5.5 | 4.12 | 29.0 |
| agates | 4.5 | 4.09 | 23.3 |
| callaina | 4.5 | 4.09 | 23.3 |
| condensation | 4.5 | 4.09 | 23.3 |
| expeditions | 4.5 | 4.09 | 23.3 |
| gerra | 4.5 | 4.09 | 23.3 |
| jomanes | 4.5 | 4.09 | 23.3 |
| nonius | 4.5 | 4.09 | 23.3 |
| patala | 4.5 | 4.09 | 23.3 |
| prasii | 4.5 | 4.09 | 23.3 |
| alia | 3.5 | 4.05 | 17.6 |
| bactra | 3.5 | 4.05 | 17.6 |
| carnelian | 3.5 | 4.05 | 17.6 |
| ceylon | 3.5 | 4.05 | 17.6 |
| cophes | 3.5 | 4.05 | 17.6 |
| hypasis | 3.5 | 4.05 | 17.6 |
| merchandize | 3.5 | 4.05 | 17.6 |
| pepper-tree | 3.5 | 4.05 | 17.6 |
| sacae | 3.5 | 4.05 | 17.6 |
| sandastros | 3.5 | 4.05 | 17.6 |
| thorn-bush | 3.5 | 4.05 | 17.6 |
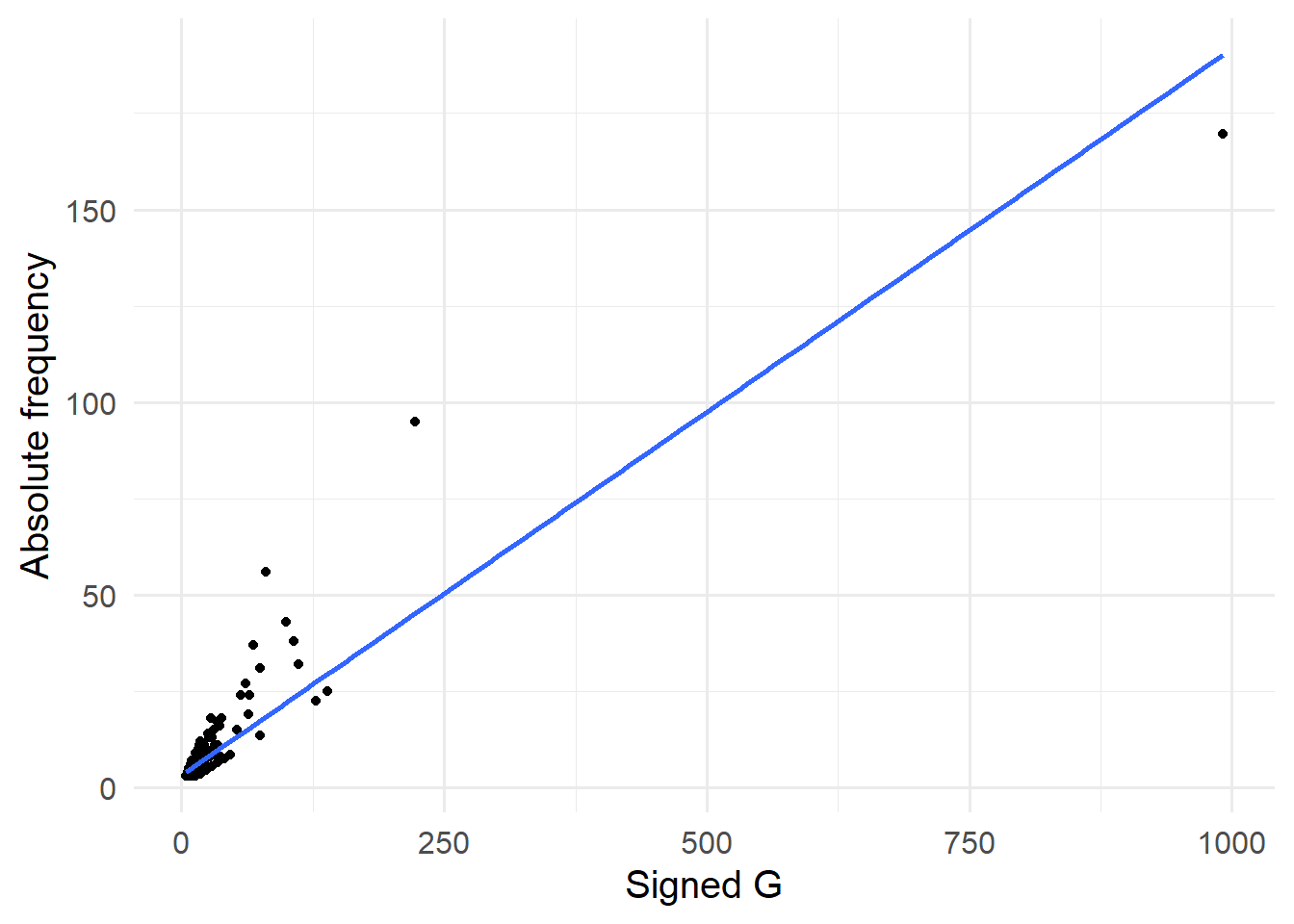
Among the three lists sorted by different measures, 16/20 words of the absolute frequency top ranking list overlap with that of the signed \(G^2\) score. As shown in the Figure 4, the signed \(G^2\) score has a positive correlation with the absolute frequency in this case.
The top 20 keyword lists, sorted by absolute frequency and signed \(G^2\) score, can be categorized similarly to the previous collocation analysis. In the categorized groups below, those without association measures remarks (“A” stands for “absolute frequency” and “G” for “signed \(G^2\) score”) are the overlapping ones.
Geographical connections: india, arabia, indian, ganges, indus, ethiopia, taprobane(G), thence, sail(A)
Animal/Plant: elephants, pepper(A)
Precious stone: stones, amber, rock-crystal, glass, beryls(G)
Historical figure: alexander, ichthyophagi(G), megasthenes(G)
Ethnic group: indians, tribe(A)
Descriptive expression (numeric): hundred, thousand, fifty(A)
The words in each group partially overlap with the results of the collocation analysis, which on the one hand confirms the potential themes in the India-related content as concluded earlier, and on the other hand suggests that the textual collocates of “India” with a high evidence ranking may also serve as keywords in the target corpus.
Comparing the normalized frequency of these words in the target and reference corpus, they all show significantly higher frequencies in the target corpus, as shown in Table 9.
| Type | Target_Nrm_Frequency | Reference_Nrm_Frequency |
|---|---|---|
| india | 45.08 | NA |
| hundred | 25.34 | 2.721 |
| stones | 14.94 | 3.063 |
| arabia | 11.47 | 1.249 |
| indian | 10.14 | 0.773 |
| alexander | 9.87 | 1.502 |
| amber | 8.54 | 0.387 |
| thousand | 8.27 | 0.833 |
| elephants | 7.20 | 0.818 |
| indus | 6.67 | 0.015 |
| glass | 6.40 | 0.535 |
| thence | 6.40 | 0.684 |
| ganges | 5.87 | NA |
| rock-crystal | 5.07 | 0.253 |
| ethiopia | 4.80 | 0.610 |
| indians | 4.00 | 0.178 |
Moreover, since the PMI score indicates the degree of probability of the selected keyword’s occurrence in the target corpus higher than that in the reference corpus, it could be adopted as a more convincing indicator for keyword analysis.
When checking the normalized frequency of the top 20 keywords with the highest PMI score, as shown in Table 10, almost all of them seem to be distinct in the India-related text, which reinforces the indication that they are especially key to the target corpus compared to the other parts of the work.
| Type | Target_Nrm_Frequency | Reference_Nrm_Frequency |
|---|---|---|
| india | 45.08 | NA |
| indus | 6.67 | 0.015 |
| ganges | 5.87 | NA |
| beryls | 3.47 | NA |
| taprobane | 2.13 | NA |
| ichthyophagi | 1.87 | NA |
| megasthenes | 1.87 | NA |
| obsidian | 1.60 | NA |
| bdellium | 1.33 | NA |
| agates | 1.07 | NA |
| callaina | 1.07 | NA |
| condensation | 1.07 | NA |
| expeditions | 1.07 | NA |
| gerra | 1.07 | NA |
| jomanes | 1.07 | NA |
| nonius | 1.07 | NA |
| patala | 1.07 | NA |
| prasii | 1.07 | NA |
| alia | 0.80 | NA |
| bactra | 0.80 | NA |
| carnelian | 0.80 | NA |
| ceylon | 0.80 | NA |
| cophes | 0.80 | NA |
| hypasis | 0.80 | NA |
| merchandize | 0.80 | NA |
| pepper-tree | 0.80 | NA |
| sacae | 0.80 | NA |
| sandastros | 0.80 | NA |
| thorn-bush | 0.80 | NA |
These keywords are manually reviewed to determine their meaning and assigned classification tags based on their category. The explanations for the top 20 keywords with the highest PMI scores are displayed in the Table 11 below.
| Word | Explaination | Category | Remark |
|---|---|---|---|
| india | name of the focused region of this study | region | N/A |
| indus | a major river in India | river | N/A |
| ganges | a major river in India | river | N/A |
| beryls | a type of gemstone | goods | gemstone |
| taprobane | island in Sri Lanka | region | N/A |
| ichthyophagi | a group of people who primarily subsist on fish | people | tribe |
| megasthenes | a Greek historian and diplomat | people | referencing scholar |
| obsidian | a type of volcanic glass | goods | other goods |
| bdellium | a fragrant resin obtained from certain trees | goods | other goods |
| agates | a type of semiprecious gemstone | goods | gemstone |
| callaina | pale green precious stone (lat) | goods | gemstone |
| condensation | the process of vapor turning into a liquid state | activity | producing activity |
| expeditions | referring to the expedition of Alexander the Great | activity | N/A |
| gerra | war (lat) | activity | N/A |
| jomanes | the most important of the affluents of the Ganges | river | N/A |
| nonius | a Roman nomen gentile, gens or "family name" | people | human name |
| patala | name of an ancient city at the mouth of the Indus River | region | N/A |
| prasii | prase, green coloured gem | goods | gemstone |
| alia | by another / different way / route (lat) | route | N/A |
| bactra | name of a city in Asia Minor | region | N/A |
| carnelian | a reddish-brown variety of chalcedony | goods | gemstone |
| ceylon | name of an island in Indian subcontinent | region | N/A |
| cophes | a river that emerges in Hindu Kush mountains and empties into the Indus River | river | N/A |
| hypasis | a river in north India | river | N/A |
| merchandize | goods or commodities | goods | general goods |
| pepper-tree | a tree that produces peppercorns | plant | origin of goods |
| sacae | historic Persian ethnic group | people | N/A |
| sandastros | a precious stone found in India and Arabia | goods | gemstone |
| thorn-bush | any of many thorny or spiny shrubs and bushes | plant | N/A |
Figure 5 demonstrates the distribution of the classification tags of the top 20 keywords with the highest PMI score.
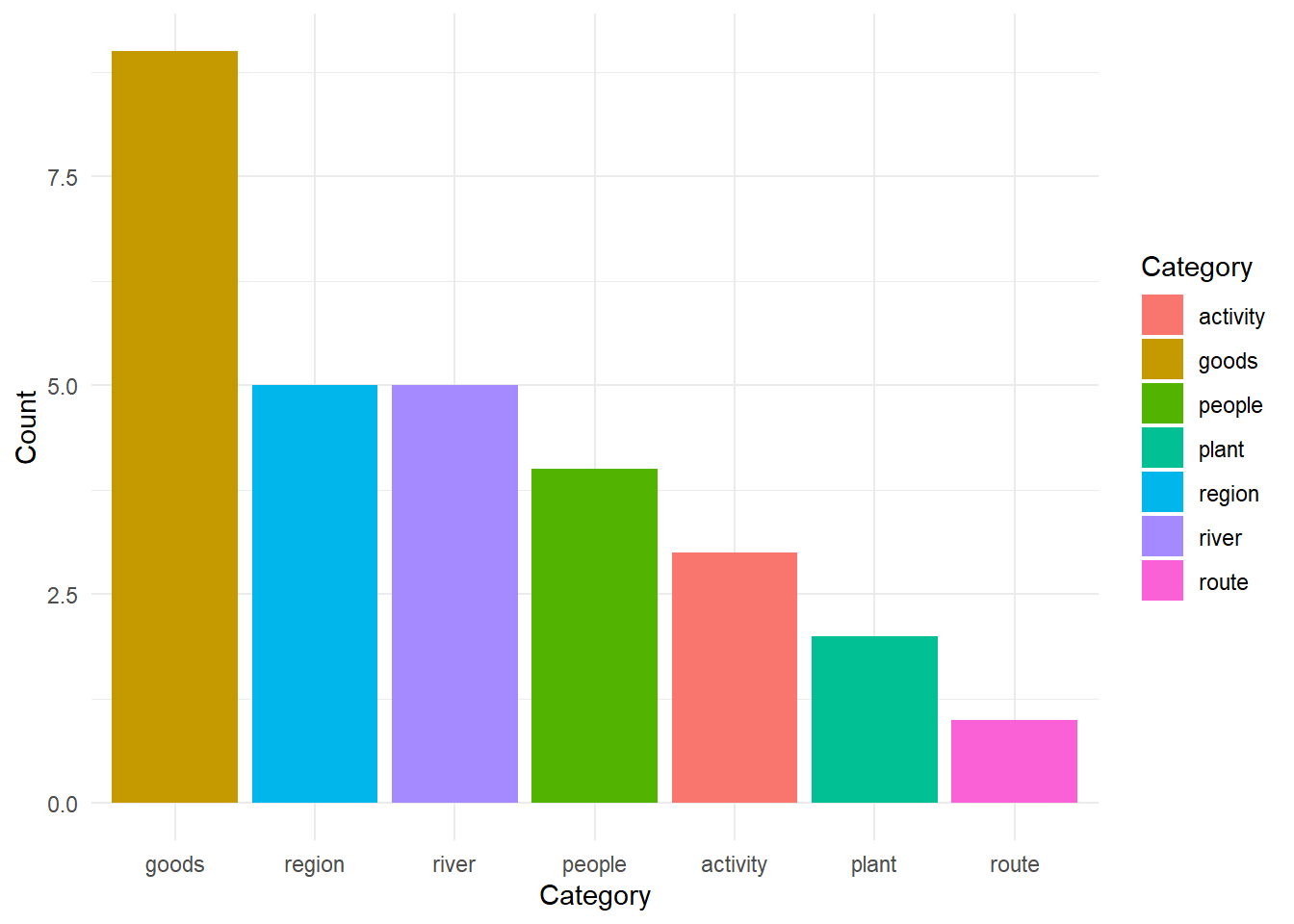
A significant proportion of the highest PMI-scored keywords in texts related to India center around the concept of “goods”, specifically gemstones. This emphasis on gemstones indicates a prevailing thematic concentration in this context. The inclusion of keywords such as beryls, agates, callaina, obsidian, prasii, carnelian, sandastros, obsidian and bdellium represents the integration of diverse gemstones and commodities closely linked to India. Complemented by the presence of keywords like condensation, merchandize and pepper-tree, which relate to the production and trade of goods, India’s role as an central hub in the Indo-Mediterranean commercial network is emphasized in the narrative.
Additionally, many of the keywords are names of rivers that flow through India, such as indus, ganges, jomanes, cophes, and hypasis. These rivers are important for transportation within India and connecting it with neighboring regions. Some of them serve as landmarks along trade routes or the origins of traded goods. Taking a broader context into consideration, as noted by Roller (2022), Pliny shows a particular interest in rivers in Natural History, not only in relation to India. The highlights on rivers reflect a shift in Roman geographical ideology, which accentuates rivers as symbols of territorial expansion and markers of inland regions, as opposed to the Greek tradition that emphasized coastlines.
Furthermore, a notable proportion of the keywords are place names, encompassing names of cities and islands in Indian subcontinent and its neighboring areas.
To summarize, aside from echoing the prominent themes about India found in the collocation analysis, the keyword analysis reveals two more concrete topics, namely stones and rivers, in the India-related narrative in Natural History. These topics provide additional information about the trading products and routes while also reflecting the transition of ancient Rome’s geographical ideology from Greek.
5 Conclusion
In conclusion, this paper investigates how Pliny the Elder describes India in his work, Natural History, by examining the potential themes and topics related to India. The research question is motivated by the notable frequency of references to “India” throughout the text. The analysis employs methods of collocation and keyword analysis within a corpus linguistics framework.
The exploration of textual collocates to the word “India” reveals the geographical connections, trade networks, historical figures, and scholarly references associated with India in Natural History. The collocates also emphasize India’s close relationship with neighboring regions such as Arabia and Ethiopia.
Moreover, the examination of keywords in India-related text aligns with the observations from the collocation analysis and highlights potential topics on stones and rivers about India in the work. These findings enhance the interpretation of the identified themes, such as geographical connectivity and merchandise trade, and also reflect Pliny’s general geographical concern in the historical context of ancient Rome.
As this paper serves as a preliminary exploration, it encourages further in-depth investigations of the text. A comparative analysis of collocation and keywords centering other neighboring regions to India, and a closer examination of “stone” or “river” in the context, incorporating additional literature regarding the historical and cultural background may offer greater insights and enrich the discussion.
References
Beagon, Mary. 2011. Chapter Five. The Curious Eye Of The Elder Pliny. In Pliny the Elder: Themes and Contexts, 71–88. Brill. https://brill.com/display/book/edcoll/9789004210073/Bej.9789004202344.i-248_006.xml (23 July, 2023).
Bestvater, Samuel & Sono Shah. 2022. Analyzing text for distinctive terms using pointwise mutual information. Decoded. https://www.pewresearch.org/decoded/2022/07/13/analyzing-text-for-distinctive-terms-using-pointwise-mutual-information/ (23 August, 2023).
Blume, Jeffrey D. 2017. Statistical Evidence Likelihod. statisticalevidence. https://www.statisticalevidence.com/likelihood (23 August, 2023).
Cheng, Joe, Bhaskar Karambelkar & Yihui Xie. 2023. Leaflet: Create interactive web maps with the JavaScript leaflet library. https://rstudio.github.io/leaflet/.
Dodd, Emlyn. 2021. Wine, oil, and knowledge networks across the graeco-roman cyclades: New data from paros and naxos in 2021. Mediterranean Archaeology 34/35. 155–168. https://www.jstor.org/stable/48691689.
Evert, Stefan. 2009. 58. Corpora and collocations. In Anke Lüdeling & Merja Kytö (eds.), Corpus Linguistics, 1212–1248. Mouton de Gruyter. https://doi.org/10.1515/9783110213881.2.1212. https://www.degruyter.com/document/doi/10.1515/9783110213881.2.1212/html (24 August, 2023).
Gibson, Roy & Ruth Morello (eds.). 2011. Pliny the Elder: Themes and Contexts. Brill. https://brill.com/edcollbook/title/14893.
Montes, Mariana. 2022. Methods in corpus linguistics - keywords and collocation analysis on the BASE corpus. https://mclm2022.github.io/studies/base.html.
R Core Team. 2022. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
Roller, D. W. 2022. Introduction. In A Guide to the Geography of Pliny the Elder, 1–14. Cambridge: Cambridge University Press. https://doi.org/10.1017/9781108693660.003. https://www.cambridge.org/core/books/guide-to-the-geography-of-pliny-the-elder/introduction/86CFA8A2F11A13051D01B543E3FA895B (20 July, 2023).
Speelman, Dirk & Mariana Montes. 2022. Mclm: Mastering corpus linguistics methods. https://CRAN.R-project.org/package=mclm.
Talbert, Richard J. A. 2000a. Barrington atlas of the Greek and Roman world. Princeton (N.J.): Princeton university press.
Talbert, Richard J. A. 2000b. Barrington atlas of the Greek and Roman world: Map-by-map directory. Princeton (N.J.): Princeton university press.
Wickham, Hadley. 2023. Tidyverse: Easily install and load the tidyverse. https://CRAN.R-project.org/package=tidyverse.
Zhu, Hao. 2021. kableExtra: Construct complex table with kable and pipe syntax. https://CRAN.R-project.org/package=kableExtra.
Footnotes
The present paper is a pilot study of my master thesis, Mapping India in Pliny the Elder’s Natural History, thus the description of the research question is connected with the content in this thesis.↩︎
The scraping code is uploaded to the same repository of the paper.↩︎
As indicated in the map-by-map directory, the range spans territories of “modern states of India (minus the Punjab), Bangladesh, Bhutan, Burma, Nepal, and Sri Lanka”.↩︎