class: center, middle, inverse, title-slide .title[ # Introduction and Overview ] .subtitle[ ## EC 421, Set 1 ] .author[ ### Edward Rubin ] --- class: inverse, middle # Prologue --- # Why? ## Motivation Let's start with a few __basic, general questions:__ -- 1. What is the goal of econometrics? 2. Why do economists (or other people) study or use econometrics? -- __One simple answer:__ Learn about the world using data. -- - _Learn about the world_ = Raise, answer, and challenge questions, theories, assumptions. - _data_ = Plural of datum. --- # Why? ## Example GPA is an output from endowments (ability) and hours studied (inputs). So, one might hypothesize a model `\(\text{GPA}=f(H, \text{SAT}, \text{PCT})\)` where `\(H\)` is hours studied, `\(\text{SAT}\)` is SAT score and `\(\text{PCT}\)` is the percentage of classes an individual attended. We expect that GPA will rise with each of these variables ( `\(H\)`, `\(\text{SAT}\)`, and `\(\text{PCT}\)`). But who needs to _expect_? We can test these hypotheses __using a regression model__. --- layout: true # Why? ## Example, cont. __Regression model:__ $$ \text{GPA}_i = \beta_0 + \beta_1 H_i + \beta_2 \text{SAT}_i + \beta_3 \text{PCT}_i + \varepsilon_i $$ --- We want to test estimate/test the relationship `\(\text{GPA}=f(H, \text{SAT}, \text{PCT})\)`. --- ### (Review) Questions -- - __Q:__ How do we interpret `\(\beta_1\)`? -- - __A:__ An additional hour in class correlates with a `\(\beta_1\)` unit increase in an individual's GPA (controlling for SAT and PCT). -- - __Q:__ Are the `\(\beta_k\)` terms population parameters or sample statistics? -- - __A:__ Greek letters denote __population parameters__. Their estimates get hats, _e.g._, `\(\hat{\beta}_k\)`. --- ### (Review) Questions - __Q:__ Can we interpret the estimates for `\(\beta_2\)` as causal? -- - __A:__ Not without making more assumptions and/or knowing more about the data-generating process. -- - __Q:__ What is `\(\varepsilon_i\)`? -- - __A:__ An individual's random deviation/disturbance from the population parameters. --- ### (Review) Questions - __Q:__ Which assumptions do we impose when estimating with OLS? -- - __A:__ - The relationship between the GPA and the explanatory variables is linear in parameters, and `\(\varepsilon\)` enters additively. - The explanatory variables are __exogenous__, _i.e._, `\(E[\varepsilon|X] = 0\)`. - You've also typically assumed something along the lines of:<br> `\(E[\varepsilon_i] = 0\)`, `\(E[\varepsilon_i^2] = \sigma^2\)`, `\(E[\varepsilon_i \varepsilon_j] = 0\)` for `\(i \neq j\)`. - And (maybe) `\(\varepsilon_i\)` is distributed normally. --- layout: false # Assumptions ## How important can they be? You've learned how **powerful and flexible** ordinary least squares (**OLS**) regression can be. However, the results you learned required assumptions. **Real life often violates these assumptions.** -- EC421 asks "**what happens when we violate these assumptions?**" - Can we find a fix? (Especially: How/when is `\(\beta\)` *causal*?) - What happens if we don't (or can't) apply a fix? OLS still does some amazing things—but you need to know when to be **cautious, confident, or dubious**. --- # Not everything is causal <img src="slides_files/figure-html/spurious-1.svg" style="display: block; margin: auto;" /> --- # Econometrics An applied econometrician<sup>†</sup> needs a solid grasp on (at least) three areas: 1. The __theory__ underlying econometrics (assumptions, results, strengths, weaknesses). 1. How to __apply theoretical methods__ to actual data. 1. Efficient methods for __working with data__—cleaning, aggregating, joining, visualizing. .footnote[ [†]: _Applied econometrician_ .mono[=] Practitioner of econometrics, _e.g._, analyst, consultant, data scientist. ] -- __This course__ aims to deepen your knowledge in each of these three areas. -- - 1: As before. - 2–3: __R__ --- class: inverse, middle # R --- layout: true # R --- ## What is R? To quote the [R project website](https://www.r-project.org): > R is a free software environment for statistical computing and graphics. It compiles and runs on a wide variety of UNIX platforms, Windows and MacOS. -- What does that mean? - R was created for the statistical and graphical work required by econometrics. - R has a vibrant, thriving online community. ([stack overflow](https://stackoverflow.com/questions/tagged/r)) - Plus it's __free__ and __open source__. --- ## Why are we using R? 1\. R is __free__ and __open source__—saving both you and the university 💰💵💰. 2\. _Related:_ Outside of a small group of economists, private- and public-sector __employers favor R__ over .mono[Stata] and most competing softwares. 3\. R is very __flexible and powerful__—adaptable to nearly any task, _e.g._, 'metrics, spatial data analysis, machine learning, web scraping, data cleaning, website building, teaching. My website, the TWEEDS website, and these notes all came out of R. --- ## Why are we using R? 4\. _Related:_ R imposes __no limitations__ on your amount of observations, variables, memory, or processing power. (I'm looking at __you__, .mono[Stata].) 5\. If you put in the work,<sup>†</sup> you will come away with a __valuable and marketable__ tool. 6\. I 💖 __R__ .footnote[ [†]: Learning R definitely requires time and effort. ] --- <img src="slides_files/figure-html/statistical languages-1.svg" style="display: block; margin: auto;" /> --- layout: false class: inverse, middle # R + Examples --- # R + Regression ``` r # A simple regression *fit <- lm(dist ~ 1 + speed, data = cars) # Show the coefficients coef(summary(fit)) ``` ``` #> Estimate Std. Error t value Pr(>|t|) #> (Intercept) -17.579095 6.7584402 -2.601058 1.231882e-02 #> speed 3.932409 0.4155128 9.463990 1.489836e-12 ``` ``` r # A nice, clear table library(broom) tidy(fit) ``` ``` #> # A tibble: 2 × 5 #> term estimate std.error statistic p.value #> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 (Intercept) -17.6 6.76 -2.60 1.23e- 2 #> 2 speed 3.93 0.416 9.46 1.49e-12 ``` --- # R + Plotting (w/ .mono[plot]) <img src="slides_files/figure-html/example: plot-1.svg" style="display: block; margin: auto;" /> --- # R + Plotting (w/ .mono[plot]) ``` r # Load packages with dataset library(gapminder) # Create dataset plot( x = gapminder$gdpPercap, y = gapminder$lifeExp, xlab = "GDP per capita", ylab = "Life Expectancy" ) ``` --- # R + Plotting (w/ .mono[ggplot2]) <img src="slides_files/figure-html/example: ggplot2 v1-1.svg" style="display: block; margin: auto;" /> --- # R + Plotting (w/ .mono[ggplot2]) ``` r # Load packages library(gapminder); library(dplyr) # Create dataset ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp)) + geom_point(alpha = 0.75) + scale_x_continuous("GDP per capita", label = scales::comma) + ylab("Life Expectancy") + theme_pander(base_size = 16) ``` --- # R + More plotting (w/ .mono[ggplot2]) <img src="slides_files/figure-html/example: ggplot2 v2-1.svg" style="display: block; margin: auto;" /> --- # R + More plotting (w/ .mono[ggplot2]) ``` r # Load packages library(gapminder); library(dplyr) # Create dataset ggplot( data = filter(gapminder, year %in% c(1952, 2002)), aes(x = gdpPercap, y = lifeExp, color = continent, group = country) ) + geom_path(alpha = 0.25) + geom_point(aes(shape = as.character(year), size = pop), alpha = 0.75) + scale_x_log10("GDP per capita", label = scales::comma) + ylab("Life Expectancy") + scale_shape_manual("Year", values = c(1, 17)) + scale_color_viridis("Continent", discrete = T, end = 0.95) + guides(size = F) + theme_pander(base_size = 16) ``` --- # R + Animated plots (w/ .mono[gganimate]) .center[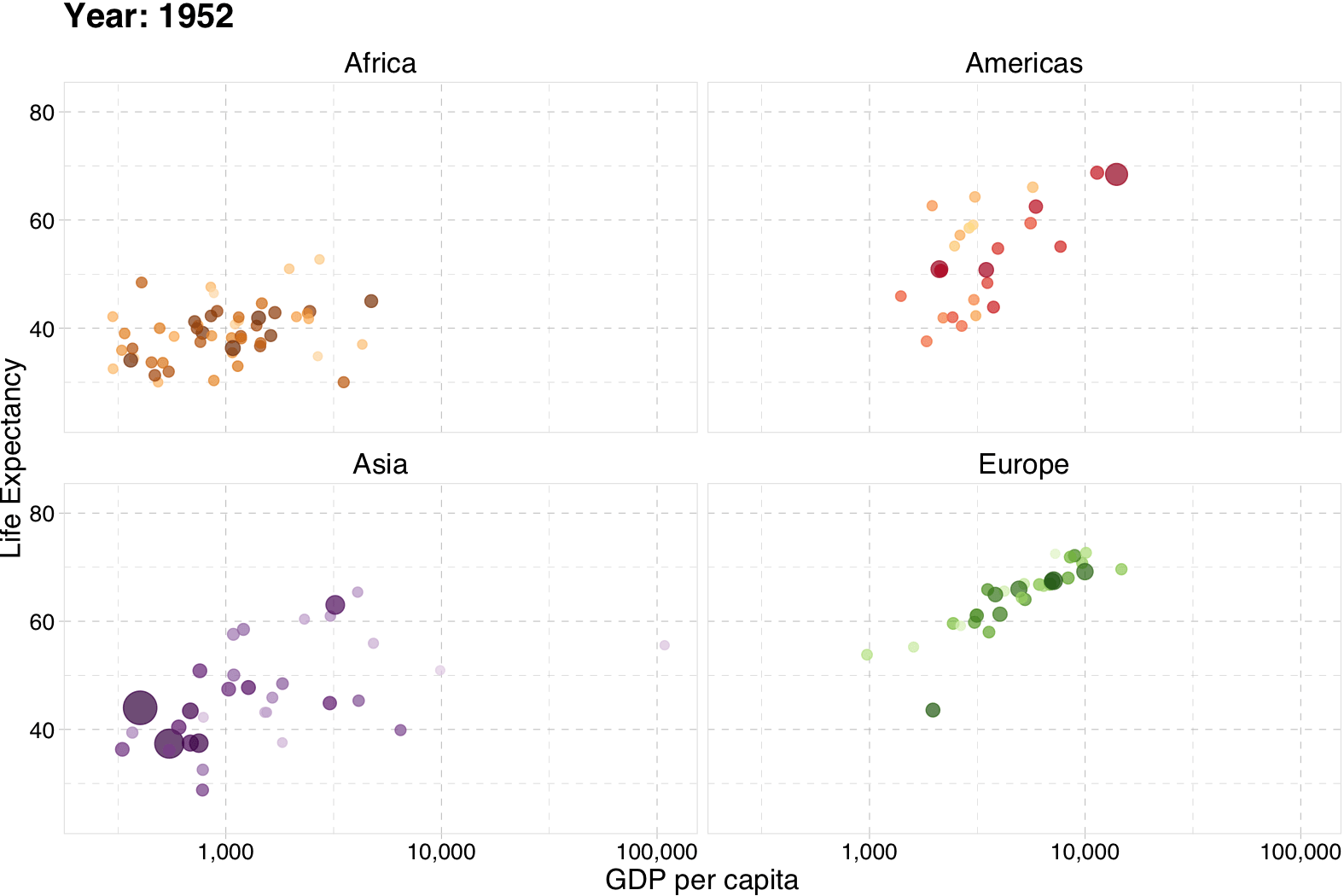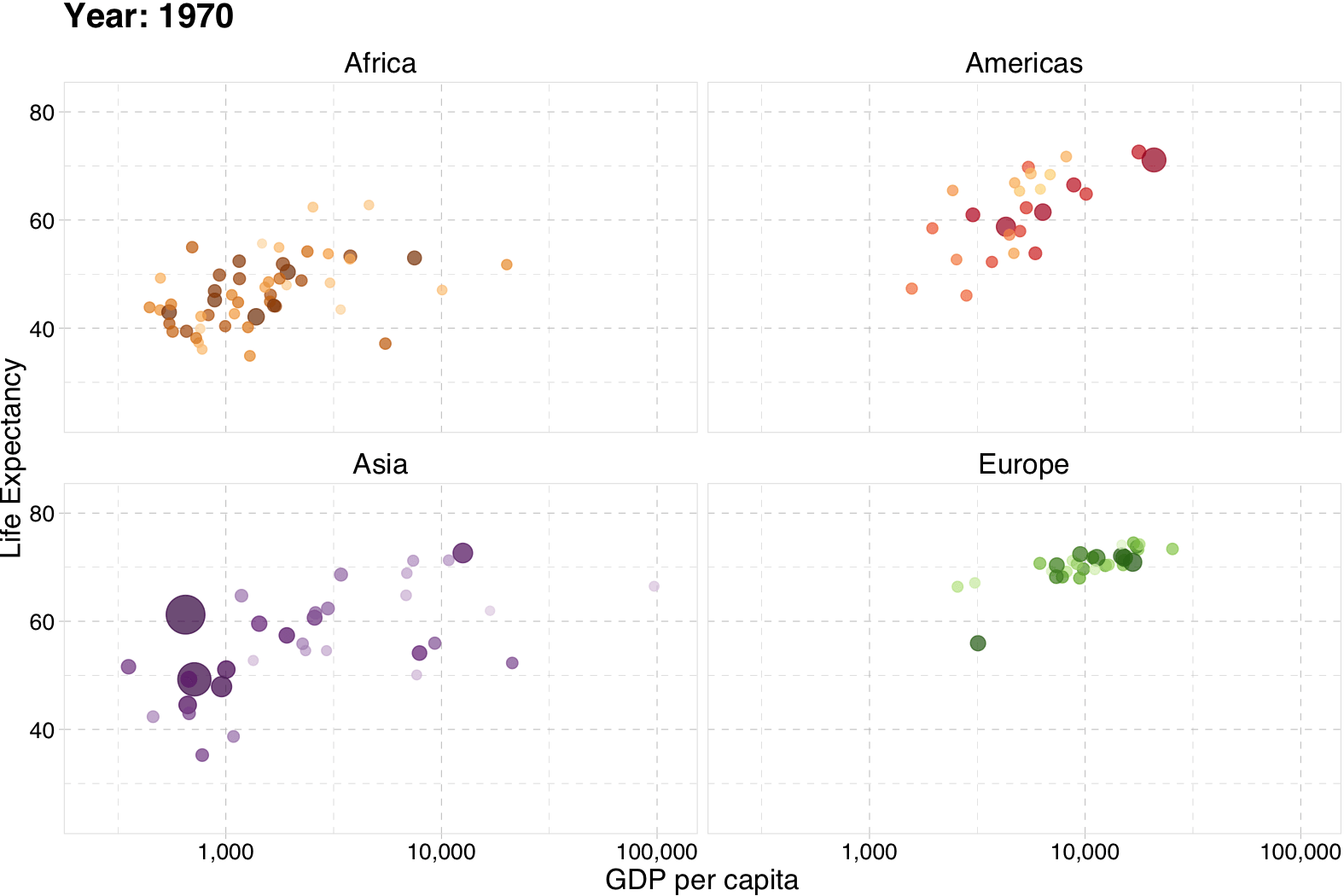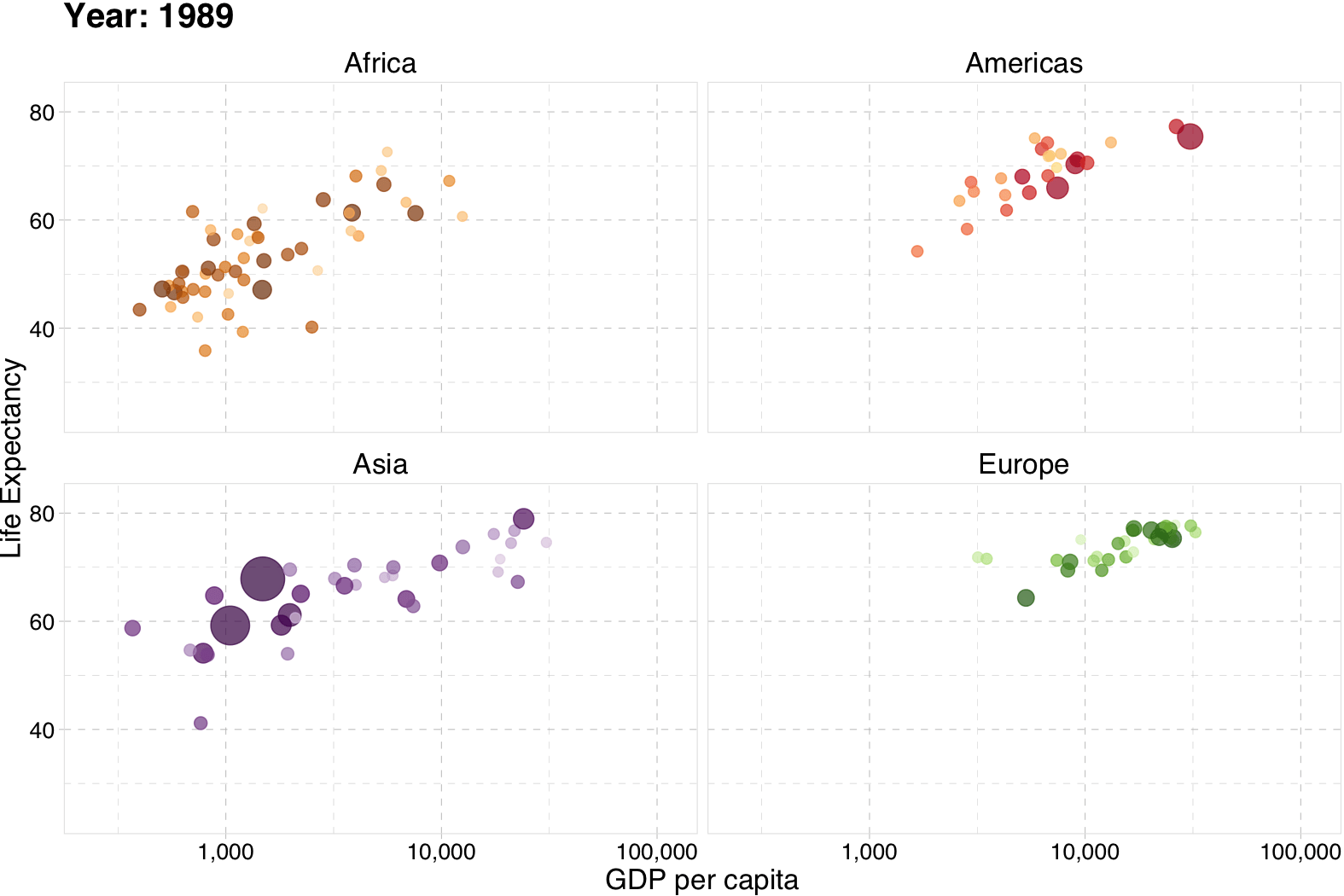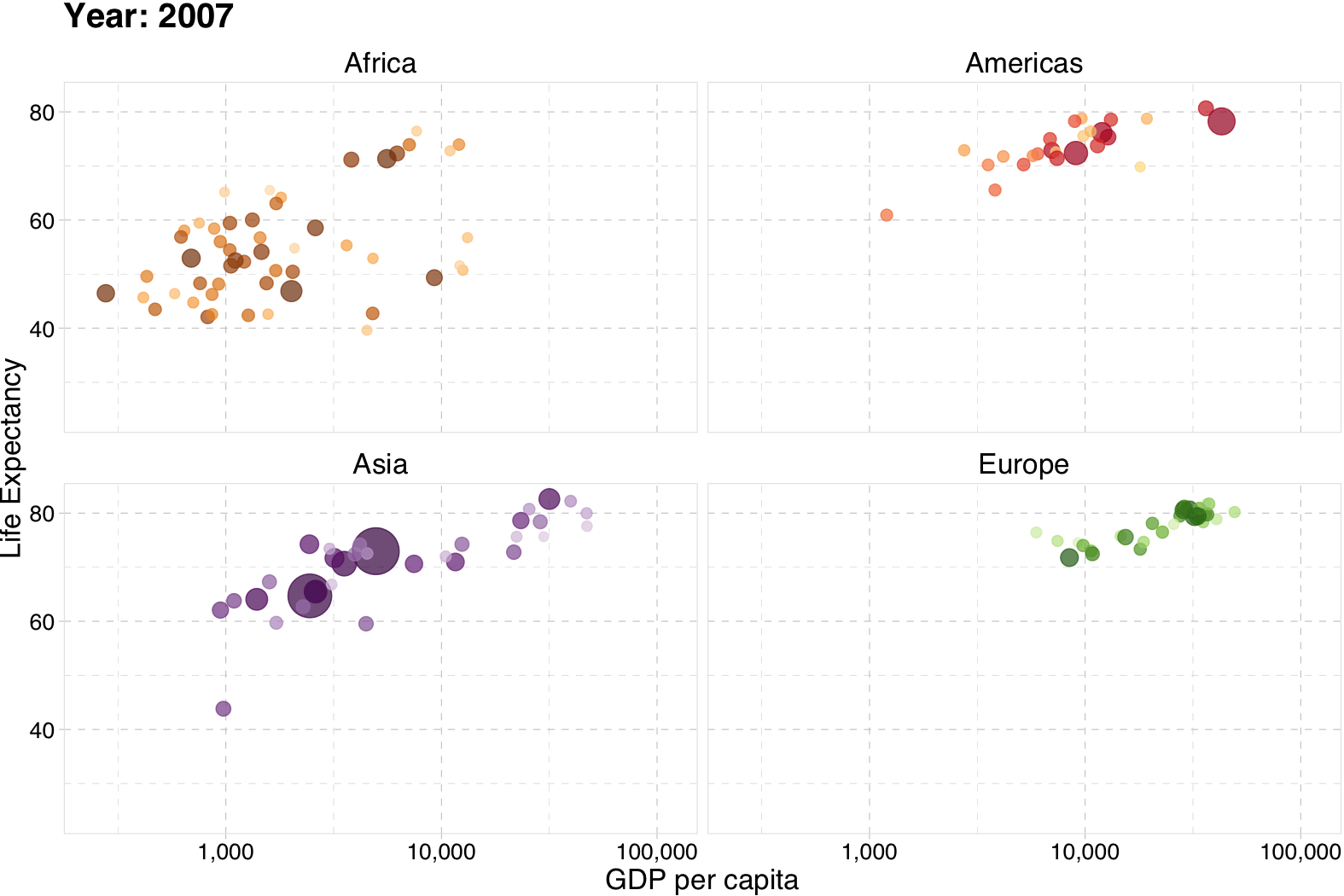] --- # R + Animated plots (w/ .mono[gganimate]) ``` r # The package for animating ggplot2 library(gganimate) # As before ggplot( data = gapminder %>% filter(continent != "Oceania"), aes(gdpPercap, lifeExp, size = pop, color = country) ) + geom_point(alpha = 0.7, show.legend = FALSE) + scale_colour_manual(values = country_colors) + scale_size(range = c(2, 12)) + scale_x_log10("GDP per capita", label = scales::comma) + facet_wrap(~continent) + theme_pander(base_size = 16) + theme(panel.border = element_rect(color = "grey90", fill = NA)) + # Here comes the gganimate-specific bits labs(title = "Year: {frame_time}") + ylab("Life Expectancy") + transition_time(year) + ease_aes("linear") ``` --- # R + Maps ``` r library(leaflet) leaflet() %>% addTiles() %>% addMarkers(lng = -123.075, lat = 44.045, popup = "The University of Oregon") ``` <div class="leaflet html-widget html-fill-item" id="htmlwidget-dfe0f284012baa0312c3" style="width:756px;height:432px;"></div> <script type="application/json" data-for="htmlwidget-dfe0f284012baa0312c3">{"x":{"options":{"crs":{"crsClass":"L.CRS.EPSG3857","code":null,"proj4def":null,"projectedBounds":null,"options":{}}},"calls":[{"method":"addTiles","args":["https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png",null,null,{"minZoom":0,"maxZoom":18,"tileSize":256,"subdomains":"abc","errorTileUrl":"","tms":false,"noWrap":false,"zoomOffset":0,"zoomReverse":false,"opacity":1,"zIndex":1,"detectRetina":false,"attribution":"© <a href=\"https://openstreetmap.org/copyright/\">OpenStreetMap<\/a>, <a href=\"https://opendatacommons.org/licenses/odbl/\">ODbL<\/a>"}]},{"method":"addMarkers","args":[44.045,-123.075,null,null,null,{"interactive":true,"draggable":false,"keyboard":true,"title":"","alt":"","zIndexOffset":0,"opacity":1,"riseOnHover":false,"riseOffset":250},"The University of Oregon",null,null,null,null,{"interactive":false,"permanent":false,"direction":"auto","opacity":1,"offset":[0,0],"textsize":"10px","textOnly":false,"className":"","sticky":true},null]}],"limits":{"lat":[44.045,44.045],"lng":[-123.075,-123.075]}},"evals":[],"jsHooks":[]}</script> --- class: inverse, middle # Getting started with R --- layout: true # Starting R --- ## Installation - Install [R](https://www.r-project.org/). - Install [.mono[RStudio]](https://www.rstudio.com/products/rstudio/download/preview/). - __Optional/Overkill:__ [Git](https://git-scm.com/downloads) - Create an account on [GitHub](https://github.com/) - Register for a student/educator [discount](https://education.github.com/discount_requests/new). - For installation guidance and troubleshooting, check out Jenny Bryan's [website](http://happygitwithr.com/). - __Note:__ The lab in 442 McKenzie has R installed and ready. That said, having a copy of R on your own computer will likely be very convenient for homework, projects, _etc._ --- ## Resources ### Free(-ish) - Google (which inevitably leads to StackOverflow) - Time - Your classmates - Your GEs - Me - R resources [here](http://edrub.in/ARE212/resources.html) and [here](https://www.rstudio.com/online-learning/) ### Money - Book: [_R for Stata Users_](http://r4stats.com/books/r4stata/) - Short online course: [DataCamp](https://www.datacamp.com) --- ## Some R basics You will dive deeper into R in lab, but here six big points about R: .more-left[ 1. Everything is an __object__. 1. Every object has a __name__ and __value__. 1. You use __functions__ on these objects. 1. Functions come in __libraries__ (__packages__) 1. R will try to __help__ you. 1. R has its __quirks__. ] .less-right[ `foo` `foo <- 2` `mean(foo)` `library(dplyr)` `?dplyr` `NA; error; warning` ] --- ## R _vs._ .mono[Stata] Coming from .mono[Stata], here are a few important changes (benefits): - Multiple objects and arrays (_e.g._, data frames) can exist in the same workspace (in memory). No more `keep`, `preserve`, `restore`, `snapshot` nonsense! - (Base) R comes with lots of useful built-in functions—and provides all the tools necessary for you to build your own functions. However, many of the _best_ functions come from external libraries. - You don't need to `tset` or `xtset` data (you can if you really want... `ts`). --- layout: false class: inverse, middle # Next: Metrics review(s) --- exclude: true