Windows: there’s WSL2 and it works great (really!)
Automation
Write a single script that executes all code from beginning to end
It’s the ideal goal for replication packages
Have a script like this from the beginning of the project and increment it as you go
But don’t obsess over it. Sometimes it can’t be done
E.g.: you are running part of your code on an external server
Automation + replicability
An extra rule: Keep track of your dependencies
We often use many external packages
Popular packages get updated often. Sometimes it breaks things…
The syntax you used doesn’t work anymore
The function you called doesn’t exist anymore
Keep note (and backups) of the versions you use
There are many tools to help you with that
Some are simpler and just track that info for you (e.g.: Julia project, R renv)
Others create a stand-alone environment with everything you need to run (e.g.: Docker)
Organization
Directories
Separate directories by function
Separate files into inputs and outputs
These are quite intuitive: they make it easy for you (your code) and anyone else to find things
Separating inputs, intermediate outputs (temp), and final outputs is crucial for storing the right things
We normally don’t use version control for intermediate calculations
Directories
Have separate folders for
Code
Data
Output
I also use separate sub-folders for tables, figures, & maps
Text (e.g. LaTeX files)
\(\uparrow\)This is from a working paper
Directories
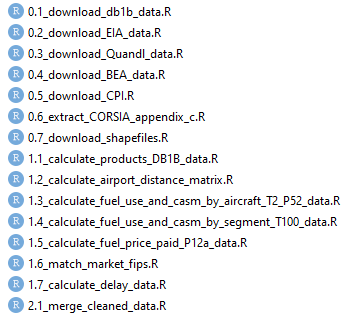
For long scripts that do many steps in sequence, like building a data set, it is also a good practice to number your scripts
Directories
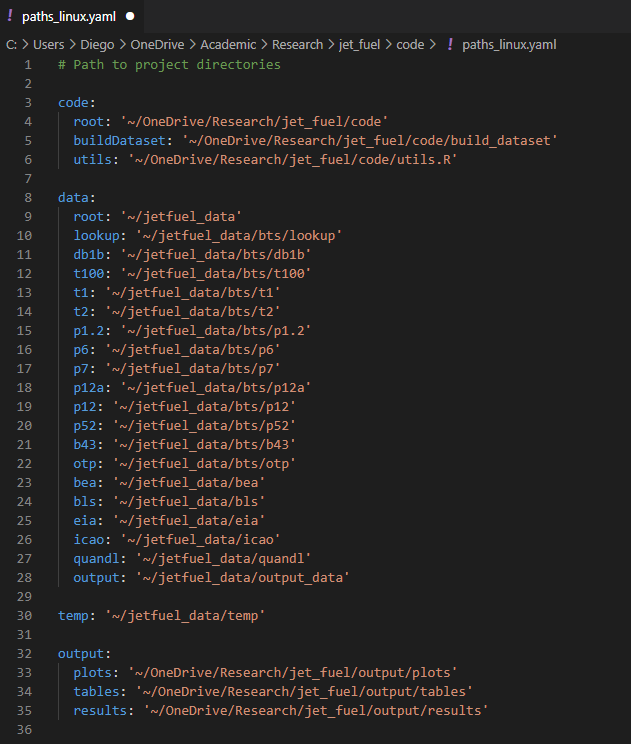
Make directories portable
In other words: use relative paths. Or don’t hard-code your paths
Instead of
C:/User/me/my_research/data/my_data_file.csv
use a relative path like this
data/my_data_file.csv
Directories
It’s not always possible to have relative paths everywhere
In that case, you can define all the paths in one single place and read it from there every time
But there are many packages to care of that for you (e.g., package here for R)
Project management
Before we continue…
By now you hopefully have
GitHub Desktop installed on your laptop
A GitHub account (and sent me your username)
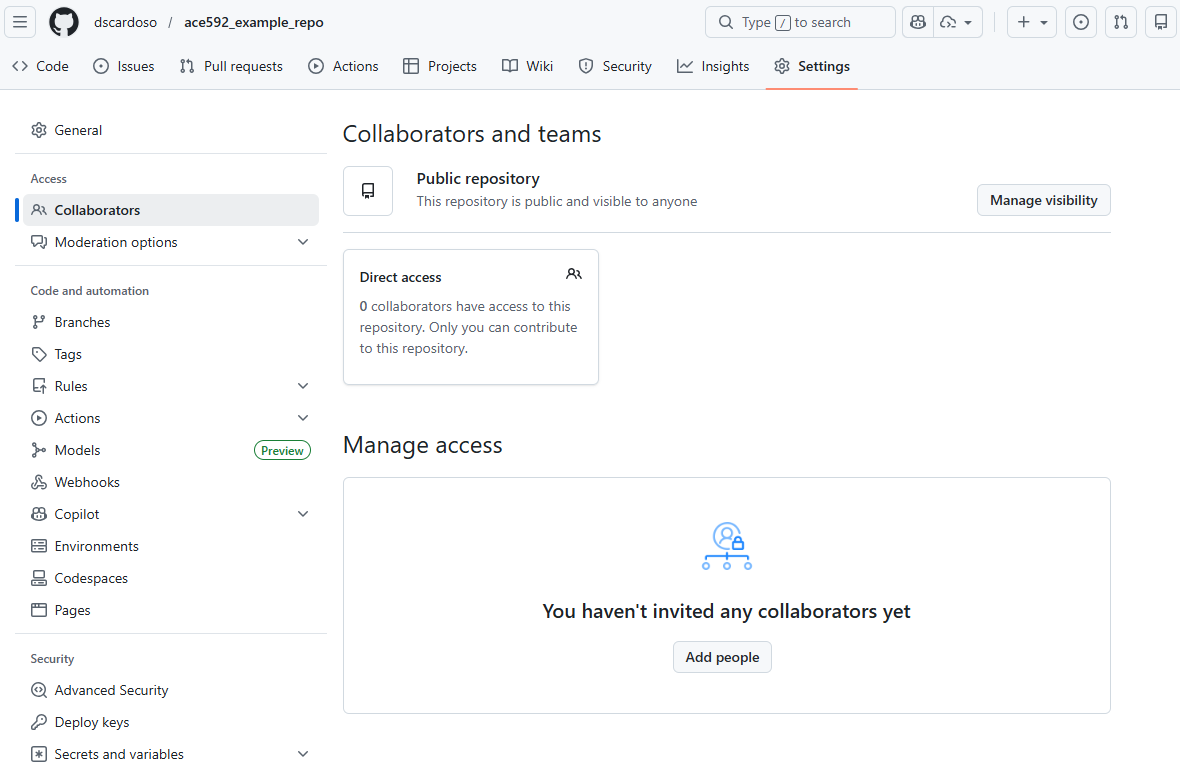
After class, please:
Watch out for an invitation for our GitHub Classroom repository
Accept the invitation
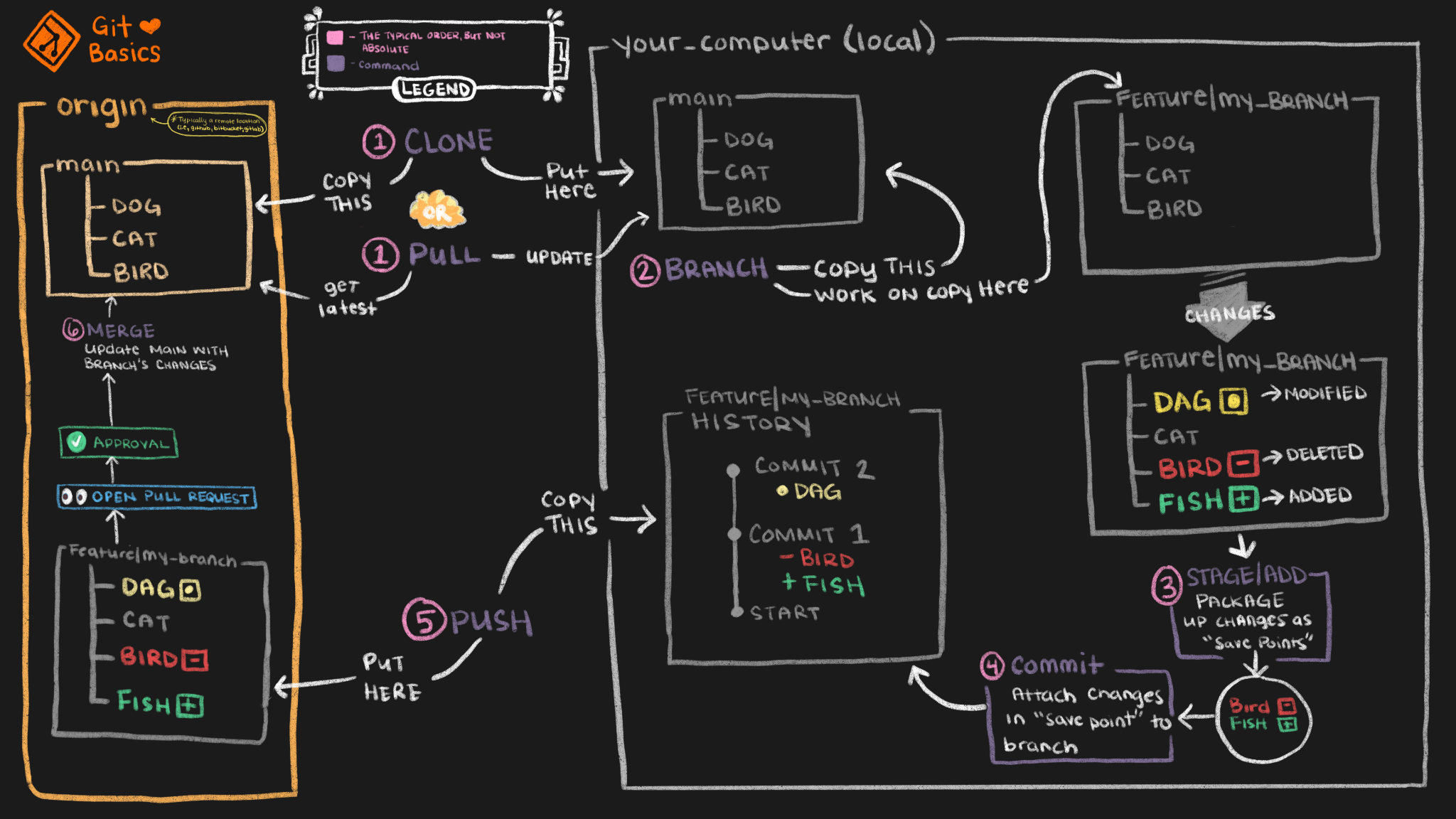
Version Control: why bother?
Git
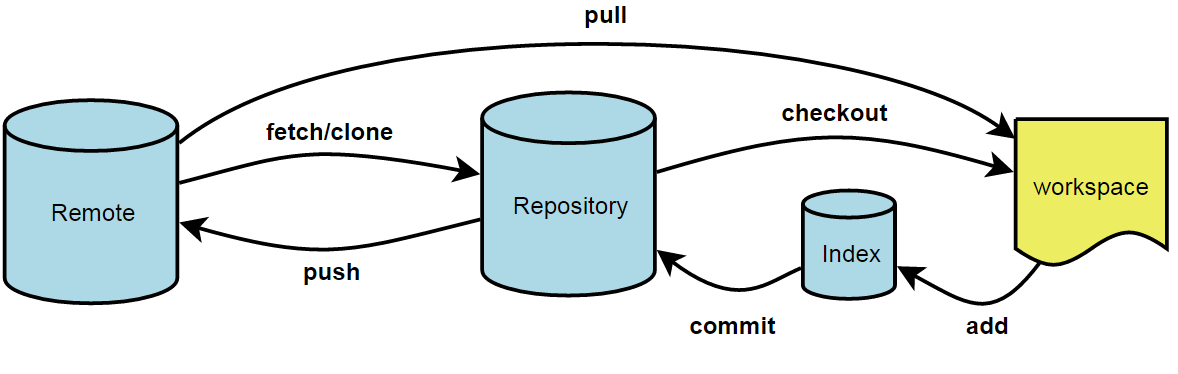
Git is a distributed version control system
Imagine if Dropbox and the “Track changes” feature in MS Word had a baby. Git would be that baby
In fact, it’s even better than that because Git is optimized for the things that economists spend a lot of time working on (e.g. code)
It gives you an easy way to test experimental changes (e.g. new specifications, additional model states) and not have them mess with your main code
GitHub
Git\(\neq\)GitHub
GitHub hosts a bunch of online services we want when using Git
Hosts a copy of your repository online
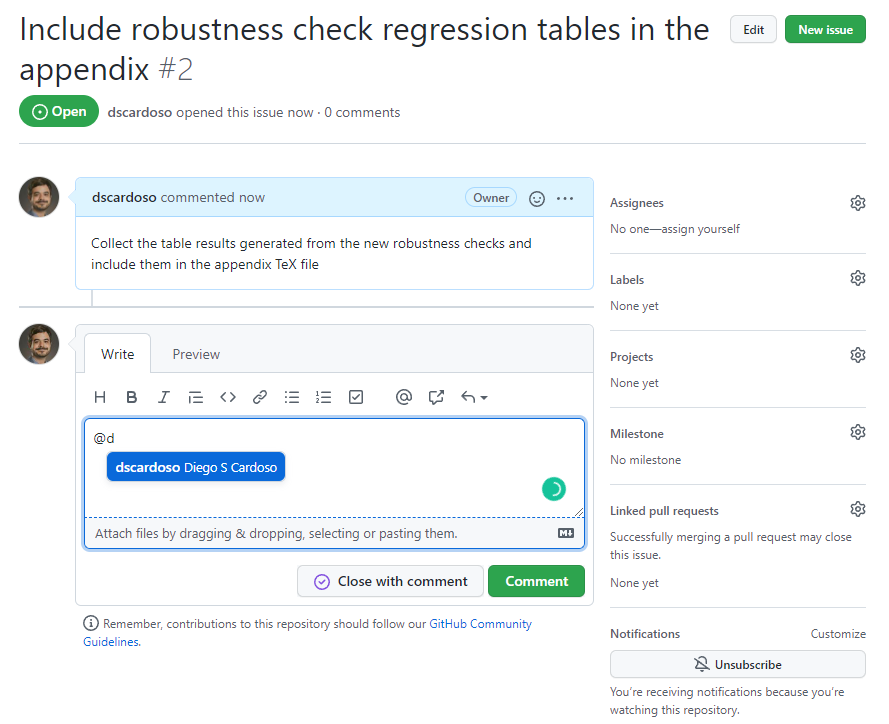
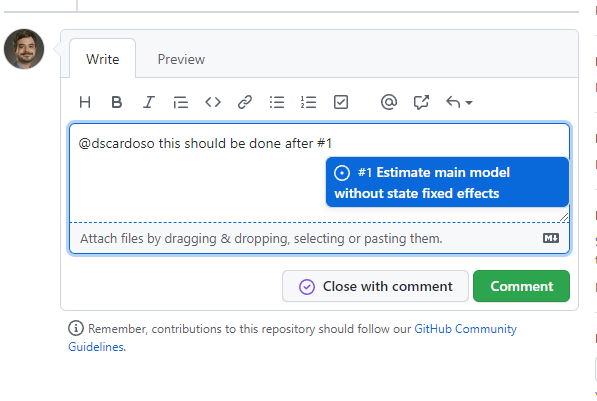
Allows for people to suggest changes to your project
Keeps track of team communication on tasks
And even let’s you host some related content (like these slides!)
You can even program and run your code on GitHub Codespaces
It’s also the main location for non-base Julia (and R) packages to be stored and developed
The differences
Git is the software infrastructure for versioning and merging files
GitHub provides an online service to coordinate working with Git repositories
And adds some additional features for managing projects
Stores the project on the cloud, allows for task management, creation of groups, etc
Why Git(Hub)?
Selfish reasons
The private benefits of having well-versioned code in case you need to go back to previous stages
Your directories will be super clean
Makes it MUCH easier to collaborate on projects
Why Git(Hub)?
Semi-altruistic reasons
The external benefits of open science, collaboration, etc
These external benefits also generate some downstream private reputational benefits
You must be confident in your code to make it public
Can improve future social efficiency
You commit to post future code (if you don’t, it’ll look shady)
Git basics
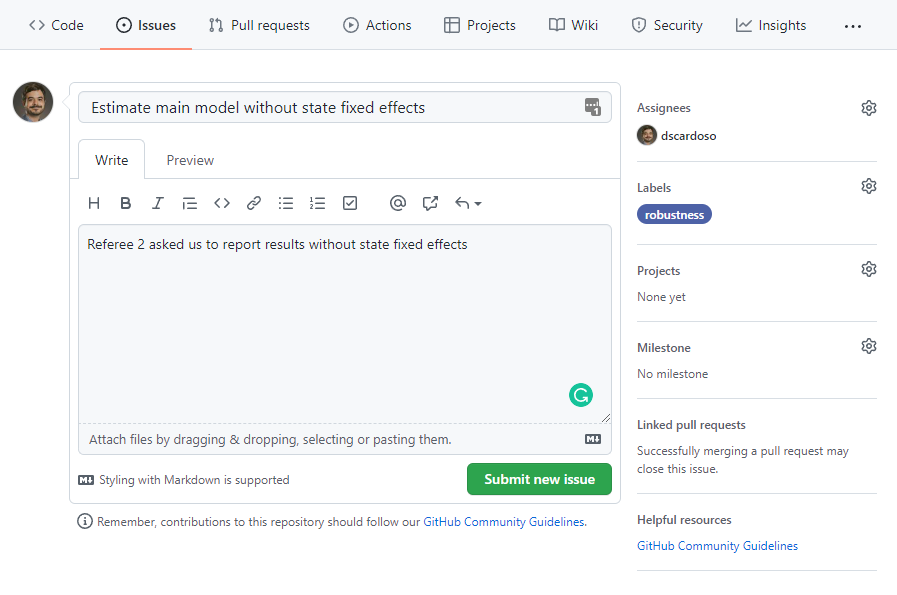
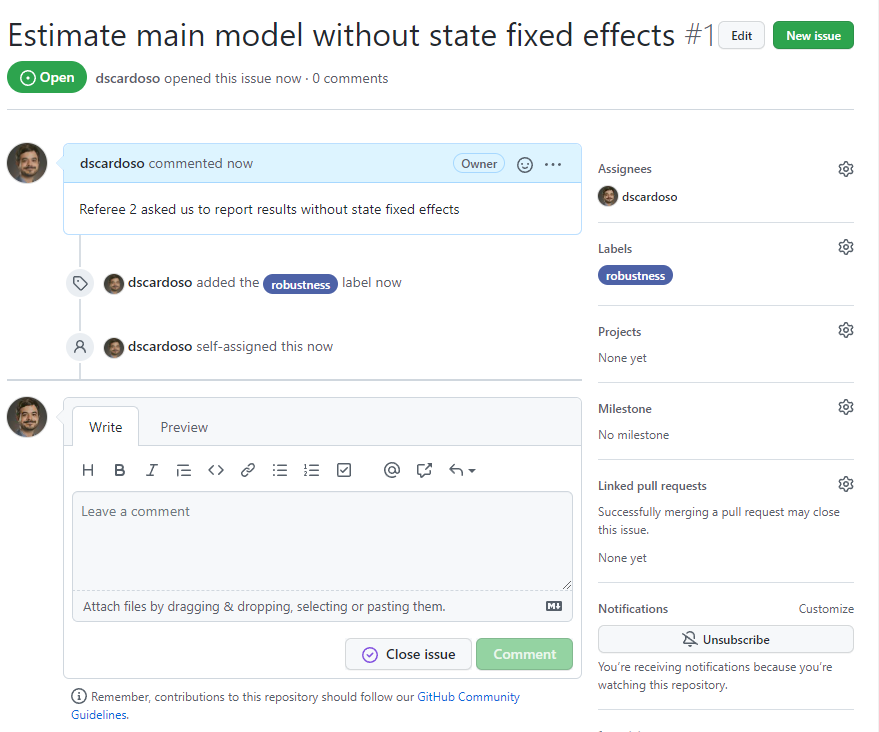
Everything on Git is stored in something called a repository or repo for short. This is the directory for a project
Local: a directory with a .git subdirectory that stores the history of changes to the repository
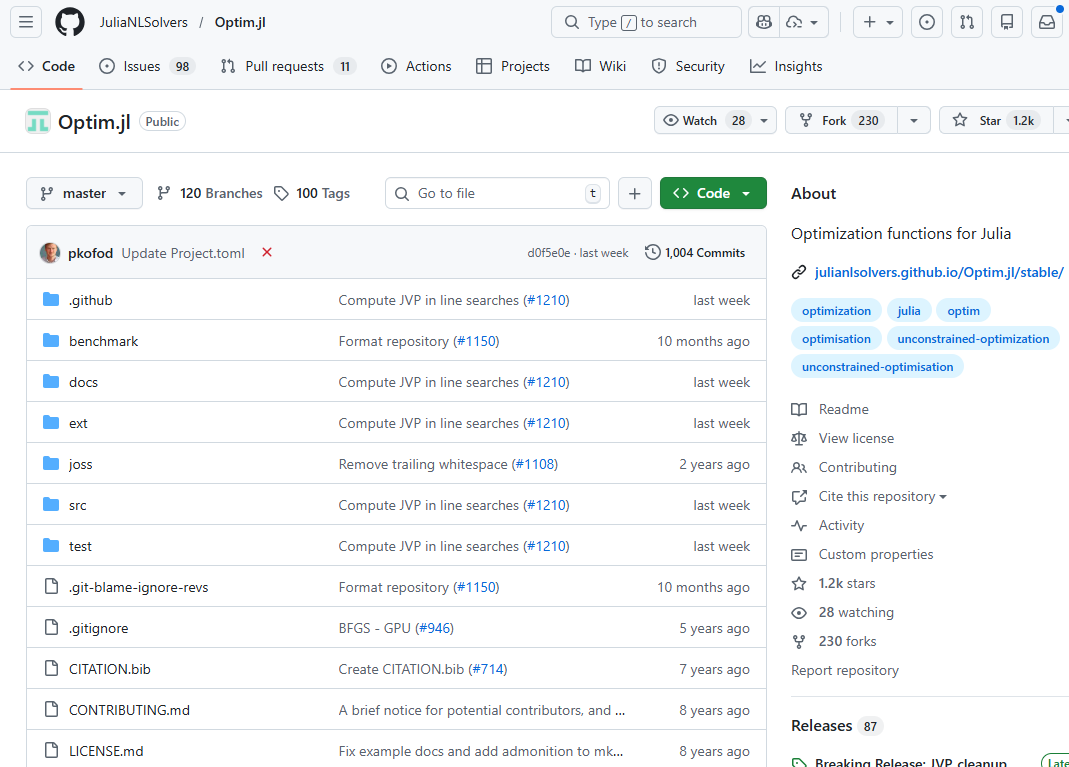
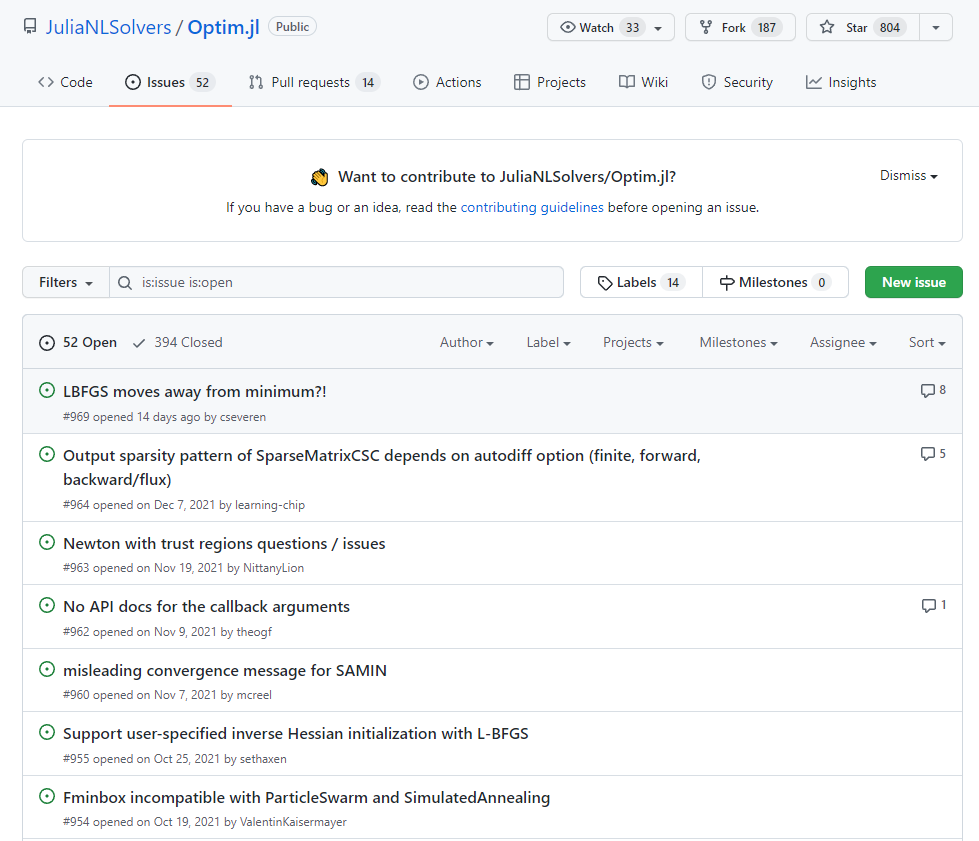
Remote: a website, e.g. see the GitHub repo for the Optim package in Julia
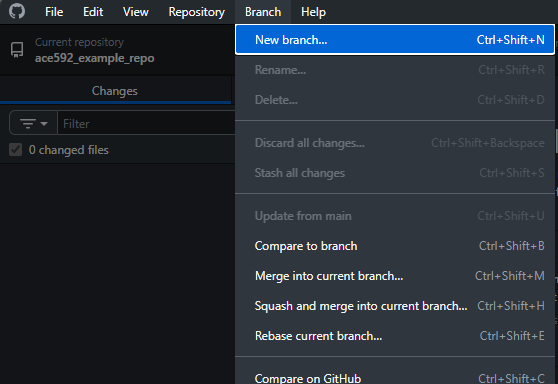
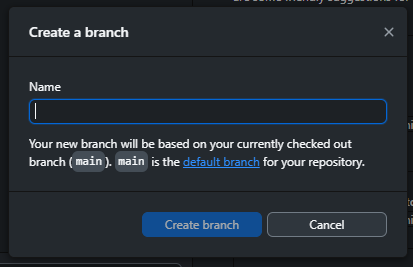
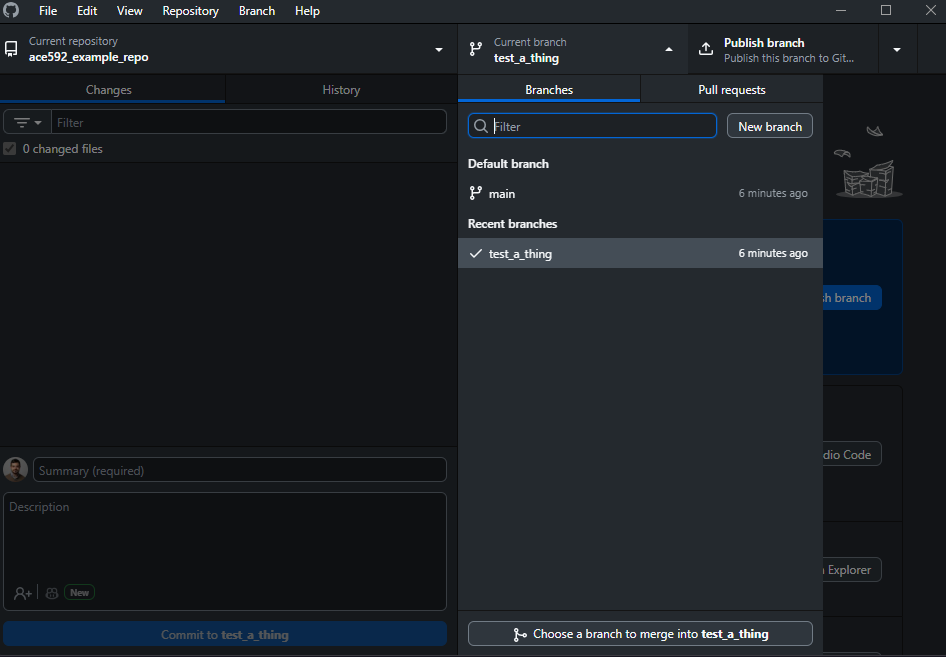
Git basics
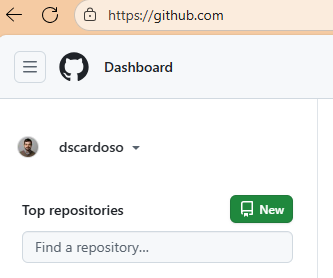
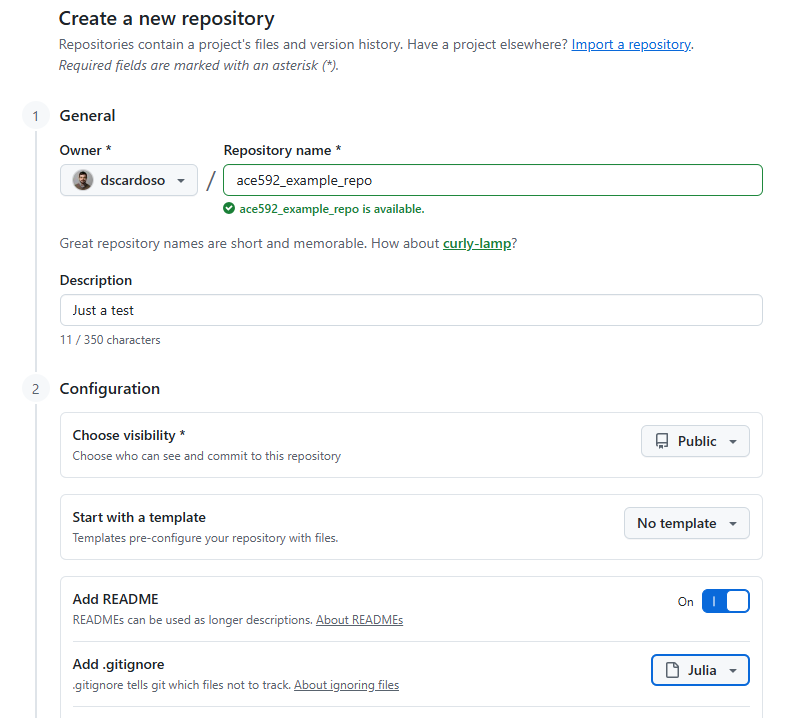
Creating a new repo on GitHub
Let’s create a new repo
Easy from GitHub website: just click on that green New button from the launch page
Creating a new repo on GitHub
Next steps:
Choose a name
Choose a description
Choose whether the repo is public or private
Choose whether you want to add a README.md (yes), or a .gitignore or a LICENSE.md file (more next slide)
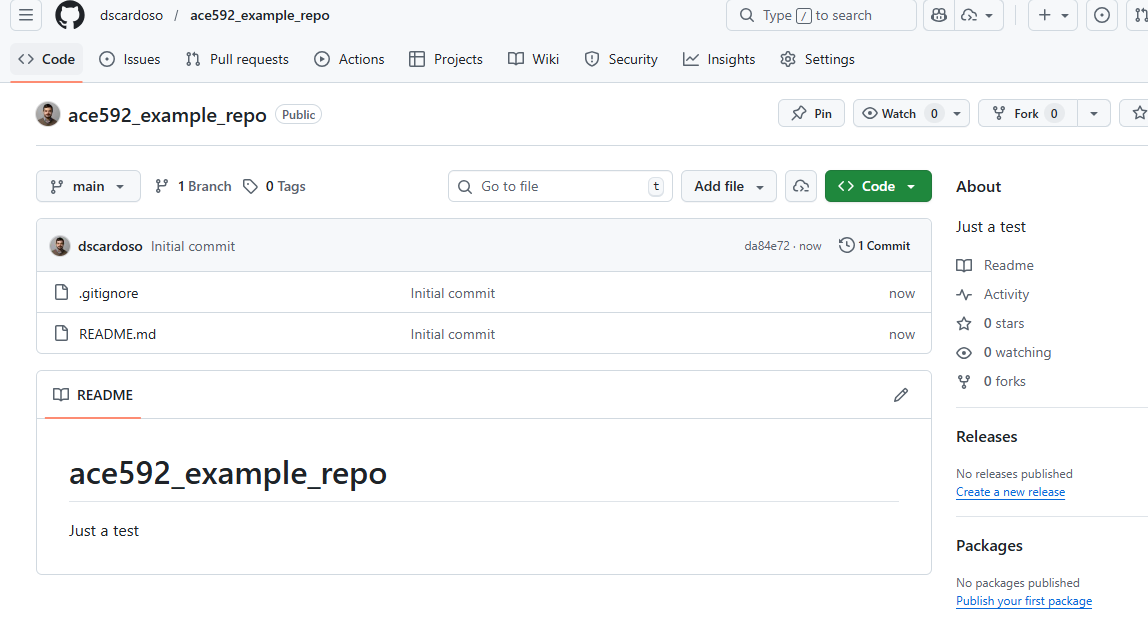
Creating a new repo on GitHub
Creating a new repo on GitHub
Repos come with some common files in them
.gitignore: lists files/directories/extensions that Git shouldn’t track (raw data, restricted data, those weird LaTeX by-product files). This is usually a good idea
README.md: a Markdown file that is basically the welcome content on repo’s GitHub website. You should generally initialize a repo with one of these
LICENSE.md: describes the license agreement for the repository
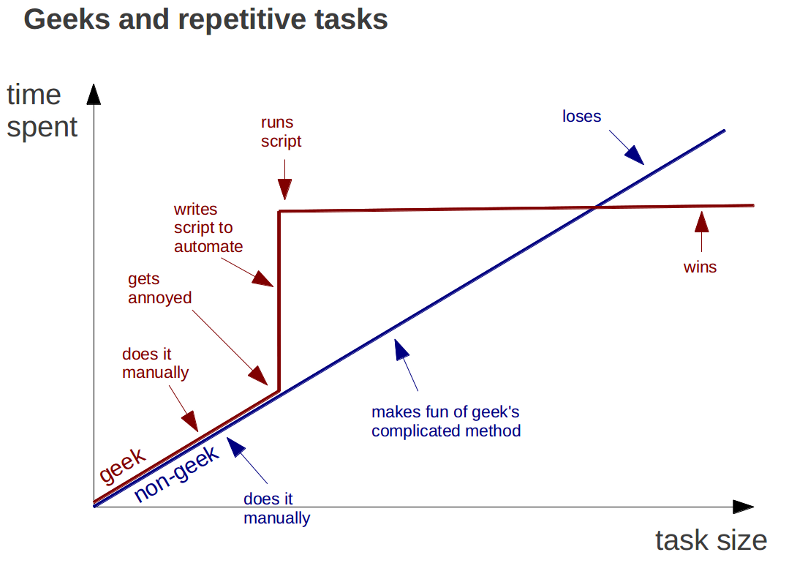
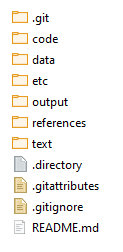 \(\uparrow\) This is from a working paper
\(\uparrow\) This is from a working paper