Introduction to Dask and the Open Data Cube 
Prerequisites: This material assumes basic knowledge of the Open Data Cube, Xarray and numerical processing using numpy.
The Open Data Cube library is written in Python and makes extensive use of scientific and geospatial libraries. For the purposes of this tutorial we will primarily consider five libraries:
datacube- EO datacubexarray- labelled arrays- (optional)
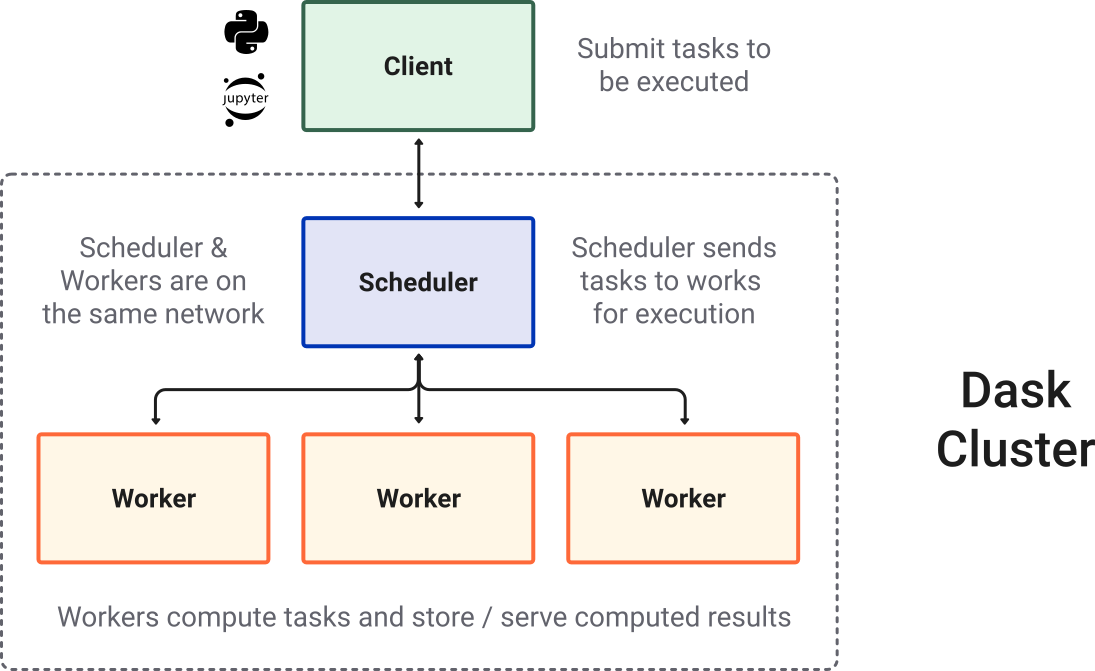
dask&distributed- distributed parallel programming numpy- numerical array processing with vectorisation- (optional)
numba- a library for high performance python
Whilst the interrelations are intimate it is useful to conceptualise them according to their primary role and how these roles build from low level numerical array processing (numpy) through to high-level EO datacube semantics (datacube and xarray). If you prefer, viewed from top to bottom we can say:
datacube.load()does the necessary file IO and data manipulation to construct a...xarraywhich will be labelled with the necessary coordinate systems and band names and made up of...- (optionally)
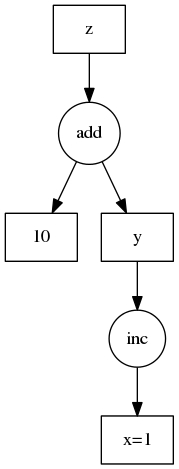
dask.arrays which contain manychunkswhich are... numpyarrays containing the actual data values.
Each higher level of abstraction thus builds on the lower level components that perform the actual storage and computation.
Overlaid on this are libraries like numba, dask and distributed that provide computational components that can accelerate and distribute processing across multiple compute cores and computers. The use of dask, distributed and numba are optional - not all applications require the additional complexity of these tools.
Planning and writing efficient applications¶
Achieving performance and scale requires an understanding of the performance of each library and how it interacts with the others. Moreover, and often counterintuitively, adding more compute cores to a problem may not make it faster; in fact it may slow down (as well as waste resources). Added to that is the deceptive simplicity in that some of the tools can be simply turned on with only a few code changes and significant performance increases can be achieved.
However, as the application is scaled or an alternative algorithm is used further challenges may arise, in expected I/O or compute efficiency, that require code refactors and changes in algorithmic approach. These challenges can seem to undo some of the earlier work and be frustrating to address.
The good news is whilst there is complexity (six interrelated libraries mentioned so far), there are common concepts and techniques involved in analysing how to optimise your algorithm. If you know from the start your application is going to require scale, then it does help to think in advance where you are heading.
What you will learn¶
This course will equip readers with concepts and techniques they can utilise in their algorithm and workflow development. The course will be using computer science terms and a variety of libraries but won't be discussing these in detail in order to keep this course concise. The focus will be on demonstration by example and analysis techniques to identify where to focus effort. The reader is encouraged to use their favorite search engine to dig deeper when needed; there are a lot of tutorials online!
One last thing, in order to maintain a healthy state of mind for "Dask and ODC", the reader is encouraged to hold both of these truths in mind at the same time:
- The best thing about dask is it makes distributed parallel programming in the datacube easy
- The worst thing about dask it is makes distributed parallel programming in the datacube easy
Yep, that's contradictory! By the end of this course, and a couple of your own adventures, you will understand why.