SICSS, 2022
Christopher Barrie
library(dplyr) library(readr) library(stringr) library(rvest) url <- "https://wayback.archive-it.org/2358/20120130161341/http://www.tahrirdocuments.org/2011/03/voice-of-the-revolution-3-page-2/" html <- read_html(url)
# identify relevant text html %>% html_elements("p") %>% html_text(trim=TRUE)
# identify relevant text html %>% html_elements(".calendar") %>% html_text(trim=TRUE)
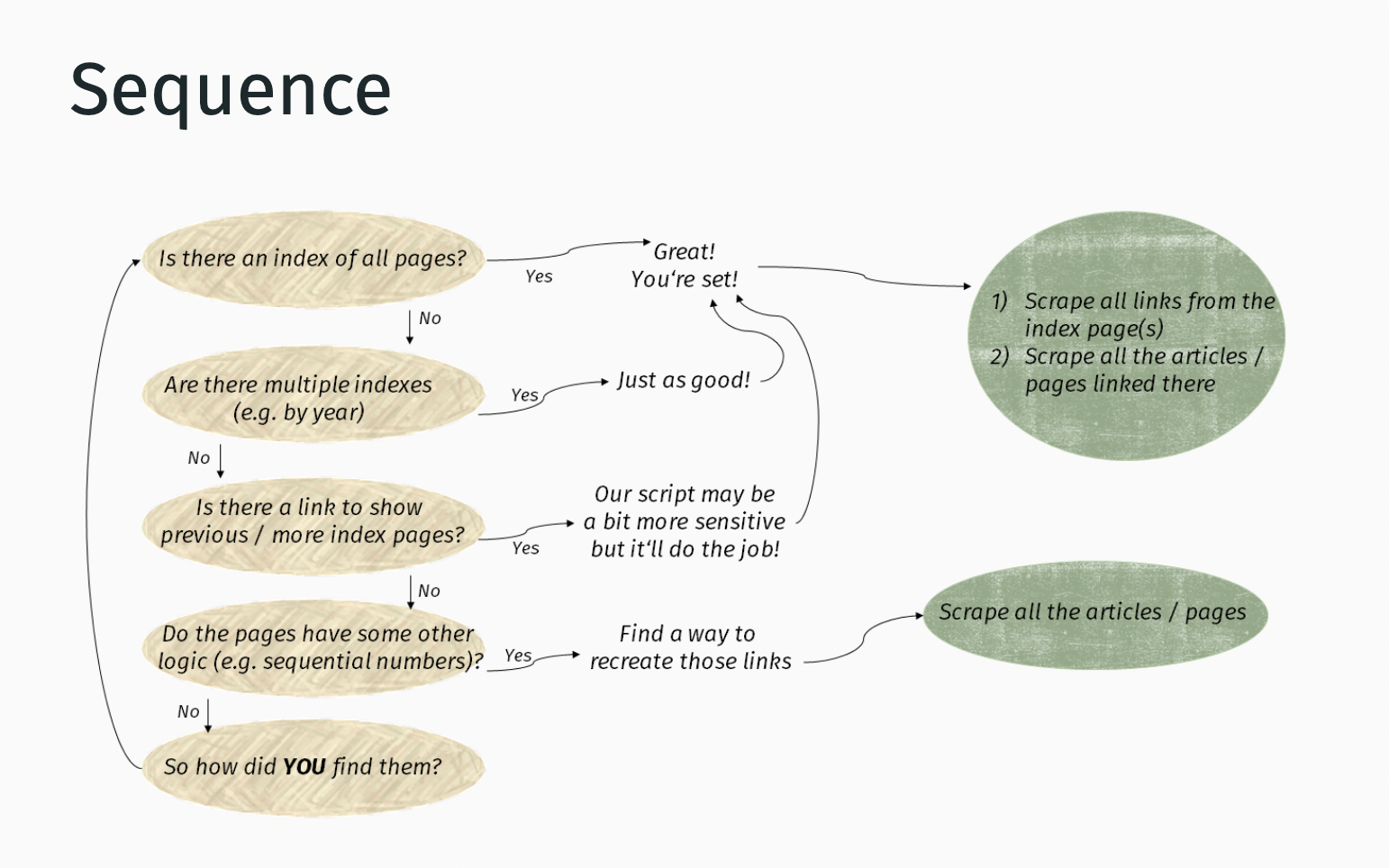
pamlinks_all <- character(0) for (i in seq_along(urlpages_all)) { url <- urlpages_all[i] html <- read_html(url) links <- html_elements(html, ".post , h2") %>% html_children() %>% html_attr("href") %>% na.omit() %>% `attributes<-`(NULL) pamlinks_all <- c(pamlinks_all, links) }
Figure 1: http://theresagessler.eu/eui_cta/slides/session5_plus.pdf