WINDOW_SIZE <- 6
DIM <- 300
ITERS <- 100
glove <- GlobalVectors$new(rank = DIM,
x_max = 100,
learning_rate = 0.05)
wv_main <- glove$fit_transform(toks_fcm, n_iter = ITERS,
convergence_tol = 1e-3,
n_threads = parallel::detectCores()) # set to 'parallel::detectCores()' to use all available cores
wv_context <- glove$components
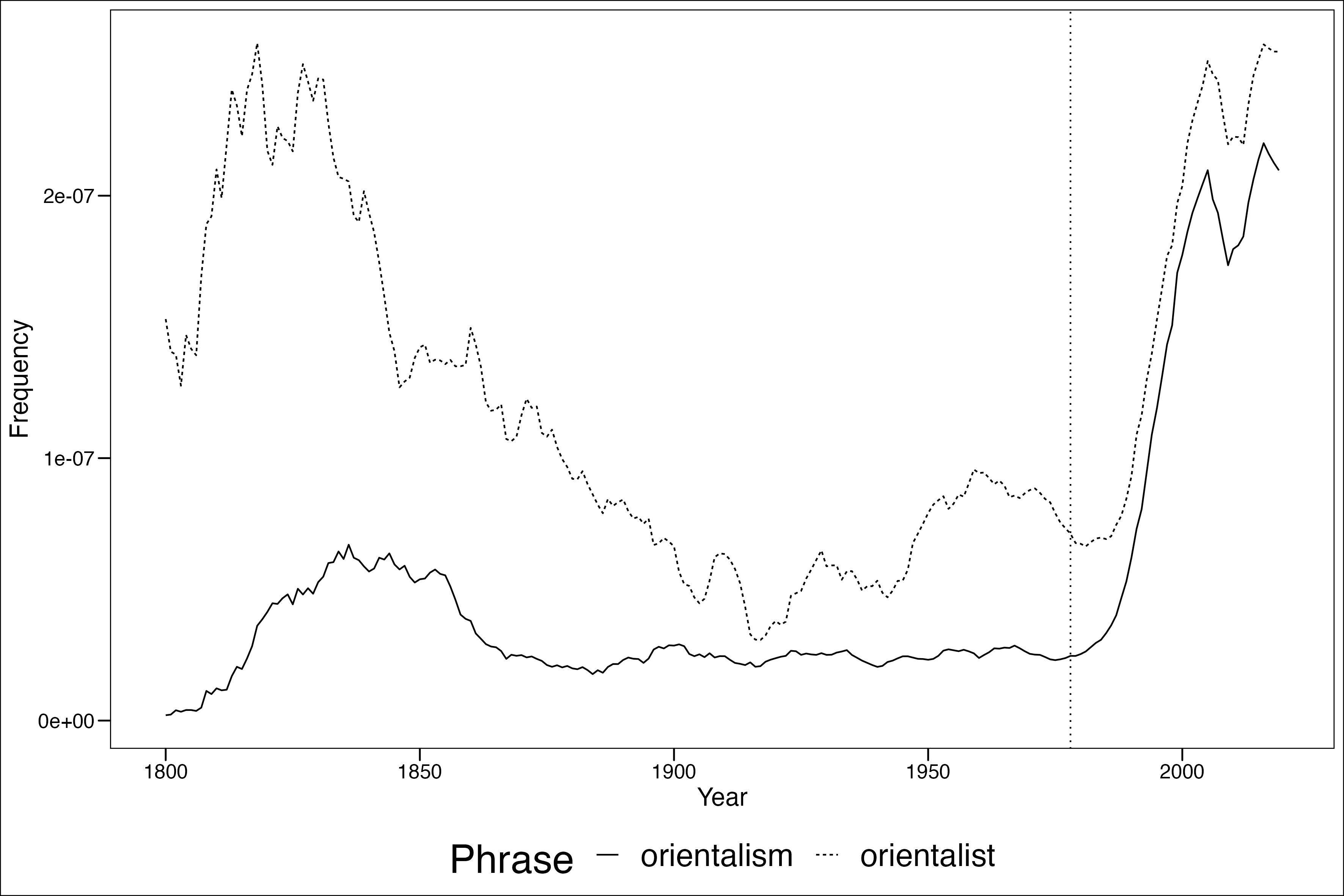
local_glove <- wv_main + t(wv_context) # word vectorsOrientalism has declined over the last one hundred years
Oslo, 2023
Christopher Barrie
Orientalism

Orientalism

Orientalism

Orientalism

Orientalism

Orientalism
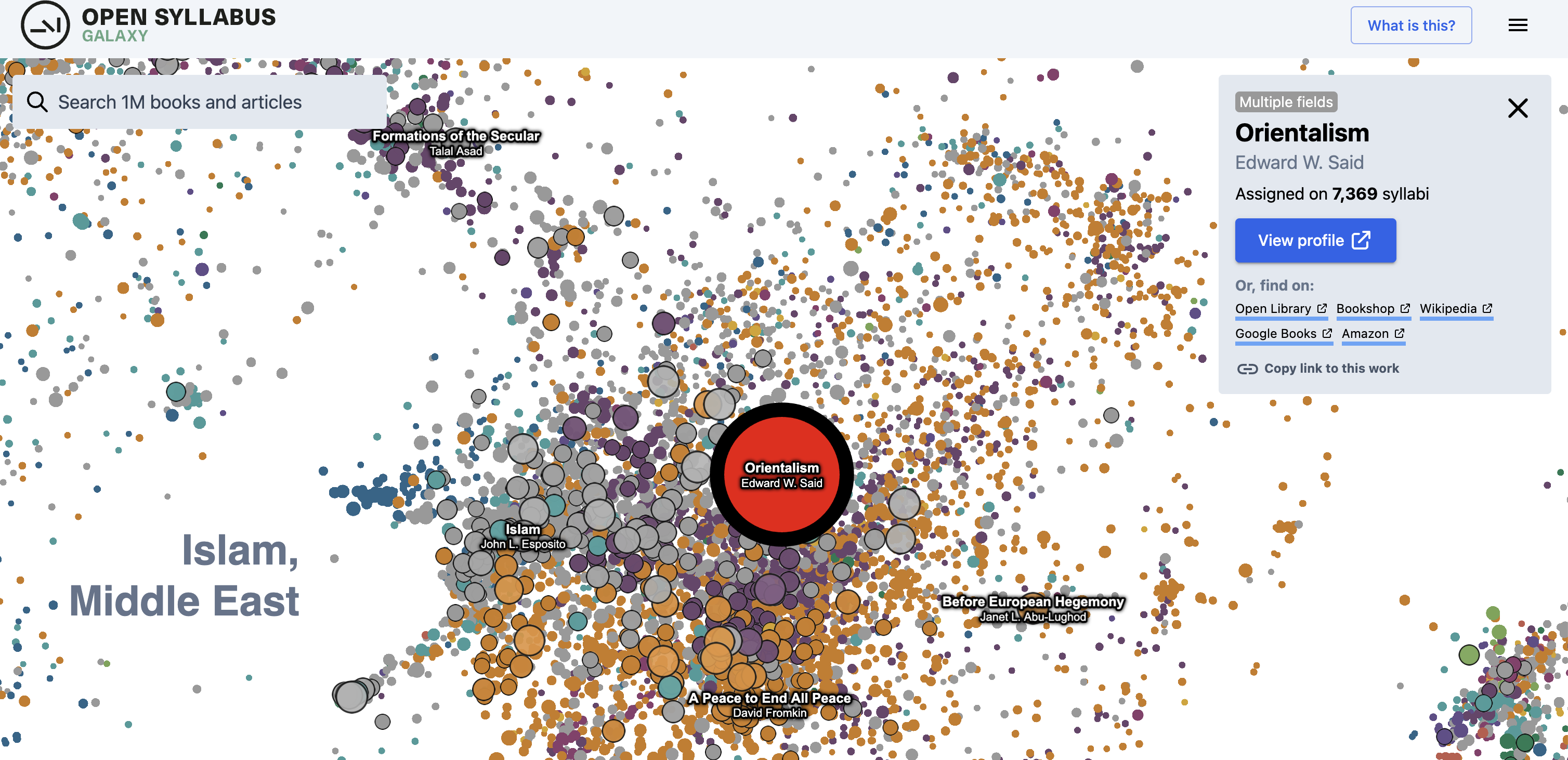
Orientalism
What do this scholarship do?
Spans:
- Humanities
- Social sciences
- Social/critical theory
What does this scholarship do?
- Exegesis (tafsīr?) of Said
- Postcolonial theory
- Literary criticism
What does this scholarship not do
- Quantify trends in Orientalism over time (/test if Said was right!)
This despite:
- Rise of digital humanities
- Rise of quantitative techniques for analyzing semantic content of texts
What do I do?
- Data:
- Google Books corpus: English (fic. + non-fic.), French (fic. + non-fic.), English (fic. only)
- Embeddings from Hamilton et al. (2018)
HistWordsproject trained with GloVe algorithm
What is a word embedding?
| Dimension 1 | Dimension 2 | Dimension 3 | |
|---|---|---|---|
| king | 1.2 | 0.7 | -0.3 |
| queen | 1.1 | 0.8 | -0.2 |
| man | 1.0 | -0.2 | 0.9 |
| woman | 0.9 | -0.1 | 1.0 |
…but bigger than this
Component parts
The PMI is defined by the following formula:
\[ \text{PMI} = \log\left(\frac{P(x,y)}{P(x) \cdot P(y)}\right) \]
Where:
- \(P(x,y)\) is the probability of word \(x\) appearing within a six-word window of word
y - \(P(x)\) is the probability of word
xappearing in the whole corpus - \(P(y)\) is the probability of word
yappearing in the whole corpus
Windows and targets

Word embeddings with GloVe
After we’ve generated our term (feature) co-ocurrence matrix
Back to Said…
We are working with these:
| Dimension 1 | Dimension 2 | Dimension 3 | |
|---|---|---|---|
| king | 1.2 | 0.7 | -0.3 |
| queen | 1.1 | 0.8 | -0.2 |
| man | 1.0 | -0.2 | 0.9 |
| woman | 0.9 | -0.1 | 1.0 |
But we have these over every decade 1800-2010 trained on the entirety of Google Books (tens of millions of published works).
So why are these useful?
- Allow us to look at relationship between words
- “we shall know a word by the company it keeps” (Firth, 1957)
- Allow us to understand relatinship between words over time
- has made possible a number of important articles excavating over-time trends in bias and prejudice…
_

_

_

Estimation procedure
- Same as in articles by Manzini et al. (2018) and Charlesworth et al. (2022)
- Mean average cosine similarity (MAC) implemented in
sweaterR package by Chung-hong Chan.
- Mean average cosine similarity (MAC) implemented in
Estimation procedure
\[ MAC = \frac{1}{N} \sum_{i=1}^{N} \frac{\mathbf{A}_i \cdot \mathbf{B}_i}{||\mathbf{A}_i|| \cdot ||\mathbf{B}_i||} \]
Where:
\(\mathbf{A}_i\) and \(\mathbf{B}_i\) are the i-th pair of vectors from the two sets.
\(\mathbf{A}_i \cdot \mathbf{B}_i\) is the dot product of the vectors.
\(||\mathbf{A}_i||\) and \(||\mathbf{B}_i||\) are the magnitudes of the vectors.
\(N\) is the total number of vector pairs.
Seed words
Select four dimensions based on secondary scholarship + close reading:
- Exoticism
- Irrationality
- Despotism
- Eroticism
Expand using gensim of Google News corpus + manual classification.
For each set of words:
Calculate cosine similarity between the word “Arab” and each individual word in each dimension.
S1 <- exotic_strange_words
A1 <- c("arab")
P_all <- data.frame(matrix(ncol=0, nrow=length(S1)))
for (i in seq_along(wordvecs.dat)) {
embedding <- as.matrix(wordvecs.dat[[i]])
x <- mac(embedding, S1, A1) #this function calculates MAC
P <- as.data.frame(x$P)
colnames(P) <- decade_names[[i]]
P_all <- cbind(P_all, P)
}For each set of words:
P_all <- P_all %>%
rownames_to_column("word")
P_all_long <- P_all %>% gather(year, value, -c("word"))
P_all_long$year <- as.numeric(P_all_long$year)
# this section is essentially doing what `mac_es()` would do if called in loop
P_all_mean <- P_all_long %>%
group_by(year) %>%
summarise(mean_sim = mean(value, na.rm = T), #note: averaging across non-NA values
word = "average")Results
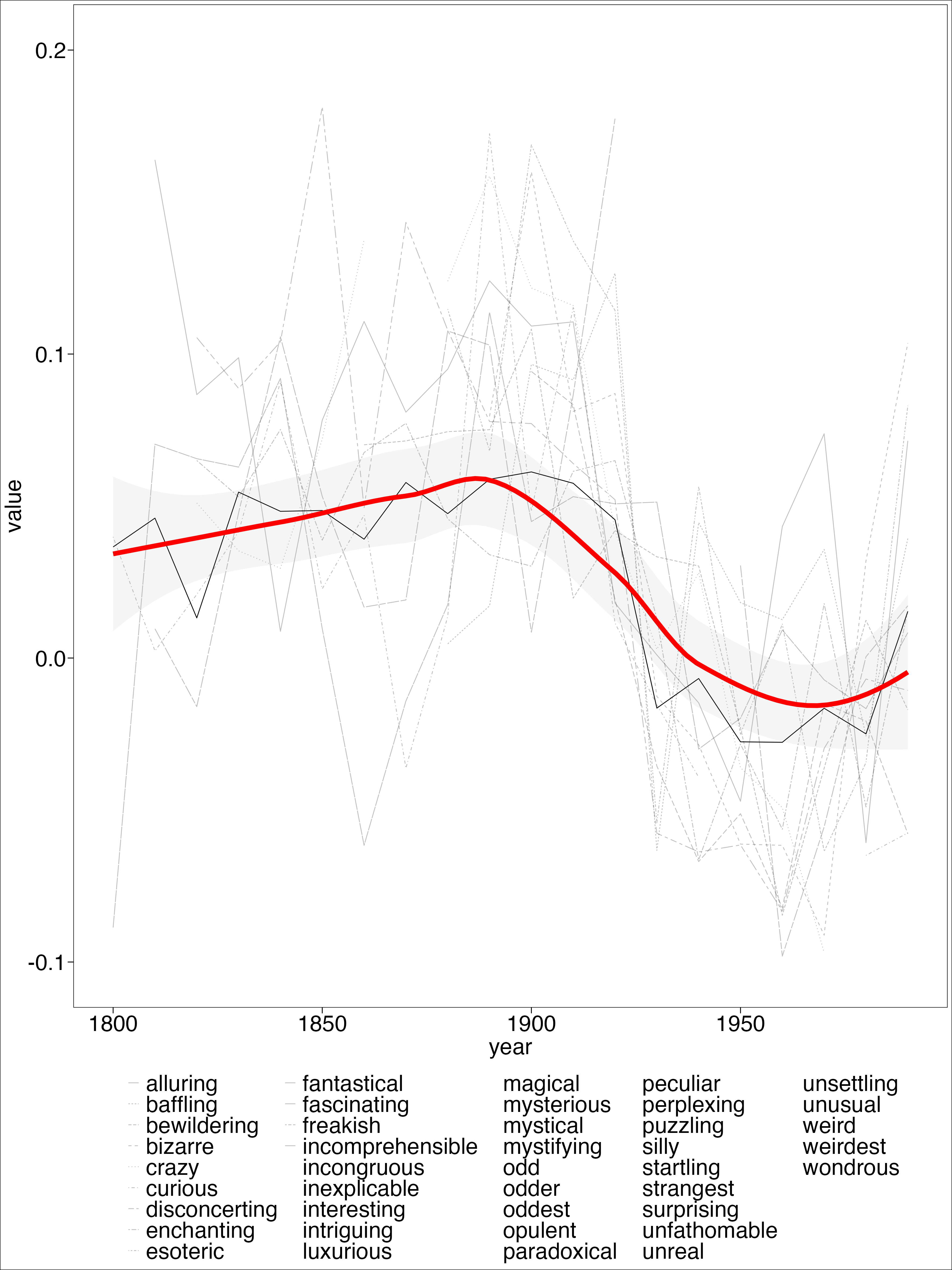
Results
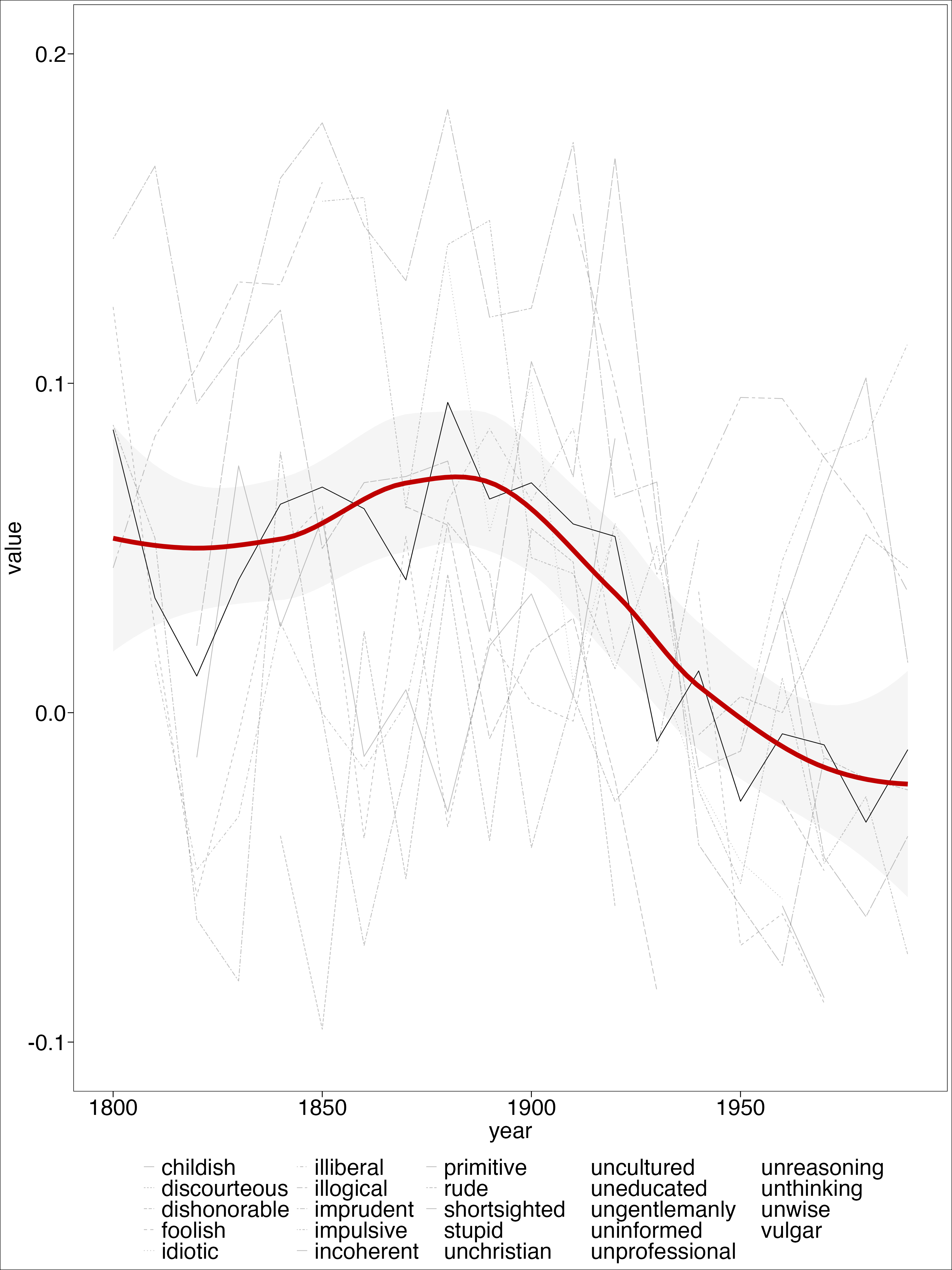
Results
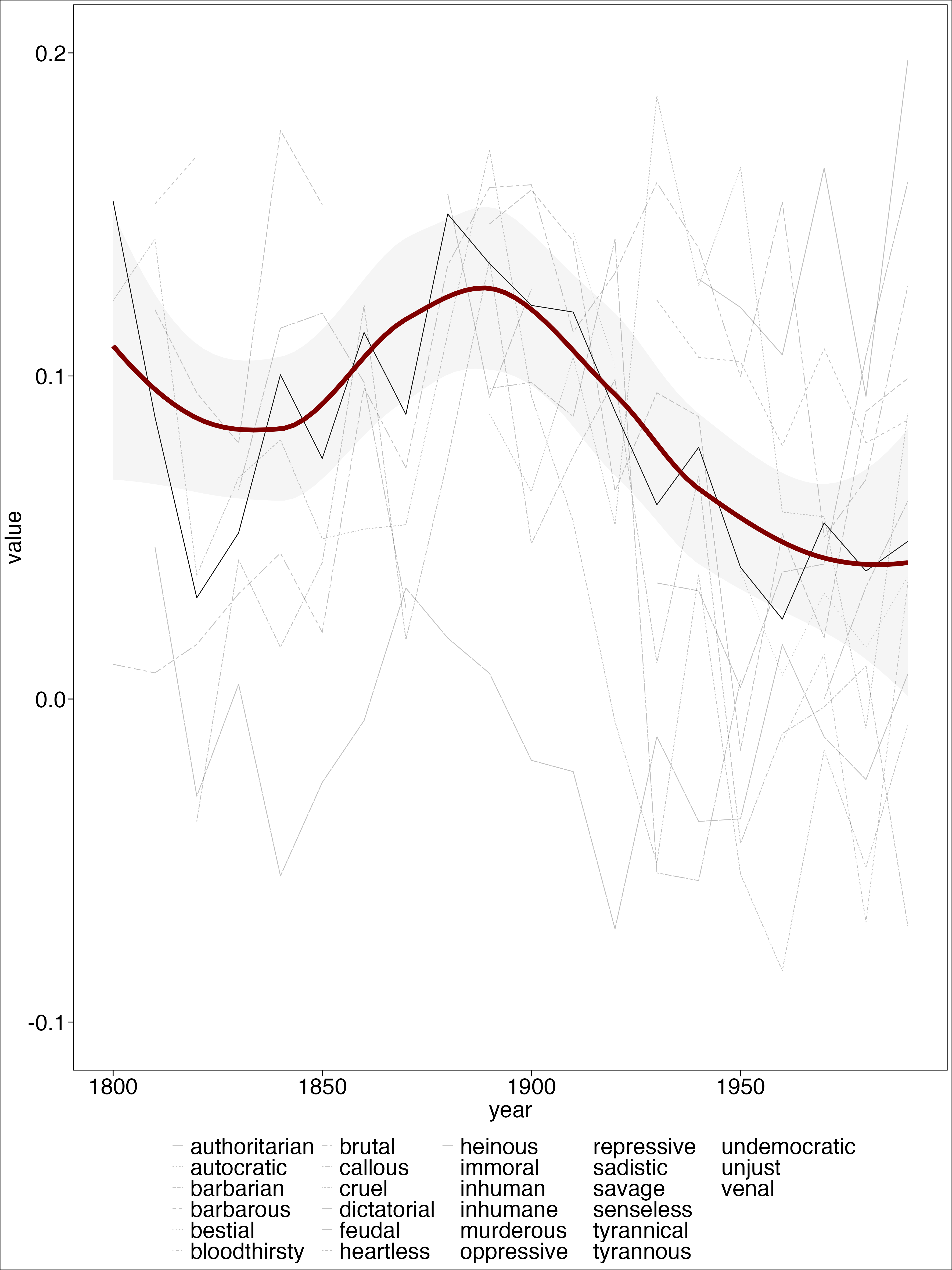
Results
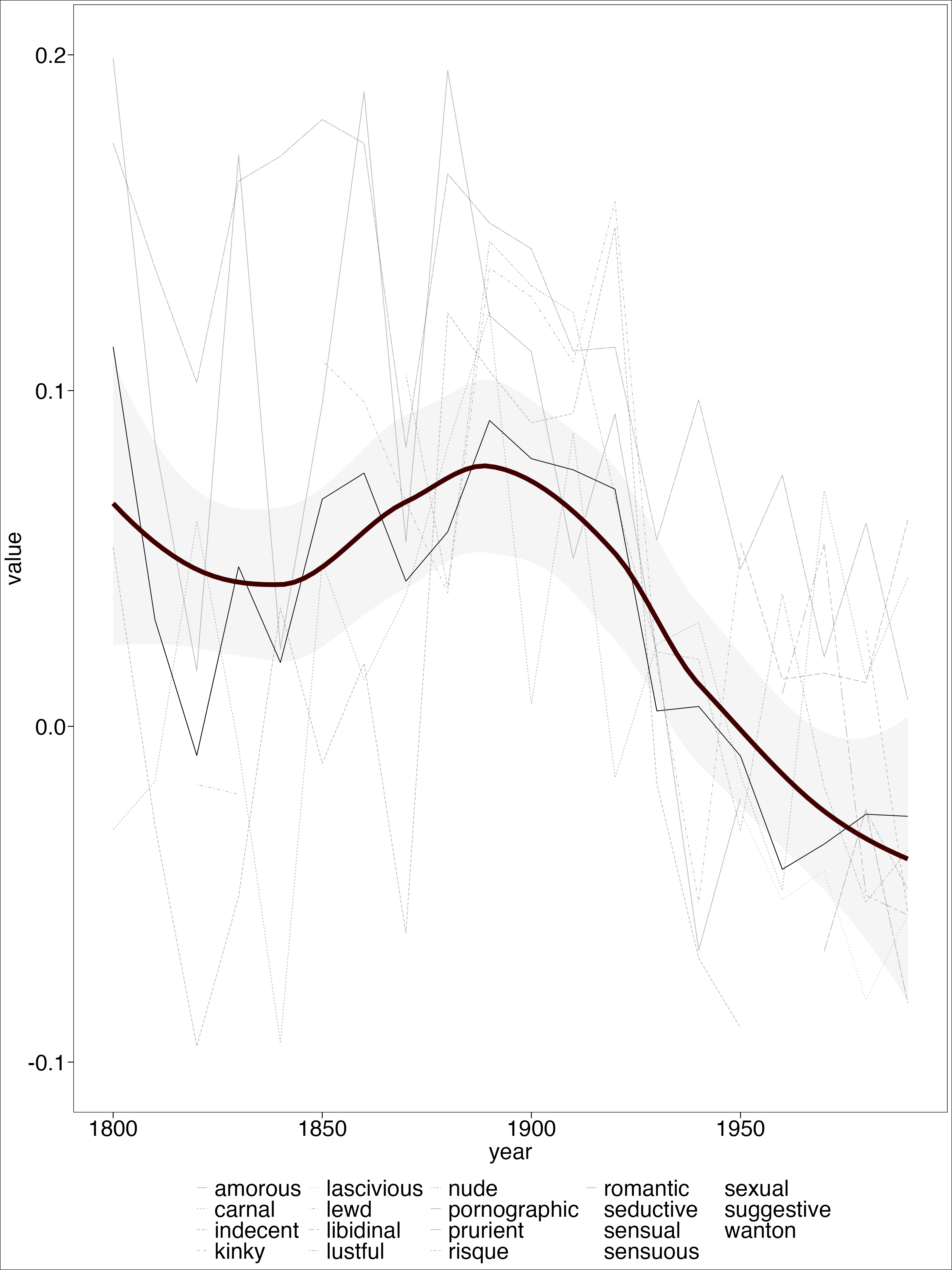
Intepretation
“I have already lost, Kingdom after Kingdom, province after province, the more beautiful half of the universe, and soon I will know of no place in which I can find a refuge for my dreams; but it is Egypt that I most regret having driven out of my imagination, now that I have sadly placed it in my memory.” (Nerval, cited in Said, 100)
“Unable to recognize”its” Orient in the new Third World, Orientalism now faced a challenging and politically armed Orient.” (Said 1978, 104)
Future directions
- Change point analyses
- French corpus
- External validity
- Alternative dimensions (?)
Materials
https://github.com/cjbarrie/oslo_embeddings