class: center, inverse <style>.xe__progress-bar__container { top:0; opacity: 1; position:absolute; right:0; left: 0; } .xe__progress-bar { height: 0.25em; background-color: #808080; width: calc(var(--slide-current) / var(--slide-total) * 100%); } .remark-visible .xe__progress-bar { animation: xe__progress-bar__wipe 200ms forwards; animation-timing-function: cubic-bezier(.86,0,.07,1); } @keyframes xe__progress-bar__wipe { 0% { width: calc(var(--slide-previous) / var(--slide-total) * 100%); } 100% { width: calc(var(--slide-current) / var(--slide-total) * 100%); } }</style> <style type="text/css"> .pull-left { float: left; width: 44%; } .pull-right { float: right; width: 44%; } .pull-right ~ p { clear: both; } .pull-left-wide { float: left; width: 66%; } .pull-right-wide { float: right; width: 66%; } .pull-right-wide ~ p { clear: both; } .pull-left-narrow { float: left; width: 33%; } .pull-right-narrow { float: right; width: 33%; } .small123 { font-size: 0.80em; } .large123 { font-size: 2em; } .red { color: red } .xsmall123 { font-size: 0.60em; } </style> # Breaking the HISCO Barrier: AI and Occupational Data Standardization ## Christian Møller-Dahl ## Christian Vedel ### University of Southern Denmark, HEDG #### Twitter: @ChristianVedel, #### Email: christian-vs@sam.sdu.dk #### Updated 2024-01-18 --- class: center, middle --- # Why do we want a finetuned model? .pull-left-narrow[ - The model learns to understand occupational structures - Vastly improves performance* - Natural starting point for other general tasks related to occupation *This is evident from the the embeddings: 768 dimensions reduced to 3* `\(\rightarrow\)` ] .pull-right-wide[ .panelset[ .panel[.panel-name[Unaligned CANINE] .center[ <div class="plotly html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-b0f0eb45fb0d40f09f99" style="width:504px;height:360px;"></div> <script type="application/json" data-for="htmlwidget-b0f0eb45fb0d40f09f99">{"x":{"visdat":{"216810d46316":["function () ","plotlyVisDat"]},"cur_data":"216810d46316","attrs":{"216810d46316":{"x":{},"y":{},"z":{},"text":{},"mode":"markers","marker":{"opacity":0.69999999999999996},"color":{},"alpha_stroke":1,"sizes":[10,100],"spans":[1,20]}},"layout":{"width":500,"height":400,"margin":{"b":40,"l":60,"t":25,"r":10},"title":"Embedding space (t-sne)<br><sup>CANINE baseline (w. lang)<\/sup>","autosize":false,"scene":{"xaxis":{"title":"V1"},"yaxis":{"title":"V2"},"zaxis":{"title":"V3"}},"hovermode":"closest","showlegend":true},"source":"A","config":{"modeBarButtonsToAdd":["hoverclosest","hovercompare"],"showSendToCloud":false},"data":[{"x":[5.8627900230362906,50.308020203634719,-11.276394323202554,-10.44412210145034,1.1368237060518476,25.702749745256682,90.519303957052685,35.360143964381869,19.858056593781519,-9.6281125447734848,-6.5594934379924181,26.305553118630673,-31.616449977554495,79.755787067023462,77.146774660575616,15.296272830873892,16.721192524094096,-18.87337212019025,15.707365023755351,58.28213469171898,39.407751505281766,-20.690036562418957,35.46901824781731,95.346845203682832,95.478455870812255,-32.669995627996045,38.859297719803529,-31.730391958033699,-27.969803849650564,-60.262590902055607,-34.239916431137694,69.249050467076401,16.748485671955862,95.276137912566298,27.941656557597284,-29.801563117041546,29.840806963292398,31.567857914001976,32.677594971562399,28.525520606269183,22.07959662648285,35.873676248252941,59.04159314225604,59.095049676574938,-55.755283966618975,-12.117560476908768,12.604915817814454,49.704581994821531,33.898226639151559,-17.417283605426924,29.17044464883044,41.247786994418796,11.12278905008678,7.5297535512454852,2.1626230779480791,88.811298577481125,32.178737816350214,32.556190095067429,47.343893412451401,61.324862500595216,89.313377097169848,-2.5690243840741842,3.9396057698816338,48.536105853704093,17.060726519627266,11.860230512304099,59.837750867575011,-30.810638940200487,65.427193855134121,-55.633469762970279,-54.470422537237233,30.827644273647593,88.764232774808818,71.171644577140839,73.84111662199976,72.400437447847722,-102.60500127497482,-24.570614400008139,-32.706744528184331,-56.784146029431867,33.370373623421571,-41.123212465627454,-8.5271855823285385,73.499029889570352,80.542209306665669,11.822673933501617,35.498205023781772,-1.9291952249857565,14.705617418174443,62.396935731365488,71.32172514783305,37.431134666794335,71.940074906371621,21.145691096129287,1.2512242785420871,41.234966329375581,-4.0419279478525008,47.403513516319094,1.3930143976522438,-16.870089512457906,-8.6938372457327837,72.940741967222976,34.561907329757226,-6.419329064208914,51.751839082547157,17.218917481208109,68.860207977972905,93.50715280102014,94.402719717023956,-1.784949132875302,55.916060065470425,83.190349958968184,93.337275046468193,88.41356045585043,91.52921455096039,-23.133910737620699,95.767022309628814,21.532678440891594,25.805829459622238,61.108954116186133,19.09634509506029,92.871843599554552,-25.156786718984311,33.798737799661147,-23.775281654177185,86.941882531255189,94.452893407419111,46.211536710632316,81.867429048836541,70.649511283772995,68.756402328622187,78.264254413121975,77.080001648542975,5.9714870394486832,13.844020613761522,68.835847287517041,-78.540380204672317,-67.472185248637217,74.741711884462092,14.257055122138683,17.173839961285864,18.655379115199342,79.752676137234545,-12.56884198719583,80.672825157214064,89.086502082374224,59.80670094205653,75.243235725680989,-65.7985006503459,-20.444936869837651,-23.4819090649702,-22.652320251472524,-24.280864859108824,99.196255714965176,-4.2710641085426184,-68.594444427423412,50.381010315383783,54.275860086392029,56.728482384458793,-24.952319580886492,40.458605567823327,-30.886185971770079,42.715424609408167,19.716855007369983,-8.9400694034848804,58.584228490253672,-67.050812219315105,-65.596117631812731,59.898680287804645,27.509610617612367,43.091846984859131,-35.019816414925941,-32.372527947442052,71.228316410475088,72.13131854389475,25.167723201979509,8.8771273389076875,56.627038972691444,47.415011462229295],"y":[96.171652630628088,92.029154753494709,12.319981088378384,12.409677327799862,-43.461815008425852,-117.38450979474584,31.951554342432406,-72.821017510396331,-161.01087997376382,-128.08206646167045,-222.34257819880335,-74.31730680281737,55.322287922008542,104.54448423095023,60.71450530338867,-139.95756522234103,-191.39004142433285,-143.33286629130194,-19.732196659702037,65.209391476089692,-184.49981945216354,114.7355147306592,-90.124644600732097,14.785747175561772,16.379324898090672,29.240274403318267,115.90903573191073,160.7446114052089,159.18201973495695,14.326632478086395,110.5405775658496,106.36107238895521,-51.041926483040506,11.628080992404925,59.233084559112463,159.37690996450667,-221.70725888346405,-222.31864784205138,-222.77401822425921,-221.35558501794983,-222.58044795660058,-182.34742940198933,80.007861589426952,58.674031275935135,112.3402516455579,-74.788711016991584,81.703139102184863,68.472267444091401,-1.5792496369440219,161.14788216522973,57.340731230989959,42.645324115154544,-63.814538796199805,172.91194532878012,-46.828001439091302,76.929968526146894,25.824269960380224,-89.273473184324757,36.977617168382132,66.802233935568822,120.910473577408,-103.24854682680849,58.865774879430276,-62.326908578360481,40.258881139106556,145.54162908196631,-11.907212520840664,-56.520323117636948,102.728582997724,116.98643416386551,-58.574570500800689,-218.56529021308009,89.754305585573576,107.49493189682933,53.296823269867737,103.36336650158601,-23.764539939836524,-158.93229270325352,53.212881432968068,-106.41680435545017,146.43890931269857,23.947931030410317,123.98136956514095,50.480030835033084,89.32345947491244,-192.76054254794789,-83.970794719607511,-219.29890660459998,-216.42934000334063,93.253009029796829,156.31764153425235,95.771074695580992,69.060468015563018,-143.06040260714519,-179.33096611103988,-87.783765302017997,64.136592830283249,13.396367793253484,-207.3889782500865,-195.42804873434966,-182.00340819585861,156.08701161209459,-69.787796029991611,-162.62581593847139,-66.442564159349999,-227.57111288028884,27.045578416422334,78.76125072002587,77.257736045301172,9.4782188583730473,121.52539689626109,31.682073429489993,102.74133181401173,106.41418177823802,104.80809556657238,-35.282295064761129,98.879712136253445,-177.13383498829032,139.92954574462229,103.34297981153568,-50.127451829327867,30.483964837030431,-156.36126420462634,-74.115904780220333,-156.50566562340657,109.91919215586088,65.755570835565521,112.25858981763695,108.04508849789104,93.908907186917602,77.818636136908665,98.344529416242082,102.72448540683409,173.47614867803807,-198.86129498792752,3.1263350830694709,-24.946458167861486,81.3861664681219,87.665357993357972,-157.10774029962485,111.99659470950544,-227.63311794847795,64.285403347410423,-19.000853639140789,77.859898846440345,55.313248787920102,52.717333453272616,82.65424389599842,53.787715608724533,-120.19621727146533,38.653243784778574,37.96902320024536,39.202649498936751,49.62035843355239,-193.38848610548652,37.379208003112403,66.326144563111953,51.570812206239694,52.868212030350648,-208.13707889277745,115.01967930089789,153.31664133025026,110.03879900436282,110.27198182252191,101.920319012791,51.142505220205379,37.864792040072139,38.297570623645349,-73.599125883205417,-49.917575295758724,38.007771639233347,92.774942724758503,69.456327565446855,102.02520497872077,-39.352366524475727,132.05782051747676,2.9429567210979131,81.410272512670403,115.69508773270496],"z":[-69.318505518504992,18.384508839153899,23.333964965938954,20.831747226810887,-62.506055028558002,-22.989469973739734,-116.46859328956869,-20.920963126033882,-32.494475523188328,-6.9430404956692708,3.9355709678867781,66.916760109893104,47.770932922254261,-58.613877622983139,-127.45425897788118,-31.892361693018902,-7.1951615397192485,37.925135551201826,-53.990111198540959,-20.083911991629737,-40.820912911631687,69.513572665099403,79.631405272345077,-120.30594978703608,-120.24128753336477,95.865866880820917,-12.390416102276715,-16.920805112204942,-17.742094916371943,17.375752362112397,61.429444660589176,-111.21271684222926,77.279216643701318,-120.41410442665783,-100.97824859807962,-16.933662795777696,19.115275521425566,21.244930275476502,27.559192690031406,17.763759552272631,19.364949897391714,-32.583303743994293,-121.44607317182198,-123.66892219326691,-27.197213651295229,12.907155646152122,11.055313962514251,-120.51051698678661,-75.939350638334872,26.267791863749697,-98.833851758269091,36.465951086901214,-33.120741315045535,-2.4764384813889033,-60.154660950413152,-130.91785952760372,-57.741384630315238,-44.364004263422046,-70.121754977442166,-104.42100189827623,13.371560143297209,-26.042143433908855,-25.312896362035772,-57.938722723431759,-15.706152043444311,-1.6508470331510909,-68.462376829006232,67.423657552681107,-111.76779416859782,-27.493983724216321,39.477921745430145,16.000049249165638,-127.35855999408339,-116.89911225628312,-109.34215688459071,-116.38631613641415,42.541944355479011,-29.900995172686837,46.679619734139507,-3.0582824527428896,-68.451493279361671,60.841892191598454,-48.141244247558099,-110.81526183276328,-63.679314687513042,-0.6100116008185007,80.379720812915181,11.164449753681396,18.877076698075445,-87.161136848602936,-10.293937618750913,-25.402933757365513,-35.826929112715618,-4.4434969400766056,-28.92674812942121,-27.615422848025776,-16.374451563072313,-4.9638052236592021,-1.2145896538266108,-12.169133799592704,-6.847452534985158,-10.437722800397808,65.205117463409394,-47.463090854489337,-54.844507059713493,9.5768198545798846,-30.768714248051808,-132.61824496078708,-132.4645989847597,24.662752966794987,7.8221384042608681,-86.726281739565053,-128.78323210268627,-126.29076139506148,-126.61776780901938,57.617372956079521,-126.12308972553031,-10.13881148013882,-67.955243756598946,-119.92672781231637,75.904163888330061,-121.79649702969719,-34.760656792711529,66.185487038819417,-32.083289313123082,-126.48027657405079,-115.48564986670441,-120.65328897500008,-125.35888427350129,-114.4171943547982,-115.10943927639288,-117.04021870059431,-115.26714512160699,3.8999642267843533,-2.1431705587358318,-37.338879243177843,6.6446344179620063,94.461586954487245,-59.673723674742469,10.346751249373002,50.061160781056046,3.4820167138764289,-131.89550423738621,-33.247505612274111,-47.963565468490373,-119.15865110286305,-116.46706514137341,-44.558796980338627,104.40771757680956,26.89242902705524,127.16763794966096,128.45752403000554,124.6226112273344,-115.65793931881117,10.96455296168044,-42.507859025640343,-125.42940025682888,-125.16098021097767,-124.61633914785605,26.818121137074765,-106.04577906274568,3.0732840819195753,-117.65022481899105,48.561914864021567,71.698166170460837,-119.74185309977709,-44.165021383237232,-45.848602385016072,-33.940481375149055,-51.740003046953603,42.063923602594116,60.321325343906715,-17.720902796101502,-115.04153239683298,-27.742797938860228,-48.303782810103726,99.094731220938172,-121.86902437673068,-44.603416380369488],"text":["Input: '1 d af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aegare' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'af 1ste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'af 1te aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'af sidste egteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegts enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsfolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtskone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsmand paa gaarden' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'alle under fattigvaesnet forsorg' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'almisselemmer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'baren' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af 3 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af deres aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'bauknecht' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'cursant' (lang: ca)<br />HISCO: -1, Description: Missing, no title","Input: 'datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter af 2 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter af sidste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datterdatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'demoiselle' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'deren kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deren kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn af 1ste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn tvilling' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres born' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres pleiedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres plejedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres son' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen frau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dienstbote' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do deres barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do deres datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do kom pat' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dreng' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ehefrau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ekstra tolv mand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'en datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'enkefrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'enkens barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'esquire' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'et pleiebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fanger' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattig' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'fattighjon' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'fattiglem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattiglemmer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattigvaesenet' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'foersvarsloes' (lang: se)<br />HISCO: -2, Description: Source explicitly states that the person does not work","Input: 'friherre' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'gaardmands enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'gaardmandsenke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'gentleman' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'gesaell' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'gift med husstandsoverhoved' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hands kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans barn af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans hustrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans koene' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone anders jensen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone husmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone jens nielsen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans moder logerende' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans son' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans stedbarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes barn af 2 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datter avlet uden aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datterdatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hospitalslem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hufnerin' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader aftaegtsmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader gaardejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader gaardmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader huseier' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader husejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader og husejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaderens datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaderens fader' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaders barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder hans hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder hans kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder og hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoderens moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hustrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'huusmands enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'huusmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'i kost' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre kiinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ikke udfyldt' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inderste' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inderste og aftaegtskone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidder og almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidderske' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidderske og almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsider' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inhysesdotter' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'inste' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'koene' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'konen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'konens mor' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'laerling' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'leerling zeevaartschool' (lang: nl)<br />HISCO: -1, Description: Missing, no title","Input: 'lemmer paa fattiggaarden' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'lever af sin formue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'lever af sine midler' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'logerende' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'logerende student i theologien' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'madmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'mamsell' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'mand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'mandens moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'marques' (lang: ca)<br />HISCO: -1, Description: Missing, no title","Input: 'min datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'min kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'none' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'not mentioned in source' (lang: nl)<br />HISCO: -1, Description: Missing, no title","Input: 'nyder almisse indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'overleden maastricht 25091812' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'overleden maastricht 29081800' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'overlmaasbracht 24091870' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'pension' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pflegekind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleiebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleiedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleje barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejebarn fra opfostringshuset' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein vater' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine ehefrau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine frau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seminarist' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'sense ofici' (lang: ca)<br />HISCO: -2, Description: Source explicitly states that the person does not work","Input: 'stakkels husdreng' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'straffefange' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'studerande' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'tidligere enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'tienestefolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'tjenestefolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ved reg braende artilleriregiment' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'NA' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'NA' (lang: nl)<br />HISCO: -3, Description: Non work related title"],"mode":"markers","marker":{"color":"rgba(102,194,165,1)","opacity":0.69999999999999996,"line":{"color":"rgba(102,194,165,1)"}},"type":"scatter3d","name":"-1","textfont":{"color":"rgba(102,194,165,1)"},"error_y":{"color":"rgba(102,194,165,1)"},"error_x":{"color":"rgba(102,194,165,1)"},"line":{"color":"rgba(102,194,165,1)"},"frame":null},{"x":[-20.372833177314231,89.92384263779185,70.00059600650745,96.718461266520578,77.267533150541439,-63.750434550558538,2.8405964251442426,58.796947652178943,68.656543740173547,-74.267911913988812,-42.782856155302078,28.524132457525397,-64.197238422130212,-79.361771535695652,30.455479863811195,-54.15940137389736,-1.8454064468187705,62.239567479981261,60.770240054331083,-32.139943975744899,17.251384787960848,29.64008792275493,9.1738822080912303,28.788751230905962,26.593144635224949,45.415323824779279,28.439067509881038,44.434582604566103,-81.857554262388689,45.148894599020394,5.0876882663612664,89.781950454584546,39.908126844041163,65.389955172992074,-37.653954032206812,54.108682867158016,47.607799325326326,96.29568576564526,37.89376121306136,7.9369071492036705,-2.1590340352197228,37.10397581577493,42.863188747689989,4.8314397808212552,-33.644861793081553,57.149901103957482,-39.021684300585257,10.175332449053633,31.397325225815027,-51.282447806022439,-4.2848148155955101,10.873301310201626,-27.303810429059098,-29.615874792682995,-51.361061769141223,-64.322051337171175,-3.1315606896629302,30.279935293659548,56.967899248843871,54.96058197294051,22.588171734640955,-62.818887414914059,-28.035165520200824,74.5806351250734,-64.939828977471805,-70.700405591825088,16.643502902155554,-22.276457836401654,49.520929190621054,39.223585005852968,93.641321949737772,-57.869164784296942,-10.202773243817838,32.107967133022612,-10.976838471384378,-35.146496822366281,89.024115024519105,-43.49273930829726,47.146285716487668,17.47838683103279,32.025754372738284,4.4996503888418973,-45.601014143556306,-10.811953655989717],"y":[22.486134707057516,99.870006239821251,-27.931979631351062,43.779337477773574,75.345305951929774,57.763377048266882,-177.94179127525226,66.851742054958976,-72.055848858954562,-47.032313633145684,-75.650306906439042,-23.435828693398943,-34.068364348508588,-48.305745538376947,-44.136775720898051,110.20519321887554,63.180989300916508,167.64710438015683,167.1371632354049,-193.24023263256072,-22.028658590398681,-148.99851513933893,30.314442101913507,120.2358075859043,-19.478654452711066,130.37018454689354,144.64541262548013,-87.227308037109395,21.144489056976113,164.32841262735536,18.211407290719908,94.151870027287544,132.35343317875913,-28.114300159117942,-34.713891980692097,22.391337792977485,2.7913058718925332,71.34852319729778,68.484432976687557,90.753170603478267,-92.887459564996306,131.22471569385249,113.79790293115451,31.976589715422289,74.277817798034931,66.584582546479254,-188.69333574044637,-173.12640594844663,-11.821237900725222,44.827687222183435,-113.20946490087812,-49.342822591491654,147.35360066828326,39.645360926141088,114.36606265810448,40.491920079509349,2.2182898620315616,153.31380163258115,121.69075887586912,66.534579759632734,34.231881080897338,-54.426864824888192,125.10433253560483,104.17704392625861,-102.52278951405447,48.199971689052433,-169.56357738648313,116.8189499442398,-9.7568263666767798,25.867008083241412,70.662129303906625,34.97471889287317,-85.699840994984797,-14.135958776334499,-198.75493314024951,148.04424183894218,103.14892939063681,44.912287033376721,-54.639144818826395,128.42871676831592,97.031250724985725,47.815276352055101,-126.95098525834867,111.60865729709398],"z":[-16.6391964520698,-124.37284988109828,27.97063111782364,-118.28714987921182,-115.58546053454486,97.044284213998552,-32.186052400142394,-93.982855273953376,-19.253318313749542,87.652061156505411,52.436813973865881,1.6172078615703556,17.597353993535304,94.120416642719889,-23.241732711842488,-30.954779382345215,-15.726986880114064,-18.848536007090807,-18.981443460784174,28.389599928548016,-10.925666664284989,-45.936169309922263,31.505638635580226,-30.287725578059629,41.606047570932724,-13.507786507415206,-11.279508808126264,-12.589207379020852,-19.74670919028113,-13.914845591342493,-37.779956175750058,-131.41771098472475,12.658187310635871,34.871555365485811,-4.9390313889598643,-41.173394118999333,8.921086433449144,-127.47172533204599,-80.730776127415282,-38.446334323314588,43.326149651812898,-29.388095222437144,-79.107688958692137,25.815507461061369,88.928960582182754,-18.558786745031444,38.39009776864588,-3.9017787364765417,-76.140568616134047,113.08856067967648,-6.5125475263390946,55.370795334237528,15.383218816370889,37.948334663003095,-12.566968076464532,-21.359281161731364,-11.499587803601864,-4.2661259011012502,-16.515154467041402,-78.613697574114312,-36.77040849970637,50.767734939844836,23.61877669261262,-26.930667709275184,14.059956105782636,17.299124860707085,-33.194267404907848,66.995725821287238,7.3478584244953602,-57.399563603663502,-126.18078556187797,129.30337944905949,76.523669558892948,-30.050322177270015,-15.130811309849653,2.8727859266842439,-43.698348033040013,111.5390356457161,-31.61820878891427,-40.805454174887522,-34.781848762299646,70.873069283313811,-6.7036669120461116,-31.623739386400164],"text":["Input: 'accountant surveyor' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'apoteker' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apoteker assessor pharm' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apotheker' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apotheker o' (lang: nl)<br />HISCO: 06710, Description: Pharmacist","Input: 'asst nurse workhouse infimary' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'attendant nurse to old lady' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'barnmorska' (lang: se)<br />HISCO: 07310, Description: Professional Midwife","Input: 'binnenlandsvaarder' (lang: nl)<br />HISCO: 04220, Description: Ship's Master (Inland Waterways)","Input: 'binnenlandsvaarder en not mentioned in source' (lang: nl)<br />HISCO: 04220, Description: Ship's Master (Inland Waterways)","Input: 'building surveyor 36' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'captain steam ferry' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'certificated fraternity nurse' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'chirurgijn en not mentioned in source' (lang: nl)<br />HISCO: 06110, Description: General Surgeon","Input: 'civil engineer' (lang: en)<br />HISCO: 02200, Description: Civil Engineers","Input: 'construkteur o' (lang: nl)<br />HISCO: 02220, Description: Building Construction Engineer","Input: 'cursan cirugia' (lang: ca)<br />HISCO: 06110, Description: General Surgeon","Input: 'docter' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'doctor' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'doctor medicinae en not mentioned in source' (lang: nl)<br />HISCO: 06105, Description: General Physician","Input: 'doctor of medicine' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'draughtsman' (lang: en)<br />HISCO: 03110, Description: Draughtsman, General","Input: 'electrical engineer' (lang: en)<br />HISCO: 02305, Description: Electrical Engineer, General","Input: 'electrician' (lang: en)<br />HISCO: 02305, Description: Electrical Engineer, General","Input: 'enke efter en lojtnant toftenberg' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'guimich' (lang: ca)<br />HISCO: 01110, Description: Chemist, General","Input: 'gwaithy helper' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'head nurse to lunatics' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'i p inc from land divd c' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'inderste gangkone ved kirken' (lang: da)<br />HISCO: 07210, Description: Auxiliary Nurse","Input: 'ingenieur en retraite' (lang: fr)<br />HISCO: 02000, Description: Engineer, Specialisation Unknown","Input: 'ingenioer' (lang: da)<br />HISCO: 02000, Description: Engineer, Specialisation Unknown","Input: 'ironer wash maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'kommissionslantmaetare' (lang: se)<br />HISCO: 03020, Description: Land Surveyor","Input: 'labourer on river alt' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'land surveyors' (lang: en)<br />HISCO: 03020, Description: Land Surveyor","Input: 'laundary maid domestic' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'lods' (lang: da)<br />HISCO: 04240, Description: Ship Pilot","Input: 'm d and surgeon' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'maid domestic servt' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'maintenance engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'marine engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'master mariner' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'mechanical engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'medical practicioner' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'medicina doctor' (lang: ca)<br />HISCO: 06105, Description: General Physician","Input: 'medicinae doctor en not mentioned in source' (lang: nl)<br />HISCO: 06105, Description: General Physician","Input: 'medicine kandidat' (lang: se)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'mestre manescal' (lang: ca)<br />HISCO: 06510, Description: Veterinarian, General","Input: 'mine surveyor local methodist' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'nightman at canal' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'nurse and housewife' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse hos nurse' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse male at present represen' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse midwifety' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse to imbeciles' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'occupied of land' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'optician' (lang: en)<br />HISCO: 07530, Description: Dispensing Optician","Input: 'physician' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'pilot' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'pirotecnic' (lang: ca)<br />HISCO: 03610, Description: Chemical Engineering Technical, General","Input: 'pupil assistant metallingist' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'quantities surveyor' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'rasurer' (lang: ca)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'retired civil servant' (lang: en)<br />HISCO: 02210, Description: Civil Engineer, General","Input: 'retired civil service' (lang: en)<br />HISCO: 02210, Description: Civil Engineer, General","Input: 'schiffscapitain' (lang: da)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'seuller maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'sjoekapten' (lang: se)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'skeppare' (lang: se)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'skipper' (lang: da)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'smalschipper en not mentioned in source' (lang: nl)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'steam tugs fireman' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'stenorgrapher' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'stoker on ste tug harb dock' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'styrmand' (lang: da)<br />HISCO: 04230, Description: Ship's Navigating Officer","Input: 'surgeon' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'surgeon and physician' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'surveyor' (lang: unk)<br />HISCO: 03010, Description: Surveyor, General","Input: 'tester' (lang: en)<br />HISCO: 01400, Description: Physical Science Technician, Specialisation Unknown","Input: 'trinity pilot' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'veterinary surgeon' (lang: en)<br />HISCO: 06510, Description: Veterinarian, General","Input: 'wharf labourer riverside' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'wom maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers"],"mode":"markers","marker":{"color":"rgba(219,161,118,1)","opacity":0.69999999999999996,"line":{"color":"rgba(219,161,118,1)"}},"type":"scatter3d","name":"0","textfont":{"color":"rgba(219,161,118,1)"},"error_y":{"color":"rgba(219,161,118,1)"},"error_x":{"color":"rgba(219,161,118,1)"},"line":{"color":"rgba(219,161,118,1)"},"frame":null},{"x":[25.600364212865639,29.838083517289022,1.7123220400302366,42.96125384413255,-26.734784110661082,26.290922951900399,49.879323174726224,-32.438504673391002,74.920702898794133,-21.721308556164104,15.167324788122992,98.577547792881191,-70.188473714870398,-23.090434636791105,-18.880685688749242,-51.375821289671521,17.581377919630832,-77.200383342989269,-17.9028284989705,-13.034526796942286,-1.3732745518922209,20.924476148643695,-9.2023552040415471,-30.180615443367529,84.750573392340272,-79.665036090668494,-22.405022771153025,-20.285837871259126,27.711870564594893,24.166565218438034,-52.588877161674908,13.429904484458106,-13.678650730525671,3.2459141448906736,-53.971362050921826,-67.238236335614317,-58.536192913041134,26.528741514022563,1.1453070071176008,-44.370896567657738,15.742218195457662,48.13201641065384,-60.870266139939048,-30.378637550238949,-62.473858278718382,51.616103420355756,-29.683766803173068,-29.713978402515156,-64.783946323726497,-71.912579522249516,21.385103170209735,27.105065303769585,-28.489755141096076,-71.307278406280986,-16.316584454844179,-45.175210582995788,-14.823107594859554,-53.681093398005679,-84.087559099327493,-36.013008847025148,59.314303543073564,-63.748909480335641,-20.409145321423441,60.558919132895468,45.68184788734105,45.640498222405192,58.023652788182304,15.53165085300043,-8.4867117981389288,-14.102700895581357,-20.284828594274327,-0.68029524078311576,20.705509596568604,-68.868980951927369,33.58590669880563,18.544808455652049,10.830475713893602,22.20777900531186,-43.341561995051229,-20.51305045439684,-79.692413624217153,-35.737282203172647,-70.092478871867129,35.136865209979085,-43.200071168598043,23.598325969887444,-18.514513361700896,-28.967513858536037,-50.41022868515202,-72.329699798215884,36.862274948591519,45.609087405069047,3.22188602599747,44.06063067236429,30.650649440131669,2.2278865078021459,39.423670121203259,27.174551333118242,-4.1429411216561078,-35.683530864306981,-15.288889508385534,34.987297847005493,6.7015631267613296,34.366637138708953,-59.662548831438919,-58.893006835409587,-11.37653927649129,-8.3427730291276276,-2.6634034346962565,0.3163091067599253,-27.567245300956426,-19.524220388853699,-40.536051575912893,-49.732456797051761,32.483415418896875,-27.108221153160947,34.975068983535252,-30.543723636299021,80.983568666673406,4.2835675274532692,35.109569554443304,29.504255807949416,-49.346532897576886,41.298984828984118,21.755768510528348,-34.278049982931108,-58.511125298271224,-38.867060548065041,70.096153397504366,40.95721260356197,-78.002756431735634,-47.759056660389902,10.669137612099128,-32.170036417623749,-6.3639305648916862,53.439039634341384,-67.898456058773846,22.31760142682057,22.753690573337348,103.13120797049326,-30.931443018991914,14.712026080652221,-33.579466061221723,-54.90008672855852,-0.76789785055291593,-9.3368129931575243,-4.2921419203113205,-2.05776542248717,6.722366759832207,29.497006370865236,-7.8809595569467925,-18.289782114523689,-1.2009271382448896,-25.426537006646132,58.045927432940964,-5.0703990075187608,13.340354523537313,49.686578805480529,-0.17047523178223137,-14.690502285005971,-92.865670084170887,-10.582328593042821,-4.6122933387825151,71.868081459584815,-77.717752357866729,34.827130067155494,42.815304767859075,61.929890821275862,-63.212298639017533,50.554083989855762,-1.3595318787418731,-64.449555450253001,71.462164635342901,78.336011958042164,31.543532592979616,-50.988916737954227,-66.241887950922376,53.894736640939733,-28.707941642245547,-17.045218132638464,85.309726326472003,19.72218341581506,-69.072102259609849,79.052292052251332,72.898827637688782,-37.336725017796851,8.2912486070490417,-45.025208140077076,-16.324002095617253,-15.494756280004824,-9.6291547061584577,38.04851657313786,-82.734721633946876,-14.069215458704363,0.15190367326335291,-55.571238534102903,30.788159240131804,108.23358062071506,-77.784754294457386],"y":[-124.88402854864346,-21.016180316243595,-176.51691400464463,70.882947367698577,22.678124566918193,-64.289447778853912,107.06004423793176,6.8409264577941782,89.1235524332929,-8.4723172676952228,0.15133555235531751,127.3366533710839,-47.900912175202279,123.72198524515645,-85.084171499080327,110.05122766956245,91.849506577700609,77.963894705373065,107.83157998991798,-174.93616953713615,-97.972748995292932,-4.5519765974232529,139.86710933189681,43.387054851976643,78.272776705094643,20.323168638165022,21.331483813632001,-209.47166923889517,-26.760010039813178,-111.68346522252567,-112.4697644468903,-214.69348956393242,-95.113807124056194,54.499217398261557,-65.88461340219888,47.102350027319531,61.712036165364815,83.887424688352709,21.187508008768571,-49.734755469509665,150.42532806760195,42.466954234129126,-136.78961274746507,-106.25960964090464,58.17126778880958,118.03797899231036,-104.44111449038108,38.190121594132989,18.274841724657492,33.559338391590728,-89.242738506173893,132.47955091618141,148.63976916966519,-2.5204826250708932,-83.092097472208437,-68.783071172628865,-79.580222935407903,51.499461898905338,14.888992161072659,-32.953721660562969,74.765264908173734,107.91138120249354,-111.42309612640565,99.708398544752242,-83.418614172700089,88.735582585500268,160.74878233154564,-83.038191728551467,-120.77751539288671,-125.31043098444918,1.1034358553569203,-119.67660168419187,-126.12737471665555,45.157843678474023,-71.583475986107445,73.708254255783558,-222.47902500774896,10.140585598538395,-25.690730572029569,32.311110676021279,-43.20340257228024,-174.99155242914037,-20.468076534727587,55.105127041221351,134.96923532967037,3.1656762215914624,-7.1888598276608393,142.86067692996411,-52.629185400389773,-39.014089889687909,111.80735327040883,141.5617248532981,-9.2171183186029459,62.350722017461003,-50.039707159079526,23.012141967814753,-55.061785722512539,-73.702622635118047,-48.27690004968192,33.426666212487326,-202.37141791812795,51.403062545278985,102.14104356818844,52.536815619269106,73.044352051775221,100.13106057874444,118.25699569572986,-44.216841196536066,48.305107952995712,-42.777788531295961,-57.6314089232147,-101.8012748265395,86.626467356555793,45.703459346640585,-66.364733167443347,127.90457169114838,94.169359118852128,-18.070037659012748,134.92157932063469,-201.82962151502284,133.80218408606763,130.35437652784682,-29.242180691438641,31.863009236787494,153.36636183432927,-104.82340379796453,64.924484242881945,71.698953051178435,92.71649422834372,23.390402207136386,-61.779131240014976,-200.28701998317598,-110.2074462573468,21.532410879247653,-120.39814353045912,114.61537376076392,66.745021237791846,94.208452570433863,-147.51413472885517,63.648676964370502,-119.91611306874682,-201.7129533398915,-76.065552800307145,59.47239123389798,-41.147626763260725,-211.05432581154733,-36.926934299222431,-39.563843461056948,20.811031769907764,-66.602389653197591,-85.105394800477768,41.099164768676587,12.801488385941102,118.12640684552436,52.806092050704173,-55.983760875186832,105.63274341843773,130.36476186812024,-57.144737334095346,11.267311268968715,39.540683555794537,14.934683969984633,-21.128211725944389,-43.24565790055005,17.847617734730296,-84.348194554573425,64.350738659044694,-81.315255457139372,105.76409520162704,-81.338646748663194,16.05268799131543,25.124492618587087,30.865161554100823,78.777200308570968,126.07705072412566,118.05375946461932,-47.809555649155463,138.97643541760797,-180.76205665804295,-86.897606880756186,78.583071487248461,-105.66554638862195,43.088044048769603,126.92322599693122,81.587446721154009,-60.2332572039006,96.909802241163334,-96.757461550029845,-110.14738528926836,-4.5426173153057752,50.540804937645682,-16.671507159081401,19.151387598088345,94.821106515678252,5.1597951899560961,84.426582100860443,90.288836335960397,110.0630997359758,50.198039149726334],"z":[-24.486066880937948,0.83904228894386856,-33.224886053292678,-54.885909943627254,-17.798261985116522,-36.359243725223429,-22.534822116742024,80.861802195614374,-113.26706893070877,49.000223156642726,-27.166459257846419,-1.7342304692730792,43.816841436930879,35.953370146497583,53.236549241825983,39.871085862362804,-15.232617222326136,40.55728507623931,-2.1967605901435223,-13.488272767734466,36.514425443782557,31.869393792648147,22.138544861773916,40.06520088391845,-10.75969630198632,36.35930860508482,68.98092832974811,7.6049674782256425,3.1516523629588939,-21.545729059517445,11.219004207501607,19.137633233562639,58.169234618940806,23.465387182318558,23.675929746545116,106.21810520527289,84.499253412639192,-28.39246697327868,96.90020016498967,36.224048090054772,-5.8141014757973188,-56.315663330912088,-5.276012819395171,-27.326910682642062,-16.150718773174482,-72.420219462746914,-27.083951900538338,36.569714998937059,57.787498337649161,-7.4808789129732496,-29.913301325370174,-60.469484530328437,2.032899880171839,-17.464445705892231,-43.607905224783266,-2.012471295654521,-43.737765845276577,-29.723794219190161,-18.140407690945821,96.906144027107487,-70.038058240406727,-10.609639016857583,59.489549094502863,-25.967081500004294,-29.99529831423418,-28.191450388926398,-8.2781734192333225,-34.633438900396193,-24.638332720996125,49.869839962970673,15.147643621175172,39.923100470739143,-19.782434595648088,60.826779118391876,-37.096398902367412,-10.004641950547997,4.7349753303768063,39.586112915919045,92.198234948976065,113.66031139899654,63.23047552968751,18.389323325250171,-17.532685546976097,-82.562265892920237,10.041051476020906,-41.427694702491486,16.757112127535368,18.627784088058803,53.042534360653228,18.702071061182085,-75.988537755732196,15.158650502137879,-22.763670885654783,14.202733920746667,35.4231350979504,-54.177046113560003,-33.001987718587621,-19.459407434770352,-2.3447971910186607,62.771024480731768,18.664356882158145,-90.659950082056639,-67.642538716835546,-92.358115407819525,94.176055287482058,53.693343210696476,23.639410957439821,-13.746113783971923,50.02955179229204,-10.358129289079782,68.025337697333114,32.058293233321287,40.445954896990344,110.85652514457063,-47.514964371882364,-22.339036986741071,11.673957281256891,98.065819105898228,4.035841459713148,-3.6906414825766145,-9.9276509409592713,-63.346295983615398,98.838493388709679,-65.119583628380127,-3.5622926895518736,5.9813560360641098,90.48820101347404,70.62319057958706,-102.12678800733217,34.522330344742777,29.118789484403198,52.298226096801386,-16.796401692278678,72.04998989980129,42.806739882909014,-70.667422378276569,88.941864608525876,-39.155268399139182,-6.1987538641378981,-28.241913707417773,65.318959948017351,-3.2137039148890199,-18.119896771751481,3.2911473993280964,-18.864500848436617,-10.029341793165063,22.19396514933068,-15.822465870481986,-45.972028521672271,-33.918909628525981,77.574767681734812,86.461503626848184,61.409519287096025,66.593320919514852,-127.1793082764307,-37.633265822049488,-42.175543500599318,-11.262440966192026,-48.698643889372249,97.402978414468137,14.813989828886285,96.710338541085576,-15.310888633778948,-26.971038058462515,38.452367055914934,78.024430168772028,15.848907236993538,-16.415775275158129,-24.799901521744854,-32.799918421516971,-50.34093631515718,-2.218960643044356,-30.644575952151691,-120.44836152753017,-31.024938328044598,23.714451720513797,64.650837911812005,-13.483091412008578,31.006441557145326,70.39716024835495,-54.347943601403493,-16.830477345365988,125.91740096121924,-41.2121477678673,-56.856287909534721,12.022134265291129,-32.312897243003896,-22.531471900290722,-34.053606555917838,53.770536664695349,-21.553090277868055,-7.8479292339347362,-17.802915298726742,79.650414366499191,54.690262079361403,34.794815882583094,14.563423618406782,-34.780998673418054,109.34574969246336],"text":["Input: 'accountant' (lang: unk)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant occa baptist' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant draughtsman out of' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant grocers' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant on dealers' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant pig iron' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'advocat' (lang: ca)<br />HISCO: 12110, Description: Lawyer","Input: 'advt en secrs tot diemen' (lang: nl)<br />HISCO: 12110, Description: Lawyer","Input: 'af sognepr' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'apprentice millwirght engrav' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'art engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'artist' (lang: en)<br />HISCO: 17000, Description: Composer or Performing Artist, Specialisation Unknown","Input: 'artist employs 5 men' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist floral' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist in choreagraphy' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist landscapes oil and etc' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist sculptor' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'artistic landscape painter' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'as a dairy maid c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'assistant librarian british mu' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'assistant teach church of engl' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'assisting decrepid mother' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'atambor del tercio del vermells' (lang: ca)<br />HISCO: 17140, Description: Instrumentalist","Input: 'atorney one of the deputy re' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'attorney at law' (lang: en)<br />HISCO: 12110, Description: Lawyer","Input: 'ba english language teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'baklist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'bedienaar des goddelijke woorts en not mentioned in source' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'bedigd translateur' (lang: nl)<br />HISCO: 15990, Description: Other Authors, Journalists and Related Writers","Input: 'biskop i odense stift' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'board school assistant pupil t' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'branddirektor i kbhs amts nordre birk' (lang: da)<br />HISCO: 15920, Description: Editor, Newspapers and Periodicals","Input: 'brass relief engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'builder contractors clerk' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'c c methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'caloinister methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'chartered accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'chawrwoman' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'city sewers employee' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'classical french teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'clergyman' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman estabd church0' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman in holy orders' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman servants' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk agent' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'clerk in holy orders' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk in holy orders, retired' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk to calico engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'cottars neice' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'courantierse' (lang: nl)<br />HISCO: 15920, Description: Editor, Newspapers and Periodicals","Input: 'cratemaker c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'curate church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of chilton foliatt' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of great torrington' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of handley m a of cambr' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of keighley' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of rhyl' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of st swithins lincoln' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'deaconess wesleyan methodist c' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'degn' (lang: da)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'doctor in de regten' (lang: nl)<br />HISCO: 12000, Description: Jurist, Specialization Unknown","Input: 'doctor of laws oxford' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'dressing c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'drummer derby regt' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'e r a 3' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'editor' (lang: en)<br />HISCO: 15120, Description: Author","Input: 'ekstra folkeskolelaerer' (lang: da)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'engineers assist l c c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'engraver and designer art' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'engraver of gold' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'engraver on metal' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'etud en loi' (lang: unk)<br />HISCO: 12110, Description: Lawyer","Input: 'evangelist church a ny' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'ex-schoolmaster' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'fd naemndeman' (lang: se)<br />HISCO: 12910, Description: Jurist (except Lawyer, Judge or Solicitor)","Input: 'folkeskolelaererstuderende' (lang: da)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'folkskolelaerare' (lang: se)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'gentleman of the chamber to th' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'headmaster of school' (lang: en)<br />HISCO: 13940, Description: Head Teacher","Input: 'hoogleraar wisnatuu' (lang: nl)<br />HISCO: 13140, Description: Teacher in Mathematics (Third Level)","Input: 'horticultural lecturer' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'hotel keepers sister' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'import accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'in rect of relief from st mich' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'interest c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'jewellers artist' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'journeyman sculptor' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'juris kandidat' (lang: se)<br />HISCO: 12000, Description: Jurist, Specialization Unknown","Input: 'kgl kammermusicus fravaerende paa en kundskabsreise til norge og sverige' (lang: da)<br />HISCO: 17140, Description: Instrumentalist","Input: 'klockare' (lang: se)<br />HISCO: 14990, Description: Other Workers in Religion","Input: 'kloster jomfrue' (lang: da)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'labourer for engravers' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'laerarinna' (lang: se)<br />HISCO: 13000, Description: Teacher, Level and Subject Unknown","Input: 'laeroverkskollega' (lang: se)<br />HISCO: 13200, Description: Secondary Education Teacher, Subject Unknown","Input: 'law writer accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'lawyer' (lang: unk)<br />HISCO: 12110, Description: Lawyer","Input: 'lecturer in metellurgy and che' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'lieut r n vet secy e a f c p' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'local preacher coal agent' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'lombard st rector allhallows' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'london docks' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'mestre de minyons' (lang: ca)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'methodist clergyman' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'min of c s church auchialeek' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister connected with brethr' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of bargeddie' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of free church retire' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of kirkben parish' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of leslie free church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of millsex q s par' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of moffat free church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of rosebam u f church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister retired methodist chu' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'ministre' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'monumental sculptor' (lang: en)<br />HISCO: 17000, Description: Composer or Performing Artist, Specialisation Unknown","Input: 'musician' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'musician kings dragoon guards' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'naemndeman' (lang: se)<br />HISCO: 12910, Description: Jurist (except Lawyer, Judge or Solicitor)","Input: 'national schooll mistres in co' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'notari' (lang: ca)<br />HISCO: 12310, Description: Notary","Input: 'nun' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'occupying a farm of 39 ac all' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'pastor' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pastor baplist' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pauper in receipt of relief of' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'perpetual curate of chatburn' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'perpetual curate of stoulton' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pitch speeder' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'pontytrian minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'preacher bap' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'predicant te jutphaas en not mentioned in source' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'predikant' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'prepetual curate of the' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'president of collrdge' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'priest' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'primite methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'prof in u of m' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'professor medicina' (lang: ca)<br />HISCO: 13130, Description: Teacher in Life and Medical Sciences (Third Level)","Input: 'prostdotter' (lang: se)<br />HISCO: 14120, Description: Minister of Religion","Input: 'proviseur et retraité des chemins de fer' (lang: fr)<br />HISCO: 13940, Description: Head Teacher","Input: 'provst for falsters noerre provsti sognepraest i oensleveskildstrup' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pumitive methodist minster' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pupil in seminary' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pupil teacher al school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher candidate schoo' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher church school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher f ch school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupile teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'rabequista' (lang: pt)<br />HISCO: 17140, Description: Instrumentalist","Input: 'rector of adstock' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector of south ockendon' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector of stangunllo' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector or barningham' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'religieuse' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'retired baptist minster' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 's mpreacher' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'sagfoerer' (lang: da)<br />HISCO: 12110, Description: Lawyer","Input: 'sagforer husfader' (lang: da)<br />HISCO: 12110, Description: Lawyer","Input: 'school master' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'schoolhoudster' (lang: nl)<br />HISCO: 13940, Description: Head Teacher","Input: 'schoolmaster' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'sculptor marble carvery' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'seminarielaerer' (lang: da)<br />HISCO: 13155, Description: Teacher in Education (Third Level)","Input: 'senira master of languages' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'skolemester i sognet hosbonde' (lang: da)<br />HISCO: 13940, Description: Head Teacher","Input: 'skollaerareaenka' (lang: se)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'skollaerarinna' (lang: se)<br />HISCO: 13000, Description: Teacher, Level and Subject Unknown","Input: 'sm kandidat' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'soemandsmissionaer' (lang: da)<br />HISCO: 14130, Description: Missionary","Input: 'soeur de' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'soeur de charite' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'sognedegn hosbonde' (lang: da)<br />HISCO: 14990, Description: Other Workers in Religion","Input: 'sognepraest' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'solicitor' (lang: en)<br />HISCO: 12410, Description: Solicitor","Input: 'solr ba of oxford' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'tamboriner de artilleria' (lang: ca)<br />HISCO: 17140, Description: Instrumentalist","Input: 'teacher' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'teacher ladies college' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'teacher prepare candidates for' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'toneliste' (lang: nl)<br />HISCO: 17320, Description: Actor","Input: 'tresoreria port empleat' (lang: ca)<br />HISCO: 11010, Description: Accountant, General","Input: 'trompetter en not mentioned in source' (lang: nl)<br />HISCO: 17140, Description: Instrumentalist","Input: 'tutor' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'u p preacher' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'unitarian minister of upper ch' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vanmarbaker' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'vicar of elberton' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of littlebourne' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of st lukes gloucester' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of tharston' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of ullenhall' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar st pauls morley' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vise pastor hosbonde' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'wesleyan minister b b lond' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'wesleyan minister new inn st c' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'weslian rev' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'writer' (lang: en)<br />HISCO: 15120, Description: Author","Input: 'zaakwaarnemer' (lang: nl)<br />HISCO: 12410, Description: Solicitor"],"mode":"markers","marker":{"color":"rgba(217,150,141,1)","opacity":0.69999999999999996,"line":{"color":"rgba(217,150,141,1)"}},"type":"scatter3d","name":"1","textfont":{"color":"rgba(217,150,141,1)"},"error_y":{"color":"rgba(217,150,141,1)"},"error_x":{"color":"rgba(217,150,141,1)"},"line":{"color":"rgba(217,150,141,1)"},"frame":null},{"x":[-32.022541132733089,-7.9909694670104958,59.916692953884194,48.259880213325026,-10.082247451726525,-83.307993813987338,43.295746160799098,-3.5679690014037906,-70.994338583079156,-3.9335893027152782,-58.504052453830944,-36.343675577928465,-17.962262157706949,43.930268664266734,-6.5705386978036939,-11.495295581648417,53.839843538568395,-33.33245661714863,18.680101530327626,10.902530449151246,2.4565772606277281,4.5229295741710374,54.511856050701937,-66.620379897812569,-73.597396062370365,-35.707741358922789,45.802004850083364,-33.719282083401758,19.817788244799157,20.444597900311766,-49.708904445600695,-19.076873735390258,62.303305393816515,86.134311568886332,-12.228645952001409,39.871032430775813,9.177748733126684,103.31723606849074,-21.140446543259898,-18.220270168969442,-26.097018280343036,-39.164006160560717,66.907534836779774,54.58568241313796,89.397833643549447,14.61665817910934,65.902177363951083,-68.44159532202373,-15.438709703988383,32.276571129812162,-33.872120321025648,101.74667595022996,60.986265282556438,91.834544570927235,-8.5557419484514821,-52.980565746844889,21.838650016224729,112.01760762683513,-47.877388780009575,41.696969929947386,42.938635684172759,5.9476225854985758,-32.280307731137157,-15.969431696856487,-42.405760209676536,-36.392506956139918,-51.367578811976486,-34.404671208772804,72.125932951346016,62.033674782549177,11.790601269999673,36.441691285238605,-27.598751279142899,-45.753394552237793,-27.964401567523549,-0.32049232639905378,-14.733270716273063,39.042981544793214,85.351352637025329,103.74306909348265],"y":[101.79121686452103,-77.315157503728443,57.480099506654611,1.1091340098090825,-191.03949975821686,13.496530315671832,139.39579195613015,-7.1507799861264534,45.849468601029088,51.215036644837689,85.420226612175597,0.12235372461848533,100.34278271515136,123.18462225793866,14.521659100270856,95.375482859110178,140.51814699090895,-114.90612214083974,150.42446771821292,-184.81663028135696,-140.26286901293713,-137.77065625194203,68.259527357592191,62.026041413432203,-80.197329064191038,144.8806358524634,7.6787335292223373,96.008191790062895,85.536555369686312,80.719052547541011,-40.674712583399725,111.04695846827428,-30.266584609319175,102.31019953770878,67.224149208414687,75.216684331631654,-55.802751965427554,116.53642006397249,-151.36394426120395,-186.69617266597655,-129.14411456662629,133.05579975064813,-27.505963248351819,-93.322527087230512,40.920405102428823,-155.68869818712497,27.013917495107151,-75.65965230096522,-207.94503352930101,126.44765152957827,42.836462632814118,47.962953769060718,65.337485282763026,116.24182899018869,50.446145486854974,53.435229595580466,83.847827226752699,94.22152827652063,65.65658019382613,46.193156292741619,91.012923410680472,56.084263487083263,97.034780875505277,29.069335040593359,-19.770211496255275,91.268167683878914,-174.67115390424732,-190.80282127837495,104.63747533494487,78.457799363283996,-175.69099961810994,10.825138828633596,130.04388699039191,-185.60248289705399,41.808811479346623,-208.04833886128566,26.448761964866055,55.79248290204135,48.981466066548762,73.126830365898954],"z":[36.361745203316254,-10.353673239616045,-121.64029736190537,-35.099328234016745,12.277615225866665,24.539407280480059,13.841965997267755,-6.3399529111333832,67.238326951026991,78.393698117104634,78.160882112060776,60.927645538930101,-42.42871623036185,-32.767671680307309,88.534604921969333,-8.6435630953187452,12.834817201601096,50.61508534304938,-13.878926770417344,-7.5313563359023927,-44.53315112514391,-40.921272232077854,-29.829265491034725,-18.595796872723014,14.093301235285784,4.440748292213514,9.5024958247687774,57.488064577030251,-32.377757881018049,4.7435347835414667,63.873046936844666,50.725101750839471,-53.479158709650719,-114.75989150194943,-7.6930203111735924,21.794688322324347,57.847229425095605,-18.880051447609087,36.979189678947627,10.500073389286355,2.7384707927943399,29.981841026124641,29.578119967367737,-29.292064541095442,-35.949791773443209,11.401301049919034,-28.48027470525345,39.751426372659772,17.104731279768888,-42.230590571240107,92.479768757525648,-115.76707532250533,-88.530475318885124,-24.957538762236865,77.673264178074504,-27.204561758003457,14.119482959756906,-17.95074641162611,85.745936504105543,28.329802783861997,-63.331068640018906,76.241815938366059,57.436217483545391,112.86951187527562,101.38596306128095,64.089110071242914,34.355599857010553,60.676551248021532,-31.330960490999804,-68.038877994679154,4.0756522415843444,-14.353763436137386,15.875812275693518,64.57746517500803,84.065365770433019,2.8742775887488126,114.96820125266679,-79.829410670115664,-118.98265594710138,-33.835149098376924],"text":["Input: 'agricultural foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'batlle aigues' (lang: ca)<br />HISCO: 20210, Description: Government Administrator","Input: 'bestyrer' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'bestyrerens hustru' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'bestyrerindens barn' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'brass caster' (lang: en)<br />HISCO: 22490, Description: Other Housekeeping and Related Service Supervisors","Input: 'bricklayers foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'builder and contractor' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'byggmaestare' (lang: se)<br />HISCO: 21240, Description: Contractor","Input: 'cabinet lock manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'coal mines manager' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'colliery proprieter' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'colour manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'contractor' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'cooperative stores manager' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'cotton manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'cycle manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'directeur papierfabr' (lang: nl)<br />HISCO: 21110, Description: General Manager","Input: 'director' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'disponent' (lang: se)<br />HISCO: 21110, Description: General Manager","Input: 'engineering foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'engineering manager' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'farm bailiff' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm foreman' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm manager' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm steward' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'fd foervaltare' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'file manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'foervaltare' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'foreman (deceased)' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'foreman at newspaper offices' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'foreman deceased' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'forvalter' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'gas inspector' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'gas manager' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'general foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'godsaegaro ingenioer' (lang: se)<br />HISCO: 21110, Description: General Manager","Input: 'godsforvalter' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'grosserer senere nationalbankdirektoer' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'handelsfoerestaandare' (lang: se)<br />HISCO: 21340, Description: Sales Manager (Retail Trade)","Input: 'hans huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'hat manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'husfader husfaester skipper og skibsreder' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'hushaallerska' (lang: se)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'husholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'husmoder inderste lever af husflid' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'huusbestyrerinde soster' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'indsidderske og fornaevntes huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'inn keeper' (lang: en)<br />HISCO: 21420, Description: Hotel and Restaurant Manager","Input: 'inspecteur des messageries' (lang: fr)<br />HISCO: 21960, Description: Transport Operations Managers","Input: 'inspektor' (lang: da)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'inspektor' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'jobber' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'joiners tool manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'keeper of the workhouse' (lang: en)<br />HISCO: 21940, Description: Administration Manager","Input: 'lantbruksinspektoer' (lang: se)<br />HISCO: 21230, Description: Farm Manager","Input: 'manager' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'manager of boot and shoe shop' (lang: en)<br />HISCO: 21340, Description: Sales Manager (Retail Trade)","Input: 'manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'mine agent' (lang: en)<br />HISCO: 22620, Description: Supervisor and General Foreman (Mining, Quarrying and WellDrilling)","Input: 'muscumsinspektor cand mag' (lang: da)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'nail manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'onderdirecteur bij de bank' (lang: nl)<br />HISCO: 21110, Description: General Manager","Input: 'opzichter bij een cementfabriek o' (lang: nl)<br />HISCO: 22690, Description: Other Production Supervisors and General Foremen","Input: 'opzichter rubberplantage' (lang: nl)<br />HISCO: 22660, Description: Supervisor and General Foreman (Man. Paper, Plastics, Rubber, etc.)","Input: 'opzichter van het stads modderwerk' (lang: nl)<br />HISCO: 22680, Description: Supervisor and General Foreman (Man. and Distribution of Electricity, Gas and Water)","Input: 'opzigter publieke werken' (lang: nl)<br />HISCO: 22675, Description: Supervisor and General Foreman (Construction Work)","Input: 'overlooker' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'pdg' (lang: fr)<br />HISCO: 21110, Description: General Manager","Input: 'post office official' (lang: en)<br />HISCO: 22220, Description: Postmaster","Input: 'railway examiner' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'road foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'schepen gewezen en not mentioned in source' (lang: nl)<br />HISCO: 20110, Description: Legislative Official","Input: 'slottsbyggmastare' (lang: se)<br />HISCO: 20210, Description: Government Administrator","Input: 'sognefoged og laegdsmand' (lang: da)<br />HISCO: 20210, Description: Government Administrator","Input: 'stewardess and housewife' (lang: en)<br />HISCO: 22440, Description: House Steward","Input: 'sugar refiner' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'symaskinefabrikant' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'wharfinger' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown"],"mode":"markers","marker":{"color":"rgba(152,158,202,1)","opacity":0.69999999999999996,"line":{"color":"rgba(152,158,202,1)"}},"type":"scatter3d","name":"2","textfont":{"color":"rgba(152,158,202,1)"},"error_y":{"color":"rgba(152,158,202,1)"},"error_x":{"color":"rgba(152,158,202,1)"},"line":{"color":"rgba(152,158,202,1)"},"frame":null},{"x":[-7.4117890614996886,-90.446094860108019,105.09534995368222,-45.326547324999353,-23.329736774906994,-27.695445308655589,13.590835100028778,-10.307782648217113,0.7249653069504961,-59.997179334178952,109.52468210084099,49.481561158049459,98.657324579075876,33.412610261773459,-55.580021751808076,24.510101442871505,-47.771874062852135,49.161907239041447,58.445758319531379,-73.402589249591458,-15.196915917959213,51.662582574424142,-12.332714751330343,123.72076534042016,39.794227811410572,-29.192021195896398,9.5864930129957475,13.290932346281126,-51.873101427359074,49.682217050586914,-38.136296298814656,103.41660780245452,-26.487580045507311,46.158321869471592,16.248917510674218,-61.408792568281079,-24.110820988844036,1.2735455637760451,-39.090233717354984,75.335608587595843,-42.72704797159264,33.507206687990838,5.8106954358612288,73.879282397961376,-49.69319327719338,64.036225332293412,-50.632521848889105,42.071079982605681,-61.393511276422267,10.965534218304077,31.457362947520295,9.5312248818690115,26.305350327243936,-59.110481261095302,27.10999105975516,19.762357943008283,16.45458856003378,-58.480268459793585,-48.462892737657114,-48.591380209132254,-33.384590496175633,-17.935111737449947,66.469048602743243,-27.727049989068085,-60.737865924718612,-4.9616082528054637,-61.438752803968868,36.751125780513583,29.910198076523187,-84.488302102480645,-6.7610862772113212,-20.057728810721692,22.094643181800439,-37.419126148359162,-61.967018464263653,-11.757224720213769,-0.26264730638368305,-51.261420082644207,-80.203741451750588,-57.03664457144896,-45.869051385707166,-57.162046203150929,9.9056049447812669,-56.798973037416339,-64.836809851693886,26.382428707821358,-6.2077507388717503,54.731514096715514,-26.437226253720961,-24.4928268376629,-19.0488688476246,-26.750823524193166,-16.571001592879412,-46.909202897953399,-60.953393713724481,-45.698777336845225,-54.209521488516735,4.7502400743130089,-33.173992445491137,14.364248175796199,-74.773800819483697,-76.134105852444108,74.441474099542248,-10.497536757782534,-52.319640458076243,-50.670160373845974,-51.390821534729646,-41.549550870332453,-15.795733925025752,5.757809406949657,50.621467350321836,60.076815186945218,-3.0713273612392116,-11.376377441738327,-14.860380294250673,16.044636814053046,-18.289780977238777,-1.7684142473528233,45.889069209504228,6.1587852123643003,40.898578909537946,76.286655755085349,-38.166993758357258,-6.9902175054008451,28.144491090800997,20.764148301945397,-39.856835571634605,1.5134667096697085,20.365323889355775,-7.4531068337219057,-16.824213628803776,-2.1244294243878654,-77.25125242588075,29.118382623647847,-24.375229310054262,29.723540068695208,31.392049676374207,-49.782323814541229,-10.885749475239754,10.289052590913393,-66.296141113271474,-0.26182305510142945,-32.407880496934432,-57.317075721104715,-30.438784739846049,-48.83712522389834,-24.674989596174701,91.204498973037033,-5.6589384876725344,-38.612424973729055,-2.4879219897335609,7.8411325450214244,-52.626856082345363,-35.261003835073005,-24.978264717422693,9.5212847083280199,-19.786543225365261,-3.6354962250221079,89.834504260121264,15.32244214126168,-24.755103749028841,-84.345421779491417,55.463411856401848,-51.528628532314066,20.852873589669073,17.701173246903942,42.806860395942891,45.917269025826933,-16.956183873375384,-49.534363366125504,10.441996909431882,-33.936614020854698,4.2482789773037251,-35.7658702274001,20.49778206669021,-22.954392453845099,55.557712154155496,-56.172720770125999,5.3652375948039674,-49.85082138048331,-48.309757266932365,-1.1129906788718578,-32.062385963213508,-67.457670699757855,10.653257822055746,-34.737413050919443,40.012672800272199,-20.952081510300207,-67.523750364112885,4.6485990411237887,-55.396866009351264,-6.4304577498144742,-53.893406972194384,1.7590992018792715,-58.692015541785793,5.9518266274773461,-52.534081997644648,14.934333053658117,-56.708242879324786,29.051682780592976,-5.8803433595934802,-13.754987901951241,-45.764421604272009,-4.0506141662474322,-36.069341825115544,-46.722309917052989,-13.032497882325114,-30.775668074560677,4.4317894876112289,85.227687420795192,36.869936618676846,51.919941724376038,-45.991782237016089,-25.777769426746673,-39.34110918873612,48.824023528693047,-15.274085234085137,-30.546071964389508,41.330437938528178,27.463091115488769,62.563372117666354,-35.741097168015138,14.705281183535918,99.840607039567317,-36.202157445866909,-26.835517167929908,46.550209665875926,11.896308010044738,-37.462727716949011,2.4348039777433401,-52.281089886526146,49.378557004969757,-42.216434762920898,2.7826062309151753,-37.053175689940353,-60.634624467099329,9.7338786746383335,-38.530975575137631,-40.112522002517842,-37.473894182979748,-13.870588031795011,-48.924834209008743,-90.709056627660843,-5.3371909649911364,57.283305831692907,-68.994274815157382,-18.311470248255915,-5.5404639100610416,87.630942507364409,44.190768401800732,16.926918211127276,-22.629991310396374,-60.031353083524579,2.8778469616798943,5.6088574267405003,-33.660927689965163,30.122006504482762,-15.436212590463214,23.714426905590258,-4.7445772132947859,44.877768527154515,86.506355814309487,-64.677761573566642,37.54122871735099,2.7114399603990464,11.941048905997254,1.0875250641995855,24.595337134149975,26.465826014822753,-5.1209720169931474,15.551513097943184,7.5707013172008999,-7.5216656968215041,-36.052528895162695,69.723700883157377,-34.978313643092427,22.567528123554887,-6.4120138079241329,51.627725830205236,-37.266808766681571],"y":[-53.794142124974044,32.189635229914124,98.251339032057828,-25.006813889210051,35.720532815415254,-194.36345689325677,-51.691199025305579,-7.0373660288070257,53.239028425467389,62.704296704415746,94.775757108892478,55.393285740932839,107.18453469101877,89.777774103410323,-188.89746405195743,132.00931133246451,46.582313515721495,-5.1497211739733393,176.62268759803047,-48.219401950718293,110.2191007572461,64.464462432315713,-166.10708207285452,79.877221137298818,23.340167752198237,40.796896968879125,107.82515337670991,16.785568440508243,72.857730776665363,73.382614881145713,32.042018798651526,70.914369120583302,-198.67679373759694,159.99381086284225,-36.188786365682233,59.673220785474577,103.48483455456912,-97.912255473916119,-79.178706332756789,95.512965081360235,48.049428607712514,10.133400998755498,-117.14213183663585,96.241312995731533,38.061411308019252,65.749096586057973,91.626087747259433,62.231482810507622,-74.696367857822054,-182.24764158188756,13.804783947241932,-33.640439354424949,-55.26099977474076,31.129963308410478,-79.590345104801429,26.166881339461717,-24.728336725016348,19.818972151419185,-69.075013261646305,-61.904910070062179,40.820966847209036,-108.82573569244897,5.2431220432132903,-0.39647537867363081,-56.545747173595487,19.400426689398721,29.871016433459516,-107.14836690402592,124.11541830457337,3.7733804894574234,12.086410341545973,64.754705193695187,25.601222159666232,-111.89040998061738,35.1900974414716,121.98898833963185,7.633325730225196,120.01205541164047,-41.162440780020312,-33.880809480112219,66.647577445713608,102.97866915993322,104.41591165279313,32.558176718144807,-82.963979864031131,-67.699988569032868,20.07615439712005,-75.86989855171214,134.14148419102509,23.184934972646243,-174.07620179063497,127.09280682640619,-95.170409756437806,74.61324533475026,34.441618500824134,-61.866180477590554,-27.686441266020957,-25.406795961941505,-126.17387416684259,-33.63897814888827,-42.675212488813102,-56.776394393963592,87.459949715621519,79.08145127924972,30.567592950522954,-190.87282840732314,32.017152576212005,79.394179866954644,-106.90160602586812,-130.20373839794252,2.3129097627004596,-27.834874713697275,-115.20658137675004,-209.77580809769921,87.513671969117198,-151.90673375735716,72.011889095990611,-137.68743340978367,31.60204464821383,99.916224425771588,77.148772190479775,94.930191994496454,150.17462290825966,-193.55070331945129,-69.497463904529042,-127.72965572383751,-25.726035843093364,-114.77056287248367,-69.736353889566132,-54.590568240885922,-88.722319192540837,-43.013916362872394,60.671871226310415,17.133705400838345,-159.98841528235744,-72.038504577848698,-53.534928790264807,-153.29174216439836,-63.733744529199775,30.099902024876268,51.270081745996251,-5.6118789886990292,45.239835306750869,-138.53159023144954,9.3204272499563174,-71.528816311504727,-115.00781995288638,32.884500383084259,-198.49141007857295,107.83729025361048,-22.488165007885932,-208.3428863249043,85.166021034777998,126.27017947174308,120.44419727033311,-205.21673966467424,-106.81514965457178,-100.32473513981567,37.646975078953524,-166.74059933908802,36.157022739950989,20.108825551169122,-70.093138325756087,-172.63991050036847,33.739723954834865,-148.47165200281285,110.19919991372385,60.158377023110965,-113.26239426301819,15.128559365058525,-186.01073220746591,5.6290907862202353,-113.79464915187845,38.730596103180986,100.39549323597761,-11.911411030646134,93.024696754763298,-21.415350157029906,32.796969417696609,113.59102849320219,25.814517571808747,-3.1058071073266889,58.285372484737564,-16.858096091995208,25.337688904875087,72.285849843529519,-8.8493777854756122,-78.63845885844178,-9.8346028248118955,-84.849281064138623,-22.692993259618984,11.338193463698019,18.40326159800291,-2.516737179540748,25.499775936820839,-68.514515224058044,87.650807358426249,-25.938823148969348,107.44022796987387,-67.395745425610542,13.794792161860677,-11.733873699483517,-131.9308706832895,-81.783956853355662,11.725425821794307,-20.028224577682092,56.235560956853575,145.71813267034233,-76.764451151470581,74.86366186337051,-90.069243980752034,147.18812829878573,-95.694048303194833,133.69894429858499,39.063929149781856,9.1193801642766328,-13.36766898383628,-35.039460237678043,84.638188167909121,-29.73216241538794,-22.762608566879589,-69.893966015897462,-120.18810477639032,97.488022341804481,-188.98399172024725,9.9452735767592291,109.10878739579893,-155.19187492447358,-36.643941494389743,-33.450348135318031,61.030236077022877,71.494120602253389,-14.283252989207821,-99.033380932020194,28.216640593858777,65.545736932766573,123.71182549302851,39.131002547051033,38.157151757530251,-84.1625250225255,154.81942666990471,-74.659115929828189,33.585667278326056,-105.20513057860039,131.27724532663055,-55.0623967418855,13.715994677987826,-105.9755327753431,37.138870169877073,18.185266499839898,-157.68195525665567,78.087724894653718,72.811839193460429,-88.030995541345334,120.67151851075734,-7.6968557804970779,31.386396126294855,5.7440070024640848,72.936983460601823,-38.544983791043826,144.92383914141718,72.536225065704542,44.291037677014138,-40.496970404409126,80.309160644577659,-137.74316860249291,-24.91373667088935,-142.84677084315948,-142.2623248485566,110.14684674160148,-165.35348799971445,-115.26414258706114,141.975793373892,-8.4749887163748863,63.847544996451909,121.43460623048855,-30.358098217688994,-101.57956155572309,142.61932072436599,-72.994511708162406],"z":[-17.869966384274239,32.873117004310537,-26.762156192884397,-6.0212257202729011,119.69811170854307,38.544894611808225,78.349741102019209,-1.9227571231678784,49.368740984492987,104.3260071262399,-21.296644269597401,-41.688715299678336,-41.903786145587979,12.202589935171224,45.370266547108891,-38.217578004035701,120.51547840271054,6.6240309284003764,-1.6658969398617776,48.655727685221223,38.650115823713271,-33.905569775221387,-5.4330584680641154,-13.123741333407795,-1.9241532832419632,87.697057082493913,-28.512481605652436,-48.161238663937773,90.885315542025623,-33.739660584806167,63.095020610963928,-28.37639636812888,10.870553409272729,-10.112442966556088,-52.041156166439585,84.161088920086058,-35.670547635356996,-25.400368612748856,54.651365174751554,-11.762757117092789,49.833940143781341,-39.619879830741958,-27.881181260154353,-11.212600669919535,80.593070668042699,-92.618017699920628,-24.003150006894575,-31.276224181794404,-11.413899333411791,2.344668535239173,-16.541758351514144,30.273658220679323,-44.571494650789468,54.560798002757139,-37.821286647748259,-45.581222471633446,-38.641748991720227,19.020528154976365,55.208958360066006,40.422692323360863,64.015692615257507,-9.6835955536194387,-37.111921806320318,39.696494911606528,-11.879992328514746,85.97249065204818,-3.4087528250164447,3.1802498219735988,14.80885165844361,-14.395172893848748,47.406965503618643,13.045122069832946,-48.415860039007924,30.813181886503678,-12.601443677672073,-24.947962558122388,55.077113464155538,-5.5425580998401083,60.447811386741606,57.80879147563445,31.344810099612655,14.657055781603153,-38.051658353507172,-9.2123388487620037,7.9184666698285104,52.540826794346735,-49.887865490391022,-8.781078053274296,1.1428019782298311,-15.185378479867056,-13.217413256213705,-13.265145932574187,28.27637050468153,43.880602306848239,-2.1541397747526552,-10.977548265694063,-12.542785901429749,-34.968204777911772,17.482494428845971,-50.497549645864197,43.497316443405346,92.480522278591735,-56.739045867541435,62.596949395833306,82.901068594756907,45.391827212869856,-4.4198134515677872,-9.5210413948308421,6.4828279372961566,-34.639456951479687,1.2224222570175594,-57.505513218686232,49.395592002713421,4.9884754617883944,88.636319077051368,-33.150476505839769,88.765159962877775,-10.15887585390314,-45.578313415299029,-65.625568263406507,20.428366954402875,-111.21858859787473,-4.0528020683578667,-15.618064768359442,-56.786575541299108,-21.684421618737126,68.143512711870557,5.6340521102400238,42.598054699648571,-24.122202586106116,-29.867191220001747,-12.548299028548911,29.33798694174375,-11.537307142153781,-8.4000149245580182,-21.27725408958479,-24.285200430769503,-8.4623775669217931,-4.8112787382022164,-31.443745391807148,105.04826934805408,53.926389567048822,118.38726639439415,13.791589509180296,93.661624562707232,57.482956851421768,72.917591924327454,-107.32192674315206,-6.9063480667253048,35.40771278340813,-35.619670495013196,-5.3521890249341686,92.887990688274769,-13.199742503930777,-13.017277296105979,-1.0738492224417651,28.738313887207962,36.038101829183319,-114.10431200364508,-33.722206825099029,117.51417807746942,37.795311649596798,-33.335201163449767,10.572124235991804,-40.439202999153387,-20.650353822279769,-81.06631973221964,9.9937233485532371,-38.361793225920046,47.548891815723671,2.6050700122789272,70.335880645834052,-0.97245427360536718,57.305760033247779,-25.428501868999948,34.634451176632957,-24.387701052816045,19.074864258480506,21.377247310968759,65.035945486450146,-20.564221331319683,54.153272845342869,9.733719866082831,-3.3956722954820924,-24.973290475856583,-17.667613141485401,-80.204922981652047,66.809008872814061,49.730816793487783,45.84667350960332,-2.6752735407847461,-43.905027387141402,17.58443841429515,7.9332157435378603,-16.323884818884608,-3.5904781890985533,89.97742264664511,-38.10314829177495,-14.735692160389879,-56.14471442425716,-48.993862443292571,97.48631361762007,17.914447923316484,16.917157818910315,57.705839818492784,94.247149713491496,7.9496226006260065,-7.1372191302378276,-13.467574969874454,-120.45938177610188,-25.685833594880371,-26.879146903278784,19.258272275745725,3.4078196426774854,66.157124600474731,10.873135236724609,96.089848055355418,51.160507234401173,-21.320623732824103,4.5686182193893021,34.052687448696027,62.277833833706481,-10.597996977925083,-19.285451826310648,62.17729056401911,89.788894126905888,-33.417564851344331,-1.0206438896812573,97.678828472552681,-43.485064372719648,84.685284558705007,-57.326764370505209,98.280138268198229,37.552028239865436,-32.755894524066392,82.933398885870432,-32.916341244053527,118.07281777343283,117.14496283261877,53.688979341880724,1.3632423178144695,28.840097992000342,10.226588813646318,21.842361981781472,-1.4307749259576616,5.8419074206547723,-16.609443127437963,24.108421983300435,-122.85461491476394,-52.06872622843138,-15.632485482031695,62.322449363039851,100.39419383580072,33.768550402784477,-39.02517269961146,31.085880791294727,-68.740362358910758,2.6948687488824725,8.9210445912611362,25.206486154384393,-21.283393827772567,-126.64845648170075,-2.594969187159351,-42.599708250057567,-35.774316141866947,-36.356931877471865,25.594253962812495,-26.852408934968405,-26.15926979411276,-38.472457446957428,-37.754559616341744,-23.955849304258628,18.548882823758937,40.481568917586337,-90.824016666834723,-31.693308087972806,-15.382890731622119,59.663012629206165,-18.147601579498083,62.158750978791403],"text":["Input: '1 london county council distri' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: '1e commpolitie' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'accountant' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'accountant office messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'adjunctcommies bij het departement van bz' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ambt 2de klas der liniedienst' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ass boekhouder' (lang: nl)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'asst assessor city' (lang: en)<br />HISCO: 31030, Description: Tax Assessor","Input: 'attorneys clerk law' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'auxy postman greengrocer' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'bank inspector' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'barister clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'beadle' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'besteller' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'besteller en not mentioned in source' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'blank clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bode provinciaal geregtshof van overijssel' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'bokhaallare' (lang: se)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'book keeper' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'book keeper provision trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'book shop porter' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'bookkeeper' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'boot repairer errand boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'brakesman coliery' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'brewers hay clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bunkin clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bus conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'c s o rural postmistress' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'caol clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'capt roy guard reserve' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'cashier' (lang: en)<br />HISCO: 33135, Description: Cashier, Office or Cash Desk","Input: 'cashier 'asbestos merchant's'' (lang: en)<br />HISCO: 33135, Description: Cashier, Office or Cash Desk","Input: 'checker' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'chervant' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'chief clerk to insurance coy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'civil servant' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'cl h m castoms lon' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'clerical officer ministry of ?' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk at bradleys westbourne g' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk at ch' (lang: en)<br />HISCO: 31040, Description: Customs officer","Input: 'clerk at wire works' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'clerk b' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk chemical merchants' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk confactor' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk cork mercht' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk drapiers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk ed in burgh city roads' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk file warehouse' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk fo work' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk galvanisine works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk general store' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'clerk genl po london csc o' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in an office' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk in coal of' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in coke wks' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in county court cso' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in liverpool bore gate' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in london city mission' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk in merchant office' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in paint works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in statehouse' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in stoneware pipe firm' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in truck agency' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk lower divn admiralty' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk mercanetile' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk of insticiary' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk of works' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk on hogordgis' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk or warehouseman' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk plate works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk po c serv' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk provision salesman' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk rectory standish' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk rly cos' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk shoe trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk silk curtains' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk stampers brass' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk steam ship coy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk steward golf' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to a brewery compy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to a doctor' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to an insurance company' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to assistant overseer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'clerk to bedding manufactr' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to iron works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to manuf chemists' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to no s' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to publisher' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to the general steam nav' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'clerk tob manuf' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk trunks makers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk wholesaler fruit merchan' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk wine brokers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk woollen cotton dye hou' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk woollen mall' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerkcoal merchant' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerks printing office' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'coal companys clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'coast waiter' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'collecteur en not mentioned in source' (lang: nl)<br />HISCO: 31020, Description: Tax Collector","Input: 'collector' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'collector (deceased)' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'coml clerk chemical but ens' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'commandeur op de werf en not mentioned in source' (lang: nl)<br />HISCO: 33190, Description: Other Bookkeepers and Cashiers","Input: 'commercial clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'commercial clerk silk brokers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'commies dept fin' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'commisgriffier' (lang: nl)<br />HISCO: 39340, Description: Legal Clerk","Input: 'committee clerk and bookkeeper' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'comptoirist' (lang: da)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'conduction pullman pc co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'controleur bij de landbouwcrisisdienst' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'corporation clerk' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'correspondence and shipping cl' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'custom house boatman' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'customs officer' (lang: en)<br />HISCO: 31040, Description: Customs officer","Input: 'division officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'dressman h m d y' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'earant boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'engraving clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'eo toldfoged' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'errand bot milliners' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy school' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy grocersmess' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy in office hupping' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy johnson grocer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy stationers temporar' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy still at school' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy to joiner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'examiner of master maker bond' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'excise officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'facteuse et detenu' (lang: fr)<br />HISCO: 37030, Description: Postman","Input: 'fireman in fire brigade' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'florists officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'flour and grain merchants cler' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'fruit commission agents clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'gartar clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'general clerk and house and landed proprietor' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'general merchants clerk unempl' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'goods agen of railway co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'h m coast guard cond boatman' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'half timer to a confectioner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'high bailiffs clerk county cou' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'hoofdambtenaar bij gemeente secretarie' (lang: nl)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'houseservatnt' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'husfader by og herredsfuldmaegtig' (lang: da)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'inspector armory' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'inspector of poor slater' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'inspector of schools, ireland' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'inspr of poor collector of rat' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'insurance clerkess' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'insurance cos clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'insurance official to the offi' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'iornmongers messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'ironfounders agents clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'jagtopsynsmand' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'jernbaneassistent' (lang: da)<br />HISCO: 39960, Description: Railway Clerk","Input: 'kantoorknecht bij posterijen' (lang: nl)<br />HISCO: 33170, Description: Post Office Counter Clerk","Input: 'knecht bij van gl' (lang: nl)<br />HISCO: 39990, Description: Other Clerks","Input: 'kolskrivare' (lang: se)<br />HISCO: 39120, Description: Dispatching and Receiving Clerk","Input: 'korenmeter en not mentioned in source' (lang: nl)<br />HISCO: 39150, Description: Weighing Clerk","Input: 'kronolaensman' (lang: se)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'kustupplysningsman' (lang: se)<br />HISCO: 31040, Description: Customs officer","Input: 'l c c tram moterman' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'laensman' (lang: se)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'law articled clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'leader railway goods dept' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'legal services other' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'letter carrier bristol post of' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'letter carrier nypo' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'letter carrier p o western' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'local' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'mail messenger p q' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'managing clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'managing clerk county cowel' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'managing clerk dry saller' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'mercantice clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'mercantile clerk jute trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'merchantile clerk junior' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'merchants clerk pawnbroker' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'message boy at percy st nc' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'message boy grocer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger at' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger at b warehouse' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger boy post office' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger eastern telegraph co' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger re mint' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger town s s comp' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'municnipal service finance cle' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'office boy jewell' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'office clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'officer of fisherier' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'oproeper bij notaris' (lang: nl)<br />HISCO: 39340, Description: Legal Clerk","Input: 'order clerk steel wks' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'parish clerk' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'parlors errand boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'pensioner prison dept' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'photographic factory messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'poor law service 1st assistant' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'porter errand' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porter leather trade' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porter millinery' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porters labourer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'post boy' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'post office cleaner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'postbud' (lang: da)<br />HISCO: 37030, Description: Postman","Input: 'postbud logerende' (lang: da)<br />HISCO: 37030, Description: Postman","Input: 'postman' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'postman st martins la grand' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'postol clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'preventive offficer h m custom' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'prison officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'railway booking clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'railway clerk and seperated from husband' (lang: en)<br />HISCO: 39960, Description: Railway Clerk","Input: 'railway coach guard setter' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway goods guard farmer' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway guard gt western ry' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway guard s w ry br co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway passing guard' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway servant' (lang: en)<br />HISCO: 39960, Description: Railway Clerk","Input: 'railway ticket examiner and out pensioner of chelsea hospital' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'range warden' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'red postman' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'relieving officer registor o' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'relieving officer registrar' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'rent collect clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'retired chapter clerk and regi' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'rolling m clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'school master of parish regi' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'school welfare officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'secretary c e z m s clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'secretary of colliery clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'seedmans typist' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'sergeantschrijver der koninklijke marine' (lang: nl)<br />HISCO: 39320, Description: Correspondence Clerk","Input: 'sergeantschrijver kon marine' (lang: nl)<br />HISCO: 39320, Description: Correspondence Clerk","Input: 'servants registry officer fa' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'sexton' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'sheriff off assist' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ship broker chartering clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'shipworkers clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'shop keeper' (lang: en)<br />HISCO: 39140, Description: Storeroom Clerk","Input: 'shop messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'shorthand law clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'signal man l and h h' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'skoleinspektoer' (lang: da)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'sola officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'solicitor assistant clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitor parliamentary clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitors cashier to magictra' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitors clerk articled' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solictr clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'sorter and packer' (lang: en)<br />HISCO: 33170, Description: Post Office Counter Clerk","Input: 'spannridare' (lang: se)<br />HISCO: 31040, Description: Customs officer","Input: 'stockworkers clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'stopman district board' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'store keeper h m convent dept' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'storekeeper' (lang: en)<br />HISCO: 39140, Description: Storeroom Clerk","Input: 'strandfoged' (lang: da)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'supt dockers h m c c s off' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'surnummerair rksbel' (lang: nl)<br />HISCO: 31030, Description: Tax Assessor","Input: 'surveyors clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'telegrain messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraph construction dept mi' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraph messr c s' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraphist' (lang: en)<br />HISCO: 38040, Description: Telegrapher","Input: 'time clerk' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'toldassistent' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'tolmeester' (lang: nl)<br />HISCO: 33160, Description: Cash Desk Cashier","Input: 'tramway conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'travelling clerk surveyors dep' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'trtamcar conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'tugowners clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'uss boat inspecter' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'visiteur bij de directe belastingen' (lang: nl)<br />HISCO: 31030, Description: Tax Assessor","Input: 'warder' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'wholesale competioners clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General"],"mode":"markers","marker":{"color":"rgba(215,144,197,1)","opacity":0.69999999999999996,"line":{"color":"rgba(215,144,197,1)"}},"type":"scatter3d","name":"3","textfont":{"color":"rgba(215,144,197,1)"},"error_y":{"color":"rgba(215,144,197,1)"},"error_x":{"color":"rgba(215,144,197,1)"},"line":{"color":"rgba(215,144,197,1)"},"frame":null},{"x":[10.648003198189521,-9.0894432012182982,-75.106055405667945,-72.9327759057268,82.688817960204489,-11.5364532268531,-77.109106430080345,-51.163172647606288,-85.505391923987645,5.0847354186439366,51.694530691943086,-69.428375362462845,-27.968977937972944,-29.677811473812032,-0.55311819700466358,47.241897622806761,-24.757523324450656,40.17349082807398,-47.687680118018363,-21.47980215589693,-78.803300121246821,-57.014069783169603,90.393223687323896,15.415669275765275,-18.100416135088906,-2.0622437292250648,7.7255671901827592,33.685550865261639,85.404948714210136,22.397325332683781,37.726230327006625,42.031656919827775,25.911296457417322,-17.530594145996805,31.537352583172215,-27.786052488438365,-16.130020109351054,-61.342234263597277,32.95468930342782,71.720028706162822,-17.232266508209761,43.434109107395081,-58.430756799101324,95.291109809808972,42.702966388874451,87.990284185194298,31.986243891122491,-49.45513670096269,-52.693157577841497,-73.214150342671502,-43.753333730331882,-64.892036755198021,-11.868440902962284,-47.213421876444919,46.569670253989742,7.296860399931191,39.780636667606785,-2.1269735269466783,8.2328831900309591,17.759628867985761,-11.562633439207262,50.167290797497706,17.820889064258893,-3.0146843684641791,22.349800716691632,-16.51030189603587,-38.973764259550656,-11.179734084687881,59.754599154184618,92.786840234953445,8.694391874770206,13.054471572784134,85.714793738047149,70.486930236825813,29.816082231576463,21.22586664504237,71.211661151075916,83.593964690596678,101.57081699157698,21.026296469492799,108.39726397777814,39.44724621977295,-46.023907240160113,60.448507539644758,-91.306573094998043,-4.7617904042726549,-14.184285892902713,2.4746888146727319,35.133784032023883,-27.935095441032583,-69.902754710639144,-2.4571154092002554,32.969897688633672,-57.314316606927768,-18.116158328392039,-18.838601227307677,53.987966366886383,89.087161716798306,90.006438117861876,60.75541514497197,88.154936877120335,84.355163077288395,-62.69975355546687,-53.761776288404413,-35.088228211627786,-44.77124851426543,-77.599007846499902,1.1676278628214627,49.308098237094342,-46.321896032458028,13.167912388452132,-34.824966480341629,52.515885982256364,29.527184467903815,-23.060540012011852,-2.6340776610353642,-45.32764201556131,8.3990418169457204,32.8363979188453,-61.308779727010972,-54.957828189001624,12.844778700843392,12.128993113043252,-44.731671309597388,-44.648167039077762,37.050747223329637,-2.1582296056617012,-58.138005821741579,71.845527065291691,-35.028929906746683,100.41413096112609,-20.704753782634931,44.377355783791096,-37.934860312871336,86.463874016282389,-58.709773218594279,14.647104610052272,12.342311533947901,16.669413901017698,33.072132619329196,47.835434162257322,27.683473497742316,-23.728135039997643,53.199908088748209,7.5434904559616616,-0.89076771554116607,41.782584296618658,37.199382350886559,-69.631637399433856,-27.116811926330982,-50.093540367366366,27.47503153187213,65.732158927666745,20.602332635687119,-30.048729590650478,63.318867618727168,-15.052936761453786,-17.443930293148011,24.993139100366029,-48.981879652264567,-49.962689374925901,-66.602722688815561,-50.940251671354517,-36.485350492693591,-71.845710725607489,-66.342035183203819,96.667462160142108,40.494464390889156,5.5954774880585276,57.238505626106843,-41.634084476559693,30.54994782562494,-7.0620981247226267,-1.5848963292873472,42.035671724832866,-47.193088383080202,11.54396962729656,-51.722585630216329,-53.510803602145245,45.865937479499991,-5.391556754877552,0.059055971180636414,-52.523544370151882,-11.235603924096232,84.594890863885254,9.4463876245368734,-49.78121714145005],"y":[110.37818268286043,-21.350406354553574,67.399986003270385,-78.873617774830763,122.99762196689716,-213.89773359121176,68.214161871831237,-28.187832649001884,-39.001966507007438,-174.99580807488204,101.32188161904745,-47.169078851172294,113.76123349855983,9.8252854081091598,-93.90724351367075,71.608410803598403,7.6549105604243985,-97.441399163538648,86.453931722685667,-27.241833749950938,72.874842483453477,-24.246051905916893,129.54634465660118,-157.65142260753362,-1.7058433650721716,-171.05318645121798,27.858953710270782,-65.274537908342637,120.38695985874398,-1.4379629931282536,-105.08972655631798,125.79924129020134,144.04112262067252,150.51672397758611,107.11918986264172,-69.69842506030578,27.263720565485624,33.286012959455988,81.461042332175069,89.104514879163219,152.59556282954722,-87.54999904937273,39.666472319791353,120.34858335498876,38.218007841008557,127.85389526475593,-58.46245108254994,-122.78894144099571,91.034330956486784,69.687240285193454,-17.883514689848621,19.642969038863967,47.961148173651097,-176.93052460251064,23.666145102585709,146.28170421167897,131.81616146761948,133.88479196911709,87.68892831310967,71.135068872866853,-182.18446695610515,20.262953879587847,91.868667929328979,-206.43617850296144,-44.253176407249711,-207.92718736037105,126.96838302885237,-166.95887797867863,149.6325020765515,127.55556513316442,-53.418097376485136,-65.909921040103299,107.49683847070439,-51.074462742569601,-67.045044276480198,75.574833289960367,21.650979275548313,80.008209714590791,71.330592183997496,34.637242034359566,107.29381915163893,28.76739168792955,119.04392789920452,92.148468474676349,29.222802106780929,-55.985357070893187,44.816214173906651,-144.64250892683839,88.028335049755384,-205.41629797123554,-54.902771388842289,-59.510088834933939,105.97109994788553,63.768609129944792,-4.8021569365281582,154.18004178277087,166.82031252855901,135.38213234183397,35.742543361067156,-25.432181783187087,44.251012023439763,82.994527467605437,34.023873609664648,38.406650220305693,-117.07711314709397,-179.77914399015341,-44.637234660522658,-145.66000944295126,61.288132821321966,-204.24238773418051,-183.62760949453829,-116.45100712580394,22.074221232223245,10.432486077729379,-5.1556471132772765,108.22703051197843,-45.304763723328463,-81.123576070426452,105.71108272567537,-33.474752450727642,56.945216572338005,81.628649315686374,-219.37100031537329,110.84430603914511,-204.18788033103584,-90.325533627747035,107.36056057858443,-34.28380845516152,74.513422252820234,131.5404467686524,129.33237121159581,-16.394591315821145,151.26981755746493,-61.918653276846193,128.86340038072643,92.776051286084709,116.01123735216741,-157.28756145920937,1.3998255039951391,130.34579377167486,61.982604045870545,122.80838204143652,115.14017021038777,147.40271268582805,9.5573213707492854,-6.8475848344622978,50.843843275400566,87.421889652557525,-42.273383036412049,-116.39872716865263,-30.148060766680512,-81.282560735390135,120.05343719899506,-138.00436098258146,-164.04163722121123,103.98221758421573,-81.75502173872384,118.06056317648337,146.93151261956461,-145.61709504701852,9.3586926260284411,-22.728711898509768,-188.09515138677062,127.63730233249572,53.290293518738906,-25.468776980679646,85.367747181250863,118.54803007366704,144.9890888675433,113.81162247961326,-191.51865081268974,-28.938752927588702,20.526648809666941,-4.0755429661431632,2.6953418498743682,-123.98850606318436,111.97859655210215,-182.47423674385158,-180.08795257542681,-88.741121768707103,152.29358030882253,77.143569904326029,-187.03158218372323,-224.76712677813961,131.9586348016004,133.32482629457152,29.483356577087701],"z":[-45.327095033275839,-56.631868655722059,22.760747157621655,11.406965616284108,-32.771910807810585,14.448970383563029,25.307194481325684,-6.7552267594994921,41.383973928620108,10.065093183882016,-40.124812988673909,49.340828301075057,26.431362941301462,76.582926180134592,36.923268192804336,-38.530984824685156,15.5900279616838,-36.95248901047065,42.471713698913277,56.720960274579184,29.083793468109601,98.231036706000296,-33.782615465406373,-4.1934974715751698,-27.695867955893146,-5.4906786794024711,31.563097224549736,64.600997500387834,-31.6686559682073,-45.428425897173483,3.6215009077905407,-26.04316233335085,-21.819482174065261,-2.9010668595838407,-87.226427950895058,-23.415071939982312,69.615934735456989,131.479105861709,-45.566293937773864,-14.887928351766964,-1.1366660648440419,38.623654183587867,126.11927251639466,-30.385093946445284,40.693909890472021,-32.121387407715808,-24.965392739421457,-4.7427375507144909,44.493134302337623,24.82744807739536,89.277426190212893,4.1211726099387054,78.677937702158061,31.186087361715632,2.0055137407127872,-2.8588825767781181,-22.82222279334367,-29.372902945226755,-33.392830470827505,-53.406016367620794,5.5812707345375117,-46.869367670495983,-25.181375200757909,-2.2783522341618681,-16.160113808816746,6.610526593719837,27.859266701368561,-4.52252879805999,-11.238789490301455,-14.009787533842376,19.820618116785909,-34.175283675995921,-128.27398670664957,-26.515697123722049,-37.903507925079104,-61.42808139243467,-25.611049756949658,-44.176693280778125,-38.773304306009187,-43.315921443560484,-35.647056556192169,-46.055120606399107,46.626963000333632,-83.276990707916937,17.63972413504063,-18.18461011231112,61.940877935130757,-21.318163522803623,8.2056163951258476,3.08230201230635,18.960070275179735,-7.1332990592388397,-86.612921421374224,10.719936424337332,56.258840958993666,0.40855300684564411,1.6383866921337564,-4.427891286218963,-115.23829749432582,-54.101499564845412,-126.01943131222939,-122.40700756659139,131.67631032824534,63.4083639594202,47.942724835465576,26.829801830977612,89.522155806492421,-1.082504089352841,-41.485444076135906,42.341340998333386,1.9407569220924035,39.13319977121602,-42.187961715355726,-40.678098193834487,56.932661516487691,-38.083425571213319,97.268601720080568,-12.611356336315563,-16.385911922238879,26.441328502848418,63.907196679250788,26.659421734392115,4.2859414169861241,54.072996778715016,45.603826192294285,81.255916361377132,-43.067538459652944,24.541442152754218,-43.103414467645905,17.164095491017655,-10.698218435120413,27.813273158948256,8.2414673428722178,-8.3548654935122109,-28.4204364855322,77.483525949181754,39.111215058914652,-1.5814460671958475,-26.807902826309871,-19.869440701650202,-34.170107345811068,-32.478249173643597,25.548164444466014,14.301841165884248,11.795941081463896,-12.687794813425086,19.350050555471999,-0.88826634270238647,92.362889359287223,68.689897339233383,-4.0643465492890174,-46.152865605586314,-24.329860089293071,-11.554383170421929,-12.380744210094077,-120.81390363573875,-44.906853620407162,-23.719054893807353,4.3151706047722742,-12.924547356816952,43.795304411755311,-12.867606058282847,15.251811239188978,25.564953827982691,17.047267354934082,-11.384639533278813,-8.4533713911209922,-36.695843784404616,16.911190372671587,-42.094991211461689,55.239372213230894,-32.834520968441133,92.917289660126812,-0.037581917137087757,-34.777841583028689,-4.130431959439151,46.269967693716389,35.947531408171962,36.357538739453247,34.384137329685444,0.26838312752432464,-7.8661847639961167,43.94592788077825,-0.29692051164135008,-26.600704803203421,-23.842512084752574,-4.0167513620235553],"text":["Input: '* merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: '? dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'a steam plow engine driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'ag threshing machine owner' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'agent' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'agent der spaanse schatkamer' (lang: nl)<br />HISCO: 44220, Description: Business Services Salesman (except Advertising)","Input: 'agent for bradford stuffs' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent for debts' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent for wholesale clothiers' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent glass house' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'agent mine' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'agent prudential insce' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent to a distiller' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent to the prudential assura' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agricultural threshing machine' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'and adopted child' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'and also repairs damaged wagon' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'antique dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'architect surveyor agent' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'assist to adrt agent' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'at school part time milk boy' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'auctioneer and valeur' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'bedlar' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'bloemenhandelaar en bloemist h' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'bookkeeper pawnbroker' (lang: en)<br />HISCO: 49020, Description: Pawnbroker","Input: 'botiguer dependent' (lang: ca)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'broker (deceased)' (lang: en)<br />HISCO: 44140, Description: Stock Broker","Input: 'cattle dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'chemist' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'china dealer etc' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'cleaning and dusting' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'clothier' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'coal dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'coal merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'commercial traveller' (lang: en)<br />HISCO: 43220, Description: Commercial Traveller","Input: 'commissaire priseur' (lang: fr)<br />HISCO: 44330, Description: Appraiser","Input: 'commissionair' (lang: ge)<br />HISCO: 43230, Description: Manufacturers' Agent","Input: 'coopman en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'corn dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'corn factor' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'corn merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'cramer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'cruyenier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'detailhandler' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'draper's assistant' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'driver of stoking machine' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'employed as handy boy during c' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'engine driver for steam raper' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'engineman stationary above gro' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'estate agent' (lang: en)<br />HISCO: 44130, Description: Estate Agent","Input: 'estate agent police pensioner' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'factoor en not mentioned in source' (lang: nl)<br />HISCO: 43230, Description: Manufacturers' Agent","Input: 'fancy goods hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'fellmonger' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'fish fryer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fish merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'fish monger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fishmonger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fishmonger (deceased)' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fly proprietor' (lang: en)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'fruiterer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fruithandelaarsknecht' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'garage hand' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'gardfarihandlare och undantagsagare' (lang: se)<br />HISCO: 45220, Description: Street Vendor","Input: 'green grocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'green grocers shop hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'greengrocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grocer (deceased)' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grossiste en confiserie' (lang: fr)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'handels' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'handelsbetjent' (lang: da)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'handelsbitraede' (lang: se)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'handelsfuldmaegtig' (lang: da)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'handelslaerling' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'handelsman' (lang: se)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'handlanden' (lang: se)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'handlare' (lang: se)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'hocker' (lang: no)<br />HISCO: 45220, Description: Street Vendor","Input: 'hoedenverkoopster' (lang: nl)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'honsekraemmer' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'horse dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'house land properitor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'houthandelaar' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'husfader fisker' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ijsercraemer' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ijzerkramer en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'in comission store' (lang: en)<br />HISCO: 49090, Description: Other Sales Workers","Input: 'in oud ijzer' (lang: nl)<br />HISCO: 49030, Description: Waste Collector","Input: 'insurance agent' (lang: unk)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'insurance agent laundryman' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'insurance agent music teache' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'iron merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'iron monger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ironmonger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'jernhandler' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'kjobmand' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'kobm' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'kobmand' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman ongergoed' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman op groentenmarkt' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'kraemer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'kramer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'lab proprietor and driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'lace dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'lakenvercoper en not mentioned in source' (lang: nl)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'land house fundholder' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'land mixer for moulder' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'land surveyor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'licentes hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'life insurance agent pearl' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'lime merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'linnekooper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'lisecensed house agent baili' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'machinist' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'machinist agricultural tract' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'maeglerassistent' (lang: da)<br />HISCO: 44100, Description: Insurance, Real Estate or Securities Salesmen, Specialisation Unknown","Input: 'makelaar' (lang: nl)<br />HISCO: 44130, Description: Estate Agent","Input: 'malerforretningsassistent' (lang: da)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'manager to financial insuran' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'manufactuurwerker en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'manufakturhandler' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'marchand de blé' (lang: fr)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'master bank land insurance a' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'metal dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'milkman' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'millers and grain merchants ag' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'newsagent' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'none derives income from land' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'ostler' (lang: en)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'pawn broker engineer' (lang: en)<br />HISCO: 49020, Description: Pawnbroker","Input: 'peddlers of tobacco' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'peddling pictures' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pedlar d g' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pedling y no' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pot dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'pot man' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'provision dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'provision merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'prudential assurance corp ltd' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'prudential insurance collecter' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'real estate wrks' (lang: en)<br />HISCO: 44130, Description: Estate Agent","Input: 'salesman' (lang: en)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'salmcoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'school part time wollen roving' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'sciptn life assnce agent' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'shop assistant' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'shopkeeper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'shopkeeper deceased' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'shopkeeper draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'slikhandler' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'spannmaalshandlare' (lang: se)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'spirit merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'stationer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'stationer and print_s' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'steam plough labourer' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'steam trawler engine driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'steenkooper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'stock broker' (lang: en)<br />HISCO: 44140, Description: Stock Broker","Input: 'stock dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'superintendent of agents life' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'surveyer' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'tallow chandler' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'tea dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'tobacconist' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'toebacqverkooper en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'traveller' (lang: en)<br />HISCO: 43220, Description: Commercial Traveller","Input: 'verhuurstrijtuigen' (lang: nl)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'victualler and land proprictor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'visverkoopster' (lang: nl)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'w martin estate agent' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'walking stick hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'wijncoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'wijnkoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'winckelier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'wine merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'wines and spirits' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'winkelier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'winkelier lederartikelen h' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'woollen draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'working clothing store' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'works in decorating store' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators"],"mode":"markers","marker":{"color":"rgba(205,180,144,1)","opacity":0.69999999999999996,"line":{"color":"rgba(205,180,144,1)"}},"type":"scatter3d","name":"4","textfont":{"color":"rgba(205,180,144,1)"},"error_y":{"color":"rgba(205,180,144,1)"},"error_x":{"color":"rgba(205,180,144,1)"},"line":{"color":"rgba(205,180,144,1)"},"frame":null},{"x":[32.670117692563174,-81.900357612994839,10.836672163067609,-21.537706818621523,-19.687601509481745,-39.654653587494245,11.037410893246438,-0.54325373120077924,15.432198915134384,10.168117181609214,78.544693987612206,55.446889537928747,51.037501421908118,39.467198128959311,29.761490277957396,-8.9783690272804275,8.4034014478380943,19.901543736923237,-3.2012994662755276,-17.146363852623953,-10.092238658001092,-61.109454807870414,13.45175325295185,6.978554688112605,-23.947574752945826,48.56199694770234,88.982707076123901,-14.006963318899794,-13.17797930632803,41.278698880357233,-64.222023717040344,88.131234687140861,47.695333368158309,-57.782590376526549,32.77806179864838,-45.884893907013044,30.554759145743439,24.311867754097275,-37.026755457832543,-37.9721575884763,18.36180142682084,66.673018991037722,101.44930277846807,49.776745772039646,46.958550113036218,46.157130454165618,17.569532137230478,5.9534505505563473,5.2046026005648027,-70.775035383694913,-38.313399751475885,-77.431692699520184,36.529626453887388,-18.890144905795388,-57.136822939475174,-5.1318725441518636,-15.089660127273062,-25.599462327742405,-32.653782992419877,-40.134030710310817,46.38361454920998,82.741521574204427,37.765150206597227,79.603930858385169,55.251347589822757,-51.687737100463949,-46.038378031435137,-49.949292189862859,-31.047275958478988,12.572421320879634,-50.854034818743571,58.185806910141544,59.796110564049741,55.982772430831268,-0.20486441011038173,-9.9068493059731271,-59.917952430508436,48.26961989481903,-26.317384047380131,76.271376302634877,23.19699824447844,11.25145776393547,48.616801234302159,86.14067257384437,-35.929823849480897,-34.531384838942522,-49.590893108983835,7.5473963409488309,-3.1925298070505166,18.443986136170832,-6.462605828702114,-27.347454344344762,-28.600075933004348,-46.505677281291597,38.882813064109904,69.333751635766362,31.85169228933859,-35.377064326512553,16.251108434782619,59.707328197267039,-1.0984438871038129,-21.756395907981169,9.0261291117610192,-68.61755113405745,-21.451993878681233,45.192544426141801,37.656829376409426,62.945764312855481,-3.6442052859132508,-45.531975695728669,-23.201758258627326,-13.207366366286031,-26.152511198773698,-65.269723519092906,-8.8557640401340887,-61.699392910507314,-76.186555229470187,33.08869909060369,-53.743009509830841,-17.782811550128912,52.859331468970552,13.962094084624242,63.851525627625648,17.749910788481916,89.859774449628404,90.136126426519908,13.108588174834802,16.822085958630758,64.654049535134476,-20.85027154240446,-18.765222767618042,-7.9147778140893132,57.974901266263707,37.986424588284954,-5.9333178316570443,-32.701055752810106,79.350800834296948,-26.732444975521009,-41.450384879868231,-24.134730312167303,-22.494003442806058,-55.490861280447461,31.882947049086411,42.002442846348778,10.76000730909594,42.027309699528622,13.080741586685781,17.308479658504993,90.16330455516011,-36.040372322861231,104.70599285376531,-58.923880407032286,30.420770299709787,71.666492137222122,35.468716323276574,4.5959675922728129,-39.170069385803956,-59.887498621557391,55.934873906507391,35.955025228256801,-26.58010664617743,21.918151145112816,29.4580254830901,46.83632168866697,17.692023688051385,57.279473439416186,53.929974147778289,-50.176080671746654,48.304582256582975,9.4120921141170868,-39.212941832571055,100.5346951506563,43.469801530896461,6.9716258145075383,15.641331198491693,4.701842968439367,-35.615272345927821,-72.720393868475938,-50.311982321449698,-40.684722030881851,19.95228548535901,-7.7754019403165806,-13.578271611600186,-75.718785607582234,-70.404565496504304,-36.181327439323411,56.363151665246683,-34.847124981688054,31.90586193467858,-2.7142057216647029,21.048988555492638,-30.181725725697561,40.574051577884369,-14.03876432660277,39.558011320411332,84.207593693678803,-57.740352106257554,55.188423549541895,-37.706185131279732,-58.238643820017742,-59.39624807507699,-35.492419626922953,-19.022410957113674,-53.535325237433362,-42.511195979230202,-39.694167934097067,53.979204534271943,-51.747579388984882,-66.913280213770918,-48.371183072021779,-24.392999350306852,43.674305348256439,-43.257961737693144,-20.887228624062043,57.488800180342906,21.041617569339206,36.039887374638951,-0.30992308159259691,95.357397395020385,44.773877410190451,-67.675382448620525,76.646171633917305,31.847154753061361,-4.5402543921947123,-23.165372604598115,91.963223552170277,-14.660694207157087,-66.890813465664053,-31.417118167326358,-52.015317826900599,50.604101306997542,8.800523092627353,24.335020030647346,28.962389728545947,-67.032333069185086,-1.9864332084213681,37.667300616791273,-15.331740058230338,-84.594267421726599,42.995624594357302,-50.745484891303946,-49.387790805469827,25.635133484206218,-54.089435556548423,-5.2775655656519191,5.5214681405915371,3.7736483615969201,20.174526587819134,-17.431337014097785,18.482469649643011,1.5717091256027058,20.4482373838622,-13.560214976841895,13.92580996497578,49.913724421457488,-24.091975066564647,-56.600869325271518,-21.436680461714214,-53.311996990225481,-17.597511709925065,-53.924222087723145,-48.864043792853046,53.522061311785905,-60.460189458638546,21.861778243434646,21.059978484482148,-35.85384340867472,-36.463999883814886,26.647650814993458,63.595635049513248,97.284954251439999,-41.356289647640295,-18.590832008558746,-61.718059554552489,47.641633996687915,-66.66574680424236,89.140429164088886,-4.8158154191037195,-76.294991575397717,78.42613884393478,-1.1574077446604436,17.238766960820644,-38.764417986723132,48.381951788315256,-32.373795653829312,51.836430696264976,22.43222885318302,-5.4190857740020144,52.038511027967871,18.329244310861586,-12.741301171023421,50.974977656553087,-7.0841529056698089,-16.004866592362582,-69.942479195475855,64.923499272602271,42.214320314882166,60.526292410800501,-65.301455845131201,-46.761385294452531,-28.724782956153998,-7.7213992898855173,52.22579417440393,52.094876779936982,62.244780907184612,-31.198963768664427,16.644553510668775,101.74725779621041,-46.882566666432609,-14.806351506631078,42.792749606974411,-59.353108981534263],"y":[84.405572010419093,13.773785999113107,-57.427084967335851,-100.55509369857829,-208.58191357747074,97.520801784310677,-221.93091100344859,42.945318449470044,93.353464807075326,-202.15918499311519,55.606007916884337,68.596749214716723,18.452686452461428,94.947033902005032,125.16689907866504,-32.980226006379013,-198.67710139713122,-168.52173538666747,-214.50778365142335,-11.2557144559297,-123.56844438154116,-107.64864929402124,-9.3012105313688771,9.250066637299172,-185.09497780707372,64.402411803666297,67.243729156849213,65.303219902354002,4.7640343792536495,67.52872770696429,20.003297244796514,116.18833273085497,117.45122715131268,69.616026436775172,19.836368142401561,71.289338216579267,-39.731972651304616,-80.962465464040875,-63.986383693160036,47.979989509072283,153.28722428287662,99.076285121646848,72.837093389388812,59.93736498505028,59.243859492502516,57.536856053338767,-25.687291187827903,143.34942843834253,83.859395692899938,-80.86966025691612,92.061606013195089,-23.764254090994619,-53.967575318346192,114.28371700109146,109.94431616913391,28.365751150669592,-119.88540663130546,-109.79035308563525,-10.702407581795308,-60.822512360912974,54.165893079595911,61.627876028318767,45.900816221881385,75.877418117857061,24.33435123610899,-122.01781958415965,-35.712609628255706,-36.982923169378878,47.18353412905455,124.09658516784926,70.485740043751676,70.928203591441559,-15.452761398276023,70.822979296582574,76.56088563597396,-184.76391108714972,-140.94679543875867,14.864881184219049,23.801454249710485,109.20694043972317,-138.91009431999291,176.51419995898789,134.16307010259681,85.165593370901021,81.089595626294638,136.59889074445897,96.872777486246889,-206.25082373707815,-230.65946160507966,-67.799248579603542,-116.34752819111858,8.7266969104337271,89.280542517433773,55.048010626908528,57.607398986515378,120.18679324195074,-101.40989824346462,-187.71125456015682,121.15238995244276,23.683844789439867,-143.57992088501197,-36.282922840014301,-223.21543949943998,-72.292210006138617,100.16106299309951,2.7743720888443462,97.037889373912563,-27.612443643298619,-126.36496717110225,-62.338265263351452,-213.64763188565453,115.99807166551093,-0.04452732700579895,54.006629830194804,-133.50345894766059,-145.13620595103083,-45.297129924244551,-17.034250553384691,33.936576379331868,70.314707896415825,-75.65989679351874,-2.00182053789724,90.948934987103513,-155.04750694983545,37.539409927708562,37.940465272222781,52.414665402409661,-223.119565368503,1.2913796883105408,-154.99356422153076,5.8694963030658691,-150.74808433426492,-14.673759174769236,121.01814965424929,-60.77778857234992,52.865764967899977,137.0353073062393,105.74534232401264,74.742841327045014,-1.6773640083136425,80.569398771660715,33.913502005694212,-91.301154718493493,94.992429282332878,-91.303678488087201,88.992317986575713,34.740595201482925,-62.914024263139545,105.63475826271576,-38.874782900680025,118.06063680955879,-107.80221401562569,-78.677043106734502,56.773438823523911,-3.5510302508008293,-27.673556843646903,29.415031074660909,-187.49588330064637,87.428126158555543,38.50371656829612,-181.60039340005918,-44.488515013179793,-50.770227729383336,59.053094549417949,84.487864089373232,68.051491855735208,33.583155665040451,-151.73229615101056,53.908934892974528,-150.12144277678638,-57.385024490161207,71.113622313252264,19.361803550860191,-179.74560813480679,-166.01898229504863,-142.40372667242346,-4.6422679213632057,-52.954219292027958,-26.382732708044518,58.460255187079689,-1.4950755976309775,-231.82370202116047,-114.95697089714358,-67.971272255936498,67.098754019525174,27.26673972532096,120.37784777948505,-178.55313533779173,56.084302235869821,-167.79277211169233,-218.30195721843819,-113.5271888286687,97.86743498500698,-196.93777574416512,-7.8668884482303616,118.43918805879862,55.95000089505902,11.915220478702015,1.941379999077836,101.17841400354276,102.73427832732256,38.658380545357986,110.39672752677552,25.003814195906603,-19.59470209453524,-12.22261633111081,-11.26737943169279,-66.135319940835259,-5.6098003488315289,66.109321750531223,-1.2291408733833289,-118.61469961461768,-35.987144749013829,-1.9017539786683368,49.654466234568758,93.005577892638186,48.398104252905824,-52.418106106875811,133.71437810727323,-23.474032144763179,-54.071299167079168,45.815193937564437,79.534622141776111,116.05758071126435,-12.108936227284625,36.512028702416259,87.633383240912778,-103.33269042888614,7.2821315473979285,32.401991100110806,23.019241368961104,174.57026628984059,-73.950783709970906,82.88590666757554,-7.4754876455169086,-215.17520454605165,93.257863514207912,42.754118823550826,6.3815744941819261,108.0226514121551,34.316161815093807,-128.60490284839318,12.321394064343071,48.795495875328541,14.355543331840407,-194.69819975520667,95.190673303176212,156.96984061668849,-104.39417729638525,-68.121352317125712,-4.9145647912129977,-3.5139228717324311,-100.16088673956833,76.377849216131992,-0.33732663950829772,-84.897305189239589,-147.66857978386605,-209.25141781677118,-178.4341498114652,-223.75715270706297,-180.21006094885544,-196.73894855388244,84.474499873543309,-71.995301597808037,-74.062987238905563,-74.711485271778344,155.91390482151022,153.75961752304391,137.52918611214557,48.596081408442821,43.065059655504207,-51.674789770166342,-66.862537705638331,105.28533402778626,-99.522348007185528,60.275416950444836,121.13428245672681,-169.75377628017452,70.350793392997872,75.191329677393128,-118.26360086073491,6.7537634730481333,-43.414315677750309,102.58951043926592,-109.57026037586056,-91.454920876088494,-88.016295681609662,67.040695488539953,71.014266756104149,78.062087026624837,-86.512994935778721,-9.7644628279164252,-129.4810232985499,-186.05095500494625,-101.40809030088541,7.4527796835216868,-102.97678868607314,69.754187376220798,62.141203704044216,-184.67559943865311,1.0864118316214986,-65.562592727131303,75.258035876431208,74.171518199457324,-73.2850538331801,3.5891611053159345,-47.610368099490742,108.58686589039731,-137.53260508335845,67.322483144498023,96.396179215531248,71.702111387729033],"z":[-46.37566206887886,22.592561630865646,48.282699801272571,59.560494289547158,-12.887186022553056,23.027159204292655,-2.0286363124752729,76.868393289472692,0.4289879906033236,-0.813613352231908,-126.43949626634652,17.938162970098837,-49.295986185929173,21.613154956494071,-33.118911155132061,-44.922495990297811,-1.217023401758514,7.4902677300278482,10.033102176584874,94.263905878926195,-11.293184237712087,14.208025309172989,5.6966998527472041,9.4941183742109079,27.282496271433754,-35.517783153509825,-74.945065382247066,-19.66119714964907,1.3426348663099428,-28.470505209141187,-18.690949335280639,-27.907024608175586,-16.433108525451065,68.944969179010883,-19.913420892269404,87.871077283589528,-38.558550771487205,-36.575686150241467,37.627865331412124,114.84988213916162,-14.136219051151542,-120.25240381559524,-37.309521744553734,-85.773909399765643,-19.638784159987505,-18.612144631473566,6.0796902065449938,-2.5816789926490711,-15.841158428047651,12.243946000546947,44.404676659426912,10.793478945149797,-30.374338861840926,25.724984375955255,-17.523429533571189,103.16623674465806,28.992273603097011,39.375586039309617,3.7239538695694256,-10.520432442986637,-41.753172310813312,-113.30509964779527,-82.638469031082067,-124.62347733986016,-46.716450902572021,-10.240180978058126,104.16703852995596,59.496576699959995,88.955767187147785,-32.499345634288211,105.17907493094339,-81.613389421930208,-69.315200435198122,-80.543211677714936,76.34730300878833,-4.2376182095733892,7.6570957636589236,9.1808319880811133,60.981939999974998,-27.493739932039606,-6.9786590452286408,0.84383525253481517,-16.674696013583265,-43.174437574506975,-2.9677708728299623,1.556681433314107,53.82254241336004,4.7636597948190538,4.736916575052164,44.747205620104324,47.036156445498371,14.102404355874377,23.003244814023532,46.8437804946931,-78.307304921383277,-42.812113772928996,-45.165862777391951,33.472434704339001,38.258477906436745,-47.234176102634684,-1.8816258587621439,52.943875653247723,11.774849107996726,40.593562120139396,48.643772421885025,-36.123613538890872,-29.795029789314935,22.119286853898338,-31.796914326590191,-14.458900028688289,23.660987557256838,-26.597810662376567,19.199393354688382,99.768693511200766,-33.926340220425622,7.7138031057465817,51.402767678356149,-26.909228981788459,61.948638244548178,8.7622686589416912,-18.604296990071404,-26.833701334112028,-85.783224157535358,-5.9823392078133235,-36.876303177852073,-38.144533989309849,9.8074865153500941,3.546734258543029,-31.728520170280689,-11.322111740876597,-13.26601198113193,-6.6638508931292328,-63.916642718107006,-35.972032526754951,-7.2524155016550447,118.32902736377496,7.9248992077553897,-36.693814699399432,-16.349829538286404,74.304848440183946,61.256028268335065,-6.9553394764019956,76.960315067907104,22.700683850017697,-34.120031134539019,-30.59278730706659,-29.420132312012118,-40.151826297749309,-128.78430006453777,-0.70199311086226934,-22.468193555997541,-0.33606147764478617,-41.786359323591014,-1.4558764993806388,-76.639300764537012,-13.87867925512337,48.755496162755882,11.639687988442319,-80.723889756505798,-73.730955583952451,27.543722028905975,-31.371868722085356,33.975163783141511,7.7933762649160689,6.2143241476523308,17.498848200655029,-48.269545693014187,-11.733615984969376,18.050049932175224,-1.3978695221324517,11.853856167424041,-25.847115047720479,-21.972764926583082,-33.879253964562011,-2.4063827525370405,-36.649196963094049,2.7230884078881905,24.951408951356935,96.773594446868032,-23.603833352269874,38.324155032402629,-0.8610235901288118,-9.4208783674475409,25.497052934969094,87.499040728456777,-34.120006550838674,-41.000119851401607,29.906801784674894,-96.219857105085694,-42.328826452641252,10.251413060398345,15.505240809392843,-27.210577356082862,-11.471281303874454,-68.624574378637845,-0.56062129786841819,8.3187909514331118,-66.5729099759169,57.856191706457665,70.481620138109349,71.034053122196582,62.746390953018029,30.94369060336626,-19.164045955794624,96.417786677031188,-19.649624912195694,-70.064954645888321,53.239791897348539,49.449753015411083,29.411893849998293,39.943830665038952,-8.9018764592674309,22.866927253516128,37.056661950421358,-54.158469622093726,-39.915743724339961,-43.272546424474541,-37.768387656401927,-4.3973287290417131,-3.8736242610670559,55.330153019506945,-1.5639302453008177,34.188486909155579,-1.5828278737636949,37.998699773929154,-108.78701579847521,83.583802883696535,13.158750564846848,68.904136293949378,63.26667257258687,-47.336590477636321,-0.32322448394705811,66.021286614501292,-25.156914259739995,50.558985931029177,-2.4458243528004973,24.942332355857801,86.233814338303389,-14.581615250462935,-118.76028404157802,118.08916157439776,19.32824860416013,-35.767789969398919,-21.303834285141068,92.446593296757214,-18.842130076134861,-34.675184666985182,-3.2596460037179678,-33.076004405002166,47.452933310098025,-64.950522265292037,34.565129793618269,66.377238170471017,9.8000652871162863,-34.406387025459679,81.190301038430832,3.3421518790915226,1.6979748390888383,13.63809872981245,-1.1283202929361362,17.6369650213033,48.640330671229805,30.407883181173919,22.049766856011171,-50.436817171518477,-51.593118598768847,-3.6654101740089531,-3.8947663914296742,-20.218299779123793,-25.066599947674806,-110.45678511860466,-32.862023846930263,31.069296335465587,71.920903169597196,-31.414829007299183,107.14317685560378,-29.289289206412384,13.142983698816431,26.829830877042799,-122.41459063672468,3.3810259687978834,53.085703333782803,-2.6745011523902962,-6.5618975982596339,34.428048207632528,-28.563700245369244,-32.017495431948575,-15.530203767334166,-95.344747658193967,9.5940924421082183,75.699811075699216,-69.170039775662161,-24.119955303812965,9.5885871310126518,-10.689601113312808,-34.464541008724296,7.2476090682164731,-124.88542044095813,107.32983143990789,16.438544707242574,62.425050221249357,-49.9458250609621,-29.902756083340556,-31.474389021555581,-34.873692577037673,76.66018577545691,-19.138279759404607,-34.896968563579875,-13.383294529182633,-18.680586793895579,-7.9949789901674038,98.701260568262015],"text":["Input: 'an mealid' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'army sergeant' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'assisant housekeeper' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'assist manageress dining club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'assistant to hall keeper bil' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'at college harley st' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'attendant at asylum' (lang: en)<br />HISCO: 59940, Description: Nursing Aid","Input: 'attendant on surgery' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'baatsman' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'baatsmanskorpral och fjaellbarn' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'barbeer' (lang: da)<br />HISCO: 57030, Description: Barber Hairdresser","Input: 'beer seller' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'beerseller' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'betjaent' (lang: se)<br />HISCO: 54030, Description: Personal Maid, Valet","Input: 'bil poster' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bill files making' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bombadier r.g.a.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'booksellar servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'brewers coller man' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bricklay l victualler' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'brigadier au chateau de pau' (lang: fr)<br />HISCO: 58300, Description: Military","Input: 'butter servant domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'cap esquadra' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'capita graduat del batallo de carados de bergada' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'caporal del regiment de guardies valones' (lang: ca)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'car cleaner' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'caretaker' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'case cleaner carpenter' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'caterers plateman' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'chamber woman' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'charge of house' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'charwoman' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'chef' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'childrenmaid servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'cleaner charwom' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'cleardy boy steel cleaner' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'clerk police pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'club house attendant' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'coal miner now corporal in the squadron 1st life guards' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'commies ter recherche' (lang: nl)<br />HISCO: 58230, Description: Detective","Input: 'constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'constabler' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'cook' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook' (lang: unk)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook and carter' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook at mill' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cooks k h' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'corporal' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'corporal r.m.' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'criat servei privat' (lang: ca)<br />HISCO: 54020, Description: House Servant","Input: 'dienstmadchen' (lang: de)<br />HISCO: 54020, Description: House Servant","Input: 'do constabel i 1 art batl' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'dom' (lang: unk)<br />HISCO: 54020, Description: House Servant","Input: 'dom serv ho maid' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domest serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic and c hotel' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'domestic general nurse' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic hotel keeper servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic servant inn servt' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic training' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'domestique' (lang: fr)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'domestique' (lang: unk)<br />HISCO: 54020, Description: House Servant","Input: 'dragon' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'engine cleaner' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'ex police sergeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'exluitenant der douanes' (lang: nl)<br />HISCO: 58320, Description: Officer","Input: 'faeltjaegare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd grenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd korpral' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'fd livgrenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'fd ryttare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd soldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd volontaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fdfanggevaldiger och gosse' (lang: se)<br />HISCO: 58930, Description: Prison Guard","Input: 'female turnkey police office' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'fjaerdingsman' (lang: se)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'flygunderofficer' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'footman' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'franskild lykttandarehustru' (lang: se)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'furir' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'g ser' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gaestgivare' (lang: se)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'gen dom sert' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gen domes serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gen serv domestic about 1 acre' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'generalloejtnant' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'generalloejtnant i ingenioerkorpset' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'generral servant domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gevorben soldat barn af 1 aegteskab' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gjorir innanbaearstorf og gaetir' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'guarda de la preso' (lang: ca)<br />HISCO: 58930, Description: Prison Guard","Input: 'guarde de les penyores dela ciutat' (lang: ca)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'gun smith' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner r.g.a.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner, royal artillery' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'hair dresser' (lang: en)<br />HISCO: 57025, Description: Women's or Men's Hairdresser","Input: 'hairdresser' (lang: en)<br />HISCO: 57025, Description: Women's or Men's Hairdresser","Input: 'hall porter and messenger' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'hall porter instit serv' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'halvbef konstabel til orlogs' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'haulier chimney works cartman' (lang: en)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'help and housekeeper' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'herbergerer manden' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'hm forces army' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'holder logerende kone' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'home house keeper' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'home servant dom' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'hoofd huishouden bij een ziekenhuis' (lang: nl)<br />HISCO: 55190, Description: Other Building Caretakers","Input: 'hotel editor' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'hotel proprietor commercial' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'house keeper general domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'house serv footsman' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'house table domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper general servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper at' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper bank police pensio' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'housekeeper is alone' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housemaid in asylum' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'hurenoppasser' (lang: nl)<br />HISCO: 55120, Description: Concierge (Apartment House)","Input: 'husjomfru' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'huusfader gjestgiver' (lang: da)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'huusjomfru' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'huusjomfrue' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'individuo del real resguard' (lang: ca)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'indqvateret constabel' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'infanteria capita' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'inn keeper 3 12 acres' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'inn keeper and grocer' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'inn keeper post master' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'innistorf' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'innkeeper' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'innkeeper deceased' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'joiner and licensed victualler' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'jungfru' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'kammarpiga' (lang: se)<br />HISCO: 54030, Description: Personal Maid, Valet","Input: 'kammerfroken og stiftsdame' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'kapitein konnedmardomadam' (lang: nl)<br />HISCO: 58320, Description: Officer","Input: 'kitchen maid dom' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'kitchen main' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'kok bij de afdeling publiekwerken' (lang: nl)<br />HISCO: 53150, Description: Ship's Cook","Input: 'kokerska' (lang: se)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'korporal ved 1 bataillon' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'kroemand' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'l/cpl 2nd batt. lincs regt' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'laghy companion' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'land cadet' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'land soldat barn af hans 2det aegteskab' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'landlord rulilie house' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'landsoldat tienestefolk' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'lensmand' (lang: no)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'licenced victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'license of hotel' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'licensed victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'licensed victualler (deceased)' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'licensed victualler and horse' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'licensed victurlar' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'lieut rn' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'lijkdienaar en schoen en gareelmaker' (lang: nl)<br />HISCO: 59220, Description: Undertaker","Input: 'liscenced victualers' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'livgrenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'loejtnant' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'loes piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'lt colonel' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'madchen' (lang: de)<br />HISCO: 54020, Description: House Servant","Input: 'major: west tor___is regt. attached sudan defence force' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'majorska' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'manageress of manor inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'matron consalescant home' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'matron hos' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'matron of ward xvi' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'member of h.m forces' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'menig ved 18 batl 1 comp' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'menige i 8 bataillon' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'metro police sergeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'military service' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'militien bij het 3e regiment' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'morayn gyffredin denlnaids' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'musqueteer manden' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'national soldat tienestefolk' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'night chargeman' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'nt attendant on lunches at asy' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'nursemaid domestic servant do' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'office hyde park hotel telepho' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'officer' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'opsynsmand med gerderne omkring hovedgaarden skioldemoese mand' (lang: da)<br />HISCO: 58940, Description: Watchman","Input: 'opvarter' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'opvarterlaerling' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'opvartningskone' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'pageboy domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'parlourmaid serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'paymaster in the royal navy' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'pensioned serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'pier toll collector' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'police constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police constable beds county' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police constable norfolk count' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police inspector (deceased)' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police inspector.' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police officer' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police pensioner now forest ra' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police sargeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'poliskonstapel' (lang: se)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'porter at singers machinists' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'porter in sanitary dept' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'porter in sense' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'potters dipping house cleaner' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'premier leutenant med afsked pentjonist' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'private 60th regt.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private 6th regt.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private r. m. l. i.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private r.m.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'profoss' (lang: se)<br />HISCO: 58990, Description: Other Protective Service Workers","Input: 'pub bell inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'publican' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'publican sun inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'quarter master sergeant r.m.' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'restaurant dining room' (lang: en)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'restraunteur' (lang: en)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'retd servt' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired assistant keeper of pu' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'retired caretaker' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'retired domestic cook' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired ladies nurse' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired police constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'roadman cleaner and repairer' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'rotesoldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'ryttare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'rytter mandens broder' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'sapper r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'school at herne bayle college' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'secretary working mans club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'sergeant' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergeant 96th' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergeant army' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergent' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergent38e regiment instruction transmission' (lang: fr)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergt police pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'sergt rmli' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'servant cooks' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'servant confectioners' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant domestic not of employ' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant g domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant holder' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant private house' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant public house domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant stables' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'sewelly maid domestic service' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'sexton of the parish' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'ships steward' (lang: en)<br />HISCO: 54060, Description: Ship's Steward","Input: 'skorstensf mester hosbonde' (lang: da)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'slottsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'soldaat eerste klasse bij de landmacht' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaat en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaat onder vrije compagnie van de heer westkerk en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet onder cap vries en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet te water en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat de numancia' (lang: ca)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat hosbond' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat hosbonde' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat mand' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat tiener' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier (deceased)' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier pvt. r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'solicitor clerk boarding house' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'solider on active service' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'staandsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'stadsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'steward' (lang: en)<br />HISCO: 55100, Description: Building Caretaker, Specialisation Unknown","Input: 'steward of the gladstone club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'stillrom maid inn' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'stuepige' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'stuepige i praestegaarden' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'stundar baejarverk og heysk' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'superintendeant police' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'sweep' (lang: en)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'temperance hotel keeper groc' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'tjaenstedraeng' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaensteflicka' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaenstegosse' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaenstepiga' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'trumslagare' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'turf and loam agent' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'tvaetterska' (lang: se)<br />HISCO: 56010, Description: Launderer, General","Input: 'under plateman club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'underofficeer ved 2 livregiment' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'unemployed late louise burmes' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'usefulmaid doemstic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'vadskerkone husmoder' (lang: da)<br />HISCO: 56010, Description: Launderer, General","Input: 'vagt' (lang: da)<br />HISCO: 58990, Description: Other Protective Service Workers","Input: 'vaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'veldwachter bij de grietenij' (lang: nl)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'vender house maid domestic ser' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'vertshuusholder hosbonde' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'victualers' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'volontaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'voormalig frans soldaat' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'wages domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'waiter' (lang: en)<br />HISCO: 53210, Description: Waiter, General","Input: 'waiter at new athaneum club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'ware cleaner dippinghouse' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'watchtrade' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'workmans club stewardess' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers"],"mode":"markers","marker":{"color":"rgba(186,217,78,1)","opacity":0.69999999999999996,"line":{"color":"rgba(186,217,78,1)"}},"type":"scatter3d","name":"5","textfont":{"color":"rgba(186,217,78,1)"},"error_y":{"color":"rgba(186,217,78,1)"},"error_x":{"color":"rgba(186,217,78,1)"},"line":{"color":"rgba(186,217,78,1)"},"frame":null},{"x":[47.929431638898485,-59.59982603948032,9.361715931190135,-69.756188043920659,35.479874136679214,64.866767249952275,26.624201776603364,-71.130688271983985,5.1194332317955871,32.265667511344532,-33.995502593025179,5.6380412289850943,17.542436976601149,7.9221365409787019,16.661600522473798,-28.138721435605483,25.93469383785245,17.313029312717497,25.052212578810309,-13.428018748248475,-22.967988011736946,0.35734990449094267,86.537127118993496,58.128209613716422,79.372901833516437,-4.3386324599922981,-7.0579205363892514,22.026260506756675,29.961715995008561,-27.820458150286225,12.012999831039426,2.1011313233069164,3.4177177891741803,-10.466872001164221,-5.5366862539485968,-19.380413609784892,-25.010071782258386,1.6634554060440705,-10.001098741908438,-50.723496251198561,-26.422476831421356,9.4193607732763471,23.035943109708352,-39.289249744894718,5.9839745679139265,-37.97586665206294,-22.681815811386315,26.574307654604461,-16.458185782879259,-3.8630855404924342,-28.364921008266542,-18.126913498475336,82.899112102204271,0.76194537306859733,-26.708653875331166,-57.554013921710371,51.458842555556146,49.20797320618874,39.177532527799961,9.8579994071259485,-66.885498405296985,40.249700884014977,-1.914784950194198,-50.326671818829588,21.854718558720251,21.332236941056319,-57.812456178422835,-33.608251124550577,-7.0869872706283221,-61.518552257117967,39.521647731795355,-68.861056991667553,-53.147559480388303,15.639142106407766,-12.649107198947434,-44.479154120581434,74.849640531755,36.528964276515801,-4.4369288096585322,40.530156058582975,-54.045492665797042,61.041542546167726,-18.726936409846697,-68.202196296606445,-40.158956393494933,-51.502625925468685,55.382802190309469,42.687240638760095,61.44818469974313,81.076460424260077,-37.901701314622017,66.581354867084755,-48.885144091437368,19.524625532872363,-34.070554786089772,85.525372619556904,79.862895402777696,53.008992463361025,81.275478330543606,52.999669303015565,-74.262549330136622,59.2003833642598,18.59670966777108,67.865197360008693,-35.783236873816165,27.966120530296177,84.981444904544063,-42.189464073137124,-49.769363001382231,49.61104878425521,-54.601993133334986,40.545336679658725,20.263508646708981,9.267595371534199,37.244175764920712,86.421672786590051,-15.174739846305027,-35.403003902426406,10.929536501963844,33.130702507379887,-51.648023417373814,-43.281530587336668,-56.885287954822083,-69.126322675569952,58.876264068997465,54.145535164864029,6.6316800387079926,-105.51666558108421,55.371316919157579,-15.646818876715697,-77.212579550144397,-11.969356151672766,0.099567407147838835,43.512653451448529,-73.282757676169055,-106.03144208143472,-56.435325092176477,-31.579284090554982,-77.128274799784336,-63.75662904357597,-67.911367646418313,-73.078780456655949,-35.740873868506007,-76.579944457187025,-104.90909831712065,-104.39431246491229,-35.26928973932732,-58.12340389236175,-28.264922622437162,-70.724074927931099,-59.546858685025263,34.171232202932515,47.55649794094392,-71.263964053750556,-77.797156033803944,-29.642879538654537,-54.450682260417103,-50.217027824964134,-105.63582807512222,-57.228703232038654,59.60147042000267,-50.17591186873279,-42.086384395251955,-48.901123148520298,84.420763639355386,-41.334438889215768,-48.038276130404441,-51.809108746542918,-55.072318744972947,-48.018551101836074,-67.890890983312502,-32.269219695595162,-78.488191577155547,-106.14806527205296,-3.9641207294271963,-13.657012899131928,-46.582588922637633,-52.952560161444232,7.8540921197608267,38.549665013848241,-73.786457831328676,-107.63872809769198,-55.751762188468646,-76.426331597858535,-58.766543809858682,-59.656270564432745,-42.58501045386118,-66.603028328270483,-65.955518884029516,-41.987004173926266,5.8499415246626958,-71.664105025755845,-75.154563184530545,-35.477469054850907,-40.828960536703839,-56.881094029273989,-47.414466598133608,59.81626786381225,-35.301080873837869,-48.662603498807265,-55.621399125388635,6.8213985119982068,-57.025875423735705,-62.499822187729805,-40.094819906408325,13.113582137628752,-61.618199368568867,-76.712096044055386,-71.506288443628634,-47.353312003206682,-60.084776358502843,-42.048334417709924,-62.484510266532304,23.545075510514312,-58.346001327730029,-62.492039648317274,-50.165911230217638,-50.39723748839868,5.6176167260385315,63.462958105143926,61.425895288813365,-103.06863491522252,-20.507765746606641,-53.014706306789677,-57.531607026261049,-42.45501971753901,-44.956037786185036,-60.821482289052753,-13.65016280652533,-52.756668452830176,8.8724797681151948,-26.918907364898384,84.137787135715314,30.290177945323606,-51.79347605187511,-15.973368995473251,-38.902021669107832,-106.42408031589684,-18.117158499502885,-72.563340029294082,-33.099985100986977,11.075303293035908,-32.12667203031107,-38.558583432081377,58.209681358595439,-69.082142515288155,-0.66330038882204201,11.73232209975105,-24.542140258617707,-8.7988607720966261,22.344299890543944,-11.893273678526407,65.551062269328128,-50.815022333215772,53.222633887804321,37.228513343507785,49.650246580377072,37.019607187972547,39.203173771429633,-19.633100324837553,47.218902170116856,-22.5179747776039,33.544147366987346,-42.075932905659066,-51.525469794994272,22.155471427896465,-66.750100376212814,75.85412157114618,-46.617725114506896,28.737565950885525,66.776731875673775,-43.834073413514041,-47.934144318524893,45.97006685814214,39.06497086349242,-10.418434782650863,16.44118899721553,5.0183044750967536,65.78253888481423,-7.9943994230926583,75.95526949266214,77.902629984900742,64.159617052540256,1.0913943392229462,45.516834091473299,-9.1577685708736691,-19.229802037622285,17.435540242979897,17.765514273734269,84.219151625637707,92.105492122676949,87.313745541946005,-44.472645845188566,-0.009230714929749537,-54.663729978462563,35.72378471062342,-52.699686180577181,-53.48191856670163,20.721453311099754,-2.4759489229206717,39.689332084847671,88.873932329405406,52.092384845379435,-7.6012506002792488,50.002019723060329,-18.102172664249988,88.643007123848605,-104.4284885227032,-16.623773352521777,0.13653664945458327,-14.105672360128509,-50.351840923668163,26.417385737829502,-60.651957674616732,23.303091677396321,13.039891478356161,91.293150730069755,88.90392745601342,-17.69130030110653,-22.294813245291021,89.28262925240152,54.46928660603767,53.90991251925437,30.609916516220576,45.119597500341584,-1.2924888903072511,62.527603519959989,-35.432952658552743,-38.408215928514728,80.25227252261773,29.510832584774871,69.579656956687629,89.010178455109298,-38.1084477097586,62.618899744563855,-45.406190214519526,26.911614065172337,47.639960833763567,66.252064422486058,68.448061702001979,-65.429841458154087,-67.637184020490139,91.380318629259378,7.5585409799755254,84.944932204809604,90.309882760161827,-13.041381186267483,-7.5660346711485191,-6.733563874404167,-17.506277220836857,-19.194256426702868,16.774477758464592,7.2687632479389661,-2.3301849558655241,72.168866154578907,-11.435444844445838,6.0064946451928467,9.5514133907336625,-24.029055357219544,-19.258702891372007,-9.4071409189611224,-3.2495455210083262,-15.486109901164726,-16.62713793277209,29.377919616719364,12.460669037479679,-29.895784909296982,-56.396143009727162,-57.898326843161179,-14.759152865196702,38.946565855049705,51.959878357293817,77.183747181512558,10.874537488793479,48.317345762995217,33.574707171976399,25.228685517478592,47.739983986466221,19.265316106773437,74.319224236992198,-74.723334903133789,17.287536116104008,-64.133989376540868,-0.34387650338876996,-13.900408229784556,-0.50216349661141046,31.830343289463219,37.015820338856528,-36.125577865796316,28.947198278411868,-55.602239556536759,2.2134249049031167,80.606761707696236,59.360476800423783,74.442895270797464,-36.903787294902678,-47.986927711144332,25.346460878139442,-79.039131075115051,-66.690068957198164,-67.804180158454216,-85.064603653836883,-20.129246309738416,26.554978962943814,15.513450701135788,-24.020737744896067,7.8529036955296103,27.680538438974917,-57.52033415906979,-37.311954546506385,0.34838934937907634,-65.892920887511309,-33.209617283407248,-60.97578399079805,-26.140935580675212,-39.402071394810342,97.77802448127521,-70.340682819951226,-11.543460985129499,98.848101478566576,23.570168260605701,17.410310303765947,71.064993263642577,-27.99138338390657,32.852884656082757,5.8365094685226655,-35.511099544336169,83.306035587379313,4.031504769849656,-27.6382792691867,1.0066924938333313,-11.577474124995431,89.23310884540264,-0.95678562563455505,9.9173672874864955,92.844268024556882,-24.467874523674819,-18.761990701933509,-61.360769915242898,-56.341650371631772,-45.595799495566943,-47.279995109030942,65.287770860168649,42.188375777458326,49.179836773089143,-25.471591654075286,12.289059072161312,-14.156992277005784,19.046107828325436,23.14895471577648,37.902882051212671,88.410818590046858,-57.257591201409724,5.2706118006560185,-16.137591086245521,-32.144848818219479,-32.38457982013616,-24.1243631312622,-33.348132440336748,-67.98552073988138,38.850104627788319,-46.174763200010453,4.5423889065795064,4.4089800043788134,-13.296459715535217,57.853153497043898,92.518439013616558,67.149428498448103,-0.27265218144628905,56.560346967426767,42.180142782857835,68.860646254229167,19.160554259898294,-3.9970289540678068,11.504144943740938,60.514711299248376,84.051785189469513,-82.692600199462547,-5.8595107927494299,-22.036066493718067,-59.504234111728714,27.545815944181772,-19.731886833788447,5.0890551545904481,24.19518536956231,-3.3026399195252627,-5.5900760698788217,-48.261169326089778,40.924923213403609,-39.141799529647251,3.231463529315616,56.376957154322774,-69.290326079865622,94.898150800996532,37.905871406002014,-37.875396142520863,10.61358396513339,89.405199627552449,90.963462964362307,-14.962578822060616,-11.153307434970777,22.713798391569554,20.485427827449218,65.112118321010954,25.164112184456407,51.511425884891665,24.442644040488684,12.483234578929444,10.309653618747966,-29.450394191456724,-3.4896084814171826,11.845342657787082,-7.3351729844541831,11.255511308734786,19.644468561260485,19.667850725511325,-12.589055210923215,78.935204611790937,8.6399020900435595,86.563855496177439,86.202512077743805,95.639690095539848,68.236956803739389,39.594451334638649,51.418307388047729,-76.631794887662878,6.2999772648808774,46.612517683108003,-27.225564585314498,-2.5405379924426361,-29.458851902685371,-73.946500680810928,17.269979735293344,-27.959140231517615,43.806869949966071,-32.280884755348239,41.023130481669234,87.930369935385556,2.0796458665155679,17.912875162100008,-9.9028242583796722,49.885282990537171,-23.366357595704674,-44.786923016123964,-29.044630441286902,-46.530480695208809,54.528684810176053],"y":[86.465921454340986,-126.34245636359195,-111.94291193837923,53.709104530654464,24.005572969822115,9.4804416180560604,85.079502633716658,33.404547577497667,-222.38581850678582,126.2833858426588,-204.08198302517539,-162.41269917842749,-115.74820889537509,-70.923128726053662,-22.637831742221096,-132.05434223244816,-17.232032254056477,-154.64881009728001,-52.764297360512209,92.399903068251447,-63.378543094608645,-221.54862067243241,86.827983758256494,112.77730874233903,77.109977438561515,-175.82879647741896,-181.2351681382145,-159.62235568788003,134.05704654956818,153.83902326495388,3.1906562523569972,-157.35247991961836,-166.95622523558202,-183.5375468840266,68.355484487152253,-106.62930715149659,-61.042184996011088,-220.8275966897597,-179.48506168665767,13.000035847855084,-98.589811362365879,-6.6329479616912659,-196.16893496855968,51.998592370961887,-74.881400373509933,52.839268737495402,-154.61375366443377,-85.733608359695992,73.784801366514586,86.277850157501078,82.42925453221649,-8.3175489796532123,77.529815325924346,-52.186568510232696,17.256840841732405,-67.973531230246437,-55.803595726850105,87.672849083416594,123.67147474289443,-50.826815054579299,54.938704968621764,39.116919713335129,-126.61933024614883,-38.481759731392565,1.395633720929043,87.187466380575174,-48.479827962852106,-18.340838241920778,13.39624926626662,72.757465951342056,73.042148380328243,47.829372383040756,50.352562284546281,5.4772783850905329,-117.14703074894467,29.716102409694511,94.090506646198847,144.67753865465832,-52.044412277990247,123.39564691769924,-39.338649313320232,74.327840353810132,7.0416412715328081,-15.632037077674292,106.3270341388945,99.370071930468697,1.2307887237043513,66.297030393521993,80.147787690641735,132.8226647719377,-2.9687591543269241,104.45214812823448,100.30098503094224,41.668395468971056,50.584788165446682,34.394550441903199,24.661973106643952,171.45376901796411,24.997011194257993,147.03509024607695,-81.015339638043656,66.719361740878355,-183.31294204315188,75.022626871351406,-5.4858747792737725,-119.54261893203008,136.14079042382474,55.491547657252859,49.559930574929624,120.87701276316938,111.44562827683617,100.3774762054591,-102.7510739072453,-83.380849637813128,-4.5077042985993439,102.82227130050698,-224.69328913795914,-109.90554307594799,-212.25093517459197,7.3752687352171886,-66.582588179337307,-60.159729680479003,65.185895105764502,82.207062810990678,122.46014927847915,63.502401986009239,93.363475882313367,-36.688937966947115,-75.988870226819429,11.708121753182798,-22.466621349747715,135.78761759945223,-99.67463490838027,16.814203959417924,-99.684361105890318,-24.89723975613872,-24.299745483971414,64.706222936325304,-31.842733991557996,29.832107129724502,-12.322880748337701,-36.466964933992308,-84.058406356939884,-22.169351077753689,-33.631764937559424,-34.922018264529534,-88.028994743084723,34.219313183263807,138.38897905130355,-111.29361115048725,96.007499405524584,-40.374601196846342,109.03727918637277,-100.85797910539036,-31.841187088809964,-60.5160056505553,-105.50881525222722,111.26035911105245,-31.763268111682812,-37.048412637275085,-26.100777046020866,-156.39511778446214,142.51625726199481,102.24474964107716,37.818644236243308,77.149609131817954,-142.02622746304323,102.29095676407562,-54.234600157813468,105.73900792007092,3.1049256147680548,-9.1045645774496489,34.256524402724992,-28.490595078942977,16.101248043758645,136.45528593654933,-38.126567823181233,104.36122924758968,5.627789097050016,160.09147149080331,-106.26213496576597,-38.355181610741816,-49.148129081572684,-31.072540619796079,97.9386517627334,101.01303577873375,111.06537204099692,83.308506203822787,69.653544835293516,-70.293128335442489,-207.74048545401496,-17.333297352331655,-22.047168660954366,77.260567372641034,68.774653843294914,-60.597665445440938,67.883517544865754,-28.0095836498637,-10.036609063995471,8.1180081549911254,-49.100938335935709,-209.23624237314587,-57.166409805153769,100.42589337120417,111.125336106614,8.2665603081454098,-20.72887387025936,-31.750415211620393,-60.456980915118521,-135.31832629508546,32.233387428171213,104.45477255946119,27.622024968212664,-1.41160251151575,-46.826284312125431,80.788107520530929,-61.464633548815705,56.280049180796205,-208.28984412534757,-27.781655247649869,-74.319075839501295,-35.017957804514332,-10.954008006707308,56.257325161067484,-55.308902996969834,107.15517895014621,108.16766343834013,-57.224404015569647,-119.55843975596626,31.810095600072799,-193.58442381266619,114.06078090123418,40.716943678441091,100.75193780964121,100.45356993905908,-95.340732196870206,78.972592437209173,-33.799869216711706,-66.343673300158713,-40.508135370281181,68.921234079269013,92.933518112540199,35.825779217359106,-197.23794560242303,65.324139602614551,-52.826467766810588,75.798189197917409,128.792581040935,-157.16741286111647,-114.00729195382442,130.2488362860868,104.02939554858433,48.630658966655041,-137.75965722503022,122.60995316247499,-184.57809538460009,115.63524149350455,-185.23283514597571,-186.75738783306247,-194.56947747476977,3.9519370969873466,-13.7820445177673,-64.786117828104793,-52.723458867873148,-20.836150810786698,77.976690966529361,63.970872565462976,78.06808013307645,-140.68444927671047,146.4618401054463,84.134544539021149,116.07503457664596,-158.02557179033951,-20.089410757092534,-84.727527129025844,-223.88488936092628,-186.58703843698399,-186.29772385238564,63.128318067443494,-139.80129754387193,69.808341341269454,83.57790873895101,41.905253574212914,-3.1142818676939932,-61.734141299679891,-141.55808916991924,-149.87712401267461,-46.113421427227927,-47.864973434261643,54.769575650289035,67.836183057814523,126.16155606646457,-77.938554029908204,-75.130773063513033,107.79166825484161,87.622001814772233,51.239830660277008,50.267541147651094,-158.31591806100988,72.190260249339488,-83.188804025336196,100.83380684653535,-73.018039278906144,-94.655871203526416,66.18834075163889,-119.09677897273886,134.79811941956967,-23.551744468619003,-33.681750964517754,9.5889656923577231,-184.70659709581514,88.400700907417686,123.19181197856807,-82.354648413455379,-221.34563976968462,-187.7377824932536,32.854903944053049,35.269977265782174,-208.23842660661526,-99.173990614810947,87.419300851214985,59.670039893579577,57.664341498940324,-92.822506477368549,-87.27286807183107,3.2575567554583462,28.245236598603032,124.34504392308476,49.440718914892571,91.759894918833453,-38.461915242017554,73.739042746598656,108.12685659290901,140.0720706276839,28.072880543693536,-189.22753930096906,-119.38181090879318,11.770959961779353,6.3175688433447785,-54.690015041819024,-45.176240662195234,-6.1193925311865183,60.927243724679009,173.83171607537298,86.614125082277027,120.78845646563978,94.980062455199302,-160.87370765156783,-191.63839318240929,-181.45584750118849,-177.03278545338097,-191.71798783110455,3.2559875112121643,-63.229191587372291,-52.232217158239472,57.116756849024874,132.14978610266957,-110.02258314662514,-193.92680675106629,-84.317270257944728,41.992336312718145,-183.3974471358174,-120.96667748618138,40.044398977845546,-115.16657578488342,-84.699936264359067,-110.7263581168604,-71.117288829712024,70.699952935984342,-209.36775048725275,157.54535058330319,56.013015621528403,79.969330875148543,-173.34621437833516,-80.553373337572367,150.16804752866844,-54.11158989764953,-9.3520825173864335,-82.675373414245342,96.287072140702563,56.968970374687906,33.022463756274696,39.005581943396685,-171.51788987460998,-193.66601712754903,-100.54436699143487,-96.031602064123746,36.700880290483994,-103.86248443812963,119.55484309629936,-112.92683007087425,-140.09518856219523,108.62569571497814,-15.724554188421662,91.175167366964942,7.0878030555934943,47.323675768031364,-187.3950234694907,36.053171352388532,-35.133392725295877,85.415881959438821,12.748655017206556,-75.32748859038567,-91.718260830272484,-134.16923884501082,25.064312931063284,-19.103723116058926,130.77388543918548,-111.3893015656071,74.531831291694374,-41.885494735626146,-0.63943052769973019,139.34006662640135,95.377914213860606,126.10864767626147,58.207282182487887,40.979485835043199,-15.88771201890126,-230.24361388337712,85.039189161039715,148.40281494789269,88.386436537057875,85.821652594998596,-36.640047038178871,55.24351797245675,150.73719561585472,95.792654631993855,33.864446841376697,-131.21505655868981,17.704120145808414,61.712769798314952,-105.11973005514244,40.565655551626961,1.7851068670424981,68.665992525563382,99.291741878381487,-66.997982033721343,-123.97856767870086,54.643740356181354,-32.367429877979234,-39.026038014661353,34.741913612410883,12.854794389505816,115.90682020286923,30.788196104343236,99.569968139398526,-173.20102221390388,28.417329885387705,-82.649533233309526,-17.665029384531909,-102.80047871403957,79.862275934288533,104.32209655120499,-126.14126810050735,-197.67219158664886,-18.331771611050268,-71.843128788871226,-127.10850387452355,39.17046888735004,-4.2700004609539386,-91.31162692487861,51.846718884491963,-107.61361145892762,-129.02009154991043,-187.1036303041121,162.53504697273846,121.51785473493187,119.09362339932694,156.67325808196622,-93.85694743073752,25.555834780157216,75.166341321688975,-154.78477173489961,102.80944328597771,-110.57852750546994,79.22289897811163,98.347450108798512,57.584071716323614,-84.751443249897889,83.197965375660374,65.370815731207387,-9.763875817769609,70.250631309052324,148.95194965806951,-58.595094178275616,-206.01535203246098,-122.29284892297383,51.879333984051456,137.17540418111739,-32.69296632747151,-129.33993714075498,52.901090988468027,-56.981749456014434,50.555755441677377,110.43738969542176,74.443968688062952,-99.520424501418475,103.51328092177229,82.763224672028485,116.25184809759482,-189.44521237387872,-143.89506310097374,-143.19927641520763,101.91172336357519,-187.3369868758642,115.52075073347314,-185.88425776966909,-208.66500980987638,-12.985587231155552,32.063924392906905,-217.8288836812242,-12.13573542369485,-189.64161434528032,80.993954200837521,-110.87132612218959,-146.52496796665707,-103.67842752286299,51.637721432219834,-12.436731443525908,47.156738544837872,45.406695180110745,27.495882390521022,102.60943628981487,-62.338618879759579,73.37132539842743,55.712738752573323,-82.999193949945536,-91.297133971411441,39.271200022264075,108.76101673373245,83.652668780048728,-52.701703229245631,-64.660997496498695,-213.44790823025821,155.60363816541513,-125.75208799887163,74.295926639842733,61.42890105445079,-116.10212749859468,56.55114270979945,71.704065590584989,161.9021706460978,12.573968694252548,33.357498348855543,124.97277707131573,111.4810749345401,150.67845366749273],"z":[22.604863876796287,15.028974999490206,-17.116266642699173,27.45511162480242,-35.159575218928218,-40.199809815017737,15.35693234055382,-13.553149742458968,14.091039091411124,15.174928182797835,-4.9879413194293871,-2.3305604783166158,-41.918666059534502,-4.0252875342693057,-23.974945243312728,46.582906442003008,38.587317416408858,-14.948737372981606,29.215855236326433,-25.192038977617024,62.394762663615815,5.8735302073926938,-127.83173430256969,-20.601950589744916,-55.346849836541438,12.127668144883748,14.134638339991634,4.0203991760140063,-48.476317456936528,10.5941490710522,97.130294063690556,4.2404358694813764,-0.19024335834979592,4.5040292843226144,3.8360530546128322,66.300202557206859,67.485891555360254,10.476750403717569,11.312156634596239,47.394039250623329,61.960269678635868,11.27662089456998,-2.8647064731165415,57.79398653280473,-3.2888053783406774,57.644936145400308,-32.865578363876217,-46.182687415020787,-10.767145386397837,71.004802058728828,92.028454135937935,45.959459995563748,-47.992647238259607,-34.804659409384037,69.632812199149356,51.382288152125582,-26.848395075458765,18.859038495562416,-26.908100656925352,58.469719159845241,16.319330174037361,-45.869417490511751,-28.799281873071369,66.83224378897134,-35.94002196880696,-54.130642548222923,43.306034935428357,-15.155311707159013,-25.170746589430639,79.246166359876398,20.134574947813952,102.02424979551202,58.266312407213277,-29.763555921676581,-4.2257469627897333,61.776549220055017,-38.051346333435163,-9.1699786828039507,-5.157257236123753,-32.616597378077159,18.091575762579371,-92.507186932643037,17.319962946668518,46.441541588578168,33.713204462871715,32.630753942292003,5.1253021850183824,-41.122403047151145,-4.9433125425453817,1.6497316623842311,27.411972306207812,-109.33037585117076,11.227546175321821,-17.064585854263687,46.266684121584881,-122.8912887238702,-44.818633455034416,0.41106152636774501,-45.531410665200184,4.2432811738972553,-17.406590512725952,-90.142472192536232,-11.115912049263986,-101.82819451886354,28.916804744822674,-18.936269886893587,-17.613853582105691,-38.404561537634549,-20.915905424151717,-80.948893773325636,-28.290631164304664,31.327494140526312,-16.356429672980688,-12.205707580239318,-78.959155065945382,-128.86169873736415,-6.2440899637121916,20.55130652435119,17.862114626044963,-45.625201644814759,61.658592590422778,7.3164700683899611,101.31673751747829,49.92525494066701,0.59234705874829474,-88.555275340232228,-31.494979134538831,13.732561974704652,-15.064204351738644,-26.765725367981027,14.587908184187695,-7.2622732590509607,-36.873630276294058,-2.959823578904083,-2.4290575667772334,34.285947902435694,18.663710955316258,-28.125468757112788,20.947903414782203,25.061436839720937,28.848475548749814,20.98675339252291,-24.576549536994118,17.196420132980716,22.566393404282501,19.459167755104701,29.582217889149593,67.685974703476404,2.0772251829136894,-4.6326148939464931,54.827595652751896,-40.894259494965652,-77.502609255784336,-5.0940956592768734,35.034997433473556,-14.76434552827175,-9.8177054299456064,64.946177491565408,24.835459045075545,57.042226163799761,44.506346453433686,-3.8061802529526205,5.1071539876824508,66.415058298519341,-91.66332348147894,-19.36653916110803,-12.77015733972836,34.846526273531069,-28.898522102180316,62.515023350323858,-17.873375639126834,33.631732985254345,-6.0919179858527706,28.461843285685863,-49.565504431719596,-6.0435717612318944,-5.7480938013830656,66.721627798206853,-42.602277420653131,-0.5944156312852904,-7.3022616301217331,15.120140432534759,95.588185808461219,32.064152389538634,55.691642358318944,60.868937900859798,65.026057814306213,50.25966894229532,84.25716823379453,-14.402360076408028,-4.5260387069534334,33.072335373631034,19.868163031354509,-21.321436489965894,75.573647651436644,-26.60605391814121,84.029052110319995,45.49360834491619,39.233181068861128,79.02895551339094,93.676949895131443,-12.771902294178316,-26.328271319033146,45.928434097544027,60.075695498781499,55.093188310868385,99.449121928737227,17.021719028318742,41.50946143456067,-8.6992393953132208,57.973540875019403,60.576860544950776,23.812347180247652,16.009692674940617,92.211586914679813,56.350124414008405,36.876461793850289,48.71724770576327,-11.37311915401169,39.358840096636179,-20.433891360173881,20.717243128127105,28.538657012129942,47.424009703754123,-26.17874212099797,62.603912954570596,62.623317669186449,32.365383903057257,42.543937959793077,77.808216688094461,-21.776638379245558,-14.153530253543646,-92.216211103477221,-36.331519150373779,54.953231541826852,-30.888175282604113,-10.398445464296634,13.718702004582603,34.915314596135651,76.988966411958273,-33.159154712502129,-39.634481088308604,93.690877764279435,31.031500923873747,-101.46194621928824,2.5326940083242242,-37.620747006355849,-7.1177443351746277,-12.104210879999521,-5.0278191568756894,-28.902330300972952,-30.315142265877245,-4.2013143659796999,-4.3721210167560915,-41.010644658669371,-37.697597864503393,-42.821756633359996,-39.191473714996256,-37.892055512664179,-2.2702255174748731,-55.617864590266294,-15.134299919036851,-22.854231847285529,32.468072345405211,-2.7457549039837175,5.5203049982790349,8.5370450311756088,-115.22350402076609,-9.5257071423893702,-14.580206458290446,-54.024359714080781,43.235273336500171,-7.9790996190846153,-78.160058327108942,-30.242360155175131,-5.1680516451538088,-8.5889615976125988,-6.2268599137161758,-93.942241660913197,-33.396226414585655,-118.7150049162835,-112.20212710987846,-24.915531892211781,35.412901708545974,-57.325435527667281,-33.641504644015143,-31.657014705571108,74.127817961061808,75.126387516758598,-123.96654412356818,-70.085820867778367,-35.909897732198274,47.932713981854285,-15.982679864841156,8.8384797951982055,3.5031394164624445,74.657054254858721,73.124161980697181,-32.913370730717062,-20.643131086953144,-31.887707351506482,-120.54690621828857,-21.395643182329792,37.916099778579486,-123.21770092554681,58.78723733193268,-11.351293218925152,39.724044280584096,-2.0122363676351718,11.091852789345682,-13.186263714071982,76.509885653778198,-47.014292418456954,0.30113112424141469,13.509909357631914,0.58766027965886125,-121.02138111000046,-121.64469650469573,10.231696735425079,53.980476232907499,-8.1754523561185497,-101.42575076366899,-101.25507824025064,-41.309894282093964,-27.103580788582249,25.790436159090266,-104.13305929974511,22.908714598344364,46.394873198526234,-13.032399069311563,-36.902337977988097,-101.12043338593244,-37.036079416263505,20.762622333334274,-102.57884098282975,63.566671039565065,-22.935966741305887,-3.3254957165583572,-40.31690742443012,-23.451338586759046,66.338529080137874,56.925197726741189,-75.489063467944788,1.2134607642778903,-125.18100608471553,11.573331922944213,77.003537046571353,-48.80861585206442,9.5703548432142824,5.6088433669834581,5.4714253930965029,-10.027360812463289,100.9245761933191,-50.440294676209049,-22.301799181710876,-39.829826936028375,-36.913366780194494,-1.4648094696319032,-0.8273137557544531,19.376161154672484,49.267482751935098,16.719560394319821,41.797205229262971,48.382356364559115,-29.408518827235188,-10.414250830291575,36.231393930842991,-9.4738707482680162,67.280371543400577,20.821949245193242,4.4945207479983988,20.545260565857987,-117.90992910539946,10.70161964706967,-30.662639709623924,-59.7539273902985,-52.400311015399225,-73.611736374596632,-30.822619696722974,-102.64799394754696,57.03385651713635,-36.874357613238793,-50.103776751580391,3.4805606521275378,-8.6112265698101886,-26.898482575300491,-36.252163011683592,-68.600567742387071,31.052628119480076,-33.151107307398348,8.004759453789756,1.3309691602764471,-57.860999667211665,-66.942644962859958,-56.798341770787012,48.876375933812021,64.667131868384431,-0.63123806279482386,45.26921920982204,-13.224353540626355,90.7033252783487,25.684153206702259,38.848591199065424,-37.699567734986097,-35.350498628646648,4.2972940901368428,-52.432219477308387,-32.409263029661155,4.9027062544978026,39.729823809884522,-64.81590765948323,43.675592495852399,6.8780573311542801,57.883189658665032,-21.007791013187401,-38.562288617354653,-123.13570820333172,32.110860462966933,0.43058759788613832,-6.8589187867143409,1.1975098517324605,5.1195522016841881,-54.113071352123946,54.725962478628809,-74.227967040352169,1.0914631481146653,52.855497849197214,-88.21607279352871,-11.958447359915906,52.969182277020238,-13.634302575457465,29.569153432868404,-109.82750125475002,-31.060618825289005,-40.677128689708034,-127.15959198529895,27.576331638910233,47.138306705753315,1.6006781817929567,19.016145339017509,24.484976764605701,57.474556630367566,-28.276313695282184,-16.131397064061069,5.3400304188543295,33.113371607680655,-2.2022551382820654,111.47167882605902,-33.84875960659361,-72.212239436781886,3.2352689490849662,-127.79861141180935,12.703593393317842,-35.456808184692129,-16.288485073712188,87.734066228009766,19.848233419334068,2.877036698818535,86.109018202948334,60.310685527009468,7.5065583480889106,117.14403020253724,22.004543723245963,-10.494426167766918,-10.724925103326704,-6.036981120595259,-30.356142706109896,-24.640333602311195,9.5313671284664867,-34.730288703889869,-59.314564491593494,-119.20479848129563,-11.82028375096808,71.240423408409924,8.5082184436741564,-121.19957200375367,-130.87595797518,57.285024685593939,20.404220898707703,9.484729392128715,84.59536754808866,0.83890586988489135,88.697703072390965,13.784476968746642,30.237100957597054,16.928179020935339,-3.4290531379287779,116.78787538894919,-10.327818685042041,-7.0034923172210855,-15.480979958255991,-51.640972932659004,48.554310547219799,-103.6640069704285,-87.896465966039685,-15.333846093954232,45.233882472938582,-46.721552701013231,-126.9498301433683,76.590800070006196,13.650079514783297,-35.201651748249404,-33.943929068143689,-118.4938759417157,4.3298163009738548,-69.832538194656465,5.5169325476520301,2.7516827520111025,96.40276186553379,64.647566827257236,7.6664972254614074,97.337017585093022,7.7438389842819646,28.103853900565607,-39.083926886298165,-1.3760284539598402,58.602410599704655,-125.96329407033417,95.997545206372678,-120.11558000720626,-121.83113468915559,-44.008852321245577,-113.89178196170215,-53.414435028253031,-94.73485325623075,56.885041324937056,47.548352598145613,-27.456499404929012,117.22908518850349,-27.083125291977186,93.433187706014692,96.749622131955874,44.204111184035483,27.089848730450438,-23.961802150538691,44.899229910770416,-82.700425802605125,-117.18438199460404,-32.808510046545706,-10.673852088024441,-15.465245405490741,2.0448622074714518,3.7839213254249953,69.850644578355457,-7.9050541390821474,27.070185339529946,3.9662953174871909],"text":["Input: 'aabo' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'afsk dragun og huusm saaer 2' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'agl horseman' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'almswoman formerly farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'ap hair cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'arrendator' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'arrendatorson' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'art metal leaf cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'assistant horse keeper' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'at work with farmer' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'atvinnan landbunadur' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'aulsbruger lever af sin jord' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'avlsbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'avlsforpagterens tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'bacon factor pork' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'bank agent farmer of 220 ara' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'beboer 1 2 halwgaard madmoder' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'beerseller farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'beeste of koehierder' (lang: nl)<br />HISCO: 62410, Description: Livestock Worker, General","Input: 'blacksmiths farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'blind institution keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'boels mand og har 7 skp hartkorn hosbonde' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'boelsmand' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'bonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde bruger gaard' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde gaardbeboer og moller' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde med 14 gaard men fatti' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og dagarbeider' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaard beboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaard mand husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer en del a' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboere' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardebeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardmand hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer husbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bondedotter' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondehustru' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondemaag' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondeson' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'boot clicker or upper cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'bover' (lang: ca)<br />HISCO: 62420, Description: Beef Cattle Farm Worker","Input: 'boys refall' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'bread store keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'bridle cutter employing 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'bruger lejegaard' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'brukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'buandi' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'burhouse and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'butcher farmer 6 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'carriers farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'ceylon forest dept' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'chemist and farmer emps 8 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'chocolate depper' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'chocolate stacker' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'cloth finisher and farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'coall cutter collier' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'concreter labourers' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'confect master employing 2 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'conrador' (lang: ca)<br />HISCO: 61110, Description: General Farmer","Input: 'cordwainer employing two men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'cork cutter formerly' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'cottager' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'cottager dug' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'county court keeper office ke' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'cow keeper' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'cowman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'criado das vacas turinas' (lang: pt)<br />HISCO: 62420, Description: Beef Cattle Farm Worker","Input: 'crofter' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'crofter general labourer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'cul' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateur' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateur son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateursonstudent' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cutting in new ground' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'dairyman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'deanflitsman' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'deceased farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'deer keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'deres datter son' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres pige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestefolk deres tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do meieripige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do tjenestedreng' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do tjenestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'door keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'door keeper down pit coalmine' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'draeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'draeng tieniste folk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'draenggosse' (lang: se)<br />HISCO: 62110, Description: FarmHelper, General","Input: 'dreng tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'driver fiskerie' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'drover' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'dyer farmer of 2 12 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'e d on a steamship seas' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'eier af gaarden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'eier af stedet' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'ejer gaarden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'ejerinde af garden jordbrug' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'embroideress on satin' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'employing on this farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'faarehyrde' (lang: da)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'faeste gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'faestebonde afg mads nielsens' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'faestebonde og gardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'farm hoosf' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farm 360 acres employing 7 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farm labourer on hop farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'farm of 350 a employing 5 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farme bailiff empy 6 men 100 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer blacks' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer gardener 35 acres emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer landowner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer rd carrier' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer sheep dealer of 14 ac' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer tan' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer weaver 16 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer (deceased)' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 100 akers employ 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 1000acres employing 29' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 101 acres emp 1 laboure' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 110 acres 2 men 2 chi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 139 acres employ 17 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 151 acres employing 6 l' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 198 acers emp 8 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 200 acres 40 arable emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 23 acres 2 men 2 boys' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 27 acres of which 16 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 323 acres emply 13 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 325 acres employing 2 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 33 acres land' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 330 acres 7 labourer 2' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 35' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 360acres 7 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 378 acres employ 7 serv' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 4 acres joiner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 4 acres lands' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 400 ac employ 13 men 5' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 400 acres 10 laborors' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 46 acres 1 servant' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 50 ac ar emp 3 men 1 gi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 527 acres employing 10' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 60 ac employs 4 servts' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 60 acres lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 61 ac arable emp 2 girl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 7 laborers 3 boys 308 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 7acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 80 acres 1 lab 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 9 acres and blacksmith' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 90 acres employing 13 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer acres 104 emp 1 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer acrs not known' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and butcher' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and cattle dealer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and miller' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and miller employing 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer brick work' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer dairy 115 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer deceased' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer ect' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer emp 5 men 2 boys' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer employs 14 men 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer graizing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer in coy with head' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer occupying 32 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer occupying 68 acres empl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 100 acres 86 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 100 acres employs 7' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 108 acres 1 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 108 of which 103 are' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 111 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 12 acr of which 6 ar' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 120 acres employg 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 126 acres constable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 13 acres of land emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 13 acres provision d' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 140 acres partner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 15 acres 9 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 150 acres emp 5 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 16 acres inspector' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 167 acres 90 acre' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 180 ac empl 7 labore' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 180 acres 8 men 4 bo' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 19 acres worsted w' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 200 acres 50 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 21 acres emp 4 bo' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 22 acres employ 1 ma' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 230 acres employ' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 24 acares employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 242 acres and 3 agri' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 250 a employing 8 me' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 250 ac emp 3 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 2700 acres of which' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 3 acres and fisherma' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 4 acres coal agent' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acre arable 14 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acres employg 10' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acres empyg 4 la' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 44 acres 40 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 45 acres proprietor' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 46 acres of grasslan' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 47 acres fuer of s' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 47 acres emp 1labour' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 51 35 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 52 ac ara' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 60 ac employing 1 gi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 60 accres keeping 1' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 66 12 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 67 acres employs 2 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 735 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 777 acres empolying' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 78 acres of land' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 81 acres emp 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 82 acres employing 1' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 99 acres and steward' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmermillerman' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmerrr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers of 32 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers son student' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farming 250 acres employing 11' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farming 7 acres of land also j' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farms 56 acres employs 1 man' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farms son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fd bonde' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd bondeaenka' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd hemmansaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd torpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'fenadarhirding og heyvinna' (lang: is)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'fermier' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fet farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'find og gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'finisher and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fisherman' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman' (lang: unk)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman light keeper' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman man' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskare' (lang: se)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisker' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisker' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskeri' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskerkarl' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fjarmadur og slattumadur' (lang: is)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'fmr' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fmr retired' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fmr son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'foderaad af pladsen' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'foreman of farm 100 acres empl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'forest woodman estate' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'forgeman employing 3 men 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'forpagter' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'framesmith employs 6 men 4 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'freeholder' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'frm' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fruit and grosser and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fruit grower 14 acres 12 women' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fyrrum sjomadur lifir af eignu' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'gaard mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer manden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardeier' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardejer' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardfaester' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardfaester hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardskarl tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'gaardskarl tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'gaarmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'game keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gamekeeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gard beboer madmoder' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardbeboere manden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardejer' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardener' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardener (deceased)' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardener [deceased]' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardfaester' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardiner' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gartnerlaerling' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gate timekeeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gdb husb' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'giestgiver og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'groom' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'groom astler' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom at new inn' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom hotel living stables' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom lad on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom to mr prescott' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'ground keeper' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'hand loom weaver and farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'handelsgartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'hans svigerson i huset som tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'hans tjenestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'hans tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'har foderaad af bonden' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'har lidt jord og renter pfasahnmester sandbergs enke' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'has the farm' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansaegarinna' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansbrukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmanstilltraedare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hmd lewer af jordbrug' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'hmd med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'horse keeper' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horsekeeper livery stables' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horseman' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horslerservant' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'horticulturist' (lang: en)<br />HISCO: 61270, Description: Horticultural Farmer","Input: 'hostler' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'housekpper on croft' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'hsmd med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huijsman en not mentioned in source' (lang: nl)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfader forpagter' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader husmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husfader jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader landmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader lever af jorden husfader lever af jorden' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfader lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfaester' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husman' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husmand' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand lever af sin jord' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med egen avling mand' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord og snedker' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huus kone lever af sin jordlod' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusfader gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'huusfaester lewer af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huuskone huusmoder' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand huusfader' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand lever af sit aulsbrug' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand mand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord drt formede' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord og saugmeste' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord og smed' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmandsenke lever af sin jordlod' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'inderster har sit ophold af g' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'inn keeper farming 114 acres o' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'innkeeper and farmer 37 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'iron monger and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'joiner and builder now assisti' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'jointly farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'jordaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'jordbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'jordlos huusmand' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'jove pages' (lang: ca)<br />HISCO: 61110, Description: General Farmer","Input: 'kaarmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'koertorpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kronoarrendator och alen' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'krononybyggare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'kronotorpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kronotorparedotter' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kudsk husfader' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'labourer and farmer of 100 acr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'labourer general farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'labourer in wood man' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'labourer under shepherd' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'ladugaardspiga' (lang: se)<br />HISCO: 62400, Description: Livestock Workers","Input: 'lady companion on salary' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'lamb cress' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'land owner farmer 20 acr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'land soldat og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'landmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'lappdraeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'lappiga' (lang: se)<br />HISCO: 62120, Description: Farm Servant","Input: 'lecturer on human anatomy' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'leiehuusmand med 3 td land' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'leigulidi bumenska' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'lever af jordlodden' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever af kaar' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever af sin plads' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever av kaar' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'lierch ffermwr gwaith teulnaid' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'lifir af efnum sinum og veidi' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'lighterman employing 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'lino herring fisherman' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'liviry hostler' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'ma farmer of 116 acres 5 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'mab ffarmwr gweithwar fferm' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'malkepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'maltster an farmer of 60 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'market gardener' (lang: en)<br />HISCO: 62720, Description: Market Garden Worker","Input: 'marketr farmer 11 acres employ' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'marquetric cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'marsh pinder' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'meieripige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'miller farmer of 86 acres em' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'national soldat gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'nursery man' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'nurseryman' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'nybyggare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'odalsbondi' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'oldermand for stolemagerlauget kgl hofsnedkerm' (lang: da)<br />HISCO: 62400, Description: Livestock Workers","Input: 'on farm lad' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'ostler no' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'out door on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'patient tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pauper for farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'pauper formerly salmon fisher' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'pecheur' (lang: unk)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'pensioner late horseman on far' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'photographic cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'pige hendes born' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pige tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pige tyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'plads med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'police pensioner and gate port' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'pork and bacon factor 1men 1 b' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'postmaster c s officer c s mes' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'potters transferers cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'poultry dealer farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'provission sho keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'radsmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'raettare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'retailer of tea coffee' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'retired eart india erchant' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'retired jeweller and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'revierforster' (lang: ge)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'river keeper game' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'roadman and dairy farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'rogter' (lang: da)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'rogter 1 fjollet' (lang: da)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'rusthaallare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'rusthaallarehustru' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'seedsman and florist' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'seemsman on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'selveierhuusmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'selvejer bonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'selvejergaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'selvejergaardmand og jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'selveyer bonde og landevaern' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'selveyerbonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'seperater of lead farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'serv on the farm indoor' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'servant' (lang: en)<br />HISCO: 62120, Description: Farm Servant","Input: 'sevant' (lang: en)<br />HISCO: 62120, Description: Farm Servant","Input: 'shepherd' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'shepherd late' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'sjomadur' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'skogsvakt' (lang: se)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'skovfoged' (lang: da)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'skovfogedaspirant skovarbejder' (lang: da)<br />HISCO: 63110, Description: Logger (General)","Input: 'small holder commonly called f' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'soefinn lever af fiskeriet' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'son' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'staldkarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'statardraeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'stock keeper trimming' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'stockman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'store keeper trawler industry' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'strandsidder' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'strandsidder uden jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'stud groom' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'studentapprenticeengineer' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'stundar sjo utgerdartimabilid' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'stundar sjoferdir haseti' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'superintendant of farm 87 acre' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'surado' (lang: ca)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'swan cutter for tus' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'tacking tinsoles on' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'taersker tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestefolk hos forpagteren' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestepige tieneste folk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tilltraedande brukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'tjaenestekal' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener en nager' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener et plejebarn fra opfostringshuset' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjeneste pige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjeneste tyende karl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestedreng' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestedreng hans jacob rasmussen og maren kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk conditor svend' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk erik larsen og ane kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk hans olsen og margrethe kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk hans vilhelmsen og sine rasmusdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk jacob mortensen og sidse jorgensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk paa kaahaugegaarden iver maelhe frydendahl bagger og anne margrethe bagger fodt madsen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk rasmus hansen og kirsten larsdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk ved hovedgaarden' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestejente' (lang: no)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl deres barn' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl frederich fugl og ellen rasmussen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl peder nielsen og grete steffensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepige hans jorgen rasmussen og maren jensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepigen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepiger' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestetyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestfolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjennestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'torpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'torpareaenka' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'tower keeper war department' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'traedgaardsmaestare' (lang: se)<br />HISCO: 62740, Description: Gardener","Input: 'traedgaardsmaestaro j a w och' (lang: se)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'trinity bury keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'tuijnier' (lang: nl)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'tuinman en not mentioned in source' (lang: nl)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'tuinman op batinge' (lang: nl)<br />HISCO: 62740, Description: Gardener","Input: 'turfhever en not mentioned in source' (lang: nl)<br />HISCO: 62970, Description: Peat Worker","Input: 'tyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'uhrmager og har foderaad' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'ulter hound kennels' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'undergartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'vilkaars kone' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'wks in nursery' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'wood cutter 203' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'woodman' (lang: en)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'woodman employing 4 men' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'working on farm laboruer' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'working on the highways' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'works stable' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'yeoman' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)"],"mode":"markers","marker":{"color":"rgba(247,217,52,1)","opacity":0.69999999999999996,"line":{"color":"rgba(247,217,52,1)"}},"type":"scatter3d","name":"6","textfont":{"color":"rgba(247,217,52,1)"},"error_y":{"color":"rgba(247,217,52,1)"},"error_x":{"color":"rgba(247,217,52,1)"},"line":{"color":"rgba(247,217,52,1)"},"frame":null},{"x":[-73.771724531040576,-14.00972414063688,68.65875613998989,-27.862461107461936,3.8680414176300557,-3.3244631344249611,-0.17433990537517996,102.73336461391156,-6.1690032511092179,-54.457279497180764,-76.896252452061731,-2.897462843828527,-50.003584739835333,46.378097373958738,-43.339190759727188,90.935196511902944,122.04418418130751,104.18951019987918,83.771577622698914,-43.311514896819681,-56.447130201337259,3.3511153536185763,-72.351590076037624,20.338577671986453,24.705577346534028,-5.117831122993918,2.0485852567733098,-18.29279431184159,-31.939613483764798,44.682850750630983,-38.495431524882314,-51.364919658558442,-13.103151768540558,80.253985898115573,-48.723076203906281,44.363485769439258,-22.365054899955052,47.290281158345628,-41.78795566548925,-32.212245339018885,-68.64265760908637,-42.804764895633475,-41.398475293250108,-54.933392161986113,-34.892701475460306,-63.771200580612508,-41.834693279275562,-36.548598284720541,12.109598892595118,38.999716434012321,22.540754720404262,89.839179987257907,-0.15751040997095445,-53.372650004778421,15.579455614907761,-14.694850180947446,-43.643544281129877,87.346961498682163,19.005739539435066,-0.90221560608748064,-11.644086635487845,-14.094188205499286,-2.6604925372528347,-51.228559566691736,-61.054639726295619,-70.238228455232601,89.449357414499914,91.245790023859229,35.8649784134616,-49.293788175010441,-48.985712987633015,-32.802109264288156,-27.162456134280127,-56.679612951319328,-22.948494852488199,-11.675209902110788,0.29423978013936397,-19.557986824019078,-42.534164903330456,-44.118895357843812,-10.319126838244712,77.408641540585464,-38.23151592024665,27.012159002409152,-14.728262541437035,7.0997639560965888,12.2383306623687,-2.9690850339970196,4.4281231841225779,53.786383488474002,29.307797246310194,-21.573877295100083,-13.669546020506258,10.169774407301986,-66.619197838535769,-1.7637650920631986,7.1638808313059039,-67.720569936045024,-21.161078795360034,-61.123992183284933,-21.413438046873082,-27.540771338008884,-35.291767193686368,-6.3241864649044954,28.438136848230599,-65.055795328235448,-50.082941829398223,6.2581435491086097,33.430592381867676,45.997137865632325,2.3615653088174744,38.541385437564799,42.783394312275931,29.795868513126386,20.669185511064075,84.287208161953558,10.789258447438506,-37.512597356873769,-12.825542633032059,19.955665267482896,4.208105380211725,-20.622759966091035,20.446573610690681,10.421932324635335,18.819065614586858,-22.230816932501295,-11.383973310095058,-39.120611168393218,-21.668746072134482,-8.4765863943088871,-22.171570556349522,-18.622401446616244,-32.135829108433093,64.185452865691971,18.941447286947916,48.535989442950324,3.5444245680184969,-33.357052165310606,-50.668160994280413,-40.4061808580555,-14.473585984785291,-30.676377175670829,-44.630593033072486,-46.474362004904187,55.543385156518859,-36.598804825813595,40.341837289887927,-64.159524458099838,39.837465991356467,-37.272526426917366,-56.778592663197479,-74.778467229392248,-79.849721340790012,-36.693715742389188,8.2546676864692685,-14.556051389128886,-24.66414109567673,8.7605224065192608,-39.95486415243581,-32.182703953407703,33.724461688515824,-31.96938449332967,12.64252448442727,-33.129681233994326,-64.801178807367009,19.433061185733731,-1.3568536188769162,-17.463190475942117,-36.864659648810914,1.5385038959650568,-64.75576165517451,72.457682764003025,-24.117514344113353,-30.791780654943079,-74.311510012696658,33.288670547156215,-91.72219522494008,-27.178854498085649,72.562488108293692,9.9698404596915715,43.468695215565148,44.26030802366342,-29.58815960569812,-66.656464901470429,-16.475213389437535,-11.920786765332233,13.535777506436256,30.029408416644234,7.3166499294932956,30.019517101092497,-45.293112278282443,-42.187306990463505,-75.087107658571611,-54.290184310184401,22.0707630459965,92.777023636047062,30.217942650652724,-52.796639976571782,-73.805885486039713,-45.484998795605613,13.596835811297042,-37.395304666912168,54.292132754578816,40.175535726491795,42.432250277398488,-31.654211568477724,-66.75920384900391,-22.984363647143731,-36.435774994237455,-8.8194480439101177,-1.2472923697179772,-1.8487152696971367,6.7886217439936614,46.283896859502015,-2.12935411099867,7.3749325959640331,54.112182742681988,5.159003745475645,-6.2745508903848695,-1.09180010884023,-44.959131973567096,12.161842779455171,46.429523327580426,16.607101869734159,70.649872869358362,43.573531782594856,-32.48626873103332,59.253770311615497,-1.9204909262084915,-21.261993633996426,-51.925897243224981,15.524495383753591,82.903997587780992,16.209908658552518,31.351666785717214,35.299839672600136,29.103437977642542,-29.945734877019525,-39.718463238837046,50.371347617450439,-55.11325376458587,-20.382154056481507,-49.508923095144624,-57.802594128274222,-5.6892212034793008,-19.441010575738808,-70.540836930093775,40.778307828092096,-19.037595918865392,-23.991154335389016,-43.733172388565329,-40.713342835381802,-19.178097219015957,12.744956886389986,-54.133732590906469,-15.097941438974619,-5.2241310300772659,-0.3224271593954785,-45.072230465345946,2.7273497864090461,15.514076186164267,47.755943659841122,-74.067061756025183,-60.299824188745809,-48.186233687379797,-67.970338533714553,-41.015038943905864,14.006615574570356,-52.624266206586931,-72.54460901073621,-20.926525244013899,-56.174366250741983,4.3286740383178852,3.5429489618408367,53.736119126293353,-40.159302316909624,-17.798378884981133,28.76966533342998,-11.150419538843888,-69.915095750704964,-21.008596367332501,-1.1614549355190837,17.197395787662664,26.075012151311181,80.046242780659512,-20.376308685350303,-10.419580447808974,-0.87604093001844829,-21.459704413099324,-58.851593044291903,12.337507429322368,-8.100144824876276,-16.796374408304583,-84.036627220435363,94.040222486446524,30.55944236971726,-14.039374076998419,43.216498362848874,-75.56627964487538,-56.861686906498321,71.960719261070736,66.490535936646353,16.786878884005716,54.763820211724394,-26.470320842220413,6.4848283985991131,-3.1152369584489055,107.14668330835354,-15.002163815238626,-26.885112442773298,-10.008446834066794,-3.3706077392154525,-2.0945162216788042,-38.298583624620335,9.8419633646587634,37.44111511764293,-46.613891376173228,29.990770489681378,7.3763209369126672,-59.111115703583025,-39.68372069682728,-40.879678256249186,-67.575385057698696,6.400242775195438,-64.571137508052459,102.70540786648201,-73.478611687151883,-57.392767745795176,-49.94161959405762,-13.103436653440363,26.731486285612842,-20.181468900576469,97.143499308942694,21.81064303698545,-76.694731198005272,-57.750151690209982,-9.8065128973332776,30.729581569495089,20.963747763409259,39.865401713865239,3.9586917479455233,-16.500917891750909,-36.498623301619048,-5.8985537962350607,50.757199733343867,-27.301620945589345,42.952395257575539,52.87617232279478,6.2486716450284048,19.59135834561663,-64.691905346962898,-3.6544067966512261,38.833797799388833,-37.527917333634484,59.844148947101843,-45.308322181445504,33.556990067208105,10.86852397479738,36.262089383045485,56.281769849381931,2.6894669115327088,45.649875359143351,-30.562985440971392,-54.626478105700791,31.56093168541862,-4.0371520435440624,0.57420075961904193,-6.6292659092857811,-2.1385638617447071,-44.157615782703772,-15.402841760734205,-13.495269617760737,-56.548956385821675,6.0816233682624103,-4.502546445688024,-20.918143427129394,27.618286827691684,-71.175759253734313,36.26883759810238,30.72533862141567,91.165478067315391,10.911335558658656,-23.266125829886601,-46.772592424999871,-6.6837109149953404,-35.902008721439749,4.258487383559288,47.339468797406582,-75.857088933918362,-49.830405413149499,-42.466684304171729,18.898078777485672,-61.06572957704266,-42.868840024133299,-44.857413009568873,24.41009649288829,-11.49494484963658,-3.1449317197116562,25.870722149062402,63.935413805666769,-43.19357405197551,-51.121211258080969,-0.49263971379240135,-51.471569475757498,-41.973662630898687,-56.274681240956006,-17.771119547504235,99.940503345213543,-43.003802905833588,4.4210836984069095,-69.337559293059442,-55.766395305106826,20.517668197502879,-1.882256866920567,-30.515737865414653,-63.465053189364632,-44.587916063630892,-53.387104576251119,-58.016246751239834,-60.398003050030546,-66.192368809039678,-16.921679537565566,22.009602281775873,-34.918004863860148,-61.708801980707115,40.167231987373064,44.714951480375937,34.133857747076014,-36.533925483398036,66.139099982593038,-10.856248217664607,60.302682519178354,8.9146126331507194,-48.220583143057326,41.220973553253643,-63.629819486108694,-29.209997716037151,-4.9978586473833149,-8.5532343919472247,-21.506800027805497,-48.20088993905339,-38.080534739766897,2.2585382543238035,60.874153619471592,43.43142807328551,3.0960124019774025,-35.007714046997002,36.635298121453204,-35.504446786444781,0.52218840580005699,-0.15385054399226203,-8.1103153315842178,20.785010228941506,27.662828379436068,-43.827202173129812,-12.109019130173952,22.27763551835174,-2.1668190959021159,92.449621215882246,-29.107928723943036,-8.5394833410610271,-69.832449383954241,89.498167280282004,19.463731359867126,-7.1693709724966661,-49.220342518467575,-21.372485440170756,-0.86163659613286026,50.940567837666087,51.545559874426033,22.308124705234569,-43.880818521026008,-44.721437896550171,-51.50991330722205,-54.215440547626642,8.2344398838810129,-72.142949159728246,70.562200298648023,-39.725873577424863,28.190324705467507,-6.6574991167909898,77.610852248678867,-35.446461365032853,-29.308842547337481,-31.175186107167971,-49.347837718712718,-49.671325329768372,-72.459870614120447,3.0404891793630875,41.989199834448932,12.062321438641577,-12.382077347088433,-34.361263837492729,-48.548361895835761,34.903324180232595,-82.441438500876387,-37.068160315918234,-7.5682841045127018,42.277715494559928,-3.4754199802076808,-38.098475639644747,-18.975624577604162,-51.245006368707045,-44.092574604024243,-53.866937901158401,23.470041726850944,-31.933524860481004,-10.474411421788101,-1.1919719831030524,79.153776216556153,-58.531236073379205,-11.035807163555027,-21.213395968800977,-70.434572330423535,-17.047773067738774,11.195462817938086,42.809484587093401,44.78797081763144,-26.696517762077484,-38.470826148459295,-24.353255796106158,51.822281934519197,3.1658741796470538,41.359896149654226,-40.774919922795391,-51.64510535288418,-52.325981763202151,22.776864696390934,-42.240342645633348,-53.916917776011076,-21.948206643336295,-11.480359089886434,-18.844305000760851,-3.4786967831063129,-29.572236667288532,-16.577191692843414,-7.2527800750613389,-54.970414522089889,89.132470475565299,-8.4552975070669287,55.756223653031256,44.067402224537361,-45.871276881821984,-5.7153909918805281,-43.612408015340399,43.713707487177452,88.842238681995369,-4.6665342262929332,-28.657633555137718,15.601839391561953,89.785419817862547,10.228659375192713,-39.082411274808045,-9.1087007495491985,-49.57556712442269,-2.2230035954703999,6.7023798706588957,45.319518405040562,87.111405664038415,-40.497729692699664,-9.0699159538179153,15.80275876599374,65.256927087022305,65.098745754039115,45.058741184624623,86.036182987107793,-75.94347238193879,-15.323983391357137,-71.318476423531038,-78.634441271426141,34.130028813815294,50.571176570611286,-26.312518742412362,88.33437625240262,61.652336901581378,31.861642692114355,-3.875026860961444,-23.083889371360623,42.782531728950786,25.233417774217624,-52.156108459389387,-25.534378094746515,-0.5216157570143275,-14.799616892336758,-62.85623124499709,-44.725841604389167,-77.731788604051729,-23.47503928686406,-68.617872287063477,12.187068532857605,-3.8371525345869117,28.212646765444486,-56.117432388478832,59.229670650520717,52.733568084338991,-45.395463085059582,-43.471393305035114,-11.195131133221066,-56.926200542742521,29.682472094505041,-47.615595153322595,102.47078896862025,-66.444444108529467,79.386376394017589,-40.632457220756898,-69.986652485303892,-42.650798138262843,-50.292488232395947,-31.603386343861196,-80.468390933212405,-2.6737162834004313,15.64508256100825,-90.802002285007831,7.0277607330249348,-60.938564610459231,105.73471909257603,-67.50950931693599,-10.896723035298825,47.89241705185426,11.322704980888188,96.651336180743542,39.82073842148354,79.056394392626842,54.137844533755562,85.122855134043505,-16.221642610659465,88.842321446998682,39.91087588470041,90.099215523244652,67.833461317545044,-32.170706873922605,9.4518048036796962,44.214523564126466,83.097897280537566,-19.621539781347824,81.402531468483318,7.0451343828563635,28.278282882778711,-13.085956799316593,-18.650783079891639,-16.02929864948506,101.08353566272642,100.74080087403063,85.359867943956218,-34.104879271615694,74.420221117271964,-65.876096466702847,43.92865490107387,-59.209410190970665,-46.024346425285955,-27.565469082470667,-54.590950146908028,-29.143113131171013,-34.831734871330063,-42.543106175067543,-27.09189742351807,-58.860281859430913,-28.626973250267003,89.386838693171427,-0.40350091164155905,64.536617463359491,-56.570748034144977,24.048046018646438,-4.8697186727950612,-60.159894687435639,45.839545029792184,-6.2910787472362708,33.757952948036433,-11.007087505796134,-74.824833554173452,-8.7308130332596594,-70.795035480657134,52.099179761834101,82.148620849572637,-12.45782906379681,80.319790748694203,-60.415240891971663,90.755966840139465,66.652041352638065,50.429397990177307,49.62518143825055,-28.633229995520118,30.390644436403743,-66.375649315509179,30.932021611127169,27.113388796050153,32.079851397062967,-14.013416319851839,-4.0561682527223191,-34.038299258644628,15.485834495984481,-70.009470028631839,73.477771869573772,65.76856522802062,9.0478310944592621,-39.50038424704271,-17.233225993622838,9.3118419617910266,-74.634081138143117,-5.6410444836488569,4.2255066662582577,-17.584041401712486,-33.217473619128491,-28.760128951394062,2.8933952059038908,9.2800289084967087,8.2612026032313643,-11.807251777201811,-51.496171203779731,-48.622410910403637,-46.251992131878907,-78.153369570006447,24.389461771567881,-33.927675519760434,20.386478166439311,-21.584754887788467,28.179394547135129,-10.21423868412216,14.760046758327556,-35.34981575345855,4.0557020447983101,-29.074124295864788,8.5059383592293685,9.1822361451055254,24.894409788785431,31.389273718741485,-18.659749857752505,-5.1189339982864688,62.334357445244443,-0.3602698086038057,2.2222147549186819,12.038134810817295,-43.447076432776463,13.116756031730072,-62.789852042797804,99.579348016343005,-19.027237432324299,41.610757839353802,-14.327104386487168,-19.515189373237153,-23.641592405317454,-35.576370506892772,-31.575905058104283,95.838247415402989,49.541400692297174,-13.334949896658516,-39.979800162294318,-66.988928140523925,-12.080163977914966,-39.054919403117168,-39.108277840967567,-43.351149498140053,-3.9215107392123909,-55.178496280571807,-71.091599816641619,-42.62570302986213,-16.232142759907536,-26.190191400691972,-3.6411941404253438,-50.371760042167431,-0.11972947322636697,-1.433236262099449,3.0486124428556876,-30.758693532563782,55.720292759213393,40.877980130198985,-54.182306820958125,-4.8141260380421871,15.428629155819999,-55.118555903052432,-56.062719646716836,6.0889255376176399,37.482871763699961,24.976594741469111,-67.5116175689421,37.542606522572022,-78.881646982190986,-47.394044016452646,-40.755497399065874,-29.569743535045767,-62.484622184378807,-38.377359651803125,21.966812366686845,2.2459834259355564,-22.638475222213795,-70.532295319989544,-47.051934506594179,-16.525116612011065,24.078870084140743,-38.50965497222105,16.873020646596487,-3.9633455341579404,1.7664096351263694,-43.669812256522178,-26.038856545092678,-47.268153780558556,14.392415604778284,-54.171154967064986,-13.177256310734009,-36.272603593316354,0.30992866096942151,11.783004271801241,41.237580924252249,47.825724175520982,11.020284748599884,-5.3153246345291549,-55.150457895120113,26.452960490029145],"y":[43.384181476403086,-103.81915367705875,52.369794105088054,-178.85396554746447,-109.4589114861073,78.868609162719963,19.399767879886628,125.0121800933059,-196.14127038553275,-43.134079605491046,-68.876714752550214,-22.723577991523442,54.563336906385238,-84.583472686086026,-44.95257380133409,97.220438203766975,83.141189892469768,81.425809706598287,91.242810867290515,-178.15804131448198,-44.938827123666293,73.840405690923902,41.955556241058183,-67.065349102162585,-55.564699274405456,-4.6798586515492699,8.8061973844089056,94.642366209334682,-108.61952450454103,-80.871043537404731,137.12967370685232,30.882837744898605,-90.956122212262017,78.458776632763318,71.735409037009376,19.561249465012448,-76.703094778950785,119.03037987889512,-54.556790601591878,-1.0016002940847895,-41.691721254890659,-50.835334640600429,-205.27889526735029,-182.59067365456841,0.12713649761951465,-82.246832943679266,-64.71912547001304,-15.944460128603311,-120.1122898265248,62.221957590407996,-69.017796938931895,119.97557279083911,-99.304851015410662,-195.85840884785887,-186.24810895911472,81.708601634790156,-56.841232692314911,95.238694066655185,55.090647703992154,79.217897486905741,-186.61845303441356,93.720161533081821,79.853952316407785,108.01987632945523,-109.51094469797783,-12.291870760726477,137.39908876389353,137.34477188230119,33.489867610322548,-109.24178512634748,-187.33696405467779,12.538268516011739,-215.84128325061684,-29.39661956291615,-75.097798481452728,113.58294597712737,-42.143780695321624,108.76486657480569,126.31907840015371,75.644042937024963,-3.3784672431689997,93.691886371259926,-49.017413519781719,-7.8961741249698667,119.86832428473274,-126.92692839921993,-51.985220521426278,-122.16989290676868,33.147806853272897,43.478437407058536,143.05241078211526,-180.4546595134226,-110.63793589892947,-185.86844546037173,-84.350326683516101,124.52328396827571,133.85578431647434,-90.479839293266764,-75.522836133424605,-94.11266947953753,113.60517969854824,-32.040305152544406,63.656626992381952,123.97598023763769,127.38785672852936,-97.849794022108313,-92.83329503981939,32.357159062822845,85.344326644456444,-17.647309974321274,-137.24883446490645,66.376496561573035,68.731644953655277,16.045089723903164,107.58418390895136,105.54193726873011,28.831751895213785,61.536050840878154,-59.764403417897327,-113.30424336824868,-49.487059450774645,114.14362992992341,87.458704193338775,18.216840609209562,-46.025956921155633,-74.473141169108985,11.239147826801801,-75.015960933616242,-67.223647039498431,12.533395013658247,-69.895171384844303,89.65344542334995,-72.010503607326712,8.9844425821579659,-26.461144732632579,68.614959387027852,77.098708317912653,-16.801129158374078,41.951452823262329,-75.247916677981607,-95.805127704104294,-105.2341586703802,-73.40627224390812,87.198687452158751,67.513833149708134,20.359764888000296,88.991733091034035,-63.865271941424439,86.889009524455986,-109.61853133607795,59.092904254369124,-62.19329690373069,19.416201465859388,-22.67717047730482,14.870668367551056,94.252626136283496,-72.210058385513463,15.309811075816684,-47.610755343469101,-107.64490578932657,-19.562176055449957,11.741985797934971,31.263963189229596,15.778591134797647,-48.996941566795968,52.746317355267713,-112.52079524061803,65.26014350616984,-23.132851647778693,-44.298797252304965,93.881282386853158,74.038832453523739,-1.3834518795799324,-74.857054261875533,41.884960738487322,-222.7807811505582,34.453867119377477,-208.42332769006339,59.434352391096695,14.981347618216581,51.232047723946266,160.3873423855047,-160.09918801577686,-45.572042316010503,-202.85831611378239,-94.125487771440604,98.950315112621468,11.560652845130372,-52.048876524328946,115.85484808008107,-191.87530516680374,-194.4520775644784,-50.835611689673982,-195.20861846023968,76.239531138985825,134.1290626314489,110.46956077025695,-122.137314334907,15.431660556157075,119.83759095001056,-49.054692799179605,-60.234069145490629,66.891338846748525,-71.844419500717024,17.944534213631339,125.78717210429707,-49.705214037295484,-138.71952184572234,65.722409132449997,-18.559653158765531,14.813793112401394,9.4020199265323505,15.016832135400129,-94.181540076827631,-8.1005550880376305,96.306622449341944,-77.151865050412084,-28.331209057014462,-57.729735678561354,-181.69426976813429,-182.37297857132452,77.036545955117134,162.97979036579099,115.63449389061633,94.032595260102994,-20.590859328618368,-20.489709867498718,-28.649769429674418,-57.915078479457783,-104.31098855134263,-28.055550187060337,-68.029806277151238,61.041816469430664,-65.65563294668631,-68.271483983693088,25.202006454430759,26.354209930423092,-191.55419930742093,10.498687546386025,0.61315667043354594,-128.05039315300121,-110.78023361613153,-155.89632493819082,14.983731387027014,46.284092593284832,77.211678172389,-55.331457292794461,156.41056072514542,108.96524957160652,-102.76187159795511,110.15984263578476,135.25169529555447,-106.38754588859855,86.479731780253942,55.359829238313431,-200.64163690786083,-66.635431075632837,-17.829402827904946,-192.88171004427014,-58.523995454689882,108.92043769164994,5.5551072392178344,-75.354546603012352,43.027159746311952,-61.333226079615834,-99.196664160611775,28.892967011053724,-0.034171490356084515,72.676505967693657,21.172300254123023,15.985821984321836,-124.66377961936412,61.946766816535913,60.286728948627157,148.45772818759707,0.5236839364462853,163.2019140840961,108.58429923287164,103.01935908579384,52.651326926082405,-83.816757463801437,-102.75791275797259,-153.78661508618822,-146.39039310322164,95.217398757835355,-207.14832315820502,92.654835951022903,-6.0442242294736621,-41.26427525926826,98.493755284948506,-69.8365435896919,-225.32232246610045,93.018256649520424,40.878209884120338,129.71116785497739,19.612943376765461,-31.813418997544087,137.5057886666404,39.262493490390092,89.385239515368625,51.80359670534218,-25.978576969671202,-229.81287266834244,69.947123356592812,122.63667914577563,-61.194006389742668,-220.51866935711095,63.156932798291137,-126.7157265764785,-195.71995838307797,-157.7930637914786,-20.688002110268137,-42.751924588111905,119.13941737707665,18.001570954093758,23.52215449818269,-49.086031111220464,79.817503252863759,116.62318550727632,108.72417633432896,121.08003629659129,103.83466167805749,48.262817388607509,-88.14318430100974,17.273329958262483,84.066109461501497,-92.4642328769106,23.460438247888199,-90.461795000609925,75.426012640878795,108.02409323165178,131.20299627205094,128.40249361058139,-34.192216826294,-63.827637079179631,49.04761683342204,-100.09483583941756,94.08186090371494,-68.160226630480167,61.917106314438307,-85.48785869268778,10.615195076020418,69.60396077384749,16.797501617560922,79.380409524394267,-216.75016807174046,68.988587293573332,57.640793435892498,-108.63226713014649,-10.293441780879483,38.793509592957342,148.07967814296222,-100.56191199136575,-195.42428234091162,68.023030259539851,-190.65238164869103,18.318293737262046,100.46137199221775,-79.436231023426686,42.451333400823508,-21.898040863215467,-97.881179036376281,8.2269975011506986,-142.66192594603001,-96.058042369939059,-63.950186787936794,-6.7181629792824946,-3.3875830423919653,-124.34024460391915,-52.333966510639478,-206.64769184958945,-172.34590181800124,-57.530227574959916,-137.25899292097861,-8.5854813691525589,-73.652307861944379,23.700409205100026,-59.51540048846833,19.893482716925494,-81.387420610303224,106.78102901799429,-18.348890237635228,112.98445703931752,54.714859767305946,-197.30110026684386,133.80687290462876,119.02109579125877,99.685104553482915,-54.226540703941474,-187.42893513498532,-49.938754826859693,97.273057867422537,18.000304570764087,-189.35359824597418,-188.53044790883646,-24.085728014153695,-127.31700040395681,-120.84367593924634,-29.811137529120263,79.984041497533411,-193.31096428779423,84.134988158368401,-184.39908504596204,-114.59094493552537,72.889410178082812,97.154793966902417,20.357851257702997,90.927334480334935,126.9797961471433,139.00549666008322,-0.021728699200496887,-18.220350811795821,68.370087867697436,-216.48158058000701,1.7341404800357987,-51.330833107502691,73.335924408754678,-127.80402453384494,82.105088801646176,-124.05063350144582,-96.69046916992275,111.78624487308961,-154.50623959629286,-109.70391773718001,56.678493709068988,112.49132554939952,110.53371442692406,27.009309500291689,-13.015676223267521,-73.440319541172201,13.131852859269275,4.1364307355191405,-10.850354737161954,82.268211959220963,68.684986705396071,30.114703848586071,-35.087368694953653,103.88870024731295,123.55192500633414,-35.214395776146006,122.20549736752402,-20.898315159345195,145.0133751218996,178.56635509710514,20.456304709158847,53.402252701900309,-7.1544104464142109,-76.668088977317765,76.788986995727868,122.35245075440845,-21.027259315160727,145.45170871984425,30.66880345206873,132.65426488369695,28.768060562643068,80.039846059454646,-21.391526041966923,130.76050786926621,77.889759845005486,147.07962673225811,-212.69241868588242,44.244374359607654,28.355780715053299,-229.28577801316752,27.745748545747659,-193.24758197629922,37.733287880344378,-73.932145298861485,138.48170822150391,57.715681482723852,-24.201304707607719,-86.420224088317923,-49.879249474565121,-98.866373386435555,-56.442903166302131,147.81833681555548,-84.982450420714798,53.673205592338192,-31.063315285912353,41.640392362463913,123.74204026803852,106.2388618193374,-20.538917875949689,-92.917891269355152,-11.014443599743762,-123.36034671014427,88.241597868306229,-109.49901956280291,-121.31325363789249,-87.086856635517009,12.634422790800883,78.637202021958288,13.617527175418482,-61.208810440976848,37.15515680072982,43.299416970816885,-45.806708458791498,-107.15038702689422,90.991123477133769,123.75485186937095,138.61834949410255,-97.152559843005704,-191.39665858134748,-204.35777323562692,116.63577562352607,74.468455114680083,-123.39789586206312,-94.780618525700007,-119.35518634890784,91.088944264250273,72.879457716436093,-40.551361850209389,-9.7859055188304751,35.643351852838883,-3.3835284402045178,-69.096955541504656,144.96694919042923,145.82422032192179,1.870026286733643,-86.964856065933603,-109.07270596291067,148.15296948463302,-52.25223725689829,86.000796810438558,136.40486355841389,112.56912150970825,69.91197159803329,74.079557678076014,-62.982806736697604,-69.155324958046293,-9.1555992617162207,-206.14903542806837,-147.16839358962923,-104.15727304088999,58.730124430759659,-90.525210735171697,12.829035347893225,118.13980089080907,44.281531872009239,117.17922495812228,95.745029944153984,155.93654101077357,51.69378480644108,-69.647573554532258,95.355640760815263,161.10694550609338,128.73879894134637,82.385160189225701,-211.54813968913624,-184.73933048178253,96.676082331827203,-12.998329669028591,-141.12095193591713,-109.71534596868769,-177.41379193815078,-81.268720396139727,-29.131951937663349,60.993417492399267,105.26408200443234,-57.326555197616734,-91.163814210963437,139.75395479592038,-74.571549764457529,105.55255690824603,168.3288312624581,88.56484176597354,-83.092773681943299,-110.09736628272657,-48.222732223901261,-41.823718402386525,134.64491387301737,-69.483537761738063,100.71146761023653,115.97466036848236,55.801515217802354,94.079070718748696,-116.65960727200637,38.778361451529236,134.96638883274923,91.899862708033652,-28.090975539184623,23.519453943922429,-168.17563370046949,87.955705230124906,69.212796472820017,-192.87133461271213,-42.894738802439967,-81.125306073877326,30.896340935915966,-25.637262301212143,-117.74356289134397,109.15418285949553,-67.514115866105769,-78.490794981201148,-68.78802458111123,23.500188023208626,-52.955916326576144,8.8805707937396079,-48.200597090788534,77.166549810739326,113.31336825541304,99.752080781438949,46.919750744418991,109.02951926551346,-194.42518534594967,-46.832309299554218,-190.76706548595863,-195.37139908822871,-20.927800455773173,17.630551624396098,-55.121422133924867,119.2566488487177,44.089514212221935,112.31724620358193,-44.014397936914364,109.75291067758991,-29.835616218371005,-168.78417931072826,141.99473169830344,-163.11014134623053,124.64762721377139,-103.19474476551865,121.44442859273103,57.110359686476521,43.280812687170688,-87.867201168163916,44.261451858470572,122.05588239288113,43.161286826874338,59.682438943570716,-94.650742786451943,-52.205207287960476,112.58334559633769,72.256211798650185,-66.178932349919023,67.380177486440701,-52.061860319175437,13.189865468616762,-94.86758247619575,-40.207429817094351,-192.53347539330721,42.048468535083039,41.363053775032242,101.31537808973528,-37.516947643207573,123.94602071271341,-63.823113719682915,33.201836291762305,-119.19373674559124,-60.964264342306215,20.57173679670964,-130.90266505822279,-110.22174464165091,16.17089238891306,91.965950563298918,119.91348213302558,-52.321201802400864,0.98487745967056406,45.600332524820949,121.31242416453151,42.390074826561914,-126.90735348901919,116.51023823886645,-220.69145777922481,81.045295508790744,154.07889008639521,-22.545325118430899,-25.893594456881249,-2.4367045906457419,-73.046947478446583,-125.20989884592282,-58.713502823438922,128.73807903578989,90.258721964146559,-191.73377551348787,91.855157407416542,108.46756082610825,72.672335433844964,41.645107037012536,162.02329042475671,161.07092536937969,107.01771108195652,9.1276576842481578,-13.40456464745025,-118.00327089964458,-56.455615986747176,-72.516011313594944,58.050034876455584,134.12712675505105,-31.820018530049158,58.892008518984987,69.467033627573755,48.780711947954231,40.917275721695674,-28.370049617554045,-22.541095197443166,26.194627763772502,71.562894149462025,-64.667269673947715,-72.59684227574067,-19.120398155811024,61.771670425691987,-11.328461764759977,-91.592343220486725,-13.038438553750783,-17.427472194044118,85.551588369233713,-206.13886958935339,-23.65566203753697,-195.54417394525714,-192.28811847415494,-46.544543514423431,-3.5736239940316166,-127.47682675841,-45.495251882889569,-177.62653002185675,128.87170969764219,-97.780400872920026,70.638692103566115,81.304689265450961,-27.629202522866741,-11.189309920067259,-7.6353547081682347,-6.0621121659705759,6.3510872382896899,106.05783201933447,98.735286546821214,1.621904541633431,70.508596200241769,-168.33733513433808,-119.30014167881299,-119.60780190192591,46.730617846754619,1.8018970801734773,22.828727405108534,104.44777971280553,19.748620690339955,13.809871816042515,-67.49495924186462,-79.533329560274296,70.556102709674107,47.464125224313989,75.089984806679709,107.81410777974733,77.695540433541069,-170.48002290950842,-23.393617685267799,-50.08576710713227,-91.077434666031621,33.427899426237197,70.731364794469272,-97.360553619362832,-116.51224129924863,113.43512816692279,-87.461647177088764,-197.09928967338337,97.554739328122395,120.91868327807838,-43.394220524827858,47.192488009531473,16.059409765724375,-94.776534450505793,123.0648063002478,122.56066587654681,123.99558081675019,13.614602285973383,-196.37293893401346,27.475193320688366,-30.980782921186602,41.40889549841021,55.847477299182415,126.95688864863288,27.261902611575003,-54.53274410190248,51.488686861189706,25.865972922144227,76.43816152392931,84.187060394417458,28.506144085150332,-31.531644209285467,-79.469728054589723,-57.581473184688996,-2.7823773694339913,-120.32867027420539,-126.49932722204791,56.43010043629917,121.6936194837163,-124.18143155949761,96.675521340698793,-45.433594333699467,-84.529629794531928,95.200029350788924,143.19473238779881,96.367341553707973,-84.132266402504001,50.496288717668627,94.953709924177545,82.709718257579851,10.412114323060452,20.576571637375785,135.51832050892145,109.47127440377398,21.883313937113456,-99.741492312170834,-71.182200581269981,-228.79026896361376,-184.05990289232039,35.464549743826751],"z":[53.356387286191115,29.00496377058078,-3.4446439091161052,32.81433279139803,17.525539467226594,75.238042698711183,97.114575388314918,-3.2316620398533171,-12.98744067424429,57.496122138465232,22.255045933580547,19.64626074222846,68.184482233189925,34.685979846524283,96.738790664943707,-125.39977192680243,-13.334512274043179,-19.34842623632618,-55.757264975112172,24.897969462221358,93.832211468736347,-11.270454200180167,57.168889457134071,-30.589712833419835,-48.193956581426676,29.822496334849788,52.247834069098346,49.253918585532219,-30.170527860278316,-17.335677796361537,-17.358630454592983,109.27953274623469,26.499889846039153,-128.34669409561252,88.781001098554825,-49.125111663502452,58.740178728527489,-80.872541353398049,16.21939377033112,39.923018756665272,44.02974563472673,-27.47578618831545,45.062066333801333,37.437177666989143,62.259371191266602,19.966636787950961,-5.9738721973863376,-16.883583504155972,-9.7052731014720877,-62.463153768185862,-29.900578334925434,-32.243170248990651,32.640148628525239,55.304832973019387,-3.7626294262340374,49.457437183875641,8.5378612959902416,-58.291009605003026,-30.993725287841457,62.139094072197366,-3.109974117111165,-12.301897866293283,63.409683452843637,36.212681857986951,-0.099703320437732487,-8.1976837041830013,-37.527609751135643,-37.571112479810225,-45.206796414265327,12.963774656662315,49.26673062528468,102.51226392046013,8.8004869583206773,18.913619449916627,-6.7808535786033834,-28.481897944456914,-20.910794504714318,-3.3342143964559501,29.669457197193008,34.882065285785515,-3.637099028277333,-12.769616942744948,60.60501220589682,3.0984459383639811,-16.381297065379915,-12.067686589934462,-22.969730332136578,-22.81489833602086,-54.268550215224359,-79.872349054619946,-20.989074931155152,21.580425521890124,-5.0069554446202869,-3.8497760126583005,9.1669318783550153,-9.4343158641608635,-25.035956228549463,-12.761622994597539,-14.4293073349099,-13.564133015926197,25.471360537661134,53.881633410705014,-34.255002122987506,-10.268903512116101,-26.772356179439775,-3.072288370439114,-29.347430464477675,-53.321316461893851,-1.3341922781553812,-77.226431221087779,-34.506219767027353,-63.089409167177458,-54.224641842543292,-14.718180392649387,-45.881996530197924,-32.100416534810449,-28.364783499012979,-24.155607737166982,-14.577784606283833,-23.527331567943971,17.52770799457118,53.437039136216065,-51.537040211470675,-42.126289985312482,-34.675044669315135,58.654275533472088,84.996204108195698,58.198334959105871,30.11796288393807,85.517389881384133,13.653405968366142,-9.5759720257445977,44.658817228201954,-31.982352493555879,-10.635130837427488,-32.721753505970234,-24.261417710501139,-17.720136134425577,107.88322529321722,56.733689966125951,55.671547657002627,13.472147020690437,58.499951351578716,76.468282822890458,-33.73233920074339,94.750283370365622,-3.3837530396165314,37.505670392931734,-4.7579677883816007,35.918365672491397,5.0633705066274537,27.605442924746455,33.704721113512939,97.403404790489375,-33.441218129010579,-14.553565347733233,58.46844286529852,-31.373848036268623,62.499148417569529,13.774453027322279,-24.944337355377527,67.148993337093771,-33.825255877074781,69.551105634748623,47.977717041870143,-31.286950540695386,1.239701195786912,-17.714230472595155,-24.474322959365136,-23.138982046658626,57.827733716201791,-36.610365000858636,18.833341052210017,28.485681046899714,52.03711094702691,23.230996564510548,13.543361297188731,4.9804144101059871,-117.49707819099666,-40.11991937666221,17.976889401564836,5.3814227926671094,-1.6161225544736457,87.317545548593429,-11.721925801856516,43.997750214929646,-30.380266871485258,-37.865624772030714,17.678362501053165,-24.730956207232065,23.611893977850865,23.867355148092141,92.225813523566387,52.454273258617619,7.8944217766644158,-8.622361981979493,-16.478370177565502,22.122169878911368,55.362347194569622,43.551982418917554,-21.156002995239486,38.108779942176064,-15.400251810822642,-4.1879668292924492,-10.557813275790931,32.497076077444198,59.566148611185021,44.412632251387279,-29.534767466228107,-63.073613479734078,64.075477553110716,57.432005223590728,49.406585297456061,-37.156426006773827,-65.385806320959233,-23.723534925141323,-17.262185759926474,-36.432826951130053,-13.433899442468029,5.7387174779881684,33.972615738222601,-24.678622379353037,2.7753306185499849,45.840965363390403,-108.56081443080197,-4.3922923218936054,86.726238586173565,-59.408175857068649,-19.537816368213232,28.952819771674086,-9.4316725407205197,-41.428849954805877,-100.06988754329811,-39.773804192269424,-40.061682223211449,-54.65292492409511,-51.666762859317551,26.731193205782926,91.326437974911315,4.6938981121620431,14.265698151354483,-36.140964585866868,-6.1819756468828819,17.728252362553629,51.781857460868039,61.262394309055956,22.492550010444912,6.998723001434195,21.948964817175714,28.151479814053079,56.241279129825962,6.6666092676266109,-33.538563963768944,-42.722275253170999,-26.24975603562585,-11.498718295529319,-26.900637524737423,-51.14862996915118,12.09127794472808,-50.855155545834037,-39.321105810129453,11.360014158545072,10.211170976216737,58.61320171572396,30.345720426405268,-6.9033324697134697,62.1137148432041,-9.8581535979699044,104.45649680441151,54.401040681067187,68.589369735986566,10.905491214340731,-11.191345145158202,-23.619332821073161,-23.077440257932682,4.1349182755886833,23.659596967922262,-23.247273907522459,71.806814247096568,17.250315001301182,52.243396817621964,18.123401612877299,2.2973296098397555,-34.532622225279098,-51.715763416753731,17.33326977947787,-12.998069301266959,-24.536948785238124,-10.110964416937488,44.633738410970992,-3.2586161717231561,6.7704178738423328,50.597704545932103,23.0067868401139,-17.800738876294808,-10.243385841702613,0.56234011796839301,-6.6970113084000431,48.66953889302949,78.620527525371543,-105.96266146512875,31.55026519361644,10.044838377376653,-69.905665566983899,-12.278048628527911,-50.002968911242341,7.4966855263143239,-29.879633288531316,26.728994981608999,35.813617512673744,-49.736972603025642,16.069896771208359,26.989720712522978,-24.108027935312055,-25.321531172357002,-32.992953859962114,-35.911119065892201,-44.179993411506103,-23.740518826714567,-10.347034450194068,-20.39413236107325,26.199205709516797,-0.1137983921576658,5.7035161663896909,59.809748812470716,-19.363078648110964,-13.808571932332926,-11.017199571704252,-29.904935355719623,58.510564491151705,-86.490918597828781,-18.477035955541268,-32.436100251629,-16.081947252939262,-31.749084256679197,65.748111007439945,-25.662206704561555,25.065764175380703,52.784191238025969,-30.555625235850641,7.1249411755757617,-12.879413503181437,-40.442767601138307,90.202676087103868,-17.642556542856596,10.506136746284071,-31.477847277688259,22.211970604282975,18.560664356681723,62.016458467704901,-19.026681983516436,12.988605346024981,0.7516904723871134,52.583794017210934,-101.56695020815734,50.719720471574405,-31.599474168742113,-31.01468766046969,-41.725817052271132,-44.757161295567222,-35.932581480879534,-37.109701374373934,73.023315656329132,-7.0491334333273015,-38.690097606697222,-3.2035675395213192,-20.613107299946101,-2.4175188062799768,-29.004382049664809,-27.300698072093741,-12.381394210866436,-15.139100748750105,-11.39091360768081,-36.286645190679181,-65.631235840750406,-10.922504543785255,-52.631180385068085,46.085282544267457,-29.788955176629202,-35.413454487790531,-40.922868910483899,-54.485531245814641,20.189686003733605,106.91391618865845,-11.128248107905614,15.263643759184292,-24.735253696695946,-9.3017898665905339,92.535138991245589,20.648981868584258,33.246218751451408,18.673777685325319,51.076018604952665,24.039605998852888,25.034090611688391,15.216957724601844,-23.003353074087194,-30.31487642721326,-14.482875588163239,-67.324914396765251,49.316131911529332,-24.282208271711099,-26.763484325245141,11.680435958697679,34.448719448048543,44.306649250330594,-15.616799890155242,-21.954585184732103,-7.2018156322413365,26.012577126483219,-16.992579269766697,19.126018562629309,-9.8493995690926877,13.881175391211032,61.40802031894922,48.200527811848453,40.5241657768971,-11.792896706360589,32.043637256079258,18.984828969518837,-8.1815378381252835,70.074258711671121,-11.783577632251058,32.382202225316966,95.791303615422621,-30.229974737995583,-118.75774372441646,32.195348882569803,18.852592641599884,-18.12895325699149,-26.228869164183244,-20.70403371100457,-25.926460680985045,46.691745524980441,-81.625180460753626,-2.4646920772870664,56.815538331685929,-37.211245557003124,-23.791430042321181,-5.2187596517737118,-6.4586753645485944,88.904022111553459,51.264254627421586,-1.9364273067826048,-1.7247541465619973,25.96476770944107,1.008760544091039,-46.2085754610235,68.796234897153951,-28.293432303024307,-51.0861964363772,20.028544829907922,-51.909621951788317,-58.264485484457325,49.967588876795631,62.072319330691968,-28.122504051662148,14.553120880948804,-127.52322364206873,-10.218843576645231,27.152585361291312,124.78325685094671,-45.283193060218608,5.7665578871341809,108.58163319261863,48.363827029310904,66.166142037245336,-18.381124297003499,-15.585492149917357,-83.820321045261409,12.05415051107242,-35.027230496816763,28.605633076072486,-21.94125159076253,51.824260747721354,46.6208748051708,-15.141429450997984,-2.6506596188001907,100.25800014617829,-36.70555317849702,-21.812724592720965,-30.432844325832832,-22.761673031396406,85.361299973948817,-1.0259733914301121,22.838672088955338,43.601814277546417,-6.8714905885449244,34.008688636552087,-10.231132448262169,55.414587957506726,-12.861940976505723,105.76946920177083,34.705942457404454,-69.823736144488507,23.400837238139697,40.19218913629971,26.172037648193424,-2.4624333851160469,-37.75895008351921,-18.209822323801891,38.752996830017047,23.489614512901611,49.277977911611863,-4.8075506539164667,-58.003794376611118,46.987517845348442,38.347773584872087,-27.314861795990389,-53.100928937740832,77.203488227669482,-40.757695953049222,26.789854658953168,-18.327080093890164,-27.771830717173263,-23.802548019620509,-37.103759820524139,-34.800288625337799,41.671556818868162,-24.950764146447174,-36.428964100157224,-23.832604415185497,-31.599220052062364,-70.97052324715817,-3.34361968641536,44.689821786287709,30.454739304124455,-53.53485207160363,-9.147492136980933,-10.010053918518592,46.92047638878261,-13.047191748870407,-27.513910338034229,60.995007783739659,12.539637702980725,-24.697954109658411,82.282725760757017,4.2065944062018978,-34.472029894324777,-32.624791983763686,-24.72858786286541,-15.31504263707129,14.246893857856479,-25.892166048491585,41.825298779254403,-5.3525881454757416,2.3155816461036629,71.719482327451857,28.314032384272672,-5.7178667331385551,-129.04783532539741,-39.719429550364019,-2.1161169898653918,4.8372403213157265,10.191729694895521,12.888798564011653,29.704605915260149,-52.834595109724546,-32.249255318020829,9.6130344395948963,27.389986067152243,-24.827400157101369,-12.272106921278763,-15.433022107655018,-3.3014039450123516,-3.3445397703039301,12.867152353386837,-7.2460423776509426,90.969963530388725,45.481090393703226,-8.799327357856555,-14.75816939486069,30.816058781020033,-25.078147135081707,-77.62728385001229,23.33556236933725,-3.7110684146743771,86.732341395980654,-3.8629809910968,19.461922210055235,94.687397694667652,71.283333302353739,14.776391507064677,91.266804079137714,-26.510154041317758,60.135119987648551,31.591486878095502,76.396880103257843,-6.4526504818915225,8.5209392415471541,41.125040292383211,-13.543177828331665,28.710262544191998,-11.238558619542912,-35.471674807829324,-13.023488148502027,19.485699622091733,21.401008522844801,40.909403178801249,-28.109633839623811,45.532081863087662,-19.529600982207853,109.63518802391579,-124.06199807858934,55.006122942380891,90.897341145784779,60.096734814120772,18.465022755020147,82.594041204227466,29.735303829049883,-38.023280966241749,38.460195792568605,14.312184630533475,-32.913370079585,49.293764531546508,-30.466434581064529,-13.141353353245341,13.410335507541388,-11.05498810504494,-14.011255977647721,-31.841774320986644,5.4126274788597932,4.3443287422249659,25.639938454284056,-96.403136591062051,-43.684384546416993,-100.19506152101572,-41.830789292900391,-101.56600779375937,-115.93715396284991,64.109342148944222,52.345445535743437,-79.838407024868616,-7.4319256928727118,11.179667884608694,-125.46461413219512,61.534726935315035,-41.386206148944325,61.258896064335005,-7.0363014757895535,-5.1516395593259663,-124.01546199633925,-122.19299399437656,-126.16221282094764,2.352638716487748,-42.161199425021124,36.992205950922504,-47.527676726109092,10.159276483722238,29.690969216259525,3.6868922015005285,15.23464619635568,-31.402796399179358,73.679196125121962,42.394797932223085,-10.66003730130678,-12.092307052876686,37.840116781111746,-118.50328253962778,-25.263694523199796,-1.0962152152023388,12.452867151861568,-38.097740337686886,1.5739024557543257,56.904132497058747,2.3542755845901464,-53.57209917728165,-22.356369596875069,98.591415963513441,8.84207208681193,-12.800556548769602,16.701698385612122,-7.8567689796426814,-123.75180995811667,20.124695816353917,-123.01157373622634,-25.468753654229612,-125.46072319996748,-23.690081527526932,-5.8759861954819907,-7.1502296968148995,31.000075392507945,-33.934614888653613,-14.776035752520432,-24.713551059479304,56.1302883294249,-21.125230612787789,9.5124476827009303,16.696619938871915,97.247739399239236,-12.032978031198921,25.703464086275375,-1.4083113803794591,0.019989268934100544,-29.328656595960354,99.262619585818314,-10.461353886881193,-27.463868771341435,-31.569523023182438,-26.496759660802958,-47.709322167769407,-17.610309105737581,15.227778139352111,84.565446743683509,-21.424175436631828,-28.098998917770963,-31.202238981348593,-17.111954052867311,-3.0618181226511179,29.197702256208206,28.753583974614273,92.889868156406735,1.9929084441682952,15.728445651911784,-17.194198075729062,18.753467545772718,-38.530173777746995,59.63894639785515,-27.284655301048709,-6.0095640091024194,26.108395188266297,-2.7086263734670188,7.0109684376993773,7.8864982420243503,-42.803312002297901,-40.009015447577205,-44.72022185647171,-3.7146322481907368,-124.41775632213731,-6.8551626706158553,6.5652647611887636,-41.171010915108333,-19.205988453508539,-6.5205215356866502,-17.702347433610342,-42.705121681103272,-20.013508597591528,-0.60210901449799192,-3.8719575050384658,70.682855575250102,16.603127673583469,115.66882390345449,89.883365179324926,-41.757318454521361,-82.613787568540431,13.925832013995485,67.805157164296048,66.08183091430449,52.12693864855575,74.799713297808026,77.956656064058336,-23.299594257261408,35.666147240341111,-6.9236186279975271,-13.851736766694442,43.991170845983724,48.585579344021895,36.048608284435133,-14.287899983788922,65.508733813881562,95.717034116944788,41.392641385732723,-26.305251623790447,-14.751820942045246,1.8551559302576608,-12.492887187786105,30.810345153426216,108.33517772544599,-20.795227622639288,120.88718748497064,-23.863505691411596,-34.976611403650104,33.043225803258608,53.428880678924088,48.857267676963367,-30.582387118876063,41.969518163869701,48.877889995775867,-28.121989031147599,49.555718109518622,-1.6501537800290085,-12.621512382368888,-1.1952129580595745,31.595751949057167,44.661932800160372,107.47003252743069,41.43055552859466,49.777035685409977,49.0990383080171,35.743173167355906,-7.9634455487302969,11.863596028637698,15.62684445944164,-19.693932836803324,79.886630498612575,11.904407326334642,-15.645575890397652,95.289376599780368,89.010919828901592,67.466512655396002,25.102936546928706,-38.488388126600626,-24.232290926941744,-38.532274490265735,-23.047830114410434,7.1486239092559209,30.103212204143009,-33.317083313804304],"text":["Input: 'acetone retortman' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'agent jute hemp brewery' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'and silk works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'any kind of plain needle work' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'appe sawmiller' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'apprent at millinary' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'apprentice hand loom weaver' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'asistants' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'assistant cotton loomer half' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'assistant in cotton betting mi' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'assistant in dyehouse worsted' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'assistant worsted overlooker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'assistmaker drawing hand' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'backer en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'backergesel en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bagersvend' (lang: da)<br />HISCO: 77610, Description: Baker, General","Input: 'baker' (lang: en)<br />HISCO: 77610, Description: Baker, General","Input: 'baker (dec.)' (lang: en)<br />HISCO: 77610, Description: Baker, General","Input: 'bakker' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bakker en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bakkersgezel en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bander ring room cotton' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'bank tender cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'banketbakker' (lang: nl)<br />HISCO: 77630, Description: Pastry Maker","Input: 'banksman' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'barn poul mikkelsen vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'beadworker trim' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'beef butcher apprentice' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'berlin wool fancy repository' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'bessemer steel rail worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'bit winder carpet works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'blanket fuller out of employ' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'blast engine cleaner' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'blauverwer' (lang: nl)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'bleached cotton cloth beatler' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'bleacher' (lang: en)<br />HISCO: 75615, Description: Textile Bleacher","Input: 'bleacher at cotton works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'bleachers brusher' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'boblin winder cotton spinning' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'boiler scaler labourer' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'boner at stay factory' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'bookkeeper to fancy goods deal' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'borduurwerker en not mentioned in source' (lang: nl)<br />HISCO: 79565, Description: Embroiderer, Hand or Machine","Input: 'borduyrwercker en not mentioned in source' (lang: nl)<br />HISCO: 79565, Description: Embroiderer, Hand or Machine","Input: 'bow manufacturer' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'braid maker trim' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'branston frame worker hosiery' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'brass dealer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'brass founders core maker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'brassfounder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'brendevinsbrender' (lang: da)<br />HISCO: 74490, Description: Other Still and Reactor Operators","Input: 'brewer' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'brewers servant' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'brouwersgesel en not mentioned in source' (lang: nl)<br />HISCO: 77810, Description: Brewer, General","Input: 'brygger karle tienneste folk' (lang: da)<br />HISCO: 77810, Description: Brewer, General","Input: 'buffer steel work' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'burler in woollen cloth mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'butcher' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'butcher' (lang: unk)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher (deceased)' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher and etc' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher decd' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher deceased' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher employn 2 men' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butchers salesmens assistant' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butchers scaleman' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butler' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'butlery' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'cab weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cabinet manufr upholsterer' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'caffawercker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'caffawerckergesel' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'caffawerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'calenderer tape work' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'can tenter in card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'candle dipper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'capainder of cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'card hand hos' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'card master' (lang: en)<br />HISCO: 75135, Description: Fibre Carder","Input: 'card room hand speed tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'card room op' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'carder' (lang: en)<br />HISCO: 75135, Description: Fibre Carder","Input: 'cardroom hand cotton mill slub' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'carman at bedstead factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carpet designer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carpet weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'carpet weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'carpet weaver hand loom' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carringe trimmer' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'casquetier' (lang: fr)<br />HISCO: 79390, Description: Other Milliners and Hat Makers","Input: 'caster' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'catcher in tin wks tpw' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'cleaner bleach works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'clipper scalpper lace' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cloth cap cutter woollen' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth corrier' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth doffer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth knotder and picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth mill over looker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth pleater bleachworks' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth printers worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth weaver woollen mil' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'coal bag fitter' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'coal leader' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coal miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coal miner cutting machinist w' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'coal pit sinker shaft' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'coal trimmer' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coalminer' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'cocoa mat maker unemployd fib' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'coil winder electric motors' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'coker in steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'collar damper' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'collar dryer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'collar maker' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'collier' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'colliery coal salesman' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'colored cotton woollen winde' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'conditioner in worsted mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'confictioner packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'cop winder cotton driller' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'corset assistant' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'corsett fact' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'cotron piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton bleacher' (lang: en)<br />HISCO: 75615, Description: Textile Bleacher","Input: 'cotton blowing room over worke' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton card mone labourer' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton cartrim sweeper cart r' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton cloth agents clerk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cotton fram tenter cardroom' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton grinder in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton hank maker ap' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cotton hanker grosser' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton heald picker' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton jinny room piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton loop pointer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton miles' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton mill minder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton mill operative reeler' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton mill roving frame cardr' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton mill stripper and grind' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton operatie doffer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton operative psinner minde' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton part time' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton peaces' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton piece folder twister' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton resler' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton ring thewstle spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton rov' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton scholar weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton self acter winder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinner operantice' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinner unempld' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinning stripper and g' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton spred tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton steamer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton thread factory worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cotton tigger' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton trade doubler' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton twister also barber' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton waever' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton warp packer manuf' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton warper mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton warper pensioner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton waste sorter machine me' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton weaver and student' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton weaver painter c jou' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton winder spinner mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'council hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'crane man steel smelting works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'currier' (lang: en)<br />HISCO: 76150, Description: Leather Currier","Input: 'cutter in clothing mang' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'daughter of constable' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'deam warper cotton mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'deres datter skraedderpige' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'deres son vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'distelateur en not mentioned in source' (lang: nl)<br />HISCO: 74400, Description: Still or Reactor Operator, Specialisation Unknown","Input: 'dito mollesvend' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'doffer cotton m' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'doffer in ring' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'doffer silk' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'domestique de meunier' (lang: fr)<br />HISCO: 77120, Description: Grain Miller","Input: 'doubling overlooker in cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'draw frame silk manufactory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'drawer jute milne' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'dres worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'dresser at factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'dresser bag stitcher' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'driller' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'droochscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'drooghscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'droogscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'droogscheerdersgezel en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'dyehouse labour' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyer' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'dyer finister' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyer [deceased]' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'dyer skeiner silk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyers laboorer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'embosser cloth finish' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'employe at small arms factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'employed in biscuit factory' (lang: en)<br />HISCO: 77690, Description: Other Bakers, Pastry Cooks and Confectionery Makers","Input: 'employed in tin wks' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'employer hosiery' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'ender velvet trade' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'ernaerer sig af haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'ernaerer sig ved strompebinden indsidder' (lang: da)<br />HISCO: 75535, Description: Hosiery Knitter (Hand)","Input: 'escardasedor' (lang: ca)<br />HISCO: 75135, Description: Fibre Carder","Input: 'ex miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'factory operative cotton weav' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'factory operative w c m' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'factory worker hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'fancy worker in ivory' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'fancy bead work' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'fancy work drapery' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'farmer and dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'feeller in felt factory' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'feldbrender svend tienestefolk' (lang: da)<br />HISCO: 76200, Description: Pelt Dresser, Specialisation Unknown","Input: 'fell monger wool works' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'felpwercker en not mentioned in source' (lang: nl)<br />HISCO: 79490, Description: Other Patternmakers and Cutters","Input: 'felt maker' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'fettler arty' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'fileuse' (lang: unk)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'finished skirts' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'finisher and seal silk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'finisher of bleachd0 cotton go' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'finsommerska' (lang: se)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'fire range iron molder' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'fireman iron blast furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'fireman steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'flannelette weaver' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flax comber' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'flax dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flax reeling tenter' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flessader' (lang: ca)<br />HISCO: 79690, Description: Other Upholsterers and Related Workers","Input: 'flex preparer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'fly worker cotton factory' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'foreman cotton warp dresser' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'foreman cotton factory' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'foreman packer f lab' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'forge apprent iron' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'former occupation spinner cott' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'formerley furnace man' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'formerlly cotton spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'formerly cotton mill worker' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'formerly horse clipper maker' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'formerly jute twister' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'formerly lace maker' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'formerly straw mat maker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'formerly tin plate roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'formerly tow spinner' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'frame winder w' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'frame work' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'frame work kinneter' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'framework knitter' (lang: en)<br />HISCO: 75540, Description: Knitter (HandOperated Machine)","Input: 'fretwork carring cabt' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'fuller and dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'fulpwerker en not mentioned in source' (lang: nl)<br />HISCO: 79490, Description: Other Patternmakers and Cutters","Input: 'furnace fitter iron' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace limer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace mam on rolling mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'furnace man silver works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace stoker sugar boiler' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'furnaceman drawes out' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'furnaceman silver ore smelter' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'galvanized cold rollers helper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'galvanized sheet dipper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'gelbgjutaregesaell' (lang: se)<br />HISCO: 72520, Description: Bench Moulder (Metal)","Input: 'general iron planer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'gentlemans tie manufacturer h' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'gentlemens hosiery asst' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'gingham weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'gjuteriarbetare' (lang: se)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'glover' (lang: en)<br />HISCO: 79475, Description: Glove Cutter, Leather or Other Material","Input: 'goods bleach dyer works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'greinwerker' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'gum works' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'half time millworker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'half turner cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hand hosiery worker' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'handskemagersvend logerende' (lang: da)<br />HISCO: 79475, Description: Glove Cutter, Leather or Other Material","Input: 'hattemager' (lang: da)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hatter' (lang: en)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hattmakaregesaell' (lang: se)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hawkes tinware' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'heald rutter' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'heand loom weane silk' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hearthrug maker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'hendes son vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hoedenmaker en not mentioned in source' (lang: nl)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'holzaufsetzer' (lang: de)<br />HISCO: 73100, Description: Wood Treater, Specialisation Unknown","Input: 'horsekeeper cotton cloth bleac' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'hose' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hoseiry hand griswold' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'hosiery boot assistant' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery factory' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery machnist' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery manufacturers foreman' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'huseier sypige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'husfader skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'husmoder syerske' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'in tobaco fact' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'indarubber hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'inderste og naerer sig af fabriq spind mand' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'india dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'indsidder skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'indsidderske ernaerer sig ved haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'indsider og vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'intermdiate tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'intermediate tenter cotton' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'iorn spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'iron dresser' (lang: en)<br />HISCO: 72930, Description: Casting Finisher","Input: 'iron firer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron flyer makery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron founder' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'iron moulder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'iron planer m v' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron plate worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron rivetter in shipyard' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron tin plats worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron turner fuel economiser wo' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'iron worker labourer blast fur' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron worker lifting up' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker wheel cutler' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker, deceased' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron wroker shingler' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'iron-dresser' (lang: en)<br />HISCO: 72930, Description: Casting Finisher","Input: 'ironworker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'ironworks boxfitter' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'jack frame tenter in card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'jacket button hole machinist' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'jobbing about cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'joiner oil work' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'journeyman tin plate worker' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'jute factory bagmaker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute mill worker preparing' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute spinner emp 350 f work pe' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute spinners' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute wareho labourer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kaffawerker' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kaffawerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kibond weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'klaedesvaevare' (lang: se)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'kleermaker' (lang: nl)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'kleermaker en not mentioned in source' (lang: nl)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'knitter spinner' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'konfekturearbejder' (lang: da)<br />HISCO: 77630, Description: Pastry Maker","Input: 'korkskaerare' (lang: se)<br />HISCO: 73290, Description: Other Sawyer, Plywood Makers and Related WoodProcessing Workers","Input: 'kousenverver en not mentioned in source' (lang: nl)<br />HISCO: 75690, Description: Other Bleachers, Dyers and Textile Product Finishers","Input: 'kvarnaegare' (lang: se)<br />HISCO: 77120, Description: Grain Miller","Input: 'laackenbereyder en not mentioned in source' (lang: nl)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'lab in iron w' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lab iron compy' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'laborer at steel boat works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'laborer in mill' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'laborer tin plate works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'labourer at fishcuring' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at motors garage' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at sanitary pipe pott' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at wordyard' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer brass foundress' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer brass works' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer factory jute' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer fibre works cocoa' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer for butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'labourer in blacking mill' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'labourer in cotton mill unempl' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'labourer in steel rolling mi' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'labourer in tinworks' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'labourer iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer marine eng factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labouring miler' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'lace curtain maker grist hand' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'lace hand' (lang: en)<br />HISCO: 75450, Description: Lace Weaver (Machine)","Input: 'lace jennier unemployed' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'lacher' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'late fire iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'late mill overseer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'late woollen manufacturer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'laundress at coller factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'lead furnace man' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lead miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'lead packer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'leertouwer en not mentioned in source' (lang: nl)<br />HISCO: 76150, Description: Leather Currier","Input: 'legatuerwercker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'letterpress printing machinery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lever af at spinde' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'lever af haandarbejde' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'lijndraaier en not mentioned in source' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lijndraijer en not mentioned in source' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lijndrayergesel' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lime hoist blast furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'linen machine ironer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'linen on cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'linnenwever' (lang: nl)<br />HISCO: 75432, Description: Cotton Weaver (Hand or Machine)","Input: 'linnewercker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'londery made sorter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'mab ffambwr gweirthin ai ffamr' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'machine wool combing overlooke' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'machinist and maker' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'machinist saw mill' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'machinist sewing mill' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'maker up' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'maker up of linen' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'maltster' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'maltster grocer employing 1' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'managing director of iron wi' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'manchonnier' (lang: unk)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'mangler dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'mantle manufactering' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'manufacturer importer of fan' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'manufucturer of linen collars' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'master cotton spinner manf' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'master dyer dress goods' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'master iron monger employs 1 b' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mathematical instrument worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mattrss maker' (lang: en)<br />HISCO: 79640, Description: Mattress Maker","Input: 'mechanic cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'mechanist linen collar works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'medical wool packing' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'meedlewoman' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'meierske' (lang: da)<br />HISCO: 77510, Description: Dairy Product Processor, General","Input: 'merino wool hosiery ironer' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'metal chaser and embosser bras' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mgr cotton weaving' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'mil hand worsted spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'milinerdress' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'mill back tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'mill hand cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'mill hand s f' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill hand wool mn' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill handwoollen mill piecener' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill loomer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill worslet mender' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mille piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'millhand cotton card room work' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'millinar' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner' (lang: unk)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner head of workroom' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner retired' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliners manager' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'millman steel works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'millworker cloth' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mils worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'minding spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'mine contractor' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner (dec)' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner (deceased)' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner deceased' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'modiste' (lang: unk)<br />HISCO: 79320, Description: Milliner, General","Input: 'modler iron' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'moeller' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'moldier' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'molenaar en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'molenaarsgezel en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollerkarl' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollersvend' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollersvend tienestefolk' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'moolenaar en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'mosaic pavement mural worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mould dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'moulder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder' (lang: unk)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder (deceased)' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder appentice' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'mounter umbrella and walking s' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'mule piecer spinning cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'mule spinner cotton out of emp' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'musline darner' (lang: en)<br />HISCO: 79690, Description: Other Upholsterers and Related Workers","Input: 'nitroglycerine exploder' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'oat worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'office boy cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'oil color mcht' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil mill labr' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil screens' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil seed cake maker' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil seed crushers' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'operator in cotton mill' (lang: unk)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'oud leerlooier' (lang: nl)<br />HISCO: 76145, Description: Tanner","Input: 'out dor worker 1 agricult' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'outfitters cutter by bandknif' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'overlooker assist silk' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'overlooker in trousers factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'overlooker wool washing' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'packer confer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer crystalate maf co' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer in fender and lee' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer in mill c' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer instruments' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer late greenwich marine 1' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer of bags flour' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer wharehouse' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'paper maker' (lang: en)<br />HISCO: 73400, Description: Paper Maker, Specialisation Unknown","Input: 'parchment maker' (lang: en)<br />HISCO: 73400, Description: Paper Maker, Specialisation Unknown","Input: 'part school calico weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'passementwerker en not mentioned in source' (lang: nl)<br />HISCO: 75452, Description: NA","Input: 'passementwerkersgezel en not mentioned in source' (lang: nl)<br />HISCO: 75452, Description: NA","Input: 'patent cotton winder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'patern dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'pattern warp dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'pauper formerly silk weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'pauper hemp dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'peller' (lang: ca)<br />HISCO: 79220, Description: Fur Tailor","Input: 'perfumer manager' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'piece cloth mending' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'piece lookers cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'piecer cotton spinning co' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'pinafore factory worker' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'pit bailiff coal' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'pit sticker' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'pitman' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'plaiter down cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'plate maker cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'plate roller iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'plater' (lang: en)<br />HISCO: 72890, Description: Other Metal Platers and Coaters","Input: 'plush weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'poncho weaver w' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'pork butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'pork butcher killing' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'porter in tin works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'potting worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'power loom factory worker fill' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'power loom reeler of cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'power loom timer worsted mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'power loom weaver dyer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'power loom weaver mindr' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'powerloom stuff weaver' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'printer carpet works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'printer in tin works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'printer on chocolate sugar hou' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'printers litho packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'puddler' (lang: en)<br />HISCO: 72190, Description: Other Metal Smelting, Converting and Refining Furnaceman","Input: 'puddler a furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'puddler overseer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'pudler' (lang: en)<br />HISCO: 72190, Description: Other Metal Smelting, Converting and Refining Furnaceman","Input: 'pudler at iron furnaces' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'pump maker well sinker' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'purrier boat worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'quarry man' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'quarryman' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'quarryman deceased' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'raswerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'rebslager logerende' (lang: da)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'reebslager' (lang: da)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'regimental packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'retired fram work knitter' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'retired malster brewer' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'retired overcooker cotton spin' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'retired plate roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'retired winder bobbin cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'ribtop hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'roller' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'roomg frame tenter cotton mill' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'rope hemp dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'rope maker' (lang: en)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'rostvaendare' (lang: se)<br />HISCO: 72120, Description: Blast Furnaceman (Ore Smelting)","Input: 'rover' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'rover silk' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'roving doubler' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'runs carding machine' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 's cotton peicer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'saaiwerker en not mentioned in source' (lang: nl)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'sail maker assistant' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'sastre' (lang: ca)<br />HISCO: 79120, Description: Tailor, MadetoMeasure Garments","Input: 'sauyer in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'sawer printworks' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer' (lang: en)<br />HISCO: 73210, Description: Sawyer, General","Input: 'sawyer' (lang: unk)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer cowkeeper' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer wood cutter' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer (deceased)' (lang: en)<br />HISCO: 73210, Description: Sawyer, General","Input: 'sawyer at colliery' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer hand saw' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer iron band saw' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer pulp works' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'school butcher lad' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'seamster' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'segor maker' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'seijlemaeker en not mentioned in source' (lang: nl)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'self act minder in cotton mill' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'self active cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'self actor minder' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'serraller fonedor' (lang: ca)<br />HISCO: 72320, Description: Furnaceman, MetalMelting, except Cupola","Input: 'sewer plain on dress maker' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sewing knitting' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sewing machinist trusses' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'shearman iron works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'sheet iron roller' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shell fitter in steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shepper grinder in cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'shiort hand tipewriter' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'shiper in cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'shoddy picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'shop assistant gents hats and' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'shoperkr' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shopkeeper oil color general' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'sigar mkr' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'sijdekousemaeker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'sijgrofgrijnwerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'sijreder en not mentioned in source' (lang: nl)<br />HISCO: 75190, Description: Other Fibre Preparers","Input: 'sijverwergesel en not mentioned in source' (lang: nl)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'silk cotton hd loom weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk ballers helper' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk cheese winder' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk furniture weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk merces' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk rover spinning operative' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk sc' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk sorter smallware' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk tie mender factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silver plater emp 30 hands' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'sinker' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'skinner and corn factor' (lang: en)<br />HISCO: 76130, Description: Hide Flesher and Dehairer (Hand)","Input: 'skraeddare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeddarelaerling' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedderforretning' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedderiarbetare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeddermester' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraederdreng tjenere' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedersvend' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'slagter svend mandens broder' (lang: da)<br />HISCO: 77310, Description: Butcher, General","Input: 'slagterdreng gaardskarl husfader' (lang: da)<br />HISCO: 77310, Description: Butcher, General","Input: 'slany hterman' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'sleevemaker' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sluber on cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'smelter' (lang: da)<br />HISCO: 72120, Description: Blast Furnaceman (Ore Smelting)","Input: 'sockenskraeddare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'soemmerska' (lang: se)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'softgoods packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'spar worker others 213' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'spindehaandtering hos faderen' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spindekone' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spindepige' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinderske' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinderske dennes datter' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinner' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinner cotton side piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'spinning worsted doffer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'spool winder at smallware mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'spring fitters viceman in stee' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'spring roller at steel works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'steam engine tenter at a worst' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'steam loom weaver of silk' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'steel armour plate dresser' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel sheet works labourer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker finishing dept' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker tongsman' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steenhukker' (lang: da)<br />HISCO: 71220, Description: Stone Splitter","Input: 'stell worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'stick umbrella maker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'stick worker paperer sand' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'sticker w cloth' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'sticktelijffmaecker' (lang: nl)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'stitcher on a cotton bleach wo' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'stockinger' (lang: en)<br />HISCO: 75540, Description: Knitter (HandOperated Machine)","Input: 'stole smelter' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'streets on stay busk' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'stud worker jewellers' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'sugar dealers forman' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'superintendant oil mills' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'superintendent in fancy goods' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'syening' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syepige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syer for folk og har 20rd aarl af post cassen madmoder' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syerske' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syerske barn' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'sypige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'sypige hos moderen' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'tailor' (lang: en)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'tailore' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'tailoress presser at clothing' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'tanner' (lang: en)<br />HISCO: 76145, Description: Tanner","Input: 'tanner ( dec )' (lang: en)<br />HISCO: 76145, Description: Tanner","Input: 'tape led warper at factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'tapetseringsarbetare' (lang: se)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'tartbagare och alderman' (lang: se)<br />HISCO: 77630, Description: Pastry Maker","Input: 'tea packer labeller' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'tent decorator' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'tenter in a cotton card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'tenting weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'thread mill worker parcel dept' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'throalt warper' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'throsle rover' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'throsstle dofer cotton' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'throstle cotton spinner and proprietor houses' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'timber sawyer unemployed' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'tin dresser' (lang: en)<br />HISCO: 71290, Description: Other Mineral and Stone Treaters","Input: 'tin plate worker employing 1 m' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tin plate worker g e r' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tin worker spiner' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tinplate cold roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tipper umbrella trade' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'tky red yarn dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'tobacco assorter' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'tobacco operator welling down' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'toilet packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'townsman to a dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'traveller for specialities for' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'treckwerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trekwercker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trekwerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trimmer carriage' (lang: en)<br />HISCO: 79630, Description: Vehicle Upholsterer","Input: 'trimmer upholsterers' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'tripe dresser' (lang: en)<br />HISCO: 77390, Description: Other Butchers and Meat Preparers","Input: 'turner in iron at drill factor' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'twister' (lang: en)<br />HISCO: 75240, Description: Twister","Input: 'twister for cotton weavers ma' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'twister in' (lang: en)<br />HISCO: 75240, Description: Twister","Input: 'twister in a factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'twister in worsted and cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'umbrella maker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'umbrella maker cane worker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'umbrella maker hawker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'under cotton' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'upholsterer' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'upholsterer furniture booker' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'upholstress apprenctice' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaever hans sons kone' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaever svaend' (lang: no)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaeverske' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'valcanise worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'velvet piece stitcher' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'w i cigarshop' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'wangler' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'warp dresser cott worsted m' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'warper (deceased)' (lang: en)<br />HISCO: 75415, Description: Beam Warper","Input: 'warper with weavers' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'warping piecer woollen' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'warsted mill hang' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'waste picker cotton waste ware' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'watchman sugar house' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver stitcher out of empl' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver at woollen cloth mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weaver cotton calica' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver cotton unempl' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver in a worsted factory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weaver in power loom wool' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weavers cloth picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'weaverstzer on tweed' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weigh clerk silk mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'weigher flax mill packring roo' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wever en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'whife of butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'wholesale butcher' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'willier in coth mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'winder in wool factory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'winder of jute yarn' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'winding silk manufacture' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'winter cop' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'wire drawer' (lang: en)<br />HISCO: 72725, Description: Wire Drawer (Hand or Machine)","Input: 'wkhome spining' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'wks hosiery fact' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'wolkammer en not mentioned in source' (lang: nl)<br />HISCO: 75145, Description: Fibre Comber","Input: 'wollen mercht capt 60 lanark' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wollen twister' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'wolwever en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'wool cloth mending' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool comber' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool cotton drawer' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'wool shawl dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool slivering' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool sorter' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool trade wool cotterror clas' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool warehoseman' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool worker f gds tex' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woolen cloth worker unemploye' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woolen peicener at a' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woolen warper wln' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen cloth gig mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen cloth marker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen manufacturer farmer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen peicer in factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen warper app' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen weaver unemployed woo' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen woollen mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worker dresser in cotton stott' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'worker in ironstone pit' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'worker in stick manufactery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'working bone mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'works in woll mills' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'works is sawmill' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'works on silk mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worseted twster' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'worsted factory operative' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted machinist' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted mill operator' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted preparer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worstud works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wrks in web factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'xocolater' (lang: ca)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'yarn weaver i e linen' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'zijdenlakenwerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'zijdereeder en not mentioned in source' (lang: nl)<br />HISCO: 75190, Description: Other Fibre Preparers","Input: 'çarrador' (lang: ca)<br />HISCO: 73210, Description: Sawyer, General"],"mode":"markers","marker":{"color":"rgba(241,204,114,1)","opacity":0.69999999999999996,"line":{"color":"rgba(241,204,114,1)"}},"type":"scatter3d","name":"7","textfont":{"color":"rgba(241,204,114,1)"},"error_y":{"color":"rgba(241,204,114,1)"},"error_x":{"color":"rgba(241,204,114,1)"},"line":{"color":"rgba(241,204,114,1)"},"frame":null},{"x":[-12.946677729649984,-73.207353049276364,-64.809333193187072,-52.28658815027935,-28.167270775490341,6.9465660751666265,47.625350512854254,-1.0980622781969933,-62.857862607867006,-19.391932391145446,-52.285032211442832,16.085937070017206,13.461404054558862,30.058693283838313,43.130792331606386,97.043636710806439,-0.92974360003717282,-8.6520286623078011,-68.479836392938083,-57.400595452965554,-54.482781743962953,-50.806544507206802,-60.617199765853876,0.80569283551821458,-75.550369155955622,-27.275341891274849,-1.467472064591786,-66.192176744029581,17.130583110631353,17.421231223887624,0.96928171304057675,47.844900487593641,21.380248854009139,0.17700942262730901,-16.334096944115771,3.5100549877381297,-29.00868332627066,-22.041785718668304,-1.6365579040926441,-19.195137971674463,0.37520578279930134,-12.946630921981706,-18.648895145309588,99.052461484377659,24.699553330479777,0.33785667217312054,85.38610082044984,-73.768729243823771,25.426564602300953,-57.791749929912747,23.331897680523142,19.689270062066115,-7.8041063309637897,-14.74406589760539,-62.90067641977695,46.850588186620705,-56.721273237966884,25.556629319593991,-23.252856201927653,-7.8855920616174702,-36.697262544435382,-18.99404512041766,-3.8506821624606573,11.079287040970504,-67.558572268928401,-69.777202557961317,-62.224324062259058,42.406834549758507,13.218675504481153,-54.359577310091289,99.855182268889578,-1.4045455365845092,98.20302782080141,-24.581539257614903,18.863645987994808,3.5298627647419138,27.307378773775792,-42.598332959240558,-56.763695269980772,73.895037403352802,-17.987222824720821,4.8556718754226402,-50.61157307631548,63.433090815354575,-8.7354797796501682,26.756954616304895,35.470514786191174,32.463615039692343,-51.448144977409406,43.613072530640565,57.101300849916569,3.9293450744504321,-26.426619461689913,-63.079434801732631,-4.731764724690616,0.58260515435439308,-42.700549537164619,29.266012806268588,-27.26235771831503,-32.333863278846174,-10.104502795506459,-58.634232138141414,-57.626600108312559,-2.0378678828551693,10.154733925606022,26.786976924486119,-22.090274180946157,-14.296105066337203,-56.128639162933148,92.743570794370015,-51.586744312865619,98.181503814159583,6.1974273476336679,-50.219138150746247,-31.080243599680536,-72.740427168348305,-53.996247827834623,19.04761747078177,6.3676235208105432,-43.315876315093071,-33.671352447314348,12.946115180079778,-19.108981800515359,5.9486244396677614,14.639514337600975,-66.331823814074099,23.052019152061547,-63.64846025572102,55.126595373327433,-5.6455102548232627,-82.662541609727995,-14.857138702379078,54.922278245378621,-47.034182606949237,-12.829752492263395,-59.679201786019959,1.0823069483882577,-66.07186534858306,-22.503886052691158,-46.562283197775514,-53.628883528243854,-43.975873902273847,80.715754492624868,-4.58537210896099,-8.0174492832676005,-40.531503850469612,-0.89106410162638949,33.193329751618229,2.7724169994165422,44.378324885575097,110.42518508525266,25.813487149720729,9.3813476824640194,-78.847590435616823,-56.47100162991601,-48.945541849135125,-0.8638046325572436,-2.6694424314259835,-40.307657296180103,-0.10148487613964732,-37.972717572495966,-83.89422328443203,45.473105647864905,-89.143506529735532,39.32934047541977,50.872741507333664,28.041701278236239,-79.562016092798203,33.501619049772522,-45.491495575374522,-45.437726563415787,34.606835548076496,-21.639773417080239,34.360401761971843,41.619331229699725,3.9788852391946734,-19.760888494974221,30.8775211526332,-51.953972037410068,-47.765553541204206,83.466278487039631,36.232911559537207,-37.558124079963001,-14.572911054247792,23.181199936068197,-1.8166730100102648,59.823460071632738,-15.705862989379078,-14.844335843327125,-8.2005515885383371,-42.223820432209877,50.787323766097984,-28.302908549125181,28.673666391102074,39.050267599598975,92.752579398859382,9.5851140711565481,4.8209874908313655,-12.312357794138553,47.170557994659035,36.781308908212054,-74.808727434924961,-39.510197221872595,-21.434511162745792,44.715981383914723,4.6276866783572421,4.6449532190360987,-21.452573872389582,-47.171677880013547,-42.990366509727139,0.27805174153431994,31.702008991939532,-20.998255065347571,-81.666521725088813,-24.36923328885376,-65.398493562574387,49.138890645816694,-7.599716923696568,-38.342653062662265,8.8440241563143545,31.546311080644369,30.564482767915358,36.846113080960343,-20.203139248110311,-41.14556750733766,94.089849077268312,94.937546883876053,-2.7711306022159081,-32.927013456699299,61.596156121242771,-58.500933595641548,-82.321254371029482,-73.499462677272874,-66.68221027854554,-10.146503238308091,-86.269818049757376,50.651302448937557,0.19633840816230805,4.7722512751115795,-19.514899109544871,-63.117194432791401,-35.427525735949047,27.016556517032541,-22.179770310648827,-9.5018998934380701,-28.630834166399683,13.588017571723819,75.952024333033179,-80.803425494464108,32.389056193748281,-44.484420778195791,19.195494647676966,73.100160649907252,63.057831197621347,42.180094553427011,-6.1372426224953696,-3.3720538299019749,-35.786471167394602,-17.456778888359487,-16.566569479511408,6.063420293673504,6.2741027719494005,13.483471741637199,92.046040473047128,0.76043988814445196,3.3576661956650677,-22.280855024578578,-72.719416943552289,-78.27078298565165,-48.261411229198863,-42.822942094267461,-3.1824600666805272,-64.322912709065463,30.352697724261418,-71.564112770507421,-11.837134437361289,85.84969250524766,75.987060359937672,28.935306095264039,-52.122916472414097,-36.262928084695169,-37.441563919204263,0.17865941113980033,-18.755562744245896,0.5981752241842625,106.10895005360015,49.008276786909484,-44.403371885863088,-58.698942782280618,87.726124920183523,43.836474569816261,48.775198550589771,95.125184514965028,-29.876241288055297,-62.674480832975455,29.59287631182082,46.156651893334683,-57.764213390457101,44.91690702926951,-51.964511382629127,-46.354004467248799,-71.454655457321962,41.727929091191115,-30.205433447701008,65.038199609184701,51.636487021234629,-60.039356091100416,-60.857815327343232,-22.698857347512316,77.124913392027537,49.978421928702623,37.363879171722814,-42.959172482806061,80.688555580529027,39.582081640143528,-63.818588832847723,-0.99384315599515249,53.173879931461435,-0.0056685662238750009,82.8994408777546,-30.423867653452032,-1.8102360364176902,24.767155443566978,-9.7894322766502206,-33.121838537134821,44.309908651308191,58.347042325124058,12.259224153331679,13.167296775196561,50.553567246318465,-52.206224930475884,6.732092082502585,49.579216279025076,49.579686904723708,53.091863347947033,52.046943514709504,80.335914378928734,45.051027273693869,31.494163666130916,49.626600451146885,-14.835746721820275,46.684286546764937,70.210581158909505,-51.63795710109229,31.020209499661771,6.7541212194677982,3.1421447537375697,11.129493423847558,43.871819236936652,-40.556120480369636,-62.261541462667459,-28.18797038211137,-57.733996852178187,-23.842056079548669,110.85382223514007,-50.080225018626273,39.299041372510899,58.125568040649696,2.2387708954032512,84.242638851457144,-33.189746867088097,15.419244354160472,-91.060202706533971,-74.261843400432667,-59.228853482933118,30.727364146509647,-42.097834129902701,-61.99368213306898,85.202171101664717,-63.244438453018347,-5.4434909357791561,2.552385053566292,-45.272199800178825,60.668397773684859,-49.450614387307752,-8.6714471298243065,-50.036569817120331,23.151122981640306,-61.060898360820339,-27.657792906931039,-89.21971242875567,-82.620258448365263,97.711729070187431,-44.053765430104406,93.576056073605827,20.060281758386907,61.957242713717918,-30.827331481837213,77.156853033654585,-11.020116641171052,-22.561086740799873,-49.897719952882753,31.27964739566147,19.065758583000477,-49.007670838835146,13.297505252915618,-20.045379971604188,-51.962984879977427,27.897838954105385,-0.14105216426199593,-4.4715933670255481,-30.575397597380558,15.245994258497145,-22.273004548904449,-59.925899397962425,-21.658495916903405,57.183577138586763,35.498111893039372,-12.988880098803124,18.234523458939517,54.576464259029052,31.546341472307233,46.946897135378038,37.906157073794795,-73.993150107081334,22.76610497912116,-20.476565669605225,26.849335242653094,8.586909201650089,-62.78085143692774,-48.340790669174822,-16.725816645588647,22.053790689078404,-18.327875740034504,70.227771485025329,20.918505574928066],"y":[-191.35041309400063,23.44821534064458,-16.985546382887676,-100.64674593422139,116.21855325663795,-167.82878074060309,40.7214574798573,-29.785347485530572,-0.11110285715033824,-165.55524404655466,-124.46035841896843,-153.1576146108705,-73.791790366593432,-117.21780725245542,92.004390946952597,87.680885931491687,-171.4261843544561,-114.99538919310837,-56.824734590713746,107.14789750581515,-14.105693239667175,-36.281341045786164,38.363426545135972,125.31054623440363,58.355155067162066,-11.315517756315922,128.9089221576302,-16.412589833465436,-7.9152577795653576,-62.646723758053056,70.357318300297976,66.628284009177676,146.80252912513944,-140.33812741587766,91.381355478236216,-124.07950713722329,-69.765220420086834,-69.319162963499224,-127.3788293172305,-71.438221070917081,-113.43354036431738,130.10577948944217,-168.12590056953033,89.677338984316009,-26.950510066756653,-142.5454144364333,49.467004170661987,48.750490381326046,126.45827242732813,-70.195716132300433,124.96575577278678,125.32208613156513,102.86106291584964,78.895491277782824,-147.04386112435802,112.93660669260565,-140.58404909819933,-53.914024103090867,90.214649062694292,-36.754082706199725,-8.5026190442531124,-113.86741617819177,106.67166601832027,88.873434188743687,35.470206475113088,57.814997389536465,-59.914392714460476,66.552950192169249,72.547408298800789,49.679606951310731,100.03653509155697,-11.458660517522647,130.63178234151553,-35.530303125196021,138.65165407101472,-31.062508708969549,25.060445717747953,-29.858915828298485,-35.662650823801407,107.08272760181963,110.13902593838171,-29.423006306400264,91.265567752010952,56.592124641705404,-15.063400493088633,17.511687073461449,124.37910787964752,122.49993595961503,32.251191646095428,56.725287165394143,-67.107226992558836,-9.2613664252965062,-209.20479459630602,75.145210465169967,97.993499978288028,-60.938773624504478,-126.99119816236063,-52.884508154312421,-214.69082614110104,-74.748682894225453,-103.23661630122709,-54.260346962884846,-139.74727540510463,-117.84061405423517,30.146620157118878,150.34075188258549,-103.2233452160298,-100.28834846602201,-138.71061165273952,39.102843499105184,-65.096110630577414,98.948498582743241,-170.06754148234782,-73.381432908313926,-74.66093988006638,-38.416905164013912,-30.964720365701524,84.105936041106787,-28.388450478179774,-37.724717490106308,9.8748542337218037,-9.8195954249321886,137.71906195373981,72.11929537232885,67.677399135088393,31.718377888993651,150.78769962133541,-38.952488373629755,67.944529864220101,-121.32846029737723,47.411936422520647,-90.160993018849865,85.37198705516812,-195.04833546066843,140.30230451961805,84.012145880379649,155.88514996137908,-19.875538550746032,-102.32191483035564,-183.79333130869958,-186.70586961220769,-188.47797800641899,98.743885883751531,11.62071361906613,-123.16443608213446,46.606530371225688,123.69264108915809,116.67405721655844,138.6229061929273,77.354348085000083,67.796692278992055,36.442052936134239,113.02952532491899,-72.619360390941722,-185.57074301193865,-196.12926217800583,11.916685240780346,117.7895935807412,-73.352801845434129,0.074430642730586208,115.88221607599053,12.747032474241616,42.199825035292569,2.412732654837872,51.485146939451496,30.287305175554973,37.398945530492938,56.8258163238295,91.176138473727349,-31.911065147515497,-186.82505020355424,-62.198409457805113,-192.46894553154826,96.198185941205907,16.973348981570265,123.7290185606721,-225.73562710123642,148.61072929777566,-171.07660969885765,70.070009828778936,57.22077960611729,98.964544964941155,-108.02215306345722,-114.70494911176867,-62.17183594630739,-138.64002159858273,71.855185248636403,-178.03283331131979,111.46039946612113,-179.28122817172633,30.769918239523744,105.76724987994231,21.897336326935562,127.12083285077766,129.07490360963459,54.041219124813608,-174.84192186464909,47.238497071587524,-19.989284892214407,36.924267232891673,61.239639163184613,-40.954572161393919,-109.86662839803786,110.85039445269763,-9.4903266827579529,142.42688401851282,143.62632993059475,-72.761650798446567,125.19827691912215,4.9474144742036863,45.337732563490583,-63.21046801966412,-85.850353297712857,-19.38440484444785,21.420284636255033,-98.867669422279164,95.492952124664029,-70.704063540716433,63.383924422344933,-192.44700999615645,-98.516237809430294,127.69187355522246,7.4264060416907087,105.0666573618806,147.1450004142977,105.2531588448872,107.27614816841761,-77.177479311730863,-126.3006167378622,91.908923530982761,-129.89396512216808,24.453579499108958,-39.117967124841051,49.807580786072883,-103.8222561475353,42.181862852739094,123.13183098349047,147.74146855827468,-102.33201502426984,75.37809976281936,-102.60100229542653,118.43090569128096,139.43543963133601,-81.818503100962275,-211.98873391207454,-60.429719260375983,19.035795546626101,85.425873218470414,-17.570929463997427,113.06963644791622,93.17720158201405,-220.65780098388939,75.252222448821612,61.552719293513839,154.2574285728283,-101.38158233895973,27.596470344280259,26.803592518644177,109.86405703245258,120.16319386793646,27.679696703241426,29.430698032399093,4.4351408689429235,129.01932537578384,-140.98597619839745,49.627951028124144,-108.89669707705805,-35.756144614526342,41.639357355892386,112.54677172331286,-28.76508591496205,-32.4028838353941,58.501163411109296,18.017085119234189,49.594983122841128,-111.43383676311315,99.96073307473911,125.42725037476667,-14.21990522192127,121.32246558599884,-196.85917155937088,-178.37488648889939,-123.52174694826168,72.888594797696811,142.17000807004251,98.458418933280214,104.33841592632835,-48.702614626700026,61.043062613530211,66.251827752090961,84.080890270997116,-89.21718101629591,115.15234365533362,-29.715389421455736,73.908562543670058,102.79177271632189,74.866373448528535,36.582367438836513,27.277306425032556,-188.59806919977754,-198.90081019111619,-51.217121521385039,19.913560616081664,3.6550308341919511,56.628682313540132,62.639355255528187,-24.496752696178032,25.040161906337698,-83.263502594348722,102.99231294064259,167.73879851402197,125.64454681785544,53.776336219429389,120.37562093697487,125.62200207509252,28.713704255783526,-140.28907759111678,135.76325815031146,-174.13806587469892,62.284452130279966,156.85495424301894,139.61226550694224,-194.45329534894071,-111.62040242788164,83.883303913841658,80.170056602696107,4.6587237328438764,100.64844608312097,-206.30250137526295,-8.3262920198073278,-194.92599880564131,-49.441993245489144,95.309452320326827,108.1636466476442,-127.3699689637654,-128.13378632560537,56.449344213152834,17.980418575096433,131.10606146415878,151.01601663975802,76.028300004822995,108.24928095334559,-52.543236507534537,90.523453232629535,75.319913282607402,-52.866581595395147,82.297897591103691,-190.48206774241959,52.225649667381276,-187.52128828943762,71.677678036409191,-162.326124726632,-58.11216244020374,90.191403251635762,101.63491247568648,-184.5997123968599,51.461405232251501,-12.660693648500882,-195.31845046465259,122.55555094898378,21.8048334906746,-25.869048918817487,31.340293259064889,-51.438593938406164,-38.642753761845746,-68.362235617298964,90.471278979795557,-25.718695783926258,143.59433652163727,-18.619338461677486,-20.291429510202708,31.296956593821069,29.134674460594226,60.018545819787178,-129.8291833118179,-39.251107404668304,34.430322415386044,-63.649471084623698,35.039037858561308,144.50748509960829,40.286960475727348,46.058280305107907,46.138745861554909,149.02223763878325,70.182024984706345,88.090413122810872,74.347115429080191,43.156606207695042,81.898581282376512,-195.43815984799227,-4.0227456585571542,-115.60062944205278,108.10955025006132,-147.75243176997438,94.942206684547912,103.17768625952132,6.54928686657074,-63.182907417421056,137.00461201181051,124.73372492969223,-124.30842286759514,121.63340031775377,142.60128229610302,17.292651736572942,-132.13064182967966,62.836901614168767,165.07944215608686,-179.68209721968626,-117.98168447098158,111.32742909098135,159.37823935466577,16.64515811086801,84.585827052000866,32.587106740443325,-45.738544220748906,112.2625955759609,29.051741106378124,-7.6715977402523237,109.39474826559605,70.681595561224697,25.143844254496639,-90.957793560450398,-46.747535158102998,-88.727213621187317,78.735287040277811,147.03098565464322],"z":[-3.36666445370156,53.057726944612789,-18.464534907311247,-20.86599268177136,-4.4085339562472505,-1.0133882468530566,-49.516891514449426,-36.299371055270832,35.632423873737764,-8.7836071827497282,-14.876541425208888,-16.583820207540981,-44.772392678334278,-27.62715476865554,-61.749393149898488,-20.118784410163954,12.766619966036661,-43.028443987160372,9.7851922281753279,-6.6555761229640682,0.18952308155962899,68.524384104241676,60.275726236880459,15.854276124066974,30.192776848769089,-22.995863830257392,14.261991304182612,-15.680917930294186,62.590801349651024,43.423776390596174,-42.063941038523751,-36.669838011845798,-16.681974427641656,-20.609238758517986,-20.827813511793284,-1.5049700050456545,-19.742379502628946,10.78657848285337,-23.850320881805654,-10.856116964245869,-0.80520259288246598,-27.350371599379915,-9.3687415349121554,-19.615047437902927,18.515283576770745,-5.3368331532712396,-30.324488226577639,56.058686044007409,-23.801469060519207,50.94649565770036,-34.170618496834521,-36.982467707801213,11.782505812254588,61.665532420054916,7.9935707319361216,-84.173481462672669,-0.10062168892227762,31.243865496190082,-15.406848098844172,-41.318434398864348,-1.1815842477410485,56.679186847689387,-28.94842181731687,-35.207256657731776,-15.14033545193935,103.31955713699004,30.776133218912538,-51.277359963985759,-28.816890511374485,64.189094212967049,-31.803963980599374,-63.738383122875867,-11.27193703035784,55.043350182871528,-24.405299039041445,-36.246621484891115,-49.112879436688814,3.9776277384208027,20.48966402973846,-30.1220240767679,48.025723334578572,-40.829729724215994,-25.884548930382891,-114.72635357953766,14.554438276460695,-54.437090956133702,9.5414584658499173,9.1677812455964034,80.925550400670787,-83.061005031426902,-51.471035093909634,95.909120964853358,7.0349195221139773,110.36321536983669,12.12388501644195,-50.57808475288644,-12.838424367325388,-21.892724877132963,24.061070042199649,19.112935879548097,46.926230125226986,-11.892424738491314,5.242331782431676,-36.468494344499966,-51.067478936403127,-5.8292649936141236,-33.180739610504247,-32.845195755783216,-2.4409770754253115,-110.27076186852096,-10.293071978997398,-31.86668019175487,0.078483242536932687,28.572439754899651,26.237780698826185,75.665338874589381,1.2372917000593537,-35.58552578545379,-13.777659819369427,-4.4748495237824981,92.541044183882207,-26.050010934414043,24.366478962993234,-16.583215319651433,-19.306875554403433,-0.67604500946685675,-4.2141160561126032,30.648237296850127,-80.906997353913169,-26.026263691718867,28.676745625089872,25.10225469380649,31.686326347585073,15.009670869711133,20.228677368510684,77.79499585431941,14.183453506163934,-15.798531962093037,59.554814691164687,35.745579016594434,50.570731761699193,58.896342202555338,-50.40901270644401,49.73416062570535,-0.85446814151272243,-20.555130663016875,-33.825507089311742,-34.527152900438516,24.358667825481881,-83.35183297847675,-30.357037459445312,-29.727970754739143,50.805063465853017,10.862961674427885,15.481913247964911,52.093486965536528,25.28486173532832,-3.5160383356817548,-16.133961463420128,28.258283761178518,-26.045601466914341,-16.645990478565825,-45.902181375969739,31.126794295704229,-80.827460454281351,-55.995172585515014,-36.183947547667934,26.683700057323826,-49.424915951480415,7.2448586846827183,60.116545633603302,-22.039179069301365,-11.374521742706861,11.754467673899708,-13.9693220495863,-36.946537781251692,1.7825876123874353,-61.351449033639504,7.9750434185287284,105.33975234459007,-113.0161059560503,-35.767589073225238,2.0446169809144474,-38.985509895597453,-37.14869103154696,-14.27662586683628,-93.481143633370749,5.3587270525126671,-34.101194943918891,16.277490550210747,53.063153944912543,-79.628646495728475,62.665355258249988,-44.866670313676444,-25.527023184442779,-105.39518993807211,3.04664720366734,64.212909019396136,94.229384484883312,-51.328221309509622,-27.058557438845209,29.146763016079433,34.971585318797885,-7.500010653557827,-74.851842617274656,53.30476306282501,52.428787636276454,38.238667745172584,-5.1874151589698343,52.773645050072517,76.406385385327297,62.246132963397393,-28.444291287656792,57.975049995992009,3.1174401094817878,-6.3685478064958732,-6.5185492256880773,-32.064179558084554,-41.021500581849317,-19.988164914702068,-22.918190516288451,-46.610518440577522,9.1450846422888485,-21.073259456762649,-2.3605509246958096,-10.869420845975185,-10.579658630255356,-13.277743837733047,-5.2073403844356339,-106.82228734484241,8.9458587158111289,-14.338077112794851,29.677718357164128,29.145793375201425,44.230667898082828,11.946232664968131,8.4836418382358492,12.540965080181286,16.50588010175121,10.470541573699194,-1.4471145313889764,-18.38536983411873,-66.181459761300019,-44.734893209056125,24.894438629200142,-13.242960629263266,-41.961137859616933,-56.873312350703983,58.896352910954896,-20.439009686955881,37.827384881536027,11.186302044169974,-40.399814186493067,-75.201459063525746,8.9415944665869738,36.265531880599639,111.53134244862694,92.922131354334198,34.850138348612255,-18.904267220863272,102.74127638307783,102.55522469062667,51.941209223151894,-16.215773464744402,-15.753823170499937,75.107115349726513,59.029780505751454,26.596460202553519,27.20478912562907,27.250046835297226,91.586077162837498,18.865600920147919,6.0157759460117637,-18.191741305926001,22.506674762084312,41.575584083819358,-44.672345640364114,-42.859084591263063,-74.51891331057368,4.4593214956306673,34.233735287012657,16.382465084771013,39.701894975088024,9.6856234681559599,14.254879704423923,-17.814769353509995,-4.6745005045955113,62.428949784727472,97.072732247036271,-128.36049333740036,20.455067462217794,-26.351846816922873,-31.552589598861722,77.471376530325358,109.38008901479316,51.737440278524218,-37.511204061092961,127.46043967607169,-63.194870342210059,37.31348203961381,42.254250600359512,46.280509012252317,-50.598212584495315,65.288109771622402,-77.21580822110073,-43.097582693704965,-3.6578851836794044,20.693575294664793,45.590008933726402,-29.569807373252033,-3.3241648387758662,10.174684677318087,115.00705385619734,3.0818981637489449,9.666836535931111,59.068962948392191,-18.420381170419677,-14.663078078141861,14.501594108155652,-118.50169452136923,-14.12232049170966,7.9416074858254939,-1.9063371441077472,28.963133625767146,-7.3939013205764921,21.111165451069542,-18.282528953363098,-9.7567277787666402,1.1370226056643384,-74.86101108574131,27.467184029124851,-69.037279699203111,18.560649432967629,-115.29526448522887,31.773246107511927,31.26572960729899,-130.60797967736011,-56.021263920946076,-39.004137357998431,-24.616072953198824,-10.977912571507987,-123.34247760636336,-24.143324431881751,-29.206989802269128,-43.797707222884853,53.20469819358155,-36.123669825350177,-0.74342373284369911,-91.403386920327264,41.143964624583994,-27.564546717285644,-10.087047500401837,34.398928431693506,-18.879641785610417,-19.464679293825753,18.226496817967423,21.734802948539144,-69.538260241564458,-17.585270070864741,-25.276827684485578,60.670910356708134,8.2636302762691898,16.31880605096649,44.738111584833582,51.879695628382969,-31.727638246121817,41.31982522344321,-15.805994438380392,-38.251958092339819,-21.295948403989787,-35.314876114265928,101.74932846497478,69.376219672852159,-77.223892363082243,17.362350576199646,-40.348380354237932,80.462150777937055,-32.578884170216583,59.174487694173266,18.046931242796557,22.500145966365128,24.448825738913222,-115.74205231026508,-4.2300318285812626,-120.01420319888179,-57.200662411733369,-80.232413635066052,89.132008884094859,-108.07263827090382,12.731763031878973,15.560206674512497,-5.671475022885974,-40.184419983253967,-33.455015240474793,-28.267222281686298,-29.980526888513939,-15.361082028508015,-10.367911725397022,-29.700995591045253,-6.7776221421721772,-25.892748492924078,38.617151505268517,0.30300582914478424,1.8134474495347777,4.2737181859287343,14.364721263006125,-4.4099108294708538,-29.609012781016464,-43.085191055395256,-38.857702628587717,-9.1119290394745498,-35.834127985372298,-29.818860974285659,-46.497011051804364,42.262748796393296,-27.192961844734597,-7.1571088792418314,6.7688414207910643,43.719539482275479,96.2691494261325,-7.2647786055091226,56.657383239332553,-12.175266546607794,-28.710132120719127,-58.577208025211846,-9.4220903407947638],"text":["Input: 'aftaegtsmand traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'app boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'appren turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'apprentice turner in fitting s' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'apprenticed to potter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'architural draftsman' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'ashpalt maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'assistant edge tool works' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'assistant picture framer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'asst enginedriverroad roller' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'auto mobile mechanician' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'balance tster' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'betielbakker' (lang: nl)<br />HISCO: 89210, Description: Potter, General","Input: 'binding board manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'black smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'blacksmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'bleachers framer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'blk smiths' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'blouse collar maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker publican golden' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker apprentice s e r' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker for ry co' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker g w rly' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker man' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler mkr' (lang: unk)<br />HISCO: 87350, Description: Boilersmith","Input: 'boilermaker lab' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'book maker games se' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'boommaeker en not mentioned in source' (lang: nl)<br />HISCO: 81925, Description: Cartwright","Input: 'boot and shoe maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot clicker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot finisher' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot rivitter' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'brass finisher' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'brass finisher (deceased)' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'brass finisher at engine wks' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass finishers plumber' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass founders finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass worker finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brassworks finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brick maker' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'brick manufacturer employing 2' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'brickmaker' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'brickmaker (deceased)' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'bridge boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'bridle manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'brukskomakare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'bufflow maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'cabinet case liner apprentice' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maekr' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'cabinet maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker' (lang: unk)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker (deceased)' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker apprenitce' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker daughter' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'cabinet maker master employg o' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinetmaker and upholsterer' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'candele maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'cap roller cotton' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'caps machine hand hatter' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'card room jobber' (lang: en)<br />HISCO: 84900, Description: Machinery Fitter (except Electrical), Specialisation Unknown","Input: 'chain maker' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'chair maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'chair maker benchman' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'chair maker journyman' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'chair upsholterer' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'china riveter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'chinell maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'chocolate box wood mkr' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'chopman' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'clay bath maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'clicker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'clock and watch maker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'clog maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'coachbuilder' (lang: en)<br />HISCO: 81920, Description: CoachBody Builder","Input: 'coachsmith' (lang: en)<br />HISCO: 81920, Description: CoachBody Builder","Input: 'collier harness maker' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'color manufacturer d p' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'cooper' (lang: en)<br />HISCO: 81930, Description: Cooper","Input: 'cooper (deceased)' (lang: en)<br />HISCO: 81930, Description: Cooper","Input: 'copper man labourer' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'copper smith labr' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'coppersmith piping' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'coppersmiths lab unemployed' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'copprsmith' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'cord wainer' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'cordwainer' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'cotton and linen manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'cutting cerditt' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'deres son hjulmand' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'deres son skomagerlaerling' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'diamantsnijder en not mentioned in source' (lang: nl)<br />HISCO: 88030, Description: Gem Cutter and Polisher","Input: 'director mechanical engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'ditto maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'dreierlaerling' (lang: da)<br />HISCO: 81230, Description: Wood Turner","Input: 'dress makers erand girl' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'drugest finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'ebbenhoutwerker en not mentioned in source' (lang: nl)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'edge tool finisher' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'edge tool works manager' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'engien boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'engine boiler maker apprentice' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'engine fitter' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engine smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'engineer' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engineer's fitter' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engineers tool manufacturer' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'engraver on pearl buttons' (lang: en)<br />HISCO: 88090, Description: Other Jewellery and Precious Metal Workers","Input: 'faggotter' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'fancy leather case worker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'farrier' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'field drain tile manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'finisher artisan' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'finisher for hosiery' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'firewood manufacterer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'fishmonger chair turner' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'fitter' (lang: en)<br />HISCO: 87110, Description: Pipe Fitter, General","Input: 'fitter (deceased)' (lang: en)<br />HISCO: 87110, Description: Pipe Fitter, General","Input: 'foreman margarine maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'foreman watch maker jeweler' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'forge labourer' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'forgeman' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'form missronery' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'foundry labourer of ironworks' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'french crower maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'furnaceman' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'ganger royal arsenal' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'gas fitter' (lang: en)<br />HISCO: 87120, Description: Gas Pipe Fitter","Input: 'gas hot water fitter' (lang: en)<br />HISCO: 87120, Description: Gas Pipe Fitter","Input: 'gen watchmaker jeweler' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'general engineer' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'gjotler' (lang: no)<br />HISCO: 87245, Description: Brazer","Input: 'glasblaser en not mentioned in source' (lang: nl)<br />HISCO: 89120, Description: Glass Blower","Input: 'glass cutter' (lang: en)<br />HISCO: 89156, Description: Glass Cutter","Input: 'glass cutter (deceased)' (lang: en)<br />HISCO: 89156, Description: Glass Cutter","Input: 'glass maker' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'glass placer potter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'glost warehouse sorter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'goudpletter en not mentioned in source' (lang: nl)<br />HISCO: 88070, Description: Precious Metal Leaf Roller","Input: 'goutdraattrecker en not mentioned in source' (lang: nl)<br />HISCO: 88090, Description: Other Jewellery and Precious Metal Workers","Input: 'goutsmit en not mentioned in source' (lang: nl)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'grinder' (lang: en)<br />HISCO: 83530, Description: Tool Grinder, Machine Tools","Input: 'grocer wife of wheelwright' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'guldsmedgesaell' (lang: se)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'gun barrel maker' (lang: en)<br />HISCO: 83920, Description: Gunsmith","Input: 'gun maker' (lang: en)<br />HISCO: 83920, Description: Gunsmith","Input: 'gunlock filer' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'hanvel maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'harness maker' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'hinge maker' (lang: en)<br />HISCO: 87390, Description: Other SheetMetal Workers","Input: 'hjulmand' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'holloware caster' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'horse nail maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'houtsagersmolenaer en not mentioned in source' (lang: nl)<br />HISCO: 81225, Description: Precision Sawyer, Hand or Machine","Input: 'houtzager en not mentioned in source' (lang: nl)<br />HISCO: 81225, Description: Precision Sawyer, Hand or Machine","Input: 'huusfaders moder' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'in a foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'in army reserve and agricultur' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'indsidder og traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'instrument maker' (lang: en)<br />HISCO: 84240, Description: Precision Instrument Assembler","Input: 'instrument maker ranger finder' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'iron forger' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'iron planer engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'iron turner' (lang: en)<br />HISCO: 83420, Description: Lathe Operator","Input: 'japanner' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'jeweller' (lang: en)<br />HISCO: 88010, Description: Jeweller, General","Input: 'joiner cabinet master' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'jour h maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'journeyman render' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'juwelier en not mentioned in source' (lang: nl)<br />HISCO: 88010, Description: Jeweller, General","Input: 'k md' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'karetmagersvend' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'key maker a p' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'keymaker' (lang: en)<br />HISCO: 83930, Description: Locksmith","Input: 'keysmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'kistenmaker en not mentioned in source' (lang: nl)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'kitter' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'kokermaker en not mentioned in source' (lang: nl)<br />HISCO: 89990, Description: Other Glass Formers, Potters and Related Workers","Input: 'kopparslagaregesaell' (lang: se)<br />HISCO: 87330, Description: Coppersmith","Input: 'kuiper' (lang: nl)<br />HISCO: 81930, Description: Cooper","Input: 'laborer unemploy' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'labourer in copper engraving w' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'labourer timber carrier' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'labourer wood' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'lace machine filler appntce' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'laces turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'lasting machine man boot facto' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'lath grinder' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'lath render licensed victual' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'laundry hand ironing machine' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'level escapement maker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'lithographer artist pottery ap' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'lock filer' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'lock smith' (lang: en)<br />HISCO: 83930, Description: Locksmith","Input: 'locksmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'locksmith, deceased' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'locomotive packer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'loodgieter en electricin' (lang: nl)<br />HISCO: 87105, Description: Plumber, General","Input: 'machine fitter' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'machine maker' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'machine makers apprentice' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'machine operator' (lang: en)<br />HISCO: 83410, Description: MachineTool Operator, General","Input: 'machineman appr' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'maesterhammarsmed' (lang: se)<br />HISCO: 83120, Description: Hammersmith","Input: 'maestersmed' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'maestersven' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'maker market talloring' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'makes butcher tools' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'manufacture glost placer' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'manufacturer of cottons patent' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'manufacturer of crop seeds' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'manufacturing optician retired' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'master chair maker employing a' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'mathamatical inst maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'mathematical instrument maker' (lang: en)<br />HISCO: 84240, Description: Precision Instrument Assembler","Input: 'mechanic' (lang: en)<br />HISCO: 84900, Description: Machinery Fitter (except Electrical), Specialisation Unknown","Input: 'mechanic gun tool maker' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'metal spinner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'meterological instrunt maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'meubeldraaier' (lang: nl)<br />HISCO: 81230, Description: Wood Turner","Input: 'mill furnaceman' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'morocan case maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'nail caster' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nail maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nailer' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nailor' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nickle telescope maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'nut and bolt maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'oliver smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'optical instrument tool maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'packet spink mathers maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'packing board coverer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'packing case maker' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'par relief dress maker illness' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'pasent shirt turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'paternmaker foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'pattern maker' (lang: en)<br />HISCO: 81935, Description: Wooden Pattern Maker","Input: 'pedreyaler' (lang: ca)<br />HISCO: 83920, Description: Gunsmith","Input: 'picture frame joiners' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'picture frame shopkeeper 3 men' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'pin maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'pipe maker' (lang: en)<br />HISCO: 89290, Description: Other Potters and Related Clay and Abrasive Formers","Input: 'piqueuse de bottines' (lang: fr)<br />HISCO: 80250, Description: Shoe Sewer (Hand or Machine)","Input: 'plaatsnijder en not mentioned in source' (lang: nl)<br />HISCO: 87310, Description: SheetMetal Worker, General","Input: 'plaster fiber manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'plater boilermaker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'plumber' (lang: en)<br />HISCO: 87105, Description: Plumber, General","Input: 'police pensioner watch clock' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'polisher' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'polisher at cycle works' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'pottemager husbond' (lang: da)<br />HISCO: 89210, Description: Potter, General","Input: 'potter' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'potter' (lang: unk)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter at' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter crate maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'potter hansferrer' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter, deceased' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'potters decorater painter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters painter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters warehouse' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters warehuose' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'powder working in manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'presser' (lang: en)<br />HISCO: 89247, Description: Pottery and Porcelain Presser (Die or Hand)","Input: 'pressing machine in factory' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'pump manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'railway loco engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'rate collector cabinet maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'remedial gymnash' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'ret harness maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'retired boot and shoe operative' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'retired french polisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'retired joiner and cabinet mer' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'retired saddler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'retired scientific instrument' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'retired watch maker finisher' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'rigger' (lang: en)<br />HISCO: 87400, Description: Structural Metal Preparer or Erector, Specialisation Unknown","Input: 'riveter' (lang: en)<br />HISCO: 87462, Description: Riveter (Hand or Machine)","Input: 'rivetter machine works' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'road maker croft 2 12 acres' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'roeremaecker en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'roerenmaker en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'roller coverer cotton mining' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'roller filter' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'roller maker foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'saddler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler tarpaulin manufactur' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler employing 1 men 1 boy' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmagerm' (lang: da)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmakare' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmakeriidkare' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sanitair gieter bij een aardewerkfabriek' (lang: nl)<br />HISCO: 89235, Description: Pottery and Porcelain Caster (Hand)","Input: 'sanitary mechanical engr em' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'satter' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'scampstress' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'schoenlapper en not mentioned in source' (lang: nl)<br />HISCO: 80130, Description: Shoe Repairer","Input: 'schoenmaker' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'schoenmaker en not mentioned in source' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'schoenmakersgezel en not mentioned in source' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'scientifc instrument maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'screw forger' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'scythe forger (deceased)' (lang: en)<br />HISCO: 83915, Description: Cutler","Input: 'sellier' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sent finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'sewing machine makers and builders' (lang: en)<br />HISCO: 84150, Description: Textile Machinery FitterAssembler","Input: 'sewing mc screw maker' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'shipping tackles maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'shoe finisher' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe laster' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe maker (deceased)' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe-maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoemaker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoemaker (dead)' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shorthand finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'silversmith' (lang: en)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'skoemagerdreng hendes son af 2 aegteskab' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skoemagermester' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomager' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagerlaerling' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagermester' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagersvend logerende' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakararbetare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakaredraeng' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakeriarbetare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skosoemmerska och filosofie licensiat' (lang: se)<br />HISCO: 80250, Description: Shoe Sewer (Hand or Machine)","Input: 'sloejdarbetare' (lang: se)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'slotenmaker en not mentioned in source' (lang: nl)<br />HISCO: 83930, Description: Locksmith","Input: 'smed' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smed' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smed mand' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedelaerling' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedelaerlinge' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedesvend' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedgesaell' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smit' (lang: nl)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smiths assistance' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'snedker' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'snedkerlaerlinge' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'snedkersvend' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'sobbing laborer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'sockensadelmakare och ordfoerande' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'solid finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'spade shaft finisher' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'spijkerblauwer' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'spijkerkoper en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'spinch maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'spindle flyer manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'spindle and flyer manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'spong bed maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'stamper' (lang: en)<br />HISCO: 83960, Description: MetalPress Operator","Input: 'steentjesbakker en not mentioned in source' (lang: nl)<br />HISCO: 89360, Description: Brick and Tile Kilnman","Input: 'stenarbetare' (lang: se)<br />HISCO: 82000, Description: Stone Cutters and Carvers","Input: 'stenhuggare' (lang: se)<br />HISCO: 82020, Description: Stone Cutter and Finisher","Input: 'stock fitter for shoes' (lang: en)<br />HISCO: 80200, Description: Shoe Cutters, Lasters, Sewers, and Related Workers","Input: 'striker' (lang: en)<br />HISCO: 83190, Description: Other Blacksmiths, Hammersmiths and ForgingPress Operators","Input: 'superintendent engeer mechani' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'surface laborer colly' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'surgical appliances' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'surveying instruments maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'table baize finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'tailore presser' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'tarpouline maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'tile presser bickiln' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'tilemaker' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'tin zinc worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tin plate worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tined holloware finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'tinman brazier ap' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tinsmith' (lang: unk)<br />HISCO: 87340, Description: Tinsmith","Input: 'tinsmith all kind of lamps' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tipe block maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'tobacco manufacturer and chemi' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'tobaco weighing' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'tool factory manager' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'tool maker' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'tool maker curling and hair pi' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'tool maker steel' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'traeskokarl' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'traeskomager' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'tulip frame maker' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'turner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'type foundry wharehouse' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'uhrmager' (lang: da)<br />HISCO: 84222, Description: Watch and Clock Assembler or Repairer","Input: 'uhrmager mand' (lang: da)<br />HISCO: 84222, Description: Watch and Clock Assembler or Repairer","Input: 'underclothing pinafore maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'upholster cabinent maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'upholstor' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'vagnmakare' (lang: se)<br />HISCO: 81925, Description: Cartwright","Input: 'valve maker pneu tyre' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'washb fecto' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'watch and clock makers' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch jobbers apprentice' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch piveter' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch polisher' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch repairer worker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch trade finishing stoning' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watchmaker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watchmaker employing 1 man' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'weigh machine man and shopkeep' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'weigher at hafod copper works' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'welder' (lang: en)<br />HISCO: 87210, Description: Welder, General","Input: 'wheelwright' (lang: en)<br />HISCO: 81925, Description: Cartwright","Input: 'white smith' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'whitesmith' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'wireman' (lang: en)<br />HISCO: 85700, Description: Electric Linemen and Cable Jointers","Input: 'wk pottery' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'wood carver' (lang: en)<br />HISCO: 81945, Description: Wood Carver","Input: 'wood prepairer' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'wood presser and bundlers' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'wood turner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'woolen manufacturer employing' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'workes in furniture factory' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'working tool maker striker' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'works arsenal' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'works in bent wd fact' (lang: en)<br />HISCO: 81290, Description: Other WoodworkingMachine Operators","Input: 'works in clock repairing shop' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'works in clock shiop' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'works in shade factory roller' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'zilversmid' (lang: nl)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'zinc worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith"],"mode":"markers","marker":{"color":"rgba(215,191,158,1)","opacity":0.69999999999999996,"line":{"color":"rgba(215,191,158,1)"}},"type":"scatter3d","name":"8","textfont":{"color":"rgba(215,191,158,1)"},"error_y":{"color":"rgba(215,191,158,1)"},"error_x":{"color":"rgba(215,191,158,1)"},"line":{"color":"rgba(215,191,158,1)"},"frame":null},{"x":[54.770025081697597,85.333034268640745,-31.636937081439662,54.710909303372311,-3.129289932702239,-48.887211413889858,-45.741951841031195,-30.651251683426995,-9.5529986311499187,-18.263154211312838,-32.227352864814087,34.185050864642164,6.7372447553092512,6.625534010028634,-16.088815661471486,-6.16396763139314,-49.640684384091074,61.930080793902711,77.321207618242042,79.102571130961735,75.444843121076545,9.7241309189494363,-13.970338613809664,-16.948232564273631,23.562860448662434,32.409187475142645,-24.298309656862696,50.385928100786693,-38.022579396146746,100.07617300708479,-9.4610031877305669,-7.0570623994280526,-1.0335315783666204,47.828799105054209,-55.822679869700146,7.3154104818061816,-33.911619249760903,-4.9407546676762886,38.861114063390531,-29.568861441194468,-54.536630422702743,49.691556772561938,-71.150900898914074,-0.21526524558722107,14.71289204016278,31.075692393923138,5.4376626684268201,2.5114895639342509,5.1166206668112233,-56.157299229622382,11.934664277356692,-53.543774936098743,7.2502596519590172,21.786430392334765,24.567201141810809,71.868822525575354,0.75362605014920059,-30.18273592844945,-46.289117701385237,78.204230220265657,-34.976878132898364,46.131840100840691,5.4925144028495607,32.355482368165205,-33.032344444493837,82.435598189981377,29.696659246818982,40.885507768901761,17.972207252642502,-31.086383013773474,22.522538580779525,23.906872590072837,101.10903773776495,73.942634243290215,-38.608601621925338,-20.745319413844236,-14.061147150875358,-20.510272786195294,-43.830470775610273,-12.474104522145259,-16.944230798449446,-62.206357390695125,46.371782505985003,1.8093252905327155,8.9325246737454833,-19.319955922963601,45.696946415954379,36.547405949242588,-14.849515921384755,77.299504375411331,88.585245155447382,51.16303680372792,75.574963425828571,12.71115760725648,2.9585798801635259,-25.872719561644466,73.620822953292546,103.02601332864222,-49.787035639200283,3.5663658169126808,57.933455840719105,-58.673577934698045,4.4444774878443276,-43.846587197005654,-53.903238524864648,-14.672811154868695,16.933918965255405,2.0997635582807184,14.246630584943864,2.6559764716465333,-64.613439365778845,-55.392468598709151,-13.116314647821882,-86.178270201483713,-63.702076705436447,11.594198693549115,-33.617560308376092,-19.163306491002452,8.3458688634220763,32.497118977392908,-67.005877973392259,26.759115297663641,-4.065459405973904,5.6877498141650618,-41.206449097912859,-4.1181292133632406,-13.014187668313994,-6.9163503967215778,-39.034889106638502,63.494747975908901,24.991375049889385,5.9919983797297407,-8.016672564351115,26.233156061381315,40.570677711295609,-51.374181869050709,16.030450213562819,-10.44065515885751,48.324899042931257,18.093513628425292,92.976555121959024,18.148605535710374,-71.310080996716835,102.94455090875088,3.75719826642713,63.137892554462667,-0.62043133880254953,-18.928873326055523,33.903089161234014,-59.403053470220435,-28.141574348442315,-47.097211307479604,-61.019741179172101,-7.9974949119363554,-29.690213793970983,47.506088921187448,-30.595781476875857,-58.30597276329172,35.711159774668481,55.051875735576424,-68.985924484007171,1.837152313664181,-42.156510559044285,21.751612275827966,-38.389092418600853,50.492001303953145,18.250683261557079,47.193184287709308,48.289853032813291,-46.407566757237497,-65.196605245328243,-69.499095397964851,36.145294662635131,24.3076207819059,25.227550258135572,22.91300225510517,53.486247230854303,7.1410277402045139,-27.158440123795735,28.889812024860859,48.552716036592734,-48.655538241679444,-42.485636178232866,-45.893997278925283,51.541460868910356,50.455772933815673,45.524804157840173,69.351596033789846,13.801896910462753,-31.907090477354615,-31.179173797565245,-27.109627371156208,71.29011151048887,23.30026637524551,2.424970734143272,-46.243772969084361,108.46338474543793,-46.831321266191395,-18.263497072182368,-60.217153861299238,51.205314620207353,1.8833350965507849,-50.822344837205456,-9.2643157343761526,52.234103445812487,38.705832997370784,-40.88067055824709,-71.441505346583511,-49.851398446440356,89.621458586809339,-49.289808876221805,22.744572068243581,-24.080090967765905,29.641162274912784,-0.62595266487603118,-70.653416880011235,75.492925724573894,22.877465473843309,-18.186065633098682,11.855399199847586,-11.659978985229507,98.8519535964368,4.6872622473638428,-90.320087650291867,-16.585610651272045,32.556996659658083,-38.296048959236636,-3.7693799003325252,17.332379704525717,-53.711624729036558,-23.285008300861158,-45.301627615721664,-9.6938183611443183,2.1868883008271403,-77.665224441098985,-22.358879859362052,-52.620382192164065,-47.874573463381203,-58.720168706644905,0.99687707594524733,82.685053478311673,-5.9161673728045461,9.129271082109927,9.4378936744985023,3.0679514389406424,-7.7057948326741412,30.878410511160673,16.523331631141126,-34.880680382369903,-34.494852400542534,1.190158786715291,11.906247590327293,-21.404848517647665,-28.121895847171817,12.751967600449337,-34.590948431462373,-20.461254402076641,-1.0368479440735567,-37.124358678379615,-79.364189600092232,8.782419066886872,55.491904787499394,17.539595741521754,-19.334276372974021,49.073638629324705,-37.964687304798353,65.109265540963534,-50.719547200948874,8.3809881024331112,-46.165040618516372,-52.205168694289014,-49.991680748971838,-44.315717672799877,-58.08338053098953,62.510325691986822,37.823004624850675,14.987781743186595,-48.928121952310221,123.70826060204155,-43.713489667346444,-20.817191521412514,105.21246373222996,90.822778570080686,-2.5478184248997482,-20.680405907288339,91.510685626061829,-59.395499937588639,12.032255249304125,-2.3850838957900877,83.120459665435931,82.002571668649495,-73.28476581645117,76.984197018137124,80.335352270919259,55.005965568910547,-29.983193050058198,25.44387336796019,-55.747705110623109,29.649739808752635,10.162872618424034,-44.700405260164558,-51.118212879194225,-0.66820987230592421,-44.028745611709567,-11.59197071682155,-25.159186130670047,-17.907364838005829,-9.6042657538611227,42.400809407590003,50.885180810313713,30.604750834175132,51.295771802179615,-51.22826341584971,-32.309393998208257,-78.819219009845298,-41.769479084394341,-45.248756468567869,52.279084437573388,83.529823241669675,82.333700840600144,87.061942322799553,19.339553601655489,83.511064755923542,12.12350897353339,23.896562971447555,-11.828804817561233,-70.037128714098998,-71.32926255571104,-1.3438881645591554,90.331978883869567,-48.863890562718737,-16.753380480798697,86.41972663120518,-35.024351365241181,-53.92724490096851,-74.750658653931438,78.759637410688072,56.726091168837343,-51.807124026553126,-42.709465478179467,-34.880368085076661,7.7961318497636665,78.66851181890739,32.835176802320781,-75.716563838847918,90.118535875027547,28.973244052609292,15.097739243094109,27.80934569534201,-79.766249380753834,24.255166676171587,-21.142195523900075,-17.67955572622596,-7.101372679537957,8.079924042853019,-53.349364870737716,-8.7069641406239722,-40.412797914089381,11.915883369078038,-39.666035001027126,-70.517371957667805,36.526164088777648,45.732858113672798,107.29110583385918,-32.591199284677053,5.2913549322698046,-2.1447078237033277,-51.041387728730605,-71.00870896808496,-17.896049693941489,-36.755896620443195,11.132605524327603,106.0398810344271,44.812173476747368,-37.404007346889109,10.721852379835457,-41.726501616870401,-43.620044376613905,-51.644478358211522,-46.83179451778075,-34.550494732497988,-36.857816784446904,-5.8072927251021031,-6.721547182223734,37.44838737796772,53.440859625517724,-34.546405332159424,-44.818142323629942,25.221278971673268,-33.124633166242681,-30.755696576592744,3.5163926920856041,-48.330248394735662,-18.632879965452279,-50.966828712938401,-40.003687491639496,-38.767797253031056,-64.99175731528436,-73.564891555725509,43.668527656076598,-15.934442221210874,64.178945561900434,82.66315182847238,-27.975727600142758,-33.484799197831158,-20.393664990494567,-13.16974464289056,-19.255880516017736,20.381983845271055,-9.3354749602336717,-33.685556572335443,-9.4153451434389765,-5.7099935735204506,19.415627413045623,1.9079677190962929,61.627088973319204,86.575632859205015,61.220524203528072,-13.712638407187846,49.634744268215854,11.121815700671835,50.566733007869054,45.411579883399433,-21.668090248687594,-20.875888765395423,-28.663396222486931,48.73296038444073,-23.117447243514032,-18.337818076133736,28.856631983417387,-25.022044168246506,-26.732734457624716,107.9403739603222,-7.0392352031607199,56.886551438947031,96.310740093457198,32.062423495956473,3.6092227767274321,87.819692862714874,-30.946609879640164,-45.900236906490072,-48.75820807129044,-51.932488696957385,-46.955870693887782,27.865979800684077,-14.581764118914071,-13.716542882185729,-89.506190538472069,-16.708979765539439,100.72307397837035,-60.960014363971666,-57.911392993275022,-9.9976115782536699,-63.599221063165096,-64.773004021037337,-21.713484880801598,83.794494108049591,103.14261908266347,1.7747687661870239,-54.880981911607392,31.931722719437488,40.97761064259408,47.162987597370744,32.507234817603788,34.636181467985821,90.78043348449971,93.072278766772854,0.0070208660915719702,9.5028164858132822,-56.170804916448837,82.777683058536155,51.069242427219422,87.548559725806157,65.422616544506454,-57.615377031372667,45.043314610539177,41.268077726612567,24.857310103725098,55.744985780533924,14.470107693407899,85.11831370708363,-54.199577215493022,97.503892914487039,87.565339950606557,-42.592123009240609,-3.2062815983001753,-54.746334505499235,-30.03057155331711,54.883542751513929,66.311809276203931,-32.13432510968039,43.815797907782255,41.574081405012677,-39.952965244194964,-11.333373643173021,47.169744408639957,-79.049030917202728,56.690007220317945,58.537558275113142,8.9757433535638356,42.627799135919282,-35.42678534687105,44.78391972123574,14.134743747248523,-62.206225966438204,87.398879709260498,18.508624437153156,-46.549658715514191,-80.667095789433972,43.21272851312068,41.144586877056867,4.154716836724015,75.791778967644632,-9.72112465895996,7.9498012155076152,81.16760422212532,-12.063917344096078,59.449404717704731,3.7214609760655675,55.075480641032811,-1.1345574537579188,-70.470712260686426,62.173804564597972,-66.716257597971193,19.714514293809106,-64.913589604577581,-18.614933990377381,-45.087613401911582,-49.002737647934154,-40.689879538801925,61.971418740296862,-53.99305441458884,43.86828504733667,-51.617209414298664,37.201453886937024,-48.523174939865314,64.529649165422114,-47.190093045063165,11.633421130829543,48.007795046560098,13.878678595080766,66.031778822593893,47.913260084923166,18.68704361893835,-34.014928999921942,-38.501285566964839,-55.774874196467337,48.390416239333923,-39.853137456479764,-27.160139570499599,25.646440205626114,-66.80617014461167,39.10635331678025,-4.0695373478551531,-15.633444917791866,-16.853536262200723,-26.624941028253804,-51.402944143734928,-78.92536018990468,57.66463845474771],"y":[66.478129182579906,76.732301424301212,16.751015672567291,117.96836732914551,-169.40147022567359,31.288073351401103,8.2041988418719249,100.11117220848205,-124.32915960877867,-84.209360549418506,49.863241716684506,-86.844984015763487,-147.60675936473623,-150.67515430873712,-72.004821495439543,-232.67879293867026,-194.9851484835263,32.261093278310462,81.234712353256739,61.075197760203906,23.472798520943993,-225.30370351776801,-181.51578450694129,160.22053224626839,23.468144326143214,1.1592929076189742,148.84967655060626,170.1585948162319,142.00654014005281,126.75482517360177,-214.22357205378736,-0.33899277299668068,-99.649990077258693,-80.33658776808376,-14.911570494192041,-110.12030620432712,75.091498585956018,-163.81140781831846,-77.890679966381882,-162.6710398191278,109.08570909820564,71.33118666735929,46.06746355369809,90.671630531448145,103.22653213551182,-24.301338708737148,-177.13947829114687,33.639693014631355,4.9721984968597743,-54.381420562528128,-76.327949946086036,-54.154262794676669,7.259844664033599,-24.961166222153611,147.2659198304172,109.85662668114922,19.125145823901665,-202.96980108707012,-188.16624284225281,49.25960362834288,-190.99158827641381,138.71171526074505,-120.96397175259339,70.270485917649694,85.822388252846892,74.526051786137145,-23.808783395063944,62.580063492411774,62.83281075455934,-93.552924894707118,20.294910843441826,20.649245044056233,101.97524608970986,95.502268187847591,35.950970304197973,23.851119190502722,126.58960507629634,-100.7583172523542,-125.03334021000612,153.60015194271304,-121.97289167485225,-53.831342182863906,31.316076311544723,-35.266166183551917,-90.952462650584749,110.44827224321317,71.646888961712122,144.96876138254999,92.119950106209558,93.785289002894757,131.03424713202332,-82.002300734785351,89.606440374335108,96.2560027253556,123.14762619325936,119.11344544702941,76.874449400188283,99.797268812140629,88.174349490490499,-55.546180351289173,64.36803353418199,-70.495637675727664,10.083477489509258,44.666640682293881,-64.896422782001977,80.697641166672923,98.538467741052315,72.07159100456677,86.356179378288289,72.644872683024317,55.023343883658406,-40.229544217418614,28.779071463922612,14.510309003909049,59.125676575335888,26.343137060354984,133.85396472191914,118.08205459807866,13.32466708703118,-54.805581768254129,46.212146729243152,-16.164467120465833,-37.485181586978648,-27.442091912716084,31.905314247012019,76.239560655205452,-6.9418687894277564,11.033756700172392,-89.526361675720764,70.657150994280045,104.95046533280689,60.591342508334726,-211.44403041316312,104.00743239064474,115.2488748380168,-74.973798061627392,112.98329356436824,151.4661855253847,66.207676051991072,40.651624798815824,68.129493657164119,-145.55005076537662,54.740816573087329,120.15830963064342,21.985696858086065,81.117323578368683,-114.90469334074079,27.336949805626521,66.290458950162304,105.9250653346372,-159.48566934288311,-44.046369080053339,68.995651359319666,-130.61950804663996,9.3122776846579036,1.384806109647839,140.27559231719303,57.681637495415174,113.75154287993635,160.44123845605696,60.688067414072194,23.818170578966622,39.74195617166982,-167.99947391407989,-26.867033775908187,144.97479837294901,101.43517821887622,96.620884192694902,58.151759708813451,-71.747119247006054,35.679913101783072,46.594989533542893,87.597211869449453,-62.883032466977816,-64.727283073637494,-58.27522461606263,120.99860791295976,100.84403640904988,-82.160569621073392,85.551917409640794,-7.0142036985142804,93.222189440054066,32.5283369777856,-52.827217180526773,142.72114015076102,143.23298834543314,142.7575895456277,50.743356297331729,84.005793394382906,-76.730122418573529,138.68145845570297,142.11389099374591,74.440042873849663,120.46420530835982,75.388041130499488,44.596126136370479,96.098199868810354,-42.065271725822278,-76.380125868883781,-34.868614304877049,123.0179940625336,-55.869328295103251,33.15089843537924,-0.062885606472289357,124.63987788449116,75.59241182087176,5.6448924049872646,24.424714642758556,41.741934577290031,92.258429815858051,124.83035476627326,-11.006711423147781,122.39309085895117,145.17661996626015,-174.40752083700167,18.599131203481146,84.018800831722302,148.76121628364504,116.88443435875911,-46.707330720729246,-155.22913371829983,109.57174583074706,-7.2479651823000921,41.988775964670289,-88.16221128828839,-25.570115251358523,-198.37434073651593,-160.04969311641221,-30.553165268638914,52.851469318730047,-6.1360254507147749,87.846067636052979,-58.852581471197247,-20.764342576568481,-92.121211525934967,-103.01747272079024,-196.0799917638497,-191.93672151114393,-44.400903099168602,-102.61298857619167,79.593804394171414,-162.03957253934053,59.447246416273956,57.570116686889129,-89.389157345494226,-221.7119402069018,146.04716301664968,-223.21046481207236,-94.7093163639952,-76.853089650044467,-97.522166184276259,-226.71839292555561,-30.965679721748728,90.784606806192286,-223.91191070325124,7.2931873347554346,-147.10890141471401,-93.813844448637468,-171.26700026351847,-50.754634693681702,-14.789613555141235,138.38813302041888,-83.6354890572171,41.622504171104978,-2.1212629964445533,-197.45675627127511,73.874609830423125,-96.798586511868592,-98.799341442483765,-178.39232794775168,-168.70434098530035,-185.50166647851736,68.059193269431148,55.808078172090681,67.587223227122735,96.558705082676255,-12.019856826927542,135.44307182022754,80.877533578147762,-84.426375979424847,99.381703719003127,97.816545089421467,65.717943040886595,-2.7267982733694054,-38.357387209212831,63.829916862878079,0.66824260976924221,72.713018672636224,-4.4947243113311002,145.91690819416746,147.19531624813567,-69.843951366329392,78.582352006724648,87.163221630416487,36.003785903873876,125.26743711562001,-60.025532903137616,-67.924878330211826,-79.225523902109359,-211.82322309528683,-58.304943815604773,-30.77211618997174,-7.1544259736579896,-68.221961367810039,-59.339047296676007,-83.917495244530571,-226.96153373815829,150.63742725694951,87.115657715196704,121.45514699839271,99.644096951982903,60.124713826519276,-128.31101911836387,135.40991357578355,53.178331420530775,31.746060076239242,48.232847806055773,109.79926772202379,58.488017357067825,62.235229342125415,119.18005490837996,-109.03376719216003,123.34474489642578,73.053880397566559,-13.226403051390362,54.674757744432888,-46.379562053760324,29.919570913923693,-2.9229182922236734,44.625505468303565,8.4694983206576637,42.941628890092936,66.268588816362467,86.006391164803816,-183.04106250442067,49.541546830508366,99.940154542387276,115.64348433904149,-187.02229864715173,-194.4243717759235,-106.78348962596769,-173.05241705330656,130.60211515168788,27.359457689133471,53.416865211066352,82.063913559633733,-7.6564725366653352,-117.83653497345115,-144.56746435858904,33.288185201599539,132.32663890466563,95.101498051075694,-16.807614320743024,-117.21887627696204,128.69083137364166,42.088491775108643,-103.94090716327685,-28.741218047005809,98.689168283470181,-107.54840639890122,-39.0081185419102,115.28145145451279,-86.585330159109532,68.050580426802824,19.577564783339234,-88.915063843755576,-142.21650734134928,-130.13273107035914,28.193899494827583,22.29183228066784,12.626929640882452,-60.875415690502138,107.59604440563133,34.892827512412083,36.703559461724041,23.294720078693587,-194.71272902925529,-21.61023707633527,68.701556436655494,72.309104202843926,-9.9069993580105695,120.32339250413197,141.68288357547792,114.16820222752611,21.538227753005309,111.70276146295302,66.452580153219031,-178.94923764343318,119.59814960303171,35.074882010121051,-27.147577244578137,88.499804789010994,37.862411989081508,17.388312568070578,-108.0431343176631,114.47043539343549,-109.81043143043786,-65.111928889354814,-33.583221574772452,141.3525349490277,109.57179591471235,116.12992375904456,60.727505778286343,-96.634847176246922,-27.894038050184157,16.321067932719675,-4.9633868099888092,-99.213255563255316,1.4904082027459387,-156.37362964479482,-60.691367258644426,12.087185035353775,-110.8337520574688,-19.997883218236925,-125.64567738558156,114.66160139460456,119.82125451727116,-77.005362816487803,89.985798370732425,103.6462718175415,26.799807974508663,100.13311573619927,83.361873070325331,91.417745696355198,-108.67999146781622,38.216927200672266,79.256021250266116,-208.24944607492705,-170.27903135022237,-146.90431948064193,-115.07103518724647,149.0277466414731,95.887312747034542,-165.96132164614951,175.52938944350061,129.12071298978304,30.071630799335303,-118.85244098485259,137.9494108605723,-111.96526449731597,49.19689826513418,-199.90959529840467,-200.27891011367944,-185.19576788789422,22.217777413527457,-226.12066778043544,-210.59359668144251,32.004219385071465,-225.33292875360453,109.75449983284464,-18.785502675677446,21.386196717434593,50.249810054127387,66.781282909125963,-73.384300947092882,102.73351844307912,94.934531659123081,66.962937095373874,-125.5695956365302,-41.208267772810579,110.49193001718487,161.77763017969326,-24.036325011221638,96.980494423202913,-110.91859490921452,128.88278049962025,87.305597256984569,155.84889155459143,131.66576852784013,-194.54017300329787,44.101727067285708,106.54830828455584,123.91995074772935,76.01094268858823,40.143620705258762,-90.646487282082816,86.634994777190357,85.871350964952569,-72.489076357472555,39.629782303955345,96.910011781610152,-194.88950128951603,103.42814953606049,99.226191837960187,121.6100944135016,-25.858294294174268,12.717693415428313,8.5240807085652133,152.56022217084654,100.98620793613198,126.52078170913849,93.967429057689884,137.52904737337698,133.77710272001707,-96.042255837186545,39.970140117039492,23.253648593178941,154.77557693734428,154.24031557975249,-109.81599563946979,129.21290646923447,78.110886269949276,95.345610841680141,114.700999476745,55.648678011413828,97.162998973686371,-146.1865507711652,-198.0830944307904,-73.111720282578204,-25.458042303379621,156.64125262014227,35.462489131171317,107.25106081433869,-228.17370894585298,104.64393605892847,57.732209029277598,-86.539938271354899,97.204919916261318,80.55409762042818,124.6362108003289,116.33649806575058,-50.732688515783877,65.081873846909843,-16.817310715672178,-7.1634278462102232,77.943776002440444,-210.09380440306856,-195.58693245777124,-197.59719955889105,-43.199702904165875,70.341063607194016,-183.67222252175529,4.2004985395751264,-200.07183102851147,-61.805401762705621,-190.78426448389482,-74.487072756514124,-200.1767265318642,-49.285733918570862,104.518803906961,52.30226019484877,73.638728914588583,33.183647498559381,-9.8476328630780952,-105.74330115823527,130.81354952529233,67.306740253534926,27.846851818497068,-27.838707912962676,-204.40444283377789,131.71951591648721,-91.984143037064825,83.883266088386009,93.191428718449529,-7.5811783294673276,12.677351656708312,-101.77005978307754,-39.831478900067026,-62.79663025808027,80.859103791230126],"z":[18.925572877877201,-12.725648010810367,74.388715507021047,-19.986267981829787,-40.72299909337535,47.378079618562502,47.945843085089514,36.807683632986986,-31.133707652187855,68.281550713069691,118.86906529350125,77.717343889011218,-38.802429235399927,-38.970539418029333,13.329066627242701,1.177222770975352,57.192451336317909,-28.028791793368136,-113.58674033431909,-112.15095303965242,-40.343766313776371,7.0384308321335771,-0.5340187209039402,28.171783706692242,-45.172883594617495,-76.128646351410026,9.4911291428845637,-5.0149550910044267,4.0274759207794535,-1.9685691133080114,-8.8352485802376588,-3.7454503085277633,-34.096780672730155,32.88582620063184,19.071933192571741,12.129680155227231,-20.116470471122245,13.921955679584654,-51.434519760976535,0.93550919388160814,6.3220976303263079,-93.907410043366639,64.520233544244363,-22.90248538569082,-44.631131044089358,4.0269540779218964,-3.2112161384051299,-36.076098132489527,-33.409739093549788,89.106699299569385,-46.392632644353611,52.762728415018756,-26.120761297896234,5.5269178469532942,-17.15209645274086,-31.058722775141703,67.71171481490579,6.0365443620783941,22.764538857509137,-126.34704655833997,39.454373247042355,-17.644365034616101,-2.3977000751093702,-41.74081877616144,97.462163385583182,-44.695728677748626,-23.57971101280631,-58.352475647995043,-31.744945211159106,61.46487713695938,88.54646301146721,87.021487072809037,-17.936410956012768,-112.29810126617184,66.710518965909301,69.986747473004826,-26.736069851497586,-17.108456648721514,-14.025782619065449,-28.871664482512287,53.466110348454635,34.670532092746271,-54.954246523213989,-36.197804931014453,-32.948663317095992,23.708598897811243,-56.881692369096349,-14.687254818394134,-16.07876230840046,-40.054335944597746,-8.3819615170386417,-18.999602144252428,-43.443494588601084,-14.73847334074393,17.154563573448744,34.834028800728561,-35.24239801101902,-28.763047414878404,33.137743808093759,-53.118942150866843,-87.143422644714065,23.654835799035769,48.99257711733371,-16.057830331444279,62.06277494586616,51.741553081243737,-28.605078647214185,-40.824787070723183,-34.466734502852759,-2.8087973302266032,-21.176655461944328,57.706933463151998,-12.35277644192087,-21.577583915970671,-19.568988801061508,-48.927881245071468,1.2013249925733378,-17.381727334603493,7.0329646306474665,-25.814082034623183,97.641694825292404,-72.624191082541685,27.591217657144533,-41.246567365554604,73.568059110180371,76.100017198958071,97.284309485078182,-50.350715017973641,-24.892680201027829,-103.72737117899882,50.09712760978055,76.554768412022398,6.4839529915328589,50.626898609407789,-104.24604527611798,35.520793463899516,47.895383218123435,-33.842067261859469,-127.33481286622811,-43.518759007102304,-121.46453060167892,-21.772559534614984,108.5900390768233,-24.838010141610141,103.16607018281063,-5.5611985627363767,4.5327941045104589,-7.946510563891259,-69.380709565288825,10.107928421978309,-5.1017336941536335,-39.00820804161588,85.027903482510169,-6.3422811405041113,95.329537249178316,18.584941856508866,21.223016509223179,6.6082156548954876,-20.454341979844273,-11.905494775289752,-12.04440303162472,102.96076119788439,110.70559801969051,8.7386092506191844,103.53460510609975,6.1301183273130588,-34.843347073816837,19.389173521981892,-41.7376360402749,-0.96586146467831724,-14.086326228405397,100.23671179394518,-34.076360852330154,-51.657904913734122,-52.121806826722121,-49.644859066429355,-83.029486623178585,-34.251055273290646,81.823865219195056,-24.539818351227584,-66.73641623371249,34.149518246902538,56.963223270992302,-31.679680997703276,11.016548834355948,8.9505510510131394,-3.1276357690653378,-102.76614817370815,2.5455813602935411,12.878332585769643,2.6860129920805353,1.4361019971205564,-33.780759727751253,-30.881322053217154,-9.3247709691327074,111.2768875371528,-39.021432522714576,-40.464754698648605,51.969059309357512,22.751749683681538,-73.529575287127116,-43.350951461253871,108.2438106895313,3.3825822725342736,-1.6132712637782636,-49.759658272948386,48.823501515160558,58.539560480497805,109.74420562505993,-59.215058807251175,-3.4425929043876922,61.53771148594933,22.827489305840661,-17.55094898775975,9.4466040896657866,55.708130162911367,-111.07998964323788,-10.267557944249852,-32.286789061558245,-43.778322811392719,-51.35397399378229,-36.782123146618765,5.8828667660323539,14.535638148824683,22.860589097797863,5.9432084451596117,44.832160242359585,13.055476588821682,-17.648892325650905,64.920105326335062,25.052206483290146,73.736940212803205,-8.2454751702687865,-49.125816105026402,-5.9973654631102473,-12.03193756484017,16.841306981577628,54.911625335765606,96.549547032143295,-0.078645346146888603,-7.8126967113489636,-49.99775986988876,76.042475323376948,75.964965606383231,45.363092122019388,10.389312052750224,-65.361556643230145,11.144802215635538,66.144526319381583,18.659258039924893,48.565494207899377,8.6824657902494948,-2.8498407318290897,28.044407219894119,16.634760065750086,93.865866495177485,36.258197413500568,46.882202698484434,56.208700090807703,32.728767559484396,-27.171212419851365,-9.9430788635057556,-11.914033910910215,63.514436644467281,6.0708918221053665,42.41726984526624,-105.6324848153386,-30.052361367865846,40.236902314369402,7.3687194076537166,6.8810191186532927,54.04089458454748,81.257281006499994,62.858643358048077,-97.931686389611698,-38.265170394514598,63.063076731516205,-2.0602861865479087,-12.253325804305833,-36.737857132657872,-16.536174910213429,-29.878428367413434,-73.11425725800018,-12.880653855735943,-6.583286213922614,-73.030249548845504,35.171802789621026,-22.387069858326072,-15.651331467315396,-38.826025314833892,-39.137531553572671,4.2783540737105366,-48.060606633731751,-111.30336163299529,-57.74216671698921,-15.051724423613861,28.687883993024158,25.490134860706018,-39.629329923001642,-3.1030982614407692,38.263955510259919,-1.0424654712239134,-18.290241290935317,-5.7182283414506312,-12.121774279154673,50.839638393308967,-1.3913084316805542,-35.080884382282626,-68.833791860255573,-68.694540802979617,22.123963140726119,-30.677616643612662,-14.52872568518846,19.363182862841121,57.215941780782885,49.793965273511979,-19.694860700600241,-111.21878060488973,-124.23461756745833,-124.68030588456973,-2.352015979956124,-40.660140511227837,6.4088964004754043,-24.796162385201612,35.605657644814407,6.6594992604361298,81.426270583837834,96.022368889935649,30.674774142256602,-127.7183353082989,82.101602062781083,62.972692858266861,-114.41272985093507,99.675004137987372,34.177128025125405,108.24826981049681,-49.084473227189442,-20.254935063659239,46.710164239548696,9.4589565175653192,10.298778386465292,1.4840771386934217,0.94613659285047613,29.151403499898734,57.084736793495985,-131.66119059403803,9.458140705624448,-41.976299400127566,-42.940632230085463,41.374571496901176,-25.703352877026081,48.288800405681066,38.126489502771726,41.452871189767372,-5.769732175128147,119.33742736576956,57.489709195859085,99.215317269008978,-12.102652279380322,4.9243435415214671,44.159506330667,-30.933658357779002,35.184984778403631,-29.945469957227484,70.398958310088659,7.9943595341169393,-2.8259065235565513,-10.486243953137111,96.190043452267773,25.357914315302303,64.915133828916382,-51.616817288487006,-29.526938514196104,-50.795339472719022,55.373992717094943,-49.740161748525509,47.661214182821958,94.81801981380552,1.210122493840055,46.609358615008354,5.1829573810736571,-27.904798663940099,17.071355515801748,0.077589912901840724,-20.036344267260461,-6.1414211549184392,-31.789509121449154,28.967365978672245,-34.553667452055699,60.703607776405981,77.621634262434966,-35.532640825802595,117.12892936088689,-25.544276470604373,15.507876122008202,60.562309700847031,-1.8880329254226049,32.807787949309983,21.532991753686659,-7.3521718179954441,41.144658892485857,-41.63607376136769,-95.887483064827137,63.200639324085436,99.194754085147324,0.30830774335268274,99.915843328582895,62.651102147677214,-50.635789412232889,-8.9011013308313469,-10.123247317656512,45.358963859564291,3.9621110199959126,-26.846188566519089,-30.400656977227801,-41.496889172853564,4.1829297818835256,-11.986522418309974,80.576986365201051,-21.632669834227332,-20.661498412203308,-23.51888192769847,-24.210747241561521,81.067383985943778,65.011127196876274,93.078540529229002,-20.829904710407394,8.5353516214019738,-10.149812334155946,-45.210637821429394,63.844890295041317,12.38128123029959,-16.795428102298338,13.995541486828015,-1.3066167497779715,-16.577502229701082,-48.793863669574577,-2.8097396178921152,-3.4648384253921862,-27.971647138832246,118.80649388614894,20.113413542063856,18.38575563423996,39.973062354038319,-55.368548970968227,2.4965651750144713,3.6610805796048336,34.527811822236096,1.9121040890104457,-42.010998350256997,101.59969275456652,-8.3098484935191586,76.839921988643013,-25.488918786843151,-9.3736643163986599,-18.820183567926868,-42.320531625797955,-27.879960304539711,38.309158198949149,93.498357979559756,-18.023188167123777,-6.1604526236022448,-1.5131564185437532,18.690758454252723,2.2411782104776838,2.0323022813522864,-10.020849122258488,11.67675104148373,-35.181408580655962,26.573769984565494,-122.94779996092959,-78.125497577290687,-26.376431806822048,-82.976743719780202,123.88761930267576,39.619299013443658,21.656982144411231,15.219973221737673,-31.941963724664458,-38.875108012570799,-42.779853009166175,58.849158173226805,-9.8412208931800702,-132.01436322293753,-25.687337421127474,20.04882418667264,18.113997025393484,99.233102649915494,-7.0583559524213477,-14.30941016855625,-24.419682041780753,-59.372435042954059,13.858715903911696,-15.648675683695116,41.231503492692731,-53.513714441478228,36.587048181292595,-8.2987222737801076,-9.2807395217776332,19.205625143847705,-13.932676186430582,67.820020711916072,-6.1422110177351934,36.023206263156958,4.2379165125391145,-59.171815655616086,-38.149432200436351,27.162641758287986,13.762824922740531,-3.6615530740408659,-25.552136404734195,-39.228852324131715,-111.63745134114019,-2.0870257551344102,-71.412787649847246,-122.13527115954442,38.965182902761661,-26.627200512529008,-17.883119422600966,0.34938319378551291,-23.091449360612128,92.079185726810763,-100.39724205618386,-1.6047601647663357,35.917255321840301,96.48184548995421,1.9781458240824186,26.17091285684462,36.341963421667508,97.35883800615143,-92.933918126077714,22.279448457206026,-38.121478690988475,49.68639282532493,-53.388534928663589,20.238637242491738,-17.048172396959806,56.501596808574156,51.450289075165266,-124.43040920932307,7.1137407592814563,-121.74070720828375,-60.346397077301447,35.577030624171471,16.280797840825013,29.113476100658826,101.8550111881234,3.697347395481716,96.415385154273665,0.32612429257221004,-62.296785789560708,8.2370965256760265,-17.887045518873713,-13.799441872060832,46.292417888132007,-23.808654424797062,28.40118217171942,-6.884023512600856,-32.164808806692029,-7.3608661272662177],"text":["Input: 'ab seaman' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'address printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'aereated water vanman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'afinador' (lang: ca)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'aftaegtsmand vejmand' (lang: da)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural laborer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ancien ouvrier et aide' (lang: fr)<br />HISCO: 99930, Description: Factory Worker","Input: 'apprentice printer feeder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'arbeider en not mentioned in source' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeider i gaarden deres aegte born' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidskarl' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand husfader' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand husfader deres dottre' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeijder en not mentioned in source' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdende par' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejderske' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand husejer' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand indsidder' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand logerende' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetare' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetaredotter' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetarehustru' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeterska' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetskarl' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'army cap maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'artisan' (lang: en)<br />HISCO: 95920, Description: Building Maintenance Man","Input: 'assist in dining rooms' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assist with dressmaking' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assistant in coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'assistant varman in business o' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in business as carri' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in the fried fish sh' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in yell business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assists in business t s' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'attends to the horses' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'automatic machnine operator' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'baadforer' (lang: da)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'backstuguhjon' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'backstugusittare' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'ballie girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'bargeman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'barmaid help in business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'barn niels nielsen somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'basket maker' (lang: en)<br />HISCO: 94220, Description: Basket Maker","Input: 'basket maker' (lang: unk)<br />HISCO: 94220, Description: Basket Maker","Input: 'basket maker sub manager' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'belt mkr rubber works' (lang: unk)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'bioscope operator co' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'blank tray maker master' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'boarder journeyman' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'boat loader' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'boatman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'boatman (deceased)' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'boeckbinder en not mentioned in source' (lang: nl)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'boekdrukker en not mentioned in source' (lang: nl)<br />HISCO: 92110, Description: Printer, General","Input: 'bogbindersvend' (lang: da)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'bokbindarelaerling' (lang: se)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'book binder' (lang: en)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'boot fitter factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'boot porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'borstelmaker' (lang: nl)<br />HISCO: 94230, Description: Brush Maker (Hand)","Input: 'bottler' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'brakeman' (lang: unk)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brakeman m e r' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brakes man' (lang: unk)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brass casters warehouse woman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'brewers drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'brewers dreyman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'bricklayer' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'bricksetter' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'bronzing at printing works' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'brunnenbauer' (lang: ge)<br />HISCO: 95955, Description: Well Digger","Input: 'brush boxer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush drwing hand' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush maker boarder' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush mastud' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush trade out of work' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brushmaker bour' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'builder' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builder (dec)' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builder architect' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builders labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cabinet porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'cabman' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'calico printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'car-man' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carman at mill' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'carpenter' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter (decd)' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter - deceased' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter and joiner' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carrier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carter' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'casual worker and pauper' (lang: en)<br />HISCO: 99920, Description: DayLabourer","Input: 'cement labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cement worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'chargeur de voitures' (lang: fr)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'chemical worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'clay tobbacco piper maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'clerk mineral water manufactor' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'co co motor engine driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'coa minder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'coach man' (lang: unk)<br />HISCO: 98530, Description: Taxi Driver","Input: 'coach owner' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coachman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coachman (dead)' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coal haulier for houses' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'coal seller and carter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'coal trimmer shipping porter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'coast guard' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'coke burner' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'comb maker polisher' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'coml clerk printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'commissionare porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'compositor' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'conducteur de messageries' (lang: fr)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'conijositer printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'copper plate printer app' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'copper printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'corporation labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cotton operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'cotton warehouse' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'couch liner seater' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'craine driver frodingham' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'dagkarl' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleier almissenydende' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleierafskediget soldat fra westindienhendes barn' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer husbond' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer inderste' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleyer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleyer barn' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagloenare' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglonner' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagsverkskarl' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'dealer in horses and haulier g' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'deceased labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deceased plate layer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deceased seaman' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'decorator house ship' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'demolition worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deres barn i laere' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'deres born do somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'deres son dagleier i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'deres son seiler' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'device maker for watermarking' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'disse personer ernaerer sig ved forskellige arbejder' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'dock board scavanger' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock hobbler trimming coals' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock labour stevedore' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock labr ston stower' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'driver' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'driver a.s.c.' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'driver draymen general' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'driver hired vehicles' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'driver of omnibus coach nd' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'droskaegare och handelslaegenhetsaegare' (lang: se)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'dyer's labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'eating driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'eldare' (lang: se)<br />HISCO: 96930, Description: Boiler Fireman","Input: 'embraiderer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'employed in the receiver print' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'engaged in berlin and fancy bu' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'engaged in classical general' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'engine driver' (lang: en)<br />HISCO: 98320, Description: Railway Engine Driver","Input: 'engine tender' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engine tenter' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engine-driver' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engraver' (lang: en)<br />HISCO: 92400, Description: Printing Engraver, Specialisation Unknown (except PhotoEngraver)","Input: 'estate worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ex railway porter pensioner' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'excavator' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'expressarbetare' (lang: se)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'fabricant de jochs de cartas' (lang: ca)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'factory hand firework factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory handboots shoe stamped' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory knitting' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'factory realer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'fan turner' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'farm labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farm servant' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farm worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farming man' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'fencemaker' (lang: en)<br />HISCO: 95990, Description: Other Construction Workers","Input: 'fireman' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'fireman new dock' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'fireman railroad engineer' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'flaxter' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'flower market porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'fobber in the factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'formerly a cheesemonger porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'formerly cash girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'funiture business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'furniture remdon and coal cart' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'gaar i dagleie hans kone' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'gas stoker' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'gatekeeper' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'gearer dock labourer' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'general labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'general worker (retired)' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'gerkman' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'gill boxes minder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'glass slopper maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'glass worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'glazier' (lang: en)<br />HISCO: 95720, Description: Building Glazier","Input: 'goods department grocer porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'greacer in coal hashery' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'grrvarb' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'hammer man dock' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'handyman decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'hans larsens kone' (lang: da)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'haulier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'haulier and smallholder' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'hauliers horse driver' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'hendes son somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'hitcher coalmine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'hoornbreker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'horse driver wag wks' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'hose pipe machine rubber hand' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'hosiery hand labourer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'house decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house decorator employ absen' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house maid visiting house' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house painter 5 man 5 boys' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house rents and funds' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'huijstimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'huistimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'huistimmermansgezel en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'hurrior in coal pit' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'husbandman' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'husfader arbejdsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'husfader dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader huslejer daglejer i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader inderste dagleier i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader indsidder dagleier i agerbruget husfader indsidder dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'huslig arbejde' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'husmoder fabriksarbejderske' (lang: da)<br />HISCO: 99930, Description: Factory Worker","Input: 'in table knife warehouse' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'inclineman coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'inderste og arbeidsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'inderste og maler' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'india rubber factory operative' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'inds og dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder daglejer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder daglejer i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidderske daglejerske' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsider dagleier i agerbruget indsider dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'inrolleret matros hendes born' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'jobbing printer apprentice' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'joiner' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'journeyman' (lang: unk)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'journeyman house painter pap' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'junr porter railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'kaartenmaker en not mentioned in source' (lang: nl)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'kammenmaker' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'karmansknegt' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'kiln fireman (deceased)' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'knecht veer en not mentioned in source' (lang: nl)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'knopemaker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'koorndrager en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'kopparkoerare' (lang: se)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'korbmacherbursche' (lang: de)<br />HISCO: 94220, Description: Basket Maker","Input: 'korendrager' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'kronoarbetskarl' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'kruier en not mentioned in source' (lang: nl)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'kudsk' (lang: da)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'lab' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lab about coal pitts' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'label puncher painters' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'laborer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer ( dec )' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer (deceased)' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer ?' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer and parish clerk' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer deceased' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer, deceased' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labr' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labr.' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'laere draenge tieniste folk' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laeredreng' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laeredrenge' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laerling' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'lamp lighter' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lantaarnbediende' (lang: nl)<br />HISCO: 99910, Description: Labourer","Input: 'lasher on coal mine u g' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'laundrymans porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'leerling drukker bij een stadsdrukkerij' (lang: nl)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press machine minister' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press machine printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'letter press printer compr ap' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letterpres painter machine min' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'lever af sin jordplet og dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'lichterman en not mentioned in source' (lang: nl)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'lichtm kd' (lang: nl)<br />HISCO: 98140, Description: Ordinary Seaman","Input: 'lime burner' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lithographic printer' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'loader at railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'lorry driver' (lang: en)<br />HISCO: 98555, Description: Lorry and Van Driver (Local or LongDistance Transport)","Input: 'lucifer match packer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'm factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'maalaregesaell' (lang: se)<br />HISCO: 93120, Description: Building Painter","Input: 'machine labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'machines printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'malerm adolph' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'malermester' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'malersvend' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'mariner' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'maskinarbejder' (lang: da)<br />HISCO: 99930, Description: Factory Worker","Input: 'mason' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'mason's labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'master bricklayer' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'master bricksetter' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'master painter employg 1 boy' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'master printer employing 2 boy' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'matroos zm linieschip de zeeuw' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'matros' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'matros 3 division 5 compagnie logerer' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'maufacturing operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'metal button closer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'metselaar' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'metselaer en not mentioned in source' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'metselaergesel en not mentioned in source' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'miller' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'millwright' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'modderman en not mentioned in source' (lang: nl)<br />HISCO: 97435, Description: Dredge Operator","Input: 'molenmaker en not mentioned in source' (lang: nl)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'moter can driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'motor driver chauffer and mech' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'motorman' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'munition worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'muraremaestare' (lang: se)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'murer' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'murermester husbond' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'muurermester' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'muurmester' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'naaldenmaker' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'navvy' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'needle maker' (lang: en)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'needle maker 4 men employs' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'net repairer and other fisherm' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'ofensetzer' (lang: ge)<br />HISCO: 95130, Description: Firebrick Layer","Input: 'opperman en not mentioned in source' (lang: nl)<br />HISCO: 99910, Description: Labourer","Input: 'oppertimmerman fregat de rhijn' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'opticians warehouse girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'out porter ry station' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'outside porter rly stn' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'over cooker coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'packer' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'packer en not mentioned in source' (lang: nl)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and glazier' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and house papering' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter at machine manufacturi' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter master employing 1 man' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter musician' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter paperhanger c' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'pan with rubber works' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'paper' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'paperworks' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'parcel vanman to ry co carter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'parkvakt' (lang: se)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'paruijkmaker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'patent picklt fork warehouse g' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'patterncalico printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'pawnbrokers warehouse man' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'pier head gateman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'plane server' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'plasterer' (lang: en)<br />HISCO: 95510, Description: Plasterer, General","Input: 'plate engraver' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'plate-layer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'platelayer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'poem girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'pontman en not mentioned in source' (lang: nl)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'porter' (lang: en)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'porter cavent garden' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter goods railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter mill' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter railway agent carriers' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter rl wy' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter st bartholomews hos' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter to painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'porter upper arcade' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter wollen marehouse' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter woolen trimming wareh' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'postilion' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'preventative service' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'printer' (lang: unk)<br />HISCO: 92110, Description: Printer, General","Input: 'printer books seller' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and bookbinder of scho' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and publisher employin' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and stationary' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer canvasser' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer checker' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer evans and adlards' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer plasterer stone mas' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'printer proofreader' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printers' assistant' (lang: en)<br />HISCO: 92990, Description: Other Printers and Related Workers","Input: 'public carrier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'publieke werken' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'r. n' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'r.n.' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'railwa signalman' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway coys shunter' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'railway engine driver' (lang: en)<br />HISCO: 98320, Description: Railway Engine Driver","Input: 'railway guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'railway porter' (lang: en)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'railway shunter horse driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'railway shunter l and s w r' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway signaler' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway work porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'rapieceuse et bacheliere' (lang: fr)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'refreshment contractors porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'removal estimater' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'road labourer and house proprietor' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'road mender' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'roadman' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ry porter hadley station' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'safe maker' (lang: en)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'sailor' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'sailor r.n.' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'sailors home porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'sasool girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'sawyers labourn house burder p' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'schaalmeester bij de spooorwegen' (lang: nl)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'scheepstimmergesel en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheepstimmergezel en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheepstimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheeptimknecht' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheeptimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'schuijtevoerdr en not mentioned in source' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'schuitenvoerder' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'schuitenvoerder en not mentioned in source' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'seaman' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'seinhuiswachter bij de ns' (lang: nl)<br />HISCO: 98430, Description: Railway Signaller","Input: 'sewer india rubr works' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'sheet metal work manufacturer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'shell stamping' (lang: en)<br />HISCO: 94920, Description: Taxidermist","Input: 'shell turner arsl' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'ships carpenter' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'shipwright' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'shipwt' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'shunter in goods yarder' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'shunter royal alleret dk' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman g n rly' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman l and y' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman l y railway' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman landnwry' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signature' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signwriter' (lang: en)<br />HISCO: 93950, Description: Sign Painter","Input: 'silk printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'sjoeman' (lang: se)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'sjouwer en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'skibsbygger' (lang: da)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'skilled labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'slater' (lang: en)<br />HISCO: 95320, Description: Slate and Tile Roofer","Input: 'sleeper' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'sleeper en not mentioned in source' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'sleper en not mentioned in source' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'snickare' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickareaenka' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickaredotter' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickaregesaell' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snijder' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'snijdersgezel en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'soeen' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'spade moulder' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'starw plait importer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'steel heater plate mills' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'sterroty pen' (lang: en)<br />HISCO: 92300, Description: Stereotypers and Electrotypers","Input: 'stevedore' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'stoker' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'stone cutter' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'stone mason' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'storeman' (lang: en)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'straw bont maker' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'superld dock gate man' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'switchman' (lang: unk)<br />HISCO: 98440, Description: Railway Shunter","Input: 'syndicus bij de ommelanden' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'teamer' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'teamman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'teglverksejer' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'tendeur' (lang: fr)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'text factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'thatcher' (lang: en)<br />HISCO: 95360, Description: Roof Thatcher","Input: 'theatrical operator' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'threader on embroidery m achin' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'tile packer' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'timmerkarl' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'timmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tin vanisher maker' (lang: en)<br />HISCO: 94190, Description: Other Musical Instrument Makers and Tuners","Input: 'tinned food labeller' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'tjenestekarl' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'tobbaco soiiner' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'tommermand' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tommermand ved holmen mand' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tommersvend' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tomrersvend' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tractian engin driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'tractor driver' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'tradesman' (lang: en)<br />HISCO: 95920, Description: Building Maintenance Man","Input: 'train guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'truck checker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'turfdrager en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'typograf' (lang: se)<br />HISCO: 92110, Description: Printer, General","Input: 'tyrefitter in motor cab trade' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'unimployed factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'vaerentgesel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'vaerentgeselle en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendgesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendgeselle en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendghesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensgezel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensgezel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensman' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensman en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentgesel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentgesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentman' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentman en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'vattenledningsarbetare' (lang: se)<br />HISCO: 96940, Description: PumpingStation Operator","Input: 'veimand' (lang: da)<br />HISCO: 99910, Description: Labourer","Input: 'violin string maker journeyman' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'vognmand' (lang: da)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'waggoner' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'warehouse woman factors' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'warehouse woman iron money' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'warehouseman' (lang: en)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'warehouseman general' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'waterman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'waterproof van cover and sheet' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'waterscheepsman en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'wharf ringer' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'wisselaers en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'wisslwachter' (lang: nl)<br />HISCO: 98430, Description: Railway Signaller","Input: 'withey stripping' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'wool porter grocer' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'work for grain dealer' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'worker assistant business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'works as a patentmaker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'works in globe mnfg' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'workstraw' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers"],"mode":"markers","marker":{"color":"rgba(179,179,179,1)","opacity":0.69999999999999996,"line":{"color":"rgba(179,179,179,1)"}},"type":"scatter3d","name":"9","textfont":{"color":"rgba(179,179,179,1)"},"error_y":{"color":"rgba(179,179,179,1)"},"error_x":{"color":"rgba(179,179,179,1)"},"line":{"color":"rgba(179,179,179,1)"},"frame":null}],"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.20000000000000001,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> ] ] .panel[.panel-name[Finetuned CANINE] <div class="plotly html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-bce0b22af06856928250" style="width:504px;height:360px;"></div> <script type="application/json" data-for="htmlwidget-bce0b22af06856928250">{"x":{"visdat":{"216810f27c64":["function () ","plotlyVisDat"]},"cur_data":"216810f27c64","attrs":{"216810f27c64":{"x":{},"y":{},"z":{},"text":{},"mode":"markers","marker":{"opacity":0.69999999999999996},"color":{},"alpha_stroke":1,"sizes":[10,100],"spans":[1,20]}},"layout":{"width":500,"height":400,"margin":{"b":40,"l":60,"t":25,"r":10},"title":"Embedding space (t-sne)<br><sup>CANINE finetuned (w. lang)<\/sup>","autosize":false,"scene":{"xaxis":{"title":"V1"},"yaxis":{"title":"V2"},"zaxis":{"title":"V3"}},"hovermode":"closest","showlegend":true},"source":"A","config":{"modeBarButtonsToAdd":["hoverclosest","hovercompare"],"showSendToCloud":false},"data":[{"x":[131.37123229276054,122.29300717184303,150.17710079676152,150.53204514320421,142.14622914363878,124.86714825737228,149.94295446623877,151.22741619352797,147.70901096592885,123.71376319738474,126.99204459350635,144.30522878183314,134.01258384988756,132.1329660512676,145.9491217662798,146.59818261944091,147.47595519605508,142.02890156961803,146.05328684003618,123.08022391883695,143.71771920982596,137.7681664455593,132.45172773391263,128.84668141874639,135.54614093499791,119.67599262507893,143.89808810140693,145.85748266140794,140.80518863801078,138.60265580118337,123.38988394245895,142.33969781872469,139.32325631921412,130.76049188094194,134.89016861454925,149.92382354869432,144.02640516420334,144.20184287734611,146.44209304079183,138.76765749637818,146.86032981846918,151.93449890197141,149.43765010173618,145.82208829320999,133.11421068801511,137.49841760430891,146.87402721596447,141.53325606398906,150.22854674438656,120.38483327989886,139.97563849069394,134.59509061410427,136.21209307630286,154.67908085691474,140.87157235293481,130.24013820993702,119.3257610049578,118.81076485313291,146.32189227206737,133.00649046918295,122.82350094746954,93.589219471491461,120.84603618678645,140.70650133711902,136.87828858187478,117.50274048644179,40.845241658996571,135.70739342608849,143.38436100678808,140.88837314823135,139.13459590483217,137.58761120117759,142.18919709605294,140.03254110826776,144.44111607866103,144.71927888475545,134.63936077487651,121.84605156814649,143.45808870412552,123.67170793068918,151.73445383956297,121.40780035207257,150.27229301340941,135.90184499399217,140.17802811219187,137.72925344672836,136.4698300126083,120.34041397931659,128.41615689867308,153.82187428657292,146.39047670386614,153.18600679348782,132.38314729016111,139.71162846923025,120.09628005192985,142.65608905166994,141.88757455920839,138.46977809509528,120.86128967569043,133.83537421032443,129.98697502123096,149.23018406660961,131.19337018384786,142.62418172833407,130.02910224332774,144.9758735234708,143.05426788837747,149.93052155068412,149.10082963383769,139.25070451674145,147.53602180795698,133.30517518814318,144.13436119845673,138.34255838356475,145.1033239835723,145.03742950453045,145.95154386123266,146.00480371558427,147.18176320913088,152.32022294397458,132.63287033341098,123.10241379763401,127.09514998211861,131.12071236685378,127.88847498422368,124.93870671390175,117.47663095711319,149.78881302922846,149.37307530575077,152.57648708700387,150.78161893502465,142.33900184797272,145.42139531240088,40.832071997270354,25.330761256434656,125.95557369561331,133.19233148439523,129.11221518337385,150.18229261448909,37.518276428291152,147.05258586537764,120.60628121116847,131.01881012939566,146.85930136289301,123.56689348231244,137.91243113634056,147.39264511206162,129.6652936396043,154.11400675201676,123.54353680139094,109.92484639547511,109.70050330023655,110.25775877824044,151.9253026382884,151.54913649915059,141.82366893614255,138.08662537217293,141.91922036611487,143.78415266913356,126.07427322294429,139.97311549045338,148.21405709207684,143.9102321869193,147.54475183633997,148.01868119101536,145.45091900317496,149.43634170573171,147.60093447847518,122.49885398901765,93.81678219168289,126.41288524560414,127.86427970801283,121.6133111072666,122.74859650793296,155.54124956250348,155.41686093325237,39.431646677762245,130.22311994855181,108.44950102451902],"y":[-111.26608899414639,-107.5058632516168,-130.40487514922199,-129.63511601162656,-129.45036429768095,-118.29749900765907,-130.58005662089909,-129.59414392343018,-130.93853714528097,-117.43300946836439,-118.89002124266771,-129.41587052926258,-131.49549290627479,-111.7701749897256,-138.06180995064707,-135.42267911678218,-135.10680031385013,-132.43838154004564,-130.31175352985116,-108.44951519947757,-142.48829839997867,-132.80601535573962,-131.21002969060922,-128.96355177898863,-134.59214270526985,-106.91013514679932,-140.83796744439397,-140.04490461824335,-139.18058191083625,-131.14207398520762,-122.54848059231401,-140.70893462149789,-138.33795575966724,-129.37238932585157,-133.64854789764965,-130.19167357471648,-138.39618060038748,-142.80016777973847,-140.16462703120126,-137.87319292952279,-136.44645501655029,-127.46471975363526,-130.67807936918612,-135.46343335005116,-127.13927593400456,-135.50177977787519,-130.58721779547139,-124.79470815030143,-129.56664601802396,-107.93792134258844,-142.19574903260067,-125.37925653340828,-129.82948075240313,-127.49655088740558,-135.1697775930231,-111.77452422721946,-108.69008737183253,-107.73381372081955,-129.84566582227021,-127.68219463509068,-112.67004520730084,-23.637998542470662,-108.13095074926686,-127.49580487943435,-123.2099256744625,-112.1505237135146,-92.176060904854481,-123.6779450712508,-139.18035695319435,-138.3096490016994,-129.579646396436,-137.52869130628105,-139.37452076413271,-136.30578218431549,-139.34366815455508,-140.43637781523236,-130.489322681326,-120.7141159212227,-132.41347152975629,-121.50773687985729,-137.83334313580212,-118.62420089836701,-127.49163128946651,-127.93831162861629,-137.86684557677984,-129.37305675440456,-135.83785138679929,-119.3622769679116,-127.09384578078735,-131.44509407427839,-126.78313768719346,-130.92089769525307,-125.36420313690166,-123.65085555887777,-112.2840003646197,-125.36749651964978,-124.68524764773487,-127.0091120415602,-115.69924492336258,-123.60698413486473,-124.49353796829458,-131.23680724818914,-127.08437087400208,-131.63151472728578,-122.18888841459007,-129.52976718938984,-130.30820413087801,-140.59638422195397,-140.02835573849958,-126.24396937358128,-131.68689914626646,-123.16204924841388,-141.86029490734478,-140.50768443185382,-133.35360068008515,-136.57812049020487,-143.17468243493212,-133.61357965516135,-128.09065574891201,-128.60902202358801,-126.89072730165321,-114.81863899219138,-122.15028432267978,-122.10084932979295,-123.92753214283015,-115.09324023469239,-106.57728980797029,-137.88451838407559,-126.39055151372062,-135.23536240943258,-135.2459871428122,-143.09845587848145,-132.6667936321272,-91.865071013826039,-14.424750194612749,-120.0112056732324,-123.66670067352111,-121.97835051121828,-128.35615489154819,-86.337064383025961,-140.88742140166892,-106.41153266271252,-110.07588624694775,-131.72655836754595,-108.59369261432232,-139.42865362283339,-136.81441721008088,-118.22200859829194,-130.7937507127761,-120.56765370204796,-23.39621998282006,-23.698229443112584,-24.340177197915899,-126.64447211097816,-136.18975422584353,-134.26976112727289,-138.04105636118516,-135.72212387168011,-135.709445784781,-121.28813072025964,-138.93648362863746,-140.73067553862811,-137.58518260955009,-130.8809325775033,-138.19294563849382,-140.03598152165009,-144.71400718920404,-134.80507159814445,-109.46113607980706,-23.612984007794275,-123.86360987163948,-120.98285052702788,-107.75457128778551,-118.47593082399129,-130.15044350923725,-129.37450394340115,-89.309209014122388,-106.83451052663837,-24.481141331101568],"z":[87.010358503365367,75.777889730451307,98.774714416888656,100.93796423840205,95.949273333156526,78.331790199763788,94.945739500082141,93.968879783012298,95.06021101289241,76.114816191049655,79.943735355841397,93.731919591018908,88.976540299860559,88.214623909387853,110.18225850037533,98.889661026336455,99.739977338701891,96.812517978887598,100.83257415269757,79.134805361345073,101.58510453340253,92.253722560788873,86.096519902210318,82.947120733958073,90.892627366772061,73.499536962479041,107.34892707796094,107.4651073175899,103.56822246709766,93.70368716384931,79.70408564212066,105.69723353446633,95.111352170862148,84.740040454427003,89.221401682645151,108.20280279074808,105.31969634823113,107.72068207972798,105.67953428279732,105.00235776352112,104.7400991890137,94.336004593833962,109.84579089129575,109.82101684426874,89.417106803401623,94.265789881814811,109.31481316426783,94.824208785179295,105.65811096512795,69.206391391600988,97.697420763129728,90.196824051578133,93.295398063007781,95.842668317666281,103.48397374722116,85.306248107191308,72.12227049762113,71.484193614964539,96.840803519049587,86.670177319946276,74.461144781597937,-28.299218020146654,73.830359900824035,93.847651857851631,84.837772819409651,71.726463467478595,11.329203098043935,87.595178628870229,98.49450075024329,105.14615868280158,93.84604017605561,95.299484879675362,96.510002499470446,92.517989204833796,96.929621512447568,98.183623132185346,86.215913216194025,75.315044707221162,88.554372534825916,75.956874582337107,100.17017500355303,76.00827574013077,109.84026602534998,87.92544079176534,102.63884349698122,92.189864281458469,92.577149854637781,73.881709967899894,83.864881580508012,95.13159488938112,95.013788651315124,111.20839889265024,81.604137498153236,84.603722465677166,72.799489067141437,88.666174277532789,88.860316888152227,88.132989857031021,73.719885609915167,82.289159295802065,83.136269961184183,88.076552103729654,81.729976221323113,89.121173493363614,78.642687704052875,87.96024672255534,87.591131175723618,97.920186571289619,98.80366445915179,91.577247596448927,89.144895325526406,88.1352818866158,105.25981003013334,104.36745224083529,102.40485821140962,100.7808789608353,105.59620689652702,103.61220813443859,97.604751903149392,111.65058696473756,83.844911197241942,74.852989707458875,79.120637190818812,80.036472039047197,79.336358299866959,76.476463037328458,71.674866356007186,104.7116607510243,111.10555176705425,108.23862277362151,107.4816459544229,97.641722737082219,96.641941427034297,10.862773361490801,-97.188628982224799,80.873111911580708,90.983049874012067,84.416397216297995,112.10121625244776,-4.726617669096715,95.810883740066203,75.170469771327731,86.425544188299568,97.64325190977533,80.14702162958929,97.048583862628703,106.95045316474628,81.921826238315703,96.877305244052891,78.000145176182443,-25.189940737267385,-26.042819766396558,-25.460803156242509,110.4976390158611,100.50186760703947,102.78740947830384,90.649460267564109,101.52482715404315,104.4750021171758,76.91683573415898,92.895167869223144,107.06491590307252,108.67574627560735,111.99614795560697,103.08677271123372,102.4271684283682,106.52966304833538,104.33710591255826,72.95224803953937,-28.213424615822895,80.688602676905944,82.383676098705735,72.406018281430846,74.256778627660253,108.06036871219163,107.49045417635092,-10.558163813285564,85.154791931538995,-25.0596663422243],"text":["Input: '1 d af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aegare' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'af 1ste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'af 1te aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'af sidste egteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegts enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsfolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtskone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'aftaegtsmand paa gaarden' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'alle under fattigvaesnet forsorg' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'almisselemmer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'baren' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af 3 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'barn af deres aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'bauknecht' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'cursant' (lang: ca)<br />HISCO: -1, Description: Missing, no title","Input: 'datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter af 2 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter af sidste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datter datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'datterdatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'demoiselle' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'deren kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deren kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn af 1ste aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres barn tvilling' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres born' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres pleiedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres plejedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'deres son' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen frau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dessen tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dienstbote' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do deres barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do deres datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'do kom pat' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'dreng' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ehefrau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ekstra tolv mand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'en datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'enkefrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'enkens barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'esquire' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'et pleiebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fanger' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattig' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'fattighjon' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'fattiglem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattiglemmer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'fattigvaesenet' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'foersvarsloes' (lang: se)<br />HISCO: -2, Description: Source explicitly states that the person does not work","Input: 'friherre' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'gaardmands enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'gaardmandsenke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'gentleman' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'gesaell' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'gift med husstandsoverhoved' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hands kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans barn af 1 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans hustrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans koene' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone anders jensen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone husmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans kone jens nielsen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans moder logerende' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans son' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hans stedbarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes barn af 2 aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datter avlet uden aegteskab' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hendes datterdatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hospitalslem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hufnerin' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader aftaegtsmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader gaardejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader gaardmand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader huseier' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader husejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfader og husejer' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaderens datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaderens fader' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husfaders barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder hans hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder hans kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoder og hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'husmoderens moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hustru' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'hustrue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'huusmands enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'huusmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'i kost' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihr tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre kiinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ihre tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ikke udfyldt' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inderste' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inderste og aftaegtskone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidder og almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidderske' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsidderske og almisselem' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'indsider' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'inhysesdotter' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'inste' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'koene' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'konen' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'konens mor' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'laerling' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'leerling zeevaartschool' (lang: nl)<br />HISCO: -1, Description: Missing, no title","Input: 'lemmer paa fattiggaarden' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'lever af sin formue' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'lever af sine midler' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'logerende' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'logerende student i theologien' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'madmoder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'mamsell' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'mand' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'mandens moder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'marques' (lang: ca)<br />HISCO: -1, Description: Missing, no title","Input: 'min datter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'min kone' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'none' (lang: en)<br />HISCO: -1, Description: Missing, no title","Input: 'not mentioned in source' (lang: nl)<br />HISCO: -1, Description: Missing, no title","Input: 'nyder almisse indsidder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'overleden maastricht 25091812' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'overleden maastricht 29081800' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'overlmaasbracht 24091870' (lang: nl)<br />HISCO: -3, Description: Non work related title","Input: 'pension' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pflegekind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleiebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleiedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'pleje barn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejebarn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejebarn fra opfostringshuset' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'plejedatter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein kind' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein sohn' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'sein vater' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine ehefrau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine frau' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine kinder' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seine tochter' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'seminarist' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'sense ofici' (lang: ca)<br />HISCO: -2, Description: Source explicitly states that the person does not work","Input: 'stakkels husdreng' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'straffefange' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'studerande' (lang: se)<br />HISCO: -1, Description: Missing, no title","Input: 'tidligere enke' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'tienestefolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'tjenestefolk' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'ved reg braende artilleriregiment' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'NA' (lang: da)<br />HISCO: -1, Description: Missing, no title","Input: 'NA' (lang: nl)<br />HISCO: -3, Description: Non work related title"],"mode":"markers","marker":{"color":"rgba(102,194,165,1)","opacity":0.69999999999999996,"line":{"color":"rgba(102,194,165,1)"}},"type":"scatter3d","name":"-1","textfont":{"color":"rgba(102,194,165,1)"},"error_y":{"color":"rgba(102,194,165,1)"},"error_x":{"color":"rgba(102,194,165,1)"},"line":{"color":"rgba(102,194,165,1)"},"frame":null},{"x":[45.707923153039765,59.872133154770651,60.137731819423912,59.027886804317248,59.609584301265571,88.149646785154843,89.420371053762636,69.810554934302715,19.342648558570424,19.438592513172146,43.674600776895986,-14.331229959285347,89.620049912092369,24.149782082373278,13.63106409601477,14.7462211080709,24.233372707927867,91.681956986085325,91.136263371330998,81.978985827074538,92.325637457875004,-51.715523221535157,14.192254055889084,13.953970948562642,37.568474266421653,-9.7289864826406376,74.495062936817774,87.927110168002827,43.71810832771942,35.819032578595213,15.147199061127793,15.262262989825897,74.204855658051116,43.269839997396183,-12.457937647563275,43.141880751381969,77.127613049155556,56.154579024362441,93.693148772790565,77.183528238975157,11.445048330734911,12.089252278760329,33.686823485909301,11.564651459928422,93.965890184100161,83.034962199448088,81.999166787223103,93.376390330365837,27.196567706960625,45.853401010234073,-12.016307581864631,87.622260807720821,86.367291807963184,88.867132189125755,87.559916096654234,87.605831245124051,45.608767785551983,-27.697547969053794,92.503947536017222,35.366960593655108,-81.314655143794241,49.660260018736025,41.51320528697449,75.600880118021365,65.220243555915118,64.058961953694237,56.399880854564842,73.873048613955248,55.417034140115923,54.456234220412973,55.302289824541582,55.098286166976763,-13.477708759125557,59.782210255718866,-13.406958369823485,47.432054801174161,95.053830654777855,94.00772286052451,43.398463806008522,-113.26602896932926,34.43647130497785,27.080325222224111,-13.138240759736423,75.458820097140674],"y":[52.454921350206511,-14.315399622266039,-14.01810619690337,-14.400444284126804,-12.762542037552999,44.141367770350236,44.823425601340404,-48.100121970438032,-32.607393501608364,-32.771610350281257,52.558123155119972,102.68387699944088,43.520336752924614,-30.975796440967148,6.6845739380758005,5.3231772006969189,-30.788064906640621,-29.026572419211139,-30.303303846458427,-29.413592855895558,-31.006563249302808,73.587862356282116,-2.5304843000442281,-3.1377071320683458,-83.302967267314685,-77.569184332335823,39.680337494290754,44.434623085241071,55.318166313898764,-100.58001670564724,3.30597938899699,3.3863328835631381,38.471117085322014,57.918849781280038,104.07283197604301,56.599095606515178,38.922742282105467,-28.75503277130548,-30.280371679386398,38.551125634842926,14.142003840635679,13.536637738560248,-11.05278735696767,13.251150594987431,-30.671494781676422,-29.425992538141202,-29.233709440269898,-32.362271061982923,-13.578011999497376,53.886736219247247,104.73243159976148,41.611838469098288,43.192853502538497,44.595033444077501,42.498631888695897,42.489416773943816,55.483101505314146,22.748513921637787,-30.833702191359301,-10.73620256142288,32.49406876013456,55.816230985893561,52.47346603875414,40.147727709327192,29.762852518501852,29.641975101291568,-30.723195018591927,37.816205813249191,-30.890725435751861,-30.863999548909462,-31.717826366327081,-33.050349370439882,102.32968293844026,69.239163446628396,101.35620052816559,-57.845197039954861,-32.015504269117336,-31.786805468785168,54.259007812871921,30.186911945172529,-10.910194095425517,-13.507364130751332,102.97442776479117,39.541732720969151],"z":[-3.0950809956371836,60.957913038580848,59.970092255681351,60.777542717613713,60.38324473375831,-43.483384823271187,-46.083883557044402,-53.853746341091366,31.468707583905907,31.647884428764595,-2.2022981117721434,25.137371134533268,-47.031147409962443,51.943554405583733,38.277642799132607,38.425068904353594,52.321859796119845,66.658091469146513,66.637287398657705,66.637348566079751,65.184016164318649,0.20622239513996368,44.60565945376068,45.012417993596017,-6.4844419300074092,78.171188459375941,-68.467833380189248,-46.145511361554469,-3.1166409867260652,-28.229135106950462,34.60560687918327,35.042726335755134,-68.925615130292314,1.1536496698169332,24.648285919923623,0.22890508429124107,-64.453655795804863,21.449114467945822,63.974125865028654,-65.714476121076004,40.37009424926277,40.832408137286663,46.724416775234246,40.092249333850731,65.851283706795797,66.924501493051352,67.353035458711958,65.631277303637575,-52.386544852047152,-3.8233252315713941,24.061025512483138,-47.790972238891321,-47.449230835947986,-47.827427816352909,-49.180292641237578,-46.550172620147585,-1.8093243878072234,66.71345974573191,67.123668856378941,46.555858420218783,32.164833967023405,-5.3607406633149095,-0.085271988217684211,-69.080620205311874,25.560749684452702,25.225288464556524,16.702275627555654,-64.718870347470869,17.672410611637318,16.286490708688294,16.488064612681772,17.307773072349725,23.820664471975832,54.477004875729968,23.403066179664968,32.012016640288167,65.30855467853597,63.902351789844928,-1.1452916359960621,58.35572403776127,46.650528378197023,-52.357793210378844,25.751791768177831,-65.387008096409147],"text":["Input: 'accountant surveyor' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'apoteker' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apoteker assessor pharm' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apotheker' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'apotheker o' (lang: nl)<br />HISCO: 06710, Description: Pharmacist","Input: 'asst nurse workhouse infimary' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'attendant nurse to old lady' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'barnmorska' (lang: se)<br />HISCO: 07310, Description: Professional Midwife","Input: 'binnenlandsvaarder' (lang: nl)<br />HISCO: 04220, Description: Ship's Master (Inland Waterways)","Input: 'binnenlandsvaarder en not mentioned in source' (lang: nl)<br />HISCO: 04220, Description: Ship's Master (Inland Waterways)","Input: 'building surveyor 36' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'captain steam ferry' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'certificated fraternity nurse' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'chirurgijn en not mentioned in source' (lang: nl)<br />HISCO: 06110, Description: General Surgeon","Input: 'civil engineer' (lang: en)<br />HISCO: 02200, Description: Civil Engineers","Input: 'construkteur o' (lang: nl)<br />HISCO: 02220, Description: Building Construction Engineer","Input: 'cursan cirugia' (lang: ca)<br />HISCO: 06110, Description: General Surgeon","Input: 'docter' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'doctor' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'doctor medicinae en not mentioned in source' (lang: nl)<br />HISCO: 06105, Description: General Physician","Input: 'doctor of medicine' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'draughtsman' (lang: en)<br />HISCO: 03110, Description: Draughtsman, General","Input: 'electrical engineer' (lang: en)<br />HISCO: 02305, Description: Electrical Engineer, General","Input: 'electrician' (lang: en)<br />HISCO: 02305, Description: Electrical Engineer, General","Input: 'enke efter en lojtnant toftenberg' (lang: da)<br />HISCO: 06710, Description: Pharmacist","Input: 'guimich' (lang: ca)<br />HISCO: 01110, Description: Chemist, General","Input: 'gwaithy helper' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'head nurse to lunatics' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'i p inc from land divd c' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'inderste gangkone ved kirken' (lang: da)<br />HISCO: 07210, Description: Auxiliary Nurse","Input: 'ingenieur en retraite' (lang: fr)<br />HISCO: 02000, Description: Engineer, Specialisation Unknown","Input: 'ingenioer' (lang: da)<br />HISCO: 02000, Description: Engineer, Specialisation Unknown","Input: 'ironer wash maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'kommissionslantmaetare' (lang: se)<br />HISCO: 03020, Description: Land Surveyor","Input: 'labourer on river alt' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'land surveyors' (lang: en)<br />HISCO: 03020, Description: Land Surveyor","Input: 'laundary maid domestic' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'lods' (lang: da)<br />HISCO: 04240, Description: Ship Pilot","Input: 'm d and surgeon' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'maid domestic servt' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'maintenance engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'marine engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'master mariner' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'mechanical engineer' (lang: en)<br />HISCO: 02410, Description: Mechanical Engineer, General","Input: 'medical practicioner' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'medicina doctor' (lang: ca)<br />HISCO: 06105, Description: General Physician","Input: 'medicinae doctor en not mentioned in source' (lang: nl)<br />HISCO: 06105, Description: General Physician","Input: 'medicine kandidat' (lang: se)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'mestre manescal' (lang: ca)<br />HISCO: 06510, Description: Veterinarian, General","Input: 'mine surveyor local methodist' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'nightman at canal' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'nurse and housewife' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse hos nurse' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse male at present represen' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse midwifety' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'nurse to imbeciles' (lang: en)<br />HISCO: 07110, Description: Professional Nurse, General","Input: 'occupied of land' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'optician' (lang: en)<br />HISCO: 07530, Description: Dispensing Optician","Input: 'physician' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'pilot' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'pirotecnic' (lang: ca)<br />HISCO: 03610, Description: Chemical Engineering Technical, General","Input: 'pupil assistant metallingist' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'quantities surveyor' (lang: en)<br />HISCO: 03010, Description: Surveyor, General","Input: 'rasurer' (lang: ca)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'retired civil servant' (lang: en)<br />HISCO: 02210, Description: Civil Engineer, General","Input: 'retired civil service' (lang: en)<br />HISCO: 02210, Description: Civil Engineer, General","Input: 'schiffscapitain' (lang: da)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'seuller maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'sjoekapten' (lang: se)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'skeppare' (lang: se)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'skipper' (lang: da)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'smalschipper en not mentioned in source' (lang: nl)<br />HISCO: 04217, Description: Ship's Master (Sea or Inland Waterways)","Input: 'steam tugs fireman' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'stenorgrapher' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers","Input: 'stoker on ste tug harb dock' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'styrmand' (lang: da)<br />HISCO: 04230, Description: Ship's Navigating Officer","Input: 'surgeon' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'surgeon and physician' (lang: en)<br />HISCO: 06100, Description: Medical Doctor, Specialisation Unknown","Input: 'surveyor' (lang: unk)<br />HISCO: 03010, Description: Surveyor, General","Input: 'tester' (lang: en)<br />HISCO: 01400, Description: Physical Science Technician, Specialisation Unknown","Input: 'trinity pilot' (lang: en)<br />HISCO: 04215, Description: Ship's Master (Sea)","Input: 'veterinary surgeon' (lang: en)<br />HISCO: 06510, Description: Veterinarian, General","Input: 'wharf labourer riverside' (lang: en)<br />HISCO: 04290, Description: Other Ships' Deck Officers and Pilots","Input: 'wom maid' (lang: en)<br />HISCO: 07990, Description: Other Medical, Dental, Veterinary and Related Workers"],"mode":"markers","marker":{"color":"rgba(219,161,118,1)","opacity":0.69999999999999996,"line":{"color":"rgba(219,161,118,1)"}},"type":"scatter3d","name":"0","textfont":{"color":"rgba(219,161,118,1)"},"error_y":{"color":"rgba(219,161,118,1)"},"error_x":{"color":"rgba(219,161,118,1)"},"line":{"color":"rgba(219,161,118,1)"},"frame":null},{"x":[91.384956976673863,94.17582707551415,79.331253369512993,92.960775156905513,93.14460919835102,94.770295044350704,63.302231895788381,64.023656631669525,134.70111213281777,-33.377887216181769,-36.560204915288423,-25.390960830531618,-25.962032165011212,-24.077932920204834,-24.574040182419743,-26.006476196774539,-22.011187353018116,-24.827565429639868,72.960613157024895,90.665438769947258,129.31337415202111,63.979119865671869,85.210048007158349,78.171361661485733,59.660003141348319,102.35870172783916,129.47195889853393,145.13021012936576,42.748880138207632,146.08915633840195,49.103569068822921,39.334171246438572,-35.103580863033706,76.791831331817875,128.23779390380261,132.95550275987478,92.950289485105912,71.43329135789871,125.42617024094682,103.21983133362735,144.67945221220617,143.81288810913608,139.94031834701718,138.10776775560316,126.89817848731556,67.657389391953373,137.75089427565177,136.67112850381434,-32.157278839803446,124.58774271487893,43.22967455692735,68.485323811317315,139.63004921961448,142.5283950814937,140.52560813723855,129.59121564642589,144.28639286697918,142.25033239736351,138.83854741599694,128.43012799971493,91.053870581141624,87.612264002723123,95.291549926806709,69.648825715028579,83.7686970451864,72.789166267542541,44.070938683021957,73.137258956632436,73.929341764240817,-34.317701113017577,-36.757397237521801,-36.254295108762527,62.077206839898111,127.10385835113941,92.196878822418299,40.752212656300074,71.946940245035776,72.705139488981303,76.129048772724033,93.361183870930873,28.981305492467236,94.656094450687064,27.314741187286764,92.464190640467933,125.2809148870771,73.345624148814892,-25.730815932861407,-20.421773324119528,87.477901923701495,36.923887089807501,72.06483949917336,74.498984216050658,-33.045934068515884,77.516979164081519,95.794292913321144,93.122978698971622,61.255775913019704,92.831489633901541,73.903365038237936,67.221754701674939,138.37241632137386,122.97447155407275,73.420853222397724,141.89497666082983,123.47499135931784,126.03988589484237,137.69488810963531,134.79657982412164,141.082775121493,136.97312815899394,124.58668192309042,135.051183948671,135.62462203979101,133.61215204247605,131.48052485625266,-21.841261834024042,85.969288756445792,84.095572161413074,40.434880993799304,-31.587172632840737,69.110987497879137,73.78078558146251,9.9217008115265237,130.08960174717984,129.18207598280688,-34.621796559442565,141.23015931053382,140.89777195062044,-44.206793049393937,125.64994631942356,128.15283188776709,147.74567040010086,146.4114265326821,131.15455525997666,96.05633226271263,141.7066088469671,137.4586795834654,94.899103791931097,27.118901512358462,145.05812733574723,93.131954075700904,144.38741340325555,131.07056960911405,103.92957113914399,105.66984811407757,104.90090228894843,104.88576148036726,105.75502455060099,102.17911915566006,85.544770884741098,145.52587735187649,144.56860983559287,143.60808967162944,142.21484627431175,73.900148281020336,135.03611598014214,127.53793390728406,62.185204876179228,61.555860104963855,93.094744007079669,94.436831636269275,92.224517742973106,-19.537287273990888,16.206815214154531,94.342547350690452,93.3455899627441,77.146090447219706,76.576085237933725,143.23255840708487,123.75871329958871,72.527747044102242,72.901889644034227,71.839982714665297,133.20789882666239,59.432739274534967,94.923247545150772,85.81592610889308,92.340882907058202,100.24423027667578,103.24861219615158,82.338009395455444,94.267348583149214,84.42968937742674,90.811262310654413,139.13676456131242,132.66885263715349,-36.493971028031133,144.268113114687,142.72705454843071,141.52399486850194,143.66309658907832,145.41252864356667,139.68253913663517,131.80788310373219,135.68078357013459,133.05365619960506,124.69207052885913,44.27993849728086,31.840495497126138],"y":[24.474427296868239,30.60474486896997,59.745213489063879,28.161357013902752,29.476321083392101,29.46977494392187,-41.646464670251966,-40.444374906082025,76.770056819242427,60.598856882136538,60.518032514097456,58.020255158850226,56.125160180378103,56.400223830162687,55.792844348575194,54.498778138538547,56.860205065154055,55.061951703784992,40.615453988169456,64.727166507552809,81.70868150678082,37.614805591341842,-40.501341282256327,59.128736642837431,-38.690747154482274,56.308169521611561,75.438059796359738,83.493025238778046,21.924336377523314,83.786921447048528,55.716353352596499,-14.855827524072078,61.07677541464237,75.585155628441186,83.9828922795881,84.233238255172083,28.524165434862287,65.852815493687544,76.643178041486834,54.7125532802091,87.533491537868031,86.098286759273265,86.933448955213322,91.425951748778402,76.467869753408806,48.080689622007121,93.655441596067419,93.793265352206035,56.958442709814008,77.196280746448878,23.526878479020528,63.500564652995656,80.172914175865841,85.455876037167911,88.733415110343529,86.679741832315344,89.140843603429303,90.721390957422912,87.184720169404983,81.732312725823746,-56.772157443642946,-35.646970913236267,58.374750405620858,64.159540959610069,-41.62017629784328,63.000849790763539,25.666458064722008,-47.237547293713114,67.568713952074148,59.759563358223382,63.193639500671459,60.380397604698963,-41.735345570694776,80.095177236649462,-55.779078123549837,-36.445047463132582,-47.384036758133668,-46.776425439341295,61.076719902049838,-49.477416101913121,-26.666586433007804,57.147650194404044,48.77842840319105,26.635743658077811,80.393327285611662,66.899367235614974,56.970139635496366,56.795549899631062,-35.689082412981328,-85.857266215127495,-40.594498702007563,66.661223109052671,58.354124337872946,-42.290188620189468,-36.973637608587346,31.343623800252331,-43.333313812617916,58.227797683491815,63.331761367497144,47.583442329550515,81.020027769435046,77.035168113845032,-48.13168159409333,82.465699521185655,82.519613730368079,82.001435214991758,88.620062306902227,85.368096970754721,87.255240994281607,86.578050041749265,83.937631238016181,86.807114172093108,88.845922983776546,86.574385217805087,75.967957488668631,57.927405671169971,-41.707520947187682,-41.481059116402697,-36.32636989192396,53.465046642665008,-5.7086833209399677,69.25107751154512,24.875766343746978,75.777564043809363,75.783344105777957,50.828558845978051,85.401996656819023,85.871468788416891,38.264670368559543,76.284449266706773,78.575595800647207,84.346624168447676,82.371268812623967,84.888786583059272,57.490732683487977,84.755012035682753,84.764291957417242,56.644164033544662,-28.947082066954223,84.543068725387059,-46.606442708487933,80.61836958922558,83.517353709278055,57.244830668527023,54.509854309911887,55.176348240949579,55.69118080543219,56.190544499613537,54.724929223906322,-42.166484379478788,89.895758215241926,86.428130336658938,87.801807807887911,89.721899052852223,69.23447342935485,85.513835533276605,80.255196485713867,-42.936580482883663,-43.31827491514214,-57.448358190030525,-46.779795725944012,-58.13787804079918,56.601071845701391,2.3560977293082668,55.987906308570544,-47.543019245279062,-41.36887711685943,-42.225597253890442,83.277887881913585,77.527576931140914,68.620592117174766,69.965600685666971,-40.664062153447475,76.087338652584762,-38.435154579678738,59.280225649188274,-40.535006270591843,-57.142822891809068,56.562664903544359,56.464548629205311,-42.304852148953728,27.811533815492218,-41.37725612632326,-56.979050850638977,83.571383389468721,86.866748970173461,47.226256874973551,85.23021626827493,88.041414886366383,87.524136672450553,86.141478622273766,87.124542387940167,83.465583692601811,74.762807081100618,88.078567471573876,89.485897996590211,75.008638449489382,26.15835965743516,-23.942679856178415],"z":[38.686882323321342,36.026750407645828,15.400807919631195,37.860559030809576,38.315244207538605,39.839538677176598,60.816379501196096,60.638779407485984,-15.909921865064844,81.081555534285073,79.439503205284979,60.97264403332229,62.286969613754593,63.192084222599732,62.07467157371471,62.18254068387585,65.392559596960851,63.597632554322956,-67.227610230924384,27.710202144336201,-9.1091226719525427,-50.948656022677881,17.48646527923276,13.642665358996643,65.661826331673382,-12.764349516838765,-12.460404138804378,-9.8309636968355534,43.826953674540825,-15.437204133751885,-5.0333247691916254,16.328614484114837,80.753019629322182,43.51011898513233,-8.910172184693824,-9.2264311286813694,36.730808074650831,-3.3845003029637746,-4.2003964403477552,-13.327985343126821,-11.308526938913316,-11.249794274698468,-10.749222212396377,-11.064250023744082,-15.292369238915398,58.502876586656264,-10.427472131759272,-9.780459429674373,80.448370266115901,-13.664558584554435,44.483752356182137,-3.421867835694322,-15.985627256575832,-17.844311521549418,-15.07383458198923,-11.488131860921403,-14.346433850043528,-13.918070923988184,-13.794667995427707,-6.6420551232238711,-62.115767749023107,38.519924259726707,-6.991027725782053,-3.2780824593261215,13.680120448938132,0.25390808323000374,45.199005492494258,-54.436397418158137,-1.4228768235938032,81.235552702272415,80.634021847752791,81.115068813267698,60.632150959612282,-6.9140477513644321,-62.557020495492957,-93.693221258863119,-54.868890928194894,-55.498234362247885,4.5908753145944097,-62.760181217317182,51.598893684910443,-9.8142335447383395,-38.582325284873519,38.176394974863378,-11.883768634473045,-2.8281954832219545,63.941998547948081,66.071044656355198,38.208874716539952,-6.3503254316937436,-64.640618782509065,-4.0951591577966617,81.668909342821365,-55.535988046272308,63.139899434223508,36.172971612356996,61.433352800548953,-5.4537563480481888,1.1086250892417757,58.9147398879444,-18.462790078376159,-3.5918141306989551,-55.465927904462504,-14.938365558801131,-11.48791736887063,-10.256430974436473,-16.580003451792244,-10.352203682638962,-18.950315501650461,-11.433873010385152,-11.410734397657594,-11.790950142569669,-12.610486076453096,-8.826157106462766,-14.49305480838783,66.502471532405949,17.343127839050823,14.546423959479929,-93.654460055718275,-7.2061721486971031,29.356854906645218,-3.1583285594856734,-93.847090340966247,-16.405270598697211,-14.257881687191112,-7.7648129146321763,-14.560559275602783,-16.236184556401643,-2.0338770735942391,-15.890080529140636,-9.3617690571696972,-12.830804592929393,-11.798787901079413,-10.84307704362274,-7.9336779411242206,-10.364558746912399,-9.2468697569730463,-7.8906045780539529,53.024439095932522,-12.462798496143373,-62.926019089056581,-13.084303420519015,-7.9429710119311201,-13.927220598242668,-13.552963450368276,-14.759914837554161,-12.859987037208185,-14.007382061630258,-14.851924470427111,18.940646687374514,-17.682801427704227,-18.706968381044121,-17.456699037366064,-17.459179419513543,-4.6560133618908912,-7.6046080816950212,-8.565382579447931,60.649166307205505,59.444230513892876,-62.435711856716992,-62.702314817788348,-62.68901335113425,66.28224534630813,40.386109235216367,-9.1657598402675244,-62.843454776939502,-55.831603697517949,-55.941100023112014,-12.499038979178765,-4.2849770593779652,-3.9343185993948642,-4.1472879338128719,-64.879780772521499,-15.923469132498214,66.030406936758695,-5.8628004149089641,18.56294177139133,-63.807802357738709,-11.164679882826364,-15.19132818647496,11.032899946607667,37.233746540495879,18.15764926786261,-63.658538502296381,-10.282971345908331,-10.971588268977317,0.94819676581659373,-16.56670444078809,-15.168273331032722,-13.403500860239825,-14.724724505853198,-15.692528044315029,-17.974704910461199,-16.539307240176118,-9.5296575370918557,-9.8111414550672134,-13.636400703379122,45.346979147699138,104.04688813803685],"text":["Input: 'accountant' (lang: unk)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant occa baptist' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant draughtsman out of' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant grocers' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant on dealers' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'accountant pig iron' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'advocat' (lang: ca)<br />HISCO: 12110, Description: Lawyer","Input: 'advt en secrs tot diemen' (lang: nl)<br />HISCO: 12110, Description: Lawyer","Input: 'af sognepr' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'apprentice millwirght engrav' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'art engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'artist' (lang: en)<br />HISCO: 17000, Description: Composer or Performing Artist, Specialisation Unknown","Input: 'artist employs 5 men' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist floral' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist in choreagraphy' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist landscapes oil and etc' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'artist sculptor' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'artistic landscape painter' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'as a dairy maid c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'assistant librarian british mu' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'assistant teach church of engl' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'assisting decrepid mother' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'atambor del tercio del vermells' (lang: ca)<br />HISCO: 17140, Description: Instrumentalist","Input: 'atorney one of the deputy re' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'attorney at law' (lang: en)<br />HISCO: 12110, Description: Lawyer","Input: 'ba english language teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'baklist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'bedienaar des goddelijke woorts en not mentioned in source' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'bedigd translateur' (lang: nl)<br />HISCO: 15990, Description: Other Authors, Journalists and Related Writers","Input: 'biskop i odense stift' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'board school assistant pupil t' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'branddirektor i kbhs amts nordre birk' (lang: da)<br />HISCO: 15920, Description: Editor, Newspapers and Periodicals","Input: 'brass relief engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'builder contractors clerk' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'c c methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'caloinister methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'chartered accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'chawrwoman' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'city sewers employee' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'classical french teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'clergyman' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman estabd church0' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman in holy orders' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clergyman servants' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk agent' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'clerk in holy orders' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk in holy orders, retired' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'clerk to calico engraver' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'cottars neice' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'courantierse' (lang: nl)<br />HISCO: 15920, Description: Editor, Newspapers and Periodicals","Input: 'cratemaker c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'curate church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of chilton foliatt' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of great torrington' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of handley m a of cambr' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of keighley' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of rhyl' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'curate of st swithins lincoln' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'deaconess wesleyan methodist c' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'degn' (lang: da)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'doctor in de regten' (lang: nl)<br />HISCO: 12000, Description: Jurist, Specialization Unknown","Input: 'doctor of laws oxford' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'dressing c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'drummer derby regt' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'e r a 3' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'editor' (lang: en)<br />HISCO: 15120, Description: Author","Input: 'ekstra folkeskolelaerer' (lang: da)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'engineers assist l c c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'engraver and designer art' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'engraver of gold' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'engraver on metal' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'etud en loi' (lang: unk)<br />HISCO: 12110, Description: Lawyer","Input: 'evangelist church a ny' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'ex-schoolmaster' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'fd naemndeman' (lang: se)<br />HISCO: 12910, Description: Jurist (except Lawyer, Judge or Solicitor)","Input: 'folkeskolelaererstuderende' (lang: da)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'folkskolelaerare' (lang: se)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'gentleman of the chamber to th' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'headmaster of school' (lang: en)<br />HISCO: 13940, Description: Head Teacher","Input: 'hoogleraar wisnatuu' (lang: nl)<br />HISCO: 13140, Description: Teacher in Mathematics (Third Level)","Input: 'horticultural lecturer' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'hotel keepers sister' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'import accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'in rect of relief from st mich' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'interest c' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'jewellers artist' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'journeyman sculptor' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'juris kandidat' (lang: se)<br />HISCO: 12000, Description: Jurist, Specialization Unknown","Input: 'kgl kammermusicus fravaerende paa en kundskabsreise til norge og sverige' (lang: da)<br />HISCO: 17140, Description: Instrumentalist","Input: 'klockare' (lang: se)<br />HISCO: 14990, Description: Other Workers in Religion","Input: 'kloster jomfrue' (lang: da)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'labourer for engravers' (lang: en)<br />HISCO: 16150, Description: Engraver and Etcher (Artistic)","Input: 'laerarinna' (lang: se)<br />HISCO: 13000, Description: Teacher, Level and Subject Unknown","Input: 'laeroverkskollega' (lang: se)<br />HISCO: 13200, Description: Secondary Education Teacher, Subject Unknown","Input: 'law writer accountant' (lang: en)<br />HISCO: 11010, Description: Accountant, General","Input: 'lawyer' (lang: unk)<br />HISCO: 12110, Description: Lawyer","Input: 'lecturer in metellurgy and che' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'lieut r n vet secy e a f c p' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'local preacher coal agent' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'lombard st rector allhallows' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'london docks' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'mestre de minyons' (lang: ca)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'methodist clergyman' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'min of c s church auchialeek' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister connected with brethr' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of bargeddie' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of free church retire' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of kirkben parish' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of leslie free church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of millsex q s par' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of moffat free church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister of rosebam u f church' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'minister retired methodist chu' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'ministre' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'monumental sculptor' (lang: en)<br />HISCO: 17000, Description: Composer or Performing Artist, Specialisation Unknown","Input: 'musician' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'musician kings dragoon guards' (lang: en)<br />HISCO: 17140, Description: Instrumentalist","Input: 'naemndeman' (lang: se)<br />HISCO: 12910, Description: Jurist (except Lawyer, Judge or Solicitor)","Input: 'national schooll mistres in co' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'notari' (lang: ca)<br />HISCO: 12310, Description: Notary","Input: 'nun' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'occupying a farm of 39 ac all' (lang: en)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'pastor' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pastor baplist' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pauper in receipt of relief of' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'perpetual curate of chatburn' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'perpetual curate of stoulton' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pitch speeder' (lang: en)<br />HISCO: 19990, Description: Other Professional, Technical and Related Workers Not Elsewhere Classified","Input: 'pontytrian minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'preacher bap' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'predicant te jutphaas en not mentioned in source' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'predikant' (lang: nl)<br />HISCO: 14120, Description: Minister of Religion","Input: 'prepetual curate of the' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'president of collrdge' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'priest' (lang: unk)<br />HISCO: 14120, Description: Minister of Religion","Input: 'primite methodist minister' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'prof in u of m' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'professor medicina' (lang: ca)<br />HISCO: 13130, Description: Teacher in Life and Medical Sciences (Third Level)","Input: 'prostdotter' (lang: se)<br />HISCO: 14120, Description: Minister of Religion","Input: 'proviseur et retraité des chemins de fer' (lang: fr)<br />HISCO: 13940, Description: Head Teacher","Input: 'provst for falsters noerre provsti sognepraest i oensleveskildstrup' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pumitive methodist minster' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pupil in seminary' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'pupil teacher al school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher candidate schoo' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher church school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupil teacher f ch school' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'pupile teacher' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'rabequista' (lang: pt)<br />HISCO: 17140, Description: Instrumentalist","Input: 'rector of adstock' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector of south ockendon' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector of stangunllo' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'rector or barningham' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'religieuse' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'retired baptist minster' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 's mpreacher' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'sagfoerer' (lang: da)<br />HISCO: 12110, Description: Lawyer","Input: 'sagforer husfader' (lang: da)<br />HISCO: 12110, Description: Lawyer","Input: 'school master' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'schoolhoudster' (lang: nl)<br />HISCO: 13940, Description: Head Teacher","Input: 'schoolmaster' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'sculptor marble carvery' (lang: en)<br />HISCO: 16120, Description: Sculptor","Input: 'seminarielaerer' (lang: da)<br />HISCO: 13155, Description: Teacher in Education (Third Level)","Input: 'senira master of languages' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'skolemester i sognet hosbonde' (lang: da)<br />HISCO: 13940, Description: Head Teacher","Input: 'skollaerareaenka' (lang: se)<br />HISCO: 13320, Description: FirstLevel Education Teacher","Input: 'skollaerarinna' (lang: se)<br />HISCO: 13000, Description: Teacher, Level and Subject Unknown","Input: 'sm kandidat' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'soemandsmissionaer' (lang: da)<br />HISCO: 14130, Description: Missionary","Input: 'soeur de' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'soeur de charite' (lang: unk)<br />HISCO: 14140, Description: Religious Worker (Member of Religious Order)","Input: 'sognedegn hosbonde' (lang: da)<br />HISCO: 14990, Description: Other Workers in Religion","Input: 'sognepraest' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'solicitor' (lang: en)<br />HISCO: 12410, Description: Solicitor","Input: 'solr ba of oxford' (lang: en)<br />HISCO: 13100, Description: University and Higher Education Teacher, Subject Unknown","Input: 'tamboriner de artilleria' (lang: ca)<br />HISCO: 17140, Description: Instrumentalist","Input: 'teacher' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'teacher ladies college' (lang: en)<br />HISCO: 13990, Description: Other Teachers","Input: 'teacher prepare candidates for' (lang: en)<br />HISCO: 14130, Description: Missionary","Input: 'toneliste' (lang: nl)<br />HISCO: 17320, Description: Actor","Input: 'tresoreria port empleat' (lang: ca)<br />HISCO: 11010, Description: Accountant, General","Input: 'trompetter en not mentioned in source' (lang: nl)<br />HISCO: 17140, Description: Instrumentalist","Input: 'tutor' (lang: en)<br />HISCO: 13020, Description: Teacher, Level and Subject Unknown, Not University and Higher Education Level","Input: 'u p preacher' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'unitarian minister of upper ch' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vanmarbaker' (lang: en)<br />HISCO: 16130, Description: Painter, Artist","Input: 'vicar of elberton' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of littlebourne' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of st lukes gloucester' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of tharston' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar of ullenhall' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vicar st pauls morley' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'vise pastor hosbonde' (lang: da)<br />HISCO: 14120, Description: Minister of Religion","Input: 'wesleyan minister b b lond' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'wesleyan minister new inn st c' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'weslian rev' (lang: en)<br />HISCO: 14120, Description: Minister of Religion","Input: 'writer' (lang: en)<br />HISCO: 15120, Description: Author","Input: 'zaakwaarnemer' (lang: nl)<br />HISCO: 12410, Description: Solicitor"],"mode":"markers","marker":{"color":"rgba(217,150,141,1)","opacity":0.69999999999999996,"line":{"color":"rgba(217,150,141,1)"}},"type":"scatter3d","name":"1","textfont":{"color":"rgba(217,150,141,1)"},"error_y":{"color":"rgba(217,150,141,1)"},"error_x":{"color":"rgba(217,150,141,1)"},"line":{"color":"rgba(217,150,141,1)"},"frame":null},{"x":[57.241079609857721,70.351921403271206,54.685752702157004,54.989405374588834,55.598440824027684,-28.635588866352222,-4.8698296976003688,23.227664336819277,23.655620953625935,-74.833840598137797,14.704024875890985,21.884306628346899,-76.486099876118587,23.03978416451416,23.064666603518667,-76.157547554066795,13.962913848493276,35.11377146991348,20.520314070565345,36.879361300172931,-8.9971488024521946,-56.220776946225769,54.603021154600498,56.014065076678705,57.428239486155377,55.545380699417834,57.602936978097567,-74.107546293683853,57.375162316732016,-4.8320969786246843,-7.3914914736943942,-4.8036726235456833,55.964186848257725,59.548730581290535,58.342030260783893,-5.5359481080408806,36.755943911121541,56.578736643127215,36.890560920646593,24.182554359846836,55.28016783243293,-76.471997360909967,39.11155621475578,54.904625587502501,55.285269900138118,53.351058800702098,54.978818045866603,55.847440328525693,54.001401425978258,21.100428878688465,36.999043655527657,60.583624548508027,60.371996502869386,23.557695698427445,-74.916396809632971,73.880459694584246,52.397481906787867,20.713503062668238,24.239026704471168,-75.659730213577859,64.549560621844549,15.764001781979147,-74.994306966973454,37.207329241123389,61.128515129260975,60.569083478856513,60.587832462237287,60.470161959816188,59.542349378220088,36.700093910236099,65.085917358170107,60.479082267716791,-4.5899105277279739,68.738371437285252,71.993978598978671,70.286950352693637,49.985567023133299,-74.671428279006321,36.416534893072416,-14.904730573731467],"y":[-63.555619167576381,-8.6011778649877755,-67.675646488037941,-67.863584477841272,-69.18711668394559,2.2263081562990972,40.862708231105046,8.4727306886506657,8.1686446762820637,60.521534362716125,66.761683007175293,-60.157495861121596,63.008335907940463,8.5215037970720946,39.944716335956436,63.144899359625597,66.258153346660251,-19.367939763213794,41.093063297739853,-19.977960221458773,41.865628651965423,64.829514515186162,-64.780462797488212,-65.3187867349572,-65.014497883000175,-64.365740894175332,10.126678907408069,61.887971966653488,9.8416356313937285,37.112331334813348,41.275799412924698,37.852266595553331,-66.52850965637036,18.834179120137986,19.128018015609729,39.269376677999567,-20.680864610010044,-67.461461237152093,-18.867701070780843,39.114327212218093,-86.813485684658488,62.649310050965632,-22.331111246204568,-84.912130296273972,-86.651146754980928,-87.149729863844371,-85.768050979008592,-85.795504826555216,-85.645114527779697,44.618333355057921,-19.560178840203552,14.791417811625669,15.293852866297538,10.472541448520346,49.832936817183935,54.553996821586452,-67.576125502405873,41.002183792557673,39.557845500640973,62.423836854020507,42.598247026013823,66.580814350214069,62.555493248673152,-18.333896757895797,-14.929949652868764,-14.94102569515986,-13.656630718882209,-13.425165115712691,17.523549140724679,-19.412472166355169,27.835102632337406,19.898494757589415,39.665589834450827,-11.299932485629384,-8.3723349600637444,-8.8994405431822283,72.215814531139159,64.977479291897126,-18.830210674523705,101.93007530389579],"z":[-75.740676287731915,27.77304777728067,-72.81506846172536,-71.436117082669924,-71.74537637013681,-47.254689345262129,26.39770392542783,55.483063395031351,54.285551763096905,3.1916566261104498,27.522060514105199,4.1557376050193255,0.16969661198146438,55.964775000784869,36.004815702699275,4.3021992724783056,27.504102393603798,18.47727772138466,38.557187455022429,16.651879535868808,25.71805941269551,6.3900266238352232,-74.117809291629825,-74.553484532107134,-74.126818454112197,-73.222550031942177,26.10078598854389,3.0286777032560104,26.006078748004928,26.571097064821064,28.335488934492449,26.201769858144029,-72.408057080271561,26.958667294917607,27.358891695559446,25.902084931633542,15.939100113476409,-73.696442800525119,17.005016527516773,35.006512194413119,-61.452776087685308,2.8020148445522848,15.175310393748353,-62.745658814601057,-63.145732300403147,-60.94366808198734,-59.750217055645145,-61.691941950214009,-61.213055608698269,-37.459565166424518,22.210343005797657,27.587796731346547,27.464274832562026,55.173495774857408,-25.268759147596459,31.581293335570326,-71.910066021883253,38.361279616708615,34.60793171611607,5.0273129245626533,62.455276328074902,27.930848101859841,1.4581306323392809,18.700908524684664,12.056371141615173,13.239022734250502,8.8279045706198538,7.9689722595527135,27.205736994320919,20.589636619872081,26.800718917613001,26.480034992134158,26.20902750718313,27.942374624977631,27.401632702491089,27.362742223512786,-43.682089244952522,-0.22807505569971778,14.475556403385106,30.193843674061561],"text":["Input: 'agricultural foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'batlle aigues' (lang: ca)<br />HISCO: 20210, Description: Government Administrator","Input: 'bestyrer' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'bestyrerens hustru' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'bestyrerindens barn' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'brass caster' (lang: en)<br />HISCO: 22490, Description: Other Housekeeping and Related Service Supervisors","Input: 'bricklayers foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'builder and contractor' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'byggmaestare' (lang: se)<br />HISCO: 21240, Description: Contractor","Input: 'cabinet lock manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'coal mines manager' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'colliery proprieter' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'colour manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'contractor' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'cooperative stores manager' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'cotton manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'cycle manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'directeur papierfabr' (lang: nl)<br />HISCO: 21110, Description: General Manager","Input: 'director' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'disponent' (lang: se)<br />HISCO: 21110, Description: General Manager","Input: 'engineering foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'engineering manager' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'farm bailiff' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm foreman' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm manager' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'farm steward' (lang: en)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'fd foervaltare' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'file manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'foervaltare' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'foreman (deceased)' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'foreman at newspaper offices' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'foreman deceased' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'forvalter' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'gas inspector' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'gas manager' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'general foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'godsaegaro ingenioer' (lang: se)<br />HISCO: 21110, Description: General Manager","Input: 'godsforvalter' (lang: da)<br />HISCO: 22520, Description: Farm Supervisor","Input: 'grosserer senere nationalbankdirektoer' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'handelsfoerestaandare' (lang: se)<br />HISCO: 21340, Description: Sales Manager (Retail Trade)","Input: 'hans huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'hat manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'husfader husfaester skipper og skibsreder' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'hushaallerska' (lang: se)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'husholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'husmoder inderste lever af husflid' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'huusbestyrerinde soster' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'indsidderske og fornaevntes huusholderske' (lang: da)<br />HISCO: 22430, Description: Housekeeper (Private Service)","Input: 'inn keeper' (lang: en)<br />HISCO: 21420, Description: Hotel and Restaurant Manager","Input: 'inspecteur des messageries' (lang: fr)<br />HISCO: 21960, Description: Transport Operations Managers","Input: 'inspektor' (lang: da)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'inspektor' (lang: se)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'jobber' (lang: en)<br />HISCO: 21240, Description: Contractor","Input: 'joiners tool manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'keeper of the workhouse' (lang: en)<br />HISCO: 21940, Description: Administration Manager","Input: 'lantbruksinspektoer' (lang: se)<br />HISCO: 21230, Description: Farm Manager","Input: 'manager' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown","Input: 'manager of boot and shoe shop' (lang: en)<br />HISCO: 21340, Description: Sales Manager (Retail Trade)","Input: 'manufacturer' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'mine agent' (lang: en)<br />HISCO: 22620, Description: Supervisor and General Foreman (Mining, Quarrying and WellDrilling)","Input: 'muscumsinspektor cand mag' (lang: da)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'nail manufacturer' (lang: en)<br />HISCO: 21110, Description: General Manager","Input: 'onderdirecteur bij de bank' (lang: nl)<br />HISCO: 21110, Description: General Manager","Input: 'opzichter bij een cementfabriek o' (lang: nl)<br />HISCO: 22690, Description: Other Production Supervisors and General Foremen","Input: 'opzichter rubberplantage' (lang: nl)<br />HISCO: 22660, Description: Supervisor and General Foreman (Man. Paper, Plastics, Rubber, etc.)","Input: 'opzichter van het stads modderwerk' (lang: nl)<br />HISCO: 22680, Description: Supervisor and General Foreman (Man. and Distribution of Electricity, Gas and Water)","Input: 'opzigter publieke werken' (lang: nl)<br />HISCO: 22675, Description: Supervisor and General Foreman (Construction Work)","Input: 'overlooker' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'pdg' (lang: fr)<br />HISCO: 21110, Description: General Manager","Input: 'post office official' (lang: en)<br />HISCO: 22220, Description: Postmaster","Input: 'railway examiner' (lang: en)<br />HISCO: 22000, Description: Supervisor, Foreman or Inspector, Specialisation Unknown","Input: 'road foreman' (lang: en)<br />HISCO: 22610, Description: Production Supervisor or Foreman, General","Input: 'schepen gewezen en not mentioned in source' (lang: nl)<br />HISCO: 20110, Description: Legislative Official","Input: 'slottsbyggmastare' (lang: se)<br />HISCO: 20210, Description: Government Administrator","Input: 'sognefoged og laegdsmand' (lang: da)<br />HISCO: 20210, Description: Government Administrator","Input: 'stewardess and housewife' (lang: en)<br />HISCO: 22440, Description: House Steward","Input: 'sugar refiner' (lang: en)<br />HISCO: 21220, Description: Production Manager (except Farm)","Input: 'symaskinefabrikant' (lang: da)<br />HISCO: 21110, Description: General Manager","Input: 'wharfinger' (lang: en)<br />HISCO: 21000, Description: Manager, Specialisation Unknown"],"mode":"markers","marker":{"color":"rgba(152,158,202,1)","opacity":0.69999999999999996,"line":{"color":"rgba(152,158,202,1)"}},"type":"scatter3d","name":"2","textfont":{"color":"rgba(152,158,202,1)"},"error_y":{"color":"rgba(152,158,202,1)"},"error_x":{"color":"rgba(152,158,202,1)"},"line":{"color":"rgba(152,158,202,1)"},"frame":null},{"x":[33.669054005472162,72.008610622610718,90.206423984239422,62.831994158867992,73.16344362119473,73.041471921048185,87.840116807558161,68.74220218353814,91.288659753914018,116.25467051647624,64.401160123233311,64.808001704513828,86.797860261756526,65.527646844507203,64.495400768447084,60.551904909850087,64.669889445151881,88.652014180399874,89.229834603794941,75.4909998347336,43.584091469746902,89.769626640578423,59.819827126520046,60.743004796193624,26.531645315864935,72.504919324020605,59.794290887540178,37.590549662209511,114.59490830761541,66.182619791904102,30.197284109113397,45.816739978132929,45.907331483978403,74.624121125725807,62.494231068879699,88.254905331063128,77.299928715612197,56.91338484311683,77.964060378686128,78.123546318536896,79.553299653636742,73.044817260186363,76.934242557515248,73.807919404025625,76.711095572716729,64.957574986875471,77.251930689416966,74.41126764373449,76.297151809764614,78.273762919915342,74.393278140533283,63.412538635976993,89.833334437356157,76.159158517601441,77.022306804465586,67.88349536702745,80.71992422335903,76.720633488712849,82.855055496102068,124.07318732480539,72.269784824091133,74.227909360543819,72.324834509751071,82.090723675452011,72.803614880127753,74.920977764227047,76.792066230420886,75.511089774228992,77.329742176617216,75.553090643487565,79.563154924761818,70.208794523211523,75.745378831422229,72.196862618384145,73.104041049117185,78.227817485608853,72.61902841503921,65.499102906953809,67.392041284169011,78.769604285077122,70.188374116285701,72.365490171658223,70.633395619432847,87.213776995306986,76.335801714142946,71.720459842236409,72.92415056711603,74.654565100120251,75.236586152941371,74.340675794912585,85.45001621656732,74.031859230197469,69.778742784296142,75.534261979752031,82.442868388828487,-140.71684358717874,73.977979786414451,68.798170411028011,58.306001950626396,75.251169480569956,69.322788543205789,-14.05385199672766,49.315344765955118,49.101011171550418,78.069161405041811,68.949578747545175,77.003321659889352,77.514362950519271,73.280009432665977,90.438746006211375,78.828529058539814,39.439099951044689,25.36733612728154,72.052569935612553,75.217830631933779,77.059244796976671,-26.393999618133588,64.787840484206185,72.159749889499935,62.174151220062171,57.96194410927739,62.681131207179973,72.275216243890782,63.223897486406258,60.890324883935889,60.92208891017038,58.303978834158777,59.350709717236285,61.206804908846351,60.494945408433452,59.107007291517064,62.399750707928597,-42.16362056019738,65.214230442357604,112.96075127786639,69.826759950206423,68.235203785061785,77.710578472480378,72.32902671978897,64.37439708330011,71.713628147568414,75.936885631307135,29.498291695159065,55.238227278941395,-33.611572785404093,78.85859453678033,72.217058195452083,62.407489467585137,38.834527522887008,62.304932514850265,73.907800687476964,65.790199587083237,73.96198149882656,86.68150848691819,86.899239924055649,79.696335829145838,63.105139962802077,74.389511122302267,71.276235232792573,58.121315426337006,73.305566500749123,37.817429781498703,37.438874301143102,68.607178026157101,74.892967916419295,71.055195008406713,36.337704962562661,74.825183675750182,92.815938057713993,29.005910688816336,92.497583580559706,114.93306107826125,113.7884069980669,115.00861362727389,75.547787380291609,59.594690829662703,89.426691767276168,88.772917117464331,89.372339801369151,76.024985382238427,74.438296306379229,75.332348782264077,83.468394750013516,58.628524344455947,61.418355051124003,61.716075113550033,61.549730305455689,60.877889445990874,60.913899831258199,57.639991591239387,60.171381864039965,59.794615900518309,77.871736886210272,61.608173767723684,76.988466606948919,69.281172926693003,22.758324606800148,-118.39006072854242,84.842189820383695,61.4592092207874,58.324334621546754,61.746630763535855,81.155377335384358,46.47228207388207,54.352039715049031,40.146606177463276,64.236108972687944,109.91575883398423,74.512261182739891,108.81977129731179,108.41492936050069,114.2734089183419,114.67355972396177,73.192083534115227,62.30320959804213,63.762680253693091,73.694539908866531,58.427356483138531,28.535333965266801,28.817755603383969,27.619670905423931,28.491758901382255,27.360790921069054,58.004390119467018,31.37900537815058,19.224972641255579,115.48780888000643,74.597000854947865,75.251106047333849,79.390258410705485,76.872695677606373,65.426116939999986,77.088338935806931,65.202973065476385,76.089166837221484,71.252888664935796,78.347456923015514,72.011369349834183,71.855236892915329,6.0061484898232296,85.702131207650666,72.873315084989329,82.126371865316344,76.002366920522491,-0.19614816507015201,64.283697329560241,89.35763943580946,28.558238477426205,76.580153626970841,68.194469787965161,90.14435106752606,90.216170638003518,85.749727357627805,93.637705361756318,87.242635728172502,-52.371479529510779,71.757389965663961,75.822083773127702,67.873772939324738,56.002983502524188,-0.35671575370591752,73.939517966926985,56.93014693210737,69.12662989627988,75.877460925239191,61.845994145900384,-36.439084824516307,56.371000766076669,73.580646618880067,50.523498540628282,71.845356878607447,46.444005265353425,38.223938522119148,77.44835942183569,38.638656106821642,77.933916473437435,73.227080825884201,68.897084986480806,63.311632358450673,74.209737731255629],"y":[53.369699782395934,59.210113347359169,22.445944216514189,115.53240594133673,55.592231557382497,55.426071566632054,19.163391953611054,2.9420089534270644,60.907882877954648,8.4230222696387287,30.548834510638727,68.300466506704467,19.767286595529526,117.95627567992869,119.828944207218,71.235313604727963,118.63649857240063,19.427497295120023,21.167733912080564,80.326875376402143,84.86728005509886,21.059575239172471,121.28356680213454,116.46446060424043,116.05708903496011,76.381635951389043,71.110651878230271,99.290354426253046,10.61069492661473,68.276644790301219,115.38243616925803,83.044806672196529,82.955945647193147,58.012510184225697,33.461043961438115,75.134060427666682,55.909427202285066,118.74563608126141,53.353159264976334,57.159030599031844,73.972520189954068,69.872683489017177,68.599212260426711,61.709816580534564,78.775540345269235,67.956416776609899,81.837917351681298,73.998750141347401,68.762800244195233,75.074707926514591,69.662420138347471,81.373920661667256,62.827275945836618,71.328081551578521,58.917079236858939,69.750769736111678,79.426350481470195,66.714049902115491,75.302562453157833,79.756616613990431,65.411326255790527,67.784563402631463,69.226050538867412,77.504700081659635,71.384841755778865,76.401434368532648,75.228019782011742,68.128583727399644,54.375896542346503,72.976928606935004,67.467385539996371,68.774580849699134,71.921251605942373,78.926790910283003,71.634588518854059,79.773045975076016,79.961203040773157,80.543295081856172,80.63172497974945,80.764002882054015,75.161620552584424,75.676570799749626,68.38790771228237,73.634335590995647,58.426227919338572,77.267920592660374,67.553590541014131,75.143183489576259,72.461609714600158,68.884889332028763,63.002095298236853,76.243335339574543,79.026204791903965,81.07528892230458,77.844326154981019,3.3917265936565686,72.231725530108008,65.100669798597295,72.996276615798578,77.709066197371087,49.709139819792583,-16.604710033388152,84.172893494000732,84.619905204803004,78.321790227749361,-2.3935187222074283,57.993610485525181,75.870589246595429,54.391747951813038,59.509302091609896,67.578117509030022,-80.25641044062391,114.94304040405463,47.960471183974704,60.019669577655073,76.02036715286188,43.060969701909258,32.157638985597345,52.318208326772634,116.24655825403109,120.41796001166279,69.649086991656176,-6.5588835501899387,120.1897330235083,121.07192684720356,121.6092943084048,119.43021861933603,120.15533357579551,120.12047726242895,119.18123582727765,120.69912926497119,121.96707569608166,4.1644781031084461,32.767780452453984,5.8501784316669685,56.378579479506406,48.5633008425567,77.427542708953581,74.574068347981978,68.552508218737756,55.855412221314367,79.423203370408459,113.95775414522392,118.32041147419399,41.806901613192103,71.108872753975632,60.942217175287482,33.275950582962309,-81.457536760899856,28.11347426812052,51.129117024845137,29.848361746105809,53.712098663737478,72.908905860878178,74.706637658843974,70.608127742614769,116.02924534819103,72.651400812063216,-5.5699473467295562,30.53229813348085,54.642620933840746,-44.504784136844805,-30.413138790424899,-1.6801659671086848,49.687236455847717,-6.8511806872360239,99.952613249660502,49.331845600990036,61.102528765181425,112.94212746997694,59.903491322470352,9.4070663905325542,7.9294629787665647,7.3074485203842414,54.658082779337207,117.83305983575032,61.692766523246647,63.152000636052954,64.151316697459151,59.767527200487116,80.307593016297943,77.601659855649402,77.601484542475944,122.22175987294965,124.03656087070385,119.38131642556552,119.73942499847104,122.23055624931926,122.73270851896912,117.76225655049487,116.36810843080961,115.37130324726226,72.348075023831967,124.46058113629245,57.87111564283996,49.993419741208889,-17.040408383265511,61.221833731627569,22.662615276245493,119.2170329574694,121.41856553908799,113.58031850682428,61.0783743056448,78.432551148533435,116.54117801772276,80.148557367720841,113.21965331126445,3.053108414280246,110.85237315855203,1.9896359192141508,1.512844604228873,5.6803748843562198,7.5486431165776899,56.945588477750029,32.452107337135381,30.639220223206877,59.203429764818772,30.101309459193342,115.81396112911307,116.70979618416523,114.43191769573978,114.67026614110698,116.43202708894472,30.702327450195234,116.21711382281302,51.325620490629575,6.1908156705109381,54.742078164806991,55.709880157153961,70.667101626255899,57.806596647831945,69.411023301893053,57.811868566983328,28.783535788797206,70.660489915057198,69.365654187430906,80.076294396472164,-22.879427070589635,-23.029314408854173,26.540059748539537,19.736476820116991,55.210803808015463,75.511110918197531,68.912373735585575,57.112925721679538,117.82046325775781,61.014893082398196,115.56952662374269,48.458568891073675,49.868895236362704,61.461942117037147,62.951729198374366,63.625427665341533,61.044950116494469,63.04852191355311,53.57194447782426,-6.9615291384768243,67.128527246565483,49.141686911541541,120.61920182247138,57.528568040956905,48.869812364632409,114.99803939054618,2.2584608279527449,62.897664703465807,117.59326037106798,46.175376942564661,116.29480104176658,-29.415420962394446,84.669243013329904,-8.1554064038438447,84.044869320150525,99.919451060545484,76.914541955049614,99.282633371272141,69.783357501715315,51.406032424080898,1.5405196888564356,30.339047360193522,78.439779201789932],"z":[-35.513191323202257,34.435665621419417,38.943522622448491,-21.669739406900465,34.452063913367013,33.277228952812159,39.532954062405317,32.509191809674817,33.40705567399187,21.398630597581818,20.503236548370815,44.962764711815232,10.993269363772876,-20.607731733465386,-24.982943461203028,53.600709109154323,-26.843092416506728,39.05813851985053,39.223187870979721,53.877559001605341,-40.372269950271289,39.813529236255874,-28.034998893348728,-33.437163227508655,-0.96538316927931389,52.892630064717324,52.979094617908558,7.2299613673166885,19.997165028526567,50.284711568169691,0.20794477020867197,42.005127558759355,42.308717337411572,54.693852173363581,-55.313964642726624,50.647298555640006,54.170329558668932,-22.833238019024087,50.435480994537443,54.230022267721118,34.919048385963002,45.695627216291655,54.656636276717741,49.016938437336513,52.967107743089606,48.876567083654741,50.688828879797711,51.90428889181144,44.83640050657938,53.420188140268863,49.399950846048959,49.860557458435416,32.962361314243253,36.470438150526611,50.516651176056335,51.073502088886016,49.108724896585436,44.372325252649091,43.939069301684093,-2.9064683761656589,53.25475209988916,47.178175979188197,44.355232157144606,46.085149738798968,51.086253834189129,50.922929123085027,51.379905298118267,41.779996949873102,50.539263098421095,42.393666983922849,52.1236704918242,56.567902991617167,40.586698438151068,54.973500027118746,42.553123869288477,48.110476738765087,49.163956751847415,47.437327778927809,46.596744175742238,44.93346276694205,42.550164212576938,50.301956199808352,47.762725476370683,49.47200383817588,20.866617757281031,45.949617144717372,55.242634483086825,48.367359018715121,45.531632706455795,52.332394294291092,28.910676880621498,46.528556666681752,46.162258270157075,48.834524542204541,56.010273408368988,34.29878538177001,55.653178930655933,52.968359370801309,52.482319015305308,54.033388353741209,56.989888277071458,72.946636092538597,34.010472863417647,34.098145805467929,40.189279277628586,42.613438421208073,55.397920411129974,47.206086248903539,38.651225201628414,31.438638896694016,43.629802623155349,-2.5302506935239366,-7.5315723622264885,21.052903126904667,48.474030519439701,40.659524147984591,-7.2563105616362673,25.21482021264611,20.663379801540849,-28.509667815988784,-23.345503926396585,55.918666426617648,15.405659362264126,-29.136204286003942,-32.375190021808095,-30.098562211208026,-28.622181052404819,-30.63036272156825,-26.920837648975894,-28.556526829964167,-32.952663742224473,-28.329725078514727,7.8268705270883974,25.830221716597165,20.480706785272204,17.076965579376743,18.831576404292392,51.211681280234544,46.118770884008221,46.508746917249645,51.270303500081361,47.248649782170702,1.6038021027067602,-21.52553374969062,-7.5094010403819045,35.303471196926196,35.68716203238283,-56.333399593121598,-3.5532221742229995,21.701127253297528,18.809475116075514,21.81012992941017,19.920667230128494,51.339151306926617,51.146308661044891,38.648749972984419,-25.875488118317296,49.562536955860622,14.646286011380806,-2.4166110298245798,40.2290332017784,-4.9175705642838219,-11.537403495459884,30.83423067385511,18.416965962387305,14.974341748110138,6.4989338258697646,19.29666176026582,34.822501067698909,0.59076412576660131,31.687537748005219,20.71666472481192,21.490368342333863,22.127641875584462,16.097186206806946,-24.429004212954951,35.534154638688349,30.560872588396336,31.561234818786744,55.120245690210531,50.943910400584613,48.592515442743057,56.624186097697219,-29.908297559553045,-27.656494351342051,-24.106601047620384,-21.828294486133757,-23.314597669688165,-26.169967199364461,-26.492989057369325,-27.66553722295232,-24.183891183178964,37.747067628684412,-23.513011108973156,53.197469799723343,18.531451260183399,-93.791790890147951,-50.710727178975063,12.832527159518939,-30.252133588103799,-26.081566894881473,-28.728818807291642,22.571476183432193,-39.917386141363146,-31.549883749699813,-45.494038484979384,-27.220003662334097,19.542146069127273,-41.982910553885588,18.942605257974435,18.666386585368475,21.899876299322159,20.189295065293837,51.571886593429241,20.70104473599649,23.239650370363606,48.846427731041501,-0.96840648560594367,2.2429045297988033,0.78576202932788342,1.4010609232294982,-0.032443203644099854,1.2950601821682586,-2.9355461170636525,-0.82815200122874533,-14.584845345344577,20.688594137159523,18.722132155742646,18.791694688461273,53.802682112589615,17.728334746552296,55.577642286404135,15.272292449405416,24.594002624209171,35.151088662177301,49.678937066351857,39.487328609029021,-7.394576761741301,-7.2232443065639362,-93.041687539637678,10.567751757370088,18.512498192675363,52.322574792502678,51.417526592322595,17.925043877446274,-20.87122258305752,34.118049116899712,-17.260933625639467,19.221690863717694,19.325760794371302,30.170668484429573,29.465764943484807,27.715549215423284,34.320216912140232,31.817596839812182,31.911467377486773,13.794016539972972,52.55980081948227,15.807630694607592,-25.474662573220268,17.886193440327389,17.20028019069531,-23.338883339699279,32.857600828645431,50.77555198431179,-22.801084863076834,-5.3545294003584223,-24.515986586346678,13.738284159840884,33.653577026064099,14.987389696911123,35.708800411164056,7.4266008163962356,43.488065096494651,6.802261875838715,52.24235472801044,22.340297295144069,32.230667753148161,21.151854607761326,52.264939991896803],"text":["Input: '1 london county council distri' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: '1e commpolitie' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'accountant' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'accountant office messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'adjunctcommies bij het departement van bz' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ambt 2de klas der liniedienst' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ass boekhouder' (lang: nl)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'asst assessor city' (lang: en)<br />HISCO: 31030, Description: Tax Assessor","Input: 'attorneys clerk law' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'auxy postman greengrocer' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'bank inspector' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'barister clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'beadle' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'besteller' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'besteller en not mentioned in source' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'blank clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bode provinciaal geregtshof van overijssel' (lang: nl)<br />HISCO: 37040, Description: Messenger","Input: 'bokhaallare' (lang: se)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'book keeper' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'book keeper provision trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'book shop porter' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'bookkeeper' (lang: en)<br />HISCO: 33110, Description: Bookkeeper, General","Input: 'boot repairer errand boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'brakesman coliery' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'brewers hay clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bunkin clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'bus conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'c s o rural postmistress' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'caol clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'capt roy guard reserve' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'cashier' (lang: en)<br />HISCO: 33135, Description: Cashier, Office or Cash Desk","Input: 'cashier 'asbestos merchant's'' (lang: en)<br />HISCO: 33135, Description: Cashier, Office or Cash Desk","Input: 'checker' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'chervant' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'chief clerk to insurance coy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'civil servant' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'cl h m castoms lon' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'clerical officer ministry of ?' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk at bradleys westbourne g' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk at ch' (lang: en)<br />HISCO: 31040, Description: Customs officer","Input: 'clerk at wire works' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'clerk b' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk chemical merchants' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk confactor' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk cork mercht' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk drapiers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk ed in burgh city roads' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk file warehouse' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk fo work' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk galvanisine works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk general store' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'clerk genl po london csc o' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in an office' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk in coal of' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in coke wks' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in county court cso' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in liverpool bore gate' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in london city mission' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk in merchant office' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in paint works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in statehouse' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in stoneware pipe firm' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk in truck agency' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk lower divn admiralty' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk mercanetile' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk of insticiary' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk of works' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'clerk on hogordgis' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk or warehouseman' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk plate works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk po c serv' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk provision salesman' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk rectory standish' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk rly cos' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk shoe trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk silk curtains' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk stampers brass' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk steam ship coy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk steward golf' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to a brewery compy' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to a doctor' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to an insurance company' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to assistant overseer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'clerk to bedding manufactr' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to iron works' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to manuf chemists' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to no s' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to publisher' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk to the general steam nav' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'clerk tob manuf' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk trunks makers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk wholesaler fruit merchan' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk wine brokers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk woollen cotton dye hou' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerk woollen mall' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerkcoal merchant' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'clerks printing office' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'coal companys clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'coast waiter' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'collecteur en not mentioned in source' (lang: nl)<br />HISCO: 31020, Description: Tax Collector","Input: 'collector' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'collector (deceased)' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'coml clerk chemical but ens' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'commandeur op de werf en not mentioned in source' (lang: nl)<br />HISCO: 33190, Description: Other Bookkeepers and Cashiers","Input: 'commercial clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'commercial clerk silk brokers' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'commies dept fin' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'commisgriffier' (lang: nl)<br />HISCO: 39340, Description: Legal Clerk","Input: 'committee clerk and bookkeeper' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'comptoirist' (lang: da)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'conduction pullman pc co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'controleur bij de landbouwcrisisdienst' (lang: nl)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'corporation clerk' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'correspondence and shipping cl' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'custom house boatman' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'customs officer' (lang: en)<br />HISCO: 31040, Description: Customs officer","Input: 'division officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'dressman h m d y' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'earant boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'engraving clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'eo toldfoged' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'errand bot milliners' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy school' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy grocersmess' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy in office hupping' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy johnson grocer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy stationers temporar' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy still at school' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'errand boy to joiner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'examiner of master maker bond' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'excise officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'facteuse et detenu' (lang: fr)<br />HISCO: 37030, Description: Postman","Input: 'fireman in fire brigade' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'florists officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'flour and grain merchants cler' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'fruit commission agents clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'gartar clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'general clerk and house and landed proprietor' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'general merchants clerk unempl' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'goods agen of railway co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'h m coast guard cond boatman' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'half timer to a confectioner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'high bailiffs clerk county cou' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'hoofdambtenaar bij gemeente secretarie' (lang: nl)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'houseservatnt' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'husfader by og herredsfuldmaegtig' (lang: da)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'inspector armory' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'inspector of poor slater' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'inspector of schools, ireland' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'inspr of poor collector of rat' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'insurance clerkess' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'insurance cos clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'insurance official to the offi' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'iornmongers messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'ironfounders agents clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'jagtopsynsmand' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'jernbaneassistent' (lang: da)<br />HISCO: 39960, Description: Railway Clerk","Input: 'kantoorknecht bij posterijen' (lang: nl)<br />HISCO: 33170, Description: Post Office Counter Clerk","Input: 'knecht bij van gl' (lang: nl)<br />HISCO: 39990, Description: Other Clerks","Input: 'kolskrivare' (lang: se)<br />HISCO: 39120, Description: Dispatching and Receiving Clerk","Input: 'korenmeter en not mentioned in source' (lang: nl)<br />HISCO: 39150, Description: Weighing Clerk","Input: 'kronolaensman' (lang: se)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'kustupplysningsman' (lang: se)<br />HISCO: 31040, Description: Customs officer","Input: 'l c c tram moterman' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'laensman' (lang: se)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'law articled clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'leader railway goods dept' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'legal services other' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'letter carrier bristol post of' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'letter carrier nypo' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'letter carrier p o western' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'local' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'mail messenger p q' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'managing clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'managing clerk county cowel' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'managing clerk dry saller' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'mercantice clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'mercantile clerk jute trade' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'merchantile clerk junior' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'merchants clerk pawnbroker' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'message boy at percy st nc' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'message boy grocer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger at' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger at b warehouse' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger boy post office' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger eastern telegraph co' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger re mint' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'messenger town s s comp' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'municnipal service finance cle' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'office boy jewell' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'office clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'officer of fisherier' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'oproeper bij notaris' (lang: nl)<br />HISCO: 39340, Description: Legal Clerk","Input: 'order clerk steel wks' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'parish clerk' (lang: en)<br />HISCO: 39990, Description: Other Clerks","Input: 'parlors errand boy' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'pensioner prison dept' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'photographic factory messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'poor law service 1st assistant' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'porter errand' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porter leather trade' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porter millinery' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'porters labourer' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'post boy' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'post office cleaner' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'postbud' (lang: da)<br />HISCO: 37030, Description: Postman","Input: 'postbud logerende' (lang: da)<br />HISCO: 37030, Description: Postman","Input: 'postman' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'postman st martins la grand' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'postol clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'preventive offficer h m custom' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'prison officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'railway booking clerk' (lang: en)<br />HISCO: 30000, Description: Clerical or Related Worker, Specialisation Unknown","Input: 'railway clerk and seperated from husband' (lang: en)<br />HISCO: 39960, Description: Railway Clerk","Input: 'railway coach guard setter' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway goods guard farmer' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway guard gt western ry' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway guard s w ry br co' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway passing guard' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'railway servant' (lang: en)<br />HISCO: 39960, Description: Railway Clerk","Input: 'railway ticket examiner and out pensioner of chelsea hospital' (lang: en)<br />HISCO: 36020, Description: Railway Passenger Train Guard","Input: 'range warden' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'red postman' (lang: en)<br />HISCO: 37030, Description: Postman","Input: 'relieving officer registor o' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'relieving officer registrar' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'rent collect clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'retired chapter clerk and regi' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'rolling m clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'school master of parish regi' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'school welfare officer' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'secretary c e z m s clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'secretary of colliery clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'seedmans typist' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'sergeantschrijver der koninklijke marine' (lang: nl)<br />HISCO: 39320, Description: Correspondence Clerk","Input: 'sergeantschrijver kon marine' (lang: nl)<br />HISCO: 39320, Description: Correspondence Clerk","Input: 'servants registry officer fa' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'sexton' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'sheriff off assist' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'ship broker chartering clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'shipworkers clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'shop keeper' (lang: en)<br />HISCO: 39140, Description: Storeroom Clerk","Input: 'shop messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'shorthand law clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'signal man l and h h' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'skoleinspektoer' (lang: da)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'sola officer' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'solicitor assistant clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitor parliamentary clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitors cashier to magictra' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solicitors clerk articled' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'solictr clerk' (lang: en)<br />HISCO: 39340, Description: Legal Clerk","Input: 'sorter and packer' (lang: en)<br />HISCO: 33170, Description: Post Office Counter Clerk","Input: 'spannridare' (lang: se)<br />HISCO: 31040, Description: Customs officer","Input: 'stockworkers clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'stopman district board' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'store keeper h m convent dept' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'storekeeper' (lang: en)<br />HISCO: 39140, Description: Storeroom Clerk","Input: 'strandfoged' (lang: da)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'supt dockers h m c c s off' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'surnummerair rksbel' (lang: nl)<br />HISCO: 31030, Description: Tax Assessor","Input: 'surveyors clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'telegrain messenger' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraph construction dept mi' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraph messr c s' (lang: en)<br />HISCO: 37040, Description: Messenger","Input: 'telegraphist' (lang: en)<br />HISCO: 38040, Description: Telegrapher","Input: 'time clerk' (lang: en)<br />HISCO: 33990, Description: Other Bookkeepers, Cashiers and Related Workers","Input: 'toldassistent' (lang: da)<br />HISCO: 31040, Description: Customs officer","Input: 'tolmeester' (lang: nl)<br />HISCO: 33160, Description: Cash Desk Cashier","Input: 'tramway conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'travelling clerk surveyors dep' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'trtamcar conductor' (lang: en)<br />HISCO: 36040, Description: Bus Conductor","Input: 'tugowners clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General","Input: 'uss boat inspecter' (lang: en)<br />HISCO: 31090, Description: Government Executive Officials Not Elsewhere Classified","Input: 'visiteur bij de directe belastingen' (lang: nl)<br />HISCO: 31030, Description: Tax Assessor","Input: 'warder' (lang: en)<br />HISCO: 31000, Description: Government Executive Official, Specialisation Unknown","Input: 'wholesale competioners clerk' (lang: en)<br />HISCO: 39310, Description: Office Clerk, General"],"mode":"markers","marker":{"color":"rgba(215,144,197,1)","opacity":0.69999999999999996,"line":{"color":"rgba(215,144,197,1)"}},"type":"scatter3d","name":"3","textfont":{"color":"rgba(215,144,197,1)"},"error_y":{"color":"rgba(215,144,197,1)"},"error_x":{"color":"rgba(215,144,197,1)"},"line":{"color":"rgba(215,144,197,1)"},"frame":null},{"x":[23.174523947609913,24.661144601952511,-34.060891009641338,-33.880148423131729,65.503348963495725,71.326539408423415,107.4616431590308,105.44964795394762,107.62859328017761,35.316467941652235,64.673721550533685,107.39764634878749,108.76071654717947,108.66660942536461,-34.377008139901413,34.181698297480395,-33.161915470387314,23.510755428028322,38.346863900660942,105.83676832742388,-151.38372827065874,40.720705276469886,-16.983954716965712,31.270603107160898,84.574799350511299,52.931535936555292,58.021869291164109,25.7456956102756,-10.527386888622795,24.673982452005632,35.416097827562311,-13.437284659152889,24.022496238066378,23.301355779256792,-27.337104765620019,37.107464279792232,74.16305430173135,25.326306239258464,21.807583750665373,62.535285640568425,22.981734215331077,-17.710024765485404,-7.9163707606628888,24.599495522553973,-5.8177508747684366,-11.16917730908817,54.192287435720594,-33.026365857642439,-30.98069578139204,-34.379635357392687,-30.283986529954525,36.415069840755692,37.04105864955276,74.173598725799465,-18.738050470594985,29.951255605181345,-8.5267987059106254,22.916365992066247,-12.587157414208905,-12.498534150857155,-12.610914106798582,42.028874307786481,-11.026282334449029,33.406775053284001,54.133494337317337,-16.076492849345797,-11.052206930346854,-19.243855454315963,-10.337547492544697,-10.321543386809594,-10.846339662941217,21.613047355024719,27.692703595995699,37.543996546903323,53.745107429683024,37.677681817915378,24.528370777997079,29.759283508588783,26.62007114170159,-4.7973607767690929,-16.40077128271194,-17.832978430771735,33.864156171088268,26.450260818455121,24.480155854072674,37.892661143926475,33.935773934637226,-39.650822002096639,-7.4408029660274222,-6.3687652012523852,-29.247394054114679,32.319358423035567,106.14336994657634,105.74008299908985,108.22151292743682,22.536700294484422,-14.753381829694822,-13.58529812472778,23.916111566678801,26.218448486947615,25.554282929224094,26.077813178390585,26.14290588707965,34.141832432821268,33.301369776335882,-16.701899806078735,-17.299436091158999,11.948966722992246,27.613256574790505,37.204054750188504,38.503690067018923,31.965750470233544,42.342707496060193,-16.144749723183299,106.68503916236875,25.14822706152129,23.107745427753294,36.292674693315114,22.831011430323716,-35.447853308319409,74.245553213247945,36.351712081560322,34.821576299267576,90.386352663889411,-8.3993561887691364,-5.8563814081208028,24.974578490298342,105.67380520154676,21.423488269092918,20.838138983910635,-16.191097991549661,33.923818088057736,-8.7374307770363355,38.837511269947079,41.942175155383296,85.204926294675076,-20.63206568632846,-17.543330125076949,-19.671727541591405,-18.621705572412008,25.269878227702979,-1.4667069808189901,22.319756328539707,22.65666125347866,105.60875349422965,103.90593391334667,36.621532510231802,37.127407437768248,23.891197028318032,-150.47163484291821,105.7074582075319,53.791053060452761,-12.967727693594764,-13.319491649553184,-10.659501838479448,26.752484547947038,22.454761105358227,21.775646572294697,-9.0388516851541265,-12.135033134722145,-35.612263081619538,-35.247271339626934,22.814164548950295,58.22830516798674,27.606095787391506,89.745513737994145,41.991161599255818,24.753557709719633,20.396884764548449,-11.141698259487592,26.552818765002083,-27.153379453231118,42.002815126680538,37.116800067041531,34.409744258859021,36.679051395056064,-104.124744201551,22.897691454341953,22.286422311812,-8.2335029347611641,20.929935629748009,36.315302953795467,-7.4381357215599984,-6.2987377163656522,-9.6351872456959651,-32.226905003673672,-30.492419621602398],"y":[-25.060816575005923,-19.624970262257953,110.00584115989029,111.36331401359617,44.37329402941436,-1.4472993821847584,77.18997758191729,76.716720414789094,77.474174860785652,51.023847176944976,42.952006624218093,79.438315750249942,77.29114872923806,78.4107887622894,111.44547295753999,48.577146996207503,50.912959507190124,-23.98080137374448,52.572232296837278,75.65639085094223,4.2845437047052055,51.175125718630682,-16.442311286483424,-44.545210989424454,78.096259448070754,-40.97833098411455,37.786418240012701,-18.619263872911823,-81.088600612490282,-24.360280206371932,50.499472149893968,-89.820243909461013,-21.195283196376657,-22.816103196625907,-24.530784314236353,50.91012611832538,-5.1498088791752235,-24.500367521467169,-22.014787392466292,41.117388584787577,-20.848623384282902,-23.105807386454241,-89.798162775493566,-17.896079238349394,-88.072073447065762,-86.240926251096596,-41.136550300694907,109.71199234064449,43.852690509838197,108.73866640856598,53.13198665158712,41.491776486542904,46.863101185828704,-7.8080951338229232,-13.59916801188635,-24.775681062860883,-86.804017225776022,-22.416776344107127,-85.96615022964771,-87.352370214328062,-88.391504748811627,62.175779545515368,-87.085027046517695,-44.750849371021893,-39.563126887821149,-19.922815900360295,-84.899210646412996,-18.628468243382283,-86.518085859468641,-88.295079452035125,-89.530081039487911,-61.747449701025666,-66.09729407756231,-58.249578609333334,-41.516262019052803,-58.839232418317103,-63.170955078163985,-23.869772891162516,-24.699182220019289,-87.32272546772495,-19.370997635013797,-20.661462226861964,-45.902352375150244,-65.08075094987376,-18.99570626207435,50.198131030342552,-44.655625752227415,-113.21458063201746,-87.623627090778626,-88.834949690573865,112.25764699353071,-42.27299256250668,79.901563815895884,80.254583804375869,79.864260797592863,-17.649853163861035,-84.960952734834692,-85.642110612107516,-62.84054454166764,-26.454756624522133,-25.1253763556956,-25.955755142866757,-23.418561624420178,-43.532384596969649,-44.580102900918568,-23.31634995907233,-24.148368168021012,85.934528027668506,-23.289034693428246,-56.711511356780932,49.644180528754312,48.919442683955708,55.087145689151363,-17.015800526871249,78.009136157570637,-20.386155502321834,-43.348876993741541,47.421928929770395,-22.227117880217079,109.98597920833993,-4.462467884833714,41.018008174535623,-49.068766311342095,75.612560372795556,-89.328737669883253,-87.014543821196526,-26.809184653414437,77.813903250643833,-24.070967823003738,-18.845157620200624,-18.340517699780868,47.427193726565164,-83.585037882203366,50.921961152615467,57.757068014884574,78.472292601387295,-16.784699647278792,-16.329978146125693,-17.036742306460066,-17.660549106602424,-21.397553681271969,13.129071886785367,-26.190413831984483,-26.202854106665178,78.901951479566989,78.366451976833488,43.042588137782452,-56.088779777482202,-43.064834280494708,5.6576467241023938,78.315503588218732,-40.273380957349431,-87.687834871111278,-90.414030611382273,-85.095074618691726,-26.078485125991048,-61.783471030472029,-24.592939388965423,-85.240056486623189,-78.835045095711507,110.00315374699596,109.60062423411354,-41.924938058795,37.956431518801729,-17.073086975826534,74.178087500882398,52.514487022553681,-22.27134627900714,-22.141784791454882,-83.827377128777016,-25.889300789498254,-24.359590187835195,63.009174931045308,48.152883282826572,-46.456270102537161,44.469377584641897,-9.0263334152692227,-42.181230126188289,-43.217342540640935,-87.612036911612549,-24.502932538514866,49.039596159593977,-88.305520828286618,-86.515271918888288,-85.236387029413862,110.71739410410231,111.65484049149542],"z":[105.954109052215,100.11588224543421,-18.409048085022686,-20.489104070078898,61.181688455944098,42.59684101334237,55.134867041149839,54.566385553265249,53.405141902529948,0.42894046491720061,62.21111010392778,55.925821285936912,59.249772443429293,57.029772702119459,-19.449733088380729,-4.6728366803424448,-0.89401022177857536,103.89266204339941,-1.3087686837738406,56.239065657341833,61.374558845287631,2.036490417654218,76.158596323390981,-0.21067635006296062,58.78381434709538,-17.241398576426899,66.491795050360096,97.84935982155217,76.772270301919434,101.57551294268806,-4.1574516772562378,73.415210569008664,106.2491876553306,107.05847514607039,49.988046217967089,-1.5453137711993958,44.795931098395577,106.91387365526197,104.89897100207767,63.725705248801333,103.63265146914779,77.305928705283236,74.130147759671686,99.225464483951455,69.264518992526234,75.122817412528192,-16.81166500897805,-19.640064562700658,-6.51194426734064,-17.840038579709208,-5.1714771763074729,5.8543395772557387,0.46823412437387518,44.900932253821217,75.293632353450576,98.00115836843915,77.962355898765821,102.20656043508015,71.455072904523149,73.182785437943267,71.328076119508168,-77.862816103461185,67.865476646891807,-1.0084735280616066,-15.010423384264628,77.700360156346534,72.782028339105352,77.014140963771325,72.682971947222342,75.539759647355453,73.655501998503965,2.836502297734266,-0.1804369182206487,3.7440001483831296,-18.256483887975236,3.3558249048466107,1.104913005086833,103.67871739884299,103.54485154026555,67.174164524401831,75.428270317905827,75.265669345902211,0.55585512414052407,0.34253017382196188,97.293634700176383,-0.35560922787240773,1.8001868659070142,-33.131165034009179,68.91583134865472,73.422121208584485,-16.156202094739029,-0.9930455488441553,57.494981491546731,55.541653011272423,53.618592731653251,100.94105769798297,72.586429180713083,74.158909683561532,1.3977925711157104,94.603307890543931,96.941739136924326,95.503776069732041,105.66672533820076,3.2108527103385156,0.36223293867713985,76.897073752523113,77.318769387522593,-9.4423108556373201,100.16151602358607,4.8026999297864927,-1.4701836479401023,-4.7011974695056091,-0.41511297206337372,74.220606900155261,57.641116372279122,98.012393597650885,64.575223564120236,-0.98954362271679563,110.86195209714182,-16.496773324127073,44.874740225932001,6.2696418232345259,-3.0001974313647199,50.644295468639314,71.331380359144632,68.340312896232845,103.08083239530565,52.15920080116787,106.48473238856715,103.40697414759943,76.353957772198171,0.14289415678887898,73.606308566963378,-3.1369295920781499,-77.897392050784291,59.857404895555938,76.925209453008662,73.191635124227815,73.940019654541729,75.612699241546451,95.933212239507029,-83.572091694279152,103.72279954943863,101.17766211592982,54.178713116456386,57.070825449981193,4.488314360154666,5.4345290182685684,65.763695852873894,62.367799227530114,56.02971111710886,-16.644270779578299,75.534475788973822,70.593804538863964,68.309157293491424,98.675984627301744,1.9658986384545565,102.20443037342703,75.010070672142405,78.355822975933464,-21.392170170604746,-19.221773321547456,64.586983604912618,66.375304530968435,97.839262140463347,50.584306766602133,-1.9355714430352,103.55995578868573,102.31608364546538,75.202818486844293,105.70013778566376,50.002876899479631,-77.812380398102775,-2.9665652505169589,-1.8498504388077881,2.917822171347455,-18.440524183635596,66.061975617531886,65.705544657889902,74.27084166165308,104.0284119634638,-3.9912265104294078,75.646312964833115,72.049740227370791,70.160567494338395,-17.073673371747763,-16.621586990433435],"text":["Input: '* merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: '? dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'a steam plow engine driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'ag threshing machine owner' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'agent' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'agent der spaanse schatkamer' (lang: nl)<br />HISCO: 44220, Description: Business Services Salesman (except Advertising)","Input: 'agent for bradford stuffs' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent for debts' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent for wholesale clothiers' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent glass house' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'agent mine' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'agent prudential insce' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent to a distiller' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agent to the prudential assura' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'agricultural threshing machine' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'and adopted child' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'and also repairs damaged wagon' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'antique dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'architect surveyor agent' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'assist to adrt agent' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'at school part time milk boy' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'auctioneer and valeur' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'bedlar' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'bloemenhandelaar en bloemist h' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'bookkeeper pawnbroker' (lang: en)<br />HISCO: 49020, Description: Pawnbroker","Input: 'botiguer dependent' (lang: ca)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'broker (deceased)' (lang: en)<br />HISCO: 44140, Description: Stock Broker","Input: 'cattle dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'chemist' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'china dealer etc' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'cleaning and dusting' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'clothier' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'coal dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'coal merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'commercial traveller' (lang: en)<br />HISCO: 43220, Description: Commercial Traveller","Input: 'commissaire priseur' (lang: fr)<br />HISCO: 44330, Description: Appraiser","Input: 'commissionair' (lang: ge)<br />HISCO: 43230, Description: Manufacturers' Agent","Input: 'coopman en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'corn dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'corn factor' (lang: en)<br />HISCO: 43200, Description: Commercial Travellers and Manufacturers Agents","Input: 'corn merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'cramer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'cruyenier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'detailhandler' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'draper's assistant' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'driver of stoking machine' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'employed as handy boy during c' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'engine driver for steam raper' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'engineman stationary above gro' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'estate agent' (lang: en)<br />HISCO: 44130, Description: Estate Agent","Input: 'estate agent police pensioner' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'factoor en not mentioned in source' (lang: nl)<br />HISCO: 43230, Description: Manufacturers' Agent","Input: 'fancy goods hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'fellmonger' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'fish fryer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fish merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'fish monger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fishmonger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fishmonger (deceased)' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fly proprietor' (lang: en)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'fruiterer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'fruithandelaarsknecht' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'garage hand' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'gardfarihandlare och undantagsagare' (lang: se)<br />HISCO: 45220, Description: Street Vendor","Input: 'green grocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'green grocers shop hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'greengrocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grocer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grocer (deceased)' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'grossiste en confiserie' (lang: fr)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'handels' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'handelsbetjent' (lang: da)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'handelsbitraede' (lang: se)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'handelsfuldmaegtig' (lang: da)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'handelslaerling' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'handelsman' (lang: se)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'handlanden' (lang: se)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'handlare' (lang: se)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'hocker' (lang: no)<br />HISCO: 45220, Description: Street Vendor","Input: 'hoedenverkoopster' (lang: nl)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'honsekraemmer' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'horse dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'house land properitor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'houthandelaar' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'husfader fisker' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ijsercraemer' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ijzerkramer en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'in comission store' (lang: en)<br />HISCO: 49090, Description: Other Sales Workers","Input: 'in oud ijzer' (lang: nl)<br />HISCO: 49030, Description: Waste Collector","Input: 'insurance agent' (lang: unk)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'insurance agent laundryman' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'insurance agent music teache' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'iron merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'iron monger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'ironmonger' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'jernhandler' (lang: da)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'kjobmand' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'kobm' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'kobmand' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman ongergoed' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'koopman op groentenmarkt' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'kraemer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'kramer en not mentioned in source' (lang: nl)<br />HISCO: 45220, Description: Street Vendor","Input: 'lab proprietor and driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'lace dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'lakenvercoper en not mentioned in source' (lang: nl)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'land house fundholder' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'land mixer for moulder' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'land surveyor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'licentes hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'life insurance agent pearl' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'lime merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'linnekooper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'lisecensed house agent baili' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'machinist' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'machinist agricultural tract' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'maeglerassistent' (lang: da)<br />HISCO: 44100, Description: Insurance, Real Estate or Securities Salesmen, Specialisation Unknown","Input: 'makelaar' (lang: nl)<br />HISCO: 44130, Description: Estate Agent","Input: 'malerforretningsassistent' (lang: da)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'manager to financial insuran' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'manufactuurwerker en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'manufakturhandler' (lang: da)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'marchand de blé' (lang: fr)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'master bank land insurance a' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'metal dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'milkman' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'millers and grain merchants ag' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'newsagent' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'none derives income from land' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'ostler' (lang: en)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'pawn broker engineer' (lang: en)<br />HISCO: 49020, Description: Pawnbroker","Input: 'peddlers of tobacco' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'peddling pictures' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pedlar d g' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pedling y no' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'pot dealer' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'pot man' (lang: en)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'provision dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'provision merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'prudential assurance corp ltd' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'prudential insurance collecter' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'real estate wrks' (lang: en)<br />HISCO: 44130, Description: Estate Agent","Input: 'salesman' (lang: en)<br />HISCO: 45125, Description: Salesperson, Wholesale or Retail Trade","Input: 'salmcoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'school part time wollen roving' (lang: en)<br />HISCO: 45240, Description: News Vendor","Input: 'sciptn life assnce agent' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'shop assistant' (lang: en)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'shopkeeper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'shopkeeper deceased' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'shopkeeper draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'slikhandler' (lang: da)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'spannmaalshandlare' (lang: se)<br />HISCO: 41020, Description: Working Proprietor (Wholesale Trade)","Input: 'spirit merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'stationer' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'stationer and print_s' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'steam plough labourer' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'steam trawler engine driver' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'steenkooper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'stock broker' (lang: en)<br />HISCO: 44140, Description: Stock Broker","Input: 'stock dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'superintendent of agents life' (lang: en)<br />HISCO: 44120, Description: Insurance Salesman","Input: 'surveyer' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'tallow chandler' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'tea dealer' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'tobacconist' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'toebacqverkooper en not mentioned in source' (lang: nl)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'traveller' (lang: en)<br />HISCO: 43220, Description: Commercial Traveller","Input: 'verhuurstrijtuigen' (lang: nl)<br />HISCO: 41040, Description: Working Proprietor (Hiring Out)","Input: 'victualler and land proprictor' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'visverkoopster' (lang: nl)<br />HISCO: 45130, Description: Retail Trade Salesperson","Input: 'w martin estate agent' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'walking stick hawker' (lang: en)<br />HISCO: 45220, Description: Street Vendor","Input: 'wijncoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'wijnkoper en not mentioned in source' (lang: nl)<br />HISCO: 42220, Description: Buyer","Input: 'winckelier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'wine merchant' (lang: en)<br />HISCO: 41025, Description: Working Proprietor (Wholesale or Retail Trade)","Input: 'wines and spirits' (lang: en)<br />HISCO: 44330, Description: Appraiser","Input: 'winkelier en not mentioned in source' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'winkelier lederartikelen h' (lang: nl)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'woollen draper' (lang: en)<br />HISCO: 41030, Description: Working Proprietor (Retail Trade)","Input: 'working clothing store' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators","Input: 'works in decorating store' (lang: en)<br />HISCO: 45190, Description: Other Salesmen, Shop Assistants and Demonstrators"],"mode":"markers","marker":{"color":"rgba(205,180,144,1)","opacity":0.69999999999999996,"line":{"color":"rgba(205,180,144,1)"}},"type":"scatter3d","name":"4","textfont":{"color":"rgba(205,180,144,1)"},"error_y":{"color":"rgba(205,180,144,1)"},"error_x":{"color":"rgba(205,180,144,1)"},"line":{"color":"rgba(205,180,144,1)"},"frame":null},{"x":[42.454098780085928,69.428376710386559,72.422471705399531,76.092026571258828,33.322119849729901,68.384561860437074,76.890827573047389,75.789856869451569,95.05605126473705,68.326620507527494,21.79825485076999,18.259220268847923,17.885786436632536,74.200329492557444,43.753965238940985,-58.52525001293079,99.48985132176773,65.985556472714947,42.975309452467741,28.650517709040294,48.735347547558362,72.877091232370418,61.846868688017473,61.216960978710404,70.635682715612788,75.146509825142161,87.911462974073416,-41.708482702449359,42.266965669249572,70.59716687627477,74.503517995392556,76.301074930813328,67.837956550704192,73.307331576840554,-39.032257893238786,-119.86519000064091,109.39901884596999,75.433883528234091,30.282257907180142,71.73677931514959,115.97716206358896,93.274192762791373,68.035544796608832,68.712107652961549,68.573238873379935,66.100453481853151,66.015877391975224,68.221205443407811,69.113728894905265,78.910992883007353,84.420457497211999,102.5818837129122,83.407029086752146,77.748167582350803,77.901016628869485,72.920133190514534,81.451099661285724,75.089120187264157,70.03391510599927,75.717647174829509,71.094525612557476,67.059183751007382,82.843102168100316,93.701456145666626,75.622784804513131,113.6890776144235,67.590832995184158,93.642475376068319,97.017623505939724,65.003781890680713,95.651392151192923,84.378180286571677,97.201299786011177,95.777725847942733,93.696254620028768,88.405780900491749,109.08621611408795,109.51053025782926,67.389693434592999,73.49906945397808,42.960175061804485,66.496475231323544,67.978820361614552,33.814722199313188,79.434330826182489,78.965911856897733,70.099544886220016,62.273850574347549,62.823952924792351,76.878514772113604,99.812965604169207,77.581174134884265,88.280944543885028,113.41401743842593,105.9621758924837,104.17004458495808,104.73783480583087,103.02604328939236,-69.902719223263915,-69.743217168516054,44.710279435612165,45.586767408605702,101.2141104593488,-14.762555996447032,70.707028674274142,32.990405343205069,49.120276362513756,32.290879908673958,72.606451400759425,76.297227160375954,72.126705515415296,25.929242896545762,24.152552018142703,75.293357389678135,69.795019983987686,75.395795547019574,74.30644363486158,72.750180915752779,107.41657256001653,72.311464862162822,74.281062800746085,71.715145935523609,74.18858818636825,35.348511484372196,73.90515447886817,72.859897348608015,103.80627399263822,94.613984504107805,60.557056785528836,26.072384667823602,23.14098279129065,25.785650492578981,79.281126564121081,20.47317213250443,20.636063427585206,-1.1038392159329287,82.653619203528734,74.078178058494515,75.309099668730084,62.761673251431667,72.663278519906029,72.374407675212368,63.569461915839064,70.480518197260366,64.586789290146029,32.614039604627209,68.849621032669447,70.679615492040767,61.933539990588358,101.24036783637312,29.947422887212124,92.673345013320798,111.58365833998154,13.706370523718778,27.293961748902568,14.16686948645645,14.61459396922543,30.537565118976424,17.784041944842532,60.985918593769902,8.0105506286748032,28.539156708876501,96.922241756346921,61.059899721429893,83.53629840541123,61.598854731003534,83.080174089390596,59.044181652991746,60.183575224117199,26.641086737378199,73.203285312294909,72.920417287221014,74.202165329978783,48.806201511974578,101.57989107155927,99.331897125643025,114.48296665180348,49.827898550394167,91.239624688773375,79.871029214456357,93.293746153062642,95.509769143595278,41.567288956015773,73.879524910834817,74.69435641292705,31.848194631755948,62.565855340723708,22.112637142795702,72.256976920019611,71.930169947003094,72.569564248920727,76.027407447941641,73.82765462482449,67.698690309867629,72.530345168986955,115.15430887802783,72.05488058871714,85.033102557449823,115.80358617338432,113.28248460007921,112.46094988123099,116.69491504568211,117.33084576671772,114.53109631136722,106.04593631374091,115.43699329130489,109.72288781594432,42.290669459144048,43.839800298756451,45.997709591029562,-38.577647512125374,37.327422807577562,104.5853417058122,102.87406263405434,104.19769643106049,105.33307740243049,70.483007983542706,27.597219142895746,14.070818983464553,24.796327692720464,67.17256663151079,35.947202753607918,35.530401238356887,71.194762608765856,34.675632730559585,88.053104424227485,72.950098411449915,77.627760117316981,114.43755500699862,-40.733088112580738,95.553330538789623,98.802445676724489,90.000683392624097,101.31351913941748,67.921013611155146,77.313680771419357,66.900323323531779,70.872572109567045,70.290319453525271,65.831241194527692,69.055561590897838,110.64322011903667,72.796757209283868,70.990087357461817,66.220623965938103,72.114699365901586,73.065403747694162,64.012505391433436,75.351294654300176,75.718182938288265,48.427562083133559,75.865518100773741,86.457726316068431,85.483735320371139,28.553431576463794,85.909467804268701,98.627059936002581,104.93810667567428,105.85826090541777,106.2226007817351,106.61398029260837,106.20537046247607,97.262657512338777,102.8553474546049,91.000848479865908,90.032888235147226,88.515269302802096,90.050425906469698,105.30589360786294,102.17694223819295,103.71662541130925,103.08802279891796,84.559335218263939,103.15900084225675,85.773483660518096,86.525792349225611,85.058928066420592,78.726793367439086,45.043090876119443,70.12621625260239,70.380343273717145,77.796784994688849,115.24904550558767,-44.841829991804161,28.087647636636415,64.167751513806138,65.931728998775029,64.790742228669231,65.286244199615567,64.58128877148323,34.75575170081094,27.827718688761831,76.578147617879381,63.473945741699062,-28.690264776919165,72.229688661291163,27.999804001579179,70.411736407004724,87.049022701493172,110.75634686178059,77.324901183189155,32.768679461538724,28.77390204531336,15.749735946711874,94.315158480539466,90.686355342015332,72.114498956242869,71.905140958255899,78.691760211528845,-38.773613427102191,-55.066065011959402,77.610018404994449],"y":[64.843460767484729,-25.840952853837532,40.074341683109353,75.768327891405406,53.470046396988799,22.882143775411496,46.694377711884734,46.838472114132884,-54.460988704683587,-28.931281292502852,-85.932158651068221,28.71139399306027,29.259226810627364,-21.796213104808256,71.435227692756015,35.502545745154038,-56.473213131727327,18.356446272410338,66.184632782865975,41.133755001065573,0.75632553664219238,24.377417357454629,-18.716872185907988,-20.157100794006716,-28.781710233079114,110.28851799784618,4.3026818090981589,29.637927277809098,66.384239015185656,22.382199652569767,30.171998808175509,109.20744688149672,21.047418763625807,35.923004228530552,29.973249868671079,57.951397432224269,18.8516071576313,73.408408493971066,26.372449369266569,-0.45341685160951223,18.218703708513811,-57.387147824257632,19.572005709403971,19.479683618968323,21.319548295247298,21.254773418209144,22.990074458837576,-30.180907593563632,-28.417528254347939,25.050697034115164,21.010652932636312,-61.948066125868955,21.127710271442488,30.341349196393232,31.462677255401051,46.149386004460091,23.802845265860164,33.369797768316388,-117.83176459256511,31.166326196370328,45.950181464373856,-10.084294160563577,19.717268019580985,-55.632760726010368,109.86205130720474,15.090074245672174,-18.941701947224772,-56.240006676127287,-55.001890408817729,-30.968208833842965,-56.313927785149303,18.556861247997581,-57.703464713148186,-58.567087968147234,-56.066461383385189,-37.467691897825553,18.620826598589446,12.179256957232935,-27.80130230000292,44.539980489009132,64.668885767960077,-30.027011282621661,35.365487915569929,-48.005389439058476,32.784333493477455,30.597042848549219,34.223903932409129,-17.507456540999648,-17.814758898419132,25.958799386326163,-60.727534604718123,19.376172593861526,-37.243267172584225,13.180676728120201,-56.039063605896551,-54.958482190948402,-55.954291636409273,-56.414883187651974,-44.229769150814583,-44.304729839666521,70.9903711880456,70.339256821728512,-58.039024343230125,74.733912133850779,36.59420097017555,-48.626164971024437,3.1145677294856839,-49.698099952663654,35.016941182992632,36.163091843334904,4.4557911765599592,47.419838093306382,47.296893999626647,32.413033005117754,31.420196654284474,25.371136317822803,33.98356137346407,36.840517943140597,19.893715047717237,40.943760439404251,45.929722117949154,4.0946956511682586,17.287544386442036,21.874048252308711,18.442818077675007,17.774808481082413,-63.495106797718918,-58.797542247301081,-18.759829257015031,43.956915262726653,43.462320729872296,41.808855119530485,24.56329674141703,44.855840394118445,42.955325537162366,-40.754084510960666,17.601923759725516,-21.325146614538831,17.903168451627373,-18.821317473223921,41.162846476684592,41.672724438456669,-36.790475990628437,23.017224643936455,-34.126606398987875,-46.704151262835644,-27.181481322843943,36.443349337514256,-16.704418504607684,-61.199805431719071,42.125347267939027,-60.969231405133549,13.510970602555997,30.510028794274401,44.230532585962536,30.298825107279352,29.59648238969595,41.617161526364264,32.181692683092429,-17.085844471060767,-85.799366164182899,42.826865140242788,-55.214656592113471,-17.50290607897421,19.144268042726434,-15.457614876776008,21.9314675770432,-15.613896271758758,-18.359776820188451,43.285815562598273,47.472888916779567,47.556151582561874,48.628843431891568,1.1267709395674399,-60.488760793047945,-59.298887296875805,14.168754173510207,4.0622835573220355,-53.427776535767471,26.869669470172415,-58.757332505592231,-61.11254502713647,62.37928514692863,47.006092972282424,32.52272438179785,52.055984494252144,-14.194582733502056,-72.720864143336286,-50.815590215646068,-50.284936035641493,-51.842941998585474,29.354349318047813,28.015840497606984,-20.305185248559983,31.994788658613565,17.931344712231727,52.049064737562141,19.633386589374393,16.187148649020024,16.821665868541753,16.612980738582745,14.952564641510161,16.524112315922729,15.433178955205092,20.803649609335427,14.045628677452697,11.584047398140971,69.657282001274581,72.654780065929046,72.760282733819238,30.974476698354422,-79.735494768915103,-55.642305348184152,-56.301182596377529,-58.046097880930809,-57.767571039498861,-36.805116448971418,42.159636859670663,28.826330324426696,42.491642505634914,-28.294759584767565,24.323980249259524,22.668606500425682,33.350524180666618,51.529841414028382,4.8291234052145819,23.960694430154597,20.829323482736545,17.110087909501065,28.916512281325982,-56.908189901927358,-56.66915007028588,-60.736051867619011,-57.855768447136654,22.141704009083789,76.196816211925977,-31.582981981996561,-28.163655671096393,-26.883813871015075,-32.823481162324917,-25.623565720170927,17.247511468585301,-25.101122015701272,24.083457491580429,20.970033331355079,33.72417475204773,28.793886968070076,17.683720779595561,26.265060854734127,26.677200258551551,46.87221244596418,37.969823831973208,19.042596448745869,77.063197506937243,-83.763004930359983,2.6514182446205985,-56.390754550767767,-63.095631168721702,-62.80001605005819,-63.3409248724764,-61.674421534808296,-64.288094622368703,-57.885289249319506,-62.074325957921118,-58.926444538035469,-59.003078845613864,-58.499656256136397,-60.942159670692689,-59.856214904628814,-56.142947987651688,-58.417178200289172,-58.994184345935302,64.854147822020494,-52.29022251735207,3.0717218512608775,3.9105355781051152,77.026775040479748,76.07877252432057,67.460916565746061,18.776485070837431,20.093526764520806,18.789568381640812,16.925733126744152,-62.491972403381538,43.291509904023577,-12.000714031834415,-10.891035700545046,-11.787278424408875,-10.180165767452435,-31.554749263702096,46.830170191581324,-88.513137286490348,74.679168896854364,-32.466671208141371,42.279341901185035,31.899015280422304,-88.887609656789735,-36.648536535500533,2.7140675697103691,14.317102069710778,32.154534290375061,-47.817924702578281,39.418240289071157,30.467433058458791,-58.0256877561444,-55.130350585929058,27.037593878234663,-49.318988629108198,74.832006987989942,30.643972121906863,34.014688876715482,75.078490364254847],"z":[-42.21495438251884,15.784147262341696,-49.432301314483247,-54.335227514130089,-36.97430274697043,-40.005312744727803,-44.098527600735238,-45.42098755875238,-9.2898707184479878,10.952097807249178,1.6354882435554732,-34.782745677825311,-34.955610358853278,-38.762392359087073,-44.561992378984513,9.7962224335338792,-6.4376729503325718,-56.49098667594297,-43.423411756443208,-35.791400001899952,9.5498557520066605,-55.759624681663482,32.397391661734666,31.299469926657931,18.149882397197672,-42.799285939446072,-1.5976274920716798,24.831206085733093,-42.281773557560449,-61.039010709991338,-51.831491747283771,-44.27471313336536,-41.934292330083743,-61.899552327303446,27.843404269571199,-51.062689962131863,-11.468155416156259,-54.080233692418282,88.625881669273724,41.914719868907945,-12.693537178236701,-3.3184870340292507,-40.904154707517307,-41.302538020956895,-44.929107853373807,-41.653992038617261,-40.58989302010113,15.199415259289754,15.165854658327822,-57.978494919031164,-58.22424979502221,-0.27275129616294919,-59.892009438921114,-58.152626066807748,-54.554717224762634,-48.393641704149516,-58.139877554210941,-60.423092683218101,-19.982316268771811,-59.474147491799641,-47.873208702065376,-51.441863130558886,-58.860921391755618,-6.5941394753929803,-43.417475815198486,-12.965133210096761,19.57054788333663,-9.1958660958786247,-10.942601679672345,13.53832103511499,-10.501645349760322,-59.008974430914492,-11.273483417469155,-9.4072224424112232,-11.82281294139146,-5.2710682583219191,-13.096343254035908,-12.580938125150432,13.632543482743277,-47.490118261788872,-41.186744252629985,12.986238448814865,-53.634079967323409,-27.18397563004979,-54.176668155492195,-55.290474455685356,-58.86393051433874,29.676585045426769,27.210385483633431,-56.109753038562225,-6.0023955221438223,-52.276264134866508,-4.9884064699554829,-13.958802832675323,0.41101095659211062,-1.0960893223875261,-2.8461230929519963,-4.6088783697220945,42.563485278296064,42.574875196642424,-42.224128078518874,-42.382998343273556,0.46382324043509976,11.709420363262602,-48.901493334533455,-25.436905300480973,7.1609516163171483,-26.381464947353159,-51.162677814927115,-57.588713659778904,-14.155021192984794,-38.461347943079517,-38.422010409215765,-56.054881686701954,-54.100153769140505,-55.114774556501935,-56.623754253017069,-51.18874123593401,-12.27450800080719,-48.894629832647738,-46.76766711096446,-13.848389811617949,-57.244214453544593,-47.256451389039441,-57.175208719600974,-57.435510147574291,-4.0432987597755332,-4.1044716826549275,32.268245662944487,-34.951764350138795,-37.291830107098377,-36.25560451951344,-54.480265617996231,-37.885844201958271,-37.366051224067434,14.547550609990504,-59.904279427682106,-38.753761657156751,-58.967768953500283,25.207611526433144,-59.977352699990064,-58.959731320718369,13.481342847025914,-47.326234358052105,13.265132112041224,-27.010211636314587,17.027621976248685,-57.486206080622743,31.311565453936755,-4.1314492731107508,-39.57512161760782,-5.6648571164065151,-11.833103445396873,-35.46754890901078,-38.308722701011604,-34.363968554366544,-35.959795828949844,-37.703187298999367,-35.716571849236495,32.909813784388717,1.7302129220968057,-37.303360468229464,-8.3282314935184427,29.761068128811285,-60.734175966417865,32.517082346518187,-57.705819957577177,30.882431326634741,28.570191129213136,-37.329240828392209,-47.092223531598513,-45.618154484113084,-47.120738830337572,9.2044862596396797,-8.1456325508927829,-8.2783006836472062,-11.416291653716893,7.4373044574031608,-4.8046458613586287,-54.840473438507807,-8.6689091501572673,-5.8769709622185173,-43.486216144722022,-43.813742271298388,-58.206222031341966,-37.847526838106738,32.217457269295771,-21.188824339946233,-32.210016240745972,-32.184695428213502,-32.172712043331849,-56.382811438549389,-56.304583321552727,19.02373042144562,-53.866515278766336,-8.3894069868686554,24.74673969469417,-60.066611952532945,-13.65418494757405,-14.138194422164654,-11.76723361250315,-11.525910165994162,-11.889561061026031,-14.87489030391338,-12.33441026203039,-13.36850216492107,-13.227160441992975,-41.792898183903574,-40.8229866151989,-42.624318967145761,29.577604044215768,-8.1021727345827443,-6.4295785137064394,-6.9745184139308511,-7.5719812955022148,-5.8043521795835282,1.4856959423947067,-38.810415118840815,-34.835623636269091,-37.970092568517153,15.49694149533949,-47.061455047788201,-47.193328674418417,-53.238812783917545,-33.311450956224029,-2.0733633688065574,-52.936498333676028,-61.667781016084213,-12.210720680698234,26.079852319139945,-7.7838108662648029,-10.091028358366788,-7.9517851015652274,-5.0666981704556937,-40.577390202000132,-53.652212826391711,13.21210177863918,14.745383025954908,15.999304080538844,12.993474492210897,12.95454407916348,-12.671142165262024,15.145310044552152,-48.850780565182717,-55.241056640904468,-58.470511622752575,-58.318810721687193,-56.350683715868293,-52.365213591189843,-54.067254702917772,-69.236070594054596,-65.245331641464077,10.255389573349989,-57.826125173135644,-4.9105103632008573,1.4110635540519778,-3.8692450136797367,-1.4285898726031843,-4.2429088718334471,-0.57000395875647469,-2.1835938354736149,-2.2932074384405166,-7.7393437986779192,-6.0025418656216054,-6.9444931246929498,-5.7625232760393565,-5.6448215865018021,-5.1360495801320258,-4.9442343091055569,-1.8058763316509026,-3.4768984617591689,-5.367719549436897,25.998075890262623,-0.1666453812464225,0.20536165557296823,0.8868700018734611,-57.661387792334807,-55.024039602613669,-42.447244657472815,-58.272043369352126,-58.304131736930756,-51.538642542306327,-10.183271693111173,5.5692670731734211,-35.480736763777301,-51.362364795827197,-51.73639749122372,-50.612055045462675,-51.261255836327891,11.306416841047671,-3.4462635820821501,-21.542349640873937,-53.56210890927354,13.160051596924431,-8.9496118261394315,-56.401263597107416,-21.298422565640298,1.9166545265027333,0.50965160184373215,-14.567030583948215,-58.334779734170063,-26.33111476814177,-41.361680835951965,-35.034690510678921,-11.573959046028095,-5.0182079043460073,-57.863544933333166,-30.581439897601879,-54.172799401379599,29.015360049846347,-52.557673893539075,-55.154357330015195],"text":["Input: 'an mealid' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'army sergeant' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'assisant housekeeper' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'assist manageress dining club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'assistant to hall keeper bil' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'at college harley st' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'attendant at asylum' (lang: en)<br />HISCO: 59940, Description: Nursing Aid","Input: 'attendant on surgery' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'baatsman' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'baatsmanskorpral och fjaellbarn' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'barbeer' (lang: da)<br />HISCO: 57030, Description: Barber Hairdresser","Input: 'beer seller' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'beerseller' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'betjaent' (lang: se)<br />HISCO: 54030, Description: Personal Maid, Valet","Input: 'bil poster' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bill files making' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bombadier r.g.a.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'booksellar servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'brewers coller man' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'bricklay l victualler' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'brigadier au chateau de pau' (lang: fr)<br />HISCO: 58300, Description: Military","Input: 'butter servant domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'cap esquadra' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'capita graduat del batallo de carados de bergada' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'caporal del regiment de guardies valones' (lang: ca)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'car cleaner' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'caretaker' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'case cleaner carpenter' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'caterers plateman' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'chamber woman' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'charge of house' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'charwoman' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'chef' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'childrenmaid servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'cleaner charwom' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'cleardy boy steel cleaner' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'clerk police pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'club house attendant' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'coal miner now corporal in the squadron 1st life guards' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'commies ter recherche' (lang: nl)<br />HISCO: 58230, Description: Detective","Input: 'constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'constabler' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'cook' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook' (lang: unk)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook and carter' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cook at mill' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'cooks k h' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'corporal' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'corporal r.m.' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'criat servei privat' (lang: ca)<br />HISCO: 54020, Description: House Servant","Input: 'dienstmadchen' (lang: de)<br />HISCO: 54020, Description: House Servant","Input: 'do constabel i 1 art batl' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'dom' (lang: unk)<br />HISCO: 54020, Description: House Servant","Input: 'dom serv ho maid' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domest serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic and c hotel' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'domestic general nurse' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic hotel keeper servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic servant inn servt' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'domestic training' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'domestique' (lang: fr)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'domestique' (lang: unk)<br />HISCO: 54020, Description: House Servant","Input: 'dragon' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'engine cleaner' (lang: en)<br />HISCO: 55220, Description: Charworker","Input: 'ex police sergeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'exluitenant der douanes' (lang: nl)<br />HISCO: 58320, Description: Officer","Input: 'faeltjaegare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd grenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd korpral' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'fd livgrenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'fd ryttare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd soldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fd volontaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'fdfanggevaldiger och gosse' (lang: se)<br />HISCO: 58930, Description: Prison Guard","Input: 'female turnkey police office' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'fjaerdingsman' (lang: se)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'flygunderofficer' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'footman' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'franskild lykttandarehustru' (lang: se)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'furir' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'g ser' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gaestgivare' (lang: se)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'gen dom sert' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gen domes serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gen serv domestic about 1 acre' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'generalloejtnant' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'generalloejtnant i ingenioerkorpset' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'generral servant domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'gevorben soldat barn af 1 aegteskab' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gjorir innanbaearstorf og gaetir' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'guarda de la preso' (lang: ca)<br />HISCO: 58930, Description: Prison Guard","Input: 'guarde de les penyores dela ciutat' (lang: ca)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'gun smith' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner r.g.a.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'gunner, royal artillery' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'hair dresser' (lang: en)<br />HISCO: 57025, Description: Women's or Men's Hairdresser","Input: 'hairdresser' (lang: en)<br />HISCO: 57025, Description: Women's or Men's Hairdresser","Input: 'hall porter and messenger' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'hall porter instit serv' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'halvbef konstabel til orlogs' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'haulier chimney works cartman' (lang: en)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'help and housekeeper' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'herbergerer manden' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'hm forces army' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'holder logerende kone' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'home house keeper' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'home servant dom' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'hoofd huishouden bij een ziekenhuis' (lang: nl)<br />HISCO: 55190, Description: Other Building Caretakers","Input: 'hotel editor' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'hotel proprietor commercial' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'house keeper general domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'house serv footsman' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'house table domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper general servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper at' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housekeeper bank police pensio' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'housekeeper is alone' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'housemaid in asylum' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'hurenoppasser' (lang: nl)<br />HISCO: 55120, Description: Concierge (Apartment House)","Input: 'husjomfru' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'huusfader gjestgiver' (lang: da)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'huusjomfru' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'huusjomfrue' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'individuo del real resguard' (lang: ca)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'indqvateret constabel' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'infanteria capita' (lang: ca)<br />HISCO: 58320, Description: Officer","Input: 'inn keeper 3 12 acres' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'inn keeper and grocer' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'inn keeper post master' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'innistorf' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'innkeeper' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'innkeeper deceased' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'joiner and licensed victualler' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'jungfru' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'kammarpiga' (lang: se)<br />HISCO: 54030, Description: Personal Maid, Valet","Input: 'kammerfroken og stiftsdame' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'kapitein konnedmardomadam' (lang: nl)<br />HISCO: 58320, Description: Officer","Input: 'kitchen maid dom' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'kitchen main' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'kok bij de afdeling publiekwerken' (lang: nl)<br />HISCO: 53150, Description: Ship's Cook","Input: 'kokerska' (lang: se)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'korporal ved 1 bataillon' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'kroemand' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'l/cpl 2nd batt. lincs regt' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'laghy companion' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'land cadet' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'land soldat barn af hans 2det aegteskab' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'landlord rulilie house' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'landsoldat tienestefolk' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'lensmand' (lang: no)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'licenced victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'license of hotel' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'licensed victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'licensed victualler (deceased)' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'licensed victualler and horse' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'licensed victurlar' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'lieut rn' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'lijkdienaar en schoen en gareelmaker' (lang: nl)<br />HISCO: 59220, Description: Undertaker","Input: 'liscenced victualers' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'livgrenadjaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'loejtnant' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'loes piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'lt colonel' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'madchen' (lang: de)<br />HISCO: 54020, Description: House Servant","Input: 'major: west tor___is regt. attached sudan defence force' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'majorska' (lang: se)<br />HISCO: 58320, Description: Officer","Input: 'manageress of manor inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'matron consalescant home' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'matron hos' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'matron of ward xvi' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'member of h.m forces' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'menig ved 18 batl 1 comp' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'menige i 8 bataillon' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'metro police sergeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'military service' (lang: en)<br />HISCO: 58300, Description: Military","Input: 'militien bij het 3e regiment' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'morayn gyffredin denlnaids' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'musqueteer manden' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'national soldat tienestefolk' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'night chargeman' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'nt attendant on lunches at asy' (lang: en)<br />HISCO: 54090, Description: Other Maids and Related Housekeeping Service Workers","Input: 'nursemaid domestic servant do' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'office hyde park hotel telepho' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'officer' (lang: en)<br />HISCO: 58320, Description: Officer","Input: 'opsynsmand med gerderne omkring hovedgaarden skioldemoese mand' (lang: da)<br />HISCO: 58940, Description: Watchman","Input: 'opvarter' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'opvarterlaerling' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'opvartningskone' (lang: da)<br />HISCO: 54040, Description: Companion","Input: 'pageboy domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'parlourmaid serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'paymaster in the royal navy' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'pensioned serv' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'pier toll collector' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'piga' (lang: se)<br />HISCO: 54020, Description: House Servant","Input: 'police constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police constable beds county' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police constable norfolk count' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police inspector (deceased)' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police inspector.' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police officer' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police pensioner now forest ra' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'police sargeant' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'poliskonstapel' (lang: se)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'porter at singers machinists' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'porter in sanitary dept' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'porter in sense' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'potters dipping house cleaner' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'premier leutenant med afsked pentjonist' (lang: da)<br />HISCO: 58320, Description: Officer","Input: 'private 60th regt.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private 6th regt.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private r. m. l. i.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'private r.m.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'profoss' (lang: se)<br />HISCO: 58990, Description: Other Protective Service Workers","Input: 'pub bell inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'publican' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'publican sun inn' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'quarter master sergeant r.m.' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'restaurant dining room' (lang: en)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'restraunteur' (lang: en)<br />HISCO: 51030, Description: Working Proprietor (Restaurant)","Input: 'retd servt' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired assistant keeper of pu' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'retired caretaker' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'retired domestic cook' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired ladies nurse' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'retired police constable' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'roadman cleaner and repairer' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'rotesoldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'ryttare' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'rytter mandens broder' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'sapper r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'school at herne bayle college' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'secretary working mans club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'sergeant' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergeant 96th' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergeant army' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergent' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergent38e regiment instruction transmission' (lang: fr)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'sergt police pensioner' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'sergt rmli' (lang: en)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'servant cooks' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'servant confectioners' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant domestic not of employ' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant g domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant holder' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant private house' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant public house domestic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'servant stables' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'sewelly maid domestic service' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'sexton of the parish' (lang: en)<br />HISCO: 55130, Description: Janitor","Input: 'ships steward' (lang: en)<br />HISCO: 54060, Description: Ship's Steward","Input: 'skorstensf mester hosbonde' (lang: da)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'slottsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'soldaat eerste klasse bij de landmacht' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaat en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaat onder vrije compagnie van de heer westkerk en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet onder cap vries en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldaet te water en not mentioned in source' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat de numancia' (lang: ca)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat hosbond' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat hosbonde' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat mand' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldat tiener' (lang: da)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier (deceased)' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier pvt. r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'soldier r.e.' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'solicitor clerk boarding house' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'solider on active service' (lang: en)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'staandsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'stadsvaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'steward' (lang: en)<br />HISCO: 55100, Description: Building Caretaker, Specialisation Unknown","Input: 'steward of the gladstone club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'stillrom maid inn' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'stuepige' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'stuepige i praestegaarden' (lang: da)<br />HISCO: 54020, Description: House Servant","Input: 'stundar baejarverk og heysk' (lang: is)<br />HISCO: 54020, Description: House Servant","Input: 'superintendeant police' (lang: en)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'sweep' (lang: en)<br />HISCO: 55240, Description: Chimney Sweep","Input: 'temperance hotel keeper groc' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'tjaenstedraeng' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaensteflicka' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaenstegosse' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'tjaenstepiga' (lang: se)<br />HISCO: 54010, Description: Domestic Servant, General","Input: 'trumslagare' (lang: se)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'turf and loam agent' (lang: en)<br />HISCO: 59990, Description: Other Service Workers Not Elsewhere Classified","Input: 'tvaetterska' (lang: se)<br />HISCO: 56010, Description: Launderer, General","Input: 'under plateman club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'underofficeer ved 2 livregiment' (lang: da)<br />HISCO: 58330, Description: NonCommissioned Officer","Input: 'unemployed late louise burmes' (lang: en)<br />HISCO: 53100, Description: Cook, Specialisation Unknown","Input: 'usefulmaid doemstic' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'vadskerkone husmoder' (lang: da)<br />HISCO: 56010, Description: Launderer, General","Input: 'vagt' (lang: da)<br />HISCO: 58990, Description: Other Protective Service Workers","Input: 'vaktmaestare' (lang: se)<br />HISCO: 55130, Description: Janitor","Input: 'veldwachter bij de grietenij' (lang: nl)<br />HISCO: 58220, Description: Policeman and other Maintainers of Law and Order (except Military)","Input: 'vender house maid domestic ser' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'vertshuusholder hosbonde' (lang: da)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'victualers' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'victualler' (lang: en)<br />HISCO: 51050, Description: Working Proprietor , Bar and Snack Bar)","Input: 'volontaer' (lang: se)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'voormalig frans soldaat' (lang: nl)<br />HISCO: 58340, Description: Other Military Ranks","Input: 'wages domestic servant' (lang: en)<br />HISCO: 54020, Description: House Servant","Input: 'waiter' (lang: en)<br />HISCO: 53210, Description: Waiter, General","Input: 'waiter at new athaneum club' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers","Input: 'ware cleaner dippinghouse' (lang: en)<br />HISCO: 55230, Description: Window Cleaner","Input: 'watchtrade' (lang: en)<br />HISCO: 51020, Description: Working Proprietor (Hotel and Restaurant)","Input: 'workmans club stewardess' (lang: en)<br />HISCO: 53290, Description: Other Waiters, Bartenders and Related Workers"],"mode":"markers","marker":{"color":"rgba(186,217,78,1)","opacity":0.69999999999999996,"line":{"color":"rgba(186,217,78,1)"}},"type":"scatter3d","name":"5","textfont":{"color":"rgba(186,217,78,1)"},"error_y":{"color":"rgba(186,217,78,1)"},"error_x":{"color":"rgba(186,217,78,1)"},"line":{"color":"rgba(186,217,78,1)"},"frame":null},{"x":[27.452622531954368,30.894168798349906,40.401098014825649,2.8142566178982857,-80.782112974269538,26.380742140758116,28.798721355731516,-79.151100352514405,43.030063748280497,-0.76834716260171465,-2.1256536207352075,31.623410483532361,15.256927357683335,62.440548485212616,-15.98912103570564,8.4206587937711141,11.80947762408085,5.0799024088039193,35.212576001951618,3.3246411667197688,7.304151720446689,26.362122572861878,29.345019548432752,10.010489793179499,26.719649790667418,7.377536118632694,-0.10885498011470635,8.7661975480102523,18.318819714710454,18.939558398016043,3.8650114905734312,9.8250462970968986,10.568464305744758,18.786007115311278,11.117106384895257,3.6342671290904436,16.564478813975271,15.341573149296636,16.432491713947954,13.71701258430207,9.8736552360061545,10.044134116707662,17.365245637872938,16.760004880005823,18.277640684051072,17.427670509665877,20.509841175556051,31.024682185743135,29.657673540294422,28.366337698528103,26.034024392689407,-78.719234645600807,54.325978338461489,3.0997528340139944,2.2260463755025701,-3.2804236836288467,8.601097292846033,27.156766574174267,17.096826507207602,28.744956645627326,-0.46310952169715502,5.2149402306883861,-52.283300134112189,7.7927400416840298,-53.696454211611616,-54.352737449961111,3.794755776302706,-77.785409532314546,-68.606295664600538,6.4758397019271712,20.862484356327261,5.9655472429195511,-78.245865616460023,31.911836863611416,-0.70579929646623907,6.0901017491773946,72.002271072666204,71.943281928029464,54.416507332860952,29.696658729344005,2.5564507174951538,6.6106866200330643,10.023577334702388,4.5130908375003012,23.459330454183601,-58.190009848212455,72.475202803833611,17.590058665331487,8.615042148456892,2.0200733957743777,130.96968234950043,63.387123761998424,65.077164996223686,66.191607624574928,63.729885111387276,65.255701237064343,66.271740510984728,64.275331092568237,65.940886649508371,62.219946734805795,5.9116403060169445,39.280170783284248,64.661962180802178,18.866514450809312,66.072740281763515,-46.554666744912446,46.414381880927159,6.9549278650138193,40.039492568214619,12.828068338048038,14.509400073678165,12.682277397028574,9.7216587633039016,37.546692719418928,36.320739452532941,71.591827129317551,13.77339286529633,17.38597895814981,18.957314318525857,0.36340936072037383,3.1680135780641963,35.232462394259848,9.1625651346057495,6.1877304945490472,-2.359547705140248,0.46091800157114776,2.2138812708262061,0.48168365716041134,6.5380418172700692,7.9806781412910146,5.9855526893941242,0.41044099583780147,3.3572900079931971,0.62276828563405751,-5.614661047272536,1.6236269332906936,2.8485686151307719,3.2086250595786723,-0.11159568841293503,3.3041802682109886,-2.3080948300863358,3.2243056491007405,0.16370661561362684,10.184248401438659,0.66298675323752865,1.1611725886589319,7.2732741138682737,4.377117493419842,-1.4225232431838488,4.7962443539813044,0.88963297933469732,-0.66773664784143205,7.4577574490193301,-0.35687576590785169,5.7316188111783841,5.5047026882237038,-0.52405555816120053,2.3844460162661565,3.0393392231815066,-1.357823941567319,-0.38494140974260993,0.8396119965886234,-0.68292096626353693,-1.223269650025236,7.6042301919976119,2.1059302094115608,-1.4181216538623918,5.0964933809246951,5.8219128279832617,6.8342364201299324,7.0411399776148462,4.0404525113832372,-0.62422913461206808,9.57352138572341,8.2872883446937955,3.8152149951051411,-3.8441196046223047,-4.8319676789482013,0.22104111595209219,0.70898084857967902,-2.6527891851348739,-0.96265729462918403,8.6470854703283759,8.9565226587090212,9.5588967429980816,7.8731960925722726,8.8436353941285955,8.9299012522526908,6.6013796885937515,15.561502900349293,12.472730904193254,12.383578626080608,9.7955155796452313,10.719107947708531,7.5905121177251944,14.984813838442662,8.6350722443500718,4.9579856261885329,8.0837155712769597,4.4987015290493799,9.9064819630896466,6.0909080035650058,4.9704289078495867,9.1612279177498657,9.4558358942277572,6.8307570701963893,5.1931404473834188,6.8564093058242799,8.4587857658966108,10.681203375910982,12.347505667683002,6.5335761987973395,8.1696780400747482,6.7264664211994516,9.7058338919121958,11.04066091205403,10.745245341663329,8.1843705634367954,6.8952731531827158,13.795529245028318,12.498309586053992,1.2025782333664017,11.087289367044892,11.383535111195274,5.6223225322410473,7.0243819650115782,7.8045845279525468,12.653435719675608,4.8984682135112756,7.3532832383218594,6.7644325200153075,3.0195899235886321,0.21888370800063389,0.54555463312239139,4.5406234430851491,2.8287444094307261,-1.4195119957111397,3.8038748478609135,7.9105073720708532,4.1309685943217005,2.794266083168758,27.456381490772756,29.708784055058683,28.638183936480686,27.049280963579509,71.42088303082447,1.3437569504945674,-1.515857444144648,7.2226952424062008,-130.41462845375844,-46.278750344163008,-47.715535669467336,-49.986612501689841,-46.220696178976908,-41.852455801787116,-42.956151541511666,-46.194525389352769,-42.363811176745244,-41.379427886499549,72.112152595417811,1.3385972261024321,10.854500910144374,1.1495240920154026,11.128372995070846,6.3241717092666061,-0.10589601896245532,7.7428513163195563,15.352067048767326,10.185731024706969,9.3828608326965171,2.4669144056326555,6.9734672562942883,5.8985097169954006,-46.481048888935483,16.76121291108851,4.7892519698928666,14.98664538672026,16.300029576061814,12.155500489054086,7.1725058400862647,12.726880955667868,12.500800221733153,12.452192677485549,14.797158070983444,14.644085338599693,9.4593560019206571,16.253257047271155,66.549526169284704,65.06533913716251,14.445377914247622,2.3254071641712746,1.989693564937201,12.484114301081442,14.611069011264441,10.435972326243574,-21.611408529054497,-21.283350891336418,-20.254879527255184,13.161658031622505,-20.074216802330671,15.624237523722645,-17.683863515013606,-16.058904057203776,4.3673091786396299,14.794918597998029,0.99729576938767295,46.236779401641563,43.373098966147936,42.187690406638126,41.569403203337437,37.175250586012226,43.421701624987314,7.3521475460185712,5.6395298983052378,-18.200247301277379,59.46076207176263,65.785314363098479,65.038671264300731,8.6972727345181244,25.081264556614283,-0.29270515773308153,27.684227617634509,30.20418515833715,27.744310372786053,26.118860074137874,34.128356194669728,26.571238307314808,43.03423636651177,42.514598136484565,38.040304234261278,49.093404654381857,-40.917628182018859,41.975351370292962,38.105779337593937,27.316916769261923,26.962313020721659,12.305146945408209,37.11620315198472,10.028829863884541,10.111313968763858,30.141612490983302,31.839134972783011,37.047750390988618,27.267664536205537,38.173514232342555,28.146404742562183,35.115844013317663,25.880999930670995,26.59134288455726,27.312298896284659,28.226579917941731,35.638495111743374,10.949344825073631,36.327529811755241,35.217257528704479,37.046629127487655,35.515875161602295,34.855505387147979,34.272027068229441,35.859021398475711,28.590769285319983,28.865226604819529,29.766005688585146,29.354761160619923,36.417739831123143,5.609296251948404,8.5920890771921545,2.8564190696829139,-103.46047235247535,6.5334263343043597,4.5400652622197937,29.328535904673618,14.788360327669229,12.101611441102987,30.695950256358909,20.815022074136966,9.9606336549661219,25.272541077310898,22.801732322948084,25.070966664163073,26.8208742013422,25.86150085701756,34.298890254310109,4.2258664883565586,2.5108853817720593,-1.1713528034918856,71.799718648053457,53.958359069578115,39.581984888767003,1.4696757950543542,5.5674433692949634,3.8178406699331999,15.971427433100677,39.203900913938654,67.941835231063664,42.337604988974988,34.264750956696666,11.558376159001362,28.929752658620163,0.2653443674759885,31.44523273207804,30.419404960902902,0.31256523232709887,3.1948380044406153,-1.6424924658963944,5.8882244747208192,-48.355667245427689,44.406369437869202,5.2454703437025669,3.9427299048417321,68.315960167539146,5.3257194753202315,-40.705091312467296,4.4352186188915717,-74.233881413943067,0.0080223305167365887,67.576856257402341,6.2793065172882345,3.1682916682643252,-42.059159502944894,-42.284866768773703,25.279330309909717,11.274349375024068,54.29898249867923,35.107528915589597,41.387098715063836,35.507218326607003,60.958588267784727,6.0687417147251805,-46.24596078378633,-47.371888932065225,36.869453954530904,-75.695898140879493,63.51381389226227,64.40100974168918,62.183739214059372,28.539919853573803,6.326765094515534,-38.123719067236387,72.693024909031266,-79.985197599671807,2.9665643949805132,2.131110880122971,4.2363591001898122,54.904147338079945,-55.097868233873228,-55.598349107642335,19.517579270163719,6.5449882615552912,2.2776408061026592,8.2587507697827824,49.838003204601854,50.353441888884724,26.245271611776101,24.573104124184532,-41.411759428144876,35.959938090241806,35.951456999570929,10.822635418406453,14.019194080278487,16.966336602332166,4.2305588782127481,11.293607307658052,-104.63935949138427,37.536445097523711,72.935545982114263,63.410985430379284,73.114894413735684,72.29548480514886,-49.344810167313838,6.7761372416456656,5.5976867274831772,1.0177849952037556,4.0174423801266714,-47.787584340576089,130.57771155429572,69.454435459602607,38.748600509978246,0.93620501887654417,72.273168615021703,4.2427982880856607,28.489333059256708,30.357247530210344,44.821784966174611,9.4515822097770652,-48.281799192709478,-48.223835178668914,4.1698370876163757,-77.957381244736808,-80.03117056185809,-42.063548156699937,66.640988990204775,63.769020834986932,67.600762196153767,65.717691773610497,63.060332137697429,24.995873373144555,70.555049610446858,58.647476757662155,41.321461156493058,60.492792099293283,64.523686517476023,62.985156678685719,70.077946005374642,71.486123453265066,39.37557078326887,70.936527389606326,69.813468949583111,67.798859692860731,71.339949603659491,64.32639727451766,70.094580680423647,68.893382722295698,64.644674377043856,58.881589002250017,62.478962800345727,67.772230609106003,68.292184212448021,67.511130247098151,67.069772347715869,66.362887394401369,70.438984833538143,67.996035024777129,68.694754982473114,25.769707393815128,26.38560649157947,6.4335063351707378,-0.44286462070364485,-13.956017256127655,2.8455711070532672,-19.503575376395236,-20.739108553401707,-0.16827137898405711,60.813812269126778,68.991769245317172,19.018890314499412,41.830806472073867,-17.073580207658651,9.3751884500360045,-42.55198652438785,-1.2695210839496542,4.6471786413229452,-0.70730005049104616,36.785405421830276,39.706098059673224,47.746451489226189,30.314167736809129],"y":[-29.628012910449335,-110.53680274365691,52.154715244690813,23.62537803294277,3.6843849261335877,-28.266354956773849,-29.677961553273931,0.032384784892903612,54.265066468927017,18.183909276428896,24.032954977739152,-108.55714281927364,-15.193106244655624,-124.46526349230993,4.8632089850357278,23.698445974344089,-17.295576044438441,23.75715427470038,-39.808219277414146,21.003537148263515,75.837489668097817,-104.49794288875707,-109.53501883498443,-5.3147515609505271,-28.669726211535711,0.2367859411644922,4.9431515459175843,-0.042941739236888425,-14.797710764090887,-16.321286146601924,2.7417399987995918,-7.7312679058966349,2.3736752261169491,-11.847013955662652,1.1152976954589391,2.3142866650528169,-8.8507184218497557,-9.7229932762624447,-8.4417323975344765,-8.5281490114808705,0.48932090142690116,2.1504438751680706,-10.799796218761827,-10.933983500761745,-9.2356122668252034,-10.189983456971721,-17.243833740602508,-30.196829716817721,-29.065839140800609,-31.392011789292862,-30.637192589456511,5.0108014226280551,-31.561294971837633,21.90298836148397,77.725438293176367,16.215783784803325,2.6194210471529225,-30.065771376181896,-10.216358817362858,38.164468672562023,24.733394546189491,13.623321212976007,67.778597559708714,21.291072332054707,65.645933945353562,66.228604320146957,21.523835152498712,6.1731382820515845,-5.6619242470437543,20.127318187899029,-15.786182853023613,21.188454709521626,3.4171959423838745,-110.04571260970211,15.54048392080599,77.518880639320642,-28.778105770073793,-27.87194392444389,-31.357451647054077,-110.47704660640387,13.446120446141288,-2.4761283951869832,-7.4485488975567957,-3.8071918276033432,-15.464727802651554,5.8317790225739135,-28.064834835909984,50.956421319923614,-6.9044871456078347,76.558865902872427,-128.98350665015352,-123.18003843512736,-129.1351713574125,-130.89579210065034,-130.55416525380818,-120.46497112643513,-123.5409021112502,-130.68591751590697,-129.56049185082267,15.249043570622753,81.035814459967838,-102.40243081782737,-118.07368207229025,-63.272680265883331,-126.71416325272818,-113.32569645189376,57.901803343768442,25.884887910527521,47.737301988712815,-14.219782653324074,-16.305542060377228,-16.005598849211371,-15.763470472164997,45.320153604394761,48.109510946187974,-6.5445512893263347,-16.074171272334496,-16.813563834743995,-11.274462039785325,23.507089972697933,26.910967049643709,50.998112353755666,24.454055104248681,25.270001637878011,-0.46222038383142638,-0.41439330511357764,20.482482493049872,24.644560719147396,3.6902703398045889,24.989431592701884,23.381131979953647,16.8350301710312,22.408935187061793,-0.57006979250383027,19.306369642023778,13.537575560556856,23.216933793914755,22.883714030585349,22.401035331028844,14.558896466830022,22.142048077597327,17.29581131024479,15.438802477671805,20.122387744067424,17.678018654575226,15.397315672139849,18.547934668343171,23.502099652148154,0.18380638306294789,12.924031051451005,18.56507543363044,16.008228149114714,17.069836985746552,20.054222429688366,16.454599143899006,17.858111500013525,21.028937625002619,15.599304040918339,19.030847503688435,21.976256547365825,19.695509629583594,21.990976785149172,0.6285290178900087,19.749577119014294,27.956788544782935,14.193848954729869,22.528095543263397,19.163711761824093,0.40061122095358659,-0.39249039638942168,-0.33814019275257295,20.84776928685816,13.053061307688301,15.891795299788086,-6.2857758561216031,3.6090967951892452,19.271106576584682,19.339143733705296,17.347490823556843,18.518570246973574,19.779741818226164,20.01808992015842,17.691780956902232,11.966464192081135,17.821729593401258,21.663362048642227,12.820909666877791,22.367544391478411,12.254543469467515,13.313714482979329,19.430788345450274,24.182610990185385,22.683003737349832,14.397800413070327,17.130561141285241,17.655019805582494,19.767965809461263,20.288055256516277,14.983034631978828,20.568830890594928,16.489624544965157,16.432181301236113,19.453275310512495,10.745464036573019,12.646824901272673,24.383688759665979,18.304828332956216,15.712268498029978,21.75807543405616,25.503654936443098,26.505511839703058,21.081480113142458,13.389756557980666,19.261307824353761,16.187778443220665,24.297735464218388,23.818127431180777,24.473795756845817,20.804700508802096,14.17005809159402,19.222712626848821,20.561417866417393,16.993941229859171,16.028828764519794,14.212203083715634,12.307338681615439,14.307473192430338,19.301689606788603,15.99189200934345,14.597996854000018,16.835002677350662,-2.0722082240715305,16.829231023596193,25.427464159210995,27.9490049018357,-1.4950662278154969,24.220825070855316,28.472698804041187,25.3565821854625,27.091438816246551,-0.2684857874383681,-30.789592440838067,-30.923294731185869,-27.620272556320451,-108.4033723743819,-4.4641157405921792,1.9704580315449121,16.868139332003391,-0.62955320595096143,2.3705773972295403,-114.19298108808069,-113.52801045146016,-113.86003664687941,-112.2126425996936,-111.46680748406649,-112.83610676841184,-114.05948962077139,-113.34207145929892,-113.39235023109623,-4.2468335753045876,0.039140377151588857,-8.0989528297037516,-0.95933984144481044,-7.1450127105924768,24.572837115561633,-44.045214176040254,20.780241770514543,-18.259956583714388,20.640773549736299,-9.3854623413949714,4.106968241022825,-0.51699114191131446,23.390694799694661,-111.20356545664552,-18.236449874801046,-0.91219569236807818,-13.878298519069089,-15.559288204283465,-12.237077093493072,1.514432814498788,-17.490965424453339,-15.920179099756313,-14.027585206993059,-15.201766587503943,-18.059588337169917,-3.460164916273694,-16.519121830787533,-119.59157467657495,-120.41123861912268,-17.368885962774616,78.57853202694578,79.136920207287986,-15.724837233595041,-13.999985422860194,-16.529742519798869,-69.912104205188228,-68.323969417316704,-69.074506111488077,-19.746328622035904,-70.226713744836161,-17.964244099726205,-68.81950746969116,-68.4110936739621,78.616023645032072,-13.024411957097605,20.475685678242169,57.729235474782961,54.935782606831289,51.684041151626623,50.238879270884361,51.879637234781534,53.09147240750427,74.137124298718717,18.178909696318005,-68.737508623733234,-122.71223507315089,-131.68761794671173,-125.05607483739118,0.25568766925106062,-100.38679677635749,19.205712363729567,-26.066217548245671,-29.235977558439444,-26.648493165049153,-24.610034642464559,-104.97957411500808,-111.26245914126577,56.517863583062216,51.897970458570335,55.252236036787686,48.142518647601875,-46.788471237116674,56.795327805842724,47.7076417870489,-113.07421030159631,-108.50607937252852,-19.604133250250989,-100.28257817400529,-18.8178005101142,-19.893757359695321,-106.60308507806492,-108.18030337701521,-101.11340008707943,-110.07363072930323,-102.22138497761463,-113.49225796415779,-107.52566936570697,-103.09090157239976,-110.83933255030692,-110.8896635606754,-108.69468421832184,-108.55755568761795,-18.474524290057516,-107.3177133461802,-100.10122922639839,-102.55355756701555,-99.255217501903985,-108.99118709100755,-105.63084016274178,-102.14821432213773,-112.50754798844216,-110.98440938280901,-110.02846927373251,-114.2552743515845,-108.69291937606313,18.02530175522023,27.495600572987108,21.245347906305732,29.162400631890058,28.667495927181459,17.713552677630982,-27.769985052611663,-13.696398245850538,-5.5204109663111849,-112.27925825557215,-15.313788162746453,-2.3400438947601212,-107.73237029131447,-17.121652934181686,-25.848705593939588,-107.20712570407787,-106.63144241301225,-33.77185796280471,21.305273204285104,14.499146815810057,-43.819494240547975,-4.8514601418269381,-65.192702494514037,47.267457675796656,19.373963048256368,26.582436024788855,-1.7948348031061385,-12.898739587454005,-101.00835587253573,-118.40929172148495,46.820619611451917,-83.309281647863983,-8.0731442231861408,-108.1310483124789,4.9205633957931454,-108.77562341101337,-112.37654498172108,5.4704660220056116,26.074153192135658,23.405691834950488,14.784875026653305,-112.55661948350135,52.191748476219544,22.346175060518043,22.54619238095141,-124.5366579840595,27.183401428639169,-46.930033353596727,23.775465418486142,5.1331720960427276,19.930208943841929,-122.03635243987635,23.792396289669824,-2.9871118097261449,-44.213085207448877,-43.771712870016373,-29.631354760629918,-6.7330214733636167,-65.205220915758503,52.12267531624618,55.092489258033517,49.583199283694256,-117.64513400660118,17.221638922822962,-112.85223964533961,-115.11033162574441,50.741567728355761,4.726280443636818,-128.11309230283726,-125.55535251471721,-124.48709813863961,-111.45611101120463,77.876106206567798,42.187841061482033,58.486085924981666,4.2599538110864703,22.51947616450224,76.396417945066815,9.8921029593361514,-67.602040032195632,67.257834238118605,66.608999617129882,-6.1467594563783026,-50.62119792820689,79.541887798016688,-2.6035083022343732,51.691457363416809,51.385266436071653,-27.766446877142723,-23.475266078694073,-45.594568967694464,53.480351262437594,-102.03337495091159,-1.6675298300723567,-16.997783001180952,-13.488238523367432,-0.1317019476209092,-1.9050465714521485,30.720737960737626,49.347032737034745,-128.85330380691488,19.347768121791798,-4.453467008181792,-5.0478912543132566,-114.09730887321807,-50.341320417155003,-49.283534324942103,-44.327566828693634,25.995289100404989,-114.60538475170937,-107.4865669959507,-122.60917192371511,-101.45009422553946,80.395671068322898,-26.743361259555126,80.406493693666761,-113.34763066413907,-112.79215823448646,56.556745608026844,7.5799173690466732,-110.05478472512897,-112.70072129907756,26.325161183529787,4.0235521674526362,5.0819262212187963,50.710098336749532,-121.97820545287456,-128.46455449071581,-119.23318283183609,-117.77121058066004,-116.20469607306927,-25.962954132959108,-121.11049306789084,-119.6641991244386,-91.214245458448019,-121.00896956639693,-120.37167052655663,-113.34918112048277,-123.56532547249623,-130.77130980440415,-84.38162257013407,-129.25501846917163,-131.31377671329793,-132.15163573101935,-126.310303714873,-120.49701908594679,-132.25666881795036,-125.3070593684721,-7.5406946041725291,-117.20316010056344,-117.75025836432404,-129.56085668225944,-120.9758314697013,-131.4992558100285,-119.82976787340667,-121.85477045096641,-125.89981343617308,-129.63474641879677,-126.56329809101182,-109.52125526784437,-108.98925159724777,76.600574620182982,-68.553874409130245,-68.061484275507098,80.378929022644456,-67.277231425113769,-68.982843406885678,-68.316304832726189,-27.536164460642954,-124.8346338041322,-7.3271673357968208,50.18192676613031,-67.513149683102853,-4.0618324152346936,-43.76306709008788,-44.741295760299657,-48.959876857383563,-43.982852230318414,50.959625269380467,49.24316320566917,51.979669661361442,-110.23365099078498],"z":[-107.4324614111312,-108.4268892402193,-75.518103494497311,-94.055635409319123,22.409759361575883,-104.90878248883702,-104.77618510382077,22.554342644398581,-75.930923200787916,-94.419138985436177,-85.640827400827902,-95.268291496332239,-109.74691269159965,-18.897012486863087,-22.183998294346367,-127.07540777553233,-111.38528762214938,-105.62204942422939,-7.1861293168069782,-99.610778692667907,-44.417265019867756,-107.7317491835329,-105.81611287363451,-135.15847298233834,-109.84543511041819,-147.67326408477317,-147.49648057940715,-145.95971504875297,-115.69041011235612,-113.79283688777812,-152.49031728967384,-136.27519768966624,-147.84973336512033,-132.76086984031934,-146.26924398055473,-151.59397991255739,-134.67262854059464,-135.7662941980393,-136.4469179173341,-133.30930683061106,-147.46094690478171,-145.81569031761018,-133.18937314798757,-135.52363495801569,-135.65816207576674,-136.94069559207762,-114.7576582774538,-111.0524699325919,-110.03658114315556,-106.12031260982683,-105.60305980063994,22.556580384901057,-41.43385766845423,-96.04631045372652,-40.934819808577842,-92.098588009348219,-127.91818914088974,-103.57617757776738,-113.8736151381397,-42.938309587864431,-134.12003837316166,-96.053479698827203,46.263985507300525,-111.27747816682425,45.126630476025852,45.859756767582851,-116.33052608547032,20.789040985127848,-94.891730640056736,-95.815274503643096,-102.82374463274498,-97.511669026155403,22.953132710508399,-105.93843236496892,-86.651568588140336,-44.415051061103739,-88.55821392345004,-88.494228556323321,-41.323242621504797,-99.733828029089295,-91.043792035255677,-137.15537190738607,-118.82481153250012,-134.37589125638789,-97.954626107236919,-15.876829096240032,-89.52106335691262,-14.639209590260503,-108.4369721909257,-45.729160049643554,86.746621906036879,-12.377752556438587,-11.846410469252483,-12.033165500114281,-13.190335893483237,-12.66070261787347,-14.220458968028566,-15.594491206457239,-14.453518312021396,-56.076657688297217,-45.61357173975766,-74.393649965706516,-12.756789647036253,3.5090563791878333,-14.014352875425537,-34.870143851428828,-84.545376740993916,-137.33191379577033,-80.037190616959435,-116.01625178528204,-106.17216919811335,-115.16732527383624,-112.33833793835174,-77.363671920839906,-74.902396564679577,-95.252370004094828,-117.71611869102763,-107.92780286130083,-135.16668296374763,-94.939267361397853,-123.12930853334655,-77.5073481434207,-94.847665240325867,-95.389458102700203,-131.18552302383978,-133.00462251264855,-101.92618762620941,-143.40410816142904,-126.90572103162616,-101.2828531413699,-129.58987785986497,-101.36350622123244,-121.68179225147487,-129.69688930745829,-137.23571846319498,-150.77169960259337,-149.15699600746541,-143.75217833174545,-148.62677992960079,-150.0026239701678,-147.33613935365702,-149.82751634520042,-146.86100266706023,-142.86275242553808,-147.748534657254,-149.80828715517004,-155.71349215411828,-149.25100573880275,-131.35750052688687,-151.79754230777755,-138.1320976293014,-144.75656466888671,-155.52491199217712,-139.95670111385331,-151.61935364410405,-132.65750179547257,-134.59396297748566,-151.58866246521936,-134.12544197845327,-151.70403560975339,-134.58887638801207,-139.29074828434725,-135.29841088679183,-144.4853440132124,-145.55843617986534,-148.07210008681449,-149.85761844916988,-99.524068383440806,-101.89401524527048,-101.13606630029413,-102.77534839858322,-118.90467422401782,-97.311789810889763,-139.02932728218451,-109.13937050612377,-128.16429640974022,-139.59899568097566,-138.18696153864045,-100.36076342818372,-93.451292904943642,-149.86868699086835,-147.81977733382772,-145.77089556740523,-144.39765087542474,-150.17053827404325,-135.60603166372928,-148.31144553732301,-133.98946776549124,-146.53561171221546,-146.23252698551687,-143.13865011652615,-135.84294650206641,-140.00753529613013,-147.60356904686887,-147.85704977499245,-142.26976633192058,-147.58607426542378,-134.85072772786938,-144.45467055972105,-115.4603204877962,-146.13074537653989,-145.55890660700882,-144.68604505115744,-146.78483277424493,-150.22448020678507,-147.21278680461552,-137.62768073858982,-141.58771270980577,-137.37871284288204,-144.86112303937537,-144.6767094354218,-142.15841276087295,-146.00424990502901,-147.88165801145317,-148.4054678438097,-139.40614893100621,-134.54121585588672,-134.56022808953622,-146.49385405717859,-147.22824586796474,-148.75041480847275,-138.38894797749583,-143.87194915028559,-151.00358853650917,-145.47895694854844,-149.52381569144472,-150.35780949045468,-145.46881455766371,-147.00513091201717,-148.05503873193544,-119.96700058981612,-135.45189928137265,-88.366363120032275,-92.360734883374235,-132.33393440057125,-137.02933044533663,-136.6755667088469,-131.27312081343428,-98.092043198627607,-123.83268190411556,-137.60712781279929,-109.30245295273758,-109.10236217541677,-107.99600205544981,-96.934929247967034,-96.863304610322018,-136.15222237287304,-92.658407445116822,-150.36714852660131,15.205687177909363,-30.870252883210213,-30.951619565906363,-35.988982411120553,-31.85291914983911,-32.886703873321842,-32.649280929208643,-33.1292835983865,-33.671246094529174,-32.600148351784746,-97.333992288985584,-134.94585031184513,-120.16973296949968,-137.62222231814425,-129.84119878734754,-105.30079344302203,-60.249770777065521,-97.987213197818363,-108.38840139845671,-96.387830165729525,-107.33105662315292,-127.61473040382495,-99.287638764580763,-98.453033603246823,-34.106125280719276,-117.66195194110161,-139.07924682867358,-122.45026834422276,-118.77348110481317,-106.89781948174816,-148.3242318013279,-108.36692757436302,-107.24677521153393,-108.50817051823728,-121.24910301207522,-117.11026026049501,-137.23264565018428,-116.69181043989241,-15.440489766199725,-15.945700214539936,-118.94558051047578,-46.030923397900729,-46.689410926343179,-110.55144068350781,-119.79785690709113,-107.21615924023982,-46.690306087611368,-46.695031465487787,-47.637136314432183,-110.75983939264889,-46.373000420531987,-115.34549217718522,-46.824205165551163,-46.283849797449285,-44.509672820243615,-117.78388032994121,-127.2391464949133,-84.191327518098575,-78.708931668043306,-77.513519440711008,-76.00109250872741,-76.226588831699019,-79.592989244155206,-47.585532143500231,-118.33334419336798,-45.203344105497678,-17.593160950751987,-14.127593894576078,-12.513237136520051,-143.33998417925486,-108.11038377555205,-92.147194137797158,-106.74361712154845,-107.32582148978292,-104.2949974209976,-104.49229001648075,-86.101837530355141,-108.32800927436908,-77.520380911509747,-74.260946344734307,-74.897341529230616,-69.620459447749582,-39.613054629097498,-78.893429169638608,-74.665844489620554,-108.96211490483148,-104.66535834727911,-106.1672646291767,-76.379490016692117,-109.6481977793114,-107.31607208585305,-98.493244049897754,-98.987889254942928,-78.560136143224469,-97.78115694212606,-76.027000997252983,-106.40918644884987,-89.551690705021585,-107.7596552790086,-105.87262044142865,-110.31290071317166,-108.61611672904513,-87.873187400971602,-105.95563127971759,-88.521413294237945,-79.042763242063145,-78.31626215454483,-78.076375786239382,-89.141099517873471,-86.938206221296653,-77.38953893460959,-110.75875694852671,-108.78553737856858,-110.75575994466624,-109.09478801742291,-89.433810220680741,-101.18663010324593,-97.981432896388611,-126.10576745496877,-47.086563971711215,-88.446330903298701,-98.72405285388362,-105.47950447711774,-110.4959615068166,-134.0265824745245,-109.98458828969277,-105.23108126320976,-136.20129282608687,-97.936550809095564,-98.577840207175484,-107.5994939765899,-98.694177163544424,-100.52614744451763,-11.213900051796115,-124.80263723889973,-91.462896955821378,-58.83435903952693,-94.225105806946033,-33.971706173551397,-76.684122172628093,-84.86064244493177,-124.68997725604136,-151.98525332185596,-107.85551601624854,-74.77148945309952,-17.541713281081218,-75.707464002436353,-10.298565091776394,-127.9377941119354,-98.93264027980652,-138.51876796074203,-96.824100534116837,-105.670237855484,-139.19686631187844,-91.041451096362223,-85.901383864791043,-96.722153612362149,-36.238493887203475,-74.283798102939073,-141.22098281293677,-93.092840628446467,-16.468522249405382,-129.49725863825083,-43.432556268993594,-132.28897713564254,21.903923242862874,-85.134554625018794,-13.844809337845673,-136.50787624185131,-152.42616586037775,-45.881136470972677,-46.279085766125917,-108.20290754221639,-132.17245194922342,-34.410255352232738,-75.152002999499061,-77.413434908580783,-75.915009911798791,-11.515433743926289,-121.82271314707839,-36.750916423764089,-31.928808620211406,-74.922451016119894,22.393840105306012,-14.151127749938036,-15.088504757507833,-14.769378278611708,-106.85850113771993,-42.526792236434645,-12.56272552324895,16.799808292597984,24.933279773569545,-106.34484104656609,-40.869149390863484,-91.31102686769259,-75.628563142445117,46.454253297550437,46.981293744168632,-110.884440077767,-64.811056593752255,-45.084844126930257,-102.70648943334342,-71.966382669040925,-71.524641414744394,-107.01586273438556,-103.24147022538898,-44.386056852678891,-77.559316605929624,-79.543406103167172,-144.13839315852866,-111.10516075554031,-111.54481828433862,-151.46522540227159,-143.03981831245738,-46.772596533787201,-76.695345595949888,-14.400360346253908,-56.26453780610165,-96.440709460598555,-95.021907083754769,-32.721458313148077,-64.371467991756205,-64.234699477770818,-60.218607057091894,-89.110596242269708,-34.353887288078191,85.702620066132354,-17.008464724062012,-73.518617508949319,-44.344139757369369,-89.289702204623794,-45.125489871653635,-104.10120191783412,-107.88975811179392,-81.662966182366276,36.346265229664304,-34.321694984910927,-33.021953138918995,-97.02922105164177,24.058072588508495,22.60429870156824,-9.1818279513752721,-16.567008986171501,-17.716392147365614,-12.688271828756086,-10.771016502452756,-12.113982991646878,-103.75141789900015,-13.073920620264531,-14.51466787528061,-9.1683814833879609,-15.773955143262743,-10.57592997872626,-12.135391918147743,-13.092932817785188,-15.555983998975146,-6.0305659122568294,-17.108942268668304,-17.089496438869279,-15.534109684894657,-16.464901339578798,-20.020407054898357,-14.479339740518059,-19.568877017111248,-51.880547197800709,-9.9808488233674115,-15.619989896729686,-16.733572230281318,-11.481592732733906,-17.76054415806593,-9.9868841147568048,-11.158663194230439,-13.355316051756027,-11.422233769480213,-12.190986019919448,-97.135939822232928,-99.24501821519523,-43.195475242847074,-55.572231123746533,-46.22559181715102,-42.51201080240795,-46.427905998281197,-45.179978499721273,-55.54266005828098,31.232870970778446,-14.534487557824434,-111.37121892360241,-71.819078917675824,-46.049191729763017,-133.23603977162588,-44.913010043155602,-58.304789171413731,-63.937913480073405,-60.952690468300162,-77.736364947998126,-78.530391775987212,-72.995725129551133,-97.849592747408408],"text":["Input: 'aabo' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'afsk dragun og huusm saaer 2' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'agl horseman' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'almswoman formerly farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'ap hair cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'arrendator' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'arrendatorson' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'art metal leaf cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'assistant horse keeper' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'at work with farmer' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'atvinnan landbunadur' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'aulsbruger lever af sin jord' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'avlsbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'avlsforpagterens tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'bacon factor pork' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'bank agent farmer of 220 ara' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'beboer 1 2 halwgaard madmoder' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'beerseller farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'beeste of koehierder' (lang: nl)<br />HISCO: 62410, Description: Livestock Worker, General","Input: 'blacksmiths farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'blind institution keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'boels mand og har 7 skp hartkorn hosbonde' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'boelsmand' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'bonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde bruger gaard' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde gaardbeboer og moller' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde med 14 gaard men fatti' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og dagarbeider' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaard beboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaard mand husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer en del a' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbeboere' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardebeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gaardmand hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer husbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og gardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bonde og mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'bondedotter' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondehustru' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondemaag' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'bondeson' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'boot clicker or upper cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'bover' (lang: ca)<br />HISCO: 62420, Description: Beef Cattle Farm Worker","Input: 'boys refall' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'bread store keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'bridle cutter employing 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'bruger lejegaard' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'brukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'buandi' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'burhouse and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'butcher farmer 6 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'carriers farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'ceylon forest dept' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'chemist and farmer emps 8 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'chocolate depper' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'chocolate stacker' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'cloth finisher and farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'coall cutter collier' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'concreter labourers' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'confect master employing 2 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'conrador' (lang: ca)<br />HISCO: 61110, Description: General Farmer","Input: 'cordwainer employing two men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'cork cutter formerly' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'cottager' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'cottager dug' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'county court keeper office ke' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'cow keeper' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'cowman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'criado das vacas turinas' (lang: pt)<br />HISCO: 62420, Description: Beef Cattle Farm Worker","Input: 'crofter' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'crofter general labourer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'cul' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateur' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateur son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cultivateursonstudent' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'cutting in new ground' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'dairyman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'deanflitsman' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'deceased farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'deer keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'deres datter son' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres pige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestefolk deres tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'deres tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do meieripige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do tjenestedreng' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'do tjenestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'door keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'door keeper down pit coalmine' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'draeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'draeng tieniste folk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'draenggosse' (lang: se)<br />HISCO: 62110, Description: FarmHelper, General","Input: 'dreng tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'driver fiskerie' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'drover' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'dyer farmer of 2 12 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'e d on a steamship seas' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'eier af gaarden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'eier af stedet' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'ejer gaarden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'ejerinde af garden jordbrug' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'embroideress on satin' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'employing on this farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'faarehyrde' (lang: da)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'faeste gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'faestebonde afg mads nielsens' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'faestebonde og gardbeboer husbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'farm hoosf' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farm 360 acres employing 7 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farm labourer on hop farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'farm of 350 a employing 5 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farme bailiff empy 6 men 100 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer blacks' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer gardener 35 acres emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer landowner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer rd carrier' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer sheep dealer of 14 ac' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer tan' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer weaver 16 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer (deceased)' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 100 akers employ 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 1000acres employing 29' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 101 acres emp 1 laboure' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 110 acres 2 men 2 chi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 139 acres employ 17 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 151 acres employing 6 l' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 198 acers emp 8 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 200 acres 40 arable emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 23 acres 2 men 2 boys' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 27 acres of which 16 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 323 acres emply 13 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 325 acres employing 2 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 33 acres land' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 330 acres 7 labourer 2' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 35' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 360acres 7 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 378 acres employ 7 serv' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 4 acres joiner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 4 acres lands' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 400 ac employ 13 men 5' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 400 acres 10 laborors' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 46 acres 1 servant' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 50 ac ar emp 3 men 1 gi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 527 acres employing 10' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 60 ac employs 4 servts' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 60 acres lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 61 ac arable emp 2 girl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 7 laborers 3 boys 308 a' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 7acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 80 acres 1 lab 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 9 acres and blacksmith' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer 90 acres employing 13 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer acres 104 emp 1 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer acrs not known' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and butcher' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and cattle dealer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and miller' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer and miller employing 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer brick work' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer dairy 115 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer deceased' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer ect' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer emp 5 men 2 boys' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer employs 14 men 1 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer graizing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer in coy with head' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer occupying 32 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer occupying 68 acres empl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 100 acres 86 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 100 acres employs 7' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 108 acres 1 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 108 of which 103 are' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 111 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 12 acr of which 6 ar' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 120 acres employg 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 126 acres constable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 13 acres of land emp' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 13 acres provision d' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 140 acres partner' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 15 acres 9 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 150 acres emp 5 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 16 acres inspector' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 167 acres 90 acre' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 180 ac empl 7 labore' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 180 acres 8 men 4 bo' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 19 acres worsted w' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 200 acres 50 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 21 acres emp 4 bo' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 22 acres employ 1 ma' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 230 acres employ' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 24 acares employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 242 acres and 3 agri' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 250 a employing 8 me' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 250 ac emp 3 lab' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 2700 acres of which' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 3 acres and fisherma' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 4 acres coal agent' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acre arable 14 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acres employg 10' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 400 acres empyg 4 la' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 44 acres 40 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 45 acres proprietor' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 46 acres of grasslan' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 47 acres fuer of s' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 47 acres emp 1labour' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 51 35 arable' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 52 ac ara' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 60 ac employing 1 gi' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 60 accres keeping 1' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 66 12 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 67 acres employs 2 m' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 735 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 777 acres empolying' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 78 acres of land' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 81 acres emp 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 82 acres employing 1' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer of 99 acres and steward' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmer son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmermillerman' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmerrr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers of 32 acres employing' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farmers son student' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'farming 250 acres employing 11' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farming 7 acres of land also j' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farms 56 acres employs 1 man' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'farms son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fd bonde' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd bondeaenka' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd hemmansaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'fd torpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'fenadarhirding og heyvinna' (lang: is)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'fermier' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fet farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'find og gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'finisher and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fisherman' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman' (lang: unk)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman light keeper' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisherman man' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskare' (lang: se)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisker' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fisker' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskeri' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fiskerkarl' (lang: da)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'fjarmadur og slattumadur' (lang: is)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'fmr' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fmr retired' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fmr son' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'foderaad af pladsen' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'foreman of farm 100 acres empl' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'forest woodman estate' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'forgeman employing 3 men 3' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'forpagter' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'framesmith employs 6 men 4 boy' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'freeholder' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'frm' (lang: unk)<br />HISCO: 61110, Description: General Farmer","Input: 'fruit and grosser and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fruit grower 14 acres 12 women' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'fyrrum sjomadur lifir af eignu' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'gaard mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer hosbond' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbeboer manden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardeier' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardejer' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardfaester' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardfaester hosbonde' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardmand mand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gaardskarl tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'gaardskarl tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'gaarmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'game keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gamekeeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gard beboer madmoder' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardbeboere manden' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardejer' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardener' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardener (deceased)' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardener [deceased]' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardfaester' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gardiner' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'gartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gartnerlaerling' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'gate timekeeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'gdb husb' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'giestgiver og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'groom' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'groom astler' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom at new inn' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom hotel living stables' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom lad on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'groom to mr prescott' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'ground keeper' (lang: en)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'hand loom weaver and farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'handelsgartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'hans svigerson i huset som tjenestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'hans tjenestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'hans tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'har foderaad af bonden' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'har lidt jord og renter pfasahnmester sandbergs enke' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'has the farm' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansaegarinna' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmansbrukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hemmanstilltraedare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'hmd lewer af jordbrug' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'hmd med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'horse keeper' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horsekeeper livery stables' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horseman' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'horslerservant' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'horticulturist' (lang: en)<br />HISCO: 61270, Description: Horticultural Farmer","Input: 'hostler' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'housekpper on croft' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'hsmd med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huijsman en not mentioned in source' (lang: nl)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfader forpagter' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader husmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husfader jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader landmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'husfader lever af jorden husfader lever af jorden' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfader lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husfaester' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husman' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'husmand' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand lever af sin jord' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med egen avling mand' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'husmand med jord og snedker' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huus kone lever af sin jordlod' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusfader gaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'huusfaester lewer af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huuskone huusmoder' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand huusfader' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand lever af sit aulsbrug' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand mand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'huusmand med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord drt formede' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord og saugmeste' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmand med jord og smed' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'huusmandsenke lever af sin jordlod' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'inderster har sit ophold af g' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'inn keeper farming 114 acres o' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'innkeeper and farmer 37 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'iron monger and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'joiner and builder now assisti' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'jointly farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'jordaegare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'jordbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'jordlos huusmand' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'jove pages' (lang: ca)<br />HISCO: 61110, Description: General Farmer","Input: 'kaarmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'koertorpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kronoarrendator och alen' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'krononybyggare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'kronotorpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kronotorparedotter' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'kudsk husfader' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'labourer and farmer of 100 acr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'labourer general farmer of' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'labourer in wood man' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'labourer under shepherd' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'ladugaardspiga' (lang: se)<br />HISCO: 62400, Description: Livestock Workers","Input: 'lady companion on salary' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'lamb cress' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'land owner farmer 20 acr' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'land soldat og gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'landmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'lappdraeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'lappiga' (lang: se)<br />HISCO: 62120, Description: Farm Servant","Input: 'lecturer on human anatomy' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'leiehuusmand med 3 td land' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'leigulidi bumenska' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'lever af jordlodden' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever af kaar' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'lever af sin jordlod' (lang: da)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever af sin plads' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'lever av kaar' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'lierch ffermwr gwaith teulnaid' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'lifir af efnum sinum og veidi' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'lighterman employing 4 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'lino herring fisherman' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'liviry hostler' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'ma farmer of 116 acres 5 men' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'mab ffarmwr gweithwar fferm' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'malkepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'maltster an farmer of 60 acres' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'market gardener' (lang: en)<br />HISCO: 62720, Description: Market Garden Worker","Input: 'marketr farmer 11 acres employ' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'marquetric cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'marsh pinder' (lang: en)<br />HISCO: 62990, Description: Other Agricultural and Animal Husbandry Workers","Input: 'meieripige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'miller farmer of 86 acres em' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'national soldat gaardbruger' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'nursery man' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'nurseryman' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'nybyggare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'odalsbondi' (lang: is)<br />HISCO: 61110, Description: General Farmer","Input: 'oldermand for stolemagerlauget kgl hofsnedkerm' (lang: da)<br />HISCO: 62400, Description: Livestock Workers","Input: 'on farm lad' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'ostler no' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'out door on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'patient tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pauper for farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'pauper formerly salmon fisher' (lang: en)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'pecheur' (lang: unk)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'pensioner late horseman on far' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'photographic cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'pige hendes born' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pige tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'pige tyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'plads med jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'police pensioner and gate port' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'pork and bacon factor 1men 1 b' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'postmaster c s officer c s mes' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'potters transferers cutter' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'poultry dealer farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'provission sho keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'radsmand' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'raettare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'retailer of tea coffee' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'retired eart india erchant' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'retired jeweller and farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'revierforster' (lang: ge)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'river keeper game' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'roadman and dairy farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'rogter' (lang: da)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'rogter 1 fjollet' (lang: da)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'rusthaallare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'rusthaallarehustru' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'seedsman and florist' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'seemsman on farm' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'selveierhuusmand' (lang: da)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'selvejer bonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'selvejergaardmand' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'selvejergaardmand og jordbruger' (lang: da)<br />HISCO: 61110, Description: General Farmer","Input: 'selveyer bonde og landevaern' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'selveyerbonde' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'seperater of lead farmer' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'serv on the farm indoor' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'servant' (lang: en)<br />HISCO: 62120, Description: Farm Servant","Input: 'sevant' (lang: en)<br />HISCO: 62120, Description: Farm Servant","Input: 'shepherd' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'shepherd late' (lang: en)<br />HISCO: 62430, Description: Sheep Farm Worker","Input: 'sjomadur' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'skogsvakt' (lang: se)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'skovfoged' (lang: da)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'skovfogedaspirant skovarbejder' (lang: da)<br />HISCO: 63110, Description: Logger (General)","Input: 'small holder commonly called f' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'soefinn lever af fiskeriet' (lang: no)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'son' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'staldkarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'statardraeng' (lang: se)<br />HISCO: 62105, Description: FarmWorker, General","Input: 'stock keeper trimming' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'stockman' (lang: en)<br />HISCO: 62510, Description: Dairy Farm Worker, General","Input: 'store keeper trawler industry' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'strandsidder' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'strandsidder uden jord' (lang: no)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'stud groom' (lang: en)<br />HISCO: 62490, Description: Other Livestock Workers","Input: 'studentapprenticeengineer' (lang: en)<br />HISCO: 61220, Description: Field Crop Farmer","Input: 'stundar sjo utgerdartimabilid' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'stundar sjoferdir haseti' (lang: is)<br />HISCO: 64100, Description: Fisherman, DeepSea or Inland and Coastal Water","Input: 'superintendant of farm 87 acre' (lang: en)<br />HISCO: 61110, Description: General Farmer","Input: 'surado' (lang: ca)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'swan cutter for tus' (lang: en)<br />HISCO: 63290, Description: Other Forestry Workers","Input: 'tacking tinsoles on' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'taersker tienestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestefolk hos forpagteren' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestekarl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tienestepige tieneste folk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tilltraedande brukare' (lang: se)<br />HISCO: 61110, Description: General Farmer","Input: 'tjaenestekal' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener en nager' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjener et plejebarn fra opfostringshuset' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjeneste pige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjeneste tyende karl' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestedreng' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestedreng hans jacob rasmussen og maren kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk conditor svend' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk erik larsen og ane kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk hans olsen og margrethe kirstine hansdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk hans vilhelmsen og sine rasmusdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk jacob mortensen og sidse jorgensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk paa kaahaugegaarden iver maelhe frydendahl bagger og anne margrethe bagger fodt madsen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk rasmus hansen og kirsten larsdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestefolk ved hovedgaarden' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestejente' (lang: no)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl deres barn' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl frederich fugl og ellen rasmussen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestekarl peder nielsen og grete steffensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepige' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepige hans jorgen rasmussen og maren jensdatter' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepigen' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestepiger' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestetyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjenestfolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'tjennestefolk' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'torpare' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'torpareaenka' (lang: se)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)","Input: 'tower keeper war department' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'traedgaardsmaestare' (lang: se)<br />HISCO: 62740, Description: Gardener","Input: 'traedgaardsmaestaro j a w och' (lang: se)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'trinity bury keeper' (lang: en)<br />HISCO: 64990, Description: Other Fishermen, Hunters and Related Workers","Input: 'tuijnier' (lang: nl)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'tuinman en not mentioned in source' (lang: nl)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'tuinman op batinge' (lang: nl)<br />HISCO: 62740, Description: Gardener","Input: 'turfhever en not mentioned in source' (lang: nl)<br />HISCO: 62970, Description: Peat Worker","Input: 'tyende' (lang: da)<br />HISCO: 62120, Description: Farm Servant","Input: 'uhrmager og har foderaad' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'ulter hound kennels' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'undergartner' (lang: da)<br />HISCO: 62700, Description: Nursery Workers and Gardeners","Input: 'vilkaars kone' (lang: no)<br />HISCO: 61110, Description: General Farmer","Input: 'wks in nursery' (lang: en)<br />HISCO: 62730, Description: Nursery Worker","Input: 'wood cutter 203' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'woodman' (lang: en)<br />HISCO: 63220, Description: Forest Supervisor","Input: 'woodman employing 4 men' (lang: en)<br />HISCO: 63110, Description: Logger (General)","Input: 'working on farm laboruer' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'working on the highways' (lang: en)<br />HISCO: 62460, Description: Horse Worker","Input: 'works stable' (lang: en)<br />HISCO: 62450, Description: FurBearing Animal Farm Worker","Input: 'yeoman' (lang: en)<br />HISCO: 61115, Description: Small Subsistence Farmer (Husbandman)"],"mode":"markers","marker":{"color":"rgba(247,217,52,1)","opacity":0.69999999999999996,"line":{"color":"rgba(247,217,52,1)"}},"type":"scatter3d","name":"6","textfont":{"color":"rgba(247,217,52,1)"},"error_y":{"color":"rgba(247,217,52,1)"},"error_x":{"color":"rgba(247,217,52,1)"},"line":{"color":"rgba(247,217,52,1)"},"frame":null},{"x":[15.422389651335738,-104.34188812314373,-112.58905254203691,-92.092303205766399,-90.630125445996384,-93.841973970486123,-146.44924079977261,4.4262945279283832,-147.58104258825489,-138.27098246353034,-110.61323217879665,-108.71487418231348,-158.07419905819779,14.444082791361023,15.143575474754575,40.750188533523364,13.630104200641952,13.711492359673528,15.169768031865377,15.444921230193776,13.896642739906113,-153.71007905735075,-140.22351219472486,67.904998534249629,27.336954135873707,-147.7431299293919,-42.754827780184371,-9.6700645435967481,-150.28139852940717,-113.5118458873022,-105.28789764948456,-114.04364990705298,-111.45650669241073,-89.900339090017383,-137.08197485081226,-136.72416288178891,-137.74847513596436,-84.556414113726959,-152.83916070815638,-19.377955694282196,-93.228755132262691,-135.00819850333451,-61.554831332180271,-61.666517509406425,-68.868547398664774,-132.53447738024639,-86.641531015461624,20.972468737526949,-106.08904728759659,-28.526438726335748,58.243418451199375,61.730503837758882,67.9582624935193,61.024214249290509,60.248145189452835,-114.41255900928806,-115.42012929947407,-16.786874560708579,-15.210407592375853,-15.848290545889901,-9.923280784218953,-15.791826812752994,-14.566256917524829,-9.6993885779462836,-7.5674579019848167,-6.971037510452474,-28.39638317784614,63.200937039519729,-141.45609001993773,-41.339046537922194,-101.06556760612361,-102.44523309280929,-102.36892691668022,-135.78056924283689,-156.50044470089725,-109.06991612721264,-136.36569472382143,-84.516167991201257,-153.50303020728674,-154.3431870388803,-153.8527875986598,-153.55512281673407,-151.0948744260169,-102.95997575651855,-107.88822160381311,-135.94108238575708,-136.21129576742322,-117.47670706707446,-18.703664703617701,-85.694367176656883,-28.150876018354243,-128.21651462122298,-137.46487511265258,-148.84840483998548,-127.50963437324869,-8.1308257508104056,-117.04269202253268,-111.98153279210722,-107.14131327575532,-135.26439144489518,-117.7602281751321,-154.05112452013782,9.6303130775526764,4.481393543555706,30.074128314173212,10.245451255868527,-58.997661457861234,4.7143154683271371,31.294938768244322,-103.24940176975754,-153.40109087943202,-115.07099633330967,-91.073912357017406,-92.153248333508756,-72.685025904652605,28.940056026662937,12.818264218482394,-150.56002627946805,-104.24159788462808,-51.605010471285176,-155.65194080593486,-92.434230387523911,-90.808654651476559,-120.26323830775193,-136.3840875232199,-144.28618746455498,-146.81000144175434,-146.7369901057323,-139.34383641591222,-155.09726400014111,-143.58685305859109,-137.84577792612603,-142.66651772977417,-140.73128505444842,-157.18891579911312,-148.39148126689804,-144.6451779802168,-143.94286518723715,-138.33565089499587,-153.03338444220753,-146.60854669199406,-145.10004499384627,-148.31388856607728,-148.98115398653067,-144.46396609568163,-145.76447101699128,-143.61608164085348,-153.81046304921975,-144.44120427401114,-145.89282957345443,-157.65757571972591,-150.98400366960766,-151.30601480515031,-146.08404560976169,-151.07435823285994,-142.51220045461261,-106.3022246526629,-142.60241609280487,-158.08470508654315,-150.26055696481509,-143.92124057428373,-141.08944188751758,-147.4887638729075,-152.2032616987602,-139.72899419433796,-142.31443693004312,-145.78831650398155,-146.68587428939421,-150.78859205574392,-68.582700911794817,-114.29802489898668,-9.7254274554557139,-89.604596928884249,-108.9051745174451,-151.5647647007435,27.875489909321907,-147.23474753664291,21.44140493023961,34.402451908343643,-145.46475793437969,-152.96497876337986,-152.94463440529671,36.419629625510069,-140.74511330157461,-140.68779757418579,-107.22776262956529,-102.27391846771013,-114.90785250248827,-69.003048205314869,-59.379663260178795,-28.969670870959384,-30.127179744303852,-29.647124538708237,-29.195180118230745,-135.89716747483891,-89.031278063108729,-133.03417706520804,-89.878416179669799,-132.93285251784232,-134.57847201400634,-129.79351168073512,-101.62020081309802,-52.990578606709107,-128.41300718617262,-84.540433068724624,-146.47350920306886,-98.024447590935623,33.357436585731662,-153.58689383460856,30.560386915383763,-139.72952503279194,-133.97174940553501,-83.514806922766851,-106.73189375392849,-131.31755167196474,-133.19079133138902,-130.90603920570535,-131.37184320909208,48.114944809491377,-152.83893506439543,-56.154360440788956,-111.78146981547594,-123.1974200890125,-154.21258718732193,-114.90703290416056,-130.12947740639669,-134.23255277145671,30.58887997734173,-108.3182206197443,-114.12478931979906,-123.63025677076163,-118.04914569766706,-109.14767063231466,-109.03246613717278,-99.892549590562012,-121.98718872940235,-116.34989335734396,-135.37026260604949,-151.24206545489164,-140.20856421180792,-55.326685964351796,-125.44255428458905,-149.15068706004118,-111.29501896153653,-150.39599494778622,-137.04607805573789,-67.228134178622796,-101.32505728416109,-147.37338922054269,-101.4884352433904,-128.29663446334487,-103.68345909279947,-141.84773081685267,-89.417709648437807,-88.386307488579192,-92.430303477402987,-34.141833419821914,-130.25753382152527,-56.300234776344027,-117.21889386680068,-111.45057950669151,-115.37365718248962,-112.31483297666892,-48.251033433873772,-102.49043599203941,-108.21602940904344,-111.38777865840378,-111.7509230144112,34.683763586802762,-109.58451032465008,-85.667317242730761,-84.703825896468359,-141.34794740388458,-28.512274857208229,27.565006512573571,-135.75666154388784,-100.64791603684422,-84.860199387793287,-96.774095833184418,-103.04271945147586,-148.55372244703773,-85.232405826072366,27.899940837906776,-10.624868491893032,-9.4620513684746079,-10.882534241097412,-18.934836038708966,-121.51140242822729,-147.82557472910548,-111.82672249981016,-148.61999600945751,-9.1545073826989398,-2.8679849053561415,-137.27492042587926,-84.356057390740602,-86.146861978877894,-84.933890694659965,-84.82737086793702,-86.784489037111001,-84.694030811177839,30.547753947602121,29.174573547734152,30.369106134332952,-108.28447008739248,-51.108628220365716,-89.042166495751687,-118.43405900310536,-131.32321140645394,28.447521440662491,-98.501665166860931,-150.37370864670146,-156.93118499552608,-153.95306401394967,-149.96129995408077,-120.74245160877626,-106.9824585126204,-106.93411896306866,-109.98589844287447,27.5123635971471,-28.176079382860269,-108.54205914014965,-109.93886930297866,-105.77114016965096,-126.52933314782526,-101.8180416559284,-29.01552741200658,-110.3943251577159,-108.88835546205154,-110.32313461555468,-111.6245207171397,-123.50042637230789,-120.81265825856666,-112.04807190015393,-122.24885787761804,-155.47375313577936,-91.856105272526662,-138.57840935364439,-109.00992271334917,-127.99729914277825,-103.19650362806004,-101.56082885671529,-104.06614947732949,-104.54397124129298,-107.81475402820743,-101.4395200096601,-102.90937372923058,-142.82130228559188,-145.58383327098113,17.003549114065816,17.44039533088031,-106.59831505510607,68.075715641128923,-41.750998494430021,-123.2798486871703,35.788794483598579,-153.92834067197543,-108.1224578605685,-109.39110387930299,-111.60501791859012,-111.47608398933974,-128.92537527549533,-106.24053482444002,-98.91525490526935,-37.447642268555207,-62.136975202979144,-106.54983577710522,-105.18206317377535,-106.65057840435983,-110.40526877312739,-8.7664318987927459,-111.16926508788451,-138.91810690249147,-115.90107550995917,-128.71334794423458,-30.20035710432186,-103.87289443408162,-67.984456200519105,-147.6042699354125,-124.45026913801436,-149.52164757516115,-83.055134295047779,-106.47738915431363,-101.75731220521448,-103.9214385541857,-93.786591122786859,-106.60378523415538,28.128885953735299,-97.223835950613093,-9.6927631952210831,-153.89626000458901,-40.639543257305611,-119.97334215632392,-98.869488419841076,-10.617616512213594,-9.9897992476813613,-10.675603289505647,-112.70897557955485,-129.41800709606292,-143.97168530487804,-124.37392181983363,-102.53859191800746,-157.16051388958448,3.9653243555447899,-153.19717244185964,-72.982889176417189,-90.273005055696984,-91.820748163364286,-104.26464574151659,-133.66371902649675,62.112595989839846,6.358921568421847,-101.50709488956176,-86.146399026015445,-132.51153879529099,-91.343126523553607,-135.53343123032147,-127.54803166036278,-150.9986432419864,-133.44012036859348,-109.58397180189235,-77.604939955110098,-41.366562951398279,-139.29086294349412,-128.23708889839756,-155.44692438686232,-94.891679020789283,71.283659951558093,-151.37245694091601,-105.00328078431683,-145.65707852944161,-148.091104624064,-93.960406899993515,-134.36898831916307,-138.55509658723543,-103.87962575572877,-105.44936292708205,-116.87167384136103,-117.68059845973401,-123.89848955396721,-112.77921876772525,-151.13430922824068,-153.08322291801136,-93.007909833073072,-92.325177427324149,-92.714812064230301,-91.757795412303409,-90.078045262442615,-123.60520675903643,-115.78067749603778,-123.88152083719281,-150.26849623085346,12.614554074525868,30.16168855462648,29.346410071165565,29.668834640592586,28.265394357458725,-92.773837655396107,-107.58847294331326,32.907634517464295,-54.63848752364796,32.68720295692529,32.761148084887459,34.741270771322426,34.560266070779079,35.68186650922825,31.57041338923959,-101.61468594834498,-119.03239127836221,-26.585601295248065,-26.734581564275697,-27.111323439604533,-29.687860358778952,-104.63516218140353,-155.7388172397969,-151.87135842005824,-121.63303560565673,-34.716353617694175,-97.66268257105601,-144.79880183320441,-109.48444964382161,-111.31120761199307,-109.18833806969279,-110.80024783427426,-109.98039252765778,-134.2764109274475,-1.7353375800239739,-105.68983284236224,-81.523110834540432,-108.03680008391103,-93.023199927031371,-152.53567849054804,-52.364188871343437,-55.313153084035832,-56.253850413740267,-57.360292459381753,-51.032369555938971,-32.25663283497461,-57.565881179740451,-50.755251495367148,-58.671274958447405,-58.914868825659141,-149.81773360419285,-38.745433323121233,-38.752901482190097,-157.246315952738,-131.68729312063749,-140.45271073837694,-146.20919860186731,-109.86944337621715,2.713261165725823,-82.768506727725679,-142.11819691891037,-137.73780291528379,-154.08490085587817,-90.863245244338032,-58.607854507844884,-57.263064125331361,27.939956334145172,-134.95638664893406,-64.871388382767421,-110.81575351933942,-127.83016851881106,-146.63907736730317,-145.65714043998571,-12.044073724444525,-11.057448018348872,-129.31116961740054,-101.96708574280918,-116.93462141248372,-147.84232641006574,-150.10965823456792,-142.88246604743037,-144.23527179953626,-153.37635675359434,-114.09483560266061,-125.18815153568397,-48.310623704242637,-52.719199230056411,-128.90149440118876,-122.82861042908513,-127.90635522636582,-128.63023223342174,-125.37425835242882,-59.140424119458906,-98.812580990370137,-36.44164141795185,-36.085398000602275,-36.81102248415764,-153.02161570629437,41.106201406027125,40.961787852861171,-51.122681516479552,-87.720807785982643,6.2752533741614531,-143.65251462480805,-126.36510342231517,-154.61091063069244,-82.885197425704717,-114.96018529840181,-153.31223037396893,-109.44870682160459,-101.44275353119558,-22.715691791920939,-109.11045829873406,-150.70648037855776,-158.29152838734507,-151.05281340297637,-155.28377377270846,-154.02604849961546,-73.916569271479773,-7.9898624657686161,-90.384221348048797,-90.171260852037094,-79.085315726877624,-80.469391318988698,-88.309269942083162,-90.910712356121124,-79.398588636618499,-85.949984525550576,-87.917542728528232,-89.393016502322027,-88.617160146123226,-6.901676549242266,-93.950513147403257,-58.009737237773884,-74.053713430691403,-142.61199701280427,-146.99071898821799,-119.30862466248009,-103.19406089409523,-88.982007065710206,-91.965494332223287,-91.536431365387642,-122.75474245202064,-112.32009907553173,-112.73028907820493,-143.83345762636367,-87.358483372818938,-142.09673134313155,-112.29104984621546,-37.802105063327936,-40.87865824775659,-108.08192629478918,-57.694201276281667,-104.03789184636632,-103.19623323439029,-31.652107163121102,-90.574683242685822,-147.08903799436666,-115.23100671690814,-148.82336507138515,-107.91536144328356,-143.2642783436192,-11.396079838295366,-147.28261998255846,-143.64179203991804,-154.45988646127063,-93.327199480287746,-146.81900476559102,-114.1192639864267,26.93167626819054,-11.584232794890868,26.282439006168026,25.754023203666808,31.274045703203367,26.102083700310395,30.838476916992292,29.51789973711448,33.171485564561017,31.796105674399492,-7.8304889259906298,-6.6937510690097914,-31.353696197276413,-84.905723450317922,-142.54697319795164,-22.767844859857785,26.825952947986188,29.562701221415658,-48.596115674172388,-102.08734906478841,-117.13040117584509,-118.12437115061228,-118.77334491971651,-118.25425991350717,-116.52094844953855,-119.3765465596566,-152.9918518193187,-153.977441752934,-106.42104899809219,-115.50305012611513,-117.05976885377517,-106.98541831967252,-147.6814325577524,-121.27349906996216,-113.03466409377405,-109.52843184990429,-113.42028943179454,-112.06652219513587,37.346789910098721,-108.49007598982612,-105.16929920097188,-106.20973493016787,-135.35511685860791,-91.764321599510737,-134.50049872407831,-92.270388166662457,-105.37531708959783,-89.90012664352632,-99.333236628561224,-47.997635163940473,-110.41384693364589,-135.86949636954856,31.232720409342157,32.101548747340807,34.476419896281712,30.557134757619057,31.279075868886245,31.858254803916441,32.239016393802785,27.44054774475504,-91.858257860856042,-92.550116002205399,-3.2255691598885416,-2.9107599620363267,-105.21905475197805,-40.792685886449952,67.225045746227309,-54.95976332746087,-73.068178762858622,-155.44101047537356,-144.56796811462237,-102.59572955646411,-115.65708620940001,-138.7277425055247,-149.48812878360658,-121.19533858458415,-89.52240733236377,-121.236822030816,-127.06961591757242,-127.89090524994822,-126.99396057320114,-127.73410353602581,-105.97776269113747,-132.2118176196596,-51.380246453922126,-50.236322666740953,-54.469551248647058,-134.88803672004087,-38.432936852043056,-155.71988306687695,-155.77810261266947,-154.93651278454035,-19.170014133793593,-130.90287569405137,14.235241316511976,-102.12851962845923,-126.1487795760337,-151.33589916024448,-126.24806298323611,-119.44196535703593,-148.36806570625166,-106.47995574532186,-106.74367710202966,-104.68889390286056,-149.36870403285596,-41.221328849910883,-42.030093653676509,-41.580160935814597,-148.88006979356274,-146.82801491863245,-150.00887115806214,-148.654115111659,-93.823519638521589,-138.24538101571088,-56.926144112365641,-43.237174261626421,-142.2673648177387,-129.59408193818686,-115.60877912133708,-154.78348723583724,-101.58896119594085,-139.25439705621184,-46.975526871879161,-152.75354384948724,-152.0755230707185,-146.46099317338334,-154.47788957803087,-148.91171132186653,-147.25714070248679,-152.28044821058015,-146.0519073651819,-113.02523629841582,-144.42481779141346,-107.37828631428147,-152.85488424575226,-153.37456664876757,-9.1976480599005139,-11.347864153558355,-136.1558934674687,-145.42591818282114,-105.30922231437577,-144.8019215306322,-142.42315627871201,-120.73003802294708,-40.502796299401616,-82.883685065405956,-109.65904125223565,-34.253180920937275,-149.24024140997415,-154.26057959475995,-142.06812979047979,-108.75393333337655,-136.85245458479625,-110.80727022829679,-149.97320398815316,-108.37047478957692,-152.10680022088809,-135.13892009168131,-102.83628866428025,-113.16679657301817,-112.17861568788257,-155.05138182251582,-107.9739940568651,-108.13403698369012,-59.132429043905987,-115.07799621726497,-155.60189389457173,-152.61204237208818,-109.26618174352454,-137.9741058311516,-106.74016150874192,-109.16580155642566,-101.90714783704225,-105.24882280982035,-88.475550891490812,-109.72394579679711,-113.40788784581227,-105.73149893893418,-104.41717919569906,-105.61738720881311,-104.6628935000243,-114.32291829023015,-103.99439004985305,-56.42196192705876,-108.98757806009138,-104.48606265019829,-31.831581829731093,19.043381901246683],"y":[50.434691683594416,-8.0248520092096154,-1.2834491345237571,25.210486609487646,-38.042120405035064,83.530255746696454,-12.185362028251175,21.585272926328901,5.3378236284166167,17.477282610293173,3.6788020065969618,-7.5108215356998356,19.783280553650862,-23.312821520721048,-25.525529225056825,-85.148739845747841,-26.754454931977111,-26.260870071043186,-24.305632869957034,-23.911692429462498,-25.011405503870723,19.157289249019936,18.557072271730934,-21.798104283111119,31.382127033233242,-36.725419963084747,44.245262725684825,1.2931897986493737,20.997540671486224,57.999768680489957,-2.4296360950527656,5.1454535115210813,53.59656004735924,-43.32507292975928,1.7264636340438255,-4.303220694766642,-1.133492701846863,27.670222976376124,-8.1315063169495456,90.620525473242481,12.316530527077582,18.441990495007484,-76.898733358971327,-76.929241325993274,60.838922552713832,21.184594758249979,20.376676811171105,-17.021777724617046,35.916288202500894,0.94679916360814986,-96.184099477299,-92.685358315434968,-114.93029861239185,-93.227574728400768,-93.849562962234941,63.210482504567821,-1.6205975213078145,-3.796265876423536,-3.9598572331905459,-3.4503174960010838,0.26439484303953936,-2.4779425779687823,-2.8197250655790946,0.14311072273362571,1.6293739169452506,3.4275119702820085,0.32971436794177122,32.99457137545582,-20.057580945494635,0.61346750701552766,-1.4705745528226426,-0.96749814604074391,-2.6966215867001186,18.577741418133382,26.817695590080437,57.122962743194051,0.64654164534228864,15.152275400049527,36.399421332833938,27.351828682745996,29.658153711285514,37.740428636947293,24.293392578913942,-2.8284002563423636,6.4020041420984422,-30.498333070585741,-29.995001728277362,-9.41541863174265,8.0940223408764354,40.719528508584467,-4.3165954510634785,48.34367858155354,1.1817353594082469,-28.034336455852422,1.8004744768966412,76.948198795845457,2.7602534839156077,2.7346445573120195,-7.8248530124090916,3.8584384960162601,0.0048167100229645921,-11.187672932836779,74.342563929593197,75.664266968272372,28.629519071460624,73.98609726047647,71.336062006910481,75.747254038341779,27.548619015759524,-2.4677308393538673,0.83526726706938348,58.235083164417887,16.266946314310076,17.313338728075536,24.885184989847399,26.879154536498191,73.514317964327304,-7.3160865895861074,7.0207830116715639,55.578589633609404,-7.6847418861432821,8.9714909993539464,9.6895137303564063,-50.728135572490714,-3.9111146321039687,17.448094556923373,17.472819620858477,17.369505353988206,2.8143485568110806,23.243979799757224,23.331517519065919,0.86637971022432214,0.98241672856407525,2.9665045595743393,-2.7891107660277217,-17.58970691634384,-12.752628037245412,12.698192032854791,14.858681395161861,24.926832069958273,22.590268262715497,11.207542379141284,-1.3362400983191089,-11.89508770318243,-16.878941342931345,7.4453303122373757,-14.1273197058654,-4.7898953120974097,-14.108315875423752,-29.49020574160771,-0.49673842146473474,-0.71742154042191764,-1.6990241596645914,12.111175316156448,22.112868651807048,-11.6088734856166,-1.7408840583751697,-12.113858559674524,1.186155157208693,-5.4624710876499298,-20.173338158966896,1.1502914726656006,-6.4731310695034026,-4.7231867973449742,2.310341274047234,-28.56371726558779,-26.932286677897149,-19.398203251674097,-8.3031972562421625,-9.5287682126202036,60.284849565930983,-28.819738163151754,10.214380458264445,0.48781954121817866,-5.7556239473003004,-86.858350302496461,-37.850081027395241,-31.68319411933545,-46.898976469496588,7.6622010149275761,-0.19679312090214082,-3.0257205409586905,-44.377306603506206,15.275837460589553,-1.5401404978806181,-2.0744200351266286,37.231288703427914,-10.964059007512912,31.426126661837017,71.877485030893027,-37.957327915938912,-37.945294850850104,-38.970727197604099,-38.498787996997997,2.5116579352809936,-44.79990485885304,0.74365786919973476,-44.456649537946063,2.63028995232533,2.5523364683393566,3.8696267267742988,-0.8930723893623923,52.184287238345647,46.78553085404635,15.585248674498478,-21.702505777606991,-3.7891318241783476,-120.46214751556816,38.198639978302637,26.429701188504772,12.624204327587702,20.839938574355536,23.371451571223631,32.110551635180059,21.804659017107468,19.939558314763552,2.2812467124473406,5.0131727099670709,-72.320884464777166,21.276856971016979,-59.075892784889739,0.42177070762044938,8.7327429729519501,-2.8361381781564505,11.721573043534967,1.2960617245405386,0.22702696783931114,-100.16488886897271,36.170102249641843,57.250942843432497,51.143358768167154,-10.354860779590821,6.9552177131672348,-10.1144343744363,-1.6042360735368479,-21.60007607414995,0.62985549747986846,17.946904025532614,-11.279430285171207,17.219588737476059,59.55852694989651,48.512352440187705,-5.224669708525183,57.851140378319833,0.67677190639516793,18.42986898057897,40.190411353428544,-4.5013628988720198,-23.211714794790559,-4.1301147914980865,48.568777690791812,4.4795121511992404,-0.96604834667774897,14.343856589474266,15.343451010178127,7.9939498883589248,39.572609768068865,2.9012725540945072,-58.962611515664427,56.212861575644517,55.70422979335909,52.663406329568005,51.570004533460079,83.589064201807062,39.291660793082741,46.511061158229133,49.093339345121336,56.830081616245614,19.243116804714628,32.951634115025769,15.152320584354689,16.865667163651022,-23.264633606398672,-0.54274563294173939,-94.407282278606445,0.36386865848683775,-2.5237492610849062,27.433203118358911,-4.1339831453495695,5.6913496627072941,-26.149388589187463,23.241790242536375,-93.696469721175134,-54.096013449047362,-51.541635549058149,-53.570578780252468,-19.153454089810317,-9.6305442359760338,-24.655549463585306,0.020609038675210314,-38.313045706564317,-51.17339725697024,-41.67838355816253,3.4142779147656306,15.058519272296742,26.680324548294767,18.968538141904673,18.637495959804067,17.634983970028649,17.671239797370202,-103.39598641061157,-87.04012830304832,-101.6378975162274,-6.2315733819952737,-13.802341894961209,30.147079144654022,-57.226040043811189,2.2529214641982382,-87.874552396737784,-2.6131497479575225,-37.651012780616178,21.021903233111026,20.598753439118425,7.0128074451638387,-33.520900843536658,40.801055037450823,34.05872207409098,37.068329362489358,27.411205844565607,-3.513033167443957,33.205083079110601,60.764970488119857,34.392630192351184,44.832952028827691,41.599382686978899,-3.7412352959427588,58.329067772873749,35.779914361391334,36.430999076710606,62.367557807531618,45.377688416931917,-33.496263697199538,60.37807834747025,44.82665333845889,26.831737756245847,11.440804837574463,20.225992475329711,62.678418786198606,45.420413323786271,-5.0186001696174234,-3.0475916291933176,0.38138888103115381,3.0553842283684016,2.8125579960377936,-3.8783731355210143,-1.0921888383918255,-19.599629030044227,-35.438696196795952,-63.951407160545848,-64.005095591435307,3.1429401370967556,-21.951386636676471,17.567163359031589,-44.892376020665587,-22.104160061401707,25.29534890510735,33.830391531662634,34.344033609769575,62.334224234553886,59.43964158470002,46.095503482724318,4.0179738946324903,1.2122888321611254,40.451303953786599,-0.32947435985993939,38.478549275487488,36.656888425486628,0.93733934222606308,6.5874399699872068,4.3855627947297009,61.285783368494059,19.101878716743943,55.316498122340938,43.811237558165388,-2.4321009534396376,3.3576134054340101,-4.9238157391935786,-24.561414535706792,-10.490252844777714,-29.967594542492453,12.279329632672042,35.715598933568607,2.6896840633505574,3.9833978081011994,16.269305825853827,44.010603727621991,29.376009904345551,38.563905626036565,-29.081886991105865,-37.474123254378625,37.141431079908372,-55.517471618703098,-3.6635372213194746,-45.738973033213611,-45.77720191091916,-45.075176150336617,60.494236895438,4.0497556385577766,-22.635318920390439,-42.979482281718496,1.3940260544697121,20.434300812785885,22.901370506331681,21.419958782202617,-9.4754375270139271,-41.603251820986635,12.908609145191642,-11.33972805780804,16.382370588766634,-92.405305635821435,41.081425983902697,42.488629831344021,17.644226333167641,3.6593348558456826,7.4941095342291844,18.216508635101587,6.3446138782609083,-5.513798857220654,4.6906803574613987,46.695486973548974,38.506077336356327,26.120277718650261,22.347899446261998,5.5471210142756675,22.181090045931949,20.366473248773683,-49.310579435946899,18.88413563228513,35.829249003847956,-17.974277342356036,-6.7758735656816027,81.634343678466436,10.7340796438463,19.86761856825191,5.8458699301435555,6.0612504169065833,-2.9096565210592025,-4.4447713824543298,-7.5399908518206225,-1.9896428293619806,5.5567031898437476,25.738234301416377,82.68769628825747,83.782115404989099,82.252060148457886,81.960650028446636,79.950481005465591,50.467833886215359,3.631575957399797,-7.9563785727436276,6.3087493664404573,71.85650843783533,25.663793270243772,27.002558838023017,28.474214887136426,27.654267930172661,82.903538626405847,38.347690441086549,-45.222221715165958,27.529959579789011,-43.52551463484631,-43.945502431325586,-45.201492130008852,-46.598836436482181,-47.544215423853103,-43.930370465730356,37.956402579043825,9.6717818007339726,-3.7018418998685347,-2.8155385894952474,-2.2899339772622631,-0.51671437956740474,-6.3737847439039905,-4.7269391751024843,-5.8786344511730455,-21.184367700198013,52.294173738396871,36.266172920077459,-27.658181468496853,63.160332334054495,63.294749252061933,62.551977408673672,62.984692264132299,64.034872828097761,12.459911217559821,-92.155083866403629,32.504339313702047,7.3686102481890003,-9.168572656554252,15.069619803098462,22.987428868405139,56.547742039683961,60.205428294742262,58.137348707081848,57.549749492833243,54.267884842556519,41.441534109905461,58.582244519226826,56.902808810339529,0.41305792169495748,0.60606895411073392,-12.166623586874261,-44.919766108555756,-44.973959570504299,-5.8655879573278398,2.5373008603796063,-9.0897613950214229,-23.930411824065398,-2.851729169352494,-51.106231983603514,30.182468156678489,-7.7294955494817081,3.1764281073155671,-5.811614828196805,18.021849936492593,71.770325911131849,69.943716980997493,25.443636880933326,2.3747573044593229,37.657645343064367,35.482575517650751,47.370241301775451,-33.659479490959953,-19.517521608872304,0.34899669043174381,2.2966484625658974,47.002237481753845,35.317807621787985,-7.7797379460997647,-7.9789574727136907,-9.5882300019336313,-25.698125700747539,-24.51309755608548,-10.538398493687209,6.733687386421324,45.337623242607194,82.259058680902982,55.918761007429424,36.046328553377677,46.821907591462946,37.387458704626383,36.396634089808316,49.284848668591295,70.10041056361986,33.818828815199311,-46.505585331447236,-47.154717532431704,-47.106717976298299,-39.429552823991074,-78.671414174118752,-78.624764353467995,55.877193671937768,16.220340330175901,41.208004431937304,12.375472294352406,48.613794516516975,-7.9810031129301802,13.813906693945931,59.906421744239047,23.319952802741639,-3.9557454515568495,-15.494184052714614,-40.911473622559363,-7.6737437394532684,-2.6959631276810061,2.8340447025943347,21.849016088717789,-2.002918429357837,25.463489885938941,-13.061912201948902,-49.666026703193509,-39.141039107946362,-40.050622265645806,-36.547104298479056,-36.942104319800784,-41.607378408144854,-43.113970792556472,-36.044161504669553,-39.112281274936549,-40.147195476830539,-41.390658512212966,-38.553878473511922,5.3033333051671043,19.295229168875075,21.126285603846107,-13.523474565366218,10.700264219177056,-26.527592595981886,-51.844964849510212,55.840278953317089,24.598530241818555,19.999627387289273,11.419153040013912,49.065565153335889,58.693944123139154,62.168447976102556,22.385826296208212,27.663862435209055,17.504355949292368,4.5369374861389566,43.169659873720029,44.849740516792281,63.024699620072411,20.781181662303482,-3.8739524234063802,-2.9810335700813737,-57.363821400449609,-43.865892233817412,-24.322274594807919,-3.7353509354427259,-25.293392812629801,-10.532839690837804,-24.296557898845258,-83.049160722078142,-3.4811977346796268,-1.8747440958795869,-6.183422215263958,13.388480675069523,-27.776342611601301,58.450331959688057,29.067127502436392,-82.175237029280424,-89.533983554146502,-87.218176729553363,-87.026566058017082,-87.820064231488431,-86.171668670623376,-88.507087187697579,-85.410097823076541,-85.858175277128595,-0.72473947969639274,-1.9319380161054993,45.231721451899325,10.491643019581522,18.15158323266219,-40.794188456145086,-88.791845855888525,-100.70142068156056,58.553714633342565,34.25314377006265,-57.180705898108677,-55.762513247592189,-54.440963581542363,-55.284422334309454,-55.06125848919433,-52.66495658632023,-2.1692233072300984,-9.2032092581356277,-3.245089445171268,59.231562997696194,58.212657201439896,4.3441863475636575,-22.820706914208774,52.263240892910041,55.652611792360553,60.605514405641379,61.796642707991843,58.37255403282888,-75.918982600456147,57.989830588309722,-7.1923279842128807,-4.4929926703320726,6.5745121729500129,9.0823301452150105,1.8519869555681767,8.3625427959845933,42.602001385146394,7.8736211528941826,37.187718706231166,83.921340148542072,64.975190099245864,20.143687809682191,-98.412350275362016,-99.501413664236196,-100.14286582361254,-100.05311232297204,-99.965060299691672,-101.17477347087234,-101.17019390108783,-87.838365360996605,7.4968003377152668,10.945233157379624,-92.33435986060104,-92.226269522815187,-2.5686063589285069,1.1172658561516204,-21.255591964619544,61.145020053198245,-10.648923043681837,25.567273780640274,-20.83977333461846,-1.1713869441770406,-2.9822841546126964,14.93149987593535,-6.0355152519306907,-51.905436751277421,-42.79847712559021,-33.36127781862691,47.39892010752552,46.342044390693054,45.771945866341248,48.041559604516998,-5.9116455276106716,2.1604083332039763,-14.161017103399139,-14.428789887484335,57.782437092547866,2.5724517849293425,50.980832701312771,-39.33778283327289,-38.108443226186793,-39.436290036761264,8.0796517128401959,18.216929951214244,-27.612544434885315,4.788191716208738,-9.9907050900276069,-2.9860536294215136,-9.8168508834282786,-5.9046004926348132,-11.411909091201625,-7.461110291575701,-6.0531857975642049,-8.1663813184968461,-20.040012108098203,-0.024752508537748557,-0.52632703262623959,0.35756385868041562,-37.024764944681323,-38.365268095248268,-34.526418098446655,-38.963661951882251,37.365687987848936,0.02500163819475329,19.948041376113295,40.571947181067074,-2.3631253587155117,-9.1057665604965461,-1.9131668600848988,-5.1987474518934675,-7.4297947448352106,2.6669844405153489,84.172720473663858,-35.328496902977832,-36.401879549704709,-18.634130520738353,-12.244360997376484,-27.706619974970046,-28.34403550029543,-10.496877551412553,-21.21239763271247,0.59035954510457256,-14.415976212853018,-5.3137759951618362,19.738443251369389,-38.684646743990577,2.9769070181863304,-0.42229805290887917,16.096383623363675,-8.3210968733017001,-2.0110391568657282,-18.312609023513513,4.309677033311301,12.472899679634571,36.514372152654097,18.259049113800764,7.8855825357234224,42.51325358350438,-8.3438882645830788,-37.127031233420979,-7.9210355654489772,6.3929738934925302,4.5104217366211641,-0.94486816728928202,17.13173739223279,5.5216624123037032,19.146240004911501,6.2724840391319159,0.82552966356475721,-2.1584309258015342,0.17303375376362676,-3.6350178111821125,-2.9856425069351258,1.8686729724744957,59.827633394474582,-3.8775997502642339,-7.9735716095686824,-7.4168620659721789,-5.1735369409762857,15.476548065974335,33.803269862887483,29.559411097113163,0.95122220315916617,8.813786931390057,-39.875065922883842,0.78152499681595278,29.007229269007894,-6.8719886090641955,-10.815636017220196,-6.8800848063516478,-7.4962020026434999,-4.2132363602113774,-3.7504224729382449,58.311895558772477,-2.6875849380786523,-1.9523279255238022,-57.298965634157341,-58.598935706335205],"z":[-14.51956814480616,81.263700361007949,74.132036583315227,15.078535632744511,-21.717853365541579,-6.8634800912654521,83.505044104648434,-86.002112515488108,67.964050825473265,61.51456013474828,76.904325631509892,80.287605604503412,56.218903635170172,22.069558933676465,22.342933254556861,-6.6378254014702254,21.65383786232702,20.46730422163839,20.934461534840899,22.545756971898239,22.234870137816301,64.167497725716586,60.563770012275796,-30.039824365713713,92.887885489654593,53.737305372775083,-0.83943902240896517,-34.45754831166618,58.639988269247631,-47.124811929573085,87.659052700492055,72.980018489522777,-54.134991034880635,25.331453029821542,27.092917969490745,15.454699387411489,25.374186186900562,33.355016534517617,91.214451929082955,22.500329184239785,26.84097001776146,57.63741895479626,35.628045569975768,35.565192110919739,3.6044929627451681,59.218395240427078,41.299854085249194,100.02117204704031,-44.030820800460639,-46.289620660326044,-16.655665876059839,-21.136011766193501,-17.194243966863354,-20.198503342820448,-19.174883824890518,-50.330552924386865,81.548719277428077,-38.006686774299276,-37.980504016732972,-36.58660756355723,-32.876286200213272,-37.843469522166572,-37.035951345880207,-35.389966521239415,-35.969814824717176,-32.02587141576911,-46.227400028708935,-58.362741836143563,56.119877552044144,23.356443272809159,93.203650234449157,91.590946813035785,94.111621081293748,59.933164898359699,65.289146121264963,-54.825926711411256,28.548641794236886,41.068837756793513,68.592157749754406,65.475575843294209,65.411231283137582,69.351996813404355,63.684422750819373,83.234105614498475,70.529145712590932,59.942985968240862,59.927178288300894,73.006648642937677,11.886173971870544,10.914634622162913,-38.845639267041733,-39.884345123699497,24.152877891472748,57.618308448713094,30.95540936699939,0.12940893817731342,70.109784448977877,79.58767982411976,80.568031056648664,27.758178137230438,71.260756036821704,91.028098529389538,23.634588353653371,27.905734887425254,91.602984339384278,23.62818792657816,-26.391373044461805,27.360088317830051,92.880241314027728,81.137583974744786,84.779984427476606,-48.752011051523731,23.573213572430927,25.219105032808177,17.040987279248533,94.241423682120114,23.182857612353178,88.99888214240049,82.318794909889732,40.17011881233045,89.400691454308074,18.313439836845905,19.458690812752746,61.048324078884107,15.574684445861338,62.499995085810362,64.580244466670834,61.277914539598171,30.431977966216142,63.484037447869383,65.83974769186095,40.748802251623744,66.583370375781627,65.709203297537286,88.762528976105514,58.672775677013078,59.055947829599134,67.253787135459916,64.649904917677716,65.037974549460387,64.819498238642311,66.778033139442158,88.559997600402639,56.287781703357808,66.383146304417764,65.45451512962633,68.209628356578392,91.70127132583012,58.624431288497249,59.651307683518482,88.732529064274473,92.469627296808113,93.859477188320312,62.652170169697037,64.498319761603028,57.044837791155686,78.149340917525095,58.553369183213633,86.236682659165638,82.771537834391935,61.457371683345116,66.474387290099358,81.174273913583448,81.6587087189192,64.223749160251359,60.653863894924569,58.944785266744283,58.058110353469822,90.945540566500043,-95.679506138667975,-50.20073992336156,44.278412617451231,23.305604064056617,68.307360202960353,87.003399378799443,2.3901762524384238,55.09139746218186,54.041922395535934,-52.596341765829671,66.83062413432954,82.668652457192607,84.386179311570856,-51.877706393108618,63.255127632140955,81.981203838104932,84.875380490691683,-39.882310202708709,76.971216455656332,14.013770942207453,-26.500033155115418,47.840784988068144,47.446682477234347,47.887605163935888,46.637971147350235,21.009438847272595,24.842086488662421,24.622882632661707,24.717866917340874,24.299159055688985,18.701005582270902,23.68431601521344,78.032854247093937,42.60839307904552,-40.292113290467967,43.413813147685396,59.319523016547542,97.9127357387963,-53.388666180023101,69.617102913324644,91.009276378698843,62.909798689067173,61.389048131094491,36.398511741149214,-43.050652388392422,57.459943291047679,58.080132474040433,16.697183566747363,26.043887708566906,-5.6166090933891342,56.809747042487992,53.715476652823334,55.955688660243894,9.5894792002932903,89.535320252451044,8.2052448501031225,23.933351525220598,27.737356456003802,-29.798434183928482,-48.938707520703979,-50.709438941256728,-45.259528129768697,73.394592099738929,96.726187411988192,69.070267403336686,83.79994681442497,50.968397221097241,75.59323434712195,62.441377810503866,90.692937747545713,57.994945530100523,40.623437218165925,-40.428195900007466,89.932788753960835,-52.780521850039385,93.562181239305488,66.044756796620803,-0.84499476392960737,86.182410757646622,53.89179572418027,81.393690897471018,-37.744691533846932,87.801173498720445,83.972055377662429,43.773269813729726,43.392264495193778,46.850254755307475,-6.7919946248954135,20.183247362247691,53.639840197733065,-49.965074184286294,-53.608770657131352,-47.833104014168526,-48.611003190995206,40.286339658114628,-45.001352881648266,-48.642033902234502,-47.885435789052174,-50.869485309514694,-47.413981256095362,-50.970284055909872,38.212396264983596,43.127495787930272,57.142431304056302,-39.848549495910206,-7.1296638550345177,25.849257319902748,91.429833043420658,35.404163181283224,99.28224861708874,82.581247794365837,59.093290898349686,37.069722236325703,-6.8400597172054223,6.5377850712885444,10.732913984907945,6.706572459348437,74.452879312888086,62.139934216588784,60.285033076310221,57.153418712092879,54.013922669819429,10.927975071288262,-56.961386419235012,26.163033148338073,38.917225494224823,35.165639503467965,43.325185789211162,40.528829777777943,45.46047788433274,44.65614961193382,-28.923525404614086,1.2176883107056082,-27.261111860622623,72.022783795852334,60.189096295750467,35.090577411447128,62.626198912814168,18.373970612119557,4.4839396788779897,97.714763403696168,54.928863905578517,60.057600640741299,63.786175094337921,90.844170939239461,16.601571352263935,-46.424900058104022,-50.283469376474009,-50.569001579289292,92.701762469631518,-40.545509865240618,-49.692962903167782,-51.188668622515138,-48.154451848262589,-32.892489776067542,-43.13013750710639,-41.566718571110968,-47.53750266284073,-45.592529244874953,-46.463869895352886,-49.682512802425052,-44.038123779053961,16.947786380989424,-48.092114410335995,-46.878315412615628,63.878997519387752,21.270653852033046,60.066588027062323,62.051441907576823,-33.072174126793328,74.458344285137017,87.93616358503435,85.250229795593611,84.752402221586578,79.789750933159311,92.80915472575397,93.557662436151119,53.877747367717575,56.145403413831787,38.386767377225262,38.428407247596418,70.239436976020187,-30.348669355851133,1.2026924574468891,59.870469267438438,15.222919273850808,61.022241688076527,-47.540158205081291,-46.960885448401903,-46.502758476070369,64.044284716623636,-34.558936651247642,81.286972257033852,80.770427676849636,47.584590909533901,-21.056148697661879,-49.808824038873041,-50.378493012322089,79.195954329427295,79.212534640699886,-34.426879170397015,62.849998851124909,66.16063829171334,-47.487063903749124,-34.148214096689138,-41.652040372671394,78.361459562193502,-92.819158491308912,55.185434546077886,62.756115022210423,56.808083300927002,24.727134273617935,-47.24431430822667,80.258677344463706,66.163189840897161,23.999055791220773,-49.249902574930388,92.249584269864172,-46.670448470741547,44.296583494349818,53.901375381325366,79.615047108241072,60.750173372724795,96.809062183945898,61.101329290058757,61.667554041651975,61.820709999339755,-51.773361967629427,29.936218553712639,65.013759726854403,59.501448480145001,94.496718759035716,58.31611279481421,-90.98282508871165,60.093439120699479,-9.2709515517280856,-20.468283920164833,23.365438659373041,69.902042083434182,60.08325155460826,-21.63793953858162,-66.761581243179378,-42.801774719891064,42.663986894002967,27.716642009334908,19.898570644359108,55.881144101459164,31.556998303246434,93.19676418289211,26.0271031844945,-47.349872947026448,-10.020232024150678,25.675019648302037,58.974038270559355,30.988593319027249,55.90147770542724,22.329898791487182,-34.686415949939061,57.043972013740323,-41.416567349766794,58.573929242660292,91.822348260008468,-8.3392681328339204,64.402773083290455,63.229465509835435,77.282563242629152,77.207381220462864,81.679682170605517,76.185178385432806,65.444342292284958,81.154676929800289,89.287394098624105,63.228282123236546,-8.1846080026610544,-7.0595850125142565,-10.052781696745457,-7.2921455062100744,-7.2376107497775006,-43.433990071810562,70.987396755566579,65.036174995318675,90.460166702639512,24.509363703688727,93.355251772305792,92.312192485382724,93.592493807345122,90.792158060192051,-6.2513642277481685,-46.839181983341582,-52.837160577497009,-7.7847700884214737,-52.90802912988044,-51.541456227495317,-52.218273304440345,-51.284844734634511,-51.482701478105469,-52.410887919386496,-43.055572193072869,10.387411751578178,-39.973915775765931,-40.808337782232918,-39.321901548162145,-39.360216351283015,-19.441861525427292,89.911367338876531,90.937073234969503,51.214575698457494,-5.1462629646592895,-46.449684441227909,56.835507826314235,63.390209877591936,62.902076967110432,60.012074448312184,61.223090788404313,62.148460234139989,64.746584383047221,-31.720838563347634,-47.178338323218419,23.159622324434455,78.919720199799073,29.49335915137571,61.148786471616098,39.772223661677131,38.440601061584445,39.763810215315331,39.448393356102237,38.288507435460524,-8.7972837710464713,40.97987260336857,38.320745671521614,51.01601845275038,50.820579126937282,55.904650618575666,28.916576963103051,28.670563598528211,87.722723667137089,20.956412893459113,75.876067202530677,65.494221065239557,75.525038715046293,18.459364329213489,33.077164946711768,79.364005064979111,28.562667562441291,89.401104436020546,28.478016696671457,-27.659248525795789,-27.615821171115975,92.407541122114822,30.34736986912932,20.806303764208785,-44.677717081834359,-20.951415867704611,57.575819607687471,56.563831759853819,-34.051588662611415,-33.379177838174428,-38.920703521371564,-44.766767375774734,72.288500098936737,86.038426443145539,86.596945227036741,60.875809768959456,61.020253576676026,86.050121933361922,74.423490023773724,-35.244689638675212,40.503205561561408,36.29606944258034,-55.259589317183902,-44.533726546313027,-54.149377754216182,-54.955830394242732,-42.05448329101165,-24.205713101049827,-49.329743289202838,-72.40244523871327,-72.166147208232161,-71.538101159006629,54.105322049595721,9.827208461999474,10.305689171616955,38.267311435998955,42.800352320124297,-66.468082784843631,64.796610818655182,-34.468691948721627,92.509245044074916,26.299887520225937,-46.589997206986581,63.575644074427366,74.969392458306373,66.002708468543901,-30.885986675194847,75.938980242057681,83.647476001294251,85.185989716995252,56.075646237431918,87.244611088840173,59.46006069213955,-9.706898184100746,12.33824887245571,-19.790016709551036,-21.702231298242179,-16.911894167876127,-17.489681344996743,-21.516620995842526,-22.589793877084965,-16.9993280194827,-20.046521273317275,-20.700044746759239,-23.10979656350845,-21.079937631866969,-30.535327993642507,22.491365811282893,26.46427800041522,-9.680627228215732,67.134243304440503,61.733151798427691,62.327681944145759,-51.947307520361413,14.786991489743723,20.108851317283815,22.739237008412417,-43.214963054923651,-43.70354875719503,-52.947807294713279,65.419124398465442,34.995878657702562,61.007065785795852,80.272313580013659,-10.963971711894173,-1.3438786411549495,63.901973486746073,26.884138563510181,92.970247418073541,91.106101618980915,63.668259018126349,25.861718018977662,62.543566999118859,73.774720060945867,61.697453326716371,69.193901432578883,56.193714555082856,64.263495617574023,82.133233390150053,82.251359717198994,84.30655612209155,28.547815918044613,65.207049897987602,-54.031326626182029,94.443511335906024,62.259890117400325,4.7355423266008332,2.3628182909758983,0.81930415676158697,3.9585124570901935,-0.85548508807039569,3.5393177820236574,-2.4462854378503618,-1.7100256613880709,-34.822280090600437,-34.743000793667299,-4.6518605819387489,21.405445248740012,62.539775259303212,-30.517593931090154,3.4606169808295473,-29.091991979043954,38.975914578139133,-48.129705013913537,60.622821059741995,60.430534753715101,60.940147154553053,61.732636720266832,60.720944691893422,60.118186719221384,91.304963677284405,89.311741662770842,82.287048311786023,-51.640411267842161,-47.381643359250624,71.357968295842227,64.324380724731768,-42.035786326133803,-48.922423913700612,-48.361693124121565,-49.192923694325678,-49.708517644462816,-29.432153667876424,-48.632457147289045,-21.232592327105738,-19.727405798313718,27.780775817588946,19.732853076930883,28.567215883881371,46.677288388230174,-49.123772306662573,19.434599463818376,-44.609433891104167,40.870637207074971,63.94317102258168,57.174073308563848,-25.232955651053143,-27.421959762008875,-26.096965451142754,-27.358802213598064,-24.837105425679319,-28.57137390086227,-26.883098334450207,6.6609195552879372,24.195065033555355,24.918418576893608,-32.226853563504477,-31.880928644479923,79.909362128764258,27.207768230090256,-28.876773238105642,43.29848321689677,-9.704587271770226,65.191063227021687,57.375147884165457,85.463557771046681,76.387763788430505,66.380866980442022,86.291225289849748,60.790200544868391,-21.568797214264951,19.058141896498704,-38.073077258726819,-36.568825285457351,-39.582190029055518,-35.850059230128331,-21.252366791570552,25.824475372637369,60.716500810053809,60.09087051027479,39.99942004574249,25.889129188869436,-6.2691600883936882,53.617773776926327,54.626917460060262,55.237104944059389,12.032292783815157,61.834272289205622,95.443271108521571,76.363954026911415,81.831755370656197,87.559103773470483,81.260072856791083,82.746868313639695,90.547339370063781,-20.693147607046978,-20.23378858555159,-19.104264617758812,57.651105305662007,26.850556950860188,24.214284002598504,25.781010054346808,55.923248050512655,53.458208426589671,54.067711010830621,55.848756179296409,35.760454174617557,41.837002120447956,27.907414761895236,-4.0318318140237217,82.174238249575154,77.1189398817708,74.958453158576006,86.970535000857325,84.26358266392225,65.195706559082382,40.092324028015071,57.511121515398017,57.884280187051765,54.63192752521082,89.031401224500357,61.464316980597772,59.851594790580805,88.336495738078753,64.332378851052781,79.943823136087175,53.346447846530474,83.371037213981694,59.498080423591766,56.170453973502525,-33.408770374789171,-33.43089420971382,62.440851843688549,88.827998025240703,82.649726620616718,66.051087466513053,66.96048856652169,-33.344703158354214,-1.7378493089456748,42.436302952525693,97.923701457930946,-6.7792377752814872,82.481490436302053,56.081283210290756,80.698636649209291,96.125068249692504,65.872107523840526,71.739566185379161,60.528334204961283,94.789402757890713,55.855482398983305,65.333404022224542,82.387212424054439,82.656946589385058,68.115282967454675,82.465331712931302,87.629388485073093,85.612646347627916,-0.09186399590023385,82.119328296797065,86.686099962495163,88.789998442467379,87.122441601686731,62.585618848884025,-45.469701924818132,-44.313188602320139,73.51411772172267,80.669392491874405,-22.539406388842039,82.475229018278938,57.767232192269425,77.045458907268895,74.137935184085777,87.521539716579838,76.310505339996652,79.792499353985647,75.915265324895728,42.332355498981222,82.867815703146022,92.551831596387672,63.759589712241542,-0.38531363910262545],"text":["Input: 'acetone retortman' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'agent jute hemp brewery' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'and silk works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'any kind of plain needle work' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'appe sawmiller' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'apprent at millinary' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'apprentice hand loom weaver' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'asistants' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'assistant cotton loomer half' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'assistant in cotton betting mi' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'assistant in dyehouse worsted' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'assistant worsted overlooker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'assistmaker drawing hand' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'backer en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'backergesel en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bagersvend' (lang: da)<br />HISCO: 77610, Description: Baker, General","Input: 'baker' (lang: en)<br />HISCO: 77610, Description: Baker, General","Input: 'baker (dec.)' (lang: en)<br />HISCO: 77610, Description: Baker, General","Input: 'bakker' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bakker en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bakkersgezel en not mentioned in source' (lang: nl)<br />HISCO: 77610, Description: Baker, General","Input: 'bander ring room cotton' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'bank tender cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'banketbakker' (lang: nl)<br />HISCO: 77630, Description: Pastry Maker","Input: 'banksman' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'barn poul mikkelsen vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'beadworker trim' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'beef butcher apprentice' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'berlin wool fancy repository' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'bessemer steel rail worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'bit winder carpet works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'blanket fuller out of employ' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'blast engine cleaner' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'blauverwer' (lang: nl)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'bleached cotton cloth beatler' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'bleacher' (lang: en)<br />HISCO: 75615, Description: Textile Bleacher","Input: 'bleacher at cotton works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'bleachers brusher' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'boblin winder cotton spinning' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'boiler scaler labourer' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'boner at stay factory' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'bookkeeper to fancy goods deal' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'borduurwerker en not mentioned in source' (lang: nl)<br />HISCO: 79565, Description: Embroiderer, Hand or Machine","Input: 'borduyrwercker en not mentioned in source' (lang: nl)<br />HISCO: 79565, Description: Embroiderer, Hand or Machine","Input: 'bow manufacturer' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'braid maker trim' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'branston frame worker hosiery' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'brass dealer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'brass founders core maker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'brassfounder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'brendevinsbrender' (lang: da)<br />HISCO: 74490, Description: Other Still and Reactor Operators","Input: 'brewer' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'brewers servant' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'brouwersgesel en not mentioned in source' (lang: nl)<br />HISCO: 77810, Description: Brewer, General","Input: 'brygger karle tienneste folk' (lang: da)<br />HISCO: 77810, Description: Brewer, General","Input: 'buffer steel work' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'burler in woollen cloth mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'butcher' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'butcher' (lang: unk)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher (deceased)' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher and etc' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher decd' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher deceased' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butcher employn 2 men' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butchers salesmens assistant' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butchers scaleman' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'butler' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'butlery' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'cab weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cabinet manufr upholsterer' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'caffawercker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'caffawerckergesel' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'caffawerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'calenderer tape work' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'can tenter in card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'candle dipper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'capainder of cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'card hand hos' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'card master' (lang: en)<br />HISCO: 75135, Description: Fibre Carder","Input: 'card room hand speed tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'card room op' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'carder' (lang: en)<br />HISCO: 75135, Description: Fibre Carder","Input: 'cardroom hand cotton mill slub' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'carman at bedstead factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carpet designer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carpet weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'carpet weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'carpet weaver hand loom' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'carringe trimmer' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'casquetier' (lang: fr)<br />HISCO: 79390, Description: Other Milliners and Hat Makers","Input: 'caster' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'catcher in tin wks tpw' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'cleaner bleach works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'clipper scalpper lace' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cloth cap cutter woollen' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth corrier' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth doffer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth knotder and picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth mill over looker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth pleater bleachworks' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cloth printers worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cloth weaver woollen mil' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'coal bag fitter' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'coal leader' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coal miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coal miner cutting machinist w' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'coal pit sinker shaft' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'coal trimmer' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'coalminer' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'cocoa mat maker unemployd fib' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'coil winder electric motors' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'coker in steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'collar damper' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'collar dryer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'collar maker' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'collier' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'colliery coal salesman' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'colored cotton woollen winde' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'conditioner in worsted mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'confictioner packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'cop winder cotton driller' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'corset assistant' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'corsett fact' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'cotron piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton bleacher' (lang: en)<br />HISCO: 75615, Description: Textile Bleacher","Input: 'cotton blowing room over worke' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton card mone labourer' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton cartrim sweeper cart r' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton cloth agents clerk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cotton fram tenter cardroom' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton grinder in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton hank maker ap' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'cotton hanker grosser' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton heald picker' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton jinny room piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton loop pointer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton miles' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton mill minder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton mill operative reeler' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton mill roving frame cardr' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton mill stripper and grind' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton operatie doffer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton operative psinner minde' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'cotton part time' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton peaces' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton piece folder twister' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton resler' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton ring thewstle spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton rov' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton scholar weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton self acter winder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinner operantice' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinner unempld' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton spinning stripper and g' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton spred tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'cotton steamer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton thread factory worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'cotton tigger' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton trade doubler' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton twister also barber' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton waever' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton warp packer manuf' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton warper mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton warper pensioner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'cotton waste sorter machine me' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'cotton weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton weaver and student' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton weaver painter c jou' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'cotton winder spinner mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'council hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'crane man steel smelting works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'currier' (lang: en)<br />HISCO: 76150, Description: Leather Currier","Input: 'cutter in clothing mang' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'daughter of constable' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'deam warper cotton mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'deres datter skraedderpige' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'deres son vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'distelateur en not mentioned in source' (lang: nl)<br />HISCO: 74400, Description: Still or Reactor Operator, Specialisation Unknown","Input: 'dito mollesvend' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'doffer cotton m' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'doffer in ring' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'doffer silk' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'domestique de meunier' (lang: fr)<br />HISCO: 77120, Description: Grain Miller","Input: 'doubling overlooker in cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'draw frame silk manufactory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'drawer jute milne' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'dres worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'dresser at factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'dresser bag stitcher' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'driller' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'droochscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'drooghscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'droogscheerder en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'droogscheerdersgezel en not mentioned in source' (lang: nl)<br />HISCO: 75490, Description: Other Weavers and Related Workers","Input: 'dyehouse labour' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyer' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'dyer finister' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyer [deceased]' (lang: en)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'dyer skeiner silk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'dyers laboorer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'embosser cloth finish' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'employe at small arms factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'employed in biscuit factory' (lang: en)<br />HISCO: 77690, Description: Other Bakers, Pastry Cooks and Confectionery Makers","Input: 'employed in tin wks' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'employer hosiery' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'ender velvet trade' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'ernaerer sig af haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'ernaerer sig ved strompebinden indsidder' (lang: da)<br />HISCO: 75535, Description: Hosiery Knitter (Hand)","Input: 'escardasedor' (lang: ca)<br />HISCO: 75135, Description: Fibre Carder","Input: 'ex miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'factory operative cotton weav' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'factory operative w c m' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'factory worker hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'fancy worker in ivory' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'fancy bead work' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'fancy work drapery' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'farmer and dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'feeller in felt factory' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'feldbrender svend tienestefolk' (lang: da)<br />HISCO: 76200, Description: Pelt Dresser, Specialisation Unknown","Input: 'fell monger wool works' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'felpwercker en not mentioned in source' (lang: nl)<br />HISCO: 79490, Description: Other Patternmakers and Cutters","Input: 'felt maker' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'fettler arty' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'fileuse' (lang: unk)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'finished skirts' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'finisher and seal silk' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'finisher of bleachd0 cotton go' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'finsommerska' (lang: se)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'fire range iron molder' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'fireman iron blast furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'fireman steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'flannelette weaver' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flax comber' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'flax dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flax reeling tenter' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'flessader' (lang: ca)<br />HISCO: 79690, Description: Other Upholsterers and Related Workers","Input: 'flex preparer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'fly worker cotton factory' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'foreman cotton warp dresser' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'foreman cotton factory' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'foreman packer f lab' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'forge apprent iron' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'former occupation spinner cott' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'formerley furnace man' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'formerlly cotton spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'formerly cotton mill worker' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'formerly horse clipper maker' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'formerly jute twister' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'formerly lace maker' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'formerly straw mat maker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'formerly tin plate roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'formerly tow spinner' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'frame winder w' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'frame work' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'frame work kinneter' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'framework knitter' (lang: en)<br />HISCO: 75540, Description: Knitter (HandOperated Machine)","Input: 'fretwork carring cabt' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'fuller and dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'fulpwerker en not mentioned in source' (lang: nl)<br />HISCO: 79490, Description: Other Patternmakers and Cutters","Input: 'furnace fitter iron' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace limer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace mam on rolling mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'furnace man silver works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'furnace stoker sugar boiler' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'furnaceman drawes out' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'furnaceman silver ore smelter' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'galvanized cold rollers helper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'galvanized sheet dipper' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'gelbgjutaregesaell' (lang: se)<br />HISCO: 72520, Description: Bench Moulder (Metal)","Input: 'general iron planer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'gentlemans tie manufacturer h' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'gentlemens hosiery asst' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'gingham weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'gjuteriarbetare' (lang: se)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'glover' (lang: en)<br />HISCO: 79475, Description: Glove Cutter, Leather or Other Material","Input: 'goods bleach dyer works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'greinwerker' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'gum works' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'half time millworker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'half turner cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hand hosiery worker' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'handskemagersvend logerende' (lang: da)<br />HISCO: 79475, Description: Glove Cutter, Leather or Other Material","Input: 'hattemager' (lang: da)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hatter' (lang: en)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hattmakaregesaell' (lang: se)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'hawkes tinware' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'heald rutter' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'heand loom weane silk' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hearthrug maker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'hendes son vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'hoedenmaker en not mentioned in source' (lang: nl)<br />HISCO: 79310, Description: Hat Maker, General","Input: 'holzaufsetzer' (lang: de)<br />HISCO: 73100, Description: Wood Treater, Specialisation Unknown","Input: 'horsekeeper cotton cloth bleac' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'hose' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hoseiry hand griswold' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'hosiery boot assistant' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery factory' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery machnist' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'hosiery manufacturers foreman' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'huseier sypige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'husfader skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'husmoder syerske' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'in tobaco fact' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'indarubber hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'inderste og naerer sig af fabriq spind mand' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'india dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'indsidder skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'indsidderske ernaerer sig ved haandarbeide' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'indsider og vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'intermdiate tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'intermediate tenter cotton' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'iorn spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'iron dresser' (lang: en)<br />HISCO: 72930, Description: Casting Finisher","Input: 'iron firer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron flyer makery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron founder' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'iron moulder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'iron planer m v' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron plate worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron rivetter in shipyard' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron tin plats worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron turner fuel economiser wo' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'iron worker labourer blast fur' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron worker lifting up' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker wheel cutler' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'iron worker, deceased' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'iron wroker shingler' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'iron-dresser' (lang: en)<br />HISCO: 72930, Description: Casting Finisher","Input: 'ironworker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'ironworks boxfitter' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'jack frame tenter in card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'jacket button hole machinist' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'jobbing about cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'joiner oil work' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'journeyman tin plate worker' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'jute factory bagmaker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute mill worker preparing' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute spinner emp 350 f work pe' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute spinners' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'jute wareho labourer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kaffawerker' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kaffawerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'kibond weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'klaedesvaevare' (lang: se)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'kleermaker' (lang: nl)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'kleermaker en not mentioned in source' (lang: nl)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'knitter spinner' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'konfekturearbejder' (lang: da)<br />HISCO: 77630, Description: Pastry Maker","Input: 'korkskaerare' (lang: se)<br />HISCO: 73290, Description: Other Sawyer, Plywood Makers and Related WoodProcessing Workers","Input: 'kousenverver en not mentioned in source' (lang: nl)<br />HISCO: 75690, Description: Other Bleachers, Dyers and Textile Product Finishers","Input: 'kvarnaegare' (lang: se)<br />HISCO: 77120, Description: Grain Miller","Input: 'laackenbereyder en not mentioned in source' (lang: nl)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'lab in iron w' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lab iron compy' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'laborer at steel boat works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'laborer in mill' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'laborer tin plate works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'labourer at fishcuring' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at motors garage' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at sanitary pipe pott' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer at wordyard' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer brass foundress' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer brass works' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer factory jute' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer fibre works cocoa' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labourer for butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'labourer in blacking mill' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'labourer in cotton mill unempl' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'labourer in steel rolling mi' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'labourer in tinworks' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'labourer iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'labourer marine eng factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'labouring miler' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'lace curtain maker grist hand' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'lace hand' (lang: en)<br />HISCO: 75450, Description: Lace Weaver (Machine)","Input: 'lace jennier unemployed' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'lacher' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'late fire iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'late mill overseer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'late woollen manufacturer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'laundress at coller factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'lead furnace man' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lead miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'lead packer' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'leertouwer en not mentioned in source' (lang: nl)<br />HISCO: 76150, Description: Leather Currier","Input: 'legatuerwercker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'letterpress printing machinery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'lever af at spinde' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'lever af haandarbejde' (lang: da)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'lijndraaier en not mentioned in source' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lijndraijer en not mentioned in source' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lijndrayergesel' (lang: nl)<br />HISCO: 75720, Description: Wheel Turner, Rope Making","Input: 'lime hoist blast furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'linen machine ironer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'linen on cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'linnenwever' (lang: nl)<br />HISCO: 75432, Description: Cotton Weaver (Hand or Machine)","Input: 'linnewercker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'londery made sorter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'mab ffambwr gweirthin ai ffamr' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'machine wool combing overlooke' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'machinist and maker' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'machinist saw mill' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'machinist sewing mill' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'maker up' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'maker up of linen' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'maltster' (lang: en)<br />HISCO: 77810, Description: Brewer, General","Input: 'maltster grocer employing 1' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'managing director of iron wi' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'manchonnier' (lang: unk)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'mangler dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'mantle manufactering' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'manufacturer importer of fan' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'manufucturer of linen collars' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'master cotton spinner manf' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'master dyer dress goods' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'master iron monger employs 1 b' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mathematical instrument worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mattrss maker' (lang: en)<br />HISCO: 79640, Description: Mattress Maker","Input: 'mechanic cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'mechanist linen collar works' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'medical wool packing' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'meedlewoman' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'meierske' (lang: da)<br />HISCO: 77510, Description: Dairy Product Processor, General","Input: 'merino wool hosiery ironer' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'metal chaser and embosser bras' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mgr cotton weaving' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'mil hand worsted spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'milinerdress' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'mill back tenter' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'mill hand cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'mill hand s f' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill hand wool mn' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill handwoollen mill piecener' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill loomer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill worker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mill worslet mender' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mille piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'millhand cotton card room work' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'millinar' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner' (lang: unk)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner head of workroom' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliner retired' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'milliners manager' (lang: en)<br />HISCO: 79320, Description: Milliner, General","Input: 'millman steel works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'millworker cloth' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'mils worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'minding spinner' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'mine contractor' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'miner' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner (dec)' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner (deceased)' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'miner deceased' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'modiste' (lang: unk)<br />HISCO: 79320, Description: Milliner, General","Input: 'modler iron' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'moeller' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'moldier' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'molenaar en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'molenaarsgezel en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollerkarl' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollersvend' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'mollersvend tienestefolk' (lang: da)<br />HISCO: 77120, Description: Grain Miller","Input: 'moolenaar en not mentioned in source' (lang: nl)<br />HISCO: 77120, Description: Grain Miller","Input: 'mosaic pavement mural worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'mould dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'moulder' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder' (lang: unk)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder (deceased)' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'moulder appentice' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'mounter umbrella and walking s' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'mule piecer spinning cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'mule spinner cotton out of emp' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'musline darner' (lang: en)<br />HISCO: 79690, Description: Other Upholsterers and Related Workers","Input: 'nitroglycerine exploder' (lang: en)<br />HISCO: 71190, Description: Other Miners and Quarrymen","Input: 'oat worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'office boy cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'oil color mcht' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil mill labr' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil screens' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil seed cake maker' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'oil seed crushers' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'operator in cotton mill' (lang: unk)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'oud leerlooier' (lang: nl)<br />HISCO: 76145, Description: Tanner","Input: 'out dor worker 1 agricult' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'outfitters cutter by bandknif' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'overlooker assist silk' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'overlooker in trousers factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'overlooker wool washing' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'packer confer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer crystalate maf co' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer in fender and lee' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer in mill c' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer instruments' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer late greenwich marine 1' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer of bags flour' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'packer wharehouse' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'paper maker' (lang: en)<br />HISCO: 73400, Description: Paper Maker, Specialisation Unknown","Input: 'parchment maker' (lang: en)<br />HISCO: 73400, Description: Paper Maker, Specialisation Unknown","Input: 'part school calico weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'passementwerker en not mentioned in source' (lang: nl)<br />HISCO: 75452, Description: NA","Input: 'passementwerkersgezel en not mentioned in source' (lang: nl)<br />HISCO: 75452, Description: NA","Input: 'patent cotton winder' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'patern dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'pattern warp dresser' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'pauper formerly silk weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'pauper hemp dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'peller' (lang: ca)<br />HISCO: 79220, Description: Fur Tailor","Input: 'perfumer manager' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'piece cloth mending' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'piece lookers cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'piecer cotton spinning co' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'pinafore factory worker' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'pit bailiff coal' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'pit sticker' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'pitman' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'plaiter down cotton' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'plate maker cotton' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'plate roller iron worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'plater' (lang: en)<br />HISCO: 72890, Description: Other Metal Platers and Coaters","Input: 'plush weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'poncho weaver w' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'pork butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'pork butcher killing' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'porter in tin works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'potting worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'power loom factory worker fill' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'power loom reeler of cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'power loom timer worsted mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'power loom weaver dyer' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'power loom weaver mindr' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'powerloom stuff weaver' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'printer carpet works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'printer in tin works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'printer on chocolate sugar hou' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'printers litho packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'puddler' (lang: en)<br />HISCO: 72190, Description: Other Metal Smelting, Converting and Refining Furnaceman","Input: 'puddler a furnace' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'puddler overseer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'pudler' (lang: en)<br />HISCO: 72190, Description: Other Metal Smelting, Converting and Refining Furnaceman","Input: 'pudler at iron furnaces' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'pump maker well sinker' (lang: en)<br />HISCO: 71300, Description: WellDrillers, Borers and Related Workers","Input: 'purrier boat worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'quarry man' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'quarryman' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'quarryman deceased' (lang: en)<br />HISCO: 71110, Description: Quarryman, General","Input: 'raswerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'rebslager logerende' (lang: da)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'reebslager' (lang: da)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'regimental packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'retired fram work knitter' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'retired malster brewer' (lang: en)<br />HISCO: 77830, Description: Malt Cooker","Input: 'retired overcooker cotton spin' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'retired plate roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'retired winder bobbin cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'ribtop hand' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'roller' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'roomg frame tenter cotton mill' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'rope hemp dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'rope maker' (lang: en)<br />HISCO: 75710, Description: Rope Maker, General","Input: 'rostvaendare' (lang: se)<br />HISCO: 72120, Description: Blast Furnaceman (Ore Smelting)","Input: 'rover' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'rover silk' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'roving doubler' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'runs carding machine' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 's cotton peicer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'saaiwerker en not mentioned in source' (lang: nl)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'sail maker assistant' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'sastre' (lang: ca)<br />HISCO: 79120, Description: Tailor, MadetoMeasure Garments","Input: 'sauyer in mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'sawer printworks' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer' (lang: en)<br />HISCO: 73210, Description: Sawyer, General","Input: 'sawyer' (lang: unk)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer cowkeeper' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer wood cutter' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer (deceased)' (lang: en)<br />HISCO: 73210, Description: Sawyer, General","Input: 'sawyer at colliery' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer hand saw' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer iron band saw' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'sawyer pulp works' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'school butcher lad' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'seamster' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'segor maker' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'seijlemaeker en not mentioned in source' (lang: nl)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'self act minder in cotton mill' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'self active cotton weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'self actor minder' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'serraller fonedor' (lang: ca)<br />HISCO: 72320, Description: Furnaceman, MetalMelting, except Cupola","Input: 'sewer plain on dress maker' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sewing knitting' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sewing machinist trusses' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'shearman iron works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'sheet iron roller' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shell fitter in steel works' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shepper grinder in cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'shiort hand tipewriter' (lang: en)<br />HISCO: 74990, Description: Other Chemical Processors and Related Workers","Input: 'shiper in cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'shoddy picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'shop assistant gents hats and' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'shoperkr' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'shopkeeper oil color general' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'sigar mkr' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'sijdekousemaeker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'sijgrofgrijnwerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'sijreder en not mentioned in source' (lang: nl)<br />HISCO: 75190, Description: Other Fibre Preparers","Input: 'sijverwergesel en not mentioned in source' (lang: nl)<br />HISCO: 75622, Description: Yarn, Fabric or Garment Dyer","Input: 'silk cotton hd loom weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk ballers helper' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk cheese winder' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk furniture weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silk merces' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk rover spinning operative' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk sc' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk sorter smallware' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'silk tie mender factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'silk weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'silver plater emp 30 hands' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'sinker' (lang: en)<br />HISCO: 71105, Description: Miner, General","Input: 'skinner and corn factor' (lang: en)<br />HISCO: 76130, Description: Hide Flesher and Dehairer (Hand)","Input: 'skraeddare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeddarelaerling' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedderforretning' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedderiarbetare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeddermester' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraeder' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraederdreng tjenere' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'skraedersvend' (lang: da)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'slagter svend mandens broder' (lang: da)<br />HISCO: 77310, Description: Butcher, General","Input: 'slagterdreng gaardskarl husfader' (lang: da)<br />HISCO: 77310, Description: Butcher, General","Input: 'slany hterman' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'sleevemaker' (lang: en)<br />HISCO: 79590, Description: Other Sewers and Embroiderers","Input: 'sluber on cotton mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'smelter' (lang: da)<br />HISCO: 72120, Description: Blast Furnaceman (Ore Smelting)","Input: 'sockenskraeddare' (lang: se)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'soemmerska' (lang: se)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'softgoods packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'spar worker others 213' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'spindehaandtering hos faderen' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spindekone' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spindepige' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinderske' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinderske dennes datter' (lang: da)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinner' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'spinner cotton side piecer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'spinning worsted doffer' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'spool winder at smallware mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'spring fitters viceman in stee' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'spring roller at steel works' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'steam engine tenter at a worst' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'steam loom weaver of silk' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'steel armour plate dresser' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel sheet works labourer' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker finishing dept' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steel worker tongsman' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'steenhukker' (lang: da)<br />HISCO: 71220, Description: Stone Splitter","Input: 'stell worker' (lang: en)<br />HISCO: 72100, Description: Metal Smelting, Converting or Refining Furnacemen, Specialisation Unknown","Input: 'stick umbrella maker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'stick worker paperer sand' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'sticker w cloth' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'sticktelijffmaecker' (lang: nl)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'stitcher on a cotton bleach wo' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'stockinger' (lang: en)<br />HISCO: 75540, Description: Knitter (HandOperated Machine)","Input: 'stole smelter' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'streets on stay busk' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'stud worker jewellers' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'sugar dealers forman' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'superintendant oil mills' (lang: en)<br />HISCO: 74500, Description: PetroleumRefining Worker, Specialisation Unknown","Input: 'superintendent in fancy goods' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'syening' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syepige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syer for folk og har 20rd aarl af post cassen madmoder' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syerske' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'syerske barn' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'sypige' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'sypige hos moderen' (lang: da)<br />HISCO: 79510, Description: Hand and Machine Sewer, General","Input: 'tailor' (lang: en)<br />HISCO: 79100, Description: Tailor, Specialisation Unknown","Input: 'tailore' (lang: en)<br />HISCO: 79190, Description: Other Tailors and Dressmakers","Input: 'tailoress presser at clothing' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'tanner' (lang: en)<br />HISCO: 76145, Description: Tanner","Input: 'tanner ( dec )' (lang: en)<br />HISCO: 76145, Description: Tanner","Input: 'tape led warper at factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'tapetseringsarbetare' (lang: se)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'tartbagare och alderman' (lang: se)<br />HISCO: 77630, Description: Pastry Maker","Input: 'tea packer labeller' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'tent decorator' (lang: en)<br />HISCO: 79920, Description: Sail, Tent and Awning Maker","Input: 'tenter in a cotton card room' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'tenting weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'thread mill worker parcel dept' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'throalt warper' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'throsle rover' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'throsstle dofer cotton' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'throstle cotton spinner and proprietor houses' (lang: en)<br />HISCO: 75220, Description: Spinner, Thread and Yarn","Input: 'timber sawyer unemployed' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'tin dresser' (lang: en)<br />HISCO: 71290, Description: Other Mineral and Stone Treaters","Input: 'tin plate worker employing 1 m' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tin plate worker g e r' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tin worker spiner' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tinplate cold roller' (lang: en)<br />HISCO: 72200, Description: Metal RollingMill Worker, Specialisation Unknown","Input: 'tipper umbrella trade' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'tky red yarn dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'tobacco assorter' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'tobacco operator welling down' (lang: en)<br />HISCO: 78100, Description: Tobacco Preparer, Specialisation Unknown","Input: 'toilet packer' (lang: en)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'townsman to a dyer' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'traveller for specialities for' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'treckwerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trekwercker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trekwerker en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'trimmer carriage' (lang: en)<br />HISCO: 79630, Description: Vehicle Upholsterer","Input: 'trimmer upholsterers' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'tripe dresser' (lang: en)<br />HISCO: 77390, Description: Other Butchers and Meat Preparers","Input: 'turner in iron at drill factor' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'twister' (lang: en)<br />HISCO: 75240, Description: Twister","Input: 'twister for cotton weavers ma' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'twister in' (lang: en)<br />HISCO: 75240, Description: Twister","Input: 'twister in a factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'twister in worsted and cotton' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'umbrella maker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'umbrella maker cane worker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'umbrella maker hawker' (lang: en)<br />HISCO: 79930, Description: Umbrella Maker","Input: 'under cotton' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'upholsterer' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'upholsterer furniture booker' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'upholstress apprenctice' (lang: en)<br />HISCO: 79620, Description: Furniture Upholsterer","Input: 'vaever' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaever hans sons kone' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaever svaend' (lang: no)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'vaeverske' (lang: da)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'valcanise worker' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'velvet piece stitcher' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'w i cigarshop' (lang: en)<br />HISCO: 78200, Description: Cigar Maker, Specialisation Unknown","Input: 'wangler' (lang: en)<br />HISCO: 75600, Description: Bleachers, Dyers and Textile Product Finishers","Input: 'warp dresser cott worsted m' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'warper (deceased)' (lang: en)<br />HISCO: 75415, Description: Beam Warper","Input: 'warper with weavers' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'warping piecer woollen' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'warsted mill hang' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'waste picker cotton waste ware' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'watchman sugar house' (lang: en)<br />HISCO: 77200, Description: Sugar Processor or Refiner, Specialisation Unknown","Input: 'weaver' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver' (lang: unk)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver stitcher out of empl' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver at woollen cloth mill' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weaver cotton calica' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver cotton unempl' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weaver in a worsted factory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weaver in power loom wool' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'weavers cloth picker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'weaverstzer on tweed' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'weigh clerk silk mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'weigher flax mill packring roo' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wever en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'whife of butcher' (lang: en)<br />HISCO: 77310, Description: Butcher, General","Input: 'wholesale butcher' (lang: en)<br />HISCO: 72500, Description: Metal Moulder or Coremaker, Specialisation Unknown","Input: 'willier in coth mill' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'winder in wool factory' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'winder of jute yarn' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'winding silk manufacture' (lang: en)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'winter cop' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'wire drawer' (lang: en)<br />HISCO: 72725, Description: Wire Drawer (Hand or Machine)","Input: 'wkhome spining' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'wks hosiery fact' (lang: en)<br />HISCO: 75500, Description: Knitter, Specialisation Unknown","Input: 'wolkammer en not mentioned in source' (lang: nl)<br />HISCO: 75145, Description: Fibre Comber","Input: 'wollen mercht capt 60 lanark' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wollen twister' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'wolwever en not mentioned in source' (lang: nl)<br />HISCO: 75400, Description: Weaver, Specialisation Unknown","Input: 'wool cloth mending' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool comber' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool cotton drawer' (lang: en)<br />HISCO: 75990, Description: Other Spinners, Weavers, Knitters, Dyers and Related Workers","Input: 'wool shawl dresser' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool slivering' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool sorter' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wool trade wool cotterror clas' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool warehoseman' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'wool worker f gds tex' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woolen cloth worker unemploye' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woolen peicener at a' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woolen warper wln' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen cloth gig mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen cloth marker' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen manufacturer farmer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen peicer in factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'woollen warper app' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen weaver unemployed woo' (lang: en)<br />HISCO: 75200, Description: Spinners and Winders","Input: 'woollen woollen mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worker dresser in cotton stott' (lang: en)<br />HISCO: 79990, Description: Other Tailors, Dressmakers, Sewers, Upholsterers and Related Workers","Input: 'worker in ironstone pit' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'worker in stick manufactery' (lang: en)<br />HISCO: 72000, Description: Metal Processor, Specialisation Unknown","Input: 'working bone mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'works in woll mills' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'works is sawmill' (lang: en)<br />HISCO: 73200, Description: Sawyer, Plywood Maker or Related WoodProcessing Worker, Specialisation Unknown","Input: 'works on silk mill' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worseted twster' (lang: en)<br />HISCO: 75100, Description: Fibre Preparer, Specialisation Unknown","Input: 'worsted factory operative' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted machinist' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted mill operator' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worsted preparer' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'worstud works' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'wrks in web factory' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'xocolater' (lang: ca)<br />HISCO: 77650, Description: Chocolate Maker","Input: 'yarn weaver i e linen' (lang: en)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'zijdenlakenwerker en not mentioned in source' (lang: nl)<br />HISCO: 75000, Description: Spinners, Weavers, Knitters, Dyers and Related Workers, Specialisation Unknown","Input: 'zijdereeder en not mentioned in source' (lang: nl)<br />HISCO: 75190, Description: Other Fibre Preparers","Input: 'çarrador' (lang: ca)<br />HISCO: 73210, Description: Sawyer, General"],"mode":"markers","marker":{"color":"rgba(241,204,114,1)","opacity":0.69999999999999996,"line":{"color":"rgba(241,204,114,1)"}},"type":"scatter3d","name":"7","textfont":{"color":"rgba(241,204,114,1)"},"error_y":{"color":"rgba(241,204,114,1)"},"error_x":{"color":"rgba(241,204,114,1)"},"line":{"color":"rgba(241,204,114,1)"},"frame":null},{"x":[-60.483376066601551,-123.09470386934768,-73.207933507935849,-74.162191661477749,-34.876862539451778,-53.025664478617003,-64.480629902740958,-78.755543461820011,-61.882934426941901,-42.255841119480507,-28.516737741414509,-73.859396740708277,-26.90317803212869,-58.699241116919232,-25.864457965378509,-25.395129604001966,-84.078998428803388,-82.159670009364831,-71.53749091697037,-124.67232075547717,-125.41461924807567,-123.81755168846007,-123.81769394099868,-124.65910296844609,-121.7067097615339,-123.75766428220446,-120.0654247100485,-68.229594312175308,8.6850274936686453,-1.8684687585044608,-3.3653930550955504,-4.6489226702637776,-5.8910803573774917,-4.2207056356471142,-119.15187124502432,-119.94285186073847,-117.36103094028046,-119.99092232871737,-118.86399985024421,-118.16746045973262,-119.3019877996859,-21.51000054317003,-59.367463475712363,-21.700702325855527,-21.562406170806408,-122.08404204026509,-72.748427161728117,17.267612856274805,-63.123600347896925,-43.393617653600508,-44.434377048418703,-40.899394319837263,-41.170722887651543,-40.5328630940705,-44.459196473405648,-48.404830117778559,-42.421413021310151,-42.246277045185238,-70.238414421761902,-62.576516440194176,-59.361220560033267,-153.57869870750088,-27.810160545784839,-28.631669092270602,-49.131504095850339,-48.436354191511036,-43.550023810359008,-58.867842586482162,-67.417796047233736,-60.081074485793657,-56.054898373358064,-59.80367978951022,-4.5374485718226785,-55.33175662760862,-7.1292484675663772,-14.731724707813504,-14.441466773568488,-71.262505588020858,-60.256952901523206,-2.0514046926527785,-1.8194714461604564,-80.495125743200589,-81.087550008817075,-83.136180635726134,-81.532793937466664,-82.722060352075914,-0.37418975700121521,-2.7309878578147138,-64.974254948611915,-58.466116822060734,9.9031811802259995,22.947741095260234,15.358942651751004,-55.613685420605947,-62.260500888569901,26.788187965296711,55.367747400484731,-119.08908488985551,32.652242765105065,-77.407730915421823,-77.562869129408995,-122.86112405400468,-125.34375200490945,3.1584754411227807,-27.604120766306611,6.6225967543856248,3.7250538214139444,-76.473358431981495,-34.857558233736313,-61.227813994750733,-69.583159922762803,-24.288375264142847,-63.173933556779545,-52.33546473611775,-115.94050138934192,-67.168955352718172,-49.743738341682516,4.2518862722192772,2.4017653952401052,-66.958889392953481,-57.877944513087023,-79.356665947678749,-23.835134571383989,-40.705706929675259,-56.224350672123286,-64.828215088993616,-113.7338086673644,-9.8189913737126879,-8.3075222380037914,-8.5539701445740715,-57.469635538856132,7.7006081562332209,-13.678371373825126,-57.289626943123857,-58.753055186899687,-58.49371399302877,-112.91719106813885,-32.597345614295662,-35.877600210254506,72.095895471813989,-37.254394094013648,8.8999636959741935,-118.92779900727615,-57.108851260592203,10.588731316342308,-25.122028761826979,-24.567546724470535,-120.7281904275217,-63.822538697833728,-43.659293570677811,-28.170795739443282,8.8542578869253354,-26.324845443164691,-39.106860205670806,-6.6789749895992294,-6.5432408838279867,38.101920783905044,-108.37860534704046,-36.780492544785766,-60.808336517713776,-76.709785929217361,-75.24692446452147,-29.735016645984413,-58.327612257971921,-106.0162293380409,-131.04081545543966,-37.540516238035323,-45.98375094490342,-67.833265131025726,-68.283104908272463,-37.386219945158615,66.142311908381231,11.435851240947784,-65.025976733903093,-25.580194301256245,-23.78997956259763,-61.431715807994259,-67.799855693892368,19.336007353752077,-81.33461769934587,-2.6903150651882699,-42.762716299703229,-82.973437052691779,-62.074324734036914,-69.131143731946068,-60.317411944784148,-72.308339126202355,-60.467524253249785,-69.263221631881208,-62.806948606650835,-60.348636345903898,-59.290544395316793,-28.543490672990522,-120.42802044285145,-25.27901706194875,-22.574519414780731,-23.415934577977627,-37.552977969520278,13.140407881911523,-77.823971695967813,-77.204710140930743,-60.032956899483899,22.303982562542497,-75.092747419765644,-23.272741786596534,-23.754292618986369,-23.527321000363067,-83.839095497240578,-77.055495209130243,-32.760018748960434,-58.52926798727102,-61.034809751993819,-71.432178374672588,-42.401235256683606,-73.778095240049495,-76.557765045130324,-31.188994668190912,-78.242640014394624,-120.60023175196831,-75.025601987275962,-46.995914551133495,-113.34402057454028,-63.399590013442079,-37.72407776107611,-40.230114992672696,-38.884182499263424,-39.047905611945147,-65.399284606691651,-37.895168185468563,-27.329451641048706,-74.747308661906445,-67.035378172770976,-59.379699224884696,-61.06686113192977,-66.797021410333087,-73.83508332580351,-67.318788337405408,-76.990782978534355,-23.825681160339585,-61.946984586362852,-60.539402557156194,-39.621796987711932,-59.632816581407063,15.483924052822157,-112.03570610394893,-67.131927695119487,-122.7618506314427,12.714887214959079,-53.866185979694734,-118.32372228726089,-119.48578465943449,-26.535732367896799,-27.186603292800946,-28.129229263524635,-28.193436013037058,-60.777368082481701,-29.35201984648133,-26.394676510877488,-33.814072183537313,-32.817552898586548,-35.442748040167906,-35.429673394771825,-63.768318209411966,-96.74789781866096,-61.066860758696116,-68.271376980082621,-56.913265919196441,-39.573530608391479,41.237246821033558,-71.822471714563633,-0.99931607451855331,-118.69348705490431,-41.094570261376575,-44.910341534962313,-72.711961609431512,-56.417170958186873,48.355140844163174,-112.02359900940392,-59.203948112949625,-69.746155334334588,-39.909722330587414,-39.922965625933415,-61.031466151751452,-63.149521060092049,-63.183006734953047,-43.081761931549252,-42.859591015987192,-71.976565875958798,-44.738583426961561,-39.009775364027917,-40.299462559833231,-39.510947662623295,-44.281350556400746,-72.5352187414193,-57.381739899740083,-60.917796003680323,-93.895331956102297,-2.9328682944640865,0.14551959187249103,-1.1653456220495526,-0.18268793660026666,-75.584535106068444,-29.544766298307966,-31.101533158703948,-42.681063962719371,-116.9417281363401,-63.113018702787215,-61.64551124114336,-67.053146721193229,-4.2277169057838293,-3.619666810993901,-3.9799853515278021,-3.2665018153062357,-3.4922545823389988,-3.9462722976013653,-2.1927656292301942,-119.91887659317895,9.2803035531630353,21.475544438656129,23.538005285381242,21.63970498351285,23.793032103996786,25.146766568497167,25.589772214566139,16.668185319449165,17.293891980873997,17.189135620240904,18.163120006350027,15.799992345504597,32.464053480086363,-24.630635047234552,-25.637093475051408,-24.836853723943779,-24.481971732265585,-21.834191993481195,-21.965765793774871,-23.087081244135021,-23.0559018890246,-25.105646102408969,-25.089251346509421,-80.306571789972068,33.127360402708831,33.455112841038904,32.703977294493704,-43.468419621257411,-41.202667996950638,-120.02196166995419,-70.403753416278889,-36.436409709977049,-37.746001158532984,-64.692759776362152,-67.807510629292977,-67.476647364019954,-63.674633839991635,-78.009553054867581,20.659053707868814,48.402101562252277,47.61027897666969,-113.47616589077001,-23.033887194096568,-57.341679008444402,-55.94593760081176,-71.84660112723995,-74.233813338237269,-118.08122119053418,-95.434028269116084,-92.517827942121869,-94.485906740523205,-28.170150349049489,-126.20672997622603,-130.52829380866879,-120.7242563995333,-130.67394087333918,-131.65444352698739,-131.50263638850535,-65.918470192601873,-67.722149130275199,-49.772120834533794,-76.90238368608621,-77.491228186399468,-77.921457850162966,-77.544329032499476,-60.644813779742336,-61.683834385002783,-60.036824918554032,-63.034291070097829,-71.262608427556941,-57.305713039764157,37.446933222359654,37.433812409776081,-72.824039887964631,-42.507259384948057,-42.781569206017984,10.580450279277965,-66.561475605752861,-63.349454585665541,-55.717232016766289,-58.788390928574337,-59.862204944737236,-117.2419583589765,-61.224908128474631,-55.632393731441383,-56.634043381017271,-55.769659244302687,-33.697273581343488,-82.040133163013337,-30.369986058656686,8.0298518674931696,-131.53073500642566,-132.11656245896279,0.57873767774924012,-35.715531399465846,-54.186121044704493,-65.363175731389319,-59.653128890955642,-71.273882464580794,-59.172736028460527,-50.19764593890649,-77.062222598488631,-120.6556014086763,-69.797387701978579,-57.606047616919298,-57.346791604409816,-63.350783844685211,9.4234032230856499,-126.15639425513396],"y":[-5.8045512281941436,-15.679067780103884,3.9859026285604835,3.9699065221141141,42.862591582060872,72.971392963785661,37.098674195663229,47.944297928449565,-1.3528811256882987,51.366298069116667,23.611437711962449,36.723195737874278,37.030775007455155,62.294553806585327,-34.052162744979952,-32.821602560168969,27.303234872930563,6.3037275273694986,25.414159199646686,-14.132904735210229,-12.590416993443961,-13.61226948009636,-13.363788809864388,-15.006456186320484,-13.468099418754665,-12.618462125714066,-12.774046509217797,29.712941643334126,-54.562783533276829,-87.979117285552135,-90.345763928431182,-92.106904785793517,-87.828844181055302,-92.009179971299972,13.819403988915386,13.168627302087007,12.359741153675571,13.314359766348653,13.113945837898083,12.049758943056185,11.070969163679946,-19.475507561233467,62.300020273147425,-19.776785883335616,-18.777898049309407,-14.157696638548323,60.946856800754702,-81.404549101437112,29.568097919195765,-1.586832931538722,-2.9863305398803819,-5.2366357184209793,-5.6457292286209153,-6.4780094619275435,-1.3537286606696819,-0.87059881758065161,-0.11832791925472057,0.2549467923839222,24.106131468885295,68.67879344357506,73.870936410178899,33.496423569782984,-30.707220236404531,-29.614243274417237,-1.4374751976900808,-1.99996744878896,-0.33905973167708514,34.235486016035274,34.995081359268404,-4.3270338775308348,4.3539435690515136,32.773417012529762,-89.433860671002691,30.489799840763055,-90.245053278365447,8.3755211664436917,8.208037889453065,31.028153981958308,66.234699970725771,-55.579557047982647,-55.707956183908415,7.7573936386121494,5.5088701589030888,7.04304665049618,7.7305644303278784,5.3563124988560729,-86.763392818370406,-87.168655923296853,66.285934735127782,5.0143721727276613,-54.904648409625246,-82.231429177744971,-28.11557721293488,70.364276307430018,29.972051670700733,-77.480727747692853,116.87336505699345,10.376825382136559,-105.67504564104468,43.270897776592513,50.552765839829483,-15.282647879208231,-14.477970709868266,6.8671633257430145,-32.816932179363235,6.8505417623271141,6.7393010262969675,49.369646245522986,60.789992439360205,4.0700579823598,29.922479526224492,-34.344856870072235,66.392420758826646,33.430163629081044,12.432829767766258,2.9341323507467827,-0.51883136205988245,6.3896592603684903,6.2500019025793536,29.070645313694733,34.511108709773147,-5.5710930940793721,-31.135622435829028,57.557698732024541,67.543958215542517,29.565265738734485,4.0996989080043376,42.280234604849042,12.183593315639268,12.33554475803672,33.19511868341791,7.0765556150413556,-52.502693763310411,-57.76061255831241,-58.282797003430439,-58.195883990478933,3.8238847382270063,42.327122292275504,44.964909580208925,-29.693194285758864,64.419101317026872,-70.26001234142808,15.645531224474883,73.757770239393238,-71.495672266366526,-55.167798298970162,-54.77418772524365,12.74324141771303,30.642715540019747,-74.328025909365593,-38.507406713291779,-54.637223788340108,35.805736893919047,-52.505008124888732,-31.384504332565825,-31.321954460205532,-83.325208442832547,57.457222866291289,54.326423895225624,-7.6084640406384656,35.573510451217743,38.38090101005843,-36.783060339742185,72.53663581633711,35.541631765286041,44.923572755719228,-75.141695631273251,-2.6831924940833378,32.332696674241284,3.8203944590762027,-75.263767245888019,36.633396795627611,-55.910366674537748,33.873145311067631,-28.460339767544323,-33.831060944027648,-5.719654354906667,40.949227979179035,-64.248288354191274,4.3226334465705518,-55.676483015124376,59.002950525572111,8.8904439959125057,2.3882652189874398,-3.6865039790345473,71.815468513217283,4.2825693440597412,72.294956875156856,4.3884399928787099,-4.3827612147586903,73.054995562344729,31.921758642579448,51.626896708090051,12.060137360934361,-29.079732210466659,-32.237602571361826,-33.10476982362399,55.558745902962151,-5.2288549820851911,39.119584840125412,38.7507956782785,72.654144091823369,-21.766912962815923,3.7955278064717946,-36.127408384165243,-37.24677196625214,-36.421930764578008,11.460707814483762,42.836952476280629,40.989599905916855,63.663516648949972,64.437560448151117,40.841642240717157,2.1791391875557138,39.025477462060067,35.93482789880386,20.974259468690761,46.663416703633629,12.922302986471527,35.948506731991401,-3.8223301989585412,3.5868567432157552,26.290168983346888,-51.780539242239286,-51.500289193629378,-53.237650443569791,-53.839241052527399,32.612362184903731,-54.172299006973695,-37.271193364987795,38.582369359890102,28.601649561618604,62.676724515400295,-4.9346483592957986,28.508107460320904,4.9079540881398644,36.118441570216049,-32.992996855630921,-55.157087846434884,-2.516253631208508,-0.63742682872810297,-50.128688245234542,31.671869901489604,-85.461275549510418,58.844571428080584,64.10353846179018,-11.342936846255819,-5.1968832903166557,34.566341466537729,13.609653620633679,14.91705320031963,37.218649534475837,39.238729234593585,38.468957278949048,39.346528645433942,31.996620139653061,39.718134080080354,35.867458204508118,42.02198146271791,41.544821153055025,44.516957675786152,43.918728662988684,65.401577757221219,2.7147718724996657,74.303337510214675,63.537470882512793,73.915526972900906,-1.3904005776829722,59.465092333116118,31.173546654418939,-90.970766855439265,6.6292951802837656,-1.6122345023536278,-75.476194808263031,40.735888871088939,34.332833228714293,4.2655776509436558,1.2009826727589066,71.568140506942044,28.857010204742995,-55.222329520514556,-54.367336814858675,69.69333856775846,70.3216887869537,67.330381311547825,-75.690086530397565,-75.466950907023786,60.043651714479502,-76.865752886485566,-76.917769334272066,-77.043445854715458,-77.958071522785659,-76.251734870433893,6.9579795724493287,71.260687299117322,29.860538776905884,20.289115377938433,-83.915317351434197,-87.577464035729918,-86.313866049664014,-85.825116236793605,38.415640215730335,-37.893772345979457,-38.887358593637941,-77.192506739574611,10.442573965057798,78.889611333483714,73.852942019211099,31.668793453895788,-91.508806234370013,-89.540269835376179,-87.148956205368663,-85.503156608811096,-87.171193919910152,-85.426168318110427,-85.425251004101696,13.82067485194,-70.016543420615292,-81.598579391183847,-80.867518002328254,-82.23096613896179,-82.264092582313452,-81.504999460445077,-81.623743198955268,-83.026320242112973,-82.056751925569614,-83.961277986149256,-82.895628282980979,-85.310570881560935,-104.34080193920099,-29.066106626040721,-39.394313423947253,-38.849786840188557,-40.142707840831157,-39.146178681862381,-39.093862910692302,-40.139622814937603,-38.764834448611772,-36.112759688978947,-32.017351895521408,7.1439155395087699,-104.42479472499149,-102.63160913481209,-102.32685817679688,59.439263885324927,-78.162607557805543,9.8787768866188674,47.113147613121029,-53.997956211554055,-55.236471309021297,32.739823133480272,64.654455309825579,64.722378040238425,28.219250713173754,-3.642016306487236,-22.633432234118612,-65.628008601824419,-65.615380618487706,70.452945089416033,-35.445809921768891,70.405662399892407,71.331462698957651,41.623684790010365,35.587361629667484,9.921555588611966,3.2345082081610799,42.727549384670034,3.174868681621406,37.542043728165673,43.175532189387511,43.637467475869315,9.9593215359309664,46.412885637646255,44.385384546941488,45.908357100482199,36.221378349495552,66.268497882134284,34.871322143538592,51.13270772888535,40.402373182586025,46.825785882943777,45.096825596259542,-7.5553609529630483,-6.6712767237135333,-6.452803581773467,-1.8058505588589768,-2.3009752937333956,69.225271642043268,-78.573017737574673,-78.139776151224069,25.732220633189126,1.8622714650853123,1.757541730705876,-55.555270787613544,34.005202807502478,-2.9901032646668839,31.707347405142137,34.132100620591338,34.033649534069902,12.526364763051639,35.117864730726588,37.291703794875552,33.849294302159485,36.447663784219159,55.224545168111035,7.8433501541762762,-27.19151229226194,-55.202710463980125,42.381374580290554,42.825784809634108,55.064472074536646,41.436148538090087,-2.5178354471535456,3.4525738198254285,6.417031364846518,-1.9242380286613303,61.156358863026675,-2.777541624325464,46.686601455832275,15.133524608617112,-7.4999643932017674,32.863826842115721,33.480911791924555,-3.9931376471848705,-70.781546765982611,42.519379093266672],"z":[-22.160485017674553,-55.772346399296225,3.6111727547171473,2.72735578837441,49.079888592674322,0.73363049367855804,12.032828262423724,-26.43940908701672,-18.501677035673346,-4.4970888042018116,67.35239546457332,-8.9310141070117819,43.443182583163662,5.4599649054886239,-12.018015818521221,-13.541979070131662,31.880815686467592,-43.296255602397061,15.262188546353785,-58.467907262630462,-56.068056710069207,-54.629336682152541,-56.54077633062203,-56.757091916808157,-58.210141125137014,-58.313617722466297,-57.254724686600724,11.285038394743934,-3.2352727519871105,2.0521618344494303,3.3593114977057885,2.3190181022876799,2.9257804114373291,4.4078425857173258,-5.4293798473726875,-5.2575871206611913,3.7642401933606839,1.9273644327851647,1.4655994124415104,1.5324222320354783,5.3517520455656999,25.315213569032448,0.37947491212332096,26.101235370063563,26.028180459739783,-55.870880463806159,-0.02783686450760962,-6.1161977438000878,12.485848651944957,10.742417318488126,11.267406255052659,8.2219975360530491,9.0054360055270237,8.2561520235563322,11.32190632339845,12.745123684867735,9.8535853492256269,22.317794312925752,15.66166825499757,6.5199451549916869,5.434667329482906,66.931883170757985,-9.209833214414429,-8.5057685677320372,14.74632099328513,14.712422897424974,22.99528041170646,18.780028868399565,12.863603462957519,-16.690227534157689,-17.952871475470388,18.145727502423735,4.2356229314137881,-54.932410521161323,2.7520030723473043,10.650315971735919,10.526139601311808,7.376173385045135,2.0628645352422823,34.507117713698378,33.532453106195007,-41.330531000697235,-44.753650381490459,-43.867948337595479,-44.070430997736892,-44.625307501385919,0.13734256309870349,-1.0370889896601827,4.3911587423036185,-17.28432541541958,-5.4384331155720611,-6.1564079953716275,49.228253353328654,6.6031582549619348,7.3427487868782064,-8.7541612694332223,-28.166858645182007,7.2736219287182466,1.5845839661815364,-26.333992669538532,-25.698958712356326,-57.644253185611255,-54.997156350053992,34.140984526017995,-9.4562250773944516,34.850387531452746,33.131443320348524,-25.315698283385537,82.742246518214884,-21.242276429997286,12.510930896574774,-14.406428220897901,2.1731245192534572,-5.9280384135947157,5.3243406932577031,-19.620142016023209,13.240532784878781,34.085825391187655,33.02013960408388,13.492602702978765,-54.249531442311977,-89.907239522185776,-13.434219870471956,-9.66832631599158,2.2263560102415538,7.1566150477045705,-31.802099560099521,25.282930584219134,37.62699046124348,37.418538399753935,-55.032792144812291,35.344891709808614,4.6091987348066672,13.941761561071132,12.400715810321399,12.661707046605045,-32.158238045690027,47.232818705461,49.197517850015338,20.757021812280041,80.758709369043032,22.209096918528427,-7.1639980042069231,3.4924239700778226,20.192667429890776,38.917768966377523,38.516490647963259,-6.9318780513581988,11.293214589830292,1.1789561054198383,-11.266930463059133,-4.8412202824394983,40.67857713711534,3.9131253729361983,58.867315903760762,58.731480125715059,-5.123699885046527,-45.859904232848017,-8.6775623924805867,-19.863144458193567,-14.146404922776592,-10.60920755242501,-14.835009120094821,6.919087267105537,-38.967054185039004,-25.937372996085539,36.88399834586896,11.370167769706661,7.8414219202303928,-20.855660679146855,36.975108328141616,-54.858089032695247,-3.2629239682049755,9.5580924264000835,-2.6751638100515764,-11.608020328838334,-18.392134773997896,-4.6526959928493508,38.588574931441414,-46.731838033883456,33.914389637742893,-10.243745531741608,-44.3183469610629,-20.813128786987818,-96.320527662288072,4.1729285828534017,4.6472361715608859,1.167753907742821,-21.337834789336416,-23.017893407099553,2.2788567944096965,-49.564286636789348,60.947560351693681,-7.3159354768779323,-3.1292196802049079,-11.387637449261415,-12.965926707049316,36.230262846038286,46.282315120214463,-26.063022049169199,-26.044271261812813,7.8489120013072373,112.67128251156826,1.7167652090462233,-20.783765769492042,-17.276144743152713,-15.968180066812284,22.092439607974871,-23.407892304106063,47.134690051923485,-0.29034301129872292,-0.62278726945318774,-9.3166011263735768,8.8596645189940642,-10.400275332173376,-13.625730611286183,63.143763168983178,-25.591248422588652,-33.467711465088222,-6.3989273115068714,10.02485554387053,-31.0473634143334,13.244119398800843,5.407617061848021,4.8082135215429052,5.8976138982843445,7.1130289637234876,12.736384699913646,4.0278465453399441,-11.872056248671393,-12.369852224326698,11.111537447469912,5.4187363686999994,-19.824079051943457,9.2237128874776193,5.7002274417131504,9.5124981786368075,-15.824141440281421,38.515044248882212,-16.968353286217035,-17.190795123761063,4.5852938503473384,19.907846826204732,-16.183517402074685,-41.384612539429824,2.5562419356629289,-56.280903990799267,47.045292160407762,-54.799460138554352,-4.2600690414468447,-1.1877220986410604,42.483954378484903,48.425491533374583,48.103277978364922,47.238422079887044,17.310107083397661,48.010555876521984,42.748116587089761,49.690145835967449,50.633539680539684,46.244018511584287,46.698717808051285,-1.3230422959528545,25.87887304954597,4.1283892598968714,3.4313525239883216,6.4414482653032854,11.850249188131064,-44.760419742009944,6.9515843151273238,0.67902571178331572,6.5718392769641021,11.421593192265359,-0.34549661287731331,-10.75559605013849,-55.017010160680691,5.5258956442264431,-27.434252517032988,5.6587139919010543,9.2726926467224402,5.5755811006321823,4.5127911060300274,5.6958442492197436,7.5192205423289584,10.403886913566959,1.7842426817817056,0.15612766324453139,-1.1509593888857812,-1.573279582003932,-0.51818482873124716,0.070114939679423241,0.085674555993241738,1.1086221825277147,-24.953237051575172,4.5027302483100682,5.6967576790325047,21.750272536464546,5.8799273150321048,3.15465508599855,4.1136569969328391,2.9407208811929948,-14.384513248152667,-13.313889776185723,-12.832237337904267,0.65817440259430526,8.4356707666467461,5.7200940185654803,6.7688681102380457,13.643873264162394,1.0252444580371944,0.69330682499622198,2.8214705286544532,3.0310809029471737,1.0289515752280352,1.1266831723835435,1.1473960965574586,7.7648494711600646,21.213802725005632,-6.9094226271821277,-7.6715418549990826,-9.7220366056342211,-8.2010691179586388,-7.1503595127750632,-8.4461644261604274,-6.4292811664772884,-7.5935216172113629,-7.733194244863741,-6.5832869274629555,-15.822710958985731,1.5745808936884742,-2.0553425084500385,-16.183024062764662,-17.763136775806746,-15.319630328856167,-14.514121746115023,-13.433135919206876,-13.965953639549635,-17.722013022171723,-13.757878177177364,-11.949586625925559,-43.542361645193395,0.64914860741943392,0.55517384989486496,0.39300728202921709,-10.543898341603079,-1.1029793753915065,4.688651595478964,-28.296106025695291,5.3966023450989535,5.4977926703527897,13.999695932830603,6.2411131431012041,4.9188802921398604,14.395760282717919,22.119555490775198,20.138921609438498,-28.653861152762079,-28.588622825275252,-49.542764116933029,-22.505466883159087,2.948203424039149,0.91640479899041061,-10.708324307286322,-6.1034529826537689,6.6152164719882602,26.149905243047822,33.913756582106053,26.625360547168942,43.34511428108631,-30.777658497536084,-26.940264651187885,7.3665367923351521,-32.471152556558991,-27.179592022296074,-30.830927983936558,18.052948038809738,1.639207560316611,1.323972412347566,-24.754681661963694,-25.65369483855148,-23.968413234409809,-25.119860263317232,-21.624107610457184,-20.859454429674063,-20.539960516739676,-16.530608565760456,7.3753452839893416,4.9822434469613288,-31.199233018773334,-30.920080458188096,14.030434983729011,21.347637384117874,23.712857203277419,-3.577233174379554,11.658407533352229,-18.623306965214955,-54.704567145691314,-56.202763530143997,-51.876116250915466,-3.7616649890302547,-51.462598087867526,-52.333185991430845,-56.518861441589948,-53.437101426143947,-0.46434275812081977,-46.386658516607476,49.698672075692087,-3.2068220423804834,-25.655715530722727,-25.791450036534783,18.163126745429224,47.603635570704213,9.178665974875992,-18.461184776666595,-19.043097794653857,7.1669592071049539,0.11572722469391916,14.613418047282622,-25.454074143198063,-6.1174755395305054,-12.097308802091336,-52.800579710147844,-51.424977181281122,-16.456598554119772,21.863376997137767,-29.85602179489636],"text":["Input: 'aftaegtsmand traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'app boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'appren turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'apprentice turner in fitting s' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'apprenticed to potter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'architural draftsman' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'ashpalt maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'assistant edge tool works' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'assistant picture framer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'asst enginedriverroad roller' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'auto mobile mechanician' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'balance tster' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'betielbakker' (lang: nl)<br />HISCO: 89210, Description: Potter, General","Input: 'binding board manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'black smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'blacksmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'bleachers framer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'blk smiths' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'blouse collar maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker publican golden' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker apprentice s e r' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker for ry co' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker g w rly' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler maker man' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'boiler mkr' (lang: unk)<br />HISCO: 87350, Description: Boilersmith","Input: 'boilermaker lab' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'book maker games se' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'boommaeker en not mentioned in source' (lang: nl)<br />HISCO: 81925, Description: Cartwright","Input: 'boot and shoe maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot clicker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot finisher' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'boot rivitter' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'brass finisher' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'brass finisher (deceased)' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'brass finisher at engine wks' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass finishers plumber' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass founders finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brass worker finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brassworks finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'brick maker' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'brick manufacturer employing 2' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'brickmaker' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'brickmaker (deceased)' (lang: en)<br />HISCO: 89242, Description: Brick and Tile Moulder (Hand or Machine)","Input: 'bridge boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'bridle manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'brukskomakare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'bufflow maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'cabinet case liner apprentice' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maekr' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'cabinet maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker' (lang: unk)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker (deceased)' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker apprenitce' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinet maker daughter' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'cabinet maker master employg o' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'cabinetmaker and upholsterer' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'candele maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'cap roller cotton' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'caps machine hand hatter' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'card room jobber' (lang: en)<br />HISCO: 84900, Description: Machinery Fitter (except Electrical), Specialisation Unknown","Input: 'chain maker' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'chair maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'chair maker benchman' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'chair maker journyman' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'chair upsholterer' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'china riveter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'chinell maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'chocolate box wood mkr' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'chopman' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'clay bath maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'clicker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'clock and watch maker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'clog maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'coachbuilder' (lang: en)<br />HISCO: 81920, Description: CoachBody Builder","Input: 'coachsmith' (lang: en)<br />HISCO: 81920, Description: CoachBody Builder","Input: 'collier harness maker' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'color manufacturer d p' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'cooper' (lang: en)<br />HISCO: 81930, Description: Cooper","Input: 'cooper (deceased)' (lang: en)<br />HISCO: 81930, Description: Cooper","Input: 'copper man labourer' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'copper smith labr' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'coppersmith piping' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'coppersmiths lab unemployed' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'copprsmith' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'cord wainer' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'cordwainer' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'cotton and linen manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'cutting cerditt' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'deres son hjulmand' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'deres son skomagerlaerling' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'diamantsnijder en not mentioned in source' (lang: nl)<br />HISCO: 88030, Description: Gem Cutter and Polisher","Input: 'director mechanical engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'ditto maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'dreierlaerling' (lang: da)<br />HISCO: 81230, Description: Wood Turner","Input: 'dress makers erand girl' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'drugest finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'ebbenhoutwerker en not mentioned in source' (lang: nl)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'edge tool finisher' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'edge tool works manager' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'engien boiler maker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'engine boiler maker apprentice' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'engine fitter' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engine smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'engineer' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engineer's fitter' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'engineers tool manufacturer' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'engraver on pearl buttons' (lang: en)<br />HISCO: 88090, Description: Other Jewellery and Precious Metal Workers","Input: 'faggotter' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'fancy leather case worker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'farrier' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'field drain tile manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'finisher artisan' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'finisher for hosiery' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'firewood manufacterer' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'fishmonger chair turner' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'fitter' (lang: en)<br />HISCO: 87110, Description: Pipe Fitter, General","Input: 'fitter (deceased)' (lang: en)<br />HISCO: 87110, Description: Pipe Fitter, General","Input: 'foreman margarine maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'foreman watch maker jeweler' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'forge labourer' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'forgeman' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'form missronery' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'foundry labourer of ironworks' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'french crower maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'furnaceman' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'ganger royal arsenal' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'gas fitter' (lang: en)<br />HISCO: 87120, Description: Gas Pipe Fitter","Input: 'gas hot water fitter' (lang: en)<br />HISCO: 87120, Description: Gas Pipe Fitter","Input: 'gen watchmaker jeweler' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'general engineer' (lang: en)<br />HISCO: 84100, Description: Machinery Fitters and Machine Assemblers","Input: 'gjotler' (lang: no)<br />HISCO: 87245, Description: Brazer","Input: 'glasblaser en not mentioned in source' (lang: nl)<br />HISCO: 89120, Description: Glass Blower","Input: 'glass cutter' (lang: en)<br />HISCO: 89156, Description: Glass Cutter","Input: 'glass cutter (deceased)' (lang: en)<br />HISCO: 89156, Description: Glass Cutter","Input: 'glass maker' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'glass placer potter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'glost warehouse sorter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'goudpletter en not mentioned in source' (lang: nl)<br />HISCO: 88070, Description: Precious Metal Leaf Roller","Input: 'goutdraattrecker en not mentioned in source' (lang: nl)<br />HISCO: 88090, Description: Other Jewellery and Precious Metal Workers","Input: 'goutsmit en not mentioned in source' (lang: nl)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'grinder' (lang: en)<br />HISCO: 83530, Description: Tool Grinder, Machine Tools","Input: 'grocer wife of wheelwright' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'guldsmedgesaell' (lang: se)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'gun barrel maker' (lang: en)<br />HISCO: 83920, Description: Gunsmith","Input: 'gun maker' (lang: en)<br />HISCO: 83920, Description: Gunsmith","Input: 'gunlock filer' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'hanvel maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'harness maker' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'hinge maker' (lang: en)<br />HISCO: 87390, Description: Other SheetMetal Workers","Input: 'hjulmand' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'holloware caster' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'horse nail maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'houtsagersmolenaer en not mentioned in source' (lang: nl)<br />HISCO: 81225, Description: Precision Sawyer, Hand or Machine","Input: 'houtzager en not mentioned in source' (lang: nl)<br />HISCO: 81225, Description: Precision Sawyer, Hand or Machine","Input: 'huusfaders moder' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'in a foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'in army reserve and agricultur' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'indsidder og traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'instrument maker' (lang: en)<br />HISCO: 84240, Description: Precision Instrument Assembler","Input: 'instrument maker ranger finder' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'iron forger' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'iron planer engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'iron turner' (lang: en)<br />HISCO: 83420, Description: Lathe Operator","Input: 'japanner' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'jeweller' (lang: en)<br />HISCO: 88010, Description: Jeweller, General","Input: 'joiner cabinet master' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'jour h maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'journeyman render' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'juwelier en not mentioned in source' (lang: nl)<br />HISCO: 88010, Description: Jeweller, General","Input: 'k md' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'karetmagersvend' (lang: da)<br />HISCO: 81925, Description: Cartwright","Input: 'key maker a p' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'keymaker' (lang: en)<br />HISCO: 83930, Description: Locksmith","Input: 'keysmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'kistenmaker en not mentioned in source' (lang: nl)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'kitter' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'kokermaker en not mentioned in source' (lang: nl)<br />HISCO: 89990, Description: Other Glass Formers, Potters and Related Workers","Input: 'kopparslagaregesaell' (lang: se)<br />HISCO: 87330, Description: Coppersmith","Input: 'kuiper' (lang: nl)<br />HISCO: 81930, Description: Cooper","Input: 'laborer unemploy' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'labourer in copper engraving w' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'labourer timber carrier' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'labourer wood' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'lace machine filler appntce' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'laces turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'lasting machine man boot facto' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'lath grinder' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'lath render licensed victual' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'laundry hand ironing machine' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'level escapement maker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'lithographer artist pottery ap' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'lock filer' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'lock smith' (lang: en)<br />HISCO: 83930, Description: Locksmith","Input: 'locksmith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'locksmith, deceased' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'locomotive packer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'loodgieter en electricin' (lang: nl)<br />HISCO: 87105, Description: Plumber, General","Input: 'machine fitter' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'machine maker' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'machine makers apprentice' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'machine operator' (lang: en)<br />HISCO: 83410, Description: MachineTool Operator, General","Input: 'machineman appr' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'maesterhammarsmed' (lang: se)<br />HISCO: 83120, Description: Hammersmith","Input: 'maestersmed' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'maestersven' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'maker market talloring' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'makes butcher tools' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'manufacture glost placer' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'manufacturer of cottons patent' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'manufacturer of crop seeds' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'manufacturing optician retired' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'master chair maker employing a' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'mathamatical inst maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'mathematical instrument maker' (lang: en)<br />HISCO: 84240, Description: Precision Instrument Assembler","Input: 'mechanic' (lang: en)<br />HISCO: 84900, Description: Machinery Fitter (except Electrical), Specialisation Unknown","Input: 'mechanic gun tool maker' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'metal spinner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'meterological instrunt maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'meubeldraaier' (lang: nl)<br />HISCO: 81230, Description: Wood Turner","Input: 'mill furnaceman' (lang: en)<br />HISCO: 89320, Description: GlassMaking Furnaceman","Input: 'morocan case maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'nail caster' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nail maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nailer' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nailor' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'nickle telescope maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'nut and bolt maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'oliver smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'optical instrument tool maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'packet spink mathers maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'packing board coverer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'packing case maker' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'par relief dress maker illness' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'pasent shirt turner' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'paternmaker foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'pattern maker' (lang: en)<br />HISCO: 81935, Description: Wooden Pattern Maker","Input: 'pedreyaler' (lang: ca)<br />HISCO: 83920, Description: Gunsmith","Input: 'picture frame joiners' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'picture frame shopkeeper 3 men' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'pin maker' (lang: en)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'pipe maker' (lang: en)<br />HISCO: 89290, Description: Other Potters and Related Clay and Abrasive Formers","Input: 'piqueuse de bottines' (lang: fr)<br />HISCO: 80250, Description: Shoe Sewer (Hand or Machine)","Input: 'plaatsnijder en not mentioned in source' (lang: nl)<br />HISCO: 87310, Description: SheetMetal Worker, General","Input: 'plaster fiber manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'plater boilermaker' (lang: en)<br />HISCO: 87350, Description: Boilersmith","Input: 'plumber' (lang: en)<br />HISCO: 87105, Description: Plumber, General","Input: 'police pensioner watch clock' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'polisher' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'polisher at cycle works' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'pottemager husbond' (lang: da)<br />HISCO: 89210, Description: Potter, General","Input: 'potter' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'potter' (lang: unk)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter at' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter crate maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'potter hansferrer' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potter, deceased' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'potters decorater painter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters painter' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters warehouse' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'potters warehuose' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'powder working in manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'presser' (lang: en)<br />HISCO: 89247, Description: Pottery and Porcelain Presser (Die or Hand)","Input: 'pressing machine in factory' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'pump manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'railway loco engineer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'rate collector cabinet maker' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'remedial gymnash' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'ret harness maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'retired boot and shoe operative' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'retired french polisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'retired joiner and cabinet mer' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'retired saddler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'retired scientific instrument' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'retired watch maker finisher' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'rigger' (lang: en)<br />HISCO: 87400, Description: Structural Metal Preparer or Erector, Specialisation Unknown","Input: 'riveter' (lang: en)<br />HISCO: 87462, Description: Riveter (Hand or Machine)","Input: 'rivetter machine works' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'road maker croft 2 12 acres' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'roeremaecker en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'roerenmaker en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'roller coverer cotton mining' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'roller filter' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'roller maker foundry' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'saddler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler tarpaulin manufactur' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'saddler employing 1 men 1 boy' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmagerm' (lang: da)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmakare' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadelmakeriidkare' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sadler' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sanitair gieter bij een aardewerkfabriek' (lang: nl)<br />HISCO: 89235, Description: Pottery and Porcelain Caster (Hand)","Input: 'sanitary mechanical engr em' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'satter' (lang: en)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'scampstress' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'schoenlapper en not mentioned in source' (lang: nl)<br />HISCO: 80130, Description: Shoe Repairer","Input: 'schoenmaker' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'schoenmaker en not mentioned in source' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'schoenmakersgezel en not mentioned in source' (lang: nl)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'scientifc instrument maker' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'screw forger' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'scythe forger (deceased)' (lang: en)<br />HISCO: 83915, Description: Cutler","Input: 'sellier' (lang: unk)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'sent finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'sewing machine makers and builders' (lang: en)<br />HISCO: 84150, Description: Textile Machinery FitterAssembler","Input: 'sewing mc screw maker' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'shipping tackles maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'shoe finisher' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe laster' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe maker (deceased)' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoe-maker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoemaker' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shoemaker (dead)' (lang: en)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'shorthand finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'silversmith' (lang: en)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'skoemagerdreng hendes son af 2 aegteskab' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skoemagermester' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomager' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagerlaerling' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagermester' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomagersvend logerende' (lang: da)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakararbetare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakaredraeng' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skomakeriarbetare' (lang: se)<br />HISCO: 80110, Description: Shoemaker, General","Input: 'skosoemmerska och filosofie licensiat' (lang: se)<br />HISCO: 80250, Description: Shoe Sewer (Hand or Machine)","Input: 'sloejdarbetare' (lang: se)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'slotenmaker en not mentioned in source' (lang: nl)<br />HISCO: 83930, Description: Locksmith","Input: 'smed' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smed' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smed mand' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedelaerling' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedelaerlinge' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedesvend' (lang: da)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smedgesaell' (lang: se)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smit' (lang: nl)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smith' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'smiths assistance' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'snedker' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'snedkerlaerlinge' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'snedkersvend' (lang: da)<br />HISCO: 81000, Description: Woodworker, Specialisation Unknown","Input: 'sobbing laborer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'sockensadelmakare och ordfoerande' (lang: se)<br />HISCO: 80320, Description: Saddler and Harness Maker","Input: 'solid finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'spade shaft finisher' (lang: en)<br />HISCO: 83110, Description: Blacksmith, General","Input: 'spijkerblauwer' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'spijkerkoper en not mentioned in source' (lang: nl)<br />HISCO: 83990, Description: Other Blacksmiths, Toolmakers and MachineTool Operators Not Elsewhere Classified","Input: 'spinch maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'spindle flyer manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'spindle and flyer manufacturer' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'spong bed maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'stamper' (lang: en)<br />HISCO: 83960, Description: MetalPress Operator","Input: 'steentjesbakker en not mentioned in source' (lang: nl)<br />HISCO: 89360, Description: Brick and Tile Kilnman","Input: 'stenarbetare' (lang: se)<br />HISCO: 82000, Description: Stone Cutters and Carvers","Input: 'stenhuggare' (lang: se)<br />HISCO: 82020, Description: Stone Cutter and Finisher","Input: 'stock fitter for shoes' (lang: en)<br />HISCO: 80200, Description: Shoe Cutters, Lasters, Sewers, and Related Workers","Input: 'striker' (lang: en)<br />HISCO: 83190, Description: Other Blacksmiths, Hammersmiths and ForgingPress Operators","Input: 'superintendent engeer mechani' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'surface laborer colly' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'surgical appliances' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'surveying instruments maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'table baize finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'tailore presser' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'tarpouline maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'tile presser bickiln' (lang: en)<br />HISCO: 83290, Description: Other Toolmakers, Metal Pattern Makers and Metal Markers","Input: 'tilemaker' (lang: en)<br />HISCO: 89210, Description: Potter, General","Input: 'tin zinc worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tin plate worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tined holloware finisher' (lang: en)<br />HISCO: 83520, Description: Buffing and PolishingMachine Operator","Input: 'tinman brazier ap' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tinsmith' (lang: unk)<br />HISCO: 87340, Description: Tinsmith","Input: 'tinsmith all kind of lamps' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'tipe block maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'tobacco manufacturer and chemi' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'tobaco weighing' (lang: en)<br />HISCO: 84290, Description: Other Watch, Clock and Precision Instrument Makers","Input: 'tool factory manager' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'tool maker' (lang: en)<br />HISCO: 83220, Description: Tool and Die Maker","Input: 'tool maker curling and hair pi' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'tool maker steel' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'traeskokarl' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'traeskomager' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'traeskomand' (lang: da)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'tulip frame maker' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'turner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'type foundry wharehouse' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'uhrmager' (lang: da)<br />HISCO: 84222, Description: Watch and Clock Assembler or Repairer","Input: 'uhrmager mand' (lang: da)<br />HISCO: 84222, Description: Watch and Clock Assembler or Repairer","Input: 'underclothing pinafore maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'upholster cabinent maker' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'upholstor' (lang: en)<br />HISCO: 81120, Description: Cabinetmaker","Input: 'vagnmakare' (lang: se)<br />HISCO: 81925, Description: Cartwright","Input: 'valve maker pneu tyre' (lang: en)<br />HISCO: 80390, Description: Other Leather Goods Makers","Input: 'washb fecto' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'watch and clock makers' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch jobbers apprentice' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch piveter' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch polisher' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch repairer worker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watch trade finishing stoning' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watchmaker' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'watchmaker employing 1 man' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'weigh machine man and shopkeep' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'weigher at hafod copper works' (lang: en)<br />HISCO: 87330, Description: Coppersmith","Input: 'welder' (lang: en)<br />HISCO: 87210, Description: Welder, General","Input: 'wheelwright' (lang: en)<br />HISCO: 81925, Description: Cartwright","Input: 'white smith' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'whitesmith' (lang: en)<br />HISCO: 87340, Description: Tinsmith","Input: 'wireman' (lang: en)<br />HISCO: 85700, Description: Electric Linemen and Cable Jointers","Input: 'wk pottery' (lang: en)<br />HISCO: 89200, Description: Potter or Related Clay and Abrasive Former, Specialisation Unknown","Input: 'wood carver' (lang: en)<br />HISCO: 81945, Description: Wood Carver","Input: 'wood prepairer' (lang: en)<br />HISCO: 81230, Description: Wood Turner","Input: 'wood presser and bundlers' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'wood turner' (lang: en)<br />HISCO: 83320, Description: Lathe SetterOperator","Input: 'woolen manufacturer employing' (lang: en)<br />HISCO: 84190, Description: Other Machinery Fitters and Machine Assemblers","Input: 'workes in furniture factory' (lang: en)<br />HISCO: 81190, Description: Other Cabinetmakers","Input: 'working tool maker striker' (lang: en)<br />HISCO: 83210, Description: Toolmaker, Metal Pattern Maker and Metal Marker, General","Input: 'works arsenal' (lang: en)<br />HISCO: 83590, Description: Other Metal Grinders, Polishers and Tool Sharpeners","Input: 'works in bent wd fact' (lang: en)<br />HISCO: 81290, Description: Other WoodworkingMachine Operators","Input: 'works in clock repairing shop' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'works in clock shiop' (lang: en)<br />HISCO: 84220, Description: Watch and Clock Assembler","Input: 'works in shade factory roller' (lang: en)<br />HISCO: 81990, Description: Other Cabinetmakers and Related Woodworkers","Input: 'zilversmid' (lang: nl)<br />HISCO: 88050, Description: Goldsmith and Silversmith","Input: 'zinc worker' (lang: en)<br />HISCO: 87340, Description: Tinsmith"],"mode":"markers","marker":{"color":"rgba(215,191,158,1)","opacity":0.69999999999999996,"line":{"color":"rgba(215,191,158,1)"}},"type":"scatter3d","name":"8","textfont":{"color":"rgba(215,191,158,1)"},"error_y":{"color":"rgba(215,191,158,1)"},"error_x":{"color":"rgba(215,191,158,1)"},"line":{"color":"rgba(215,191,158,1)"},"frame":null},{"x":[71.884899740921142,-35.634103583046127,-11.38246687395505,12.549345107831355,-74.460335088817644,-71.094760151307995,-70.50139437347724,-77.041518543594904,-98.71664261727166,-38.606859173405176,53.92687798914951,51.616271797239065,48.088442299735533,47.826825786774279,46.515576346527425,48.122200110846521,54.07176582680021,49.366983482711014,49.937917554581396,50.145590728119963,51.812857365429494,48.887131283542651,45.326736212040686,51.596427345647783,47.930913609346987,49.139951509624581,48.561489050855222,50.635172688399116,-86.264539615732289,1.9165928915625046,-42.512303856919708,-45.279591635584872,15.303057317927896,-41.011332399622887,-40.701631864865931,-43.086598494610357,-43.229779082484463,-42.276038375314101,49.927686168746625,-39.529227266721612,54.182667440512937,30.900670495699334,31.029237319514944,-14.476615872944587,52.715721132327864,-43.035965184503269,45.739297445921856,-16.875137797727831,-16.862541073046604,-91.473559826575368,-93.758742424041728,-39.391068882721278,-87.992566471601677,-52.509215580009545,-16.514049829463787,55.681697782649806,54.283523465727946,51.544199398245667,-39.119349118868087,49.68739779435316,50.233594186090919,50.955696795984132,-46.958758065721931,47.227677657252876,-95.50296999487901,-48.704553335194085,25.119918371624742,25.978365122629665,25.432787056201651,-18.18490438848081,-8.1393547771231525,-8.2067797035211694,12.14514157347096,11.382539491731121,-39.639919917200295,-55.956748531400898,-93.659663967544191,-92.475227027002859,-94.718825017245024,-93.251816399039484,-93.635002479698315,3.0782817198642762,10.591843497658628,10.640596164252589,10.167981689447002,-79.092178593498744,46.741723471078096,13.315125226161644,-28.543547365535805,28.359739128508192,27.052106545100202,-11.39649882616351,-4.1484420664567372,-2.731732707978404,-2.6707992454553504,-1.485556727572694,26.798841446073794,25.720758329724926,-100.28887498610078,-80.639246713913707,-81.408716557390946,39.910818879096908,-99.683749076453537,-46.715674368157238,-10.444284236585752,5.9035041007298341,-52.528549420411672,13.308214700119391,26.612108951115271,27.089449237410797,28.390022722753635,13.721200316648508,-12.893748378238334,-12.293893527674745,70.010290224848916,-79.011928078810087,-46.431071419429436,59.22391822397347,43.718365317750624,-39.524255965545343,29.625538469167417,-40.347126318282058,-37.883186361386976,-33.802472446137607,-73.74271076213482,-105.11007057138211,-14.467160317992613,-51.221382701185092,3.1569432715890184,33.599828631449391,30.061625842868178,26.926447896155555,27.540704916177074,30.832971936040341,26.594656925360869,26.363317984955881,30.276699439563252,31.681503968005593,29.06146252136703,33.506876776592115,32.313996535178674,32.600435209584234,-29.790063227401493,-73.111564585541785,-73.840557694915503,42.588967964755852,-0.93113367223399879,-76.342967409212505,44.280236912044934,44.718046901661232,27.902176402439409,43.612924022913631,-45.267326399438126,50.292722872124614,-16.244617643926667,-16.777828613799734,-16.97096063253672,-18.001605506415995,26.161757478644386,14.183094221033601,12.688743477009874,2.5720914956170087,3.7254638881522673,5.6168024271263475,34.492891403831464,-73.362388532315435,3.4731121417197452,54.084383047300818,-44.283454262730324,-33.501430801754566,-44.762023977121885,-34.41428379079251,-35.501567757616705,-37.291578872183671,-38.261123902831507,-38.628746311685063,-37.825321849323167,-77.509149378643173,38.675094312393291,-80.825793091703744,-9.5748763517980677,-60.03364010670839,-49.525158406561722,-46.151891422786953,-88.11926226938327,-103.54035174549844,-122.8104574582939,-71.835120416595544,-78.787664704000647,-73.207277345775594,-78.770291654066725,-68.718047888287202,-73.079875942269268,-31.659668984243858,-16.000404636717782,-36.414166027954472,-49.000312652135236,43.87264239674419,-49.329219246695047,40.775236294255961,-14.247183874061864,-42.813109913349074,-13.779374329394415,28.600305498007192,-32.219262893851472,5.062828147375976,-17.774870080156308,-76.603815773724818,61.85008861893197,50.996093617194234,-51.567911068237052,-53.871469192939927,-112.73849712866908,-38.583810574512377,40.978451380459568,10.832666002346347,47.511510052628154,26.583648347298361,-17.220236312787293,-29.029298104130742,124.58007371021561,27.049318556147682,23.591498508877034,2.5095227678054042,45.476793986027978,12.424810560071828,-45.474928641159075,4.6335162345699601,-93.985144234349306,-84.888049438462474,-2.9430444903806716,-1.0141451866889362,68.449926296400292,-2.4906283418648005,-2.1313289007624685,-0.23931116552977663,-1.2807875678872007,-2.3325583489968698,-0.72457646574936529,12.498959610482087,-73.220924034134072,50.217238926945505,25.400315520386027,26.070289524340463,27.093401390975867,27.849022803527554,45.30425486136437,-97.689898518086139,-16.19210434556339,13.974103641645991,51.135004350272553,50.036366594968548,-95.700099359931713,30.078713199798802,29.719604638116067,30.617496299917676,28.387000075898495,28.743486737257612,27.626499186732044,44.571887148435742,-38.847339297843313,-4.2314808279122937,-46.842133500343053,-1.154028579502385,39.076966774277125,-60.352891879460252,-43.812574127905705,33.213979653367225,-31.158787870977022,54.317958511346284,-46.310588997499046,51.779232221680708,35.188426477576201,-15.676734843827901,51.484459166042456,49.568931906840099,-10.981217007741822,34.339257183658987,-81.313235415063417,-13.033124092871262,-53.977409228968924,-78.531432059851269,-78.945004664113341,-76.077268312045064,-77.806939461839463,-77.294897798508742,84.559736236441807,-74.493627392542081,-76.325800847325226,-80.008368408985262,-78.343069283260618,47.892305343635641,45.419593234205983,46.25635374213342,45.920115182163478,-72.571832483801415,-72.403314640382845,12.120631671864299,42.860816008848808,-36.906944382734707,-37.492620595186153,-36.012827973493856,-28.898827749601484,-41.040760180404071,-39.181818727166991,30.757568268995101,-11.952465891253523,38.512116298033355,-79.233778074287429,-38.657184153688739,38.425277234384517,7.3138184106557471,-46.733618515265121,-50.298578636681135,50.886171252364718,-79.145824518880843,-33.364725883884503,51.373468206407281,50.18487320948325,49.411523885524254,42.38244856944241,-98.554958471949291,-48.366901760523078,-75.581031340498271,9.7814453554177518,9.8048622959827902,-2.8657275772941957,-42.490591453468383,42.947621779260977,43.788523469416461,44.377924295371109,-134.44729198101888,-44.481838268804921,13.432927368163194,13.003344915774008,12.542945053304672,-75.879056790760174,-1.0614736264606583,15.059339222262102,10.357803065166479,6.3283066146806704,12.859532486098571,-36.547267118748628,-99.733624204640563,19.463321891399328,20.725219254281381,22.016799342269188,20.810171493746122,21.376794099889629,-44.961437393579857,-78.165145929972482,9.046361387849382,-74.616288587342865,-55.049863705190042,36.658696767772149,-77.01916035451724,34.550115269109064,-19.720936648811367,42.672111606107698,39.911613756290471,14.240096532601969,13.400602887108331,13.945803931063853,-2.2889854086111936,-0.93783697438912972,-0.029737983740330046,0.042650103146206743,-33.675640634752043,-3.428067302976832,-5.1704319126295051,-3.202424009595183,-93.325277939268432,-56.687644998901277,-57.155903444221046,-13.51355172949628,-12.264932271881861,-45.559797757962315,-33.609587652693357,-30.0574933736243,-11.360875064690317,-13.330576720845512,-90.028275971760564,-75.096264532664662,-38.218133738921772,-76.549515580040676,-76.006660241877171,-14.182389596206521,54.356098678397508,50.2509807505091,42.630090442614879,40.800521283988466,46.10837723327495,38.338880006502301,41.095712573793307,43.140787701948057,-29.744466938408241,40.485437671363208,40.581349958582386,38.041500572846608,28.092357707218994,71.064496277468095,-27.878807905880166,-32.513594254192945,-41.264092080232047,-42.444556451715712,-42.576176706863805,-12.956381786402435,-31.370755847166812,-35.697328333694308,-41.029121417293034,-42.783094226046209,-38.518947092755653,-36.768705442565654,-10.054590675024825,22.671586374408403,70.051514516150263,70.537363608922988,22.036329680334674,22.159894009499855,27.225427476033754,-34.664890351073517,26.97699553233404,49.550409988902366,4.4542451888636876,21.049451910867621,20.218812706523838,40.721682204826109,13.42408923224267,42.331101838523026,-9.5198258853485509,-65.860841594233946,-80.095327010739283,-77.658656140831141,41.316404674623342,9.5722739133223502,41.024905923241811,70.942928849690574,41.591053642490436,-15.135622429513685,-29.261943675834907,50.678772231657234,28.745870906268017,27.602215477406926,28.04247598053173,36.048720836837887,27.613266010113982,6.6819532813174769,7.2530326366664122,7.3607554658899961,43.355885234766475,20.925489880755812,-94.516944754244804,-89.511250016387478,-68.382178108461304,-69.501876569332339,0.40378918079721637,-1.5264778058614239,-1.3172201857357508,25.583544631990033,23.456480430724373,21.23352683173065,22.169883792181004,23.962823121873367,21.776602814663658,23.333871615149484,-34.94761148204099,-70.914849793028509,-27.812984829270874,42.564699324907373,52.746861123083995,-0.22261063984156712,-79.046121732617038,-45.111731483375728,31.273959982979314,30.472292894914311,31.081065206736433,35.36565281769581,36.389983042387193,35.551583010868555,35.664530391682874,10.722228647954845,12.796567348157756,42.807340559724352,43.083336095691173,-69.881085466412486,-92.715809906065559,-40.598950382913287,-31.659072819144132,-15.704561074294475,-31.412054758000352,-49.760720437510685,-48.722304720293018,-11.977176783630178,-87.866219702075426,-13.635755424373434,20.799526331200781,41.191106683939388,26.26799898220272,26.14307273427907,41.698378938833152,12.242090860088382,-106.13565144091962,-43.883075181772917,-37.353308779544818,-39.767764668525778,-35.39533208944659,33.701278848906583,-2.4137754974385683,-121.31368709304753,-54.732273944883033,68.690500915825382,-43.85649513116303,33.013801141289044,34.315412215387383,34.038468940474559,34.142094983792852,4.5681335220971597,-37.251845418473287,2.0999211885360625,27.035222181697875,3.4409135040377343,52.443350615712603,-37.653813780071324,13.199845213906235,-50.316148970454492,40.408441866833435,41.111710261600592,38.370683285998929,39.59694836598598,39.478000778028601,42.120483030532363,38.84826888993917,42.809421205614719,39.985635696427885,40.924156533862615,39.312721237207839,41.756815280599923,41.569330324564966,13.276299991663343,-75.222751215955782,-77.425004622606011,32.452441170410729,28.030864917622957,-17.212795717296203,-17.591545176980343,-11.438609783511414,-12.780400050754247,55.145208621276751,-94.672364565392328,12.892654520625586,-15.145310751619315,11.435661894618788,19.611482249762005,-90.229090609387669,45.842293931180791,-32.831533469635957,-43.160310750772055,-67.478608817085544,-48.555921495801172,-90.337150049410198],"y":[17.812869816774093,34.664142017081467,81.723525409782496,-24.223807904896574,-5.1039744651383838,-6.7869526066506936,-7.8981960892488416,-12.241452078081425,-18.72479214546669,37.041835283649128,-70.458259132759309,-70.83252368463603,-73.98709971658937,-76.092627985535032,-75.066664528348028,-75.451585379610449,-71.283473743123068,-70.488790051401352,-73.282928644943652,-74.636649330984326,-67.913576214488216,-73.273162617797553,-75.662052663315848,-66.858317332641363,-69.377633262006412,-68.697169173912386,-68.581165927498802,-66.458873899959855,39.853047739152451,38.441712450699598,21.786121845119201,23.591668858277441,80.436622163034656,25.832949141693078,26.673741824910934,25.587160035437456,23.439029464747513,23.157732761609957,50.026253092733064,21.105206225307153,-44.740697666886973,-110.65228645540948,-110.87454314274588,85.713841373838022,-45.116251512641483,21.908993497091377,-60.298624000001055,-67.949211492700414,-67.513220377850516,37.039368469309977,42.665610960728223,22.627845341985505,35.78554043168225,33.217821907267322,94.454316171603779,-44.166420206099019,-44.356429554499833,-72.245197875242809,40.920378889982224,-72.900307582036859,-72.598636793293139,-71.913747921775169,25.016205782286725,78.007379210260893,39.336434674560834,55.298116396596932,120.83771442918528,119.36616075627133,120.46070445634103,81.107762156944943,78.332387041768399,78.642479274315804,-62.950558540925869,-62.738054566612199,40.565785399636695,68.876508857923881,36.605498844520149,35.899725731431815,38.701288070998196,37.79984376296715,35.70379569171169,26.90182416542671,15.632398646953407,15.406721025371159,17.959775899914142,-6.8456590198864991,80.921756920491106,84.114569939873761,32.775704907720034,-16.238483626715649,-15.447554198164365,82.230750061465457,-44.900473685761398,-44.075487922289959,-44.905957367347277,-42.742259600635514,-15.409403814830878,-15.177359276555027,34.200526715065884,-11.673418499680729,-12.337302787962287,89.350472662450741,-17.495511726772758,28.121879462654121,79.757371836969796,90.123064502263745,36.390246244670479,84.26091134676669,-12.250104018991525,-13.176535608936643,-14.167467244397081,81.431579676030864,79.585512465838605,80.43894100826418,18.778618573203218,-5.9569956973281952,24.008802733202472,69.317312511520171,79.842510575222875,23.424415933597729,-18.584383047388375,35.238240197266101,41.400465165154905,35.582711419673309,-7.8679769785576816,-11.648993320789684,79.705491964440682,4.9190183812028554,90.866440184023091,-107.84713755354255,-118.25452002173945,-114.40272183333772,-111.41359909846958,-116.92848203364207,-114.4722213003304,-116.55194796355477,-114.26578254495925,-116.77577135906317,-114.05440470999299,-109.25941284061322,-112.50175558484305,-108.39889741001622,53.908823753640007,-11.894750081198007,-9.784586850420526,-61.944370834888204,55.60237161590738,-10.047061642725511,-74.796140644063314,-58.831865114873224,-117.65284758680279,-60.636070976024953,32.34275510194324,-74.131077953231468,97.337359415736657,94.184281848573818,94.702967207240334,95.891175311497491,-14.109479565992244,81.49229478305881,80.931341766934665,90.446363606608955,90.669775815558637,92.75277588411096,-35.936425424078259,-7.8490625277458346,90.424682205001432,-62.404021287121715,44.350351519190959,50.982253549238266,34.315336386407971,52.90093079301252,106.63965730705644,107.75569151939709,108.46858791314533,107.52961033849759,60.632560133952218,-9.3035873750391396,87.353945537552789,-6.7078105557257048,83.535838780864708,48.054750857019975,25.637169734511275,25.707279048608186,15.536114982068669,-13.368502246015341,-2.4191931720699578,3.4043035950985723,-11.893880146096176,-9.1964184708369778,-12.903439362105928,-7.3593667680561987,-7.9071832039633305,52.776818275345988,95.493860172699087,55.264757652004285,31.489377980881653,82.723260169997999,33.854562170489388,82.228766220038565,84.80064021572862,21.666956164622782,77.359757101912692,-115.46167334880707,53.669596180390002,76.775109116543959,96.022382881935997,-7.9570633461958202,29.183883164811771,-63.494352759962922,36.640346039606115,25.285380610527078,2.446735285368566,-45.454476136029058,89.642982880645008,78.783753262679767,-73.013331807540268,122.00735027560191,92.584133526538992,24.42536092958942,-122.96610032483053,-15.821490087387133,-7.7205371810053345,92.045985379859047,-59.069753800830789,77.583688504726439,19.75707254190992,92.797862717653501,40.674554075816374,21.734696215831072,53.3822963173237,53.792517895760696,30.342009528944256,51.822082735526635,54.394648558150202,54.636000852719803,-45.799248569806963,-45.632708172779992,-45.864970003173397,79.971736011633269,-8.1510240814364057,-75.967140476212549,-117.53522882691179,-118.91886899276567,-118.67124070593957,-118.28511588863765,-69.785335758087882,-19.832593830965063,76.858572032525274,79.814484355291086,-73.780612988273376,-88.790859570736046,40.960707110941961,-117.2636558424004,-114.86690604152426,-115.13994872824965,-116.43774549614136,-113.94612829238339,-115.99729327355199,-60.954846263250978,39.229310282980478,-42.676683476835734,20.601713659598378,51.738494931243714,87.633921544098598,47.885229299360567,19.650224133641959,-29.928661205743641,50.776795361457886,-43.932943346647079,19.88360911440628,85.004948601464989,-31.085796876497312,-67.971436190408994,83.978116164907377,-65.987580983678669,82.927862495960042,-32.237070848729537,-8.9932839831097624,81.768255371008095,46.234456136202688,-8.6461646846997109,-9.9806185466211339,-9.4961797997189556,-12.225563080636286,-10.080954725019943,23.176786486747794,-10.975139179895271,-11.984475672609458,-10.720610377162341,-10.766120952042719,-76.741672961617297,-76.862805114104944,-77.578192498060162,-74.306512184830453,-5.787882412448333,-3.5456489931618136,80.907791560284963,84.533054285423233,41.348374837445967,36.484788942993482,38.129704163428471,33.230998991677914,37.537915266346047,36.997482514671347,-114.26154507800582,71.857599219818709,-53.286951966637787,-5.8088449451110034,25.312697188142273,89.603556730889522,88.392933947181234,31.691779818843809,32.626579771311476,-88.042619923283993,-7.4366395159428844,34.731205518780492,-88.453486034864738,-87.429958858329741,-87.893569398191346,-64.091051521465417,-18.751588675696443,-62.373110289797111,-10.422076774598159,-61.055272783884647,-61.353912718966328,52.58127719675673,38.573338982794326,-57.600031061881673,-62.098143742209778,-62.047055813246132,20.24756249376285,21.995652859781956,-63.699599440143423,-63.665448312806141,-64.531072828989792,-11.234790481752642,-37.793567693452779,-27.36812855538744,16.750131709876268,90.188564822583785,85.255416993107232,106.99405297284929,-17.502925906761902,-68.31933769685341,-70.558479109776684,-69.548871738261184,-69.671461738709965,-68.727908014095064,19.176857982893136,-5.9835220219308818,-25.738712674050429,25.733818860839943,34.366114724713263,-74.017450507271491,-5.6636126353676959,-52.03485303842259,79.945567545794944,88.283416176356909,85.683978587523555,80.240408681874385,-19.082756405566418,-20.608932448669751,52.763480465475219,53.252582161662083,51.661620920756647,53.278702381753838,55.036134019896508,54.536799048696942,51.25526359792002,52.626765125122731,41.898515588553003,45.91833932930323,45.372817356232886,80.83773396764083,71.467348497061707,18.229728150000476,50.514885653803816,32.715098294942457,78.941886914168805,82.52561142356511,25.050889199353133,-7.6763775386640871,43.479993523285614,-12.94929840965734,-11.380722199983463,84.228529248682023,-45.121077060023389,84.25321976109079,81.315547532700336,90.808766154677571,79.41535354013601,85.054700359130976,87.570896598066653,75.944798779149025,49.830730080397991,83.043036472701019,82.434616438873363,82.452050077266492,-19.265112694489549,19.80294574433125,32.462792921158581,36.237689274860102,39.069641162266031,39.13280905817178,38.117300246806423,-78.143672974343616,33.258180125617322,32.880986181532549,38.95676359954485,41.333312824262769,36.850490602331355,31.047296352918991,80.399363295408307,-17.809948039471951,17.288870201104892,17.477874670452682,119.13321473023302,117.37549410385969,-12.065236004318727,106.13318287812598,120.78424455968974,84.272471378491588,93.944797606295126,116.13868659553523,118.46938279526721,88.022750909239605,-25.414858735954219,81.389207640754819,78.167367448644171,-6.8026058396203073,-9.2550040786113428,-9.0157709588767059,87.341559842185987,-25.113535969399283,-65.666943917583595,18.48788500270037,84.682734849560603,86.808275751176978,43.479610896654847,-61.654894508206077,-49.408814265688477,-49.224423194735657,-48.316422466702541,-52.477236772866313,-49.367596170658771,-48.648171834650022,-47.960239931631364,-48.937421978829867,-65.30578824842992,115.22155430127268,41.836946622611357,38.183922947263234,6.4809573450102516,5.822727733800054,-43.252369811497914,-38.422980624454567,-38.901033147254211,115.77120611497013,115.72255442359885,118.52220126604938,117.00140712017388,116.80526067656749,117.32255414696084,118.38914621455321,47.974439614389929,43.277852926722282,33.340775758626812,-60.128681455744434,84.144146815903923,-38.482548718600064,-13.090176049910724,-64.216444543978952,-24.587956158964751,-23.645776598238879,-23.168887139143393,-64.38769536856104,-65.159830699205401,-66.092849652207377,-66.160482844666603,-27.00050010473198,-26.318958526992692,-62.032384625572028,-58.928037165313633,46.923538391356118,36.913142622154339,39.671222257028077,49.037244799939437,95.303361894000176,53.654560281290756,-61.410575362799854,-62.127150849115893,72.758291912520548,38.37817605122558,82.989440186132384,112.53350831238117,-54.965980918619152,-10.588584913881192,-10.653397793162515,-63.477671097535044,-24.997197235418696,56.768316370788874,-60.336974898847579,24.834999268547303,50.110592094418479,41.518591334507207,-65.100924595742228,-46.734353705821981,44.306506779330057,47.013185515879911,-124.28700150460372,36.117599479042191,-66.169581460791377,-64.625633363482365,-68.573708005548482,-68.199503643647319,90.940741214334281,108.36334446941252,38.378704566520355,121.03081623744288,74.400159051803442,84.93736558484855,40.322981117918374,84.995389445692339,26.344755814086081,-62.600685053410707,-62.080983500543944,-64.016192831477341,-63.051554717392293,-65.773136325877871,-62.262628635656263,-64.114903550972073,-63.81599721209043,-65.304930521574832,-63.956943927097768,-62.188222508629295,-65.729585486686645,-64.04299332480015,-7.2497372957222703,-5.1784019536104093,36.020361342296503,-30.812719619060697,-14.494404948035632,79.894651066678847,82.067684896078148,72.331457496905486,79.036352952678939,-45.334311909650616,39.64150642968788,-25.338207259266802,101.13696184992948,-25.850164123040813,115.24037371074465,34.364564044104917,79.987674149458471,109.60034661651599,23.090296915617305,34.181389141148365,22.675063742429728,35.460653834075735],"z":[72.362806053920991,78.681649592625845,12.139019204476517,47.539851201109137,-99.509627951504243,-95.752637528517198,-97.273754230002496,-97.908476613272512,62.608572851595561,80.737401232824624,-14.282161302893011,-15.057652202445194,-10.702398264439838,-9.1971687925728851,-11.99044460414726,-13.624389706276968,-14.984612520133679,-14.450003002089009,-15.946023317264256,-11.774652866104264,-19.239400911447671,-13.272599767118464,-8.9350950438535044,-17.120770261942081,-16.936162909031751,-17.299336751357629,-15.893716296153418,-17.810512022142124,10.181543197196447,54.524245631253066,-8.7365093377991379,-3.3727313048125458,11.983220695964315,-6.306786221419026,-6.615409533957302,-6.9925473517348289,-6.8942134226196004,-7.8430657334887632,-70.65556752529578,82.001594587413038,32.767049898871498,-55.641210476678545,-57.059675308147455,7.9255273283367824,34.494702133594572,-6.8287695071431829,30.581205670977635,25.073848099495795,24.782600722860128,6.839610906055821,36.368017562087594,81.739730230731666,7.1790405076949684,-3.5120626638034969,31.427436619656969,36.64330177936656,36.369541744715924,4.535539509690099,79.703324854057442,2.1403605097538998,2.9709197667758969,4.450173850424477,-1.9129958450988909,-41.884639409409488,4.5630160753830591,36.357536607202427,8.6425551064787349,8.7078854560778645,9.8523372224864136,9.747558760360981,2.2387226411752335,2.7541335233571167,-27.126662442689394,-28.394664864299887,82.863934121449091,-28.424150574301603,6.1041595914740663,7.4154256096738287,5.1137987251602262,6.0770985420394199,7.9944885606101161,-86.986276809935859,10.756725027453122,10.554231342221856,12.972066850262914,-103.01925603381569,-38.113057669109601,-2.3578058510882012,82.568121352341507,-12.604875337909494,-13.094554203873782,7.9322157864830842,16.095120420324786,16.364541376961657,15.161173299767743,15.543867865709718,-10.937405211614543,-12.255187326990333,-48.684184316810182,-102.91469426939385,-99.913386740128573,-44.332513164780195,64.414630949554891,-0.47853894464147123,11.653360645345073,-3.0396113998140688,75.28819400415955,-2.9587161696530355,-16.878911663426528,-11.836565848114052,-12.172350460387069,9.6799467617251267,12.560128213017018,10.792960414750196,72.031469443455194,-92.948642625071685,0.56176465339391468,51.125428165047829,-42.38993508989698,81.675939714679046,-13.549838486117888,81.123508083297367,81.944378117379358,80.040844455709973,-99.801366957135443,69.332870934278816,17.662278082186461,13.86212927554285,-5.1822859460686299,-57.49637244031647,-55.314466369081728,-52.818924369898305,-55.161634012936339,-53.887776937997891,-56.169531645650636,-55.123318863929271,-53.467020622634955,-56.13984081252233,-51.114449724625203,-57.77275516849776,-56.064314406117767,-56.701513496224763,-4.5673168501286279,-103.28528555505154,-102.32706627736675,34.129723347245424,89.158318825080144,-98.39807428577906,-11.357253399994026,30.609804101790555,-53.483518739754452,32.483607133348073,-1.2105839966072593,-17.266776007884634,29.705846861637696,27.091383806777628,29.868191924484382,30.718182247750661,-13.862487398846179,7.5521951078113601,7.8985236114445048,-2.1236092063967686,-7.1895270221523342,-3.2245247962304888,-10.489679271038387,-105.72846510953516,-8.4554559948395198,-14.097344688575719,0.063309347007129868,-10.58151232153315,-3.3392145325096436,-8.4692520043462789,-40.574797582872492,-40.27592578493033,-39.710767471639443,-38.627004794469258,78.062629380258088,-96.538269934166891,-44.43904804008892,-99.337541110224308,10.600373075172755,65.935244714761595,-2.0375106442036692,-1.8510762604007103,38.02089066049686,67.6972651527106,66.36846389774351,5.0424898456121685,-101.38265459610358,-93.953285407933407,-98.928644105426613,-96.497540084877741,-8.4097372879928169,37.239969836805074,28.970450614273176,36.262545067169256,-4.5502169255844276,-43.100434587096593,0.077565216564152106,-42.389328033814294,9.9226902237143833,-1.3700927822702016,10.895955411047813,-53.457841371772091,36.732589949604403,-47.031317040999717,29.037327716414712,-106.11787227194303,15.443413255123936,-15.605495252774718,75.374982890972362,-7.3185897367865858,-29.197936767295122,26.866615011703221,-42.0770827121354,11.010022183986138,-8.3333062355450664,10.200792791711116,24.043246330939251,68.051253103464219,77.754986659648708,-15.773527991530075,-20.502195293838877,-1.5192123670618898,31.796264560072096,10.266845206884687,-1.4169324422239071,-3.1484872856622235,35.266698594239045,37.519987203691677,92.722139803020198,89.581487944761221,-52.712057030021477,92.787653208304377,91.174920141882325,87.483807105407621,16.16810263846509,17.544521583114609,17.554657957616438,9.9258006750094179,-94.580306061227972,-13.584472297112299,-57.06998149097214,-59.644343148364655,-55.590335892549014,-57.484494364003439,-11.815210802236548,63.072335174091933,10.500107447512518,9.5582285055160501,-13.605545052810601,2.8276758497863894,35.448886100994265,-57.900716807280148,-57.333101632294976,-55.554464329937964,-56.14549359398427,-55.450576862317618,-58.274419876272979,27.893162158734398,81.438976343504621,15.687904479808935,-3.4706629908509496,90.951814985394122,-42.50856603726259,65.89150481178504,0.24675199085330782,-11.844688057207538,38.467182525159487,34.556127732002061,-0.23620734485595427,-29.374731969842244,-11.61926774858218,24.468448693288611,-30.273325771955346,-15.944141268108694,10.255613093274521,-11.490976045051449,-104.39403293235615,10.581653889094932,65.124796841241618,-104.75795032089077,-107.42520845133274,-104.0483385064266,-106.29001490104207,-105.90358887632425,13.17450711735488,-104.5555002257923,-104.80447972370857,-105.34760021671879,-103.59867309616358,-11.45497467140912,-10.798535565235316,-9.5477827841757552,-10.111281907358034,-102.06340106940063,-99.720411568404856,10.824463901312768,-43.033746728588127,77.27580286096287,83.762874916536987,82.093210661658318,83.984769837281135,81.533820068351005,83.024316670082953,-60.374242929096802,24.626039163956833,22.897028457581918,-91.659505967279173,81.13827368971188,-41.48373776494671,-1.3192830468067263,-2.4679890992154001,-1.6843433864433381,3.8981201270568473,-106.67779761996991,78.485373440986734,1.9279008534333271,2.26641371566572,1.4912210974705247,38.485867473129503,64.137307264624425,-61.281820026668719,-107.5906022308794,-27.187845572541285,-27.976809411928773,90.18596302949561,81.292811423173461,30.216443478383535,30.77194521818739,28.716533224937731,67.279201899478622,0.87969995482814589,-27.565947234303795,-28.86673794619615,-28.18111588340204,-93.351950609784495,30.819963807223232,25.33634046734549,11.840421149279443,-4.4450090596235672,-8.0201407435308312,-39.164763000183981,63.668255949234592,-25.37790788935963,-25.870000341467261,-23.912537762582538,-24.914719833325925,-24.144951167808891,0.49985500326831178,-95.434313559782282,51.406977613220121,11.871412243561162,-49.053483577116488,-28.332492230242529,-104.60652585070655,24.04169739371655,9.4841161940216008,-43.712432603131163,-43.459536126512809,10.955921898471825,22.791402101039662,22.549263288861322,94.432413456783223,93.06572847339369,92.933779350453904,91.041362354705853,1.6902161798259876,88.494742092156088,90.64377752391637,88.316701107800469,36.787253921762911,64.080549233329421,63.688618901672577,9.0695945947429344,25.542591084134788,-0.73030604621167361,0.72470145249230178,80.305103967712256,15.123753184115774,12.543245385047701,14.715661935493635,21.915419029356201,82.144582039941568,-102.21835915108026,-100.90442997846942,8.6189979213895427,34.922937510657796,-32.351315854264882,-45.512859112607288,-40.204566824525934,-39.542590932185433,-41.909134152481322,-42.95204619748931,-42.787877705188905,60.488502798232204,-43.832602654818118,-39.821694749529534,-40.501841471961264,-12.299931647628906,70.258652932917272,84.347584845197673,83.570282231279307,80.435992381061467,76.820720320032464,78.980842488352025,78.958044256068732,77.341407578230132,77.759123121289363,77.698275011786961,81.389287681948389,78.232842472862657,77.577997438852194,6.3794633147034308,-96.023850736541064,72.926967803428212,71.728339833183469,-18.429708185312659,-16.608866849730497,-13.531198396830733,-41.027285798589659,10.160643750890427,-33.188430797509518,-4.5006911653374226,-17.602035855965728,-18.283881508171305,-41.175112812014625,47.667156601464789,-43.033308092820761,10.261544193236317,-97.798415744690885,-102.00855278393915,-101.82614722583226,-44.876692019120014,50.257951857275501,39.523182964735312,73.038444360260698,-41.530915407738497,8.5398674401915144,-6.9901972890976003,-15.685637847687229,26.773733465512993,26.301902505098202,27.113834501309658,24.226142799380487,27.604733280801458,51.640502446505138,51.087554555193613,51.363051844670068,40.17875717221753,-19.27116484966394,37.247187455396237,5.3561445167225212,3.923065485895068,4.0703482558334043,19.236403196810659,29.272623492511496,29.777923945278122,-15.080992679925659,-16.936802704453296,-20.39277740734261,-20.442187303286644,-18.910104972883488,-18.757746953631251,-19.242507216980052,1.6033563226049417,-11.418861920048867,83.02420154096329,29.810466220251968,-29.397167410333793,29.267390721264579,-104.06251271209399,5.1769929478865651,-12.470544839786681,-12.700565839616839,-12.750579128405137,-14.781306385279935,-13.885909889162095,-13.158091268559927,-14.852578742695295,48.770883718567333,48.885348649558779,29.35061174367684,28.126152101946833,-28.517242351013202,9.284366598721757,85.478100258554207,-12.660502080432694,30.703540550442725,36.656566649138462,-61.065308273168384,-61.22766793838273,23.454800695118173,8.7634402569284653,14.31620633158674,-18.2989172139442,28.283281616351562,-20.356519017125464,-19.634606522504082,32.292859472962277,46.412036713008192,-49.14411886298754,5.7495284660068213,80.813667964264098,-5.3750674071467097,44.158077333779644,-14.603298741016159,16.559124899240054,-29.233124316862959,64.011847630358332,-11.849331847829598,-1.9566012251305662,-12.242788427808367,-11.889781535471535,-11.924741694059174,-12.768192250928598,-3.5717781137523867,-38.762598176610702,54.556872752328097,8.6517104985321236,31.69936279276477,-30.441345770272431,78.675093985864549,-7.5842013542848656,-1.8040913831773429,39.619317667784394,43.04991654676968,42.788278757599834,44.090147113973636,42.117856845440734,40.962225497035909,40.724809239325481,42.486804172441445,44.080102961645387,41.323542805640407,41.904823168266624,42.300091088464477,44.302813941752902,45.736616796631239,-100.6476851972857,-5.2867216604577605,-11.959681372252517,-14.336603328715322,10.306469688751683,10.034952400630662,23.290256918975242,16.33217759804446,36.720393689991539,34.705513372136899,49.435216303910224,30.000127707754814,49.775584292539378,-20.497265616886629,5.3859816226359021,-44.324201756445447,-15.801481230519355,-4.0506195678826558,7.3474004124357251,-4.8358774267588558,7.036104626617214],"text":["Input: 'ab seaman' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'address printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'aereated water vanman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'afinador' (lang: ca)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'aftaegtsmand vejmand' (lang: da)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural laborer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'agricultural worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ancien ouvrier et aide' (lang: fr)<br />HISCO: 99930, Description: Factory Worker","Input: 'apprentice printer feeder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'arbeider en not mentioned in source' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeider i gaarden deres aegte born' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidskarl' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand husfader' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeidsmand husfader deres dottre' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeijder en not mentioned in source' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdende par' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejderske' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand husejer' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand indsidder' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbejdsmand logerende' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetare' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetaredotter' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetarehustru' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbeterska' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'arbetskarl' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'army cap maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'artisan' (lang: en)<br />HISCO: 95920, Description: Building Maintenance Man","Input: 'assist in dining rooms' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assist with dressmaking' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assistant in coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'assistant varman in business o' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in business as carri' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in the fried fish sh' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assisting in yell business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'assists in business t s' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'attends to the horses' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'automatic machnine operator' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'baadforer' (lang: da)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'backstuguhjon' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'backstugusittare' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'ballie girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'bargeman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'barmaid help in business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'barn niels nielsen somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'basket maker' (lang: en)<br />HISCO: 94220, Description: Basket Maker","Input: 'basket maker' (lang: unk)<br />HISCO: 94220, Description: Basket Maker","Input: 'basket maker sub manager' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'belt mkr rubber works' (lang: unk)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'bioscope operator co' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'blank tray maker master' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'boarder journeyman' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'boat loader' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'boatman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'boatman (deceased)' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'boeckbinder en not mentioned in source' (lang: nl)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'boekdrukker en not mentioned in source' (lang: nl)<br />HISCO: 92110, Description: Printer, General","Input: 'bogbindersvend' (lang: da)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'bokbindarelaerling' (lang: se)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'book binder' (lang: en)<br />HISCO: 92625, Description: Bookbinder (Hand or Machine)","Input: 'boot fitter factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'boot porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'borstelmaker' (lang: nl)<br />HISCO: 94230, Description: Brush Maker (Hand)","Input: 'bottler' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'brakeman' (lang: unk)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brakeman m e r' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brakes man' (lang: unk)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'brass casters warehouse woman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'brewers drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'brewers dreyman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'bricklayer' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'bricksetter' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'bronzing at printing works' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'brunnenbauer' (lang: ge)<br />HISCO: 95955, Description: Well Digger","Input: 'brush boxer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush drwing hand' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush maker boarder' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush mastud' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brush trade out of work' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'brushmaker bour' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'builder' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builder (dec)' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builder architect' (lang: en)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'builders labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cabinet porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'cabman' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'calico printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'car-man' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carman at mill' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'carpenter' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter (decd)' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter - deceased' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carpenter and joiner' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'carrier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'carter' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'casual worker and pauper' (lang: en)<br />HISCO: 99920, Description: DayLabourer","Input: 'cement labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cement worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'chargeur de voitures' (lang: fr)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'chemical worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'clay tobbacco piper maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'clerk mineral water manufactor' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'co co motor engine driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'coa minder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'coach man' (lang: unk)<br />HISCO: 98530, Description: Taxi Driver","Input: 'coach owner' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coachman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coachman (dead)' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'coal haulier for houses' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'coal seller and carter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'coal trimmer shipping porter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'coast guard' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'coke burner' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'comb maker polisher' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'coml clerk printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'commissionare porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'compositor' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'conducteur de messageries' (lang: fr)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'conijositer printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'copper plate printer app' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'copper printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'corporation labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'cotton operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'cotton warehouse' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'couch liner seater' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'craine driver frodingham' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'dagkarl' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleier almissenydende' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleierafskediget soldat fra westindienhendes barn' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer husbond' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglejer inderste' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleyer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagleyer barn' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagloenare' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'daglonner' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'dagsverkskarl' (lang: se)<br />HISCO: 99920, Description: DayLabourer","Input: 'dealer in horses and haulier g' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'deceased labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deceased plate layer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deceased seaman' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'decorator house ship' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'demolition worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'deres barn i laere' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'deres born do somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'deres son dagleier i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'deres son seiler' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'device maker for watermarking' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'disse personer ernaerer sig ved forskellige arbejder' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'dock board scavanger' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock hobbler trimming coals' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock labour stevedore' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'dock labr ston stower' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'driver' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'driver a.s.c.' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'driver draymen general' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'driver hired vehicles' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'driver of omnibus coach nd' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'droskaegare och handelslaegenhetsaegare' (lang: se)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'dyer's labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'eating driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'eldare' (lang: se)<br />HISCO: 96930, Description: Boiler Fireman","Input: 'embraiderer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'employed in the receiver print' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'engaged in berlin and fancy bu' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'engaged in classical general' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'engine driver' (lang: en)<br />HISCO: 98320, Description: Railway Engine Driver","Input: 'engine tender' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engine tenter' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engine-driver' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'engraver' (lang: en)<br />HISCO: 92400, Description: Printing Engraver, Specialisation Unknown (except PhotoEngraver)","Input: 'estate worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ex railway porter pensioner' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'excavator' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'expressarbetare' (lang: se)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'fabricant de jochs de cartas' (lang: ca)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'factory hand firework factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory handboots shoe stamped' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory knitting' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'factory operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'factory realer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'fan turner' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'farm labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farm servant' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farm worker' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'farming man' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'fencemaker' (lang: en)<br />HISCO: 95990, Description: Other Construction Workers","Input: 'fireman' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'fireman new dock' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'fireman railroad engineer' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'flaxter' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'flower market porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'fobber in the factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'formerly a cheesemonger porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'formerly cash girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'funiture business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'furniture remdon and coal cart' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'gaar i dagleie hans kone' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'gas stoker' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'gatekeeper' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'gearer dock labourer' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'general labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'general worker (retired)' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'gerkman' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'gill boxes minder' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'glass slopper maker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'glass worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'glazier' (lang: en)<br />HISCO: 95720, Description: Building Glazier","Input: 'goods department grocer porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'greacer in coal hashery' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'grrvarb' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'hammer man dock' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'handyman decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'hans larsens kone' (lang: da)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'haulier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'haulier and smallholder' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'hauliers horse driver' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'hendes son somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'hitcher coalmine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'hoornbreker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'horse driver wag wks' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'hose pipe machine rubber hand' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'hosiery hand labourer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'house decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house decorator employ absen' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house maid visiting house' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house painter 5 man 5 boys' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'house rents and funds' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'huijstimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'huistimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'huistimmermansgezel en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'hurrior in coal pit' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'husbandman' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'husfader arbejdsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'husfader dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader huslejer daglejer i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader inderste dagleier i agerbrug' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'husfader indsidder dagleier i agerbruget husfader indsidder dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'huslig arbejde' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'husmoder fabriksarbejderske' (lang: da)<br />HISCO: 99930, Description: Factory Worker","Input: 'in table knife warehouse' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'inclineman coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'inderste og arbeidsmand' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'inderste og maler' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'india rubber factory operative' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'inds og dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder daglejer' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidder daglejer i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsidderske daglejerske' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'indsider dagleier i agerbruget indsider dagleier i agerbruget' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'inrolleret matros hendes born' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'jobbing printer apprentice' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'joiner' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'journeyman' (lang: unk)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'journeyman house painter pap' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'junr porter railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'kaartenmaker en not mentioned in source' (lang: nl)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'kammenmaker' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'karmansknegt' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'kiln fireman (deceased)' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'knecht veer en not mentioned in source' (lang: nl)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'knopemaker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'koorndrager en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'kopparkoerare' (lang: se)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'korbmacherbursche' (lang: de)<br />HISCO: 94220, Description: Basket Maker","Input: 'korendrager' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'kronoarbetskarl' (lang: se)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'kruier en not mentioned in source' (lang: nl)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'kudsk' (lang: da)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'lab' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lab about coal pitts' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'label puncher painters' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'laborer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer ( dec )' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer (deceased)' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer ?' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer and parish clerk' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer deceased' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labourer, deceased' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labr' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'labr.' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'laere draenge tieniste folk' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laeredreng' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laeredrenge' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'laerling' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'lamp lighter' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lantaarnbediende' (lang: nl)<br />HISCO: 99910, Description: Labourer","Input: 'lasher on coal mine u g' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'laundrymans porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'leerling drukker bij een stadsdrukkerij' (lang: nl)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press machine minister' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press machine printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letter press printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'letter press printer compr ap' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'letterpres painter machine min' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'lever af sin jordplet og dagleier' (lang: da)<br />HISCO: 99920, Description: DayLabourer","Input: 'lichterman en not mentioned in source' (lang: nl)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'lichtm kd' (lang: nl)<br />HISCO: 98140, Description: Ordinary Seaman","Input: 'lime burner' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'lithographic printer' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'loader at railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'lorry driver' (lang: en)<br />HISCO: 98555, Description: Lorry and Van Driver (Local or LongDistance Transport)","Input: 'lucifer match packer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'm factory' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'maalaregesaell' (lang: se)<br />HISCO: 93120, Description: Building Painter","Input: 'machine labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'machines printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'malerm adolph' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'malermester' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'malersvend' (lang: da)<br />HISCO: 93120, Description: Building Painter","Input: 'mariner' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'maskinarbejder' (lang: da)<br />HISCO: 99930, Description: Factory Worker","Input: 'mason' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'mason's labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'master bricklayer' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'master bricksetter' (lang: en)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'master painter employg 1 boy' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'master printer employing 2 boy' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'matroos zm linieschip de zeeuw' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'matros' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'matros 3 division 5 compagnie logerer' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'maufacturing operative' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'metal button closer' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'metselaar' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'metselaer en not mentioned in source' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'metselaergesel en not mentioned in source' (lang: nl)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'miller' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'millwright' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'modderman en not mentioned in source' (lang: nl)<br />HISCO: 97435, Description: Dredge Operator","Input: 'molenmaker en not mentioned in source' (lang: nl)<br />HISCO: 95910, Description: Housebuilder, General","Input: 'moter can driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'motor driver chauffer and mech' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'motorman' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'munition worker' (lang: en)<br />HISCO: 99930, Description: Factory Worker","Input: 'muraremaestare' (lang: se)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'murer' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'murermester husbond' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'muurermester' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'muurmester' (lang: da)<br />HISCO: 95120, Description: Bricklayer (Construction)","Input: 'naaldenmaker' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'navvy' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'needle maker' (lang: en)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'needle maker 4 men employs' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'net repairer and other fisherm' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'ofensetzer' (lang: ge)<br />HISCO: 95130, Description: Firebrick Layer","Input: 'opperman en not mentioned in source' (lang: nl)<br />HISCO: 99910, Description: Labourer","Input: 'oppertimmerman fregat de rhijn' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'opticians warehouse girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'out porter ry station' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'outside porter rly stn' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'over cooker coal mine' (lang: en)<br />HISCO: 98590, Description: Other MotorVehicle Drivers","Input: 'packer' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'packer en not mentioned in source' (lang: nl)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and decorator' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and glazier' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter and house papering' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter at machine manufacturi' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter master employing 1 man' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter musician' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'painter paperhanger c' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'pan with rubber works' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'paper' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'paperworks' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'parcel vanman to ry co carter' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'parkvakt' (lang: se)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'paruijkmaker en not mentioned in source' (lang: nl)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'patent picklt fork warehouse g' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'patterncalico printer' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'pawnbrokers warehouse man' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'pier head gateman' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'plane server' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'plasterer' (lang: en)<br />HISCO: 95510, Description: Plasterer, General","Input: 'plate engraver' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'plate-layer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'platelayer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'poem girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'pontman en not mentioned in source' (lang: nl)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'porter' (lang: en)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'porter cavent garden' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter goods railway' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter mill' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter railway agent carriers' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter rl wy' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter st bartholomews hos' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter to painter' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'porter upper arcade' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter wollen marehouse' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'porter woolen trimming wareh' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'postilion' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'preventative service' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'printer' (lang: unk)<br />HISCO: 92110, Description: Printer, General","Input: 'printer books seller' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and bookbinder of scho' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and publisher employin' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer and stationary' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer canvasser' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer checker' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer evans and adlards' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printer plasterer stone mas' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'printer proofreader' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'printers' assistant' (lang: en)<br />HISCO: 92990, Description: Other Printers and Related Workers","Input: 'public carrier' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'publieke werken' (lang: nl)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'r. n' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'r.n.' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'railwa signalman' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway coys shunter' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway drayman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'railway engine driver' (lang: en)<br />HISCO: 98320, Description: Railway Engine Driver","Input: 'railway guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'railway porter' (lang: en)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'railway shunter horse driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'railway shunter l and s w r' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway signaler' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'railway work porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'rapieceuse et bacheliere' (lang: fr)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'refreshment contractors porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'removal estimater' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'road labourer and house proprietor' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'road mender' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'roadman' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'ry porter hadley station' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'safe maker' (lang: en)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'sailor' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'sailor r.n.' (lang: en)<br />HISCO: 98130, Description: Able Seaman","Input: 'sailors home porter' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'sasool girl' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'sawyers labourn house burder p' (lang: en)<br />HISCO: 93120, Description: Building Painter","Input: 'schaalmeester bij de spooorwegen' (lang: nl)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'scheepstimmergesel en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheepstimmergezel en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheepstimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheeptimknecht' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'scheeptimmerman en not mentioned in source' (lang: nl)<br />HISCO: 95455, Description: Ship's Carpenter","Input: 'schuijtevoerdr en not mentioned in source' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'schuitenvoerder' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'schuitenvoerder en not mentioned in source' (lang: nl)<br />HISCO: 98690, Description: Other Animal and AnimalDrawn Vehicle Drivers","Input: 'seaman' (lang: en)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'seinhuiswachter bij de ns' (lang: nl)<br />HISCO: 98430, Description: Railway Signaller","Input: 'sewer india rubr works' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'sheet metal work manufacturer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'shell stamping' (lang: en)<br />HISCO: 94920, Description: Taxidermist","Input: 'shell turner arsl' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'ships carpenter' (lang: en)<br />HISCO: 95410, Description: Carpenter, General","Input: 'shipwright' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'shipwt' (lang: en)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'shunter in goods yarder' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'shunter royal alleret dk' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman g n rly' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman l and y' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman l y railway' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signalman landnwry' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signature' (lang: en)<br />HISCO: 98430, Description: Railway Signaller","Input: 'signwriter' (lang: en)<br />HISCO: 93950, Description: Sign Painter","Input: 'silk printer' (lang: en)<br />HISCO: 92950, Description: Textile Printer","Input: 'sjoeman' (lang: se)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'sjouwer en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'skibsbygger' (lang: da)<br />HISCO: 95440, Description: Wood Shipwright","Input: 'skilled labourer' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'slater' (lang: en)<br />HISCO: 95320, Description: Slate and Tile Roofer","Input: 'sleeper' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'sleeper en not mentioned in source' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'sleper en not mentioned in source' (lang: nl)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'snickare' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickareaenka' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickaredotter' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snickaregesaell' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'snijder' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'snijdersgezel en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'soeen' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'somand' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'spade moulder' (lang: en)<br />HISCO: 99910, Description: Labourer","Input: 'starw plait importer' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'steel heater plate mills' (lang: en)<br />HISCO: 92110, Description: Printer, General","Input: 'sterroty pen' (lang: en)<br />HISCO: 92300, Description: Stereotypers and Electrotypers","Input: 'stevedore' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'stoker' (lang: en)<br />HISCO: 98330, Description: Railway SteamEngine Fireman","Input: 'stone cutter' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'stone mason' (lang: en)<br />HISCO: 95145, Description: Marble Setter","Input: 'storeman' (lang: en)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'straw bont maker' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'superld dock gate man' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'switchman' (lang: unk)<br />HISCO: 98440, Description: Railway Shunter","Input: 'syndicus bij de ommelanden' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'teamer' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'teamman' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'teglverksejer' (lang: da)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'tendeur' (lang: fr)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'text factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'thatcher' (lang: en)<br />HISCO: 95360, Description: Roof Thatcher","Input: 'theatrical operator' (lang: en)<br />HISCO: 92120, Description: Hand Compositor","Input: 'threader on embroidery m achin' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'tile packer' (lang: en)<br />HISCO: 97152, Description: Packer, Hand or Machine","Input: 'timmerkarl' (lang: se)<br />HISCO: 95410, Description: Carpenter, General","Input: 'timmerman en not mentioned in source' (lang: nl)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tin vanisher maker' (lang: en)<br />HISCO: 94190, Description: Other Musical Instrument Makers and Tuners","Input: 'tinned food labeller' (lang: en)<br />HISCO: 91090, Description: Other Paper and Paperboard Products Makers","Input: 'tjenestekarl' (lang: da)<br />HISCO: 99900, Description: Worker, No Further Information","Input: 'tobbaco soiiner' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'tommermand' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tommermand ved holmen mand' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tommersvend' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tomrersvend' (lang: da)<br />HISCO: 95410, Description: Carpenter, General","Input: 'tractian engin driver' (lang: en)<br />HISCO: 98540, Description: Motor Bus Driver","Input: 'tractor driver' (lang: en)<br />HISCO: 96910, Description: Stationary Engine Operator, General","Input: 'tradesman' (lang: en)<br />HISCO: 95920, Description: Building Maintenance Man","Input: 'train guard' (lang: en)<br />HISCO: 98420, Description: Railway Brakeman (Freight Train)","Input: 'truck checker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'turfdrager en not mentioned in source' (lang: nl)<br />HISCO: 97125, Description: Loader of Ship, Truck, Wagon or Airplane","Input: 'typograf' (lang: se)<br />HISCO: 92110, Description: Printer, General","Input: 'tyrefitter in motor cab trade' (lang: en)<br />HISCO: 98530, Description: Taxi Driver","Input: 'unimployed factory hand' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'vaerentgesel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'vaerentgeselle en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendgesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendgeselle en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varendghesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensgezel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensgezel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensman' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varensman en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentgesel' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentgesel en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentman' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'varentman en not mentioned in source' (lang: nl)<br />HISCO: 98135, Description: Seaman, Able or Ordinary","Input: 'vattenledningsarbetare' (lang: se)<br />HISCO: 96940, Description: PumpingStation Operator","Input: 'veimand' (lang: da)<br />HISCO: 99910, Description: Labourer","Input: 'violin string maker journeyman' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'vognmand' (lang: da)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'waggoner' (lang: en)<br />HISCO: 98620, Description: AnimalDrawn Vehicle Driver (Road)","Input: 'warehouse woman factors' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'warehouse woman iron money' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'warehouseman' (lang: en)<br />HISCO: 97145, Description: Warehouse Porter","Input: 'warehouseman general' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'waterman' (lang: en)<br />HISCO: 98190, Description: Other Ships' Deck Ratings, Barge Crews and Boatmen","Input: 'waterproof van cover and sheet' (lang: en)<br />HISCO: 90100, Description: Rubber Product Maker, Specialisation Unknown","Input: 'waterscheepsman en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'wharf ringer' (lang: en)<br />HISCO: 97120, Description: Docker","Input: 'wisselaers en not mentioned in source' (lang: nl)<br />HISCO: 99999, Description: Unspecified worktitle or several titles","Input: 'wisslwachter' (lang: nl)<br />HISCO: 98430, Description: Railway Signaller","Input: 'withey stripping' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers","Input: 'wool porter grocer' (lang: en)<br />HISCO: 97130, Description: Railway and Road Vehicle Loader","Input: 'work for grain dealer' (lang: en)<br />HISCO: 97190, Description: Other Dockers and Freight Handlers","Input: 'worker assistant business' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'works as a patentmaker' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'works in globe mnfg' (lang: en)<br />HISCO: 94990, Description: Other Production and Related Workers Not Elsewhere Classified","Input: 'workstraw' (lang: en)<br />HISCO: 94290, Description: Other Basketry Weavers and Brush Makers"],"mode":"markers","marker":{"color":"rgba(179,179,179,1)","opacity":0.69999999999999996,"line":{"color":"rgba(179,179,179,1)"}},"type":"scatter3d","name":"9","textfont":{"color":"rgba(179,179,179,1)"},"error_y":{"color":"rgba(179,179,179,1)"},"error_x":{"color":"rgba(179,179,179,1)"},"line":{"color":"rgba(179,179,179,1)"},"frame":null}],"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.20000000000000001,"selected":{"opacity":1},"debounce":0},"shinyEvents":["plotly_hover","plotly_click","plotly_selected","plotly_relayout","plotly_brushed","plotly_brushing","plotly_clickannotation","plotly_doubleclick","plotly_deselect","plotly_afterplot","plotly_sunburstclick"],"base_url":"https://plot.ly"},"evals":[],"jsHooks":[]}</script> ] ] ] --- # Introduction .pull-left[ ### Motivation - Manual labelling of data is tedious, expensive and error-prone - We collectively poor thousands of hours into similar work - 4 mil. `\(\rightarrow\)` 96k `\(\rightarrow\)` 605 days of work ### This presentation - **Automatic tool to make HISCO labels** - 98 percent precision - How it is done `\(\rightarrow\)` ongoing updates ] .pull-right[  *Willam Bell Scott (1861) "Iron and Coal" (Wikimedia)* ] --- # HISCO codes - Derived from ISCO (International Standard Classification of Occupations) - Invented for the sake of international comparability - Introduced by Leuwen, Maas, Miles (2002) based on ISCO68 - Hiearchical structure well suited for analysis - Common application: Convert to ranking (HISCAM, HISCLASS, etc. ) - Usually labelled with 'smart' manual methods  --- # Data example <div class="datatables html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-b8cff0b60907d67fdaf9" style="width:100%;height:auto;"></div> <script type="application/json" data-for="htmlwidget-b8cff0b60907d67fdaf9">{"x":{"filter":"none","vertical":false,"fillContainer":false,"data":[["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31","32","33","34","35","36","37","38","39","40","41","42","43","44","45","46","47","48","49","50","51","52","53","54","55","56","57","58","59","60","61","62","63","64","65","66","67","68","69","70","71","72","73","74","75","76","77","78","79","80","81","82","83","84","85","86","87","88","89","90","91","92","93","94","95","96","97","98","99","100","101","102","103","104","105","106","107","108","109","110","111","112","113","114","115","116","117","118","119","120","121","122","123","124","125","126","127","128","129","130","131","132","133","134","135","136","137","138","139","140","141","142","143","144","145","146","147","148","149","150","151","152","153","154","155","156","157","158","159","160","161","162","163","164","165","166","167","168","169","170","171","172","173","174","175","176","177","178","179","180","181","182","183","184","185","186","187","188","189","190","191","192","193","194","195","196","197","198","199","200","201","202","203","204","205","206","207","208","209","210","211","212","213","214","215","216","217","218","219","220","221","222","223","224","225","226","227","228","229","230","231","232","233","234","235","236","237","238","239","240","241","242","243","244","245","246","247","248","249","250","251","252","253","254","255","256","257","258","259","260","261","262","263","264","265","266","267","268","269","270","271","272","273","274","275","276","277","278","279","280","281","282","283","284","285","286","287","288","289","290","291","292","293","294","295","296","297","298","299","300","301","302","303","304","305","306","307","308","309","310","311","312","313","314","315","316","317","318","319","320","321","322","323","324","325","326","327","328","329","330","331","332","333","334","335","336","337","338","339","340","341","342","343","344","345","346","347","348","349","350","351"],["61110","99910","73210","97145","14120","33940","95120","58330","75135","72500","30000","92400","71105","77610","87105","99910","41025","79100","81120","71300","98620","95410","83320","98135","43220","98620","2000","99910","98620","84900","58340","80110","62490","83915","95120","71105","13020","83990","89210","22000","84100","72725","72500","75400","99999","58320","95320","62120","14120","33110","31000","98320","95410","99910","83110","62490","64100","98620","44140","51050","75400","88010","-1","96910","51050","21110","87340","95145","97145","97120","93120","72500","95510","77810","72500","77610","61115","84100","80110","93120","76145","99910","44120","21000","51020","98190","83110","83110","58300","95440","99910","99910","33110","72890","75220","22610","96910","98190","79920","95910","87340","98620","98190","2120","41030","72100","41030","83930","17000","81925","21000","80110","41025","71105","89242","41030","87340","98190","80110","98620","30000","59990","72190","61115","21110","81920","83530","61115","74490","58220","77660","99910","61110","99910","83110","99910","31000","85700","62700","98320","6100","92625","98130","89242","21220","43220","41025","87330","33110","58320","98320","71300","58340","83110","81120","72000","14120","22610","39960","95410","95440","41030","41030","39140","64990","83110","83110","75000","72100","98620","62490","99930","51020","1390","83590","41030","98130","57025","22520","22000","4215","2305","30000","75220","13020","41025","72500","84100","13020","41025","95145","93120","83110","98555","87350","83990","77120","22520","61115","75220","80310","87340","62430","41030","99910","80320","41030","95410","41040","45220","75220","79990","21240","87105","22620","95510","87400","62740","75220","98420","71105","62120","73210","89320","99930","22000","61110","83590","6510","43200","95120","55100","95120","87462","83990","87210","99910","80110","79100","80110","80110","87120","43200","61110","99910","58300","92950","7530","31000","83110","30000","51050","71105","45220","99930","96910","30000","75600","98620","99930","83920","-1","61115","80320","89242","99999","14120","95145","77120","41030","97125","22220","98430","89156","83990","14120","3110","58340","80110","99910","95410","92950","83110","72500","21240","33135","79620","14120","99930","75000","72500","21000","83590","21240","61110","22610","84220","93120","41025","41025","72500","58330","64990","83590","64990","62460","45125","33940","98590","12410","73400","41025","51050","80110","63220","81120","22000","97120","77310","98420","97125","95920","71110","99910","98590","89320","79310","51050","75400","55240","87105","75000","58330","87105","54090","79100","22000","98330","22000","41025","93120","83590","97152","80110","75622","99910","44320","21000","58340","79475","41030"],["farmer","labourer","sawyer","warehouseman","vicar of harpford","bank clerk","bricklayer","sergeant r.e.","carder","iron moulder","clerk in an office","engraver","miner","baker","plumber hm dockyard","miller","provision dealer","tailor","cabinet maker","mechanical driller","carrier","carpenter","turner","mariner","commercial traveller","carman","engineer","workman","carter","mechanic","soldier","boot and shoe maker","drover","cutler","brick setter","collier","school master","horsenailer","potter","overlooker","engineer","wire drawer","butcher","weaver","match maker","major general, rha, retired","slater","servant","wesleyan minister","bookkeeper","warder","railway shunter","joiner","farm labourer","blacksmith","groom","fisherman","carter (deceased)","shipbroker","publican","ribbon weaver","jeweller","retired","engine driver","licensed victualler","cotton manufacturer","tin plate worker","mason","storeman","dock laborer","painter","caster","plaisterer","maltster","iron worker","baker (deceased)","cottager","fitter","shoemaker","painter and glazier","tanner","plate layer","insurance agent","works manager","inn keeper","lighterman","blacksmith deceased","chain maker","h. m. f.","shipwright","agric labr","labourer (deceased)","book keeper","tank plater","spinner","foreman","crane driver","boatman","sailmaker","builder","tinner","lurryman","water man","architect","grocer","roller","pharmaceutical chemist","lockmaker","potter","wheelwright","manager","shoe finisher","iron merchant","pitman","brick maker","greengrocer","tinker","waterman","shoe maker","coachman (deceased)","clerk","bill poster","puddler","yeoman","linen manufacturer","motor body trimmer","grinder","crofter","tin smelter","police constable","confectioner","delver","farmer (deceased)","laborer","forge man","porter and labour master","higher executive officer, department of industry","linesman","gardener","railway driver","surgeon","book binder","h.m's navy","brickmaker","lead smelter","traveller","china dealer","coppersmith","accountant","pilot","engine driver lwer","driller h.m. dockyard","army pensioner","file maker","cabinetmaker","foundryman","clerk (deceased)","agricultual foreman","railway servant","ship carpenter","millwright","draper","clothier","stock taker","keeper","smith","farrier","cotton operative","steelworker","coachman","trainer retired","cotton operative","innkeeper","scientist","gun lockfiler","poulterer","naval pensioner","hair dresser","bailiff","gane intake manager","master mariner","electrician","clerk in warehouse","cotton spinner","school teacher","merchant","core maker","engine fitter","schoolmaster","dealer","stonemason","decorator","shoeing smith","lorry driver","boiler maker","nail master","miller","farm bailiff","little farmer","twine spinner","leather cutter","whitesmith","shepherd","iron-monger","farm worker","harness maker","silk mercer","carpenter, joiner","garage proprieter","hawker","selfactor minder","trimmer","railway contractor","plumber","mine agent","plasterer","chassis erector","groom and gardener","carpet yarn spinner","guard","miner (deceased)","gentleman's servant","mill sawyer","furnaceman","woollen dresser","railway inspector","retired farmer","polisher","veterinary surgeon","coal agent","brick layer","house steward","brck layera","rivet maker","nailor","welder","builder's labourer","bootmaker","tailor (deceased)","boot finisher","boot maker","gas fitter","mine agent","farmer and publican","labourer - deceased","rm","cal:printer","optician","inland revenue","locksmith","auctioneer's assistant","licenced victualler","retired miner","pedlar","piecer","transport driver","civil servant","dresser","coach man","process worker","gun maker","dead","yeoman and relieving officer","saddler","brick burner","bottle maker","clerk in holy orders","stone cutter","corn miller","shopkeeper","porter","post master (deceased)","signalman on railway","glass cutter","nailer","baptist minister","draughtsman","private machine gun corps","boot closer","agricultural worker","pit carpenter","pressman","boiler smith","moulder","sub-contractor on the railway","cashier","upholsterer","clerk in holy orders, chaplain to the hon. east india company","maker up","twiner","brass founder","company director","electro plate polisher","contractor","farmer?","head gardener","watchmaker","decorator and contractor","timber merchant","fruit dealer","brassfounder","ship's corporal rn","game keeper","brass finisher","gamekeeper","ostler","potseller","banker's clerk","driver","solicitor","paper maker","waste dealer","publican (dec)","cordwainer","woodcutter","chair maker","plant supervisor","stevedore","butcher","railway guard","corn porter","tradesman","quarryman","corn miller","coach driver","furnace man","hatter, deceased","publican (deceased)","power loom weaver","steeple jack","plumber and glazier","loomer in cotton mill","sergeant r.g.a.","master plumber","footman","tailors assistant","sanitary inspector","fireman","underground manager","coal merchant","house decorator","bobber and polisher","hydraulic packer","clicker","dyer","farm servant","auctioneer","manager, iron works","gunner, royal artillery","glover","pharmacist"]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>hisco_1<\/th>\n <th>occ1<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"pageLength":8,"columnDefs":[{"orderable":false,"targets":0}],"order":[],"autoWidth":false,"orderClasses":false,"lengthMenu":[8,10,25,50,100]}},"evals":[],"jsHooks":[]}</script> --- .pull-left[ ## The naive solution - List all unique occupational descriptions and label them e.g. "farm servant: 62120" - Label via lookup table ## The challenge - 17865 different occupational descriptions fit with "farm servant" in DK censuses ("in service", "servant girl", "servant boy", "servant woman", "servant karl") - HISCO has ~2000 occupational classes, each with similar complexity in writing - Spelling mistakes, **negations**, and different spelling conventions ] -- .pull-right[ ## The solution  - Use machine learning! - Multi-label multiple classification - Trivial machine learning problem - Apply tricks from the machine learning literature to improve performance on unseen examples ] --- .pull-left[ ## The tricks - Unseen test and validation data - LSTM reccurent: Reads with memory "lives of fishing and farm work" (Hochreiter, Schmidhuber, 1997) - Overparameterized neural network: More parameters than data (Allen-Zhu, Li, Liang, 2018) - Regularization via dropout: Some neurons are randomly disabled in training (Srivastava et al 2014) - Embedding: Represent language in high-dimensional space (Mandelbaum, 2016) - Data augmentation (Moris et al, 2020): + "farmer": {"farmtr", "fermer", "yellow farmer"} ] .pull-right[ **Overfitting**  (Wikimedia) ### Metrics - Accuracy - Precision - Recall - F1 - Micro- and macro-level - In training: Binary cross-entropy (differentiable) ] --- # Data sources ### Used today: | Source | Lang | Observations | Reference | |------------------|----------------------------| | Danish census | Da | 4,673,892 | Clausen (2015) | | UK Mariage certificates | En | 4,046,387 | Clark, Cummins, Curtis (2022) | | DK Ørsted | Da | 36,608 | Ford (2023) | | HSN | Nl | 13,495 | Mandemakers et al (2020) | | SE Chalmers | Sw | 14,426 | Ford (2023) | - But also much more in the pipeline. ~70gb -- - *Adequate performance down to 10.000 labels* -- - **Amazing performance in millions of observations** --- # What is other data? .pull-left[ ### Other data - Swedish census data - Norwegian census data - Dutch family history data - Labelled biographies - IPUMS - Barcelona Historical Marriage Database - ~70GB ] .pull-right[ ### Call for data! - If you have something with HISCO labels on it, please send it to christian-vs@sam.sdu.dk. I owe you HISCO codes ] --- # The architecture  ### Training - Model starts at random state - Continuously tweaked towards more correct predictions ### Ongoing work - Replacing the brains by a multilingual transformer model (XML-RoBERTa) *akin to a chatGPT-frankenstein* --- # Training  ### Stopping condition - When validation loss has not improved for 10 epochs training stops --- # The product ```r # Example prompts string_to_hisco("A farmer") string_to_hisco("Tailor of beautiful dresses") string_to_hisco("The train's fireman") ``` -- ``` ## string hisco description ## 1 A farmer 61110 General Farmer ## 2 Tailor of beautiful dresses 79100 Tailor, Specialisation Unknown ## 3 The train's fireman 98330 Railway SteamEngine Fireman ``` --- # The performance (1/5) *DK data based on 300.000 validation observations* ### Macro level performance |level | recall| precision| f1| |:-----|---------:|---------:|---------:| |macro | 0.9707673| 0.9805047| 0.9755535| -- ### Micro level |level | recall| precision| f1| |:-----|---------:|---------:|---------:| |micro | 0.8228573| 0.9100653| 0.8989688| --- # The performance (2/5)  --- # The performance (2/5)  --- # The performance (2/5)  --- # The performance (3/5): Confusion matrix 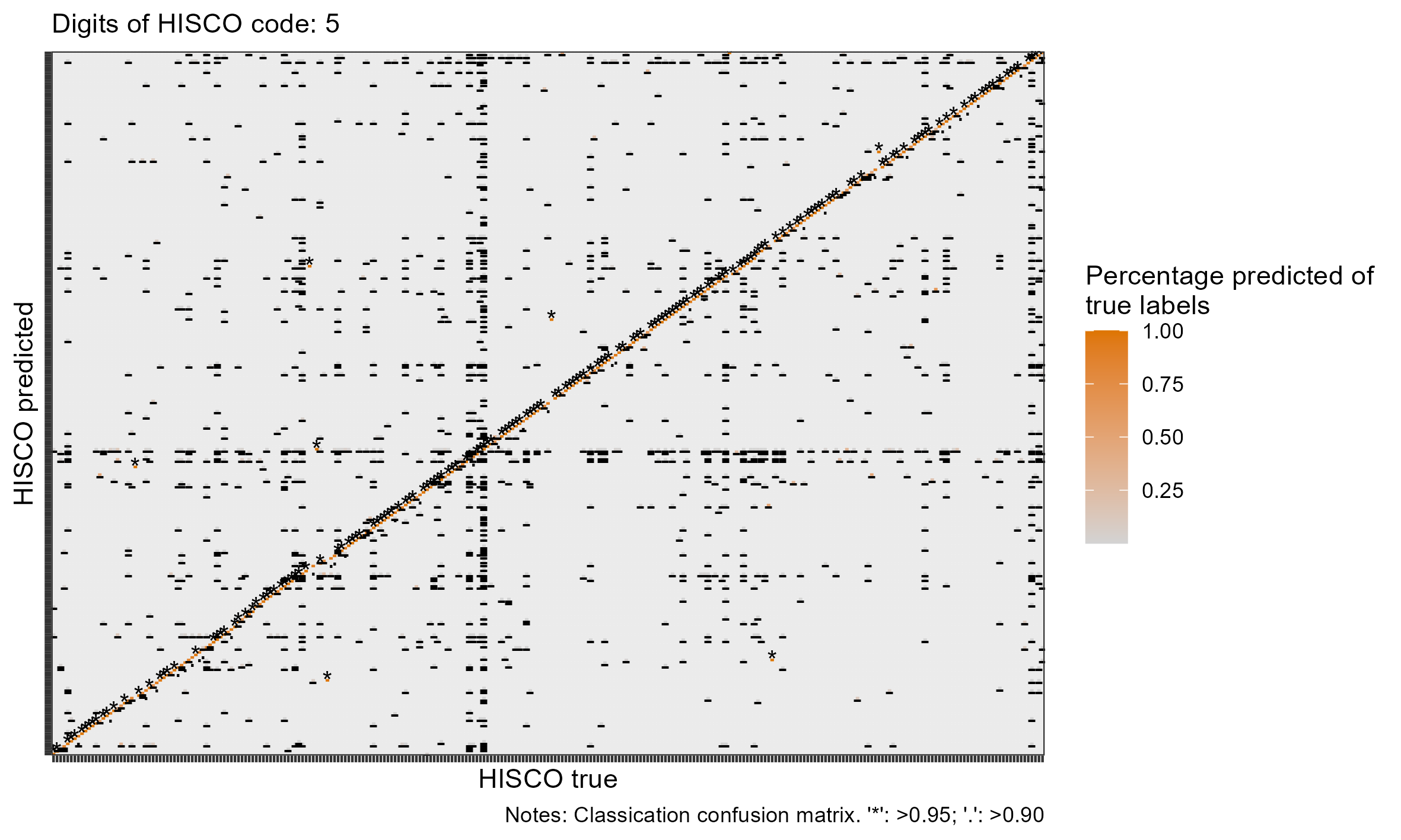 --- # The performance (3/5): Confusion matrix 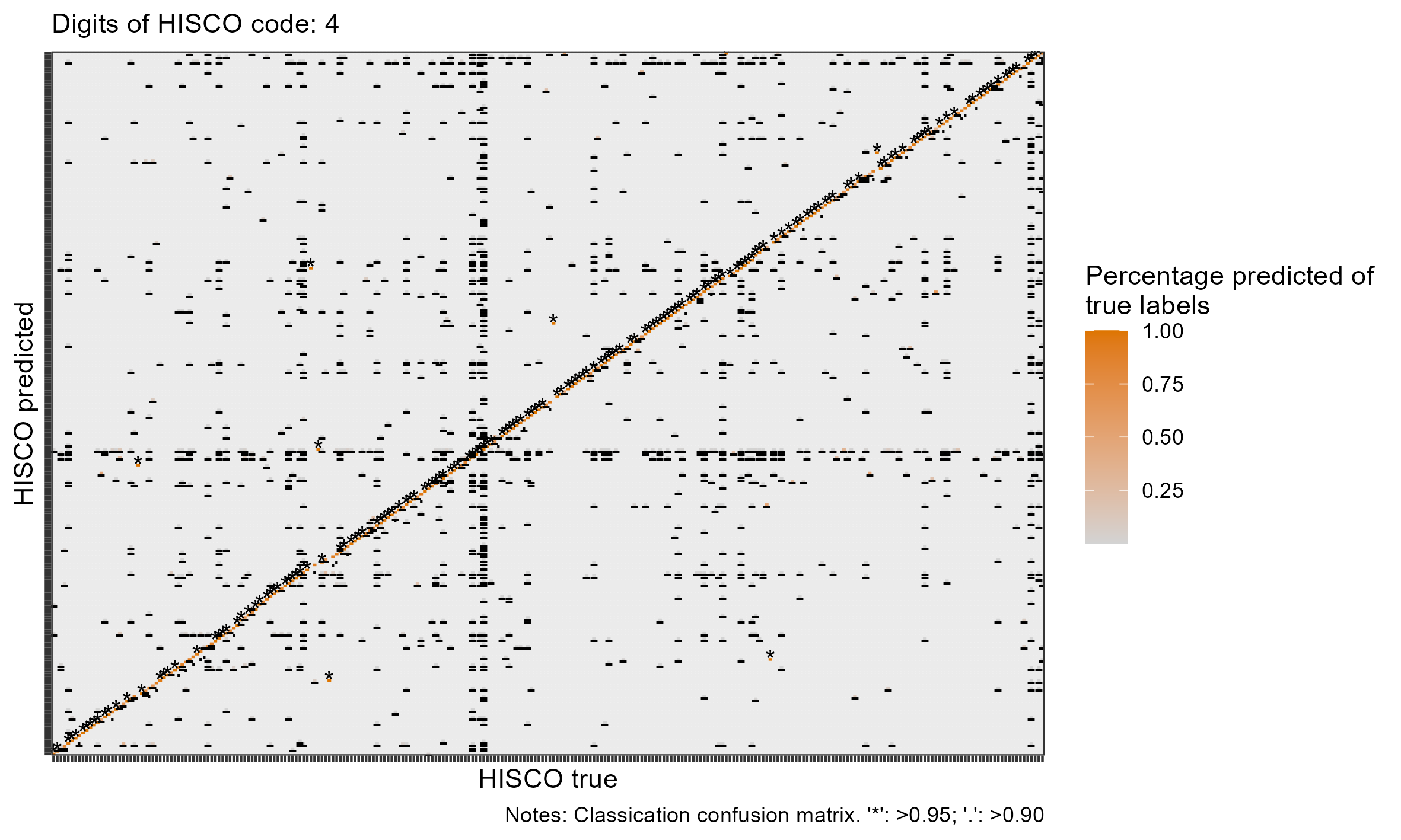 --- # The performance (3/5): Confusion matrix 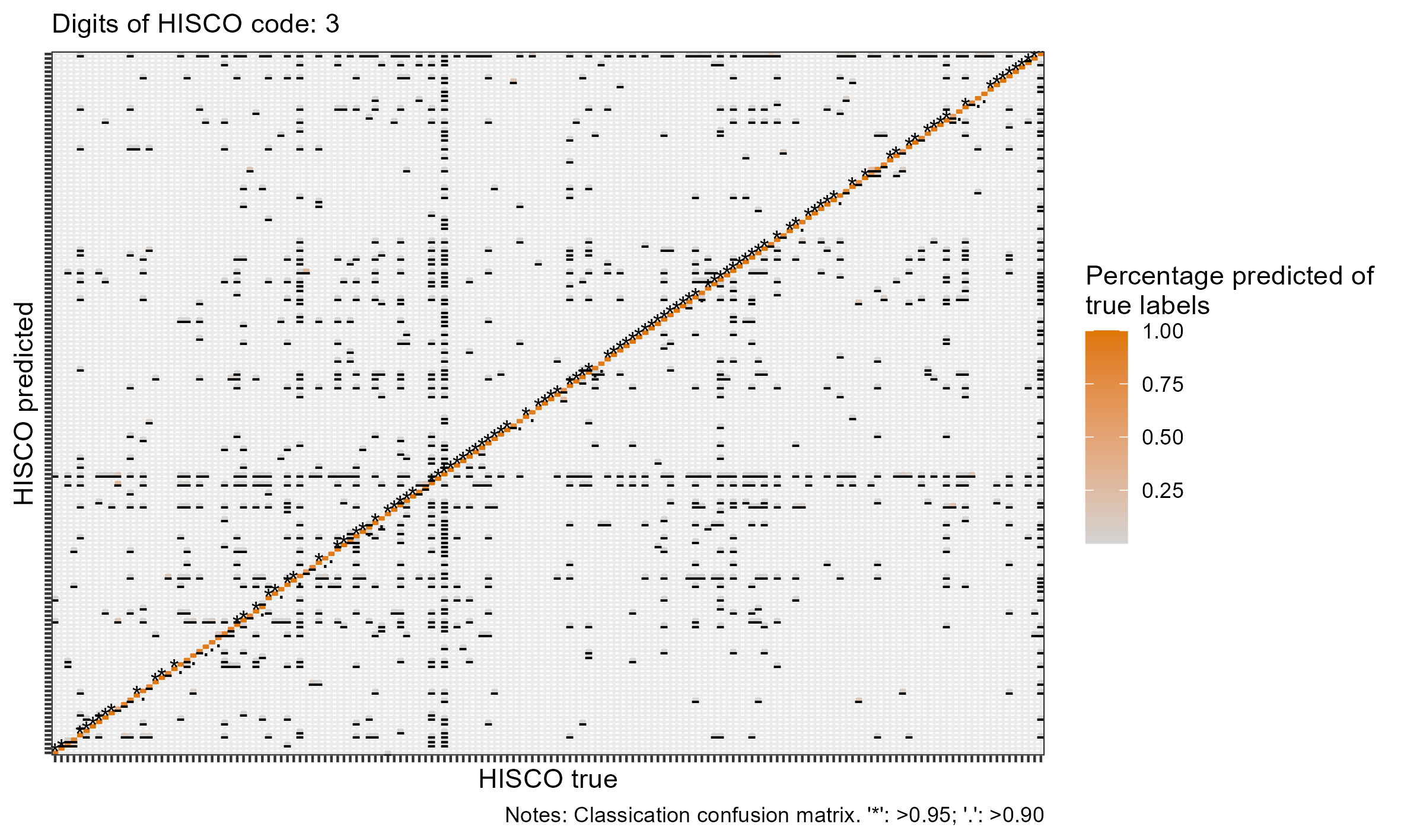 --- # The performance (3/5): Confusion matrix 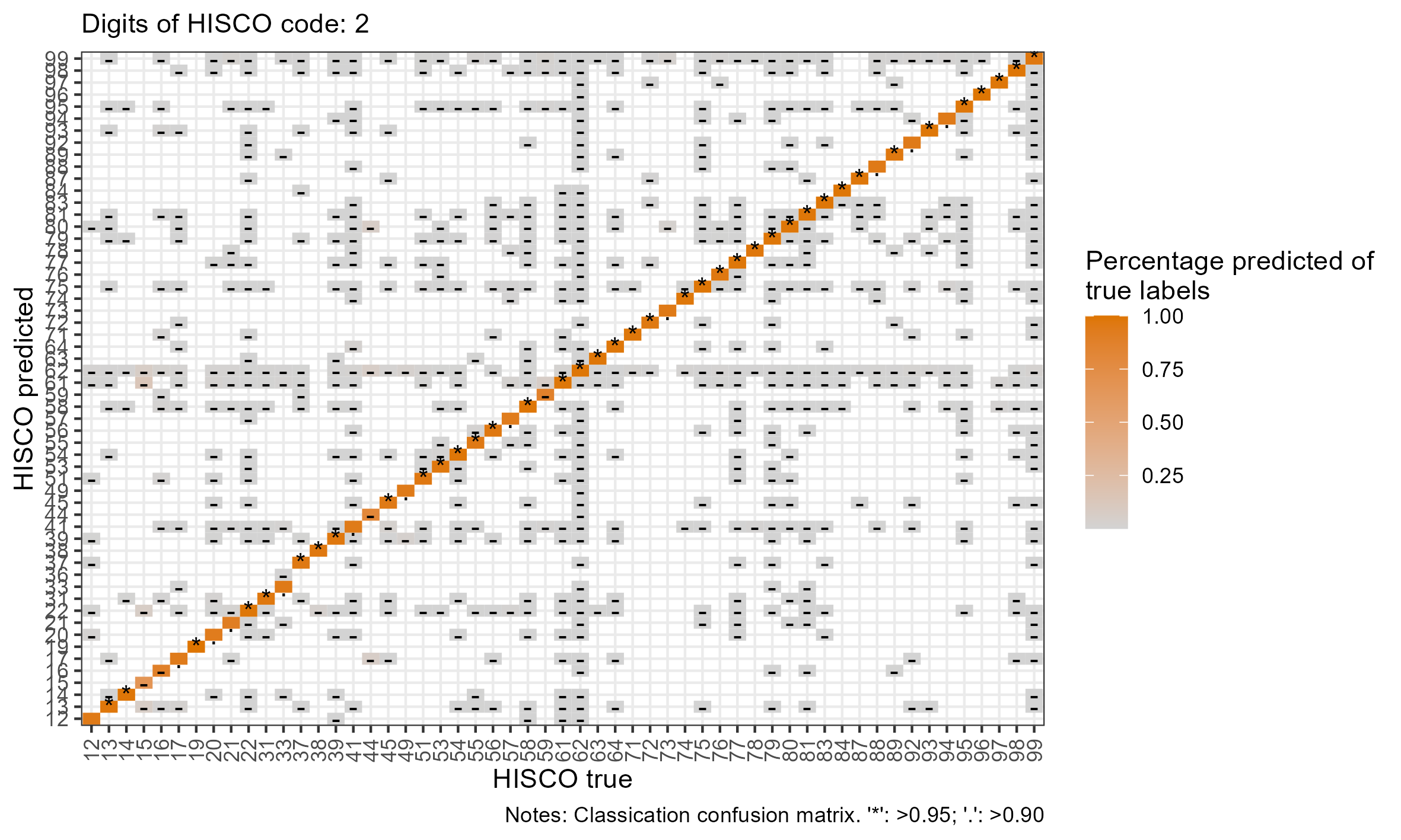 --- # The performance (3/5): Confusion matrix 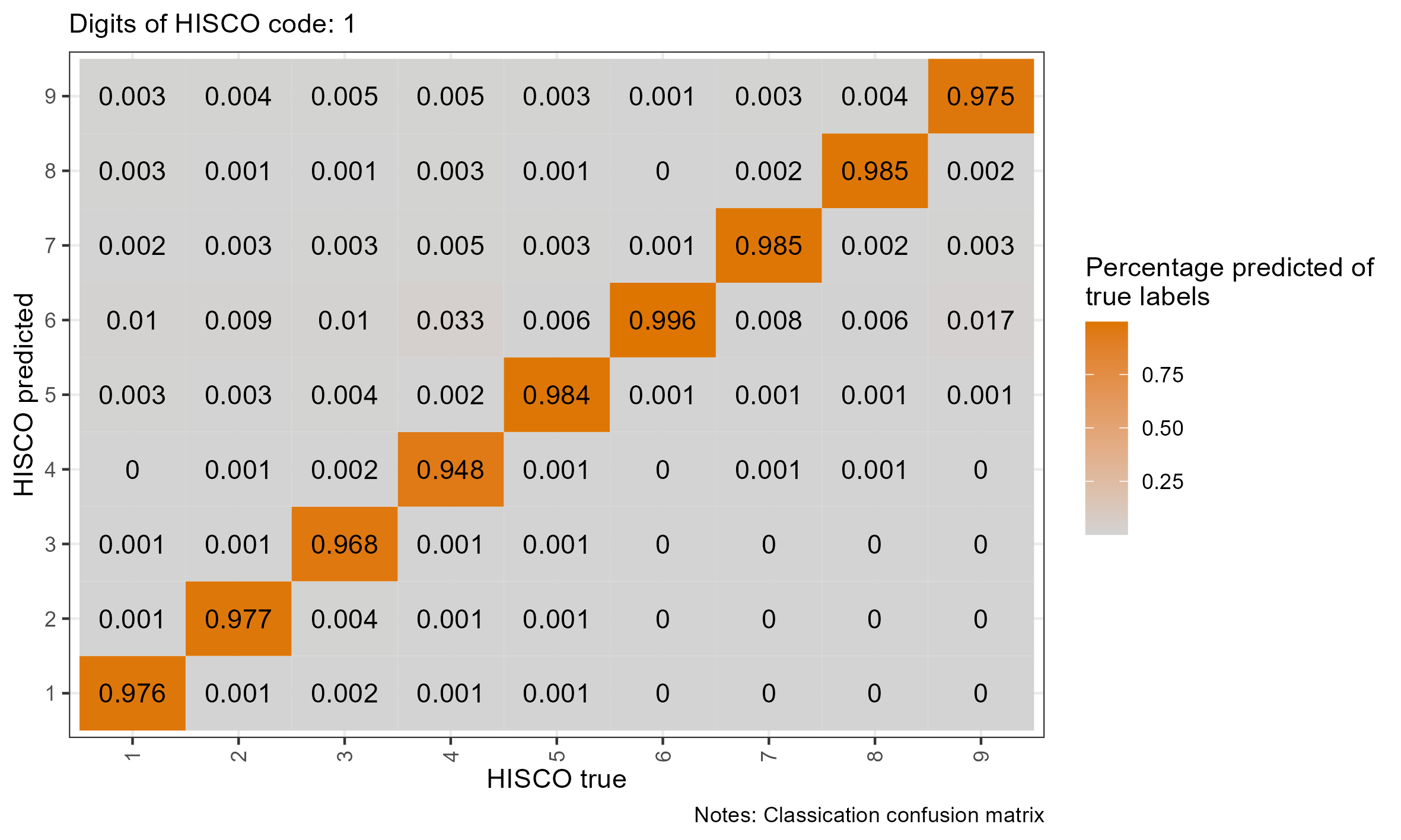 --- # Performance (5/5) **Conversion to status scores as validation** `\(\Rightarrow\)` **Higher than human accuracy** <div class="datatables html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-5d5ecef37318f50c5478" style="width:100%;height:auto;"></div> <script type="application/json" data-for="htmlwidget-5d5ecef37318f50c5478">{"x":{"filter":"none","vertical":false,"fillContainer":false,"data":[["1","2","3","4"],["hisclass","hisclass_5","socpo","hiscam_u1"],[0.00161509,0.00203475,-0.0361373,-0.000976822],[0.480137,0.202318,2.71758,1.55728],[0.480139,0.202328,2.71782,1.55728],[13,5,42,99]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>Statistic<\/th>\n <th>Bias<\/th>\n <th>Standard_error<\/th>\n <th>RMSE<\/th>\n <th>Scale<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"pageLength":8,"columnDefs":[{"className":"dt-right","targets":[2,3,4,5]},{"orderable":false,"targets":0}],"order":[],"autoWidth":false,"orderClasses":false,"lengthMenu":[8,10,25,50,100]}},"evals":[],"jsHooks":[]}</script> --- # Transformers - Architecture that fuels ChatGPT - Lives inside chatGPT - It is not chatGPT (that would be expensive) - Instead: XLM-RoBERTa w. 279M params - Trained on 2.5TB of website data / 100 languages - Finetuned for our purpose -- ### Results - Still training - 'light' version: 94.7 pct accurate --- # Transformer results <div class="datatables html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-74f85b52c86f694031ab" style="width:100%;height:auto;"></div> <script type="application/json" data-for="htmlwidget-74f85b52c86f694031ab">{"x":{"filter":"top","vertical":false,"filterHTML":"<tr>\n <td><\/td>\n <td data-type=\"number\" style=\"vertical-align: top;\">\n <div class=\"form-group has-feedback\" style=\"margin-bottom: auto;\">\n <input type=\"search\" placeholder=\"All\" class=\"form-control\" style=\"width: 100%;\"/>\n <span class=\"glyphicon glyphicon-remove-circle form-control-feedback\"><\/span>\n <\/div>\n <div style=\"display: none;position: absolute;width: 200px;opacity: 1\">\n <div data-min=\"0\" data-max=\"0.985\" data-scale=\"3\"><\/div>\n <span style=\"float: left;\"><\/span>\n <span style=\"float: right;\"><\/span>\n <\/div>\n <\/td>\n <td data-type=\"number\" style=\"vertical-align: top;\">\n <div class=\"form-group has-feedback\" style=\"margin-bottom: auto;\">\n <input type=\"search\" placeholder=\"All\" class=\"form-control\" style=\"width: 100%;\"/>\n <span class=\"glyphicon glyphicon-remove-circle form-control-feedback\"><\/span>\n <\/div>\n <div style=\"display: none;position: absolute;width: 200px;opacity: 1\">\n <div data-min=\"0.198\" data-max=\"0.988\" data-scale=\"3\"><\/div>\n <span style=\"float: left;\"><\/span>\n <span style=\"float: right;\"><\/span>\n <\/div>\n <\/td>\n <td data-type=\"character\" style=\"vertical-align: top;\">\n <div class=\"form-group has-feedback\" style=\"margin-bottom: auto;\">\n <input type=\"search\" placeholder=\"All\" class=\"form-control\" style=\"width: 100%;\"/>\n <span class=\"glyphicon glyphicon-remove-circle form-control-feedback\"><\/span>\n <\/div>\n <\/td>\n <td data-type=\"character\" style=\"vertical-align: top;\">\n <div class=\"form-group has-feedback\" style=\"margin-bottom: auto;\">\n <input type=\"search\" placeholder=\"All\" class=\"form-control\" style=\"width: 100%;\"/>\n <span class=\"glyphicon glyphicon-remove-circle form-control-feedback\"><\/span>\n <\/div>\n <\/td>\n <td data-type=\"number\" style=\"vertical-align: top;\">\n <div class=\"form-group has-feedback\" style=\"margin-bottom: auto;\">\n <input type=\"search\" placeholder=\"All\" class=\"form-control\" style=\"width: 100%;\"/>\n <span class=\"glyphicon glyphicon-remove-circle form-control-feedback\"><\/span>\n <\/div>\n <div style=\"display: none;position: absolute;width: 200px;opacity: 1\">\n <div data-min=\"2e-04\" data-max=\"1\" data-scale=\"4\"><\/div>\n <span style=\"float: left;\"><\/span>\n <span style=\"float: right;\"><\/span>\n <\/div>\n <\/td>\n<\/tr>","fillContainer":false,"data":[["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31","32","33","34","35"],[0.947,0.971,0.951,0.336,0.125,0.538,0.713,0.797,0.718,0.867,0.804,0.955,0.921,0.923,0.964,0.726,0.679,0.8139999999999999,0.825,0.749,0.75,0.924,0.977,0.911,0.966,0.974,0.897,0.975,0.962,0.982,0.982,0.985,0.953,0.661,0],[0.95,0.975,0.952,0.34,0.198,0.545,0.733,0.799,0.729,0.87,0.819,0.962,0.925,0.925,0.966,0.754,0.6840000000000001,0.821,0.832,0.752,0.75,0.927,0.982,0.916,0.972,0.975,0.91,0.987,0.974,0.986,0.984,0.988,0.954,0.75,0.8],["all","da","en","nl","se","0","1","2","3","4","5","6","7","8","9","1","2","3","4","5","6","7","8","9","10","11","12","13","1787","1834","1845","1880","1","2","3"],["Overall","Languages","Languages","Languages","Languages","Major category","Major category","Major category","Major category","Major category","Major category","Major category","Major category","Major category","Major category","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","By hisclass","Year","Year","Year","Year","Number of occupations","Number of occupations","Number of occupations"],[1,0.524,0.454,0.0152,0.0064,0.009299999999999999,0.0101,0.0192,0.0177,0.0271,0.0322,0.13,0.0924,0.0738,0.22,0.0095,0.0131,0.0183,0.0371,0.0167,0.0024,0.125,0.047,0.111,0.056,0.141,0.0263,0.0159,0.0658,0.109,0.159,0.18,0.982,0.0183,0.0002]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>accuracy<\/th>\n <th>f1<\/th>\n <th>stat<\/th>\n <th>subset<\/th>\n <th>pct_obs<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"pageLength":6,"columnDefs":[{"className":"dt-right","targets":[1,2,5]},{"orderable":false,"targets":0}],"order":[],"autoWidth":false,"orderClasses":false,"orderCellsTop":true,"lengthMenu":[6,10,25,50,100]}},"evals":[],"jsHooks":[]}</script> --- class: center # Trained embeddings <img src="Figures/tSNE_KMeans_Clustering_with_lang.png" width="650px" /> --- class: center # Untrained embeddings <img src="Figures/tSNE_KMeans_Clustering_with_lang_raw.png" width="650px" /> --- #### An applcation 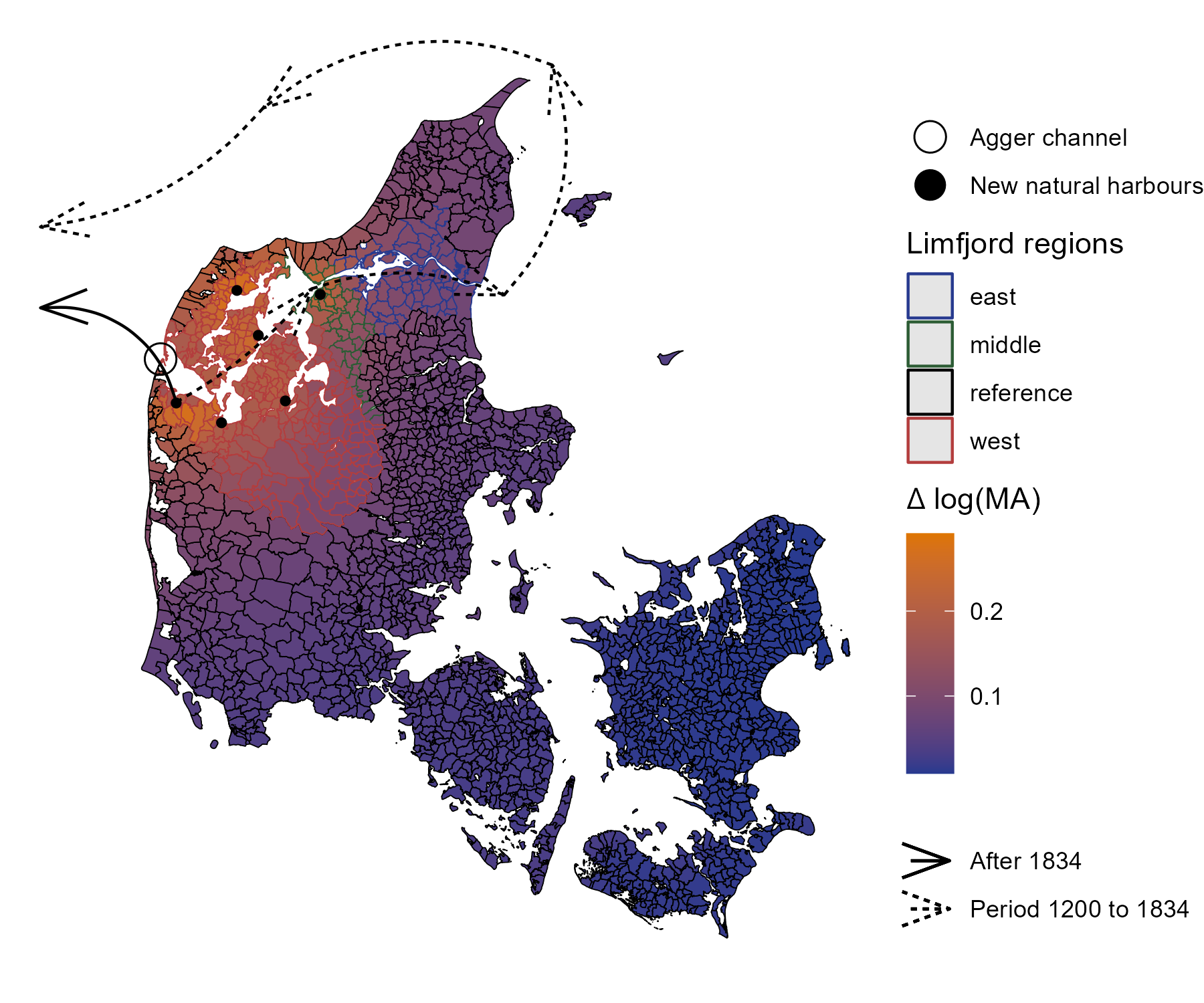 --- # Empirical strategy `$$log(y_{it}) = Affected_i \times Year_t \beta_t + FE + \varepsilon_{it}$$` --- ### Breach `\(\rightarrow\)` Parishes with fishermen 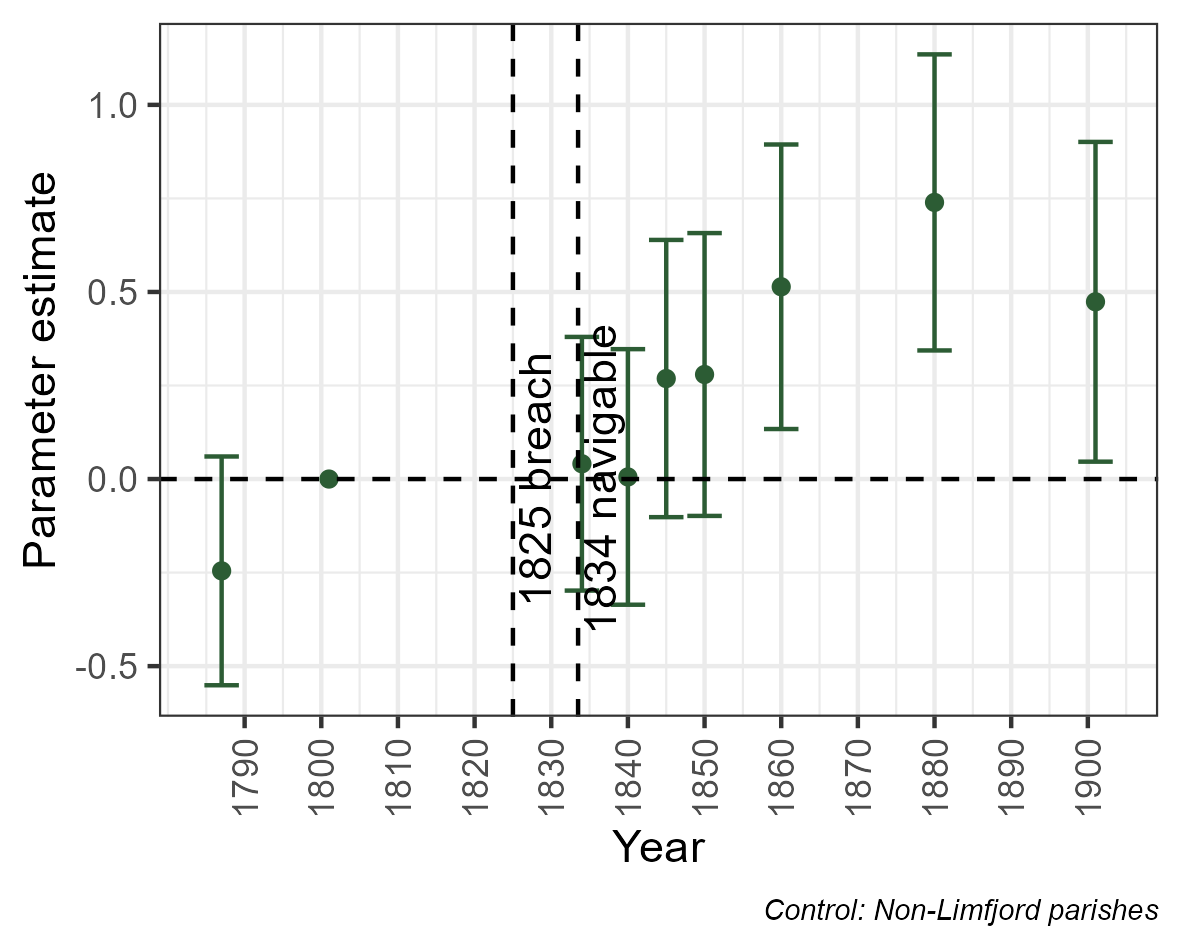 --- # Conclusion .pull-left[ ### Steps ahead - More data, more training - A generalized understand of occupational descriptions - Application oriented validation ] .pull-right[ **Please let me know** - How do we make this a tool? - <p style="color:red;">If you have data to HISCO codes, please send it to me (christian-vs@sam.sdu.dk)</p> - <p style="color:red;">In return I owe you HISCO codes for your project!</p> ]