Web scraping 2
Advanced Crime Analysis UCL
Bennett Kleinberg
21 Jan 2019
Getting data from the Internet
Webscraping 2
Today
- “Real” webscraping: basics of a webpage
- Access webpage in the wild
- Retrieve wild data
- Download data through webscraping
APIs: Pros & Cons
Pro
- easiy to access
- nicely documentation
- works even if website changes
Cons
- quota limits ($ $ $)
- under the platforms’ control
- only for few platforms
Don’t let the data determine your research!
COOL
But what about:

No APIs
- incels.me
- stormfront
4chan
APIs are restrictive!
… what about:
Your research question –> no API?

Main problem:
Really ‘juicy’ data of the Internet vs APIs
“Real” webscraping: basics of a webpage
Three elements of a webpage
- Structure
- Behaviour
- Style
Three elements of a webpage
- Structure
- Behaviour
- JavaScript (!= Java)
- user interaction
- examples: alerts, popups, server-interaction
- Style
Three elements of a webpage
- Structure
- Behaviour
- Style
- CSS (Cascading Style Sheets)
- formatting, design, responsiveness
- examples: submit buttons, app interaces
Three elements of a webpage
- Structure
- HTML (hypertext markup language)
- structured with
<tags> - contains the pure content of the webpage
- Behaviour
- Style
For now: HTML
The very basics of HTML:
Raw architecture of a webpage
<!DOCTYPE html>
<html>
<body>
HERE COMES THE VISIBLE PART!!
</body>
</html>Note: Every tags < > is closed < />. Content is contained within the tag.
HTML basics
Ways to put content in the <body> ... </body> tag:
- headings:
<h1>I'm a heading at level 1</>

Content in the body tag
- paragraphs:
<p>This is a paragraph</p>

Content in the body tag
- images:
<img src="./img/ucl.jpg">
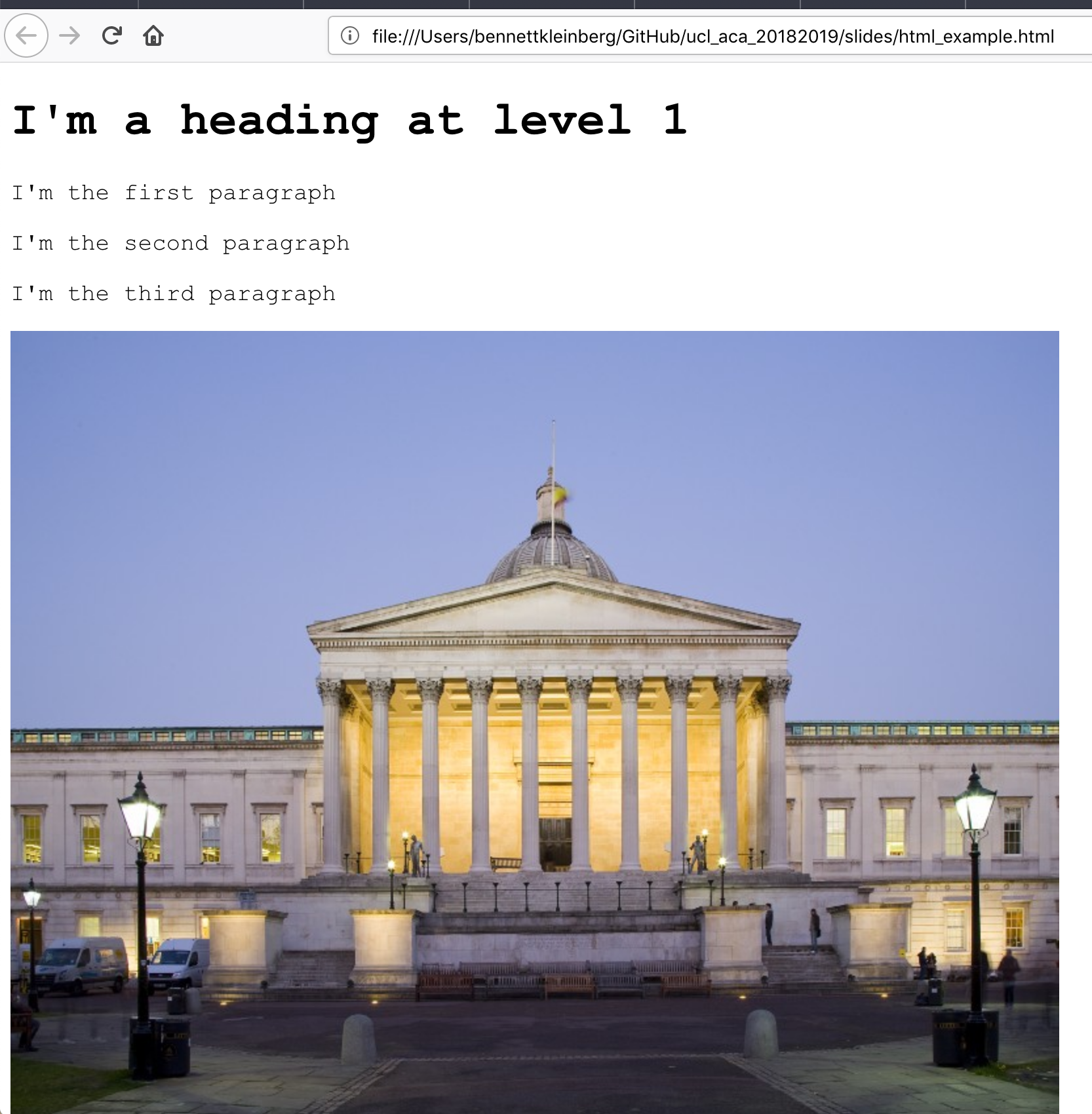
Content in the body tag
- links:
<a href="https://www.ucl.ac.uk/">Click here to go to UCL's website</a></a>
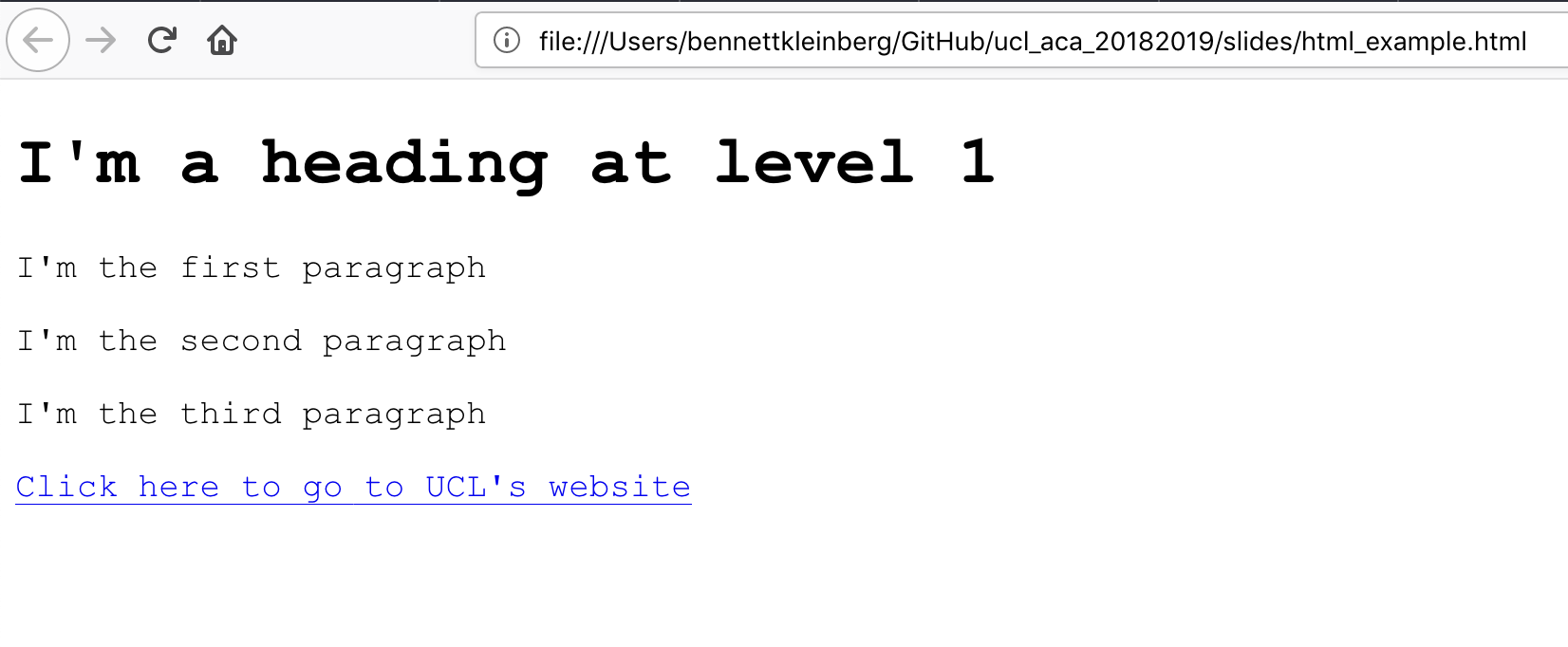
Content in the body tag
- tables
<table>
<tr>
<th>Departments</th>
<th>Location</th>
</tr>
<tr>
<td>Dept. of Security and Crime Science</td>
<td>Division of Psychology and Language Sciences</td>
</tr>
<tr>
<td>35 Tavistock Square</td>
<td>26 Bedford Way</td>
</tr>
</table> Html <table>...</table>
Content in the body tag
- lists
<ul>
<li>Terrorism</li>
<li>Cyber Crime</li>
<li>Data Science</li>
</ul> 
HTML basics
Elements (can) have IDs:
<p id='paragraph1'>This is a paragraph</p>
<img id='ucl_image' src="./img/ucl.jpg">Same for tables, links, etc.
Every element can have an ID.
You need unique IDs! Two elements cannot have the same ID.
HTML basics
Common elements (can) have CLASSES:
<p id="paragraph1" class="paragraph_class">I am the first paragraph</p>
<p class="paragraph_class">I am the second paragraph</p>
<p class="paragraph_class">I am the third paragraph</p>Multiple elements can have the same class.
Now what?
Web scraping logic
If all webpages are built in this structure…
… then we could access this structure programmatically.
But where do I find that structure?
Is it just “there”?
YES!!
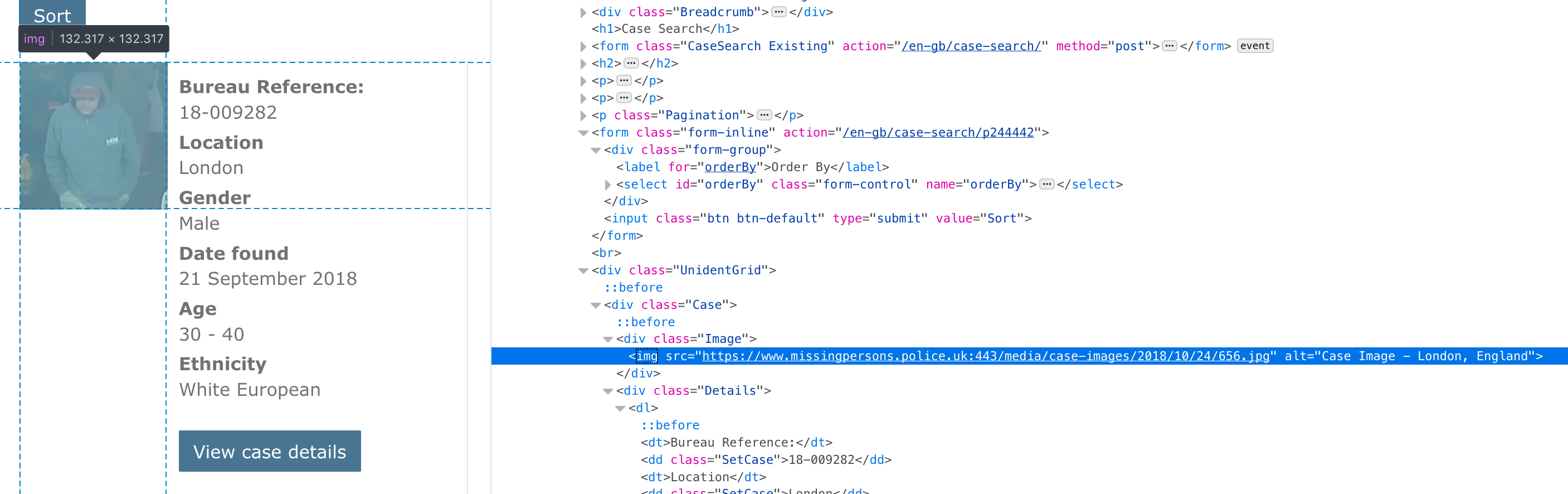
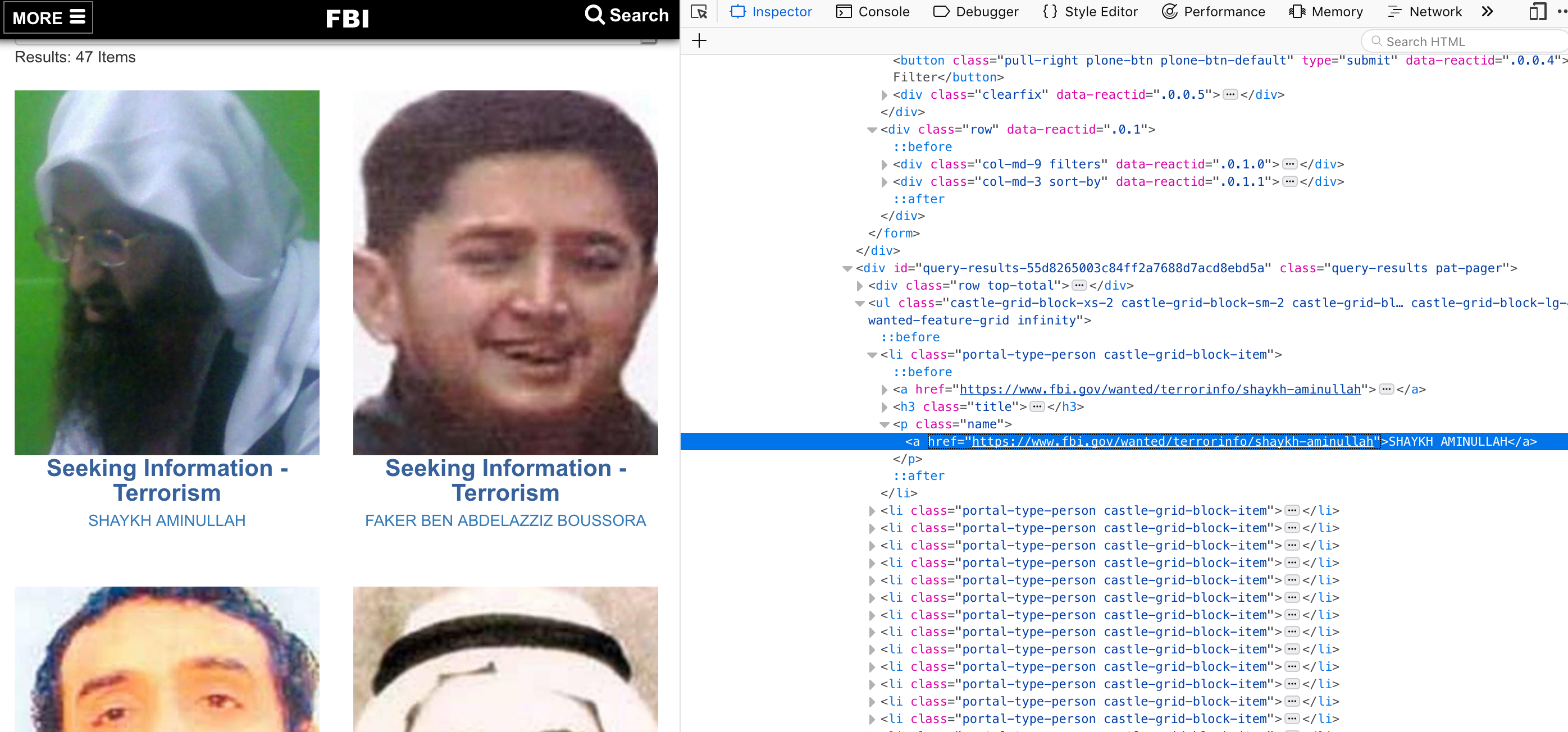
How to see the html structure?
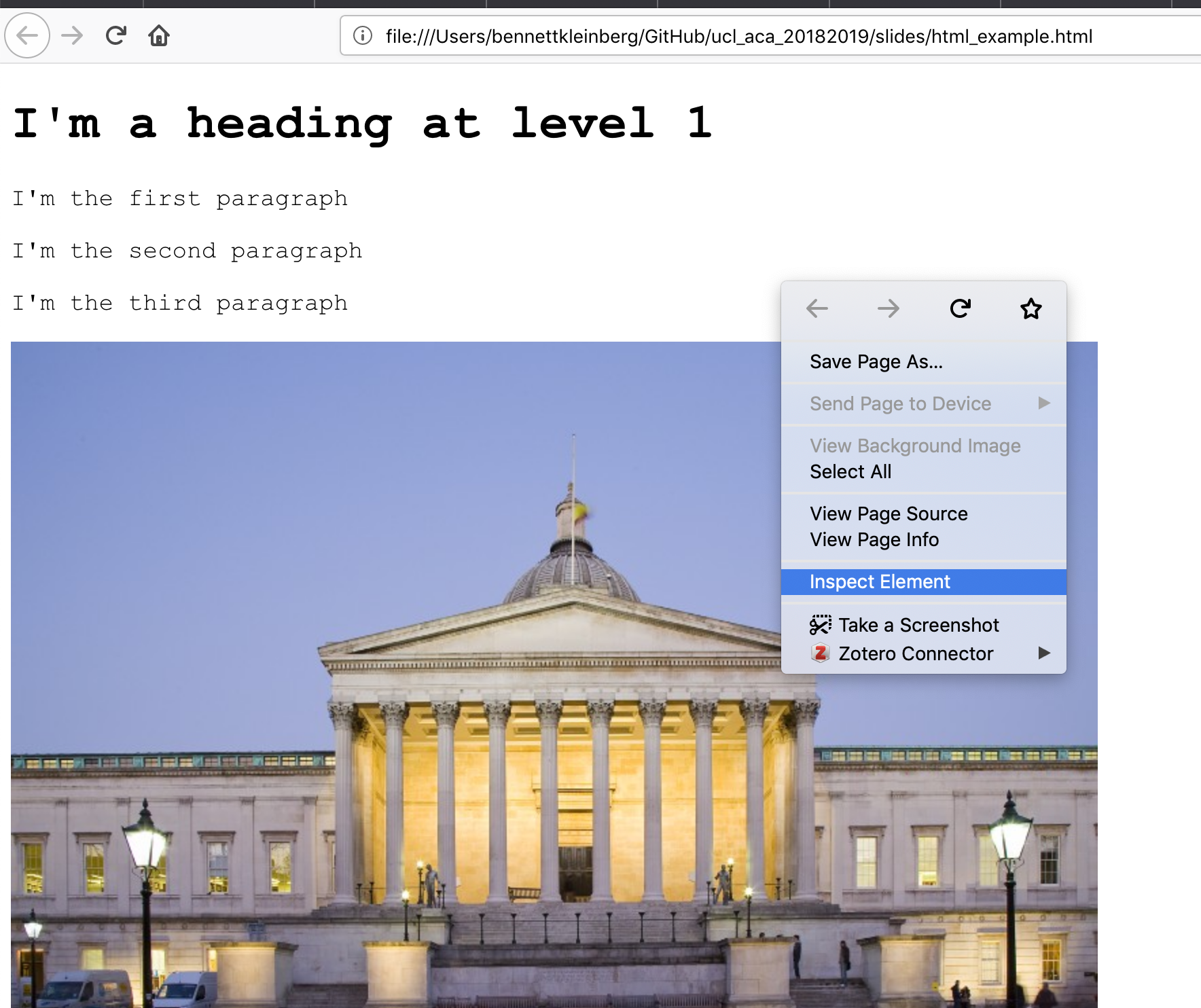
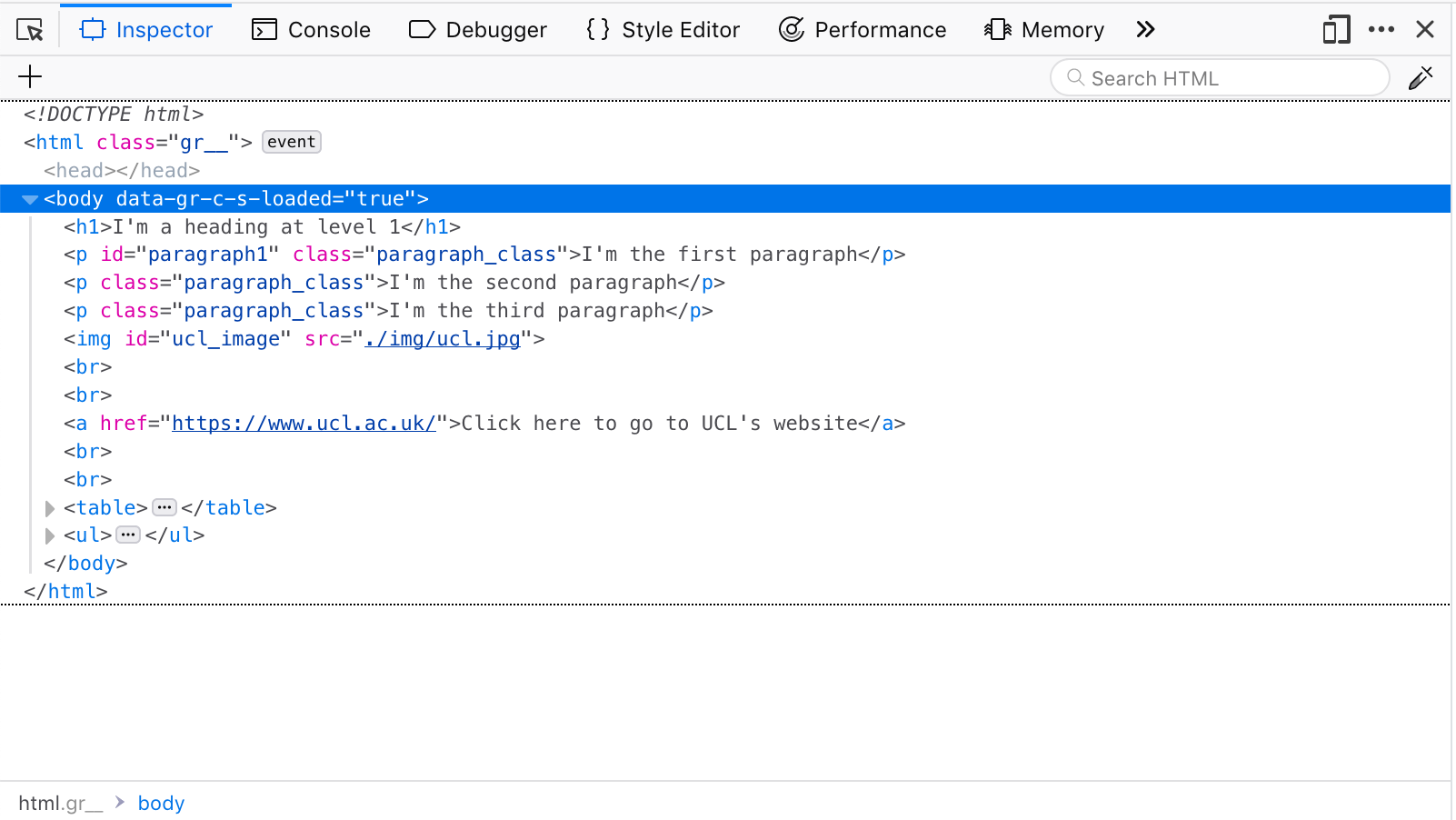
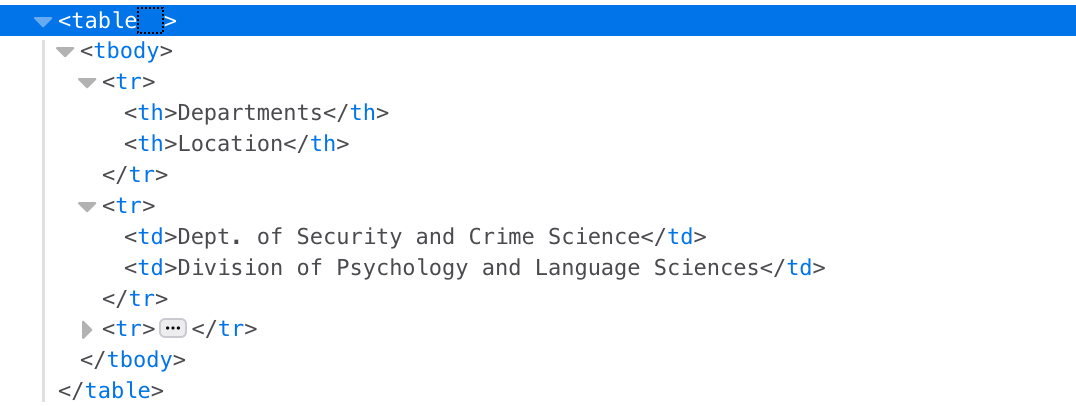
Example 1: Missing persons
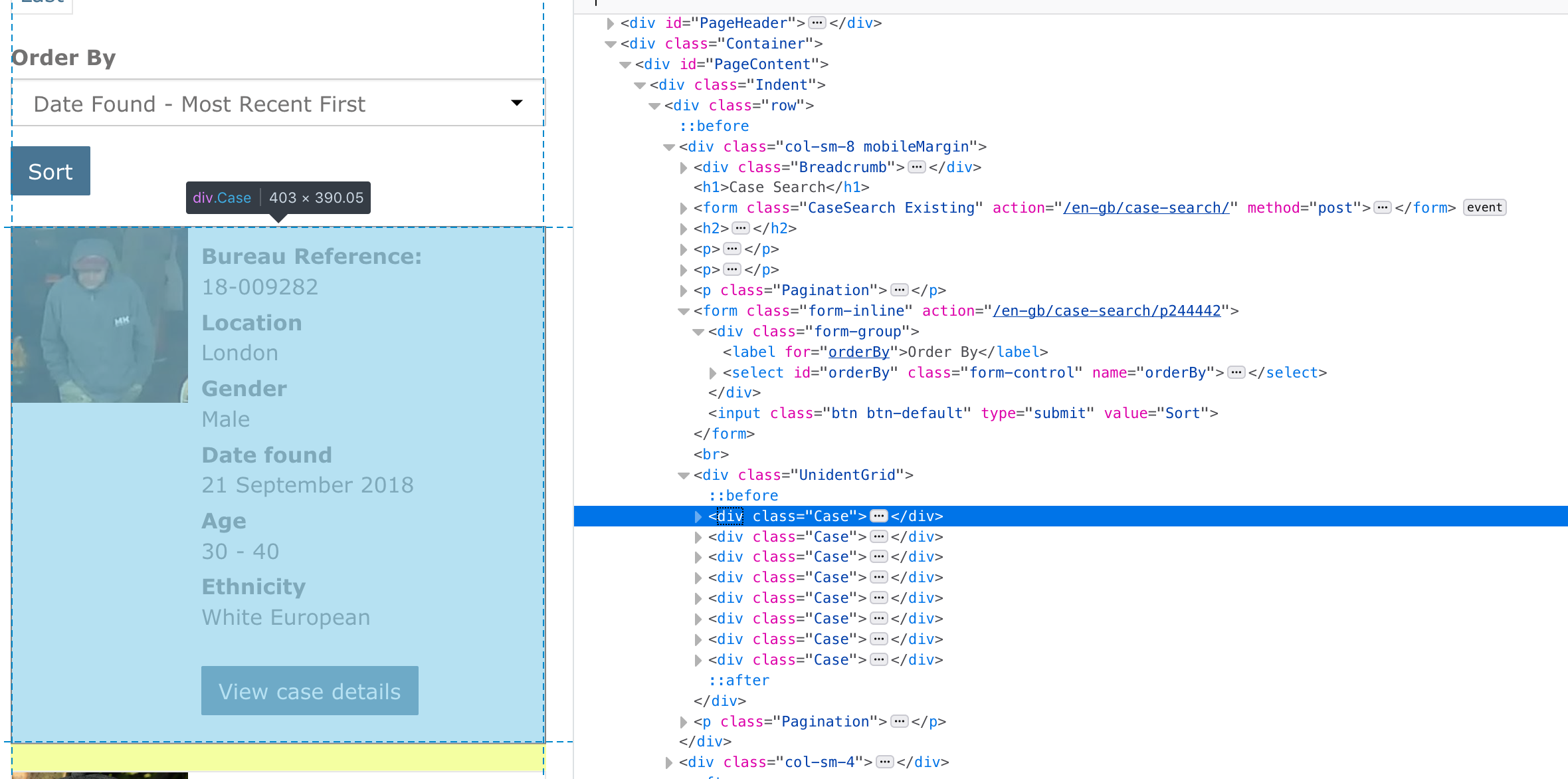
Example 1: Missing persons
Example 2: FBI most wanted
Webscraping in a nutshell
- understand the structure of a webpage
- exploit that structure for web-scraping
Webscraping in practice
Case for today: Missing persons FBI
https://www.fbi.gov/wanted/kidnap
Explore the target page
Aims
- Get a list of all names
- Store the bio information
- Extract the “details” description
- Download the poster
Getting started
Set up your workspace first:
library(rvest)## Loading required package: xml2target_url = 'https://www.fbi.gov/wanted/kidnap'Remember…
- understanding the structure of a webpage
- exploiting that structure for web-scraping
1. Get a list of all names
understanding the structure of a webpage
1. Get a list of all names
exploiting that structure for web-scraping
Access the full html page (snapshot-mode):
target_page = read_html(target_url)
target_page## {xml_document}
## <html lang="en" data-gridsystem="bs3">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset= ...
## [2] <body id="visual-portal-wrapper" class=" portaltype-folder site-Plo ...1. Get a list of all names
Key here: look for the <h3> heading with class title:
target_page %>%
html_nodes('h3.title')## {xml_nodeset (40)}
## [1] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/aria ...
## [2] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/ange ...
## [3] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/jenn ...
## [4] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/feli ...
## [5] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/mark ...
## [6] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/mich ...
## [7] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/ashl ...
## [8] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/jaym ...
## [9] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/ilen ...
## [10] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/carl ...
## [11] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/lisa ...
## [12] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/kyro ...
## [13] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/bian ...
## [14] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/jabe ...
## [15] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/shan ...
## [16] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/abby ...
## [17] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/ruoc ...
## [18] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/josh ...
## [19] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/copy ...
## [20] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/eric ...
## ...#note: equivalent to "html_nodes(target_page, 'h3.title')""1. Get a list of all names
A closer look:
all_titles = target_page %>%
html_nodes('h3.title')
all_titles[1]## {xml_nodeset (1)}
## [1] <h3 class="title">\n<a href="https://www.fbi.gov/wanted/kidnap/arian ...It’s the text of the <a href=...> tag.
1. Get a list of all names
So what we want is:
- Access the full html page
- Search all h3 headings with class “title”
- Find all
<a >tags (= links) - Extract the text
1. Get a list of all names
- Access the full html page
read_html(target_url) - Search all h3 headings with class “title”
html_nodes('h3.title') - Find all
<a >tags (= links)html_nodes('a') - Extract the text
html_text()
1. Get a list of all names
Combined:
all_names = target_page %>%
html_nodes('h3.title') %>%
html_nodes('a') %>%
html_text()1. Get a list of all names
all_names## [1] "ARIANNA FITTS"
## [2] "ANGELA MAE MEEKER"
## [3] "JENNIFER LYNN MARCUM"
## [4] "FELIX BATISTA"
## [5] "MARK HIMEBAUGH"
## [6] "MICHAELA JOY GARECHT"
## [7] "ASHLEY SUMMERS"
## [8] "JAYME CLOSS"
## [9] "ILENE BETH MISHELOFF"
## [10] "CARLA VICENTINI"
## [11] "LISA IRWIN"
## [12] "KYRON RICHARD HORMAN"
## [13] "BIANCA LEBRON"
## [14] "JABEZ SPANN"
## [15] "SHANNA GENELLE PEOPLES"
## [16] "ABBY LYNN PATTERSON"
## [17] "RUOCHEN LIAO"
## [18] "JOSHUA KESHABA SIERRA GARCIA"
## [19] "ALEXIS TIARA MURPHY"
## [20] "ERICA NICOLE HUNT"
## [21] "TIONDA Z. BRADLEY"
## [22] "DIAMOND YVETTE BRADLEY"
## [23] "NEFERTIRI R. TRADER"
## [24] "KRISTEN MODAFFERI"
## [25] "LASHAYA STINE"
## [26] "JONATHAN FRASER"
## [27] "AMINA AND BELEL KANDIL"
## [28] "FALOMA LUHK"
## [29] "MALEINA LUHK"
## [30] "KAYLAH HUNTER AND KRISTIAN JUSTICE"
## [31] "RUSSELL JOHN MORT"
## [32] "AKIA SHAWNTA EGGLESTON"
## [33] "RONDREIZ PHILLIPS"
## [34] "DEVONTE JORDAN HART"
## [35] "AMBER ELIZABETH CATES"
## [36] "SHAINA ASHLEY KIRKPATRICK"
## [37] "SHAUSHA LATINE HENSON"
## [38] "AMY LYNN BRADLEY"
## [39] "SUZANNE G. LYALL"
## [40] "MYRA LEWIS"2. Store the bio information
understanding the structure of a webpage
2. Store the bio information
We know: there’s a table with class wanted-person-description that contains the data we want.
But: we need to access each ‘kidnapped’ person!?
For-loops to the rescue…
2. Store the bio information
exploiting that structure for web-scraping
So what we want is:
- Access the full html page
- Search all h3 headings with class “title”
- Find all
<a >tags (= links) - Extract the
textactual link - Access that page
- Extract the table with class
wanted-person-description
2. Store the bio information
all_persons_links = target_page %>%
html_nodes('h3.title') %>%
html_nodes('a') %>%
html_attr('href')
all_persons_links## [1] "https://www.fbi.gov/wanted/kidnap/arianna-fitts"
## [2] "https://www.fbi.gov/wanted/kidnap/angela-mae-meeker"
## [3] "https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum"
## [4] "https://www.fbi.gov/wanted/kidnap/felix-batista"
## [5] "https://www.fbi.gov/wanted/kidnap/mark-himebaugh"
## [6] "https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht"
## [7] "https://www.fbi.gov/wanted/kidnap/ashley-summers"
## [8] "https://www.fbi.gov/wanted/kidnap/jayme-closs"
## [9] "https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff"
## [10] "https://www.fbi.gov/wanted/kidnap/carla-vicentini"
## [11] "https://www.fbi.gov/wanted/kidnap/lisa-irwin"
## [12] "https://www.fbi.gov/wanted/kidnap/kyron-richard-horman"
## [13] "https://www.fbi.gov/wanted/kidnap/bianca-lebron"
## [14] "https://www.fbi.gov/wanted/kidnap/jabez-spann"
## [15] "https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples"
## [16] "https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson"
## [17] "https://www.fbi.gov/wanted/kidnap/ruochen-liao"
## [18] "https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia"
## [19] "https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy"
## [20] "https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt"
## [21] "https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley"
## [22] "https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley"
## [23] "https://www.fbi.gov/wanted/kidnap/nefertiri-trader"
## [24] "https://www.fbi.gov/wanted/kidnap/kristen-modafferi"
## [25] "https://www.fbi.gov/wanted/kidnap/lashaya-stine"
## [26] "https://www.fbi.gov/wanted/kidnap/jonathan-fraser"
## [27] "https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil"
## [28] "https://www.fbi.gov/wanted/kidnap/faloma-luhk"
## [29] "https://www.fbi.gov/wanted/kidnap/maleina-luhk"
## [30] "https://www.fbi.gov/wanted/kidnap/kaylah-hunter"
## [31] "https://www.fbi.gov/wanted/kidnap/russell-john-mort"
## [32] "https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston"
## [33] "https://www.fbi.gov/wanted/kidnap/rondreiz-phillips"
## [34] "https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart"
## [35] "https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates"
## [36] "https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick"
## [37] "https://www.fbi.gov/wanted/kidnap/shausha-latine-henson"
## [38] "https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley"
## [39] "https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall"
## [40] "https://www.fbi.gov/wanted/kidnap/myra-lewis"2. Store the bio information
Now what?
for(i in all_persons_links){
print(i)
}## [1] "https://www.fbi.gov/wanted/kidnap/arianna-fitts"
## [1] "https://www.fbi.gov/wanted/kidnap/angela-mae-meeker"
## [1] "https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum"
## [1] "https://www.fbi.gov/wanted/kidnap/felix-batista"
## [1] "https://www.fbi.gov/wanted/kidnap/mark-himebaugh"
## [1] "https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht"
## [1] "https://www.fbi.gov/wanted/kidnap/ashley-summers"
## [1] "https://www.fbi.gov/wanted/kidnap/jayme-closs"
## [1] "https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff"
## [1] "https://www.fbi.gov/wanted/kidnap/carla-vicentini"
## [1] "https://www.fbi.gov/wanted/kidnap/lisa-irwin"
## [1] "https://www.fbi.gov/wanted/kidnap/kyron-richard-horman"
## [1] "https://www.fbi.gov/wanted/kidnap/bianca-lebron"
## [1] "https://www.fbi.gov/wanted/kidnap/jabez-spann"
## [1] "https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples"
## [1] "https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson"
## [1] "https://www.fbi.gov/wanted/kidnap/ruochen-liao"
## [1] "https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia"
## [1] "https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy"
## [1] "https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt"
## [1] "https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley"
## [1] "https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley"
## [1] "https://www.fbi.gov/wanted/kidnap/nefertiri-trader"
## [1] "https://www.fbi.gov/wanted/kidnap/kristen-modafferi"
## [1] "https://www.fbi.gov/wanted/kidnap/lashaya-stine"
## [1] "https://www.fbi.gov/wanted/kidnap/jonathan-fraser"
## [1] "https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil"
## [1] "https://www.fbi.gov/wanted/kidnap/faloma-luhk"
## [1] "https://www.fbi.gov/wanted/kidnap/maleina-luhk"
## [1] "https://www.fbi.gov/wanted/kidnap/kaylah-hunter"
## [1] "https://www.fbi.gov/wanted/kidnap/russell-john-mort"
## [1] "https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston"
## [1] "https://www.fbi.gov/wanted/kidnap/rondreiz-phillips"
## [1] "https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart"
## [1] "https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates"
## [1] "https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick"
## [1] "https://www.fbi.gov/wanted/kidnap/shausha-latine-henson"
## [1] "https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley"
## [1] "https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall"
## [1] "https://www.fbi.gov/wanted/kidnap/myra-lewis"2. Store the bio information
Before you write a loop…
arianna = all_persons_links[1]
temp_target_url = arianna
temp_target_page = read_html(temp_target_url)Single-case proof.
2. Store the bio information
description = temp_target_page %>%
html_nodes('table.wanted-person-description') %>%
html_table()
description## [[1]]
## X1 X2
## 1 Date(s) of Birth Used September 6, 2013
## 2 Place of Birth California
## 3 Hair Black
## 4 Eyes Brown
## 5 Height 2'0" (at time of disappearance)
## 6 Weight 45 pounds (at time of disappearance)
## 7 Sex Female
## 8 Race Black
## 9 Nationality American2. Store the bio information
What we need for the for-loop:
- do this for each link
- store it somewhere (easiest: in a list)
- log progress
2. Store the bio information
list_for_data = list()
for(i in all_persons_links){
print(paste('Accessing:', i))
temp_target_url = i
temp_target_page = read_html(temp_target_url)
description = temp_target_page %>%
html_nodes('table.wanted-person-description') %>%
html_table()
index_of_i = which(i == all_persons_links)
list_for_data[[index_of_i]] = description
print('--- NEXT ---')
}## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/arianna-fitts"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/angela-mae-meeker"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/felix-batista"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/mark-himebaugh"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ashley-summers"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jayme-closs"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/carla-vicentini"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/lisa-irwin"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kyron-richard-horman"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/bianca-lebron"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jabez-spann"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ruochen-liao"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/nefertiri-trader"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kristen-modafferi"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/lashaya-stine"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jonathan-fraser"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/faloma-luhk"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/maleina-luhk"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kaylah-hunter"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/russell-john-mort"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/rondreiz-phillips"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shausha-latine-henson"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/myra-lewis"
## [1] "--- NEXT ---"2. Store the bio information
Now we have a list of tables.
Each table contains the details of one missing person:
# thirteenth element in the list
list_for_data[[13]]## [[1]]
## X1 X2
## 1 Date(s) of Birth Used June 26, 1991
## 2 Hair Long Dark Brown
## 3 Eyes Hazel
## 4 Height 4'11"
## 5 Weight 115 pounds
## 6 Sex Female
## 7 Race White (Hispanic)3. Extract the “details” description
understanding the structure of a webpage
3. Extract the “details” description
We want: the text of the <div > with class wanted-person-details
exploiting that structure for web-scraping
So what we want is:
- Access the full html page
- Search all h3 headings with class “title”
- Find all
<a >tags (= links) - Extract the
textactual link - Access that page
- Extract the
table with classwanted-person-description<div >with classwanted-person-details
3. Extract the “details” description
Start with single-case proof:
arianna = all_persons_links[1]
temp_target_url = arianna
temp_target_page = read_html(temp_target_url)
person_details = temp_target_page %>%
html_nodes('div.wanted-person-details') %>%
html_text()3. Extract the “details” description
person_details## [1] "\nDetails:\nArianna Fitts was reported missing from the San Francisco, California, area on April 5, 2016. She was last seen in Oakland, California, in February of 2016. On April 8, 2016, Arianna's mother, Nicole Fitts, was found murdered and buried in a public park in San Francisco. It is believed that Arianna was not with her mother when she was killed.\n"3. Extract the “details” description
Putting it in a loop:
list_for_person_details = list()
for(i in all_persons_links){
print(paste('Accessing:', i))
temp_target_url = i
temp_target_page = read_html(temp_target_url)
person_details = temp_target_page %>%
html_nodes('div.wanted-person-details') %>%
html_text()
index_of_i = which(i == all_persons_links)
list_for_person_details[[index_of_i]] = person_details
print('--- NEXT ---')
}## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/arianna-fitts"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/angela-mae-meeker"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/felix-batista"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/mark-himebaugh"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ashley-summers"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jayme-closs"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/carla-vicentini"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/lisa-irwin"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kyron-richard-horman"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/bianca-lebron"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jabez-spann"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/ruochen-liao"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/nefertiri-trader"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kristen-modafferi"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/lashaya-stine"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/jonathan-fraser"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/faloma-luhk"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/maleina-luhk"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/kaylah-hunter"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/russell-john-mort"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/rondreiz-phillips"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/shausha-latine-henson"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall"
## [1] "--- NEXT ---"
## [1] "Accessing: https://www.fbi.gov/wanted/kidnap/myra-lewis"
## [1] "--- NEXT ---"3. Extract the “details” description
#look at the 20th element
list_for_person_details[[20]]## [1] "\nDetails:\nErica Nicole Hunt was last seen on July 4, 2016, near a relative's house in Opelousas, Louisiana. Her roommate reported her missing on July 5, 2016, and she has not been seen or heard from since.\n"4. Download the poster
understanding the structure of a webpage
4. Download the poster
What do we want?
understanding the structure of a webpage
Each kidnapped person has a ‘download link’…
https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdfDon’t overthink it!
4. Download the poster
Compare these two:
https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdfarianna## [1] "https://www.fbi.gov/wanted/kidnap/arianna-fitts"Notice something?
4. Download the poster
We can just ‘work around’ this:
download_url_arianna = paste(tolower(arianna), '/download.pdf', sep="")
download_url_arianna## [1] "https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdf"https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdf
4. Download the poster
Make use of R’s vectorised structure:
all_download_links = paste(tolower(all_persons_links), '/download.pdf', sep="")
all_download_links## [1] "https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdf"
## [2] "https://www.fbi.gov/wanted/kidnap/angela-mae-meeker/download.pdf"
## [3] "https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum/download.pdf"
## [4] "https://www.fbi.gov/wanted/kidnap/felix-batista/download.pdf"
## [5] "https://www.fbi.gov/wanted/kidnap/mark-himebaugh/download.pdf"
## [6] "https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht/download.pdf"
## [7] "https://www.fbi.gov/wanted/kidnap/ashley-summers/download.pdf"
## [8] "https://www.fbi.gov/wanted/kidnap/jayme-closs/download.pdf"
## [9] "https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff/download.pdf"
## [10] "https://www.fbi.gov/wanted/kidnap/carla-vicentini/download.pdf"
## [11] "https://www.fbi.gov/wanted/kidnap/lisa-irwin/download.pdf"
## [12] "https://www.fbi.gov/wanted/kidnap/kyron-richard-horman/download.pdf"
## [13] "https://www.fbi.gov/wanted/kidnap/bianca-lebron/download.pdf"
## [14] "https://www.fbi.gov/wanted/kidnap/jabez-spann/download.pdf"
## [15] "https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples/download.pdf"
## [16] "https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson/download.pdf"
## [17] "https://www.fbi.gov/wanted/kidnap/ruochen-liao/download.pdf"
## [18] "https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia/download.pdf"
## [19] "https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy/download.pdf"
## [20] "https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt/download.pdf"
## [21] "https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley/download.pdf"
## [22] "https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley/download.pdf"
## [23] "https://www.fbi.gov/wanted/kidnap/nefertiri-trader/download.pdf"
## [24] "https://www.fbi.gov/wanted/kidnap/kristen-modafferi/download.pdf"
## [25] "https://www.fbi.gov/wanted/kidnap/lashaya-stine/download.pdf"
## [26] "https://www.fbi.gov/wanted/kidnap/jonathan-fraser/download.pdf"
## [27] "https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil/download.pdf"
## [28] "https://www.fbi.gov/wanted/kidnap/faloma-luhk/download.pdf"
## [29] "https://www.fbi.gov/wanted/kidnap/maleina-luhk/download.pdf"
## [30] "https://www.fbi.gov/wanted/kidnap/kaylah-hunter/download.pdf"
## [31] "https://www.fbi.gov/wanted/kidnap/russell-john-mort/download.pdf"
## [32] "https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston/download.pdf"
## [33] "https://www.fbi.gov/wanted/kidnap/rondreiz-phillips/download.pdf"
## [34] "https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart/download.pdf"
## [35] "https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates/download.pdf"
## [36] "https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick/download.pdf"
## [37] "https://www.fbi.gov/wanted/kidnap/shausha-latine-henson/download.pdf"
## [38] "https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley/download.pdf"
## [39] "https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall/download.pdf"
## [40] "https://www.fbi.gov/wanted/kidnap/myra-lewis/download.pdf"4. Download the poster
Now:
- access each
- “download” (= write) the file
- needs a filename on your computer
4. Download the poster
Create filenames:
library(stringr)
file_names = paste(all_names, '.pdf', sep="")
file_names## [1] "ARIANNA FITTS.pdf"
## [2] "ANGELA MAE MEEKER.pdf"
## [3] "JENNIFER LYNN MARCUM.pdf"
## [4] "FELIX BATISTA.pdf"
## [5] "MARK HIMEBAUGH.pdf"
## [6] "MICHAELA JOY GARECHT.pdf"
## [7] "ASHLEY SUMMERS.pdf"
## [8] "JAYME CLOSS.pdf"
## [9] "ILENE BETH MISHELOFF.pdf"
## [10] "CARLA VICENTINI.pdf"
## [11] "LISA IRWIN.pdf"
## [12] "KYRON RICHARD HORMAN.pdf"
## [13] "BIANCA LEBRON.pdf"
## [14] "JABEZ SPANN.pdf"
## [15] "SHANNA GENELLE PEOPLES.pdf"
## [16] "ABBY LYNN PATTERSON.pdf"
## [17] "RUOCHEN LIAO.pdf"
## [18] "JOSHUA KESHABA SIERRA GARCIA.pdf"
## [19] "ALEXIS TIARA MURPHY.pdf"
## [20] "ERICA NICOLE HUNT.pdf"
## [21] "TIONDA Z. BRADLEY.pdf"
## [22] "DIAMOND YVETTE BRADLEY.pdf"
## [23] "NEFERTIRI R. TRADER.pdf"
## [24] "KRISTEN MODAFFERI.pdf"
## [25] "LASHAYA STINE.pdf"
## [26] "JONATHAN FRASER.pdf"
## [27] "AMINA AND BELEL KANDIL.pdf"
## [28] "FALOMA LUHK.pdf"
## [29] "MALEINA LUHK.pdf"
## [30] "KAYLAH HUNTER AND KRISTIAN JUSTICE.pdf"
## [31] "RUSSELL JOHN MORT.pdf"
## [32] "AKIA SHAWNTA EGGLESTON.pdf"
## [33] "RONDREIZ PHILLIPS.pdf"
## [34] "DEVONTE JORDAN HART.pdf"
## [35] "AMBER ELIZABETH CATES.pdf"
## [36] "SHAINA ASHLEY KIRKPATRICK.pdf"
## [37] "SHAUSHA LATINE HENSON.pdf"
## [38] "AMY LYNN BRADLEY.pdf"
## [39] "SUZANNE G. LYALL.pdf"
## [40] "MYRA LEWIS.pdf"4. Download the poster
Refine filenames:
refined_file_names = tolower(str_replace_all(string = file_names, pattern = " ", replacement = "_"))
refined_file_names## [1] "arianna_fitts.pdf"
## [2] "angela_mae_meeker.pdf"
## [3] "jennifer_lynn_marcum.pdf"
## [4] "felix_batista.pdf"
## [5] "mark_himebaugh.pdf"
## [6] "michaela_joy_garecht.pdf"
## [7] "ashley_summers.pdf"
## [8] "jayme_closs.pdf"
## [9] "ilene_beth_misheloff.pdf"
## [10] "carla_vicentini.pdf"
## [11] "lisa_irwin.pdf"
## [12] "kyron_richard_horman.pdf"
## [13] "bianca_lebron.pdf"
## [14] "jabez_spann.pdf"
## [15] "shanna_genelle_peoples.pdf"
## [16] "abby_lynn_patterson.pdf"
## [17] "ruochen_liao.pdf"
## [18] "joshua_keshaba_sierra_garcia.pdf"
## [19] "alexis_tiara_murphy.pdf"
## [20] "erica_nicole_hunt.pdf"
## [21] "tionda_z._bradley.pdf"
## [22] "diamond_yvette_bradley.pdf"
## [23] "nefertiri_r._trader.pdf"
## [24] "kristen_modafferi.pdf"
## [25] "lashaya_stine.pdf"
## [26] "jonathan_fraser.pdf"
## [27] "amina_and_belel_kandil.pdf"
## [28] "faloma_luhk.pdf"
## [29] "maleina_luhk.pdf"
## [30] "kaylah_hunter_and_kristian_justice.pdf"
## [31] "russell_john_mort.pdf"
## [32] "akia_shawnta_eggleston.pdf"
## [33] "rondreiz_phillips.pdf"
## [34] "devonte_jordan_hart.pdf"
## [35] "amber_elizabeth_cates.pdf"
## [36] "shaina_ashley_kirkpatrick.pdf"
## [37] "shausha_latine_henson.pdf"
## [38] "amy_lynn_bradley.pdf"
## [39] "suzanne_g._lyall.pdf"
## [40] "myra_lewis.pdf"4. Download the poster
Download each pdf from the url and use the refined filenames
for(i in 1:length(all_download_links)){
print(paste('Accessing URL: ', all_download_links[i], sep=""))
download.file(url = all_download_links[i]
, destfile = refined_file_names[i]
, mode = "wb")
}## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/arianna-fitts/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/angela-mae-meeker/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/jennifer-lynn-marcum/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/felix-batista/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/mark-himebaugh/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/michaela-joy-garecht/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/ashley-summers/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/jayme-closs/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/ilene-beth-misheloff/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/carla-vicentini/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/lisa-irwin/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/kyron-richard-horman/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/bianca-lebron/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/jabez-spann/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/shanna-genelle-peoples/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/abby-lynn-patterson/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/ruochen-liao/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/joshua-keshaba-sierra-garcia/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/copy_of_alexis-tiara-murphy/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/erica-nicole-hunt/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/tionda-z.-bradley/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/diamond-yvette-bradley/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/nefertiri-trader/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/kristen-modafferi/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/lashaya-stine/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/jonathan-fraser/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/amina-and-belel-kandil/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/faloma-luhk/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/maleina-luhk/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/kaylah-hunter/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/russell-john-mort/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/akia-shawnta-eggleston/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/rondreiz-phillips/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/devonte-jordan-hart/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/amber-elizabeth-cates/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/shaina-ashley-kirkpatrick/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/shausha-latine-henson/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/amy-lynn-bradley/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/suzanne-g.-lyall/download.pdf"
## [1] "Accessing URL: https://www.fbi.gov/wanted/kidnap/myra-lewis/download.pdf"Notes on webscraping
- highly customisable (= juicy data)
- basically: “anything goes”
- can be unstable/sensitive to html changes
What this means
Same idea, different code details:
What this means
Same idea, different code details:
What this means
Same idea, different code details:
What this means
Same idea, different code details:
RECAP
- Always: problem first, never the method first!
- Method follows problem!
- HTML structure key to ‘real’ webscraping
- Webscraping:
- understanding the structure of a webpage
- exploiting that structure for web-scraping
- principle is always the same: understand + exploit the html structure
Outlook
Tutorial: APIs + Webscraping in R
Homework: Do the readings for today (blogposts/guides)
Next week: Text data 1