Laboratório de Econometria
Lab. 2 - Tidyverse
Lab. 2
Antonio Vinícius Barbosa
19-08-2024
![]()
Pacotes do tidyverse
O tidyverse é uma coleção de pacotes que facilitam a organização e visualização de dados.
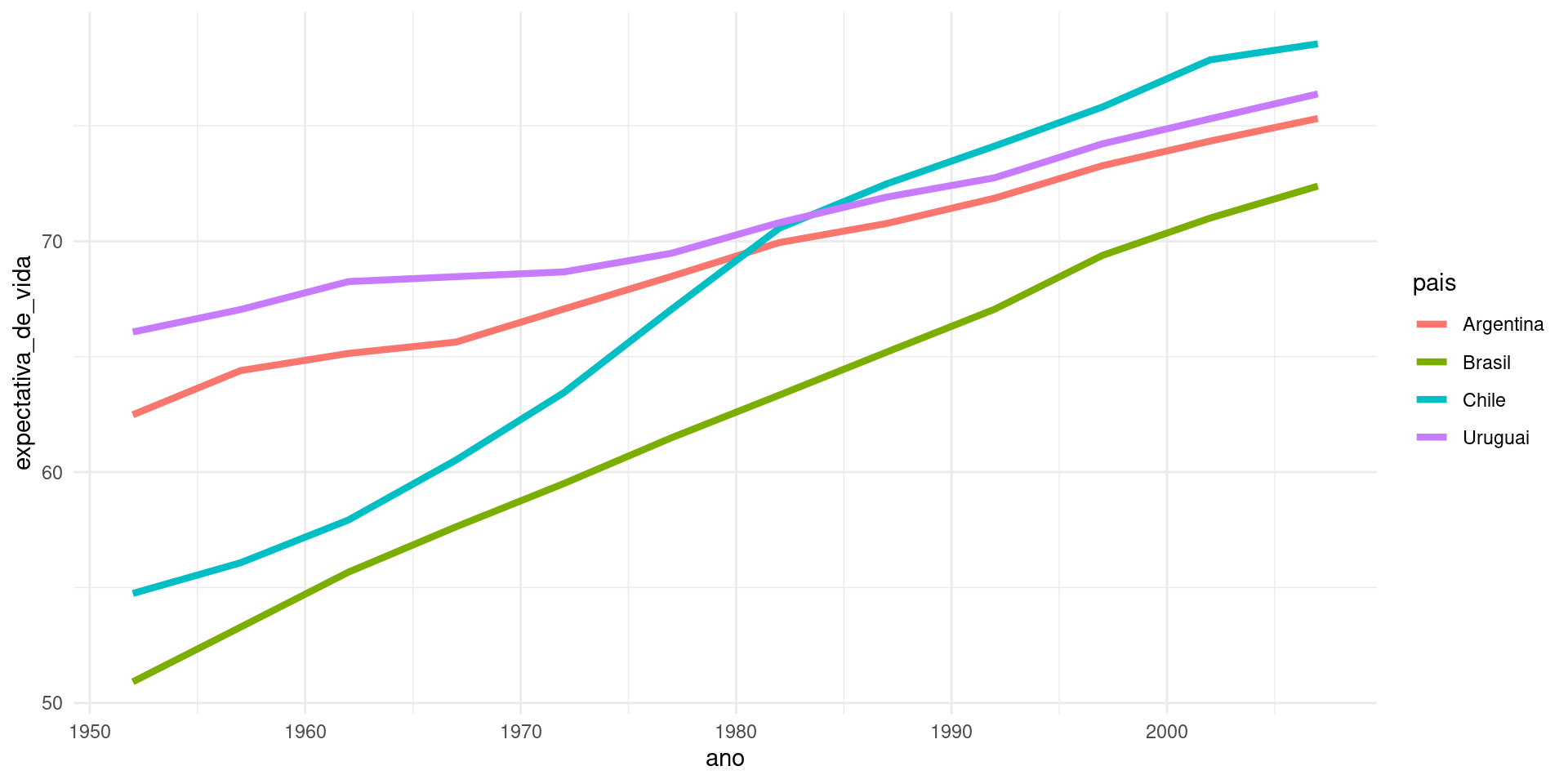
Nesta aula, utilizaremos como exemplo os dados do Gapminder, com informações sobre países ao longo do tempo.
O pacote readr
O pacote readr oferece algumas funcionalidades que facilitam a leitura de dados no formato retangular. As principais funções do pacote readr são:
read_csv(): arquivos separados por vírgularead_csv2(): arquivos separados por ponto-e-vírgularead_delim(): arquivos separados por qualquer delimitador
![]()
Para ler os dados, fazemos:
O pacote dplyr
- O
dplyré um pacote bastante útil para manipular dados. - Os códigos são escritos de uma maneira intuitiva e elegante.
- Se utilizam dos pipes para realizar operações sequenciais.

As principais funções do dplyr são:
select(): seleciona por coluna do banco de dadosfilter(): seleciona linhas baseado em seu valormutate(): cria/modifica colunas baseado em colunas existentessummarise(): realiza operações sobre um conjunto de valoresarrange(): reordena as linhas da base de dados
A função select()
Utilizamos select() para selecionar colunas ou variáveis dos dados:
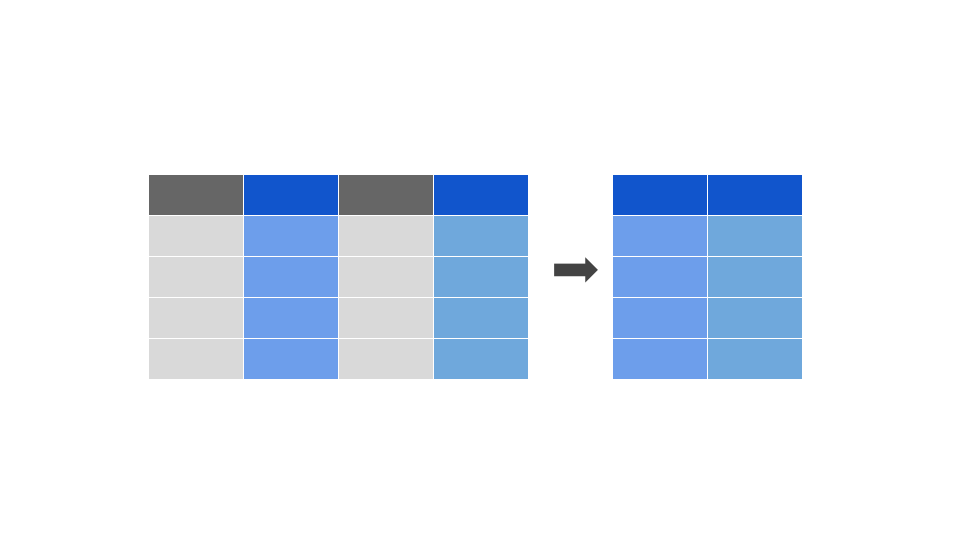
A função filter()
A função filter() permite selecionar observações baseado em seus valores ou em uma condição:
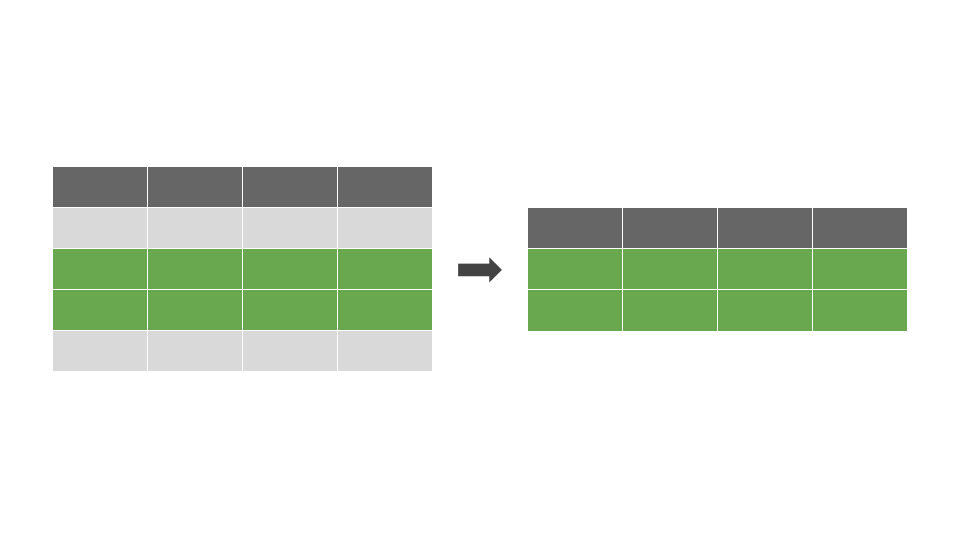
A função mutate()
Utilizamos mutate() para criar ou modificar variáveis (colunas) baseado em outras variáveis do banco de dados:
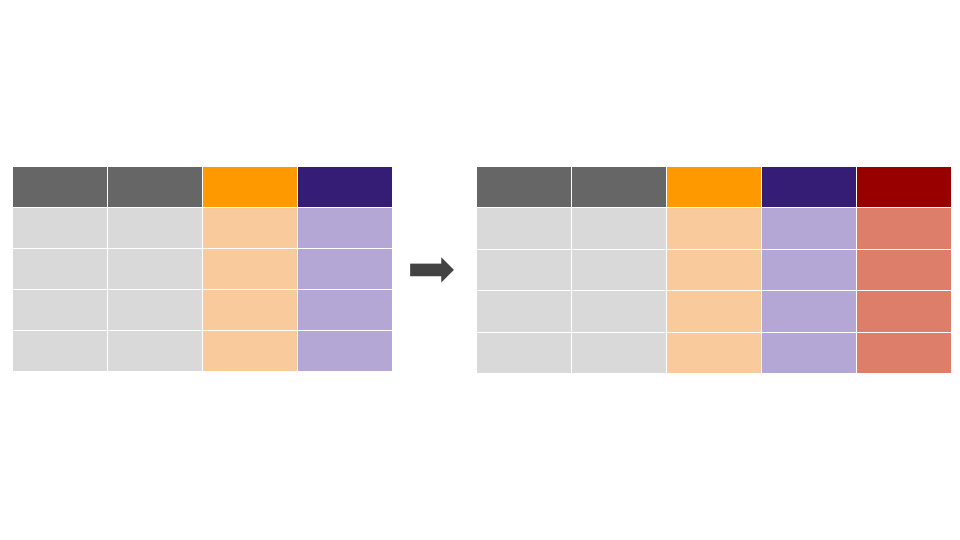
A função arrange()
Utilizamos mutate() ordena a base de dados, baseada em uma ou mais variáveis:
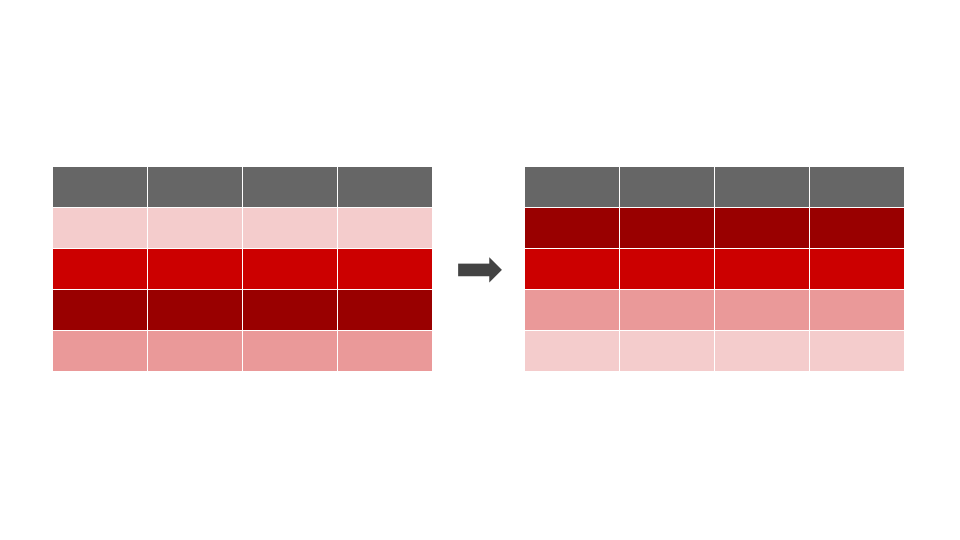
A função summarise()
A função summarise() realiza operações sobre um conjunto de observações, reduzindo variáveis a valores.
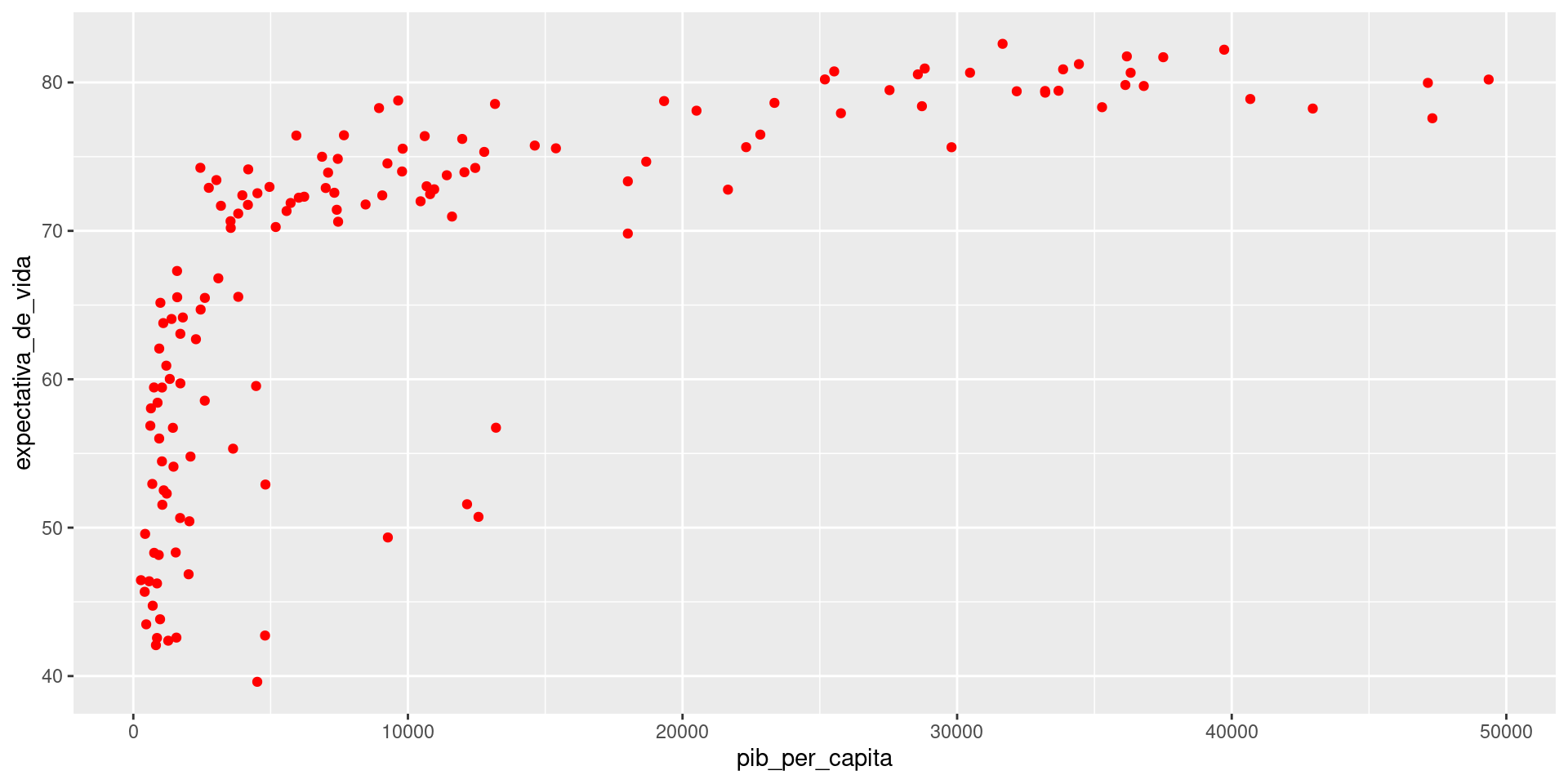
O pacote ggplot2
O pacote ggplot2 é um dos mais elegantes e flexíveis ferramentas de visualização gráfica do R.
![]()
- Possui lógica semelhante ao pipe (
|>), onde é possível adicionar camadas e informações através de um operador sequencial (+) - Através dele, podemos definir sistematicamente quais são as camadas de um gráfico e como eles se interelacionam.
O pacote ggplot2
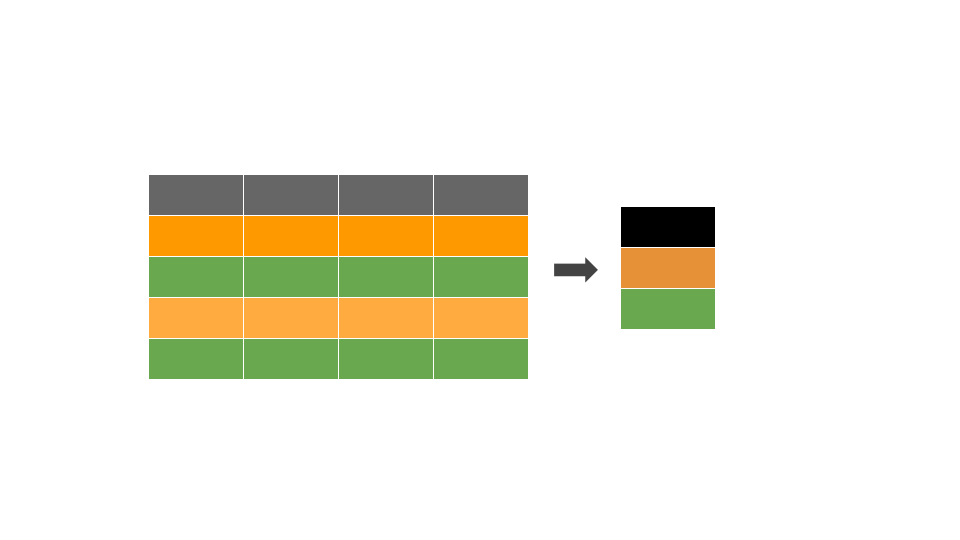
O pacote ggplot2
De forma geral, existem quatro partes fundamentais para a visualização no ggplot2:
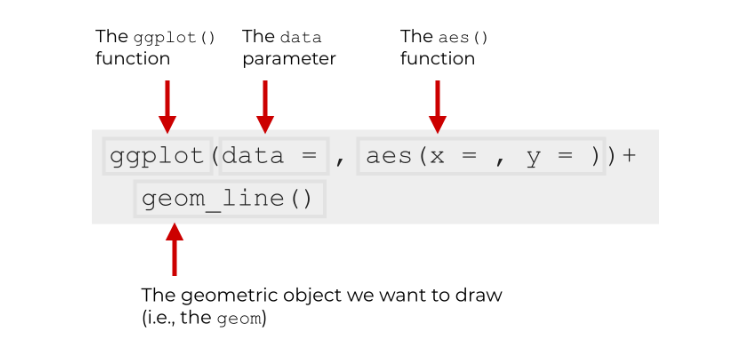
O pacote ggplot2