Introdução à Ciência de Dados no R
Aula 09 - Visualização de Dados
Aula 09
Antonio Vinícius Barbosa
16-04-2024
Visualização de Dados
“Um simples gráfico trouxe mais informações ao analista de dados do que qualquer outro dispositivo.” (John Tukey, Exploratory Data Analysis, 1977)

O pacote ggplot2
O ggplot2 faz parte do toolkit do tidyverse para ciência de dados.
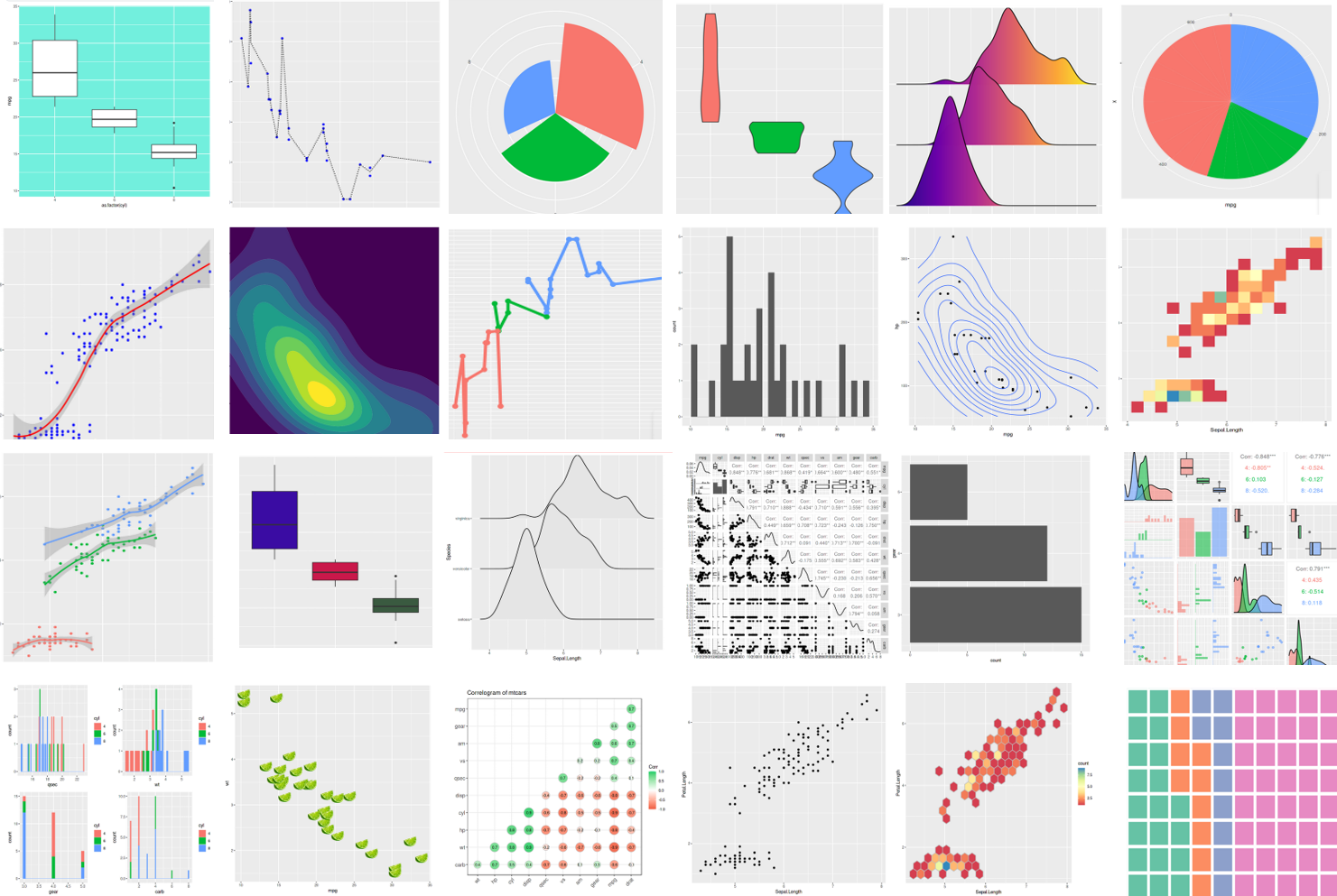
Alguns exemplos
Gramática dos Gráficos
A gramática dos gráficos nos permite descrever concisamente os componentes (ou camadas) de um gráfico.
No
ggplot2, existem 7 camadas principais:

A camada Data
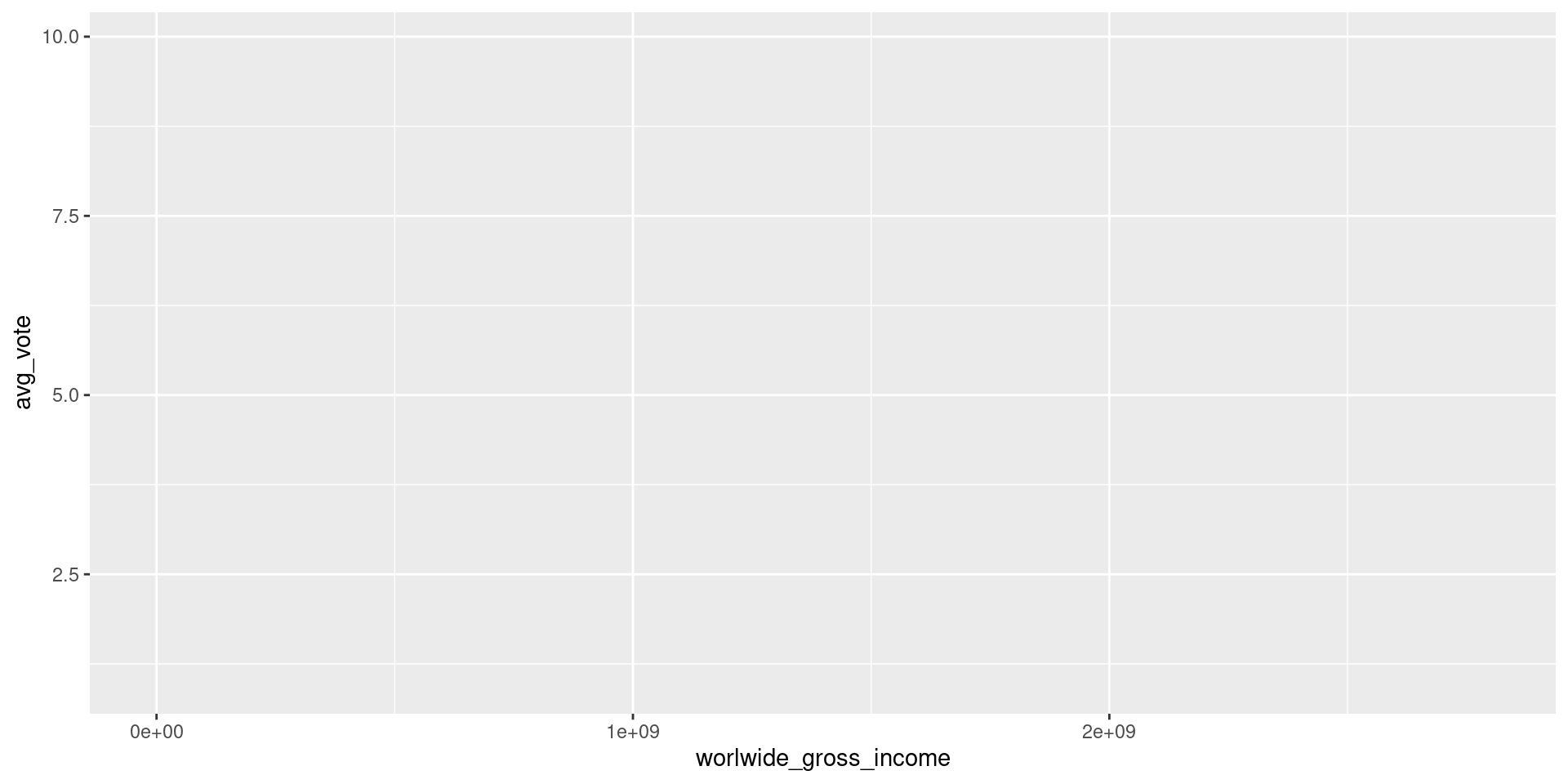
A camada Data especifica o conjunto de dados a ser plotado.

A camada Data

Como resultado, temos apenas um quadro em branco (cinza, na verdade!). Precisamos adicionar mais camadas ao gráfico.
A camada Aesthetic
A camada Aesthetic, ou simplesmente aes, adiciona os eixos (variáveis) e seus elementos visuais.

A camada Aesthetic
Como resultado, saimos de um quadro em branco para a representação das variáveis nos eixos x e y. Precisamos informar o tipo (geometria) de gráfico!
A camada Geometries
A camada Geometries é utilizada para o mapeamento das informações e define a forma como os dados serão apresentados.

A camada Geometries
Sintaxe básica
De forma geral, existem quatro partes fundamentais para a visualização no ggplot2:
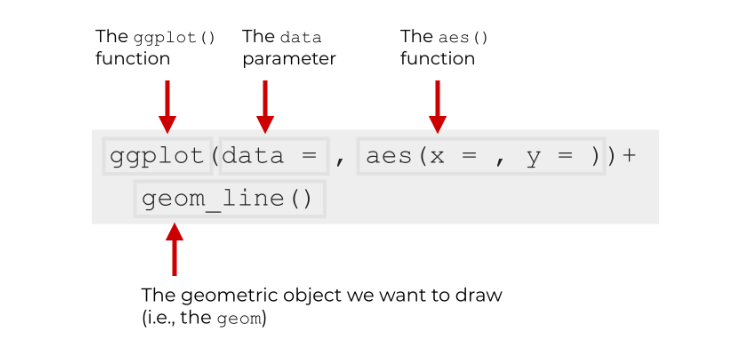
A função ggplot(), a camada data, os parâmetros aes() e a camada de geometria, especificada por geom_xxx()
A camada Geometries
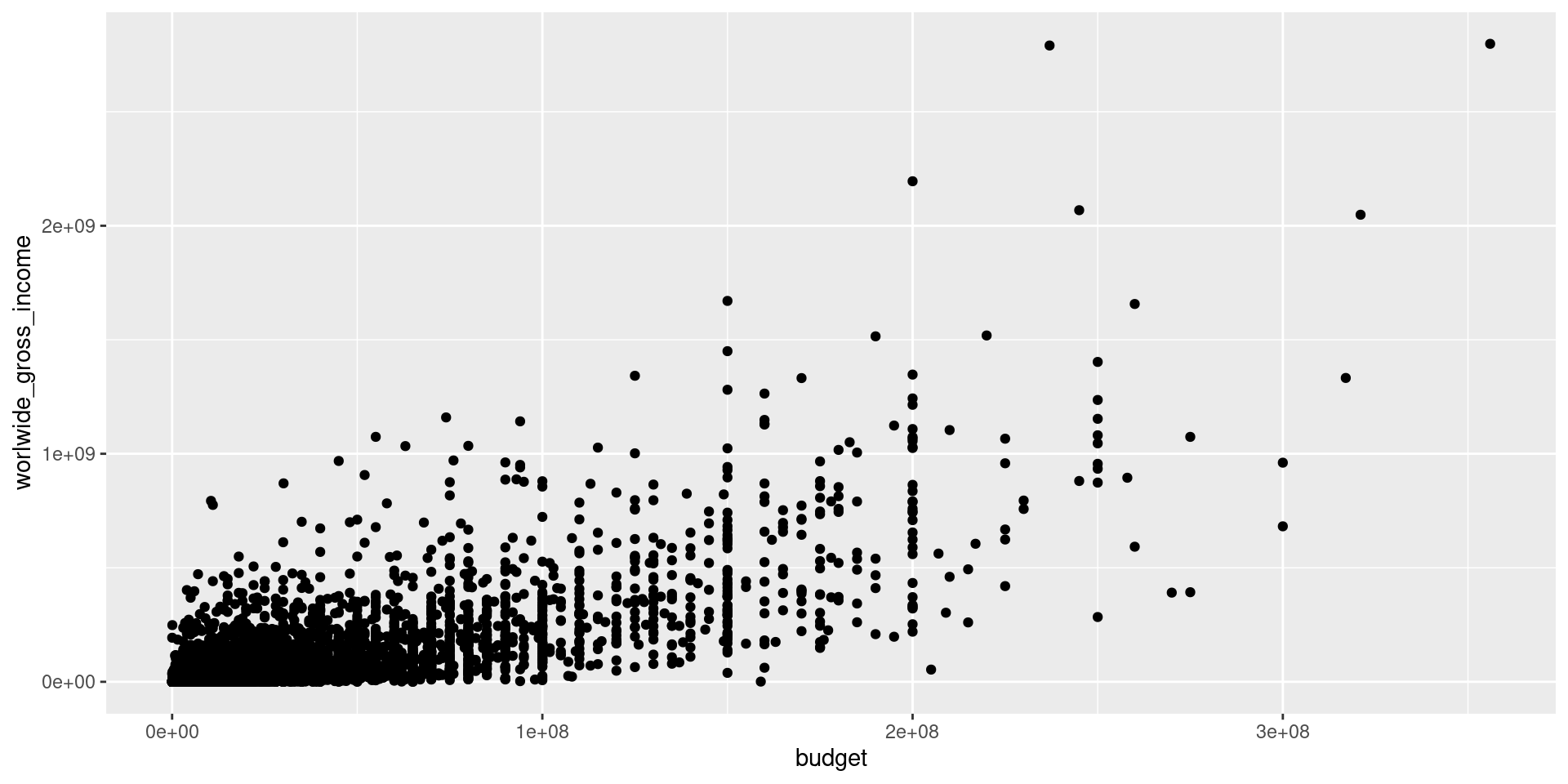
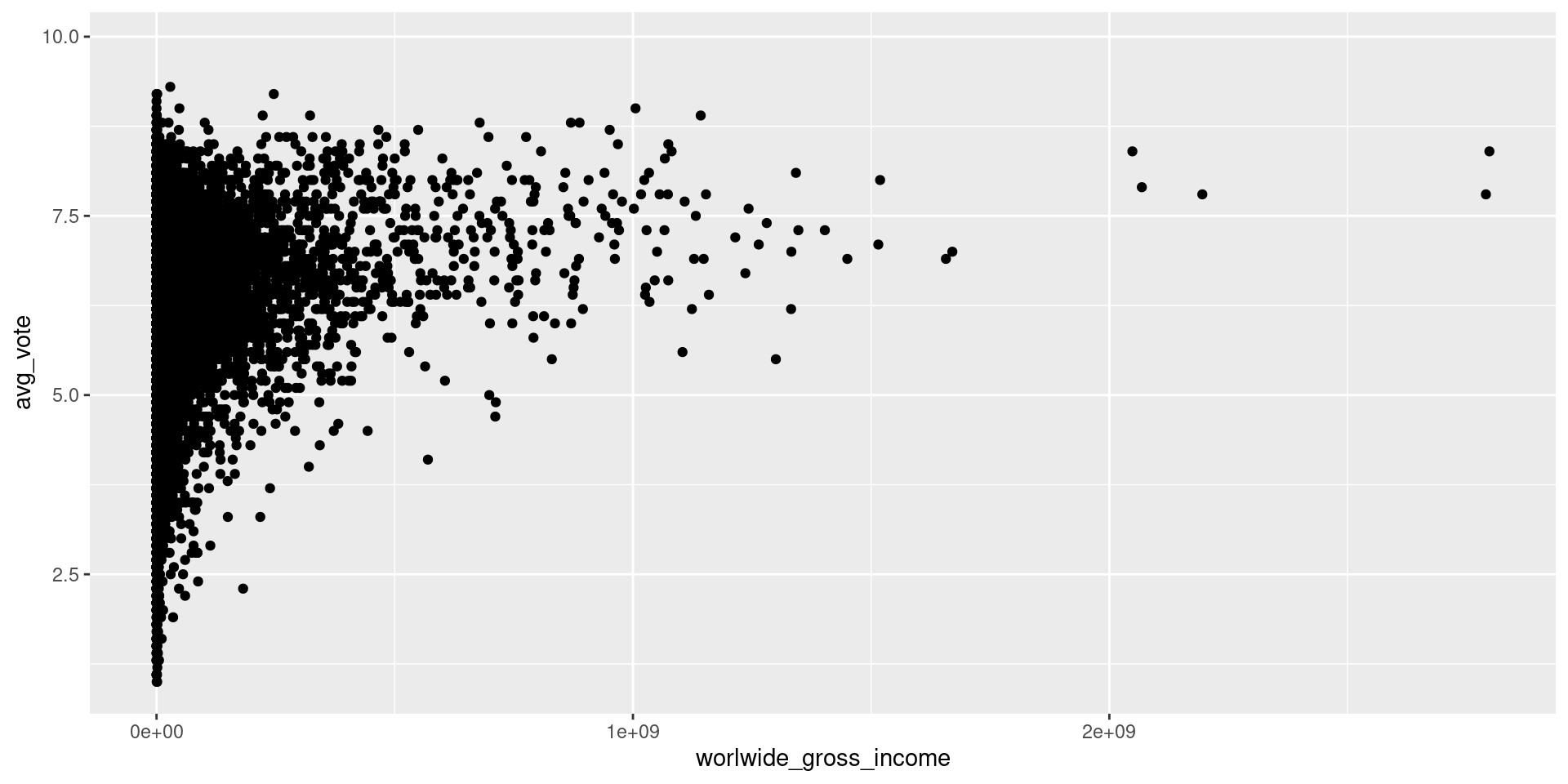
A camada Geometries
É possível alterar alguns elementos da geometria geom_point(), tais como cor, transparência, formato, tamanho,…
A camada Geometries
A camada Geometries
A camada Geometries
A camada Geometries
A camada Geometries
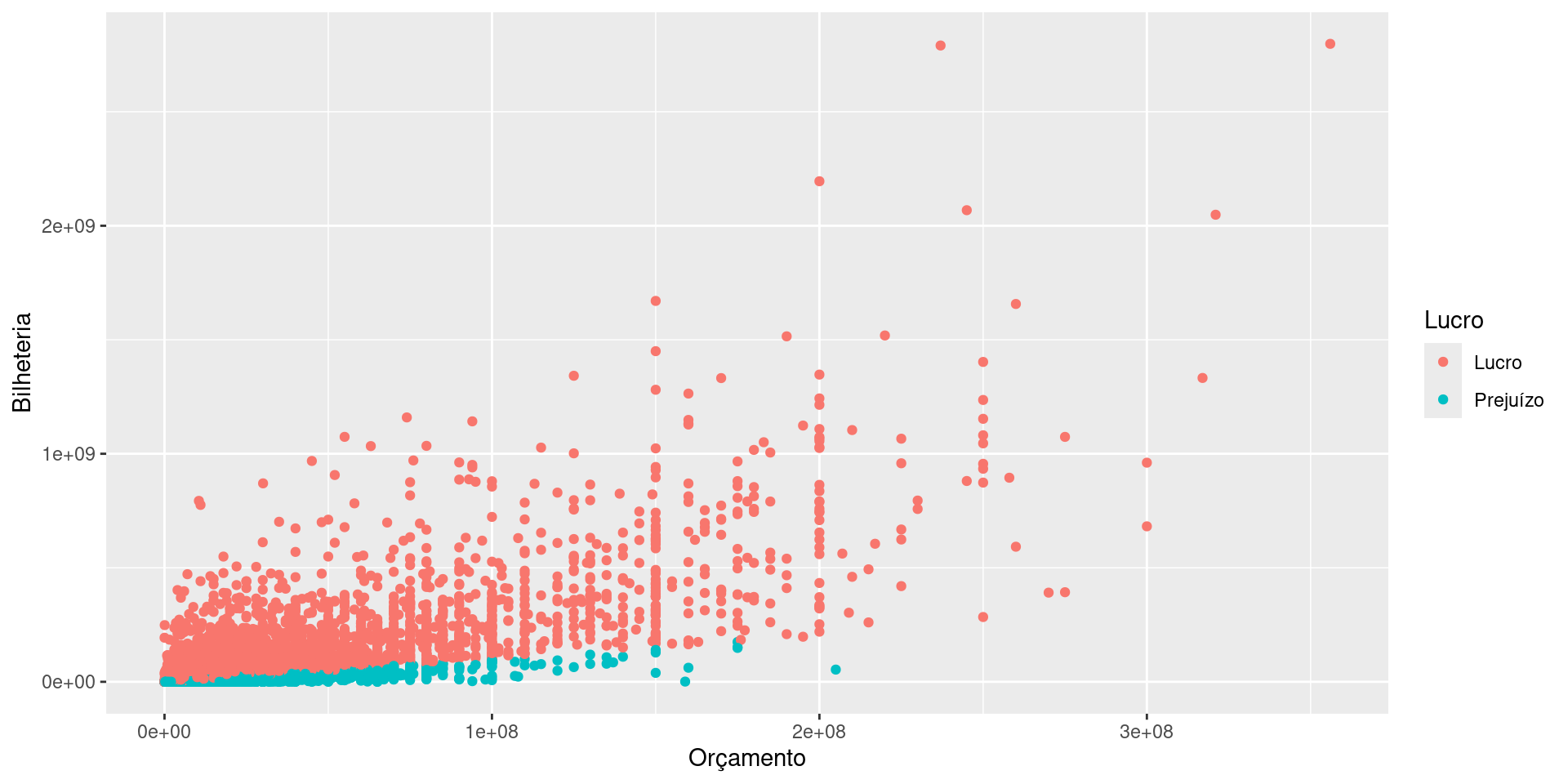
A camada Geometries
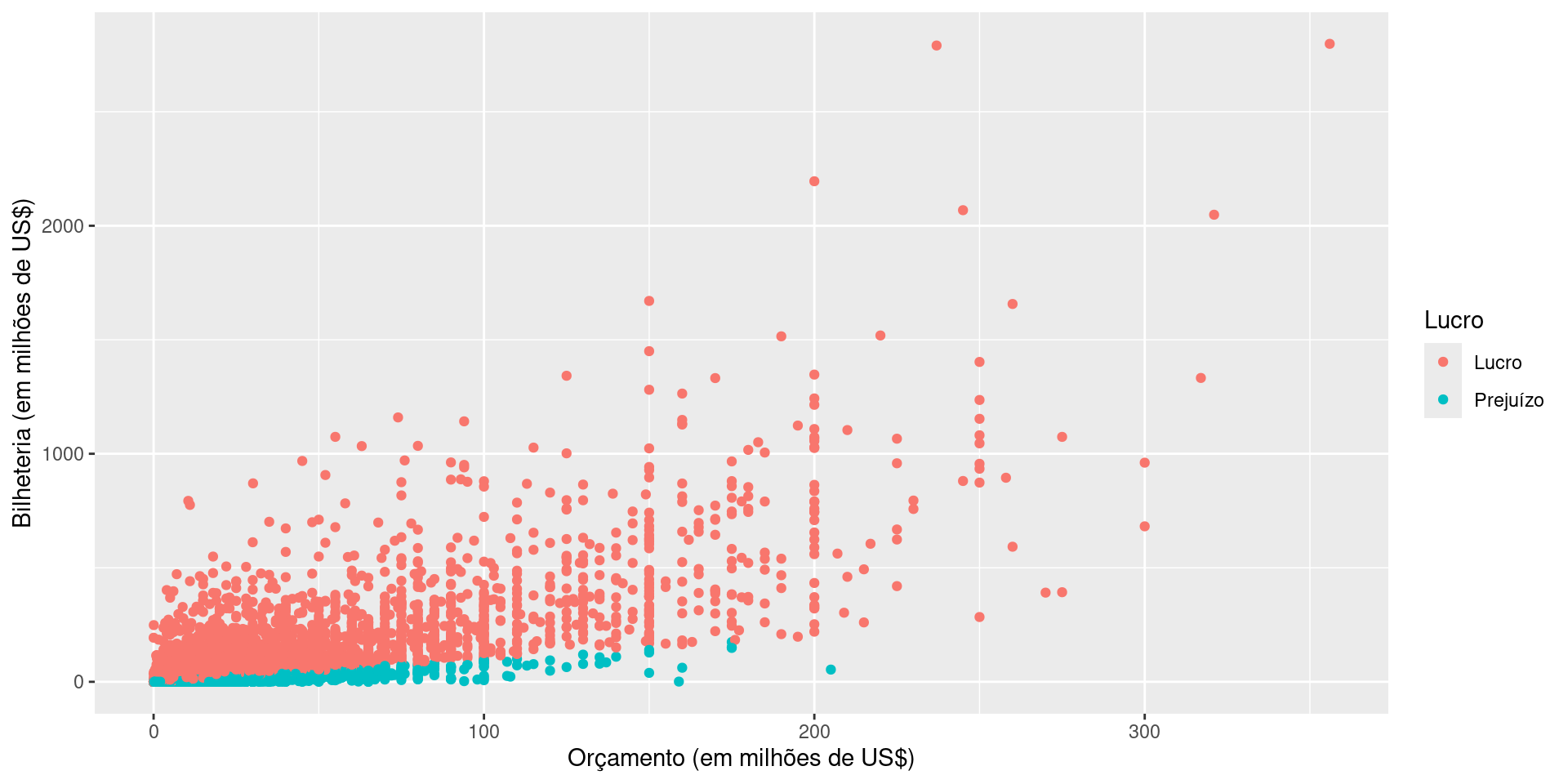
A camada Geometries
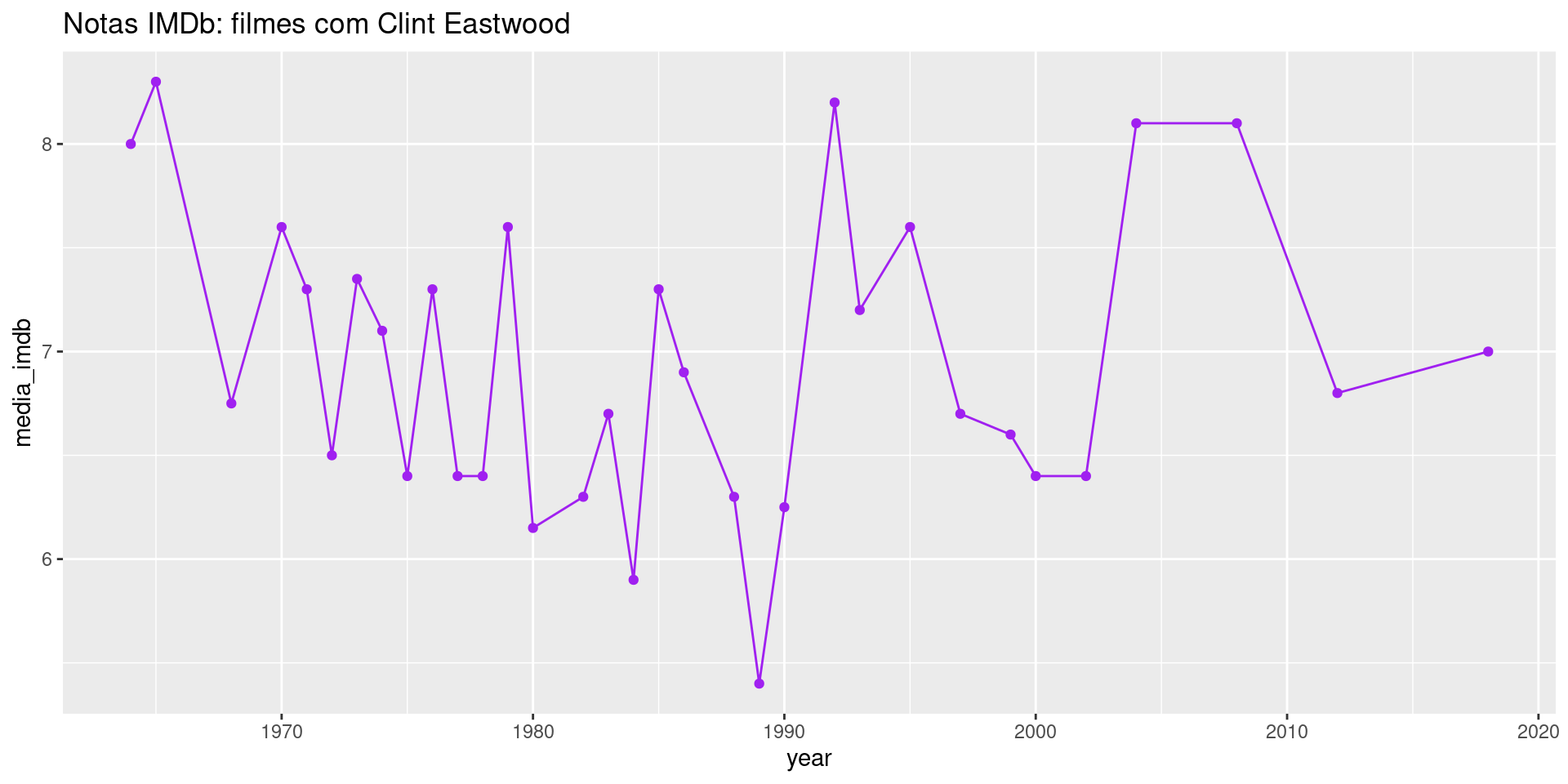
A camada Geometries
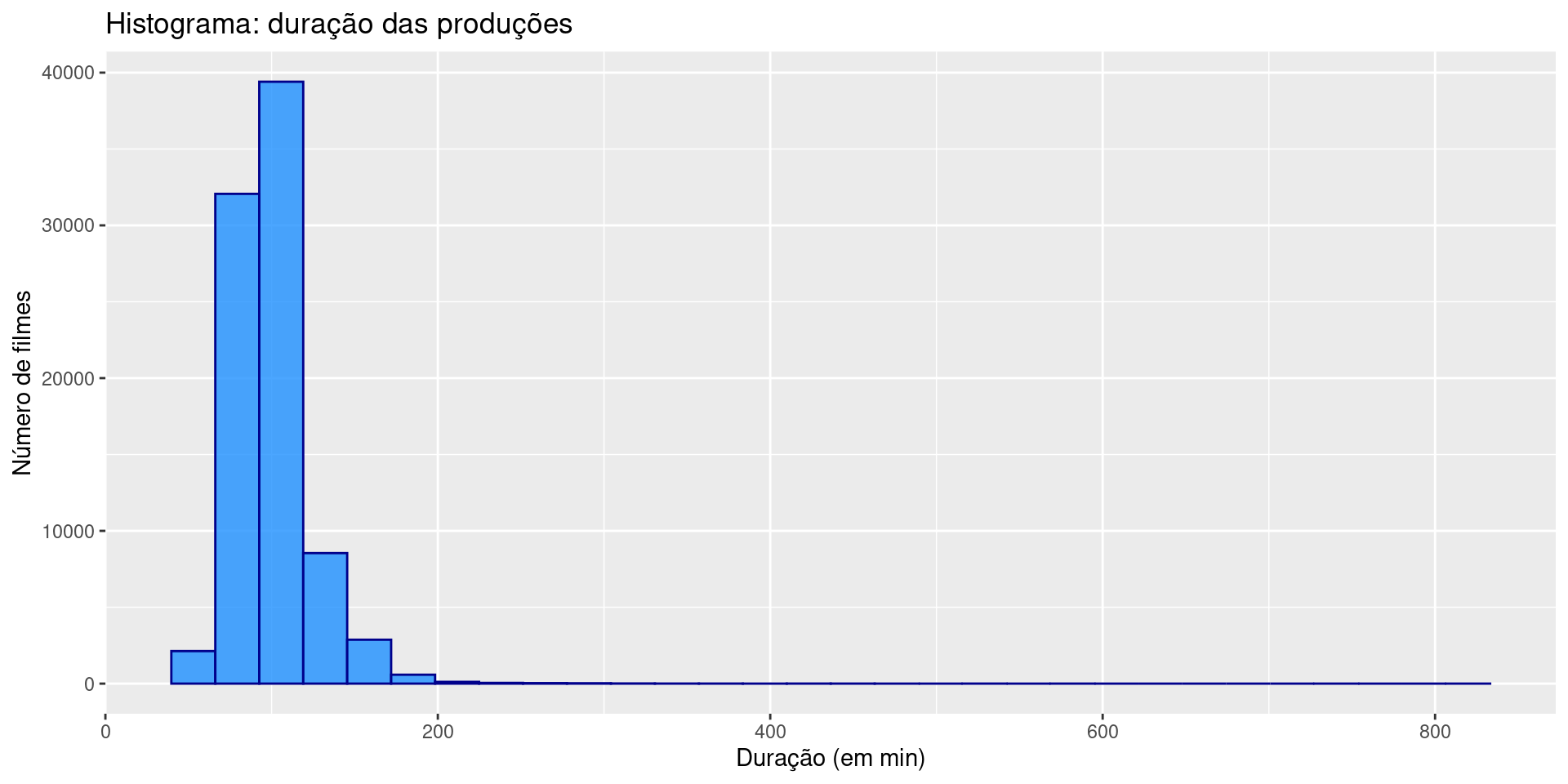
A camada Geometries
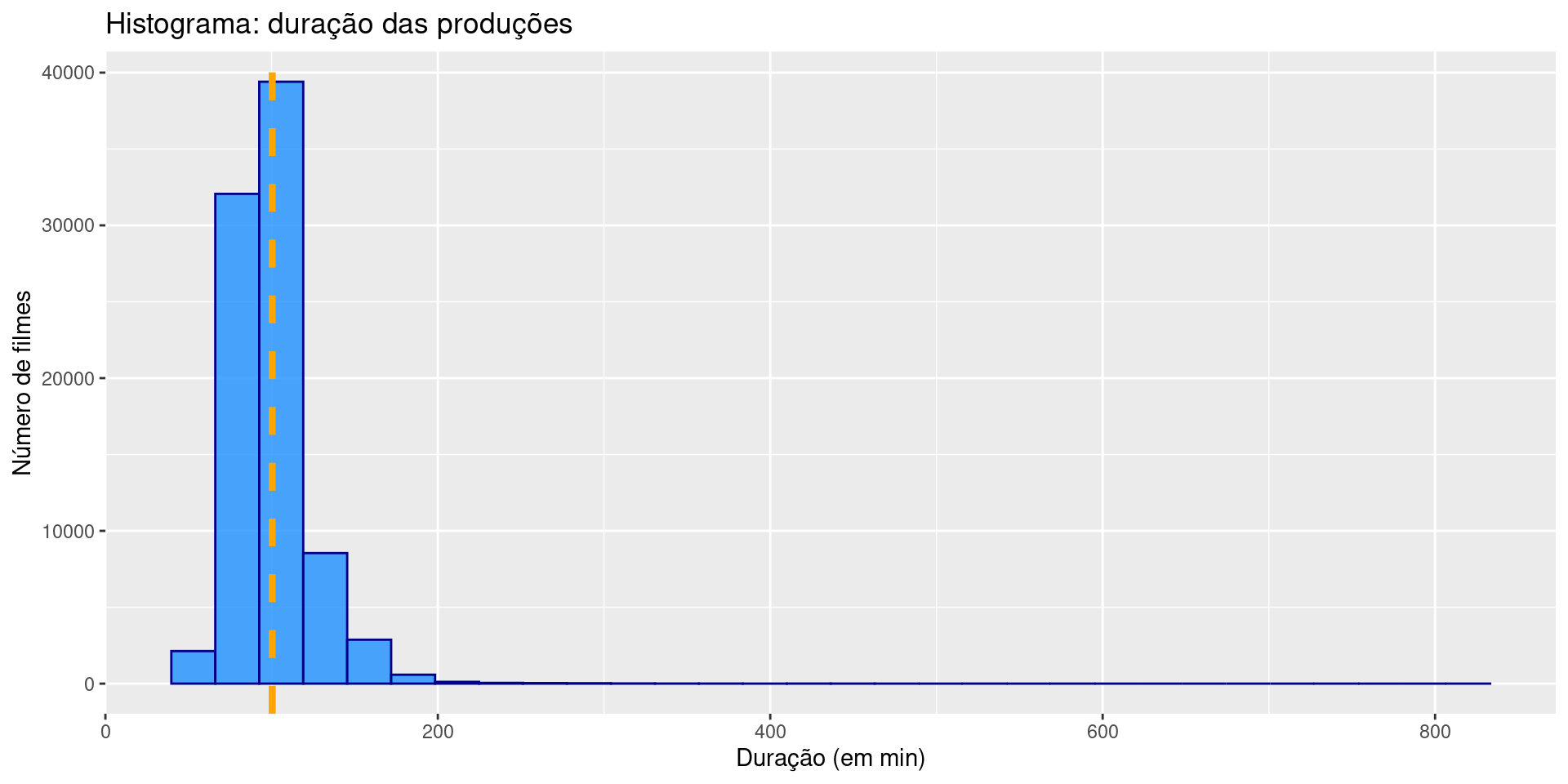
A camada Geometries
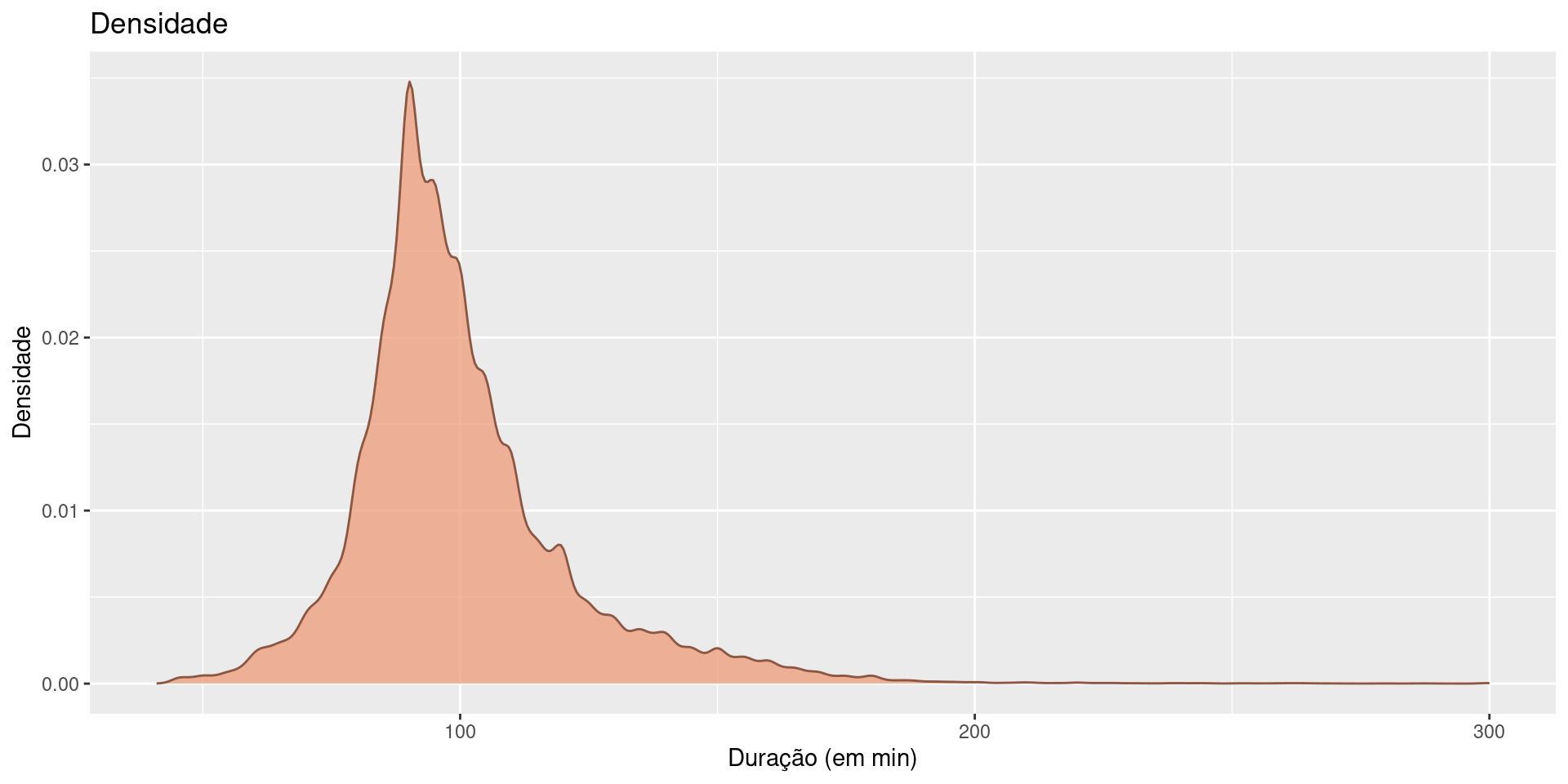
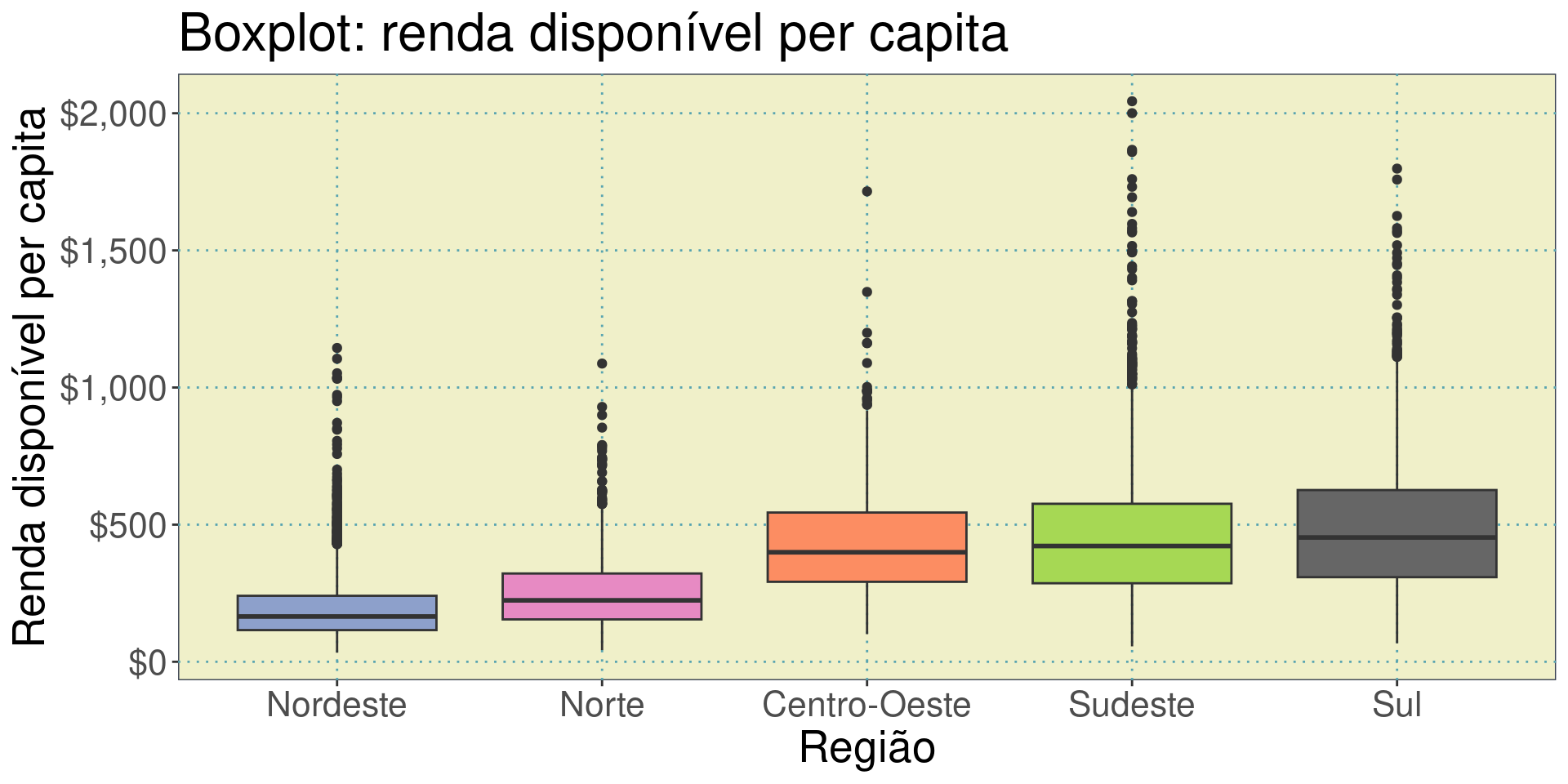
Boxplots
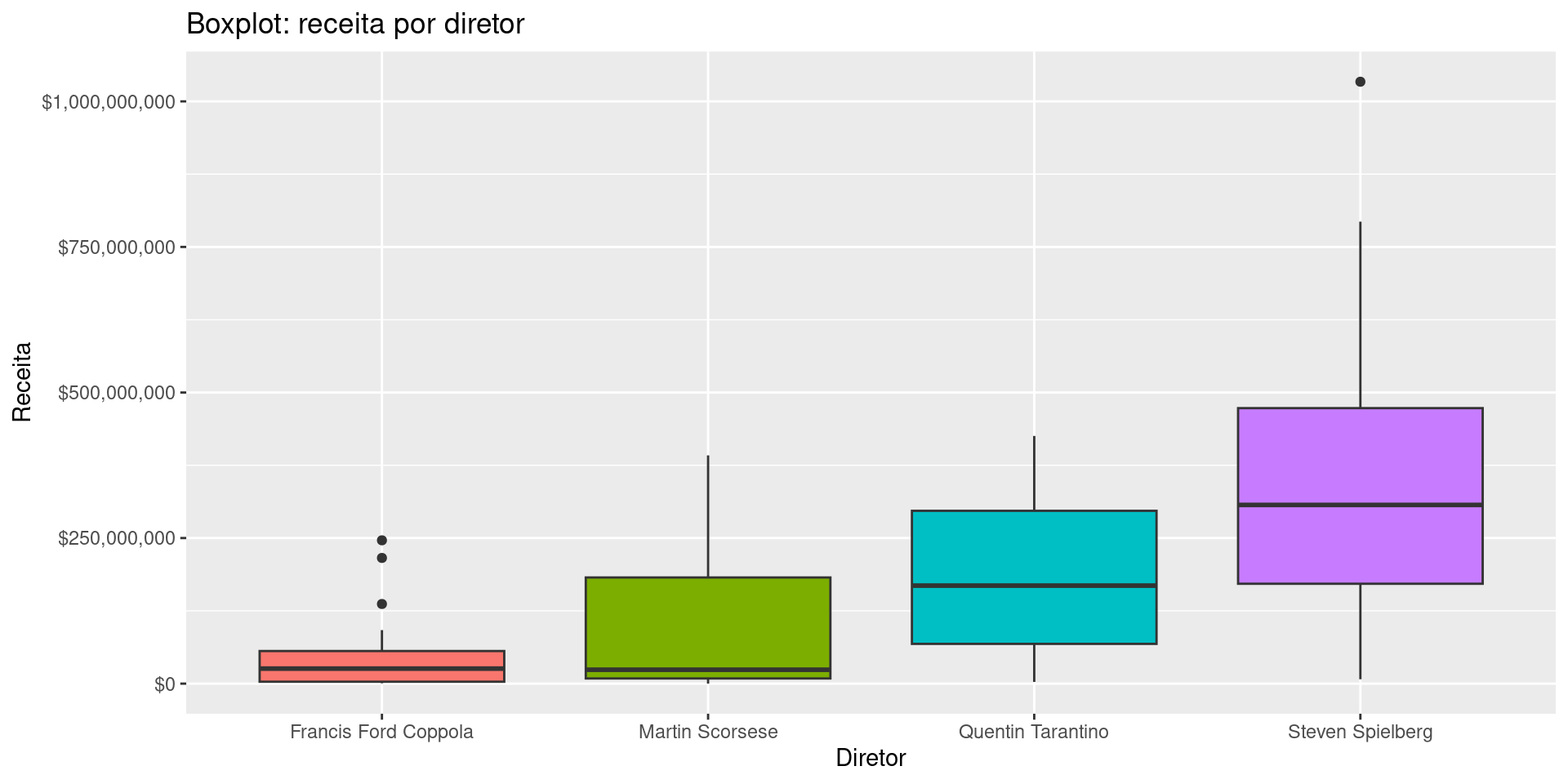
Gráfico de barras
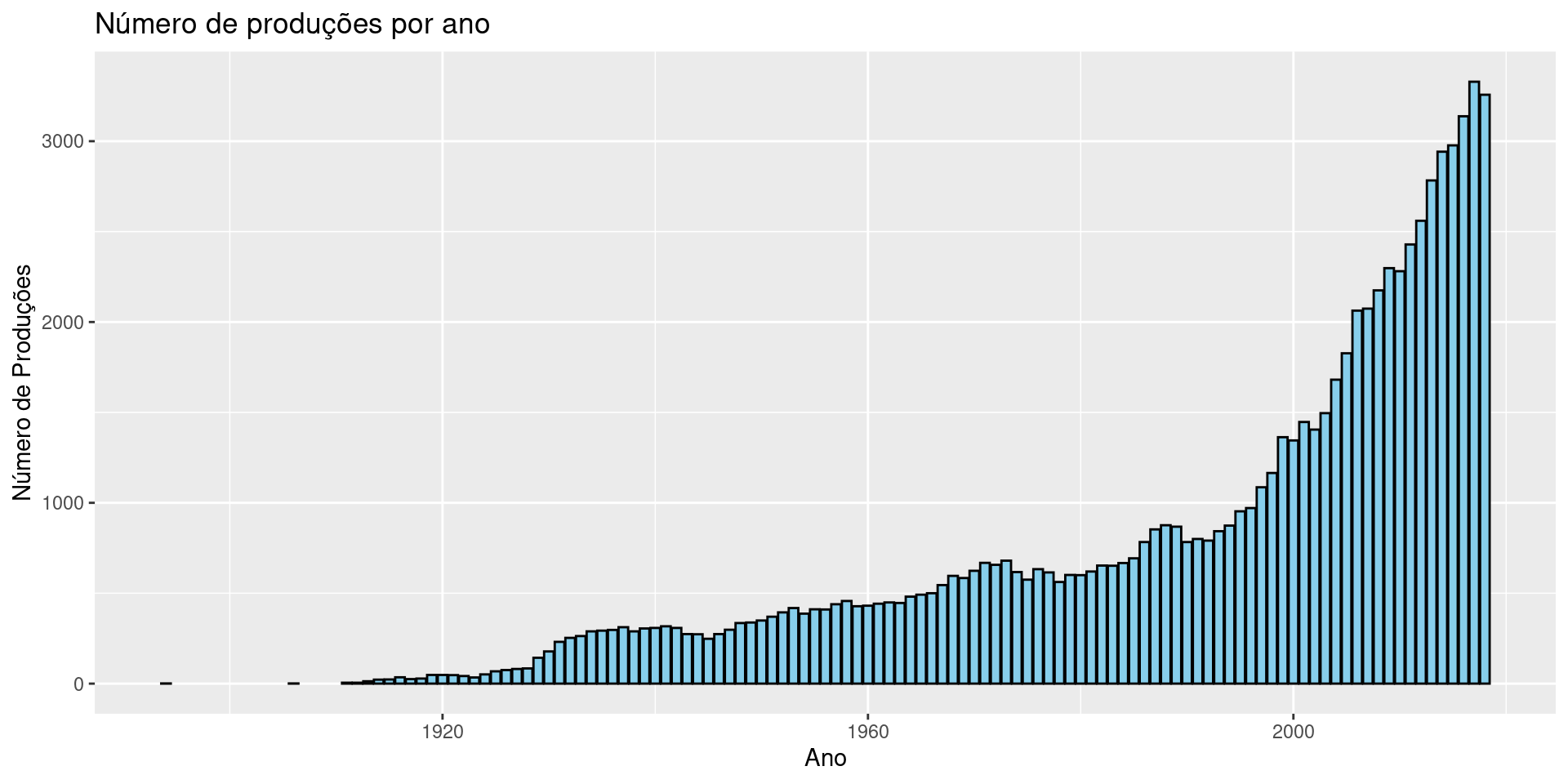
Gráfico de barras
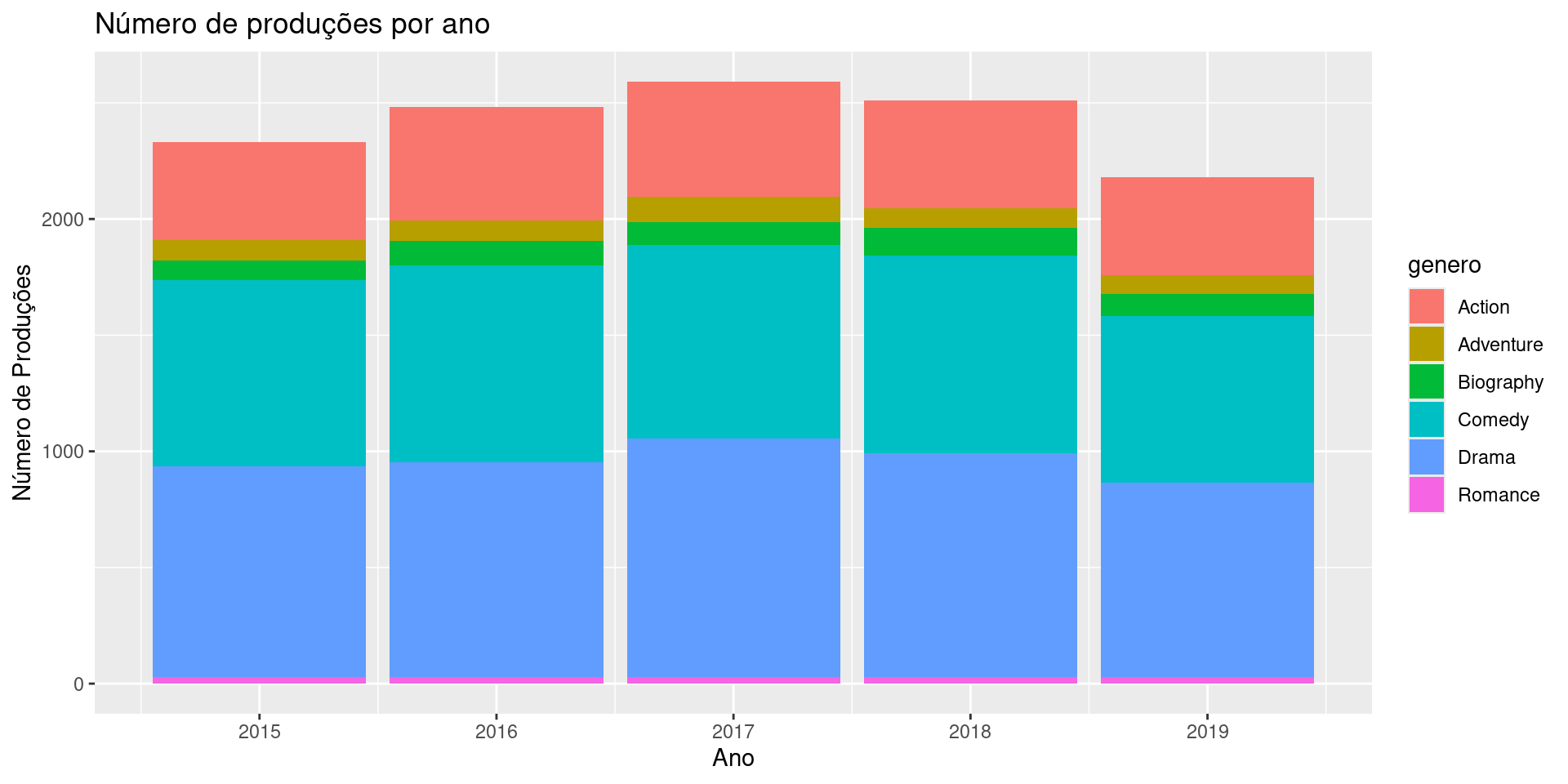
Gráfico de barras
Alternativamente
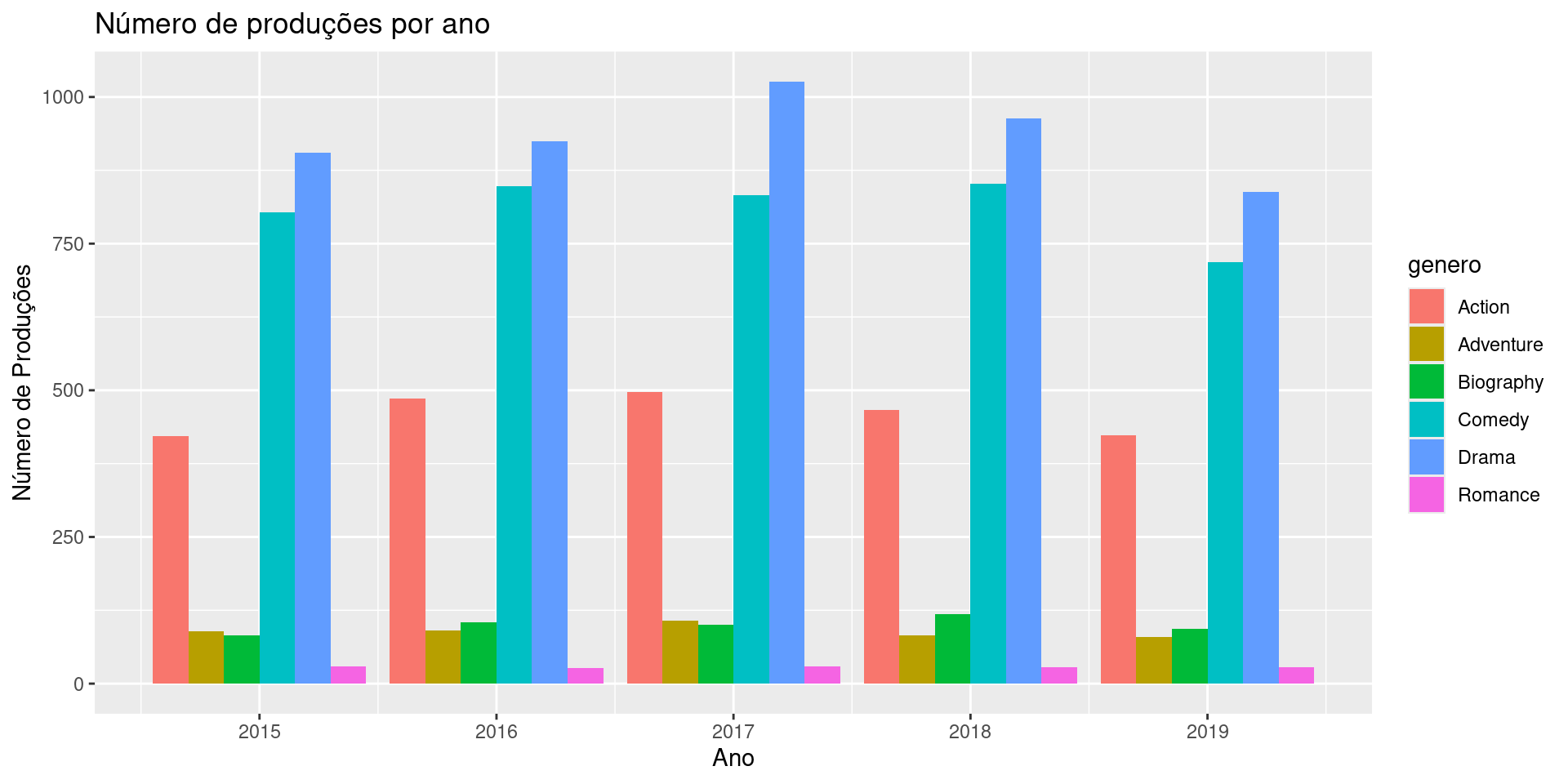
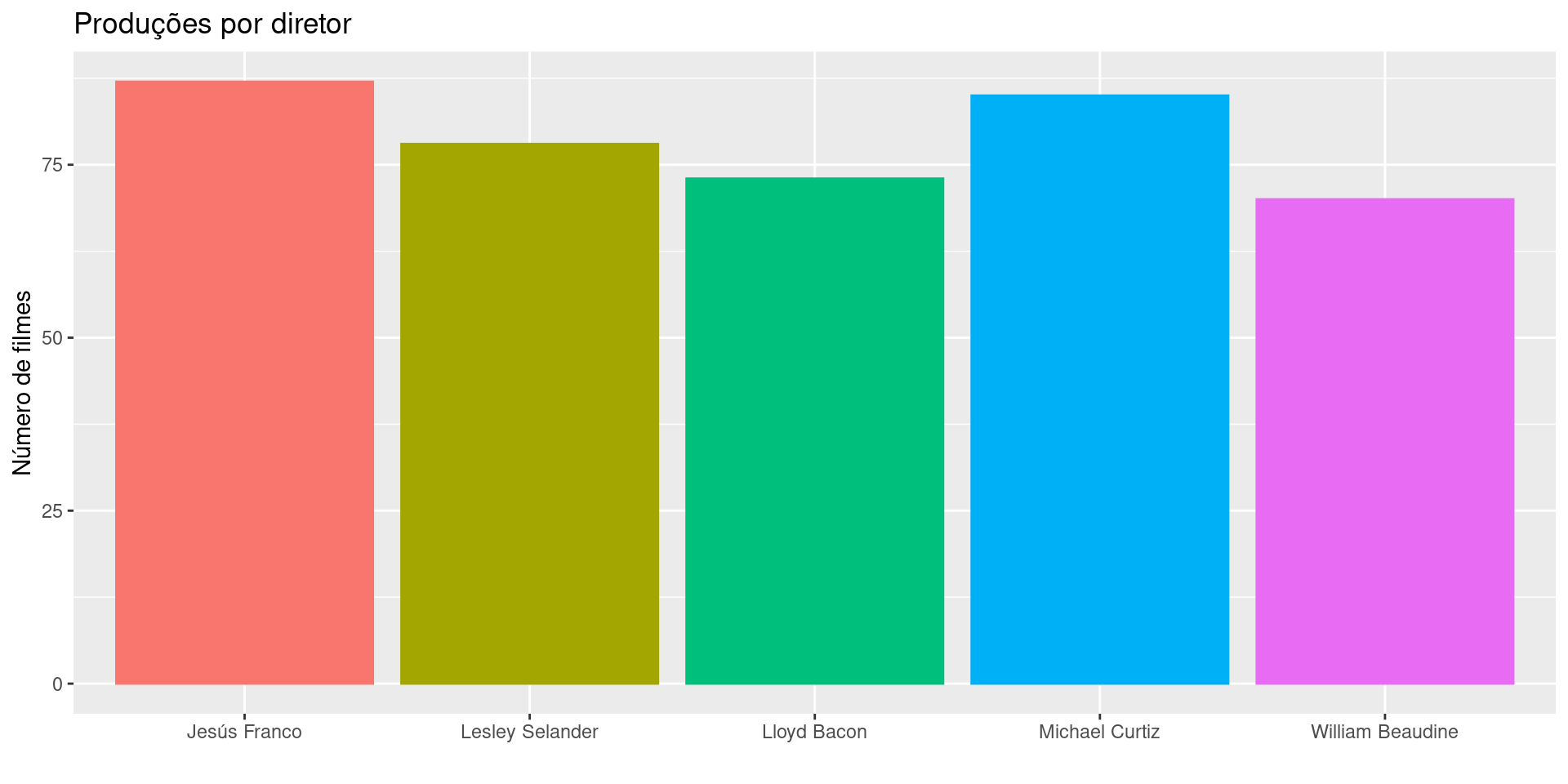
Gráfico de barras
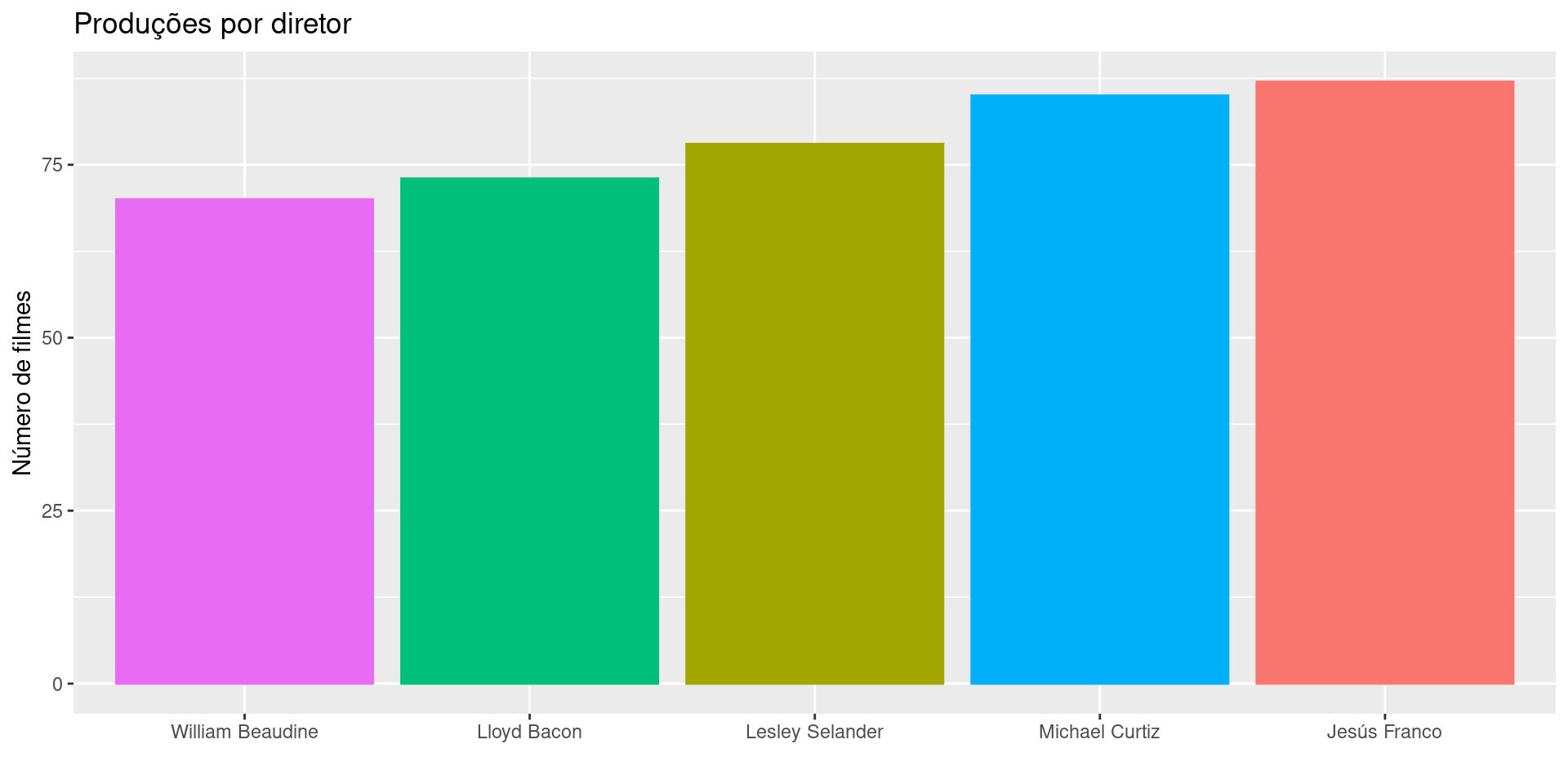
Perceba que os diretores foram apresentados em ordem alfabética. Para colocar em ordem crescente, fazemos:
Gráfico de barras
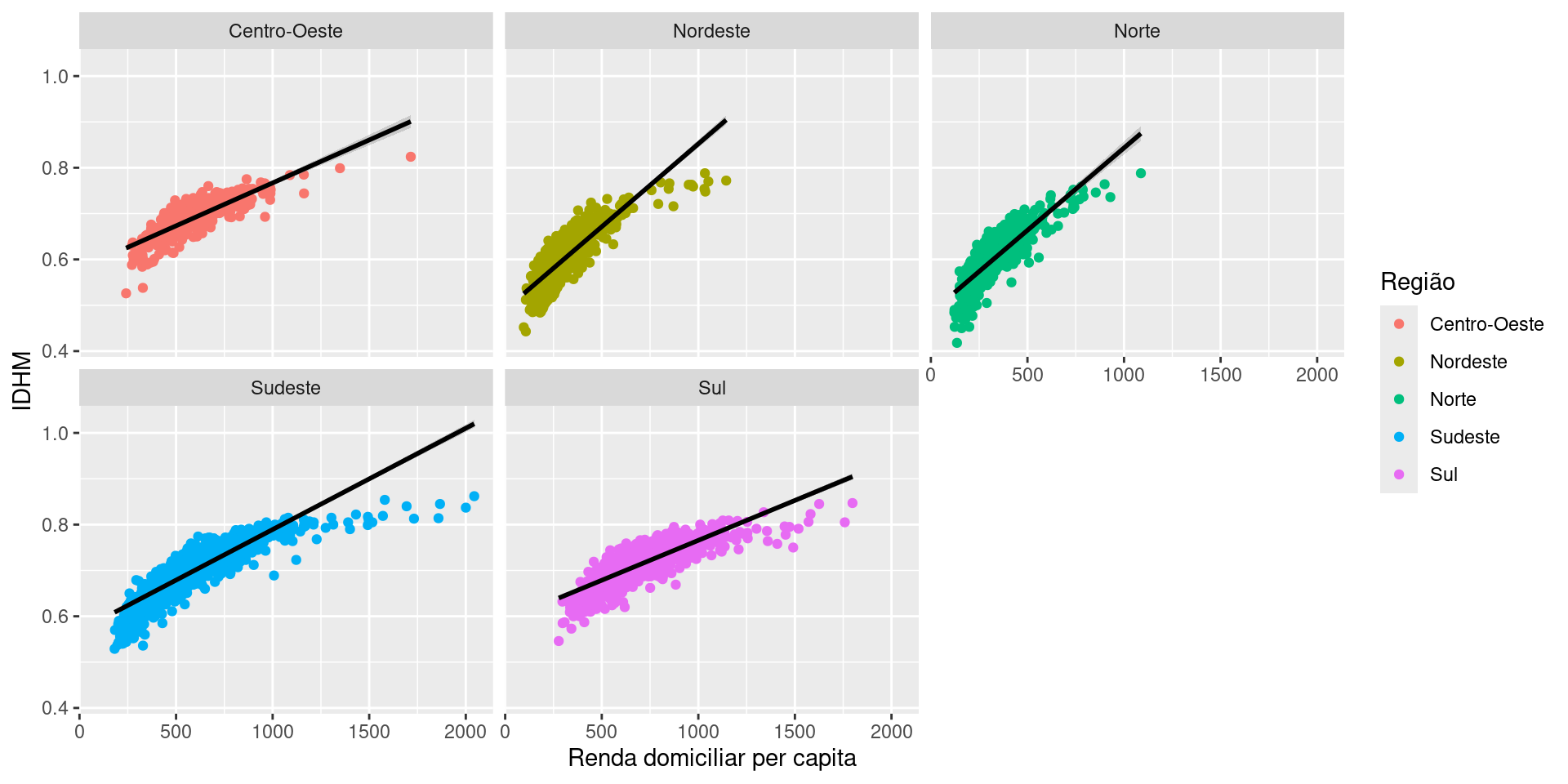
A camada Facets
Outra funcionalidade bastante útil é a possibilidade de usar facets para replicar um gráfico para cada categorias de uma variável.

Para exemplificar esta camada, vamos criar uma variável com o primeiro gênero de cada filme, conforme código a seguir.
A camada Facets
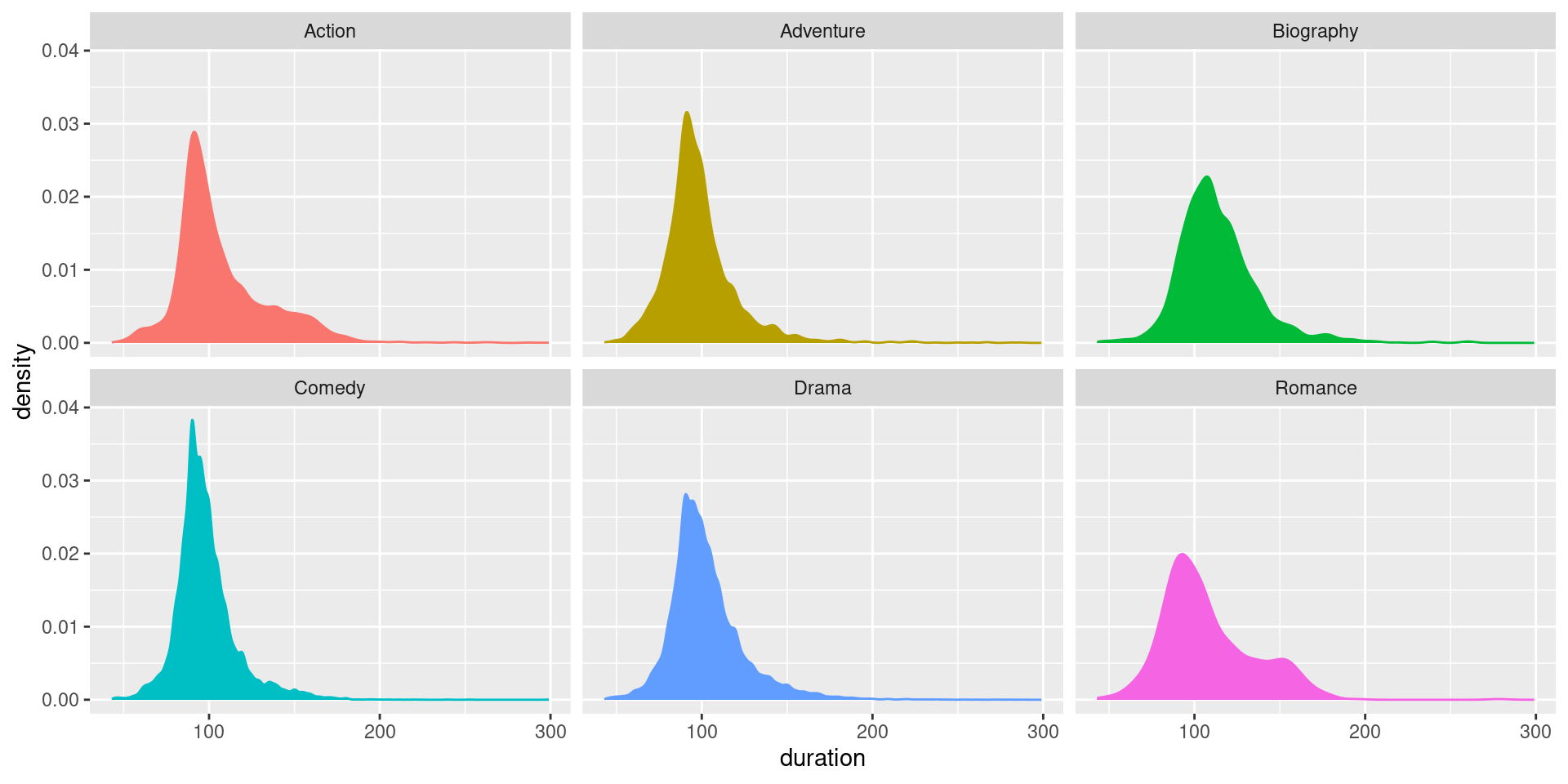
A camada Statistics
A camada Statistics permite plotar estatísticas calculadas a partir dos dados.

A camada Statistics
Primeiro, podemos plotar a relação linear entre a renda per capita e o IDHM:
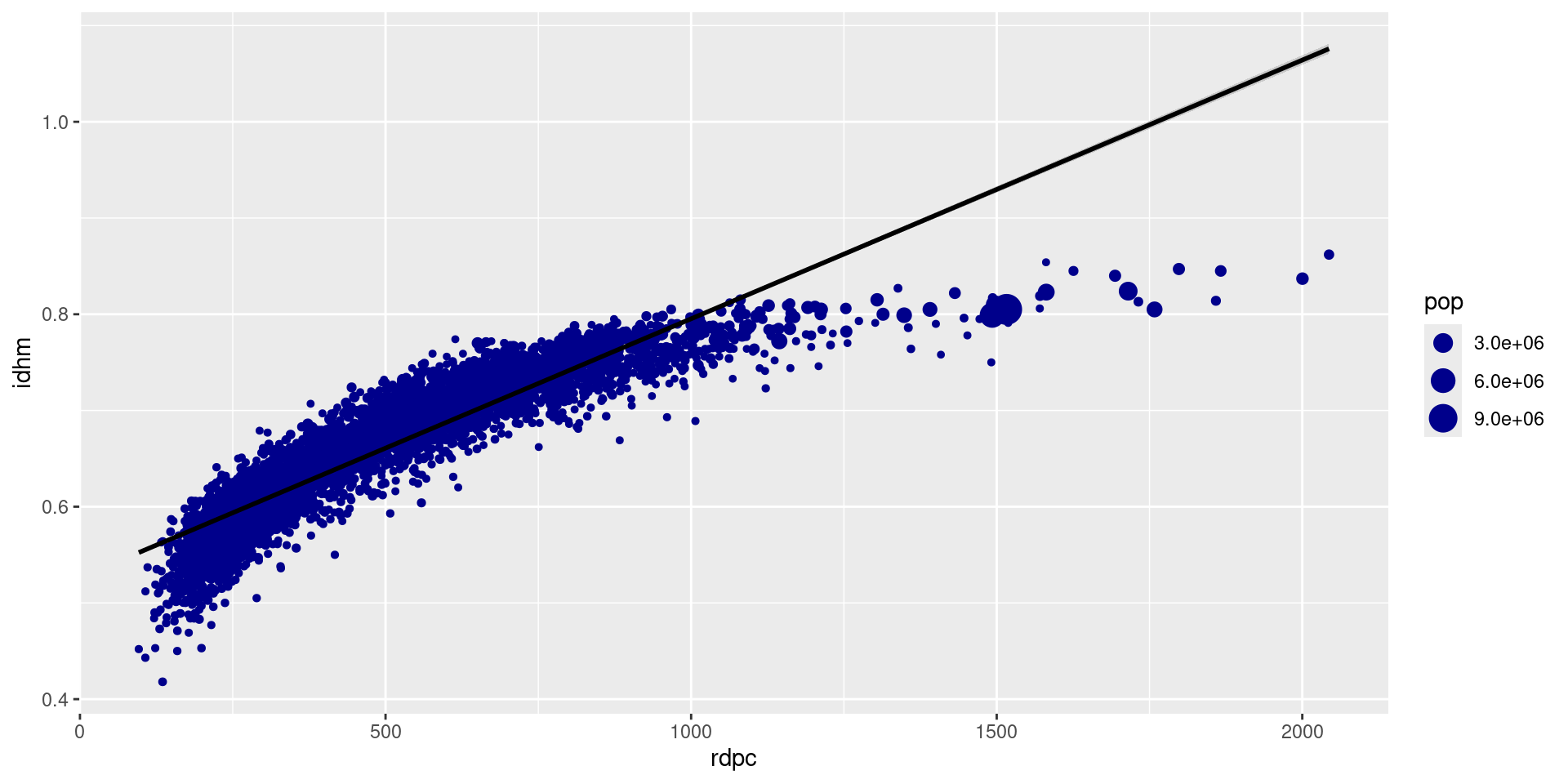
A camada Statistics
A camada Themes
A camada Themes altera a forma de apresentação dos gráficos.

Existem 3 elementos básicos da camada Themes: texto, linhas e retângulos. Juntos, este elementos controlam qualquer elemento visual de um gráfico.
A camada Themes
Para modificar o tipo do tema, vamos considerar o histograma abaixo
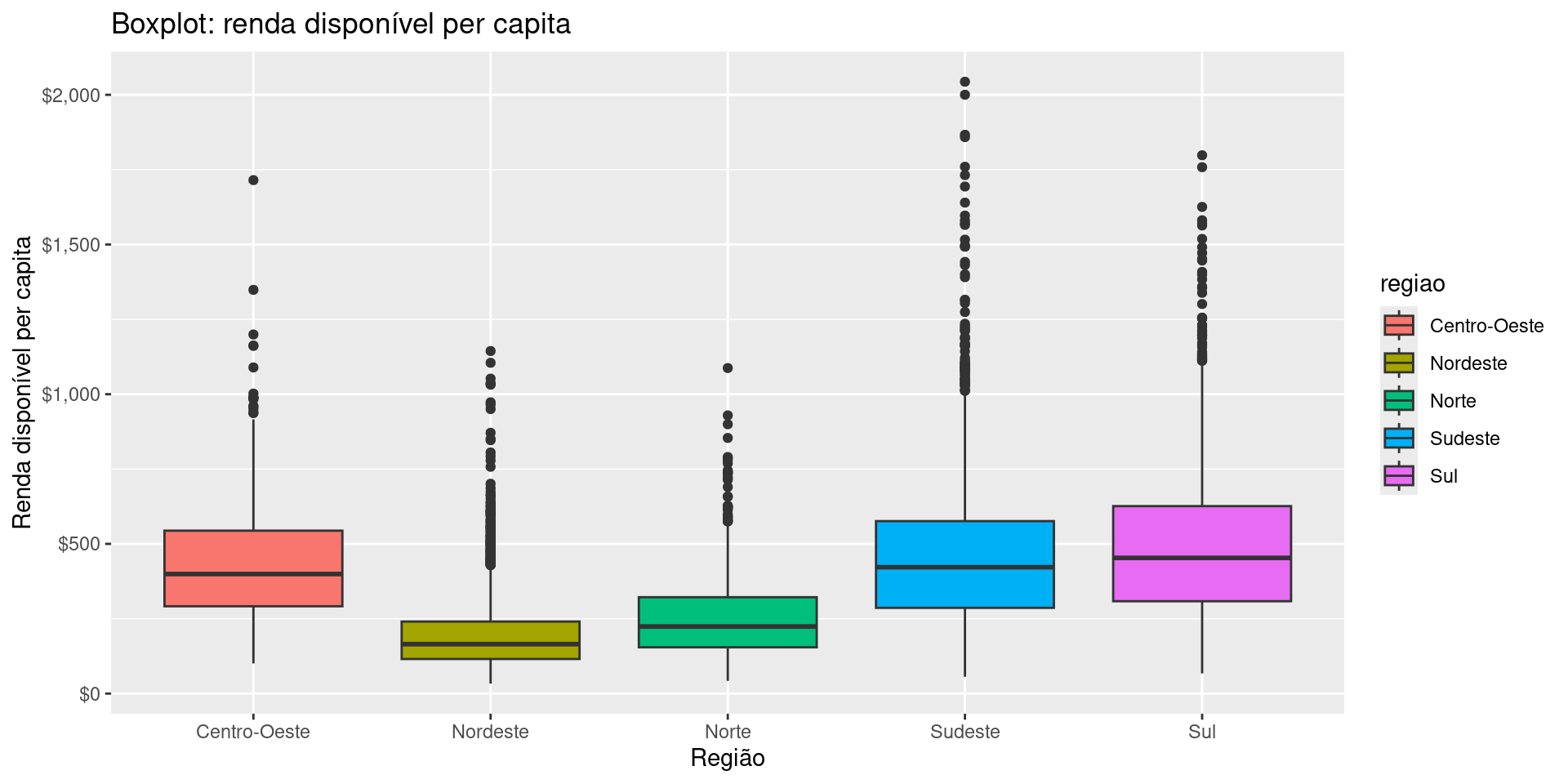
A camada Themes
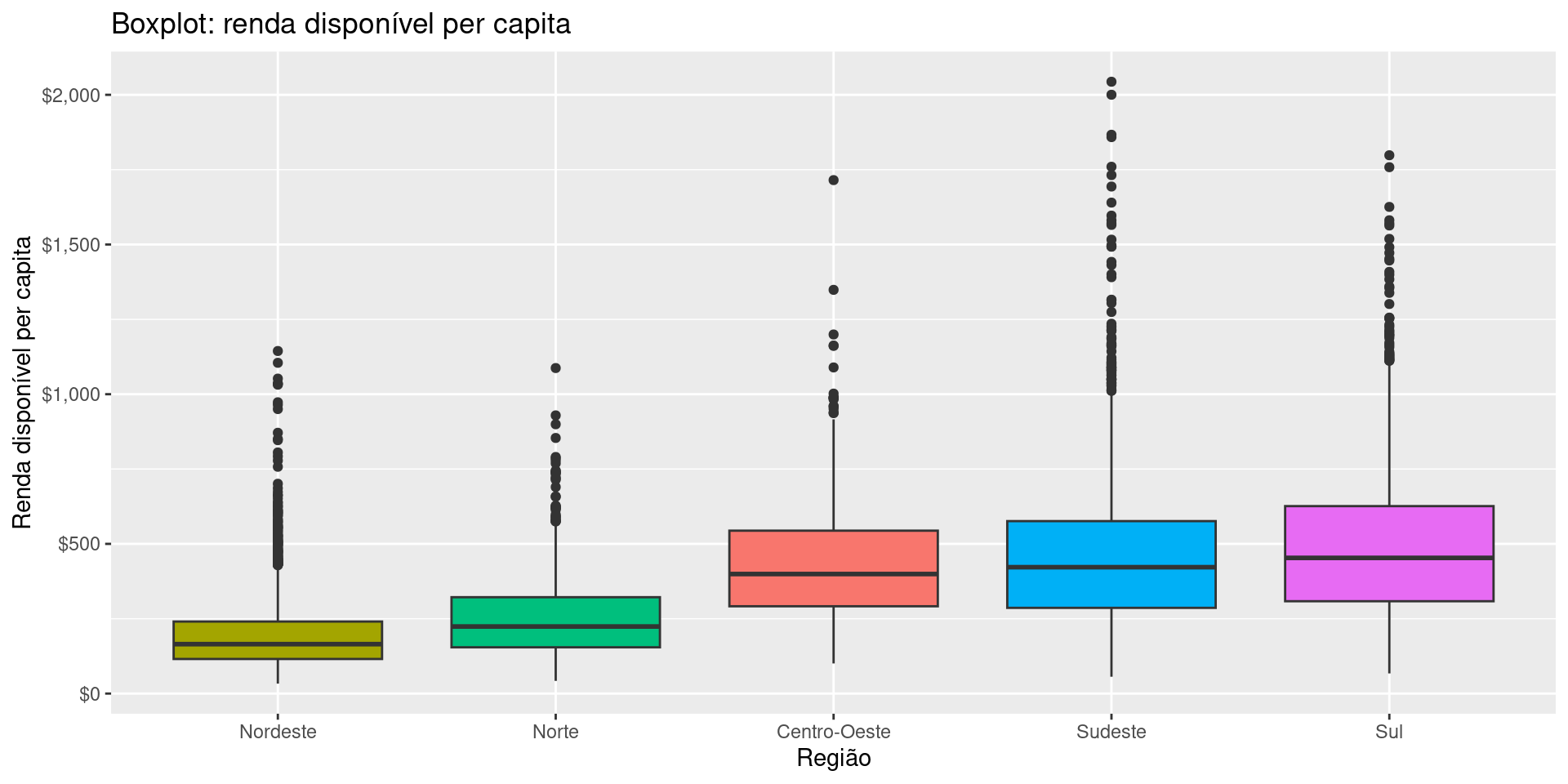
A camada Themes
Para escolher as cores das categorias manualmente, fazemos:
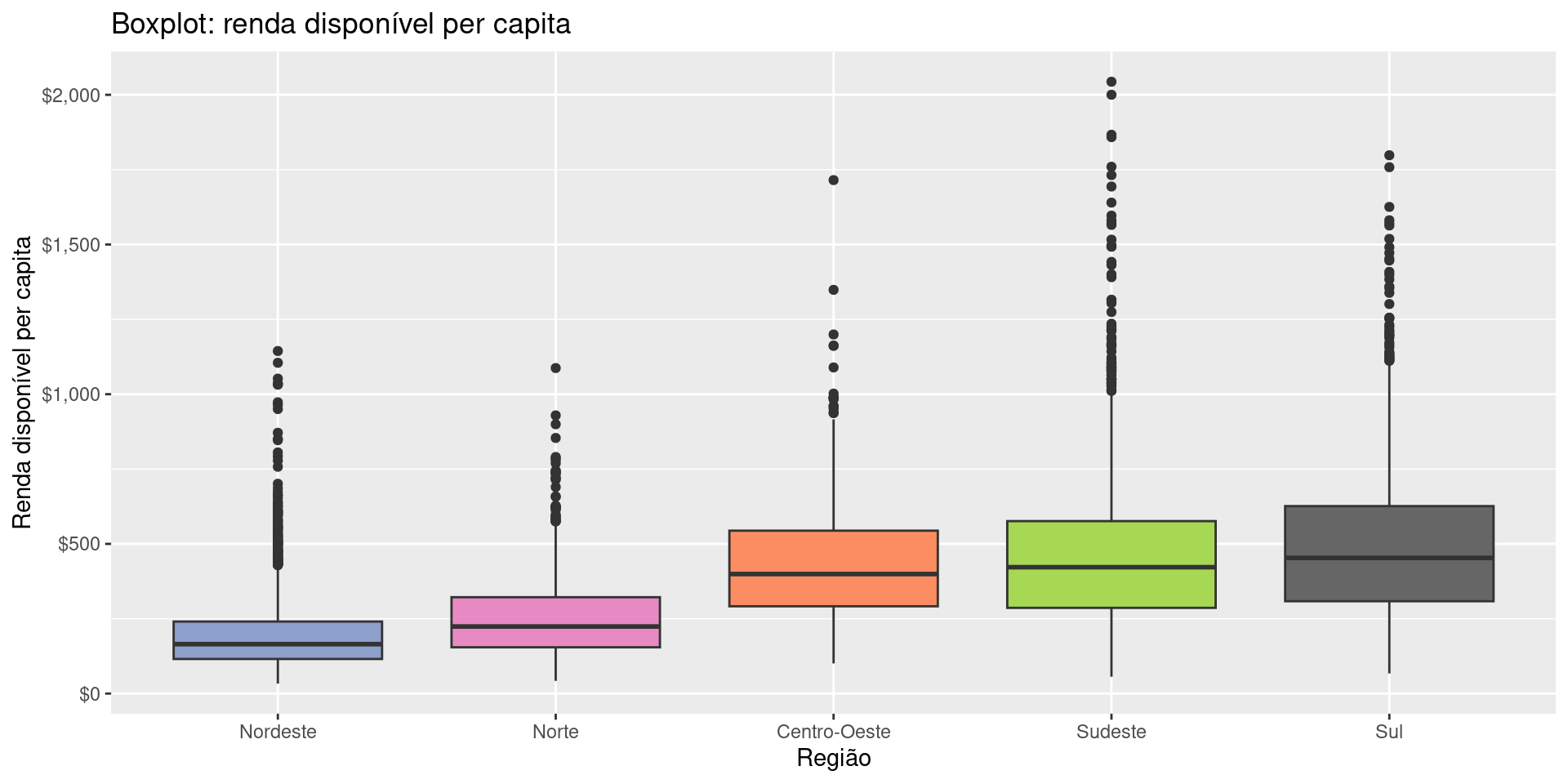
A camada Themes
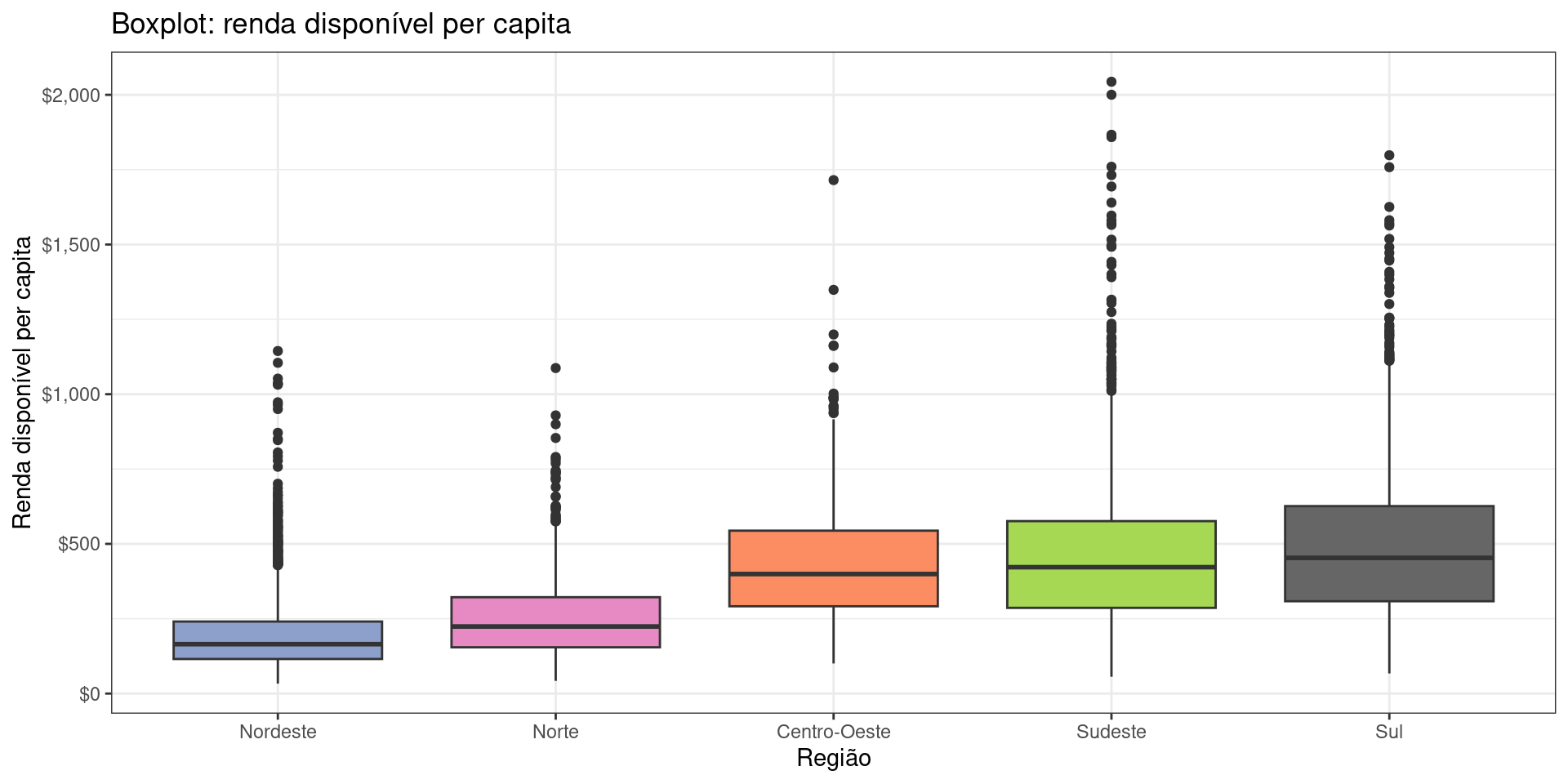
Built-in Themes
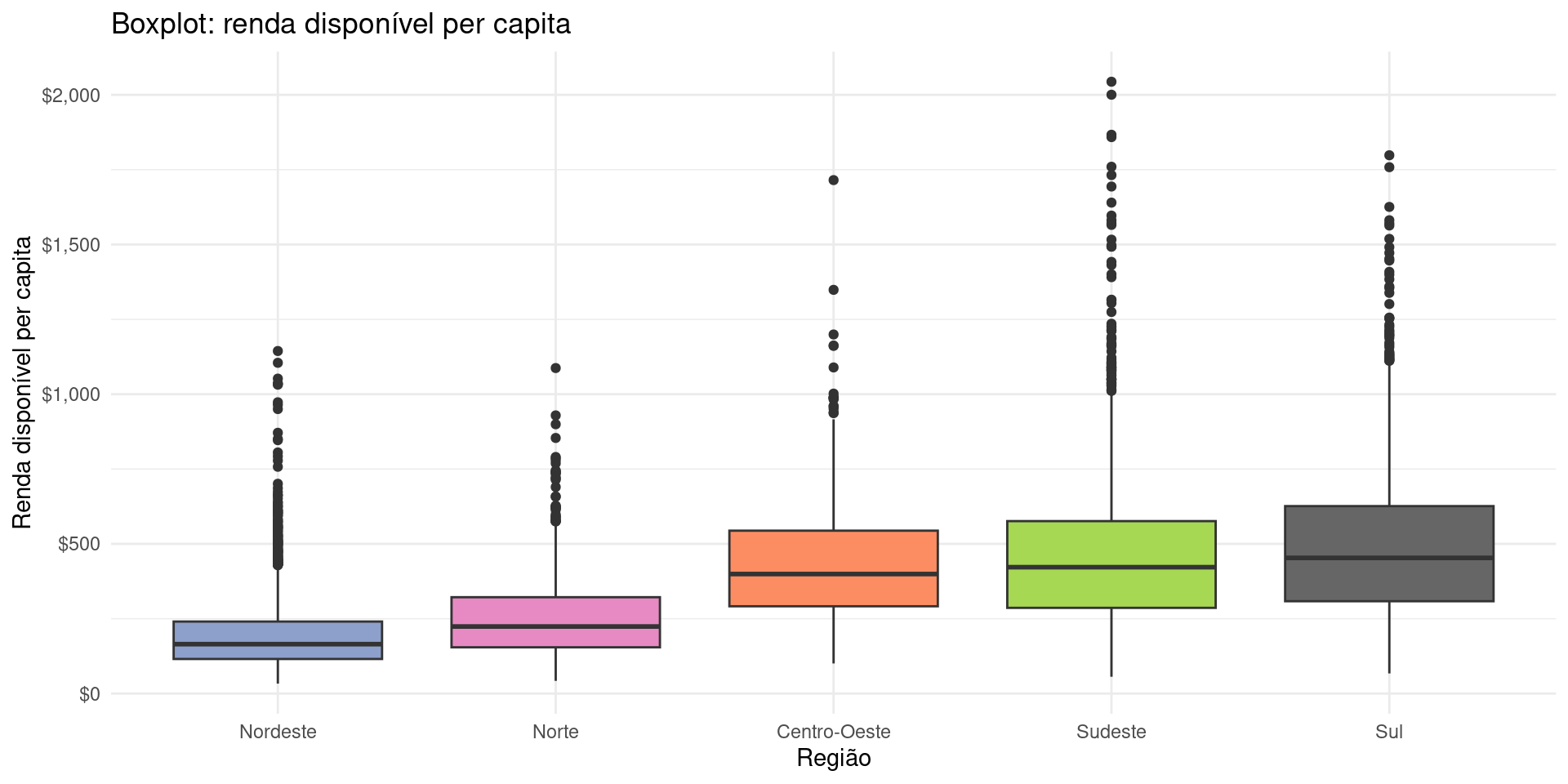
Built-in Themes
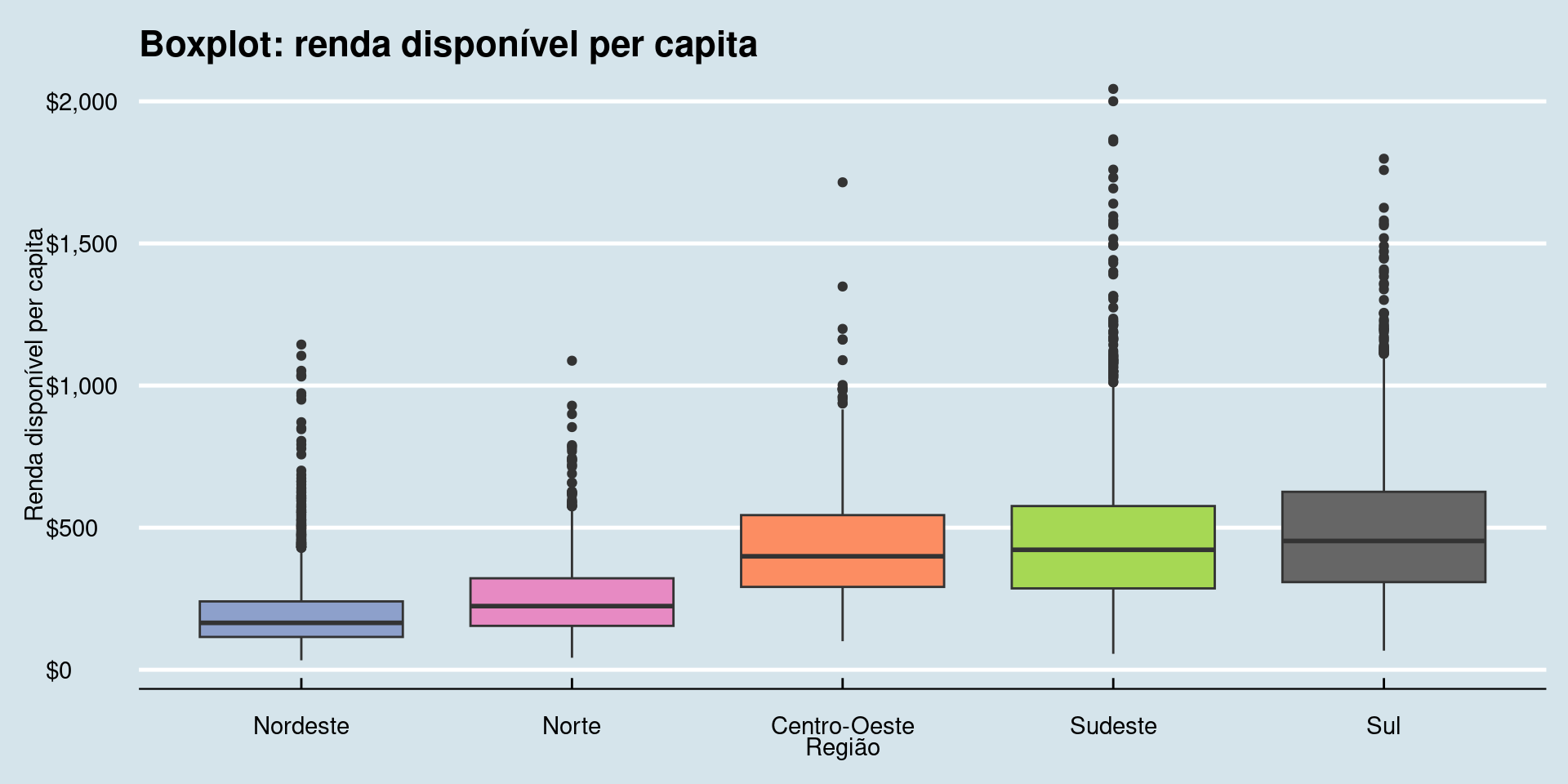
A camada Themes
Podemos ajustar os elementos do theme manualmente
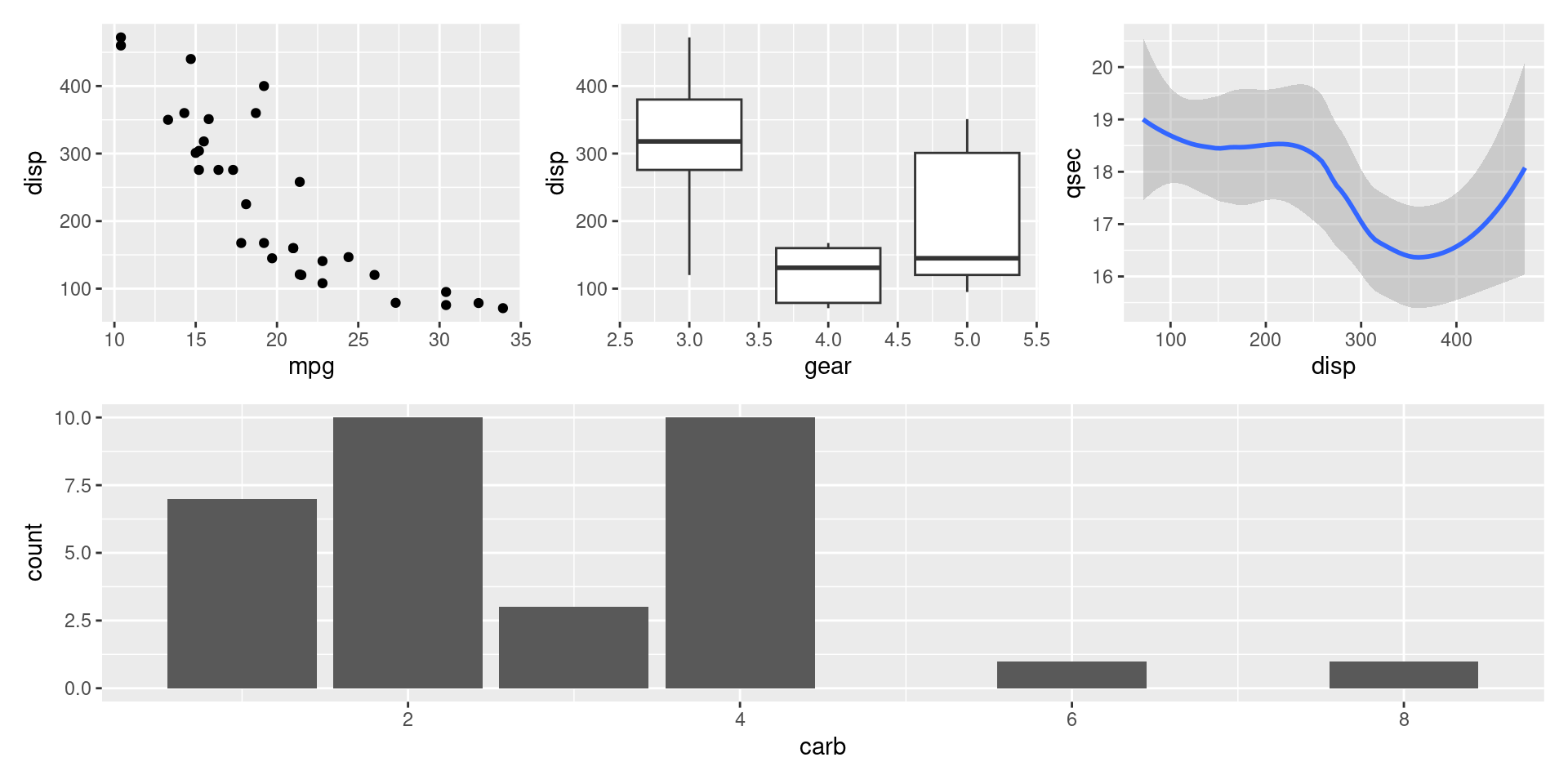
Combinando plots
Suponha que queiramos combinar vários plots em uma única imagem, uma opção bastante simples é atravé do pacote patchwork.
Exemplos de uso do patchwork
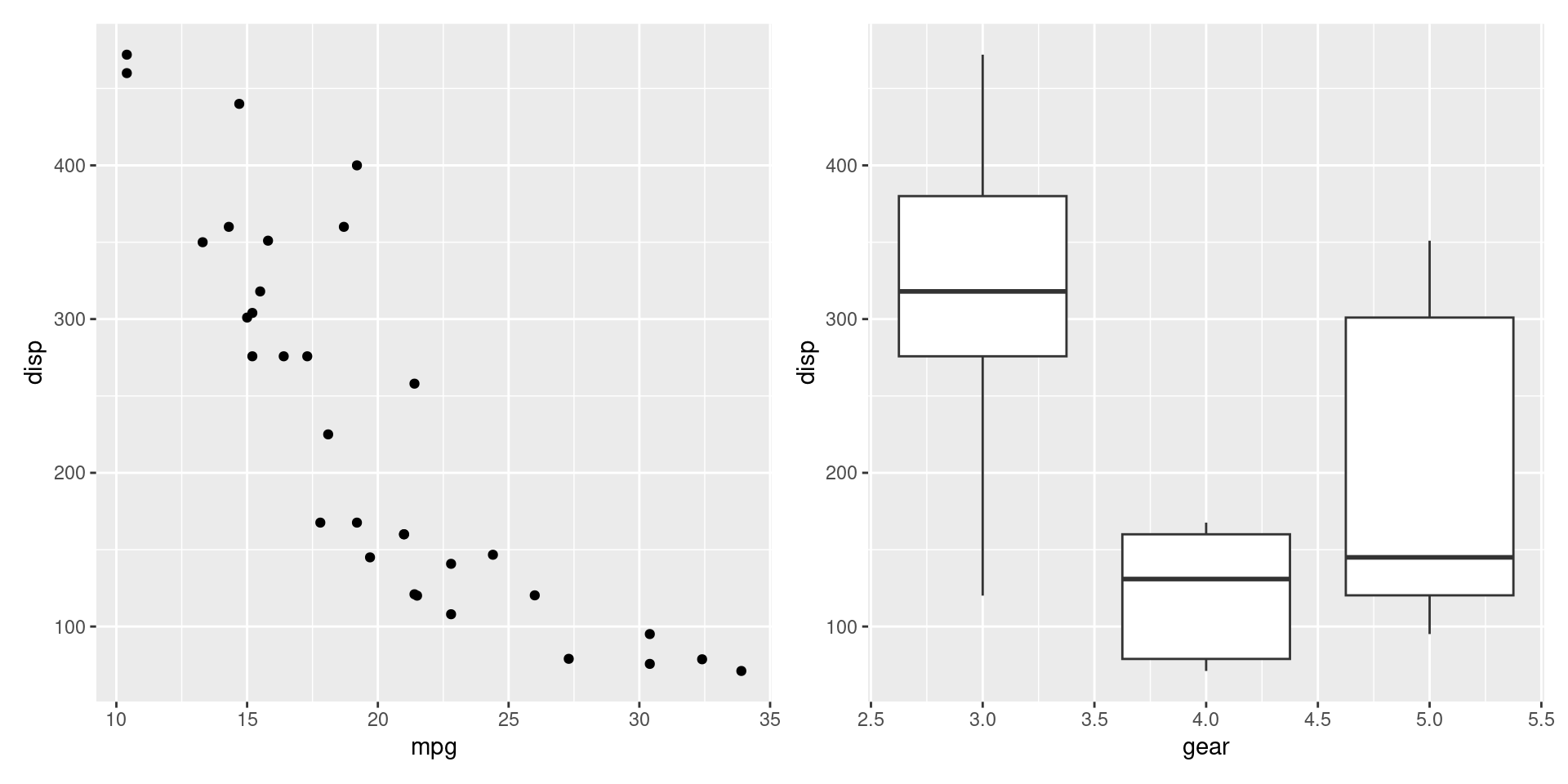
Exemplos de uso do patchwork