Introdução à Ciência de Dados no R
Aula 08 - Manipulação Avançada
Aula 08
Antonio Vinícius Barbosa
26-03-2024

Formatando Dados
Manipulação de Dados
Nesta parte, veremos mais alguns pacotes importantes para a manipulação de dados no R:
lubridate: pacote para manipular variáveis contendo datas.stringr: manipulação de variáveis de texto (characters ou strings).forcats: manipulação de fatores.

Manipulando datas
Manipulando datas no R
Em muitas situações, é necessário manipular informações que contêm datas a fim de capturar, por exemplo, o intervalo de tempo entre dois eventos ou a dinâmica temporal de uma variável.
O pacote lubridate possui diversas funções que facilitam a manipulação de datas.

Foi criado por Garrett Grolemund e Hadley Wickham e faz parte do conjunto de pacotes do tidyverse. Ver documentação oficial.
Manipulando datas no R
Nesta seção, veremos como:
- Transformar e extrair datas
- Aprender funções básicas para a manipulação de datas
- Realizar operações com datas
A classe Date
Variáveis que contêm datas são tratadas como um tipo especial de objeto, da classe Date. Para criar um objeto dessa classe, fazemos:
A função as.Date() transforma objetos na classe Date, porém com um valor inesperado. Tal função se ajusta apenas para datas do tipo yyyy-mm-dd.
O pacote lubridate
Para lidar com datas do tipo dd-mm-yyyy, o pacote lubridate oferece a função dmy() (day, month, year):
Para os demais ordenações de datas, o pacote oferece as variações dym(), mdy(),
myd(), ymd() e ydm().
Formatos de datas ao redor do mundo
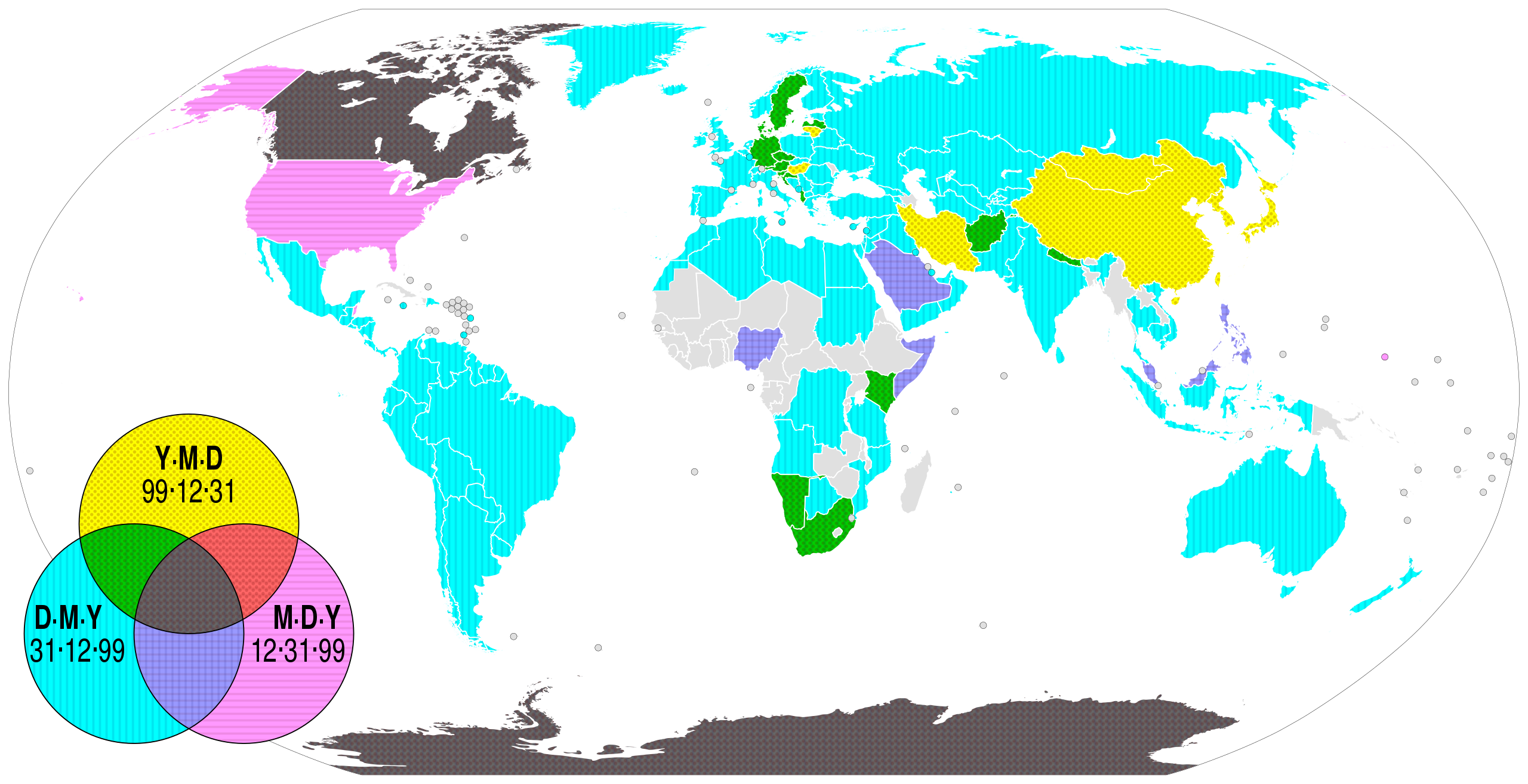
O pacote lubridate
Podemos transformar diversos formatos para a classe Date:

O pacote lubridate
Além de datas, podemos adicionar as horas. Para isso, basta identificar a ordem do year(y), month(m), day(d), hour(h), minute(m) e second(s)
O pacote lubridate
Para extrair informações instantâneas do sistema, fazemos:
O último bloco de informações da função now() corresponde ao fuso horário.
O pacote lubridate
Há diversas funções para extrair informações de um objeto da classe Date:
# Extrair data
date(hora_atual)
## [1] "2024-03-26"
# Extrair ano
year(hora_atual)
## [1] 2024
# Extrair mes
month(hora_atual)
## [1] 3
# Extrair dia do mes
day(hora_atual)
## [1] 26
# Extrair hora
hour(hora_atual)
## [1] 11
# Extrair minutos
minute(hora_atual)
## [1] 24
# Extrair segundos
second(hora_atual)
## [1] 47.46304O pacote lubridate
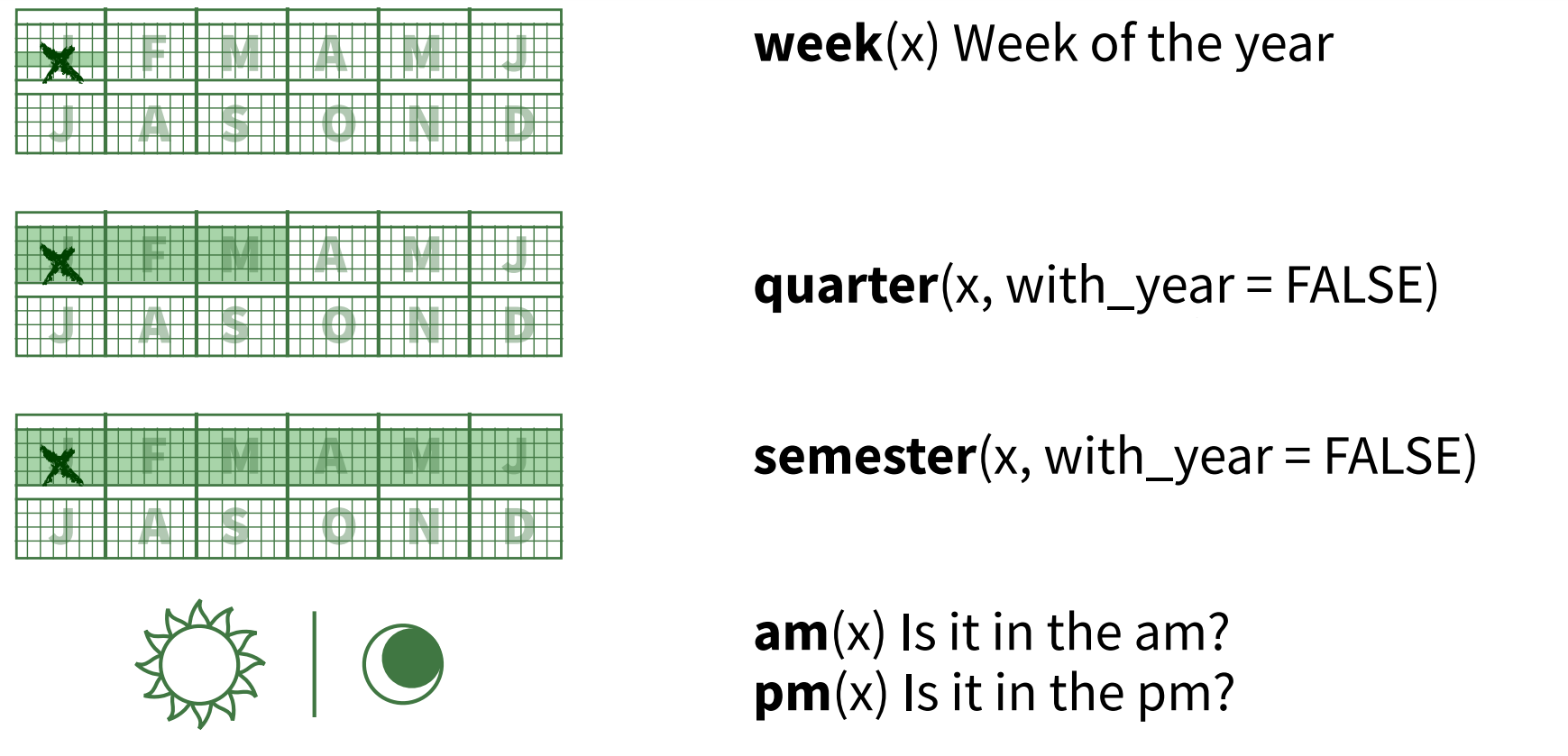
Outras informações de um objeto da classe Date:
Outras informações:
Operações com datas
Intervalos de datas são realizados areavés da função interval()
# Datas
data_inic <- ymd("2023-04-08")
data_fim <- ymd("2023-06-16")
# Intervalo de datas
periodo <- interval(data_inic, data_fim)
periodo
## [1] 2023-04-08 UTC--2023-06-16 UTC
# Outra notação (operador intervalo %--%)
periodo <- data_inic %--% data_fim
periodo
## [1] 2023-04-08 UTC--2023-06-16 UTC
evento <- ymd("2023-12-10")
evento %within% periodo
## [1] FALSEOperações com datas
Algumas operações aritméticas disponíveis são:
# Adição de datas
today() + days(5)
## [1] "2024-03-31"
today() + years(2)
## [1] "2026-03-26"
# Datas recorrentes
aulas <- today() + weeks(1:2)
aulas
## [1] "2024-04-02" "2024-04-09"
# Diferença de datas
as.period(periodo); as.period(periodo, unit = "day")
## [1] "2m 8d 0H 0M 0S"
## [1] "69d 0H 0M 0S"Datas em R
- Outras classes de datas no R são
POSIXctePOSIXlt. - A classe
POSIXcté útil para datas que contenham horas. - A classe
POSIXltfacilita a extração de componentes da data. - O pacote
lubridateé um wrapper para manipular as duas classes, com uma sintaxe mais simples e intuitiva. - Para mais informações, ver a ajuda das funções https://lubridate.tidyverse.org
Quizz #1
- Utilize a função do
lubridateapropriada para analisar cada uma das seguintes datas:
- Precisamente, qual a sua idade agora? Calcule a idade em anos, meses, semanas, dias, horas e minutos.
Quizz #2
Para este exercício, será necessário utilizar a base dados::voos
- Observar a estrutura de dados utilizando
glimpse(). - Criar uma variável informando a velocidade média (km/h) do voo utilizando as variáveis
distanciaetempo_voo(medida em minutos). - Construa a variável com a data e hora exata da decolagem.
- Reporte a hora de chegada relativa ao local de partida.
- Criar um banco apenas com dados dos voos atrasados.
Strings (ou variáveis de texto)
Variáveis de texto
- Outra classe importante são as variáveis character (ou strings).
- Muitas vezes, é difícil manipular strings devido a existência de diversas funções com diferentes argumentos.
- Neste sentido, o pacote
stringrtraz uma sintaxe mais consistente e simples para manipular tais variáveis.
As funções do stringr
- O pacote também faz parte do
tidyverse - As funções de manipulação de texto começam com
str_ - Para listar todas as funções disponíveis, basta digitar
stringr::str_e visualizar todas as funções com este prefixo
As funções do stringr
Algumas funções básicas para manipulação de caracteres:
As funções do stringr
As funções do stringr
# Variavel sexo
sexo_quest <- c("M", "F", " M", "F ", " M ")
sexo_quest
## [1] "M" "F" " M" "F " " M "
# Remover espacos em branco
sexo <- str_trim(sexo_quest)
sexo
## [1] "M" "F" "M" "F" "M"
# Remover espacos em branco em qualquer parte
str_squish(" Este texto está com espaços ")
## [1] "Este texto está com espaços"
# Concatenar strings
pre <- "O status é:"
status <- "APROVADO"
str_c(pre, status, sep = " ")
## [1] "O status é: APROVADO"
# Excluir padrões
id_var <- c("id1", "id2", "id3")
str_replace(id_var, "id", "")
## [1] "1" "2" "3"As funções do stringr
Para dividir elementos de uma string baseada em um caractere específico, utilizamos a função str_split():
# Inserir texto
texto <- c("Lorem ipsum dolor sit amet")
# Dividir string (em lista)
str_split(texto, " ")
## [[1]]
## [1] "Lorem" "ipsum" "dolor" "sit" "amet"
# Dividir string (em matriz)
str_split(texto, " ", simplify = TRUE)
## [,1] [,2] [,3] [,4] [,5]
## [1,] "Lorem" "ipsum" "dolor" "sit" "amet"As funções do stringr
Para adicionar caracteres e ajustar em um tamanho fixo, utilizamos a função str_pad()
Documentação oficial

Quizz #3
Exercício 1
O CPF é um número composto por 11 dígitos. Por exemplo, 54491651884. No entanto, para facilitar a visualização, costumamos mostrá-lo com separadores a cada 3 casas: 544.916.518-84. Como obter esse padrão utilizando unicamente as funções do pacote stringr?
Exercício 2
Suponha que tenhamos o seguinte endereço em uma URL: https://www.ibge.gov.br/cidades-e-estados/pb/campina-grande.html Transforme o endereço no formato identificador Campina Grande (PB)
O pacote forcats
Fatores
Até o momento, vimos a existência de objetos da classe factor. De forma geral:
- Representam uma forma prática de lidar com variáveis categorizadas, tanto para fins de modelagem quanto para fins de visualização.
Fatores
As principais funções do pacote
forcatsauxiliam na reordenação das categorias e na modificação dos níveis de um fator.Fatores são estruturas de dados utilizadas para ordenar strings. Formalmente, um fator é definido como um vetor de
integerscom dois atributos específicos:- levels: vetor de strings que indica a relação de ordem entre as variáveis.
- class: a string atômica
factor.
Variáveis categóricas
Suponha um vetor com as disciplinas preferidas dos alunos em uma dado semestre:
Variáveis categóricas
Fatores são estruturas úteis que permitem ter maior controle durante a análise dos dados:
O pacote forcats
Para entender as funcionalidades do pacote forcats, utilizaremos o banco de dados airquality:
tibble::glimpse(airquality)
## Rows: 153
## Columns: 6
## $ Ozone <int> 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, 18, 14, …
## $ Solar.R <int> 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256, 290, 27…
## $ Wind <dbl> 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6, 6.9, 9…
## $ Temp <int> 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68, 58, 64…
## $ Month <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,…
## $ Day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,…O pacote forcats
Estamos interessados em mudar os níveis de um fator:
Podemos renomear os levels através da função fct_recode():
O pacote forcats
É possível mudar a ordem em que os levels são apresentados:
O pacote forcats
Outra função bastante útil para agrupar categorias é a fct_lump. Considere o seguinte vetor:
O pacote forcats
A função fct_lump() utiliza o level de menor frequência e categoriza como “Outros”
O pacote forcats
Ainda, podemos definir o número de categorias e agregar as demais em “Outros”