Introdução à Ciência de Dados no R
Aula 03 - Estruturas de Dados
Aula 03
Antonio Vinícius Barbosa
01-02-2024

Estruturas de Dados
Estruturas de Dados
As estruturas de dados em R podem ser divididas em:
Vetores
Vimos que os vetores possuem as seguintes propriedades:
- São homogêneos (seus elementos são de uma mesma classe)
- São, geralmente, criados pelo operador
c() - Podem ser indexados pela sua posição
Vetores
Matrizes
- Adicionando 2 dimensões a um vetor, o transformamos em uma matriz
- As dimensões correspondem ao número de linhas e de colunas
Matrizes
Ou através da função matrix():
- Os elementos de uma matriz são indexados por
[i,j], comirepresentando a linha eja coluna - O argumento
byrowpermite ajustar a forma de preenchimento - se por linha ou coluna.
Arrays
A partir do entendimento de matrizes (elementos com duas dimensões), podemos entender o conceito arrays. Arrays são objetos que armazenam dados em mais de duas dimensões.
Arrays
- Suponha que tenhamos informações sobre as despesas com saúde, com educação e com funcionários em 3 municípios, para o ano de 2022:
# Despesas 2022
despesas_2022 <- c(12.2, 23.4, 17.3, 11.4, 22.7,
20.1, 14.9, 18.5, 32.9)
# Criar matriz
despesas_mun_2022 <- matrix(data = despesas_2022, nrow = 3, ncol = 3)
# Inserir nomes
colnames(despesas_mun_2022) <- c("Areia", "Patos", "Picuí")
rownames(despesas_mun_2022) <- c("Saúde", "Educação", "Funcionários")
despesas_mun_2022
## Areia Patos Picuí
## Saúde 12.2 11.4 14.9
## Educação 23.4 22.7 18.5
## Funcionários 17.3 20.1 32.9Arrays
Se dispusermos de informações dos gastos de anos anteriores, podemos pensar numa estrutura de dados de matrizes empilhadas, como na representação abaixo:
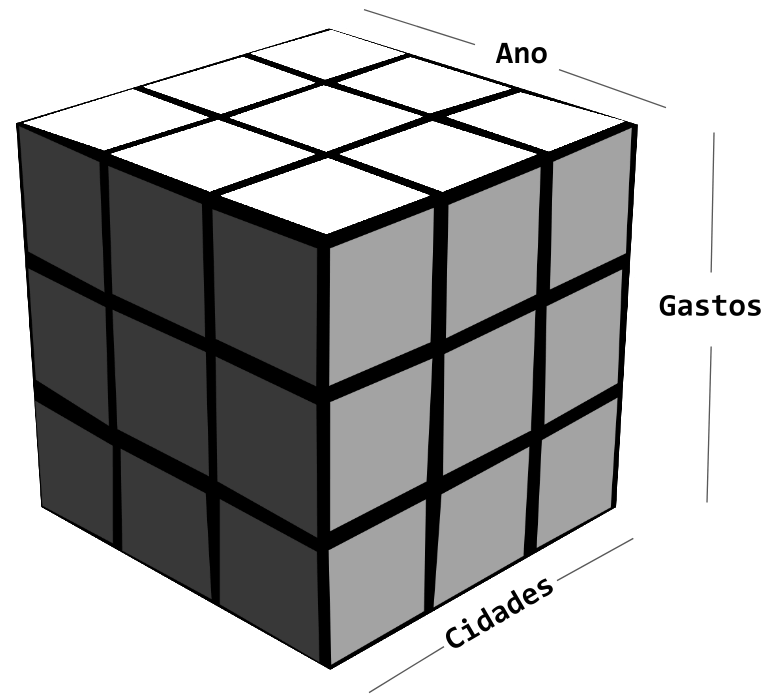
Arrays
Além de 2022, suponha a existência de dados para os anos de 2021 e 2020:
# Despesas 2021
despesas_mun_2021 <- matrix(data = c(11.3, 19.3, 18.1, 12.2, 19.8,
20.2, 15.8, 18.9, 26.2),
nrow = 3, ncol = 3)
colnames(despesas_mun_2021) <- c("Areia", "Patos", "Picuí")
rownames(despesas_mun_2021) <- c("Saúde", "Educação", "Funcionários")
# Despesas 2020
despesas_mun_2020 <- matrix(data = c(11.8, 21.2, 19.2, 12.1, 17.3,
21.8, 16.0, 17.1, 28.6),
nrow = 3, ncol = 3)
colnames(despesas_mun_2020) <- c("Areia", "Patos", "Picuí")
rownames(despesas_mun_2020) <- c("Saúde", "Educação", "Funcionários")Arrays
# Despesas 2022
despesas_mun_2022
## Areia Patos Picuí
## Saúde 12.2 11.4 14.9
## Educação 23.4 22.7 18.5
## Funcionários 17.3 20.1 32.9
# Despesas 2021
despesas_mun_2021
## Areia Patos Picuí
## Saúde 11.3 12.2 15.8
## Educação 19.3 19.8 18.9
## Funcionários 18.1 20.2 26.2
# Despesas 2020
despesas_mun_2020
## Areia Patos Picuí
## Saúde 11.8 12.1 16.0
## Educação 21.2 17.3 17.1
## Funcionários 19.2 21.8 28.6Arrays
Para criar um array, fazemos:
hist_despesas_mun <- array(c(despesas_mun_2022,
despesas_mun_2021,
despesas_mun_2020),
c(3, 3, 3))
hist_despesas_mun
## , , 1
##
## [,1] [,2] [,3]
## [1,] 12.2 11.4 14.9
## [2,] 23.4 22.7 18.5
## [3,] 17.3 20.1 32.9
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 11.3 12.2 15.8
## [2,] 19.3 19.8 18.9
## [3,] 18.1 20.2 26.2
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 11.8 12.1 16.0
## [2,] 21.2 17.3 17.1
## [3,] 19.2 21.8 28.6Arrays
Para selecionar um elemento de uma array, utilizamos seus indexadores de acordo com as dimensões:
# Selecionar a matriz de 2022
hist_despesas_mun[,,1]
## [,1] [,2] [,3]
## [1,] 12.2 11.4 14.9
## [2,] 23.4 22.7 18.5
## [3,] 17.3 20.1 32.9
# Selecionar a matriz de 2020
hist_despesas_mun[,,3]
## [,1] [,2] [,3]
## [1,] 11.8 12.1 16.0
## [2,] 21.2 17.3 17.1
## [3,] 19.2 21.8 28.6
# Selecionar dados de Areia no ano de 2021
hist_despesas_mun[,1,2]
## [1] 11.3 19.3 18.1
# Selecionar gastos em saúde de Picuí em 2021
hist_despesas_mun[1,3,2]
## [1] 15.8Data frames
Data frames
Um data frame é uma das estruturas mais importantes para armazanamento de dados em R. Equivale, de certa forma, às planilhas eletrônicas, com informações dispostas em linhas e colunas.
- Um data frame é um conjunto de vetores de mesmo tamanho
- Cada linha representa informações para uma única unidade de observação
- Cada coluna representa uma característica observada das unidadesde observação
- Cada linha pode possuir elementos de diferentes tipos (números inteiros, números reais, caracteres, lógicos, fatores)
- Elementos da mesma coluna devem ser do mesma classe
Data frames
A estrutura básica de um data frame é representado pela figura abaixo:

Cada linha apresenta informações da unidade observada (indivíduos, municípios, estabelecimentos, etc.). As colunas representam as variáveis observadas (CPF/CNPJ, renda, gastos com saúde, população, faturamento).
CGU - Fiscalização de Municípios

- Programa da Contoladoria-Geral da União (CGU) para avaliação dos recursos públicos federais repassados a estados, municípios e ao Distrito Federal.
- Desde 2003, mais 2,5 mil municípios brasileiros já foram fiscalizados
- O programa possui três formas de seleção de entes: Censo, Matriz de Vulnerabilidade e Sorteios
Criando data frames
Suponha que tenhamos uma lista de municípios sorteados para serem fiscalizados no estado da Paraíba. A forma mais simples para se construir um data frame é através da função data.frame()
# Municípios sorteados
mun_pb <- data.frame(
cod_mun = c(2500601, 2504603, 2506806, 2510808, 2515302),
municipio = c("Alhandra", "Conde", "Ingá", "Patos", "Sapé"),
populacao = c(18.01, 21.41, 18.18, 100.69, 50.15),
pib = c(599889, 550883, 117110, 1158945, 401733),
fisc = c(1, 0, 0, 1, 0)
)
mun_pb
## cod_mun municipio populacao pib fisc
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 0
## 3 2506806 Ingá 18.18 117110 0
## 4 2510808 Patos 100.69 1158945 1
## 5 2515302 Sapé 50.15 401733 0Explorando os dados
Para retornar a dimensão do banco de dados, utilizamos a função dim():
Ou, para saber a estrutura básica dos dados, utilizamos a função str()
# Estrutura dos dados
str(mun_pb)
## 'data.frame': 5 obs. of 5 variables:
## $ cod_mun : num 2500601 2504603 2506806 2510808 2515302
## $ municipio: chr "Alhandra" "Conde" "Ingá" "Patos" ...
## $ populacao: num 18 21.4 18.2 100.7 50.1
## $ pib : num 599889 550883 117110 1158945 401733
## $ fisc : num 1 0 0 1 0Renomeando variáveis
Para renomear as variáveis de um data frame, fazemos:
# Renomeando as variaveis (colunas)
names(mun_pb) <- c("cod_ibge", "nome_mun", "pop_mun",
"pib_mun", "fisc_cgu")
mun_pb
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 0
## 3 2506806 Ingá 18.18 117110 0
## 4 2510808 Patos 100.69 1158945 1
## 5 2515302 Sapé 50.15 401733 0Selecionando variáveis
Assim como as matrizes, os elementos de um data frame podem ser acessados através da estrutura [i,j]
Filtrando dados
Para filtrar um subconjunto dos dados baseado em algum critério, utilizamos a função subset():
# Populacao maior que 500k
subset(mun_pb, pib_mun > 500000)
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 0
## 4 2510808 Patos 100.69 1158945 1
# Municipios fiscalizados
subset(mun_pb, fisc_cgu == 1)
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 4 2510808 Patos 100.69 1158945 1Filtrando dados
Outras operações para filtrar um subconjuntos dos dados são:
# Interseccao entre conjuntos
subset(mun_pb, pop_mun < 25 & fisc_cgu == 0)
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 2 2504603 Conde 21.41 550883 0
## 3 2506806 Ingá 18.18 117110 0
# Uniao entre conjuntos
subset(mun_pb, pib_mun > 500000 | fisc_cgu == 1)
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 0
## 4 2510808 Patos 100.69 1158945 1
# Excecao
subset(mun_pb, nome_mun != "Alhandra" & nome_mun != "Patos")
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 2 2504603 Conde 21.41 550883 0
## 3 2506806 Ingá 18.18 117110 0
## 5 2515302 Sapé 50.15 401733 0Adicionando linhas e colunas
Variáveis (ou colunas) podem ser adicionadas ao data frame fazendo:
# Adicionando variaveis
mun_pb$aprovado <- c(1, NA, NA, 0, NA)
mun_pb
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu aprovado
## 1 2500601 Alhandra 18.01 599889 1 1
## 2 2504603 Conde 21.41 550883 0 NA
## 3 2506806 Ingá 18.18 117110 0 NA
## 4 2510808 Patos 100.69 1158945 1 0
## 5 2515302 Sapé 50.15 401733 0 NAAdicionando linhas e colunas
Suponha que novos municípios tenham entrado na amostra. Portanto, gostaríamos de adicionar linhas na base da dados atual:
mun_pb_2 <- data.frame(
cod_ibge = c(2509404, 2512507, 2516201),
nome_mun = c("Mogeiro", "Queimadas", "Sousa"),
pop_mun = c(12.49, 41.05, 65.81),
pib_mun = c(90377, 365554, 807574),
fisc_cgu = c(1, 1, 1),
aprovado = c(0, 0, 1)
)
# Adicionando linhas
mun_pb_cons <- rbind(mun_pb, mun_pb_2)
mun_pb_cons
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu aprovado
## 1 2500601 Alhandra 18.01 599889 1 1
## 2 2504603 Conde 21.41 550883 0 NA
## 3 2506806 Ingá 18.18 117110 0 NA
## 4 2510808 Patos 100.69 1158945 1 0
## 5 2515302 Sapé 50.15 401733 0 NA
## 6 2509404 Mogeiro 12.49 90377 1 0
## 7 2512507 Queimadas 41.05 365554 1 0
## 8 2516201 Sousa 65.81 807574 1 1Atualizando variáveis
Suponha que agora todos os municípios tenham sido fiscalizados:
mun_pb_cons[c(2, 3, 5), 5] <- 1
mun_pb_cons
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu aprovado
## 1 2500601 Alhandra 18.01 599889 1 1
## 2 2504603 Conde 21.41 550883 1 NA
## 3 2506806 Ingá 18.18 117110 1 NA
## 4 2510808 Patos 100.69 1158945 1 0
## 5 2515302 Sapé 50.15 401733 1 NA
## 6 2509404 Mogeiro 12.49 90377 1 0
## 7 2512507 Queimadas 41.05 365554 1 0
## 8 2516201 Sousa 65.81 807574 1 1Atualizando variáveis
Suponha que agora todos os municípios tenham sido fiscalizados:
mun_pb_cons$aprovado[is.na(mun_pb_cons$aprovado)] <- 1
mun_pb_cons
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu aprovado
## 1 2500601 Alhandra 18.01 599889 1 1
## 2 2504603 Conde 21.41 550883 1 1
## 3 2506806 Ingá 18.18 117110 1 1
## 4 2510808 Patos 100.69 1158945 1 0
## 5 2515302 Sapé 50.15 401733 1 1
## 6 2509404 Mogeiro 12.49 90377 1 0
## 7 2512507 Queimadas 41.05 365554 1 0
## 8 2516201 Sousa 65.81 807574 1 1Removendo variáveis
Para remover variáveis, fazemos:
mun_pb_cons[, -3]
## cod_ibge nome_mun pib_mun fisc_cgu aprovado
## 1 2500601 Alhandra 599889 1 1
## 2 2504603 Conde 550883 1 1
## 3 2506806 Ingá 117110 1 1
## 4 2510808 Patos 1158945 1 0
## 5 2515302 Sapé 401733 1 1
## 6 2509404 Mogeiro 90377 1 0
## 7 2512507 Queimadas 365554 1 0
## 8 2516201 Sousa 807574 1 1Removendo variáveis
Alternativamente, podemos fazer:
mun_pb_cons$aprovado <- NULL
mun_pb_cons
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 1
## 3 2506806 Ingá 18.18 117110 1
## 4 2510808 Patos 100.69 1158945 1
## 5 2515302 Sapé 50.15 401733 1
## 6 2509404 Mogeiro 12.49 90377 1
## 7 2512507 Queimadas 41.05 365554 1
## 8 2516201 Sousa 65.81 807574 1Remover linhas incompletas
mun_pb_cons[complete.cases(mun_pb_cons),]
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 1
## 3 2506806 Ingá 18.18 117110 1
## 4 2510808 Patos 100.69 1158945 1
## 5 2515302 Sapé 50.15 401733 1
## 6 2509404 Mogeiro 12.49 90377 1
## 7 2512507 Queimadas 41.05 365554 1
## 8 2516201 Sousa 65.81 807574 1Ordenação
Para ordenar data frames baseado em uma variável, fazemos:
# Ordenar por populacao (crescente)
mun_pb_cons[order(mun_pb_cons$pop_mun),]
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 6 2509404 Mogeiro 12.49 90377 1
## 1 2500601 Alhandra 18.01 599889 1
## 3 2506806 Ingá 18.18 117110 1
## 2 2504603 Conde 21.41 550883 1
## 7 2512507 Queimadas 41.05 365554 1
## 5 2515302 Sapé 50.15 401733 1
## 8 2516201 Sousa 65.81 807574 1
## 4 2510808 Patos 100.69 1158945 1Ordenação
Para ordenar data frames baseado em uma variável, fazemos:
# Ordenar por fiscalizacao (decrescente)
mun_pb_cons[order(mun_pb_cons$fisc_cgu, decreasing = TRUE),]
## cod_ibge nome_mun pop_mun pib_mun fisc_cgu
## 1 2500601 Alhandra 18.01 599889 1
## 2 2504603 Conde 21.41 550883 1
## 3 2506806 Ingá 18.18 117110 1
## 4 2510808 Patos 100.69 1158945 1
## 5 2515302 Sapé 50.15 401733 1
## 6 2509404 Mogeiro 12.49 90377 1
## 7 2512507 Queimadas 41.05 365554 1
## 8 2516201 Sousa 65.81 807574 1Quizz #1
- Crie um data frame com informações sobre 5 colegas de turma. Colete ao menos 4 variáveis de diferentes tipos (uma delas deve ser a idade!)
- Observe a estrutura dos dados e mostre um sumário de todas as variáveis.
- Adicione mais duas observações aos dados e ordene a base completa pela idade dos indivíduos. Em seguida, crie um vetor indicando o nome dos colegas com maior e menor idade.
- Alguns data frames já estão incluídos no
Rpara realizarmos testes. Exemplos famosos são omtcarse oiris. Explore estes data frames utilizando a funçãodata("dados").
10:00
Listas
Listas no R
Uma lista é uma estrutura de dados composta por elementos de vários tipos. Um vetor que possui elementos de um mesmo tipo é chamado de vetor. Já um vetor composto de elementos diferentes (vetores, arrays, data frames, matrizes, expressões, etc.) é chamado de lista.
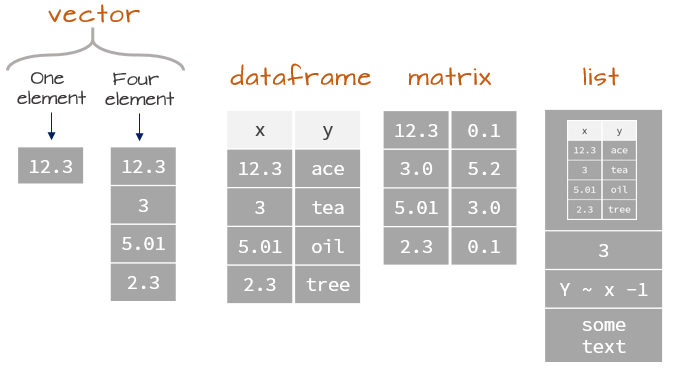
Listas
Uma forma simples de lista é dada a seguir:
Listas
Uma lista pode conter elementos mais complexos:
n <- c(2, 3, 5)
s <- c("a", "b", "c", "d", "e")
b <- matrix(1:4, nrow = 2, ncol = 2)
# Criar uma lista com os elementos
minha_lista <- list(n, s, b, cliente)
minha_lista
## [[1]]
## [1] 2 3 5
##
## [[2]]
## [1] "a" "b" "c" "d" "e"
##
## [[3]]
## [,1] [,2]
## [1,] 1 3
## [2,] 2 4
##
## [[4]]
## [[4]][[1]]
## [1] "João"
##
## [[4]][[2]]
## [1] 24
##
## [[4]][[3]]
## [1] 3 4 3 2 0 7
##
## [[4]][[4]]
## [1] "M"Listas
Para observar a estrutura de uma lista, fazemos:
Como podemos observar, o quarto elemento da lista é uma lista! Este é um exemplo de uma lista aninhada (nested list)
Listas
Para adicionar novos elementos na lista, podemos usar a função append()
Listas
As listas são indexadas por parênteses duplos [[ ]], ao invés de parênteses simples utilizados para vetores e matrizes. Para selecionar elementos de uma lista:
Quizz #1
- Sejam
p <- c(2,7,8),q <- c("A", "B", "C")ex <- list(p, q). Qual o resultado dex[[2]]? E o dex[2]? - Se
a <- list("x" = 5, "y" = 10, "z" = 15), qual código obtém a soma dos elementos dea?- sum(a)
- sum(list(a))
- sum(unlist(a))
- Seja
nova_lista <- list(a = 1:10, b = "Bom dia", c = "Olá"). Escreva o código que adiciona 1 a cada elemento do primeiro vetor denova_lista.
10:00
De forma geral…
O R armazena objetos de diversas formas (estruturas). Há, portanto, cinco tipos de dados comumente utilizados na análise de dados:
| Homogêneo | Heterogêneo | |
|---|---|---|
| 1-D | Vetor | Lista |
| 2-D | Matriz | Data frame |
| n-D | Array |