Análise de Dados e Documentos Dinâmicos
Tópico IV - Manipulação de Dados II
2024-04-17
Junção de Dados
- Nesta parte do curso, veremos algumas funções úteis para realizar a junção (ou joins ou merge) de bases de dados no
R. - O join de bases de dados surge da necessidade de juntar informações de fontes distintas em uma única base de dados.
- Join é um conceito bastante comum para quem já trabalha com bancos de dados (principalmente com SQL).

Junção de Dados
Para entender o conceito de joins, utilizaremos a representação gráfica baseada no livro R for Data Science. Considere dois bancos de dados, com a chave dos indivíduos e o valor de uma variável

De forma geral
O pacote dplyr possui funções que possibilitam realizar o joins (ou merge) de duas bases de dados. Podemos utilizar o diagrama de Venn para ter uma visão geral dos diferentes tipos:
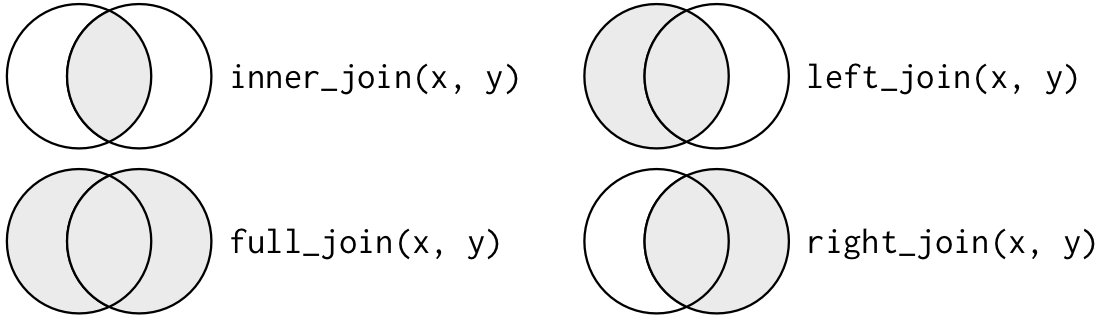
Usando o inner_join()
O resultado do inner_join() é uma nova base que contem as chaves comuns nas duas bases e os valores da variáveis na base de dados x e na base de dados y

Usando o left_join()
A função left_join() preserva todas as observações do lado esquerdo (x) e remove as informações do lado direito (y) que não possuem correspondência.

- O resultado é uma base com informações dos indivíduos 1, 2, e 3 .
- O indivíduo 4 foi excluído por não ter correspondência em
x.
Usando o right_join()
O comando right_join() preserva todas as observações do lado direito e remove as informações do lado esquerdo que não possuem correspondência.

- Neste caso, o resultado é uma base com informações dos pacientes 1, 2, e 4. O indivíduo 3 foi excluido por não ter não ter correspondência em
y.
Usando o full_join()
O comando full_join() preserva todas as observações de ambos os bancos

- O resultado é uma base com informações completas, com as correspondências incompletas representadas por
NA.
O pacote tidyr
O pacote tidyr dispõe de funções bastante úteis para organizar os dados no formato necessário para a análise.

Pivoting
Existem dois tipos de formatação dos dados:
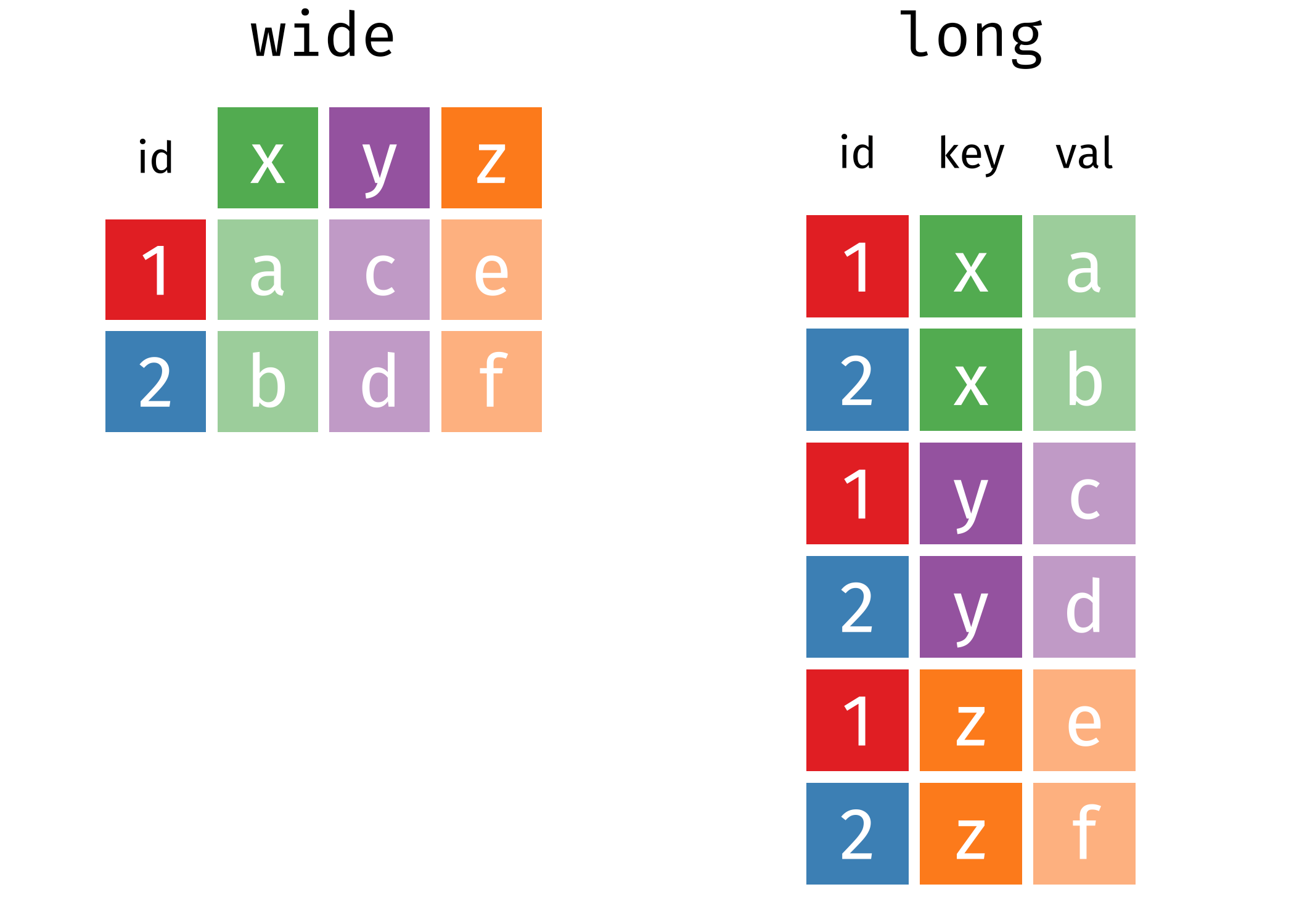
Pivoting
As principais funções para transformar os dados para formato long ou wide são:
pivot_longer(): empilha o banco de dados, deixando no formato longo (long).pivot_wider(): transforma o banco para um formato expandido (wide).
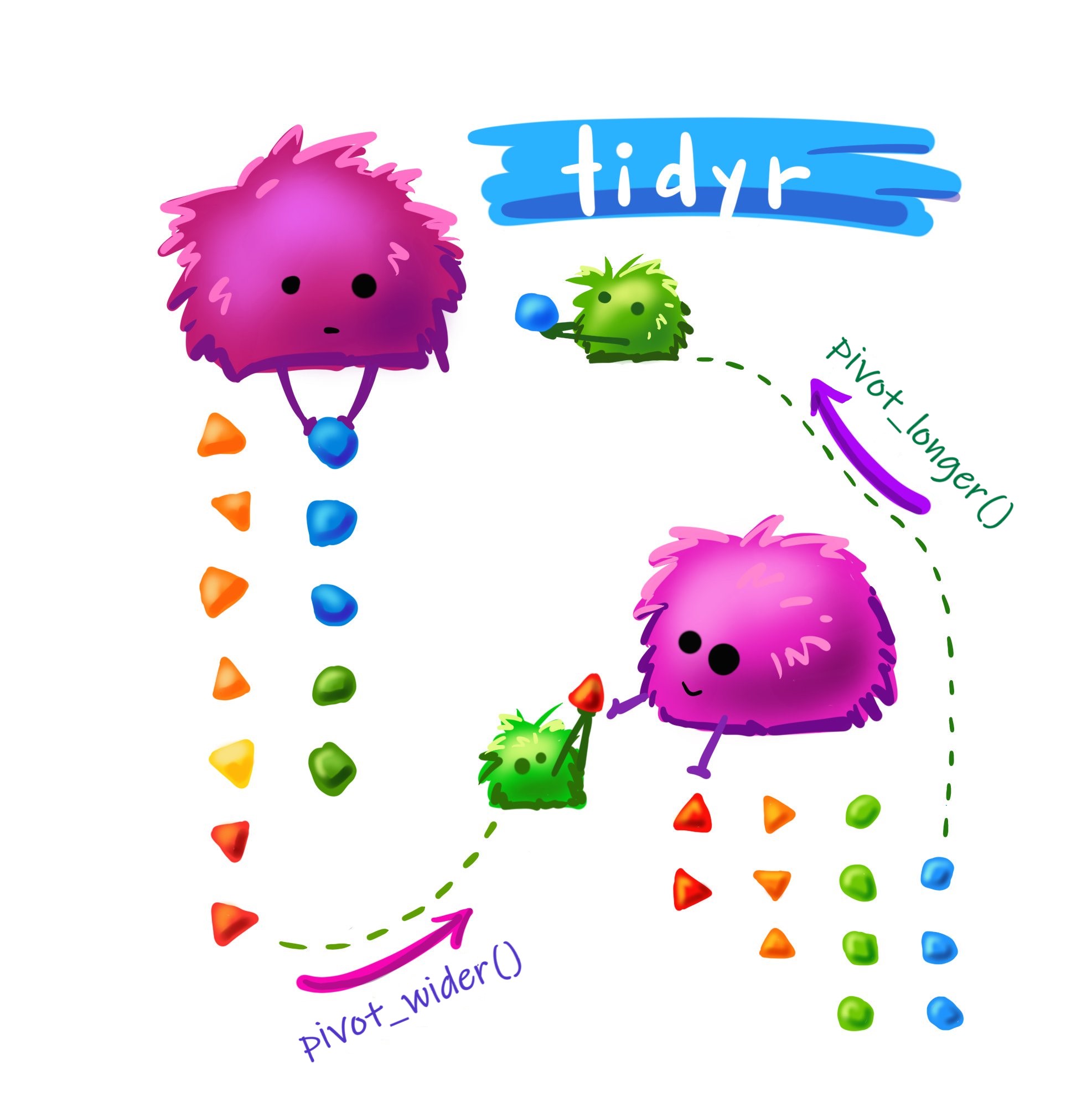
A função pivot_longer()
pivot_longer(): empilha o banco de dados, deixando no formato longo.

A função pivot_wider()
A função pivot_wider() transforma o banco para um formato expandido (wide)
