Análise de Dados e Documentos Dinâmicos
Tópico III - Manipulação de Dados
2024-04-14
Manipulação de Dados
Seguindo o fluxo da Ciência de Dados, o objetivo agora é organizar e transformar os dados a fim de obter uma base pronta para análise.
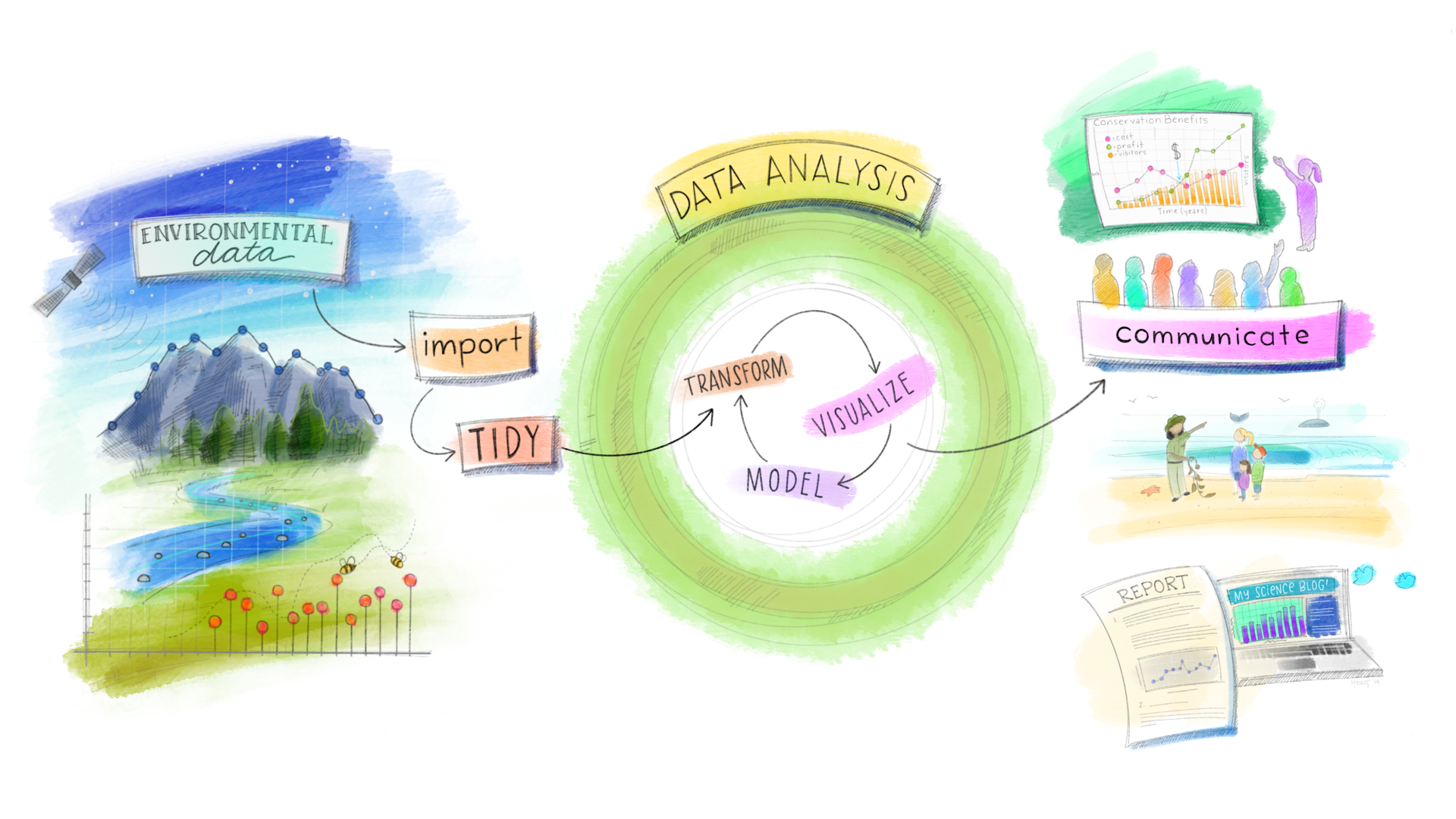
Manipulação de Dados
Nesta parte do curso, veremos alguns importantes pacotes de manipulação de dados no R:
dplyr: pacote para tratamento e manipulação de bases de dados.tidyr: pacote para a formatação dos dados.
Estes e outros pacotes fazem parte de um sistema integrado de pacotes para ciência de dados conhecido por tidyverse, os quais compartilham de uma mesma concepção, gramática e funcionalidade.
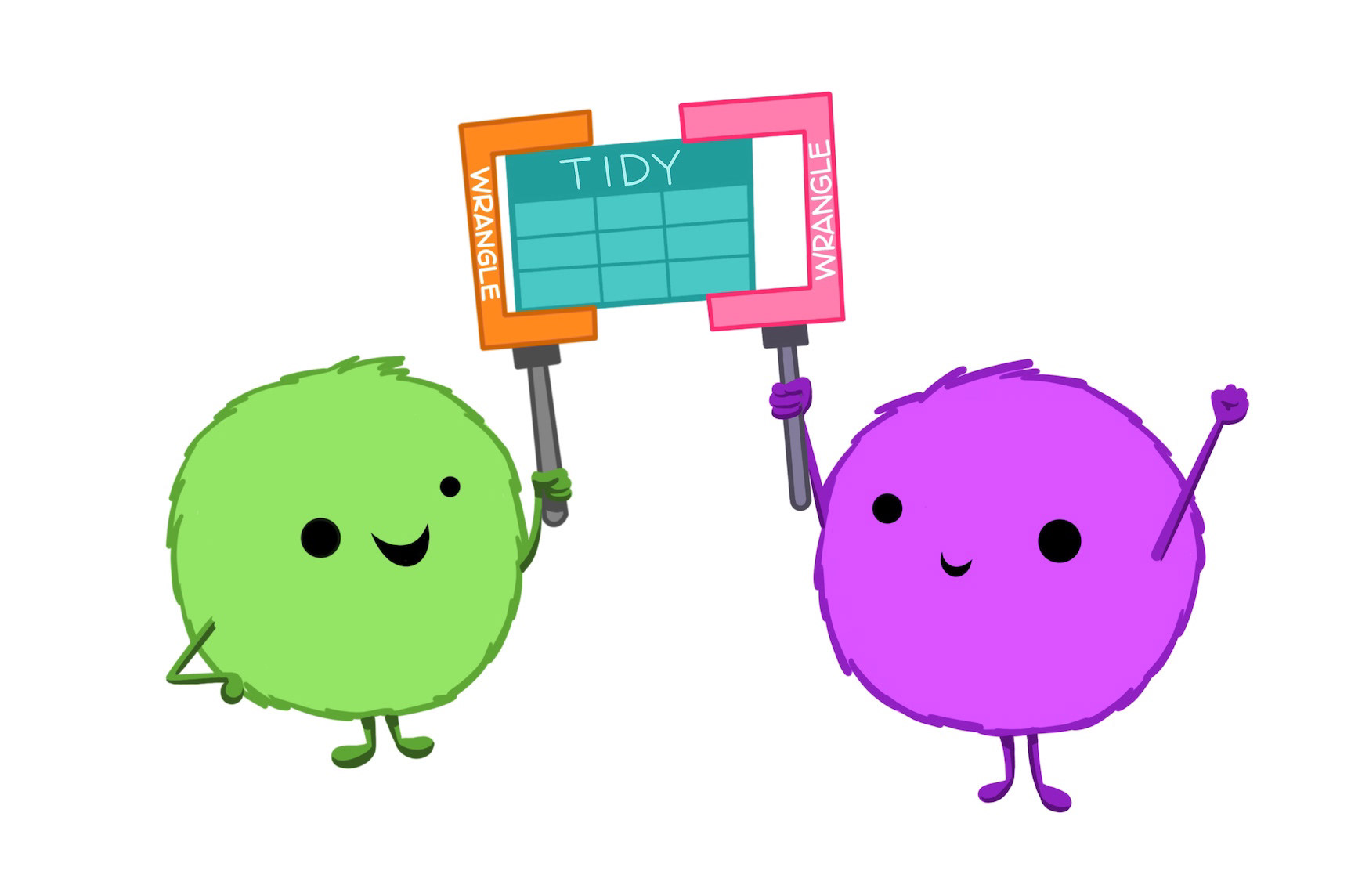
Tidyverse

Para instalar os pacotes do tidyverse, fazemos:
Tidyverse


Para mais informações sobre os pacotes que fazem parte do tidyverse, ver https://tidyverse.tidyverse.org/index.html
Manipulação de Dados
Um importante conceito para se obter uma base analítica é o data tidying, ou organização dos dados. Um banco de dados é considerado tidy se:
- Cada observação forma uma única linha.
- Cada variável forma uma única coluna.
- Cada célula armazena um único valor.
- O dados tidy podem ser utilizados diretamente para modelagem ou visualização.

Tibbles
Uma tibble é um tipo especial de data frame, com características otimizadas para facilitar a manipulação dos dados.
Pipes |>
- Os operadores
|>são chamados de pipes - Foram introduzidos, pela primeira vez, através do pacote
magrittr. - Pipes são operadores sequenciais e podem ser lidos como e “então…”
- Versões anteriores do pipe:
%.%e%>%(para versões anteriores a 4.1.0) - O pipe
|>é operador nativo doR(tecla de atalhoCtrl + Shift + M)

Pipes |>
No RStudio, inserimos o novo pipe como default em Tools > Global Options

Pipes |>
O pipe |> funciona de forma simples: utiliza o valor resultante da operação do lado esquerdo como argumento da função do lado direito:
O pacote dplyr
- O
dplyré um pacote bastante útil para manipular dados. - Os códigos são escritos de uma maneira intuitiva e elegante.
- Se utilizam dos pipes para realizar operações sequenciais.

O pacote dplyr
As principais funções do dplyr são:
select(): seleciona por coluna do banco de dadosfilter(): seleciona linhas baseado em seu valormutate(): cria/modifica colunas baseado em colunas existentessummarise(): realiza operações sobre um conjunto de valoresarrange(): reordena as linhas da base de dados
Tais funções correspodem a maior parte das operações usuais de manipulação. Para aprender mais, ver vignette("dplyr")
Dados do PNUD
Nesta parte, utilizaremos os dados do PNUD (Programa das Nações Unidas para o Desenvolvimento), contendo informações socioeconômicas de todos os municípios do país, obtidos a partir dos Censos de 1991, 2000 e 2010.
# Abrir dados
pnud_mun <- readr::read_csv(
"dados/pnud_mun.csv",
show_col_types = F
)
# Ver dados
head(pnud_mun)
## # A tibble: 6 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA … RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
## 2 1991 ARIQU… RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018
## 3 1991 CABIXI RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
## 4 1991 CACOAL RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
## 5 1991 CEREJ… RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
## 6 1991 COLOR… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
## # ℹ 2 more variables: lat <dbl>, lon <dbl>A função select()
Utilizamos select() para selecionar variáveis ou colunas de uma base de dados:

A função select()
A função select() seleciona um subconjunto das variáveis (colunas).
# Selecionar variaveis
pnud_mun |>
select(
ano, regiao, muni
)
## # A tibble: 16,686 × 3
## ano regiao muni
## <dbl> <chr> <chr>
## 1 1991 Norte ALTA FLORESTA D'OESTE
## 2 1991 Norte ARIQUEMES
## 3 1991 Norte CABIXI
## 4 1991 Norte CACOAL
## 5 1991 Norte CEREJEIRAS
## 6 1991 Norte COLORADO DO OESTE
## 7 1991 Norte CORUMBIARA
## 8 1991 Norte COSTA MARQUES
## 9 1991 Norte ESPIGÃO D'OESTE
## 10 1991 Norte GUAJARÁ-MIRIM
## # ℹ 16,676 more rowsA função select()
É possível selecionar variáveis através dos nomes, índices, intervalos de variáveis ou utilizar as select helpers: starts_with(), ends_with(), contains(), matchs(), entre outras (ver link):
# Selecionar variaveis
pnud_mun |>
select(
1, muni, starts_with("idhm")
)
## # A tibble: 16,686 × 6
## ano muni idhm idhm_e idhm_l idhm_r
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA FLORESTA D'OESTE 0.329 0.112 0.617 0.516
## 2 1991 ARIQUEMES 0.432 0.199 0.684 0.593
## 3 1991 CABIXI 0.309 0.108 0.636 0.43
## 4 1991 CACOAL 0.407 0.171 0.667 0.593
## 5 1991 CEREJEIRAS 0.386 0.167 0.629 0.547
## 6 1991 COLORADO DO OESTE 0.376 0.151 0.658 0.536
## 7 1991 CORUMBIARA 0.203 0.039 0.572 0.373
## 8 1991 COSTA MARQUES 0.425 0.22 0.629 0.553
## 9 1991 ESPIGÃO D'OESTE 0.388 0.159 0.653 0.561
## 10 1991 GUAJARÁ-MIRIM 0.468 0.247 0.662 0.625
## # ℹ 16,676 more rowsA função select()
Outros exemplos:
# Selecionar variáveis
pnud_mun |>
select(
muni, uf, ends_with("vida"), contains("pc")
)
## # A tibble: 16,686 × 4
## muni uf espvida rdpc
## <chr> <chr> <dbl> <dbl>
## 1 ALTA FLORESTA D'OESTE RO 62.0 198.
## 2 ARIQUEMES RO 66.0 319.
## 3 CABIXI RO 63.2 116.
## 4 CACOAL RO 65.0 320.
## 5 CEREJEIRAS RO 62.7 240.
## 6 COLORADO DO OESTE RO 64.5 225.
## 7 CORUMBIARA RO 59.3 81.4
## 8 COSTA MARQUES RO 62.8 250.
## 9 ESPIGÃO D'OESTE RO 64.2 263.
## 10 GUAJARÁ-MIRIM RO 64.7 391.
## # ℹ 16,676 more rowsA função filter()
A função filter() permite selecionar observações baseado em seus valores ou em uma condição:

A função filter()
A função filter() filtra por linhas:
# Filtrar linhas
pnud_mun |>
select(
ano:uf, gini, pop
) |>
filter(
uf == "PB"
)
## # A tibble: 669 × 5
## ano muni uf gini pop
## <dbl> <chr> <chr> <dbl> <dbl>
## 1 1991 ÁGUA BRANCA PB 0.53 8048
## 2 1991 AGUIAR PB 0.49 6739
## 3 1991 ALAGOA GRANDE PB 0.6 30011
## 4 1991 ALAGOA NOVA PB 0.52 15140
## 5 1991 ALAGOINHA PB 0.47 11787
## 6 1991 ALCANTIL PB 0.42 3845
## 7 1991 ALGODÃO DE JANDAÍRA PB 0.37 2211
## 8 1991 ALHANDRA PB 0.48 13128
## 9 1991 SÃO JOÃO DO RIO DO PEIXE PB 0.56 17354
## 10 1991 AMPARO PB 0.5 1668
## # ℹ 659 more rowsA função filter()
Ainda, é possível realizar operações condicionais:
# Filtrar linhas
pnud_mun |>
select(
ano:uf, gini, pop
) |>
filter(
uf %in% c("PB", "RN"),
gini > 0.5,
ano == 2010
)
## # A tibble: 176 × 5
## ano muni uf gini pop
## <dbl> <chr> <chr> <dbl> <dbl>
## 1 2010 AÇU RN 0.53 52854
## 2 2010 AFONSO BEZERRA RN 0.53 10666
## 3 2010 ALEXANDRIA RN 0.53 13284
## 4 2010 ANGICOS RN 0.51 11421
## 5 2010 ANTÔNIO MARTINS RN 0.51 6783
## 6 2010 APODI RN 0.55 34143
## 7 2010 ARÊS RN 0.53 12632
## 8 2010 AUGUSTO SEVERO RN 0.68 9041
## 9 2010 BODÓ RN 0.52 2368
## 10 2010 BOM JESUS RN 0.54 9341
## # ℹ 166 more rowsO operador lógico %in% é utilizado para identificar se um elemento pertence ao vetor.
A função filter()
Para filtrar elementos contidos em um intervalo específico, fazemos:
# Filtrar linhas
pnud_mun |>
select(
ano, muni, uf, gini, pop
) |>
filter(
between(pop, 10000, 20000),
ano == 2010
)
## # A tibble: 1,385 × 5
## ano muni uf gini pop
## <dbl> <chr> <chr> <dbl> <dbl>
## 1 2010 CEREJEIRAS RO 0.5 16815
## 2 2010 COLORADO DO OESTE RO 0.49 18204
## 3 2010 COSTA MARQUES RO 0.52 13246
## 4 2010 NOVA BRASILÂNDIA D'OESTE RO 0.56 18998
## 5 2010 SÃO MIGUEL DO GUAPORÉ RO 0.62 19630
## 6 2010 ALVORADA D'OESTE RO 0.53 16275
## 7 2010 ALTO ALEGRE DOS PARECIS RO 0.54 11701
## 8 2010 ALTO PARAÍSO RO 0.54 16802
## 9 2010 CAMPO NOVO DE RONDÔNIA RO 0.67 11659
## 10 2010 CANDEIAS DO JAMARI RO 0.47 18992
## # ℹ 1,375 more rowsNeste caso, between(pop, 10000, 20000) equivale a testar se pop >= 10000 & pop <= 20000.
A função filter()
Para excluir elementos específicos, fazemos:
# Filtrar linhas
pnud_mun |>
select(
ano, muni, uf, regiao, rdpc
) |>
filter(
!(regiao %in% c("Norte", "Nordeste")),
ano == 2010
)
## # A tibble: 3,319 × 5
## ano muni uf regiao rdpc
## <dbl> <chr> <chr> <chr> <dbl>
## 1 2010 Abadia dos Dourados MG Sudeste 596.
## 2 2010 Abaeté MG Sudeste 707.
## 3 2010 Abre Campo MG Sudeste 444.
## 4 2010 Acaiaca MG Sudeste 357.
## 5 2010 Açucena MG Sudeste 325.
## 6 2010 Água Boa MG Sudeste 322.
## 7 2010 Água Comprida MG Sudeste 701.
## 8 2010 Aguanil MG Sudeste 524.
## 9 2010 Águas Formosas MG Sudeste 390.
## 10 2010 Águas Vermelhas MG Sudeste 307.
## # ℹ 3,309 more rowsA função mutate()
A função mutate() cria ou modifica variáveis (colunas) baseado em outras variáveis do banco de dados:

A função mutate()
A função mutate() cria ou modifica colunas (variáveis). Como exemplo,
# Criar variaveis
pnud_mun |>
select(
muni, uf, rdpc, pop
) |>
filter(
uf == "PB"
) |>
mutate(
pib = rdpc * pop,
pais = "Brasil"
)
## # A tibble: 669 × 6
## muni uf rdpc pop pib pais
## <chr> <chr> <dbl> <dbl> <dbl> <chr>
## 1 ÁGUA BRANCA PB 63.2 8048 508553. Brasil
## 2 AGUIAR PB 88.3 6739 595121. Brasil
## 3 ALAGOA GRANDE PB 146 30011 4381606 Brasil
## 4 ALAGOA NOVA PB 102. 15140 1541555. Brasil
## 5 ALAGOINHA PB 85.3 11787 1005549. Brasil
## 6 ALCANTIL PB 120. 3845 461823. Brasil
## 7 ALGODÃO DE JANDAÍRA PB 69.7 2211 154129. Brasil
## 8 ALHANDRA PB 130. 13128 1710447. Brasil
## 9 SÃO JOÃO DO RIO DO PEIXE PB 72.2 17354 1253653. Brasil
## 10 AMPARO PB 61.4 1668 102382. Brasil
## # ℹ 659 more rowsAlterando múltiplas colunas com across()
- Em muitas situações, é comum fazer uma mesma operação em múltipas colunas. No entanto, copiar e colar pode ser tedioso e passível de erros.
- A função
across()facilita tais operações de uma forma clara e sucinta

Alterando múltiplas colunas com across()
Utilizamos across() dentro da função mutate() para alterar múltiplas colunas:
# Alterar escala de variaveis
pnud_mun |>
select(
ano:idhm_r
) |>
filter(
uf == "CE"
) |>
mutate(
across(starts_with("idhm"), ~.x * 100)
)
## # A tibble: 552 × 8
## ano muni uf regiao idhm idhm_e idhm_l idhm_r
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ABAIARA CE Nordeste 28.6 10.3 60 37.7
## 2 1991 ACARAPE CE Nordeste 34.9 17.9 53.7 44.3
## 3 1991 ACARAÚ CE Nordeste 27.7 8.9 53.4 44.9
## 4 1991 ACOPIARA CE Nordeste 25.4 7.7 51.4 41.3
## 5 1991 AIUABA CE Nordeste 25.6 8.1 57.4 36
## 6 1991 ALCÂNTARAS CE Nordeste 28.5 12.2 49 38.6
## 7 1991 ALTANEIRA CE Nordeste 28.8 12.2 51.2 38.1
## 8 1991 ALTO SANTO CE Nordeste 30.4 9.7 66.1 43.8
## 9 1991 AMONTADA CE Nordeste 24.1 6.2 61.9 36.6
## 10 1991 ANTONINA DO NORTE CE Nordeste 30.9 12.9 56.1 40.9
## # ℹ 542 more rows- O símbolo
~.xrepresenta uma variável dinâmica, guardando informações sobre todas as variáveis selecionadas.
A função arrange()
A função arrange() ordena a base de dados baseada em uma ou mais variáveis:

A função arrange()
- A função
arrange()ordena a base de dados, baseada em uma ou mais variáveis -Como default, os valores são ordenados na ordem crescente - Para ordenar em ordem decrescente, utiliza-se o argumento
desc()
# Ordenar linhas
pnud_mun |>
select(
ano, muni, uf, regiao, espvida
) |>
filter(
ano == 2010,
regiao == "Nordeste"
) |>
arrange(
desc(espvida)
)
## # A tibble: 1,794 × 5
## ano muni uf regiao espvida
## <dbl> <chr> <chr> <chr> <dbl>
## 1 2010 FERNANDO DE NORONHA PE Nordeste 75.4
## 2 2010 OLINDA PE Nordeste 75.2
## 3 2010 SALVADOR BA Nordeste 75.1
## 4 2010 NATAL RN Nordeste 75.1
## 5 2010 SOBRAL CE Nordeste 74.9
## 6 2010 JOÃO PESSOA PB Nordeste 74.9
## 7 2010 JABOATÃO DOS GUARARAPES PE Nordeste 74.8
## 8 2010 PAULISTA PE Nordeste 74.8
## 9 2010 SÃO GONÇALO DO AMARANTE RN Nordeste 74.7
## 10 2010 LAURO DE FREITAS BA Nordeste 74.6
## # ℹ 1,784 more rowsA função summarise()
A função summarise() realiza operações sobre um conjunto de observações, reduzindo variáveis a valores.

A função summarise()
A função summarise() realiza operações sobre um conjunto de valores. Suponha que queiramos obter a renda per capita média dos municípios em 2010:
A função summarise()
Em geral, tal função é utilizada conjuntamente com a função group_by(), a qual serve para realizar operações dentro de um grupo. Por exemplo, para obter a renda média dos estados brasileiros, fazemos:
# Agregacao por gupo
pnud_mun |>
filter(
ano == 2010
) |>
group_by(
uf
) |>
summarise(
m_rdpc = mean(rdpc)
) |>
arrange(
desc(m_rdpc)
)
## # A tibble: 27 × 2
## uf m_rdpc
## <chr> <dbl>
## 1 DF 1715.
## 2 SC 767.
## 3 RS 742.
## 4 SP 714.
## 5 RJ 666.
## 6 PR 610.
## 7 MS 597.
## 8 GO 583.
## 9 MT 580.
## 10 ES 576.
## # ℹ 17 more rowsA função summarise()
Podemos agrupar por mais de uma variável, como no exemplo a seguir:
# Agregacao por gupo
pnud_mun |>
select(
ano, regiao, gini
) |>
group_by(
regiao, ano
) |>
summarise(
m_gini = mean(gini)
) |>
arrange(
desc(m_gini)
)
## # A tibble: 15 × 3
## # Groups: regiao [5]
## regiao ano m_gini
## <chr> <dbl> <dbl>
## 1 Norte 2000 0.599
## 2 Norte 2010 0.568
## 3 Nordeste 2000 0.562
## 4 Centro-Oeste 2000 0.561
## 5 Norte 1991 0.543
## 6 Centro-Oeste 1991 0.541
## 7 Sul 1991 0.531
## 8 Sudeste 2000 0.530
## 9 Nordeste 2010 0.525
## 10 Sul 2000 0.524
## 11 Sudeste 1991 0.522
## 12 Nordeste 1991 0.517
## 13 Centro-Oeste 2010 0.495
## 14 Sudeste 2010 0.466
## 15 Sul 2010 0.460Contando elementos
Algumas funções auxiliam na contagem de elementos em um banco de dados
n(): permite a contagem do número de linhas por grupo, independente de agrupamenton_distinct(): possibilita a contagem de elementos distintos em um vetor.count(): permite sumarizar a contagem de linhas em um grupo.
Contando elementos
Contando elementos
Contando elementos
Contando elementos
# Contando elementos por grupo
pnud_mun |>
select(
ano, uf, regiao, gini
) |>
filter(
ano == 2010
) |>
group_by(
uf
) |>
count()
## # A tibble: 27 × 2
## # Groups: uf [27]
## uf n
## <chr> <int>
## 1 AC 22
## 2 AL 102
## 3 AM 62
## 4 AP 16
## 5 BA 417
## 6 CE 184
## 7 DF 1
## 8 ES 78
## 9 GO 245
## 10 MA 217
## # ℹ 17 more rowsRenomeando variáveis com rename()
Para renomear variáveis, utilizamos a função rename(), com a sintaxe dada por rename(nome_novo = nome_antigo)
# Renomeando variaveis
pnud_mun |>
select(
ano, regiao, gini
) |>
rename(
regiao_br = regiao, ind_gini = gini
)
## # A tibble: 16,686 × 3
## ano regiao_br ind_gini
## <dbl> <chr> <dbl>
## 1 1991 Norte 0.63
## 2 1991 Norte 0.57
## 3 1991 Norte 0.7
## 4 1991 Norte 0.66
## 5 1991 Norte 0.6
## 6 1991 Norte 0.62
## 7 1991 Norte 0.59
## 8 1991 Norte 0.65
## 9 1991 Norte 0.63
## 10 1991 Norte 0.6
## # ℹ 16,676 more rowsUsando if_else()
Uma função bastante útil é if_else(). Ela é utilizada para criar uma nova variável baseado em uma condição: se a condição for TRUE, atribuímos um valor; caso contrário (se FALSE), atribuímos outro valor.

Usando if_else()
Por exemplo, considere que desejamos criar uma variável indicando se a expectativa de vida é alta ou baixa baseado na média da expectativa de vida:
# Criando variaveis baseado em uma condicao
media_espvida_2010 <- pnud_mun |>
filter(
ano == 2010
) |>
summarise(
m_esp_vida = mean(espvida)
) |>
pull()
pnud_mun |>
filter(
ano == 2010
) |>
select(
muni, uf, espvida
) |>
mutate(
ind_espvida = if_else(espvida >= media_espvida_2010, "alta", "baixa")
)
## # A tibble: 5,562 × 4
## muni uf espvida ind_espvida
## <chr> <chr> <dbl> <chr>
## 1 ALTA FLORESTA D'OESTE RO 70.8 baixa
## 2 ARIQUEMES RO 73.4 alta
## 3 CABIXI RO 70.4 baixa
## 4 CACOAL RO 74.3 alta
## 5 CEREJEIRAS RO 72.9 baixa
## 6 COLORADO DO OESTE RO 73.8 alta
## 7 CORUMBIARA RO 71.4 baixa
## 8 COSTA MARQUES RO 70.0 baixa
## 9 ESPIGÃO D'OESTE RO 74.2 alta
## 10 GUAJARÁ-MIRIM RO 74.4 alta
## # ℹ 5,552 more rowsA função case_when
A função case_when() permite vetorizar múltiplas operações condicionais do tipo if_else. Neste caso, permite criar várias categorias:
pnud_mun |>
select(
ano, regiao, gini
) |>
mutate(
concentracao = case_when(
gini < 0.4 ~ "baixa",
gini >= 0.4 & gini < 0.6 ~ "média",
gini >= 0.6 ~ "alta"
)
)
## # A tibble: 16,686 × 4
## ano regiao gini concentracao
## <dbl> <chr> <dbl> <chr>
## 1 1991 Norte 0.63 alta
## 2 1991 Norte 0.57 média
## 3 1991 Norte 0.7 alta
## 4 1991 Norte 0.66 alta
## 5 1991 Norte 0.6 alta
## 6 1991 Norte 0.62 alta
## 7 1991 Norte 0.59 média
## 8 1991 Norte 0.65 alta
## 9 1991 Norte 0.63 alta
## 10 1991 Norte 0.6 alta
## # ℹ 16,676 more rowsMais sobre dplyr
Para uma visão geral de todas as funções disponíveis no dplyr, ver os links abaixo:
Roteiro prático
Roteiro prático
“De acordo com a OMS (Organização Mundial da Saúde), o Brasil é o quarto país no mundo em mortes por violência no trânsito. Em 2018, 1,35 milhão de pessoas morreram no trânsito.” (Exame, 24/09/2019)

- Este roteiro utiliza os dados de acidentes agrupados por pessoas da PRF (Polícia Rodoviária Federal) para o ano de 2023, disponível neste link
Quizz #1
- Instale e carregue o pacote
dplyr. - Crie a pasta
Dadosno seu dirétorio de trabalho e salve o arquivoacidentes2023.zip. - Abra o arquivo através de uma das funções do pacote
readr, salvando com o nomeacidentes_br_2023. Dica: verificar encoding dos dados. - Observe a estrutura dos dados através da função
glimpse(), uma opção à funçãostr(). - Obtenha o número total de pessoas envolvidas em acidentes de trânsito, utilizando a variável
pesiddo banco de dados. - Qual o número total de feridos graves no trânsito em 2023? E o de pessoas mortas?
Quizz #1
- Em que dia da semana se concentrou o maior número de acidentes? E em que dia ocorreu menos acidentes?
- Calcule o número de acidentes que ocorre por tipo de pista, através da variável
tipo_pista. - E em qual turno do dia ocorrem mais acidentes? Utilize a variável
fase_dia. - Mostre o número de acidentes por estado (em termos percentuais).
- Apresente as cinco principais causas de acidentes de trânsito em 2023, listados em ordem decrescente.
- Elabore mais uma estatística interessante com os dados.
Análise de Dados e Documentos Dinâmicos