06 - Базові інструменти прогнозування
Прогнозування часових рядів
10/25/22
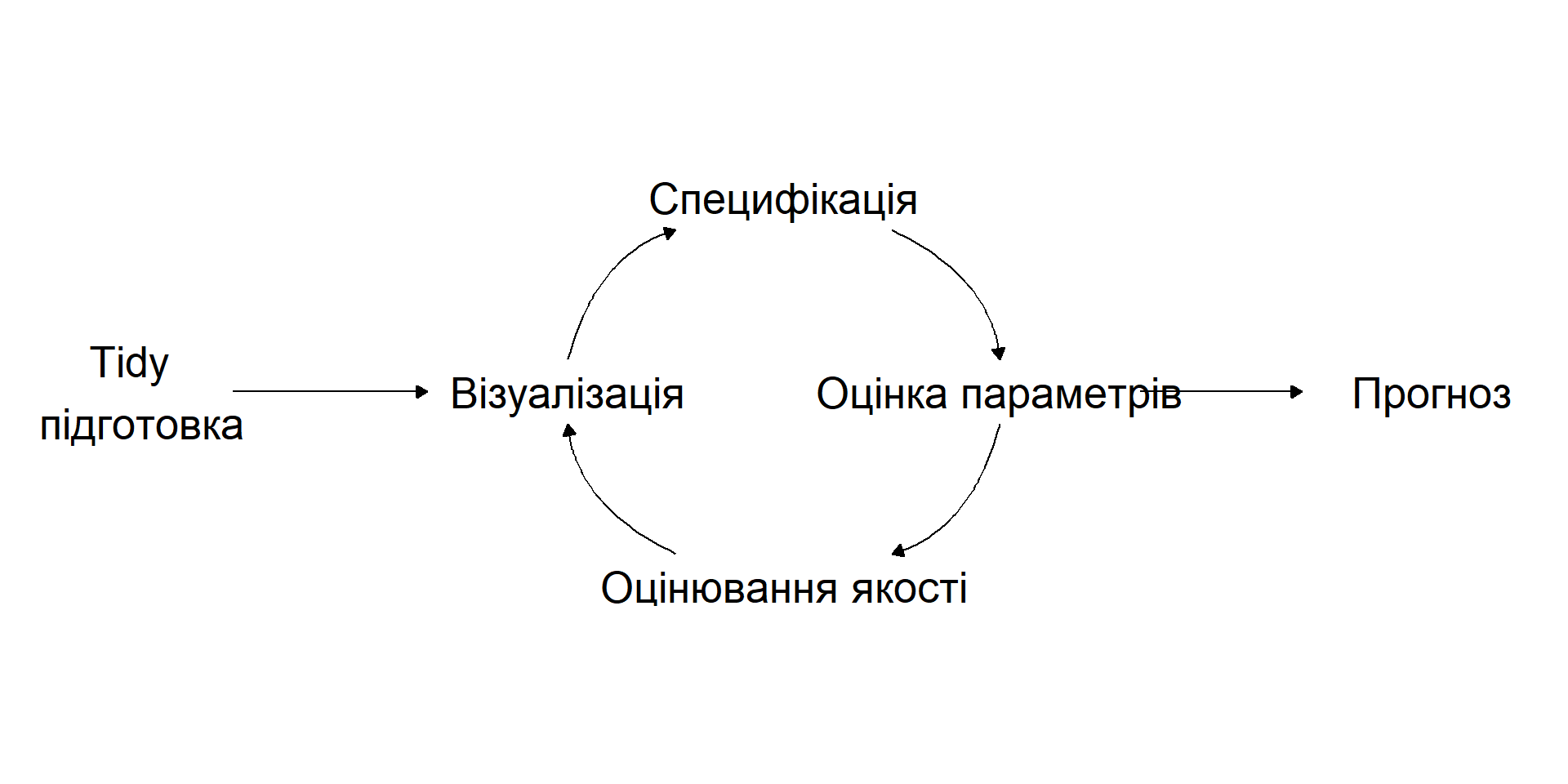
Етапи
Процес можна розбити на такі етапи:
Підготовка даних
Візуалізація
Специфікація моделі
Оцінювання параметрів моделі
Оцінювання якості та точності
Побудова прогнозів
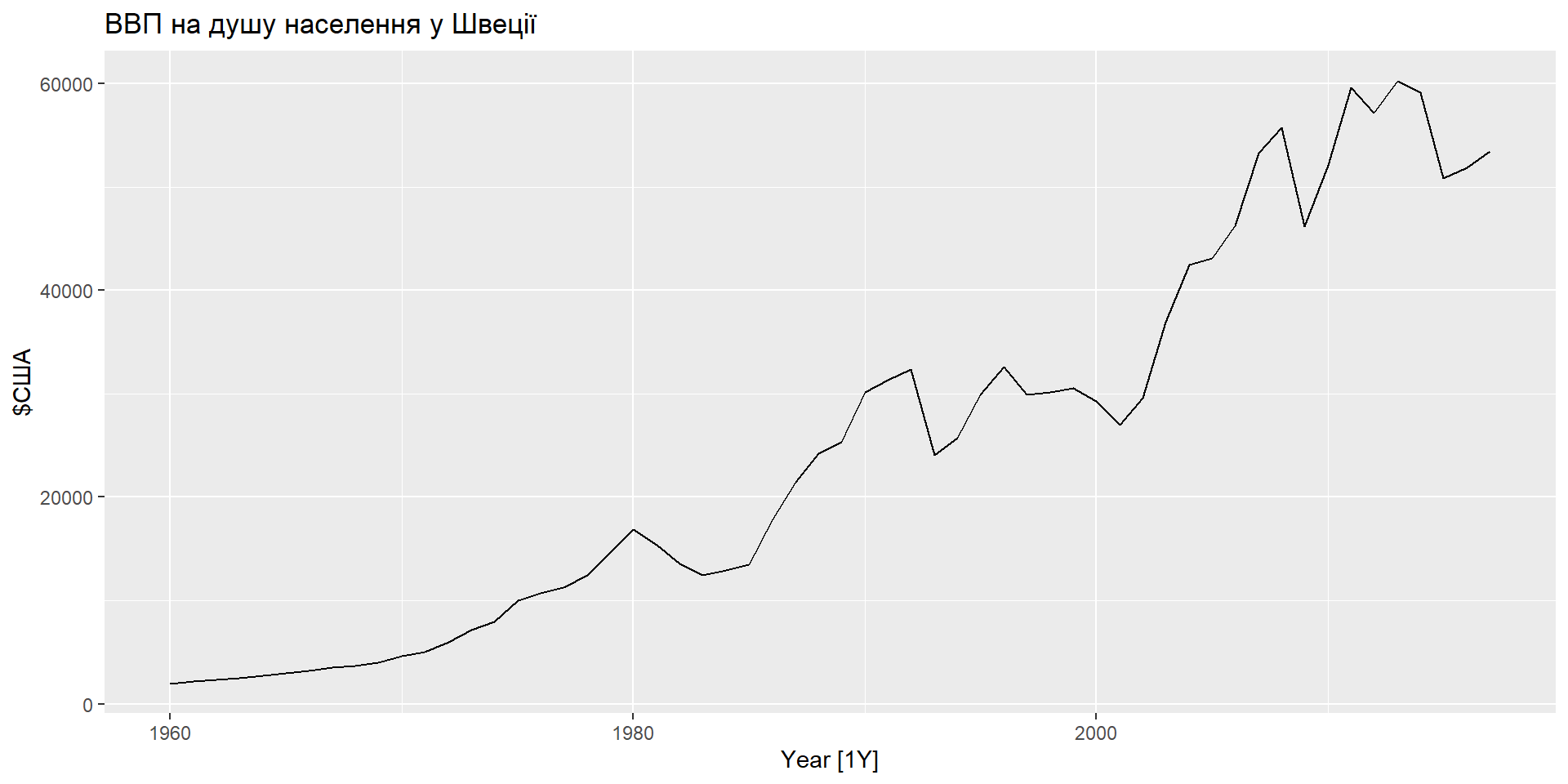
Візуалізація
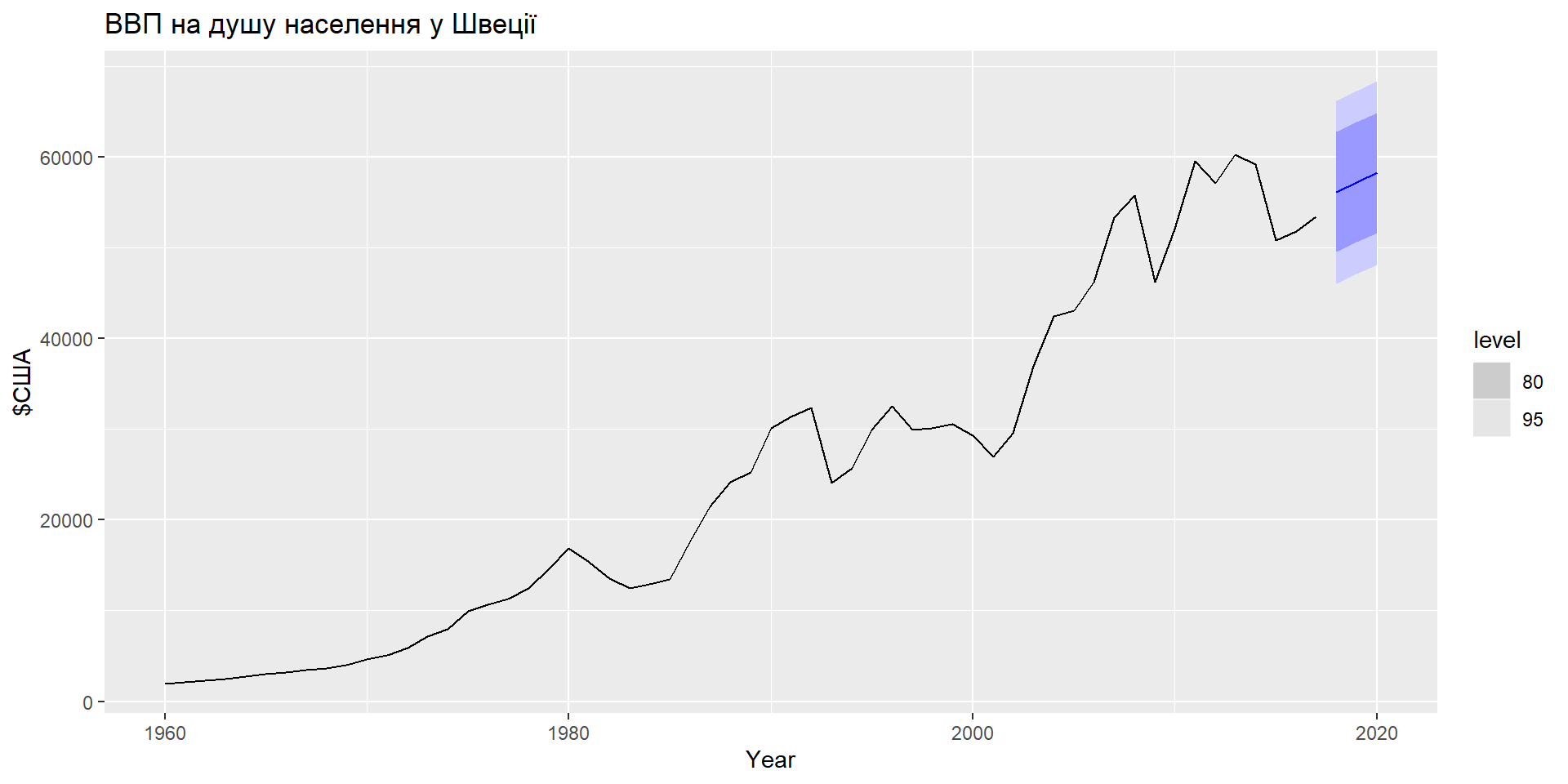
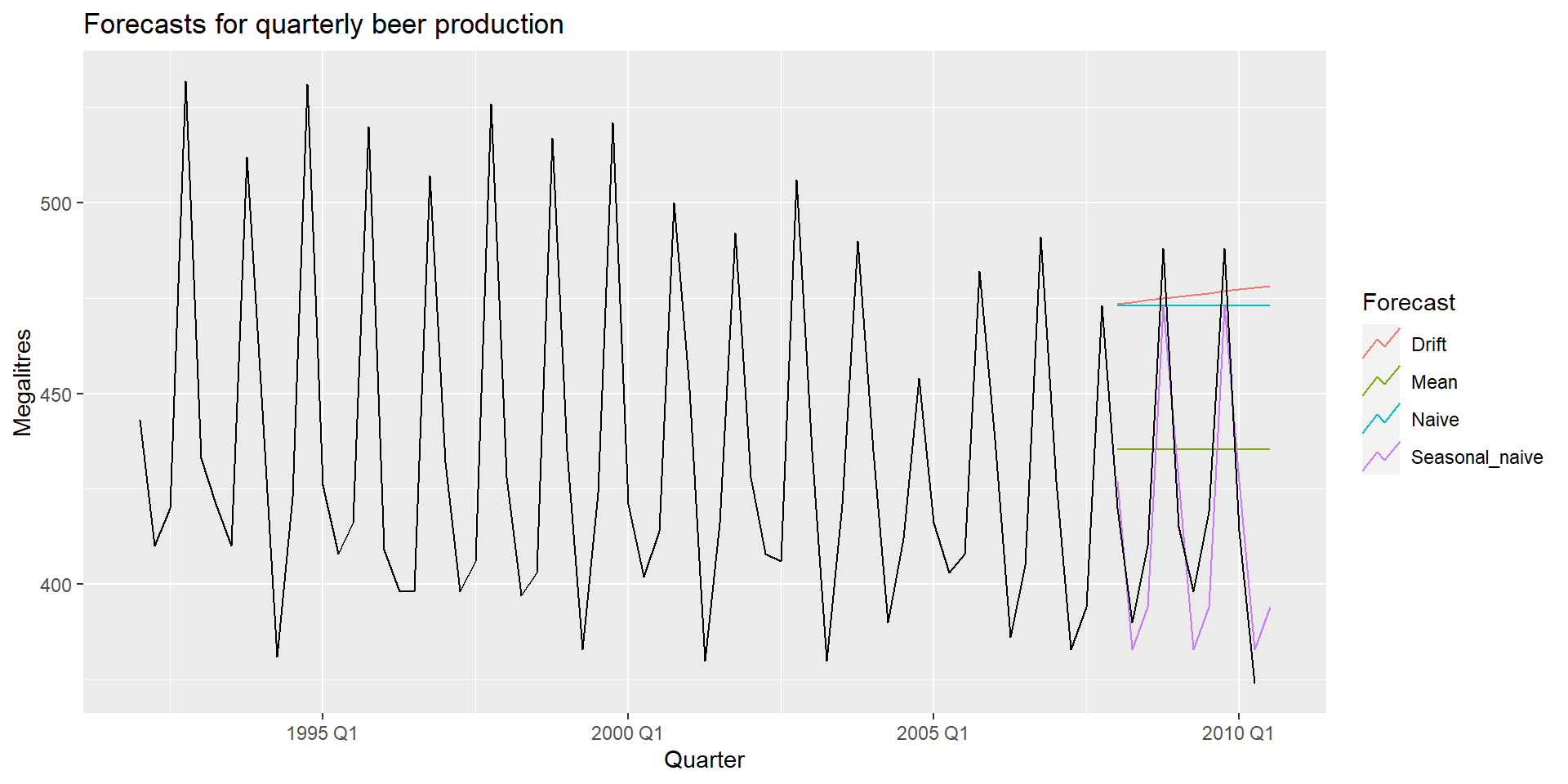
Візуалізація прогнозів
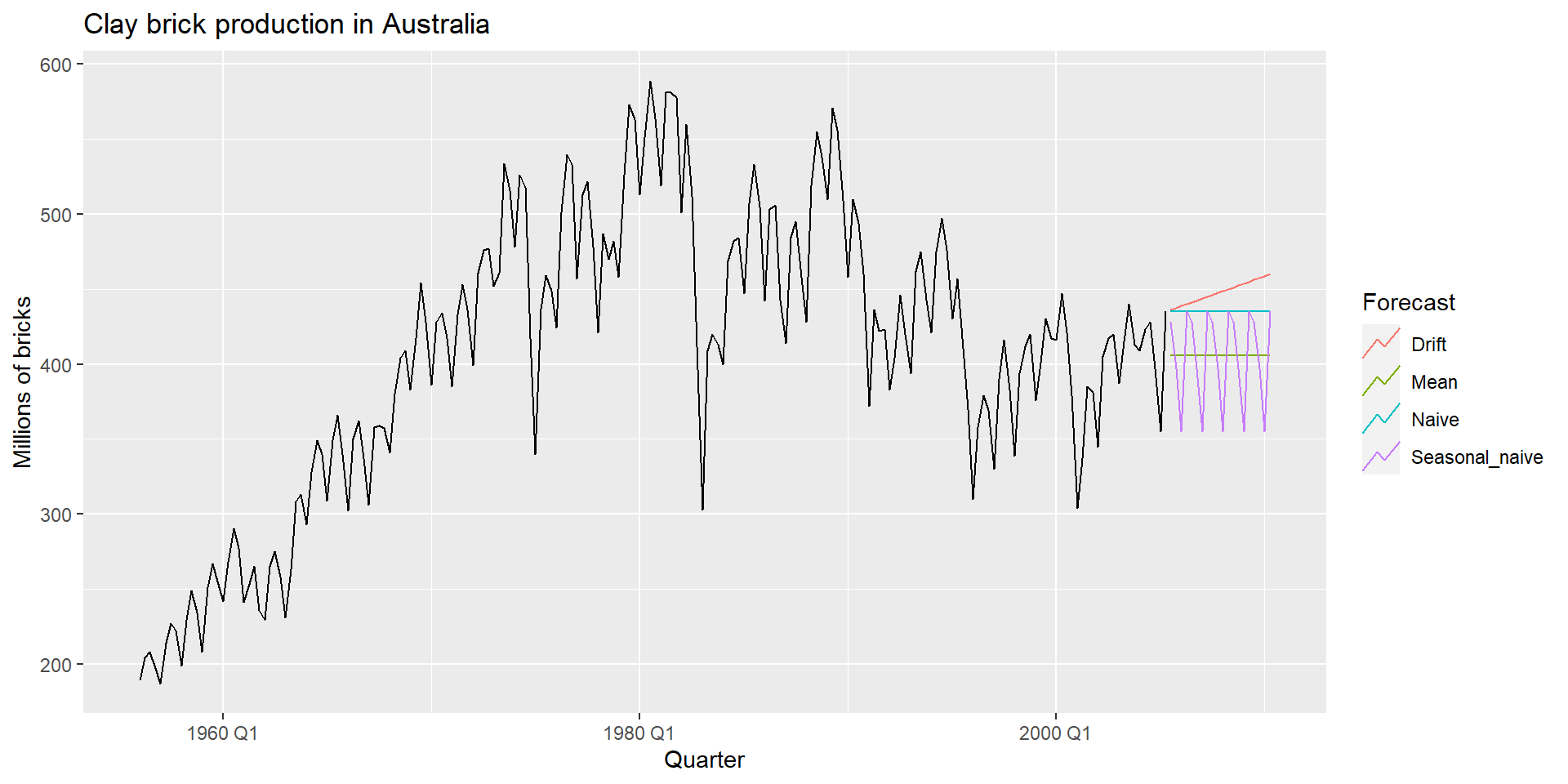
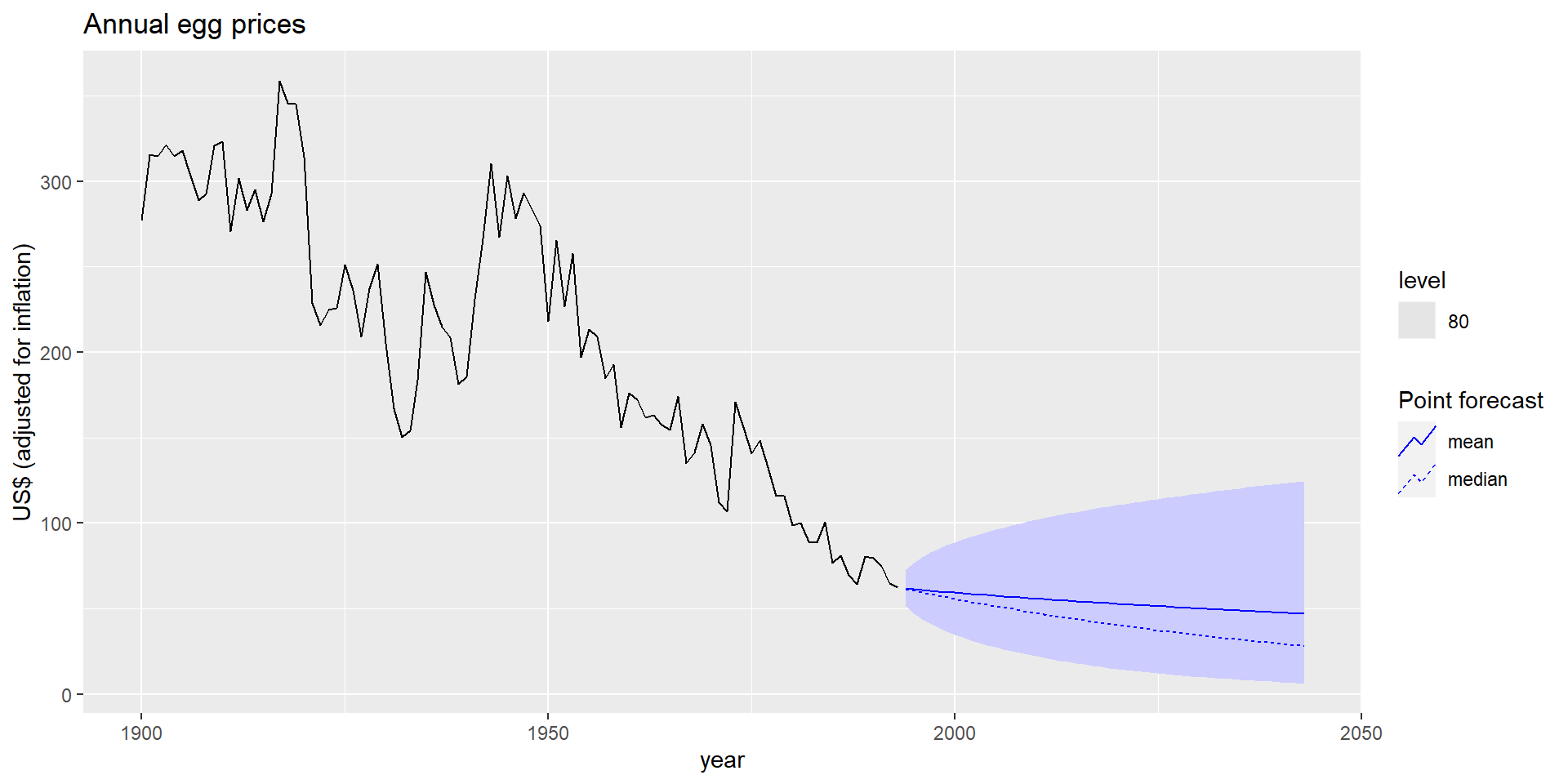
MEAN(y): Метод на основі середнього
Прогноз усіх майбутніх значень дорівнює середньому з вибірки \(\{y_1,\dots,y_T\}\).
Прогнози: \(\hat{y}_{T+h|T} = \bar{y} = (y_1+\dots+y_T)/T\)
NAIVE(y): Наївний метод
Прогноз дорівнює останньому значенню з вибірки.
Прогнози: \(\hat{y}_{T+h|T} =y_T\).
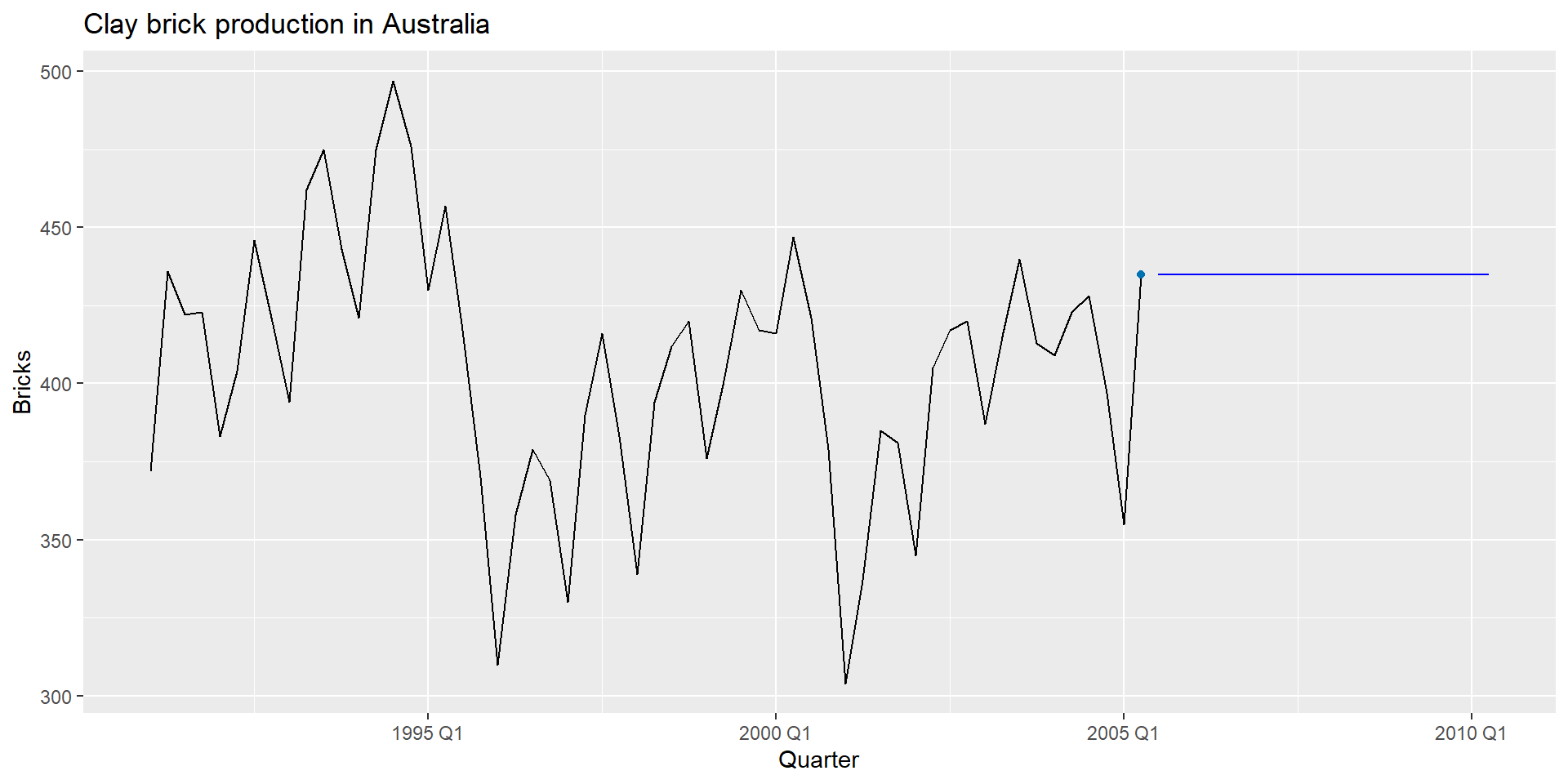
SNAIVE(y ~ lag(m)): Сезонний наївний метод
Прогнози дорівнюють останньому значенню минулого сезону.
Прогнози: \(\hat{y}_{T+h|T} =y_{T+hm(k+1)}\), де \(m=\) сезонний період, а \(k\) – ціла частина \((h -1)/m\).
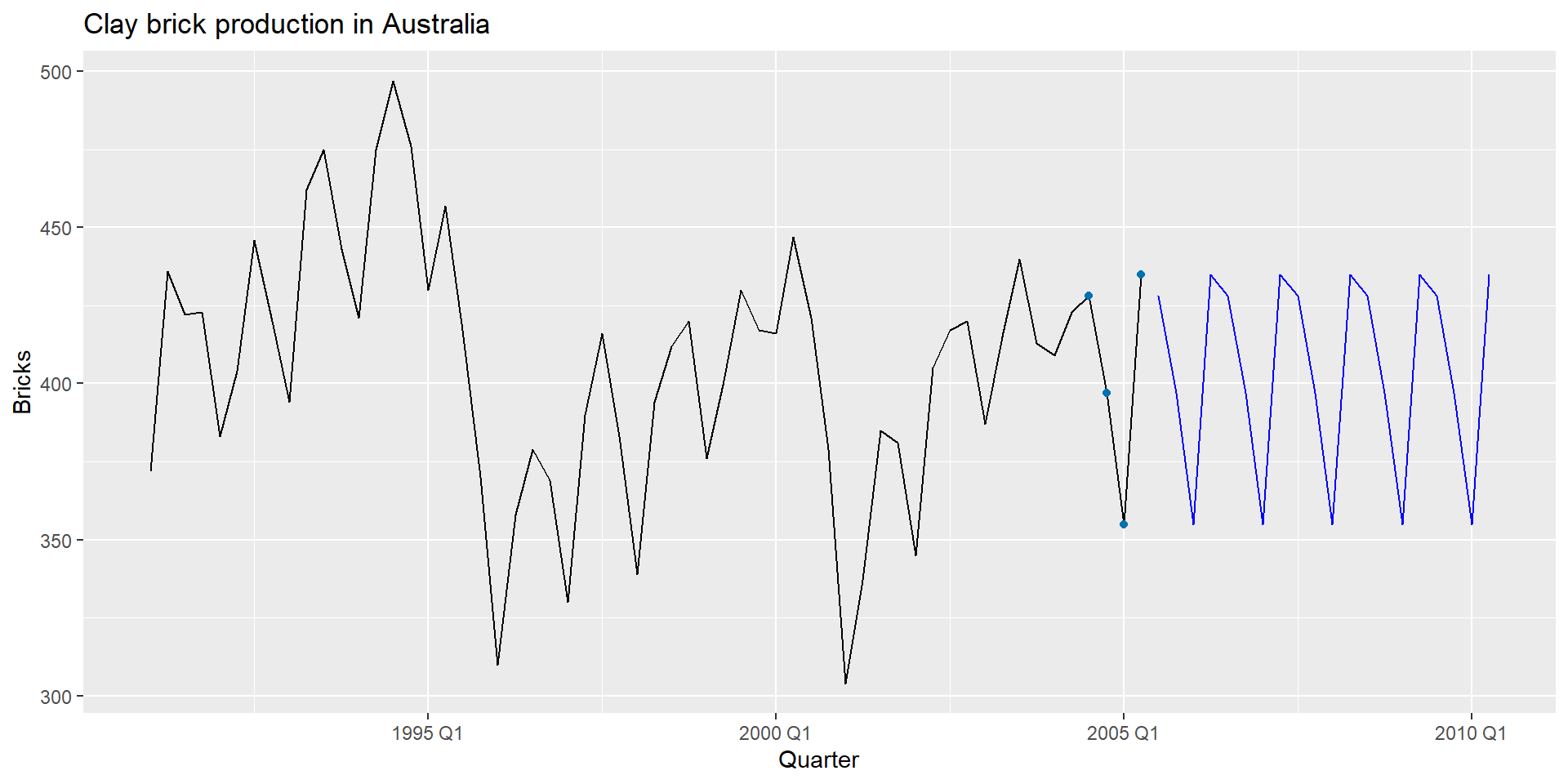
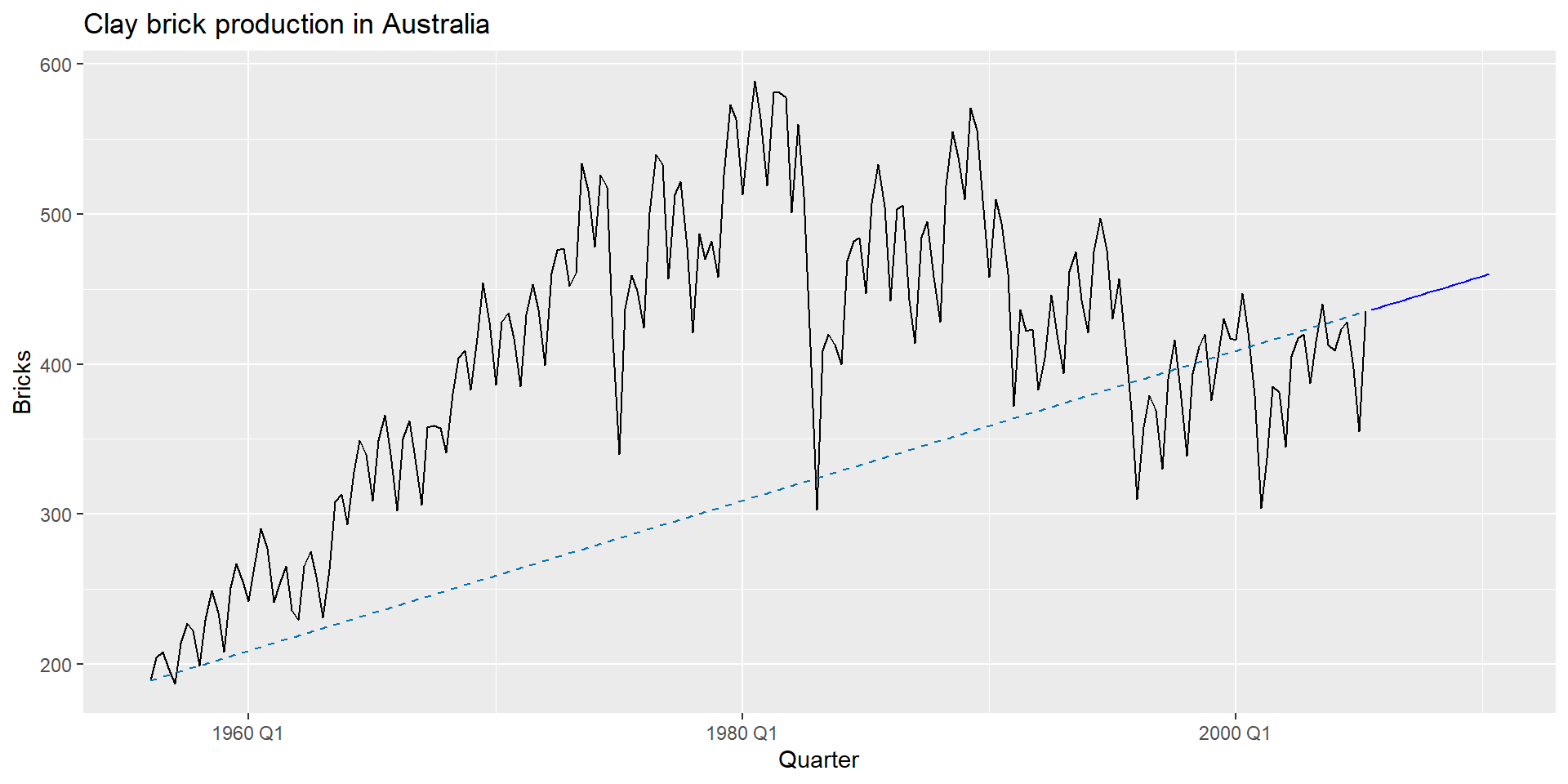
RW(y ~ drift()): Дріфтовий метод
Візуалізація прогнозів
Ціна акцій Facebook на закриття
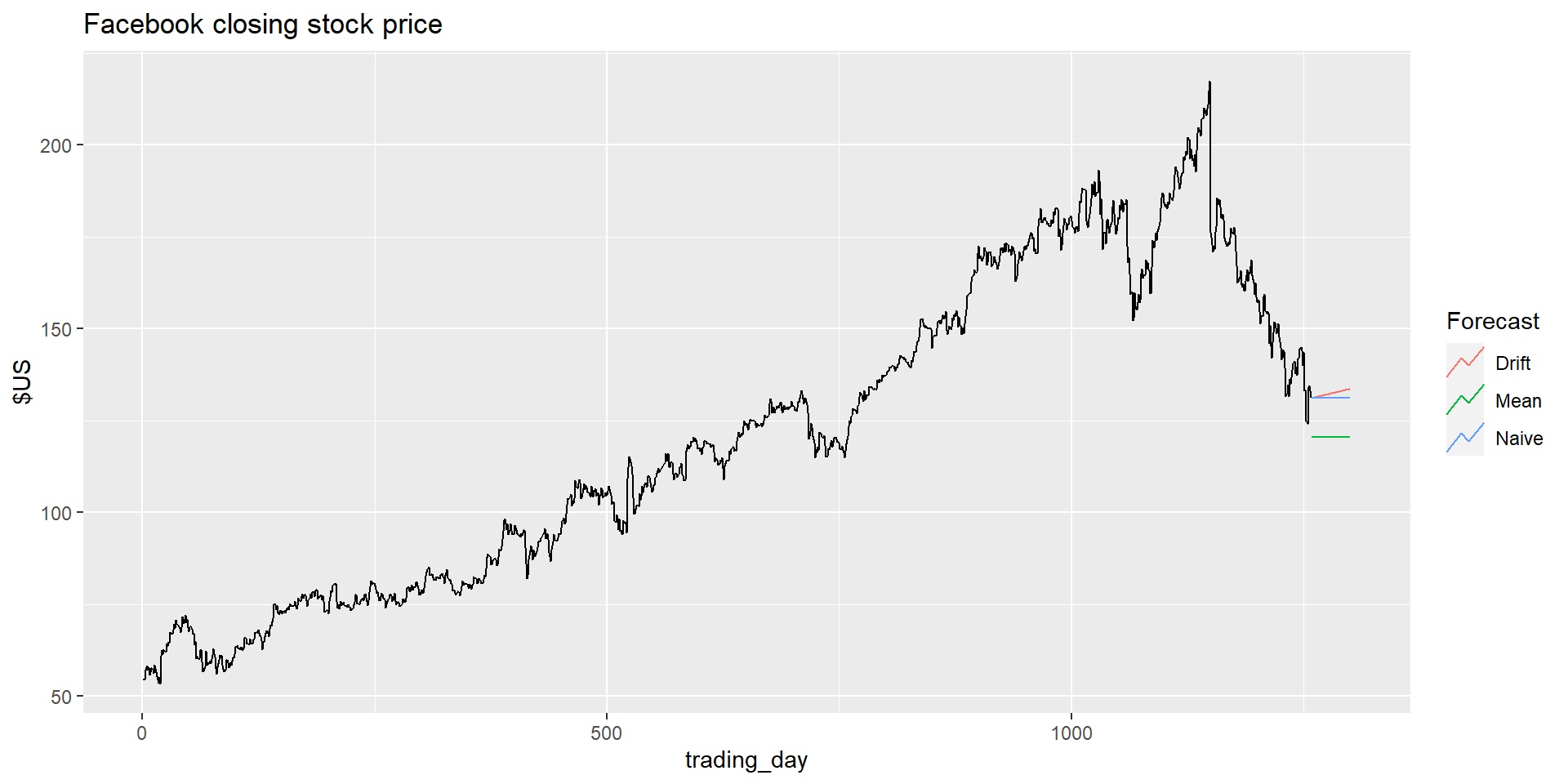
Ціна акцій Facebook на закриття
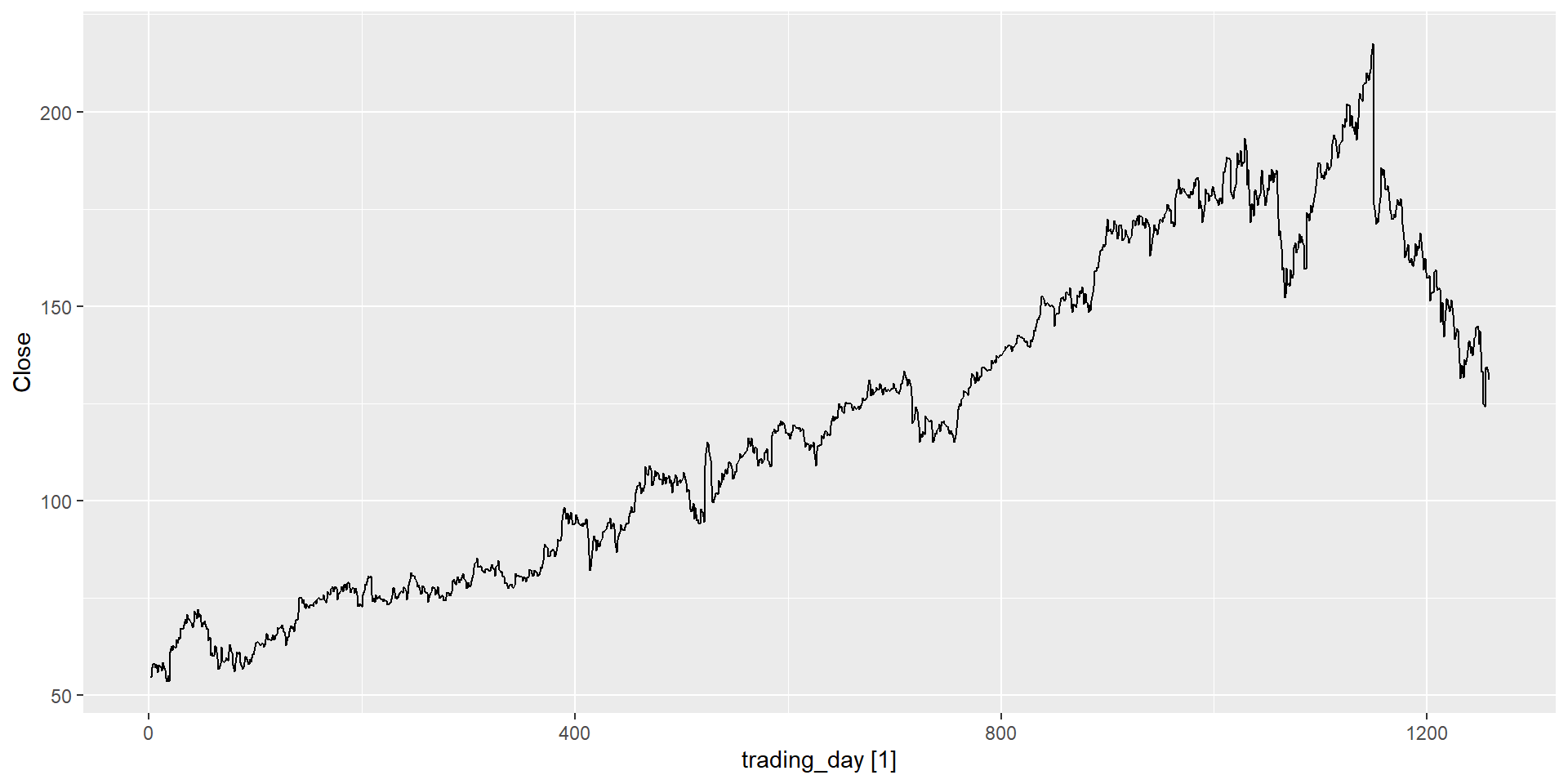
Ціна акцій Facebook на закриття

Ціна акцій Facebook на закриття

Ціна акцій Facebook на закриття

Ціна акцій Facebook на закриття
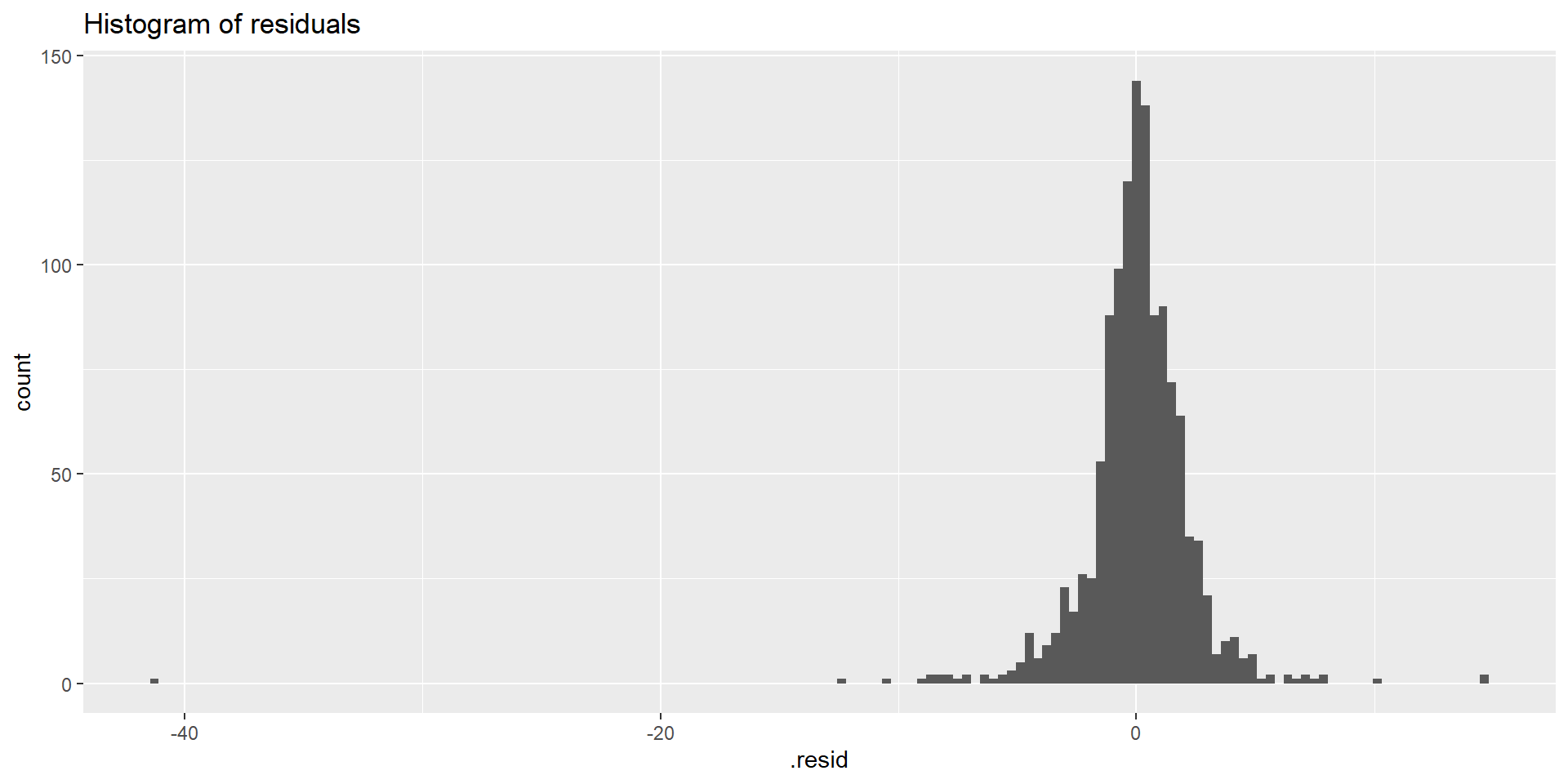
Ціна акцій Facebook на закриття

Функція gg_tsresiduals()

Моделювання з перетвореннями
Прогнозування з перетвореннями
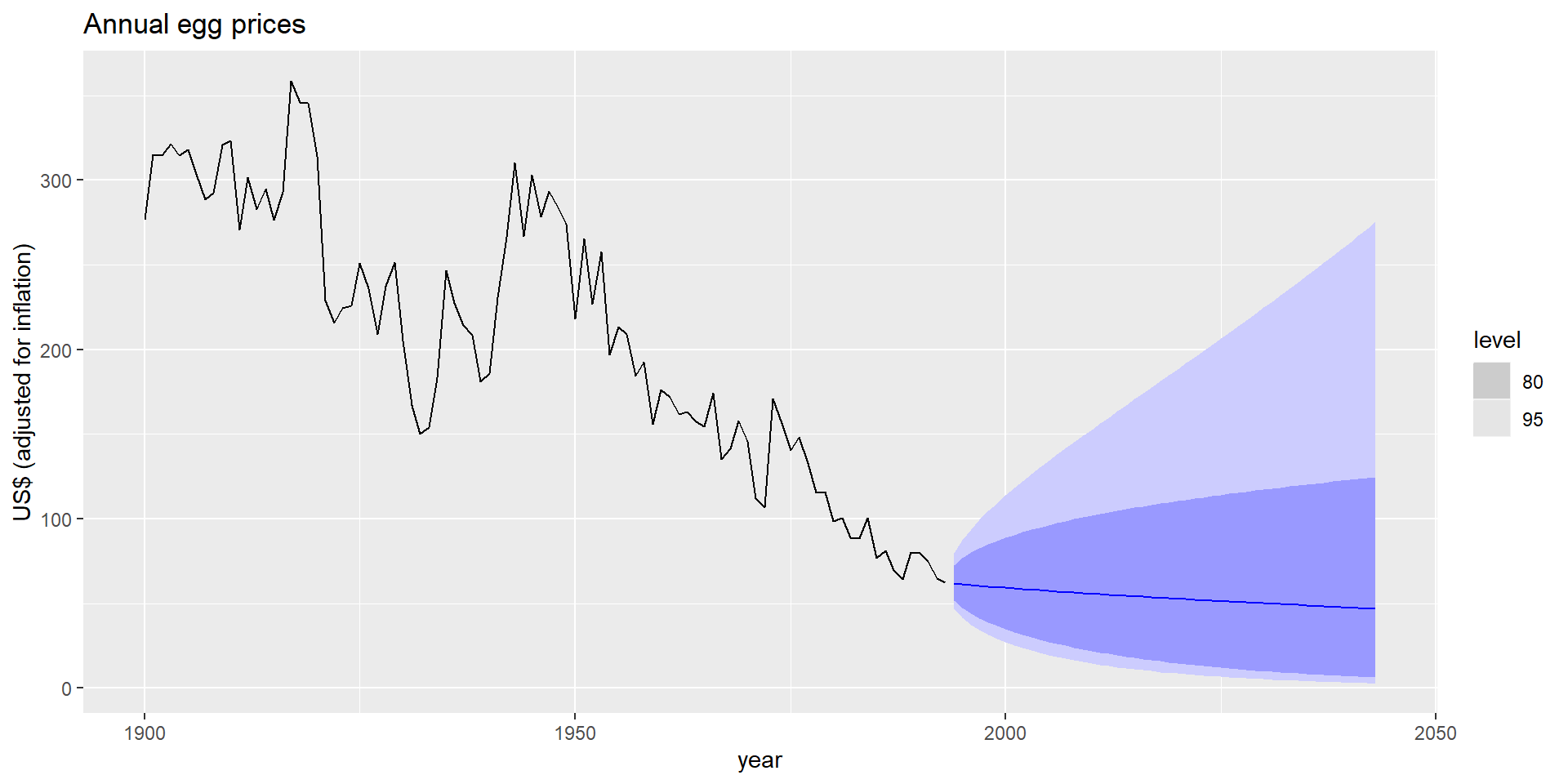
Корегування зміщення (bais)
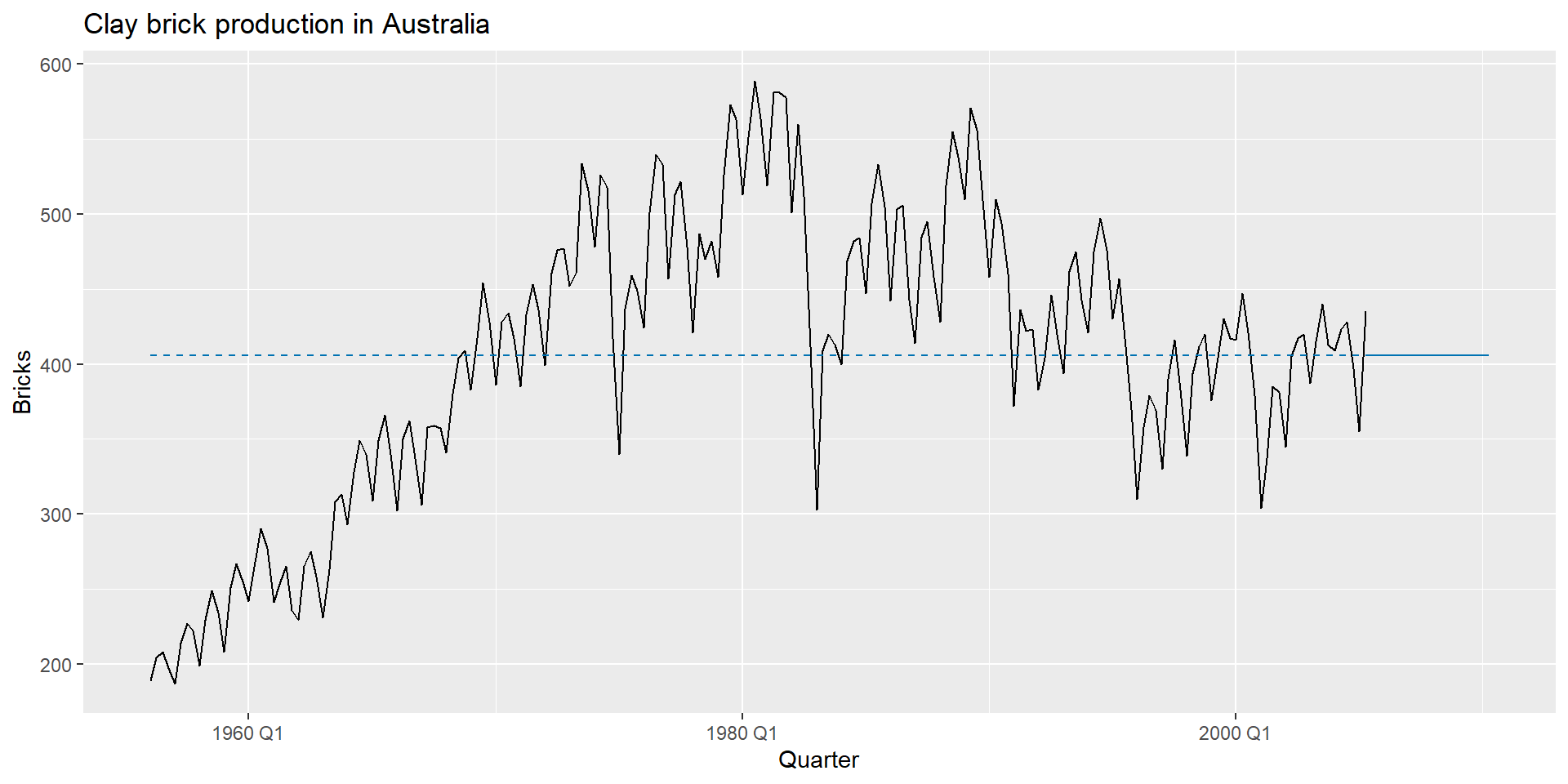
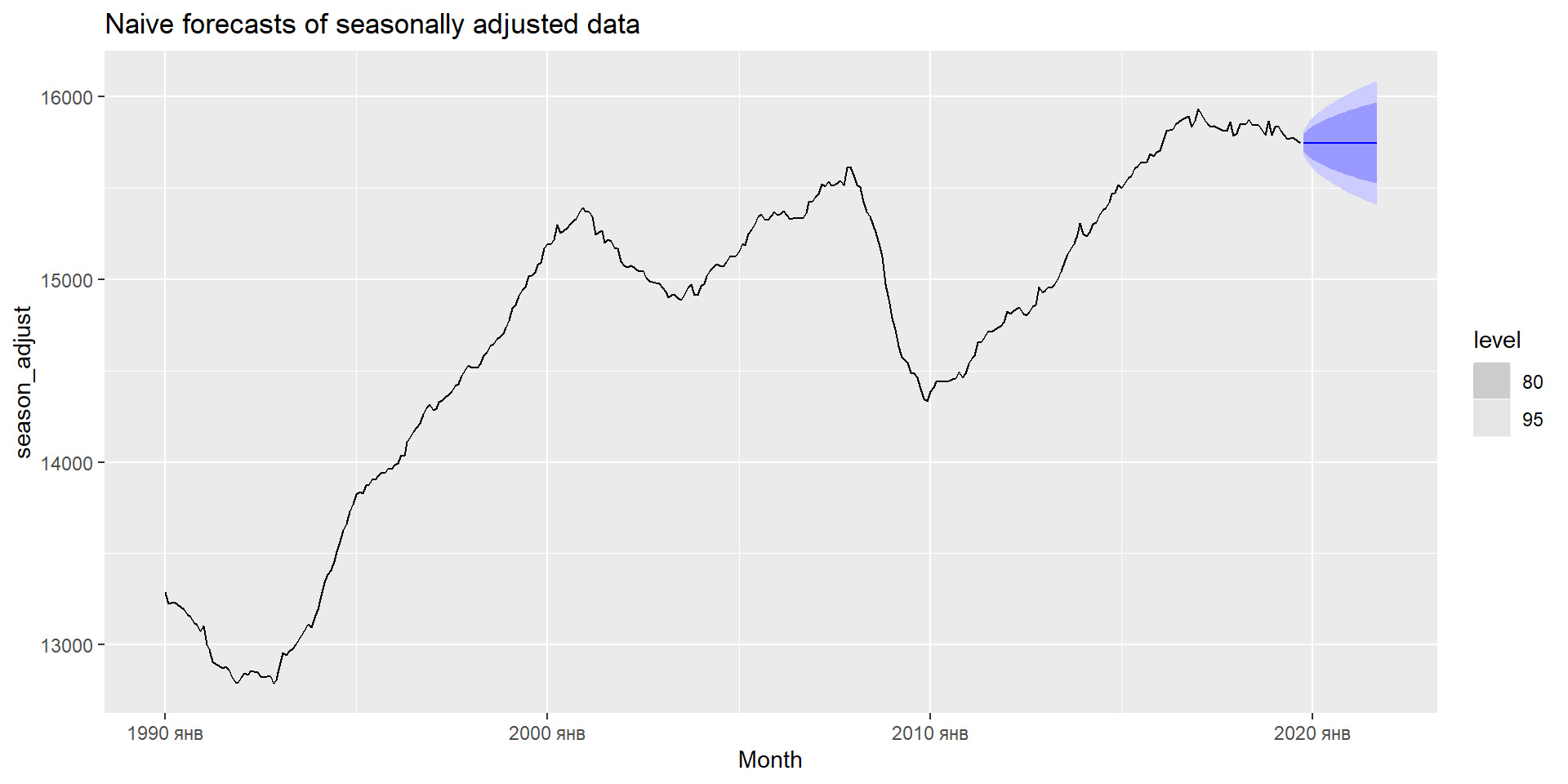
Зайнятість у розрібній торгівлі США
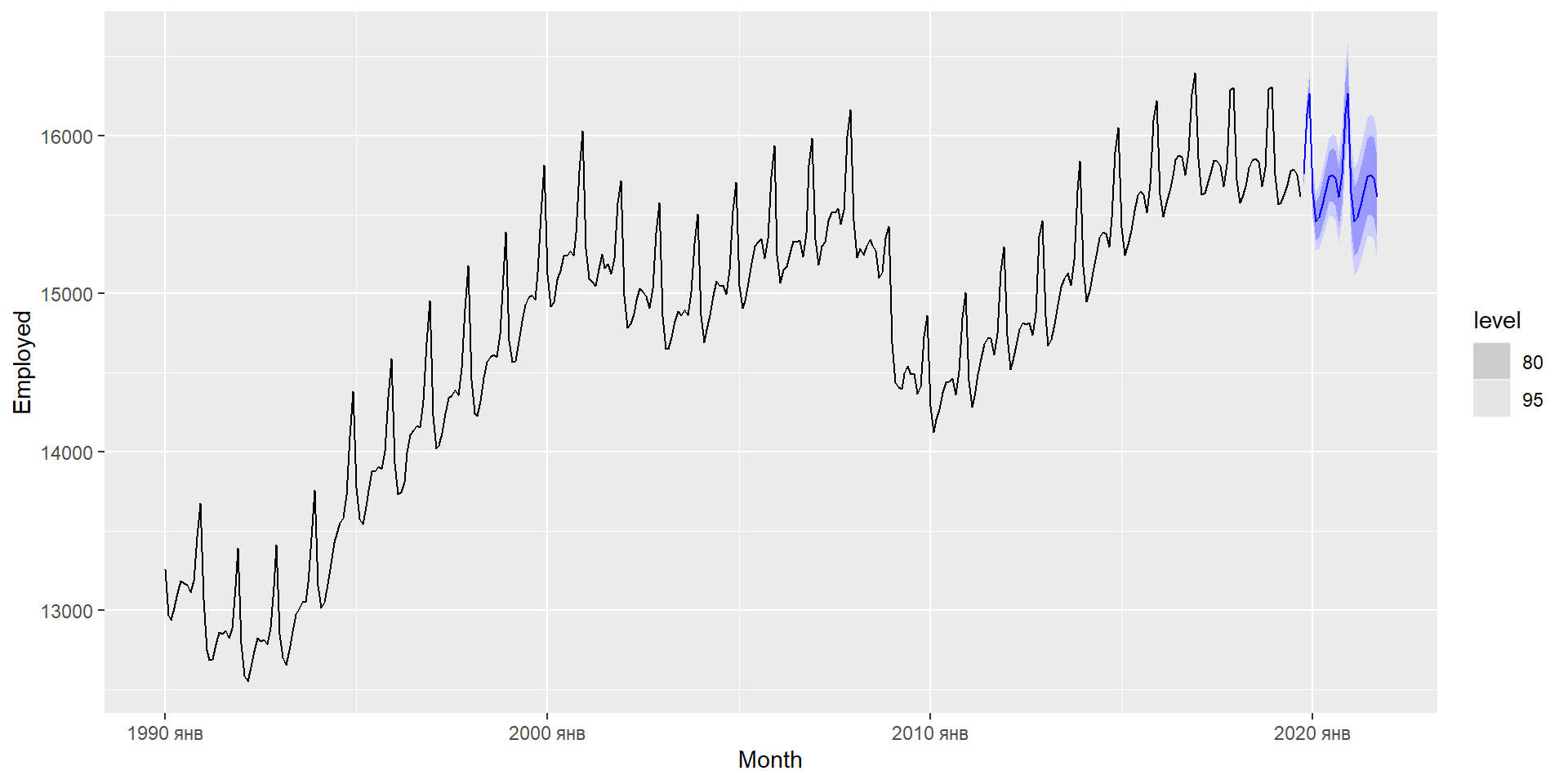
Зайнятість у розрібній торгівлі США

Модель, яка добре відповідає навчальній вибірці, не обов’язково буде добре прогнозувати.
Ідеальну модель можна отримати, використовуючи модель з достатньою кількістю параметрів.
Перенавчання (over-fitting) моделі так само погано, як і недонавчання (underfitting).
Тестовий набір не приймає участі при побудові моделі.
Точність прогнозу базується лише на тестовому наборі.
Вимірювання точності прогнозу
Вимірювання точності прогнозу
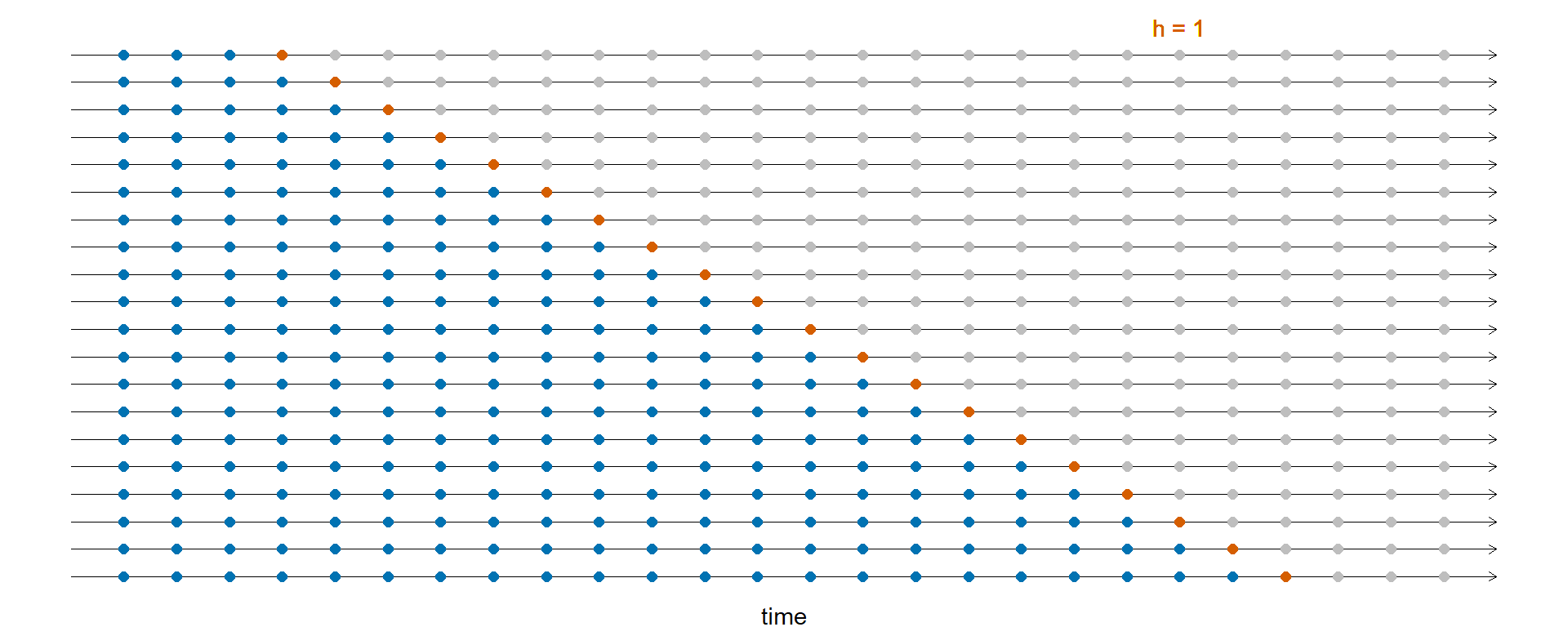
Крос-валідація у часових рядах

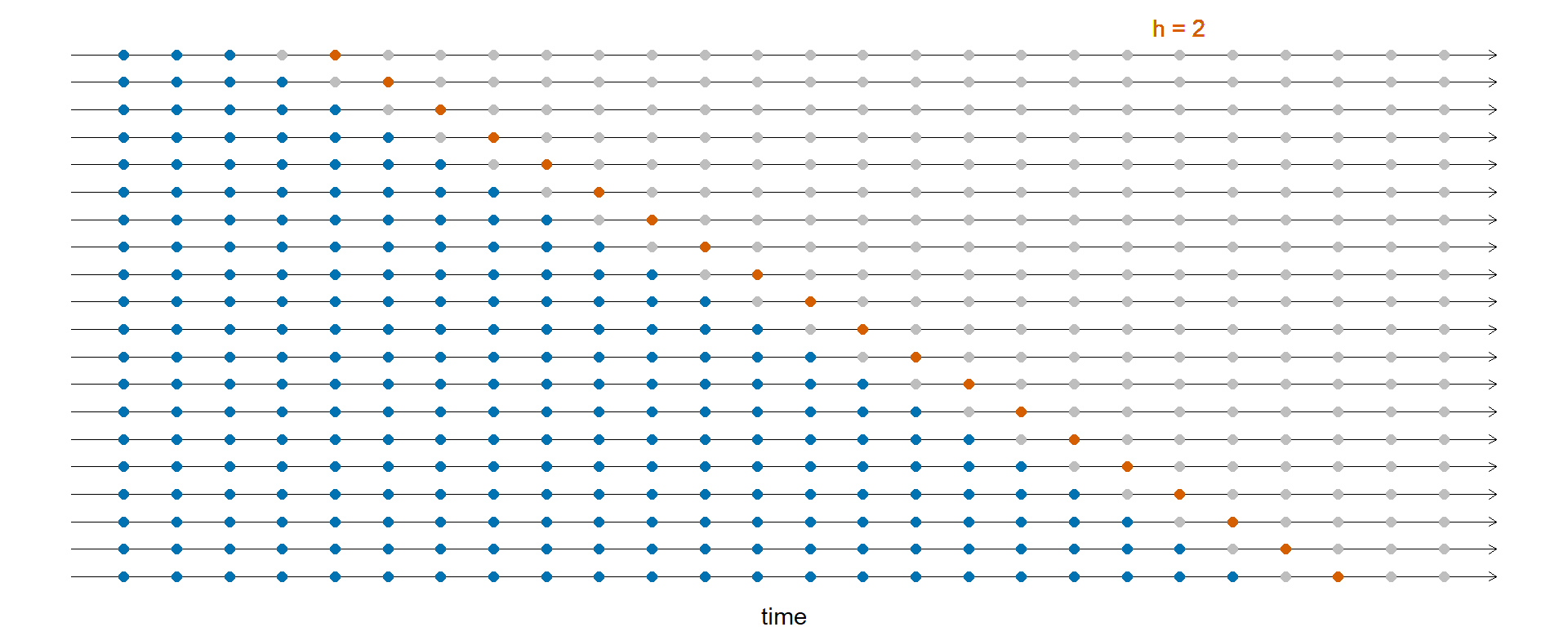
Крос-валідація у часових рядах

Крос-валідація у часових рядах

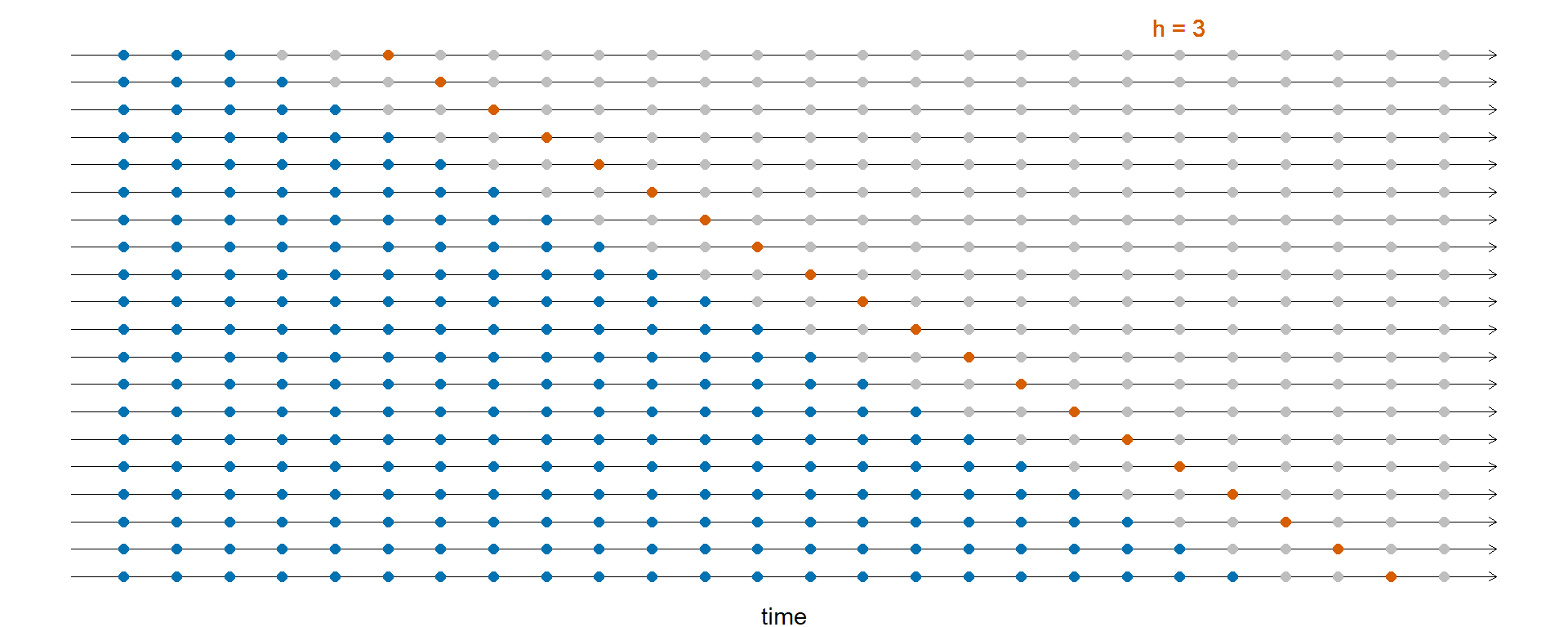
Крос-валідація у часових рядах

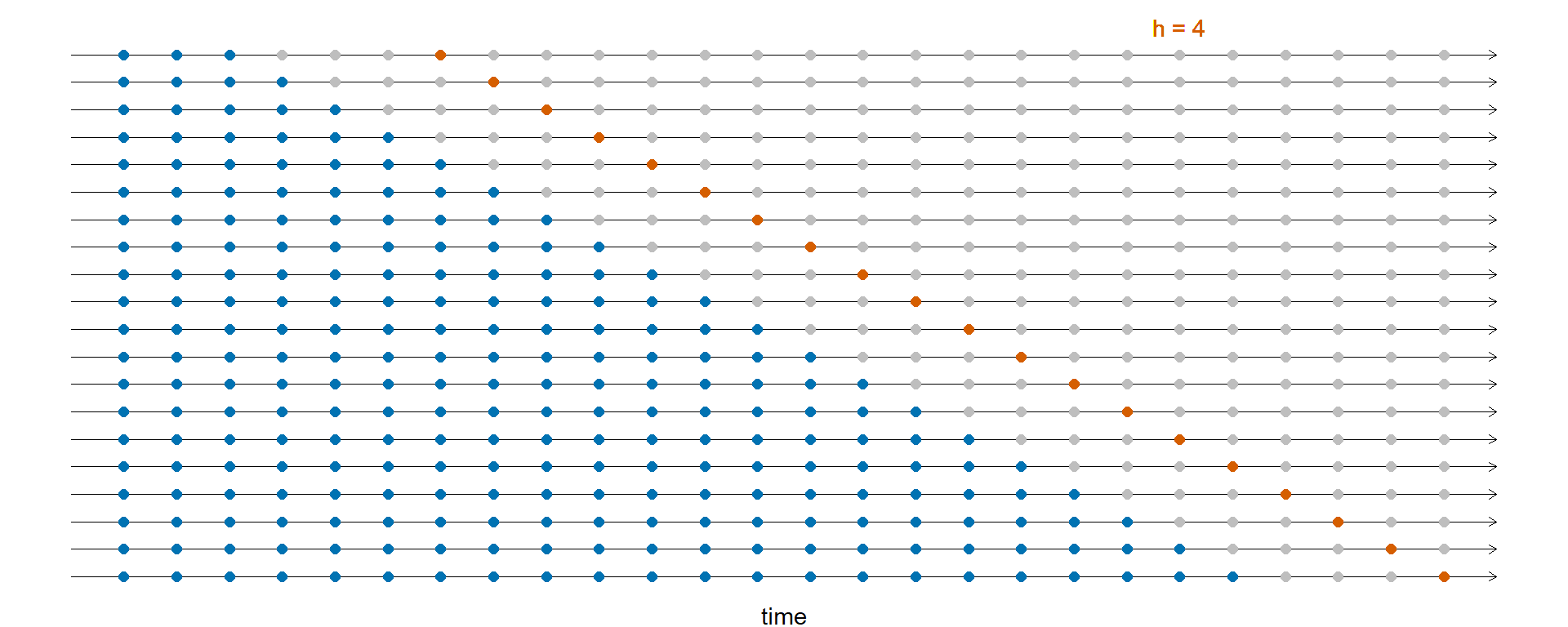
- Точність прогнозу усереднюється по тестовим вибіркам.
Дякую за увагу!
ihor.miroshnychenko@kneu.ua