Engine Transmission
Mazda RX4 V-shape manual
Mazda RX4 Wag V-shape manual
Datsun 710 Straight manual
Hornet 4 Drive Straight automatic
Hornet Sportabout V-shape automatic
Valiant Straight automatic
Duster 360 V-shape automatic
Merc 240D Straight automatic
Merc 230 Straight automatic
Merc 280 Straight automatic
Merc 280C Straight automatic
Merc 450SE V-shape automatic
Merc 450SL V-shape automatic
Merc 450SLC V-shape automatic
Cadillac Fleetwood V-shape automatic
Lincoln Continental V-shape automatic
Chrysler Imperial V-shape automatic
Fiat 128 Straight manual
Honda Civic Straight manual
Toyota Corolla Straight manual
Toyota Corona Straight automatic
Dodge Challenger V-shape automatic
AMC Javelin V-shape automatic
Camaro Z28 V-shape automatic
Pontiac Firebird V-shape automatic
Fiat X1-9 Straight manual
Porsche 914-2 V-shape manual
Lotus Europa Straight manual
Ford Pantera L V-shape manual
Ferrari Dino V-shape manual
Maserati Bora V-shape manual
Volvo 142E Straight manual04 - Аналіз номінативних даних
Кількісні методи в економіці
11/9/22
1. Перевірка гіпотези про те, що розподіл номінативної змінної відрізняється від певного заданого теоретичного розподілу
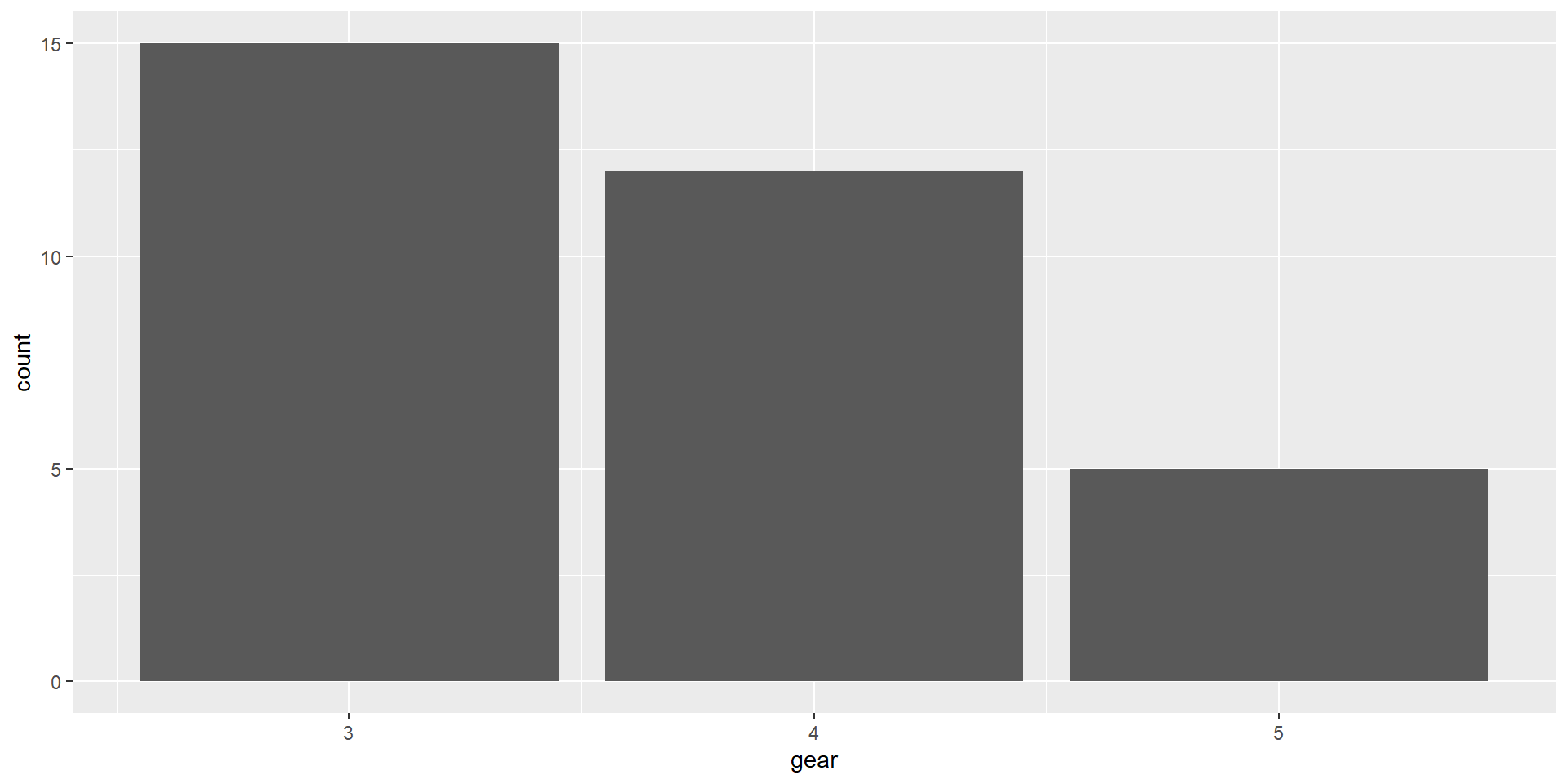
1. Перевірка гіпотези про те, що розподіл номінативної змінної відрізняється від певного заданого теоретичного розподілу
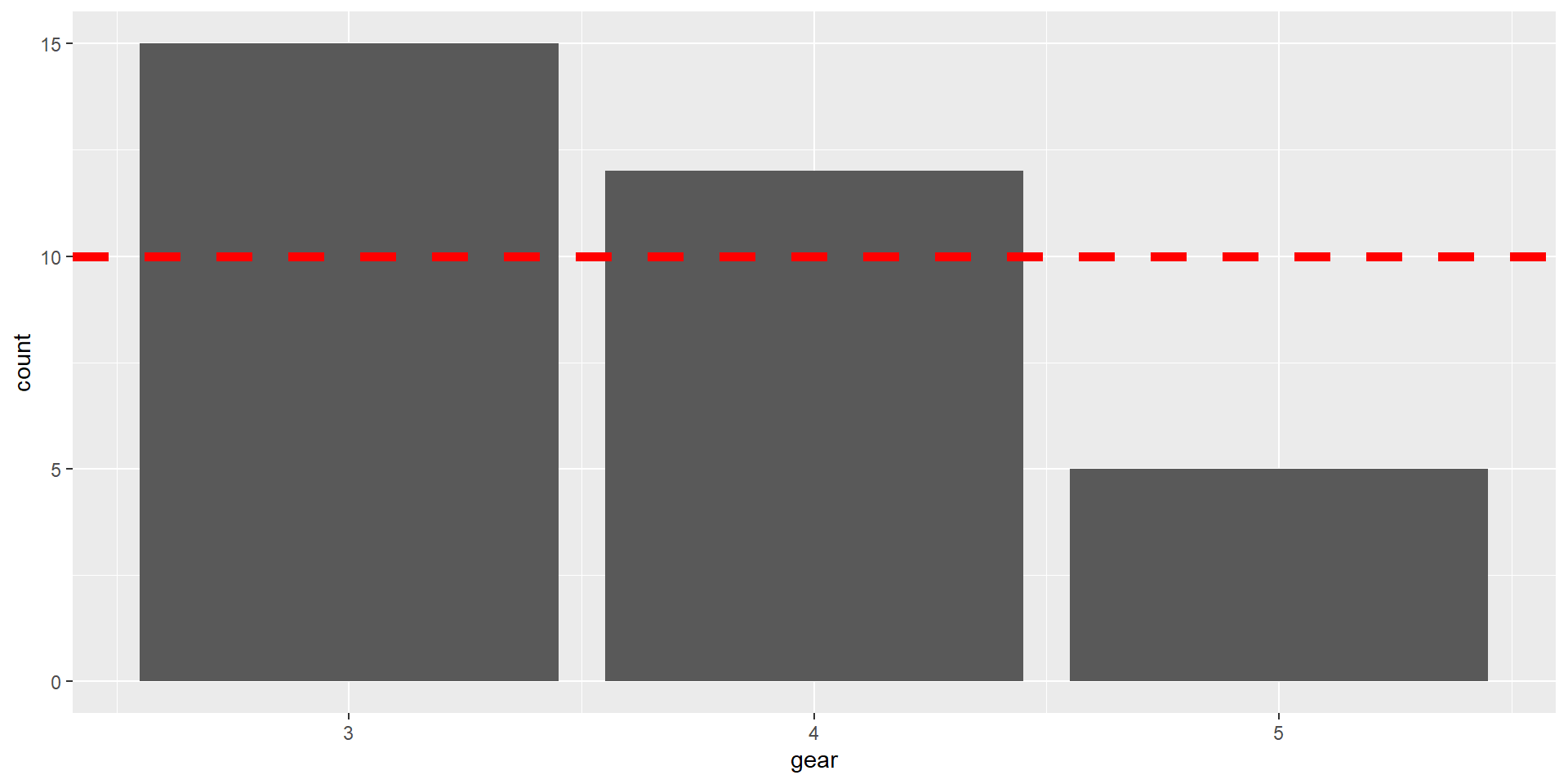
1. Перевірка гіпотези про те, що розподіл номінативної змінної відрізняється від певного заданого теоретичного розподілу
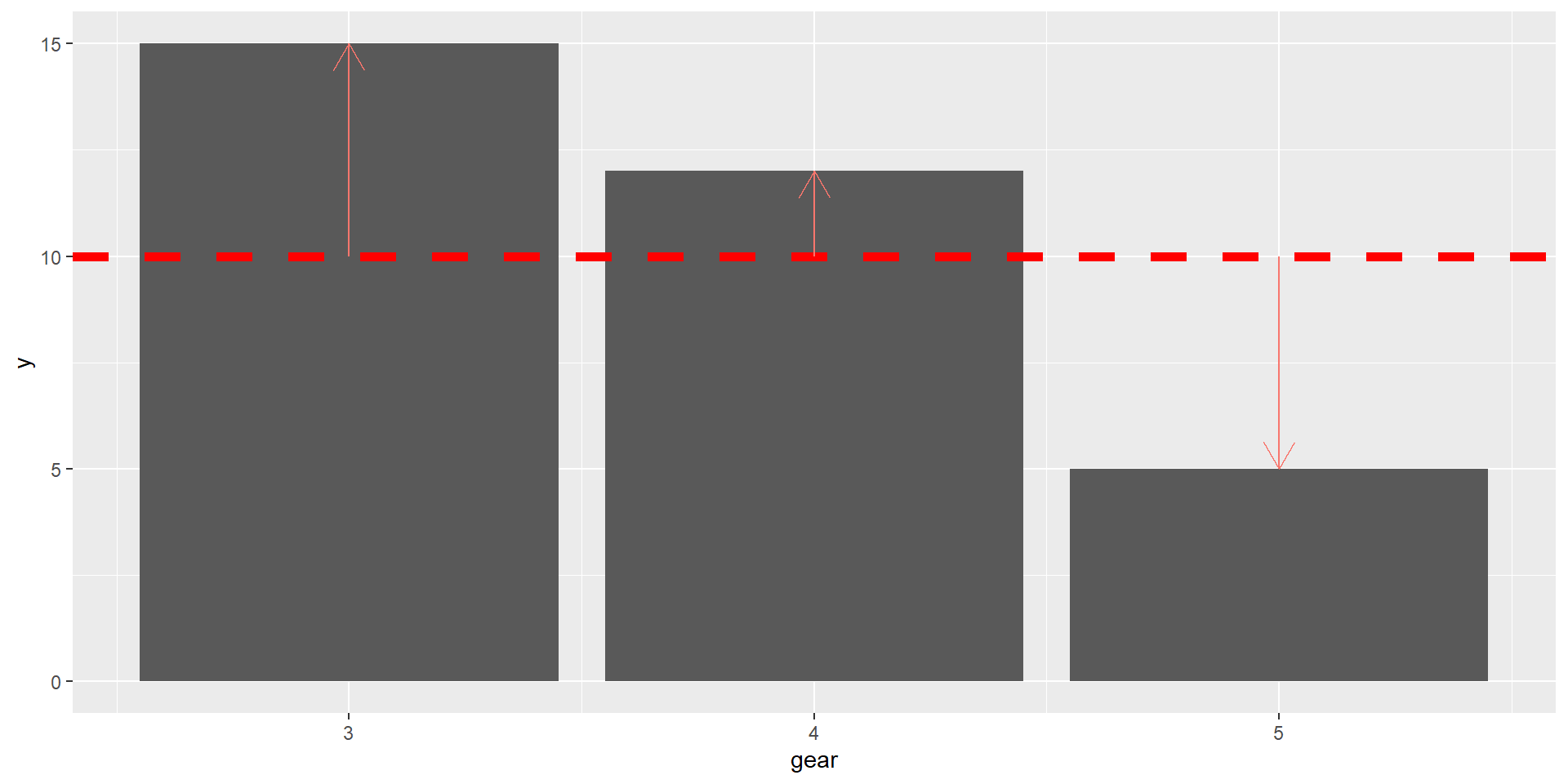
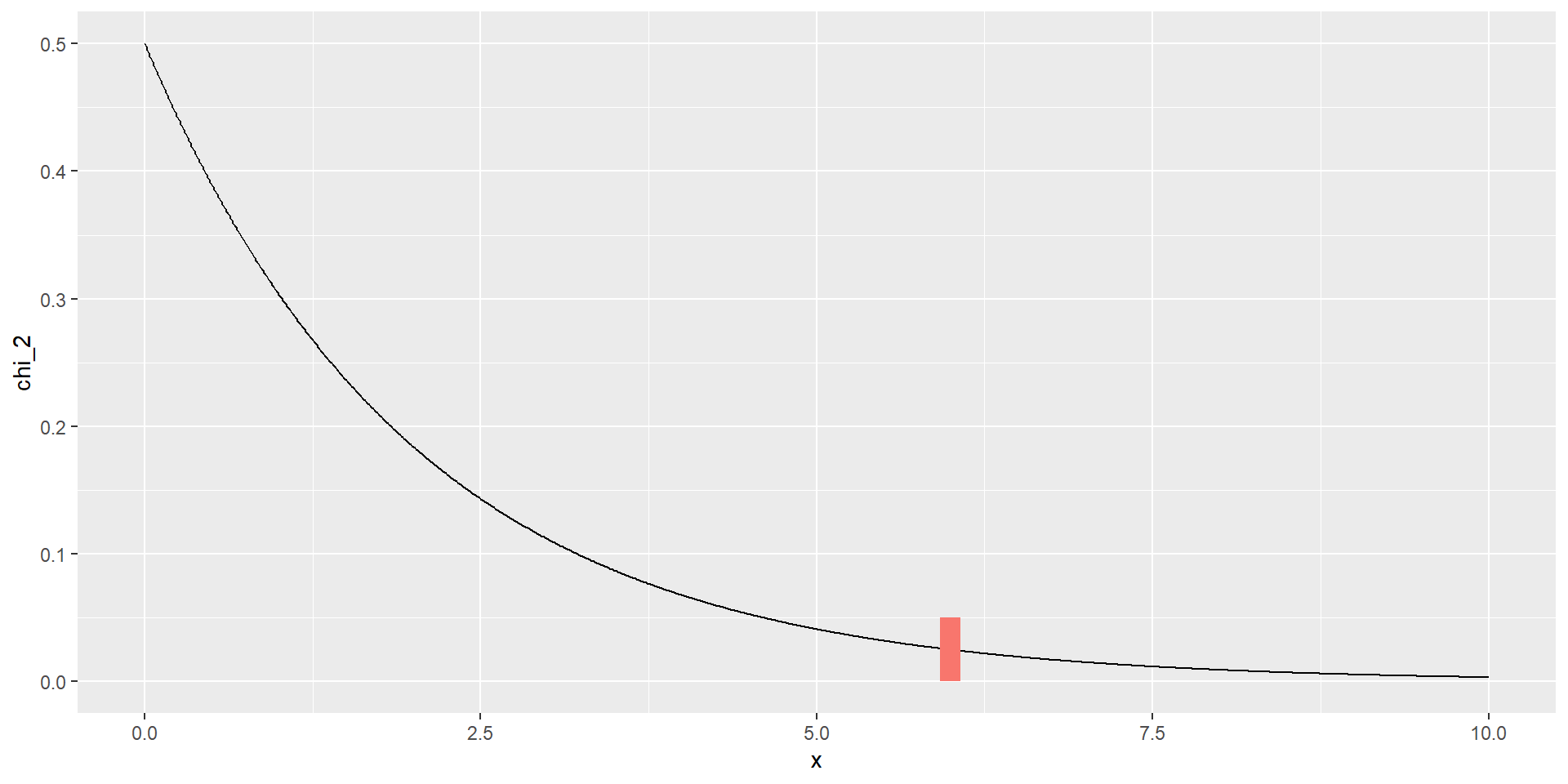
Розподіл \(\chi^2\) Пірсона
Розподіл \(\chi^2\) Пірсона
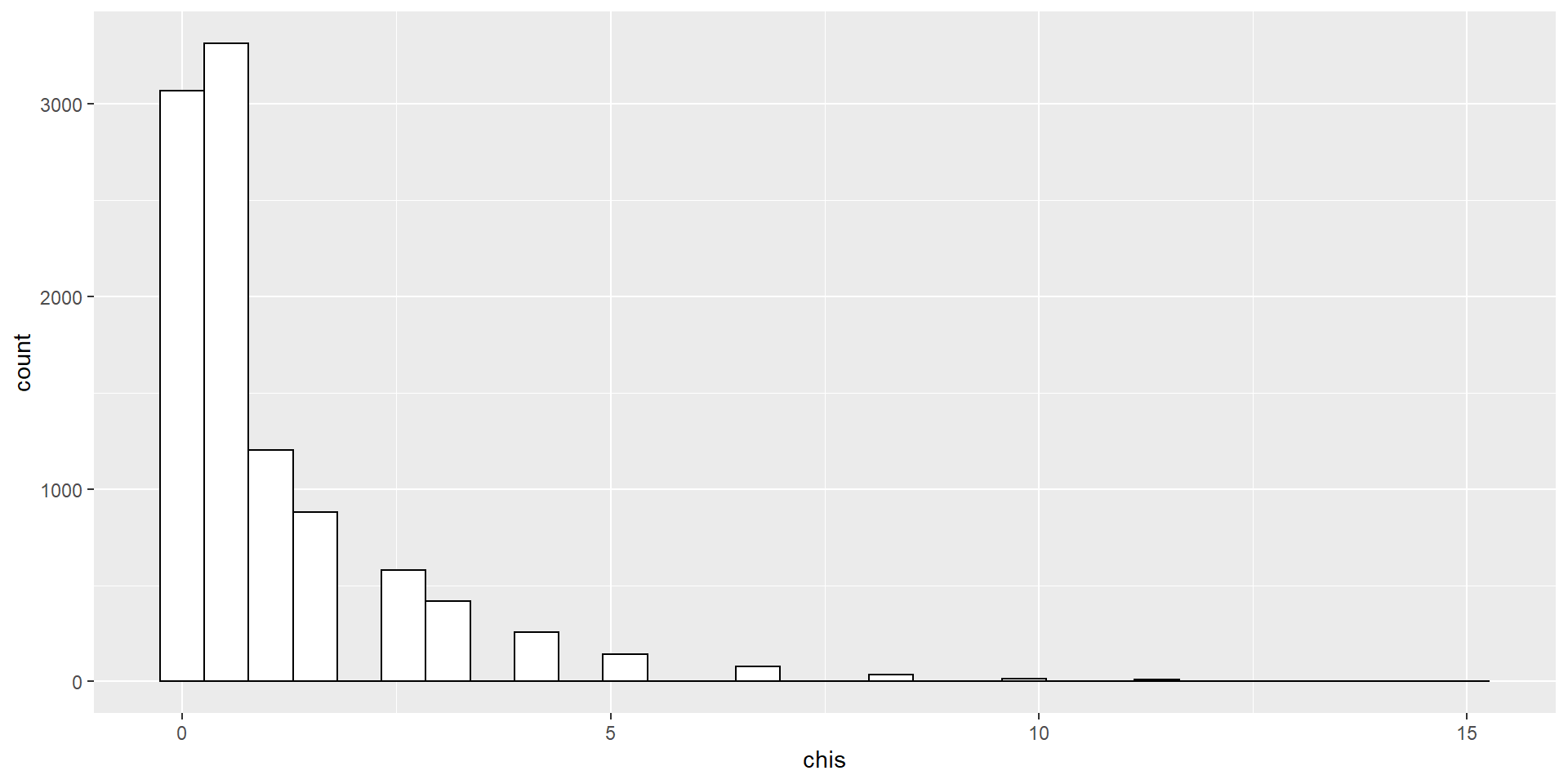
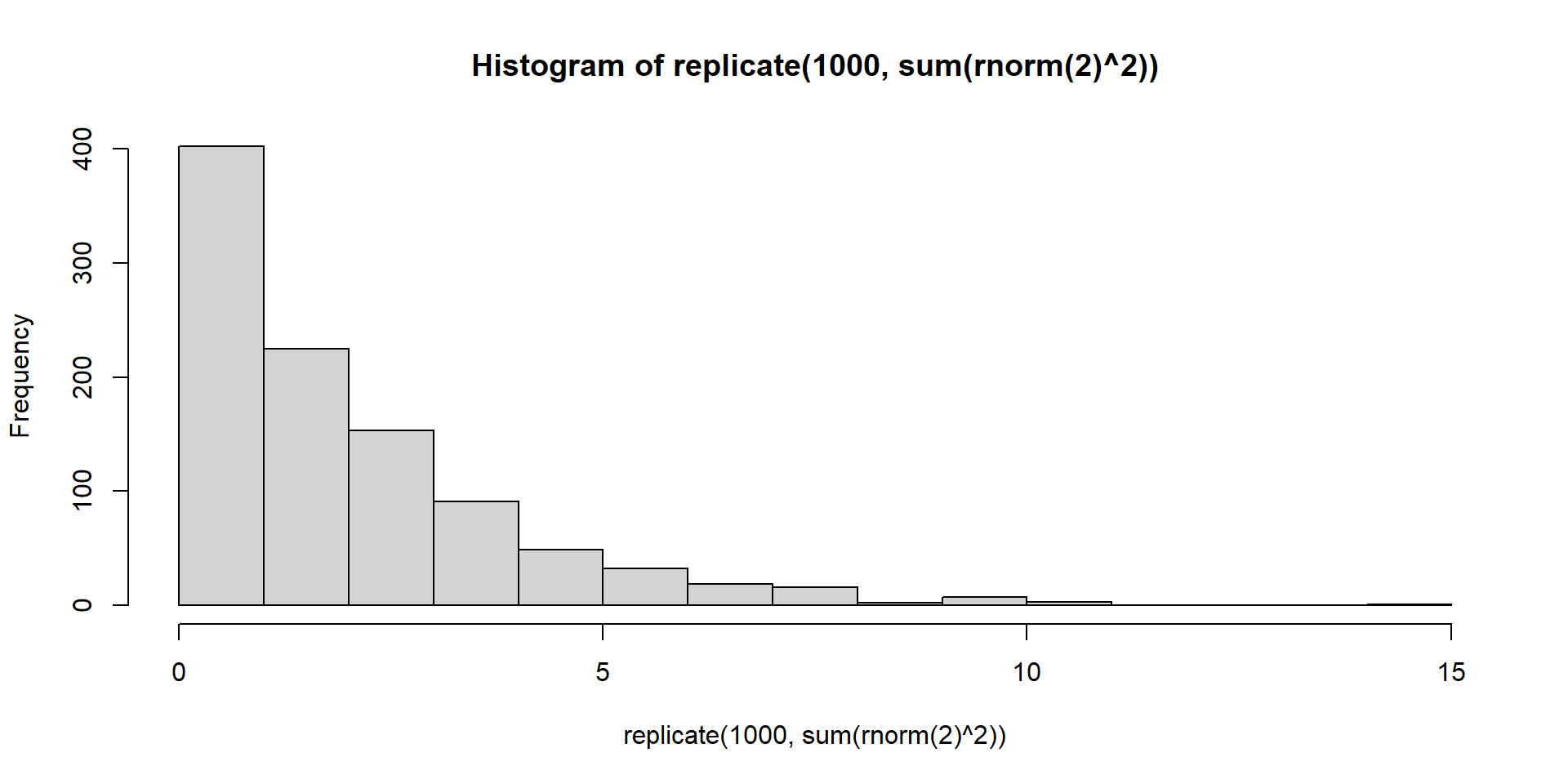
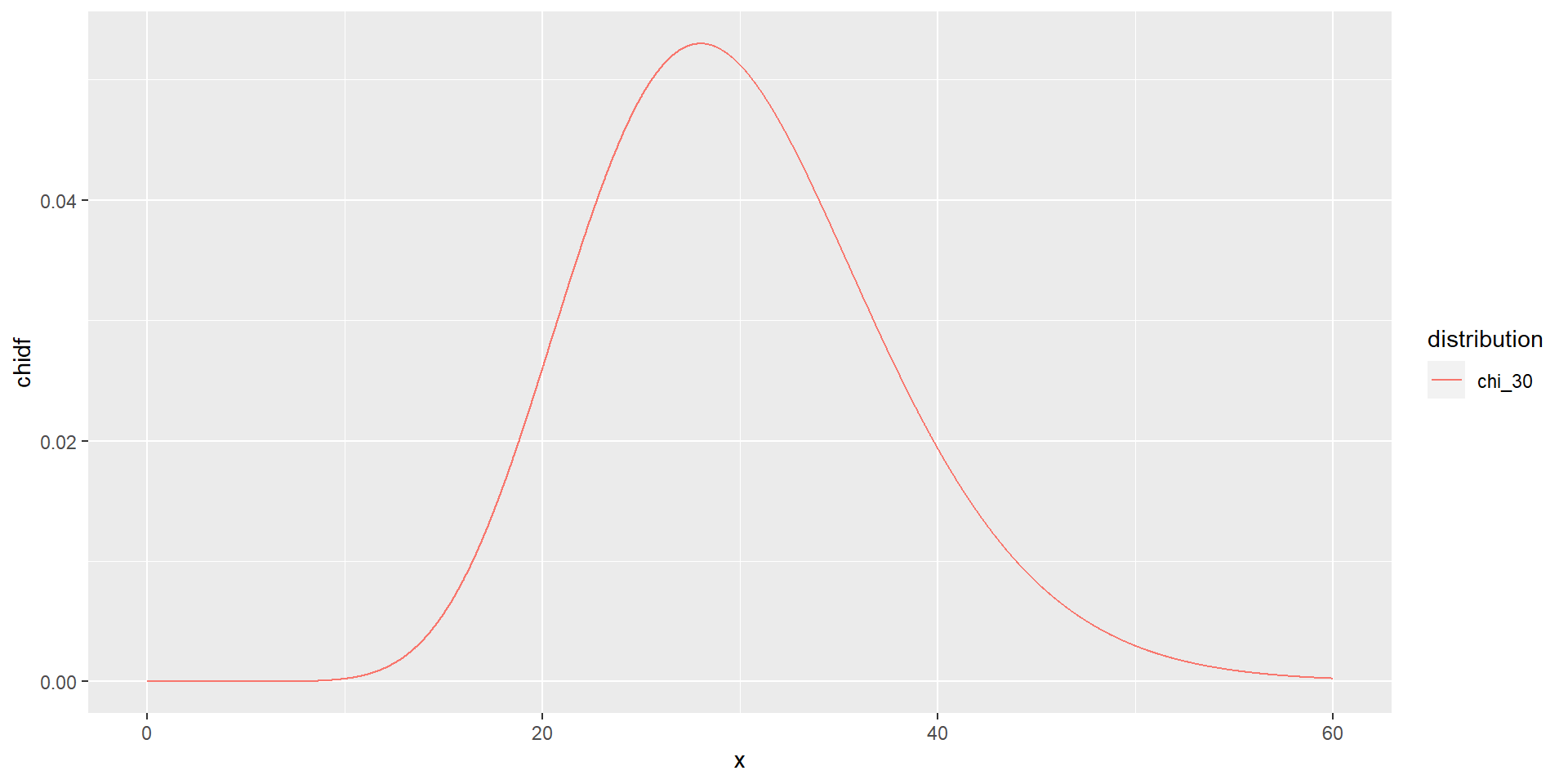
Розподіл \(\chi^2\) з \(k\) степенями свободи - це розподіл суми квадратів \(k\) незалежних стандартних нормальних випадкових величин.
Розподіл \(\chi^2\) Пірсона
Розподіл \(\chi^2\) Пірсона
Розподіл \(\chi^2\) з двома степенями свободи \((df = 2)\):
Розподіл \(\chi^2\) Пірсона
tibble(x = seq(0, 8, .01),
chi_1 = dchisq(x, df = 1),
chi_2 = dchisq(x, df = 2),
chi_3 = dchisq(x, df = 3),
chi_4 = dchisq(x, df = 4),
chi_5 = dchisq(x, df = 5)) %>%
pivot_longer(cols = -x, values_to = 'chidf', names_to = 'distribution') %>%
ggplot(aes(x = x, y = chidf, colour = distribution))+
geom_line() +
scale_y_continuous(limits = c(0, 1))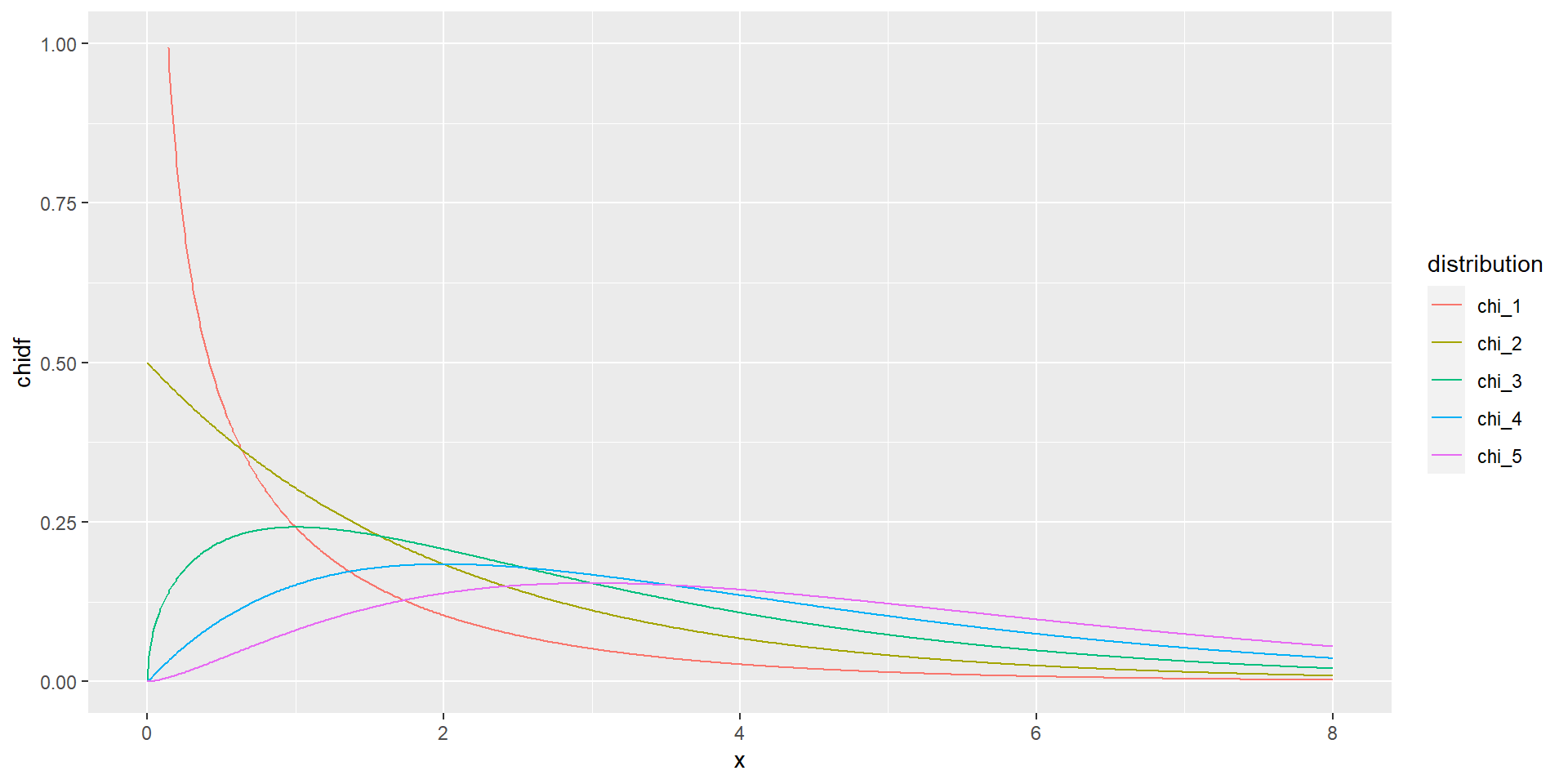
Дякую за увагу!
ihor.miroshnychenko@kneu.ua