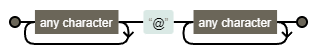Регулярні вирази (англ. regular expressions, regexes) - це патерни, які використовуються для знаходження певних комбінацій символів у тексті.
Наприклад, якщо користувач вводить адресу електронної пошти у вашій програмі, на веб-сайті або в додатку на телефоні, в ідеалі ви хочете мати можливість перевірити, що він дійсно ввів адресу електронної пошти, а не щось інше.
Використовуючи регулярні вирази, ми можемо перевірити, чи = введений текст певному формату. Це дуже корисно, оскільки ви можете використовувати регулярні вирази для перевірки введення користувача, або для пошуку певних комбінацій символів у тексті.
Вони дуже потужні, але в той же час достатньо складні. Якщо ви вперше з ними зіткнулися, то вони здаються дуже незрозумілими. Але якщо ви вже з ними працювали, то ви не зможете без них.
Звичайний пошук
Для початку розглянемо декілька задач і спробуємо їх вирішити використовуючи більш простий синтаксис, і подивитися, з якими обмеженнями ми зіткнемося.
Створимо файл validate.py метою якого є перевірка адреси електронної пошти користувача.
Terminal
code validate.py
Напишемо просту програму, яка буде приймати від користувача адресу електронної пошти і перевіряти, чи вона = певному формату.
Використаємо метод strip() для видалення зайвих пробілів з початку і кінця рядка. Але як перевірити, що введене значення дійсно є валідним для електронної пошти?
Перша ідея, яка з’являється - це перевірити, чи введений текст містить символ @. Якщо так, то ми можемо припустити, що це адреса електронної пошти:
Ми можемо продовжувати роботу над цією програмою. В кінцевому підсумку нам доведеться писати багато коду, просто щоб валідувати адресу електронної пошти.
Бібліотека re
В Python є бібліотека для регулярних виразів, яка лаконічно називається re. В ній є багато можливостей для визначення, перевірки і заміни шаблонів.
Цей варіант програми працює так само, як і наш перший варіант, але вже з використанням пакету re.
Регулярні вирази
Нам треба уточнити потер пошуку: ліворуч від символа @ може бути певний запис, праворуч від символа @ має бути також якийсь запис, який закінчується на .edu. Для цього існує ряд спеціальних символів, які дозволяють визначити певні шаблони:
Регулярний вираз
Опис
Приклади
.
Будь-який символ
a.b = “acb”, “a1b”, “a#b”
*
0 або більше повторень попереднього символу
ab*c = “ac”, “abc”, “abbc”
+
1 або більше повторень попереднього символу
ab+c = “abc”, “abbc”, але не “ac”
?
0 або 1 повторення попереднього символу
colou?r = “color” і “colour”
{n}
Рівно n повторень попереднього символу
a{3}b = “aaab”
{n, m}
Від n до m повторень попереднього символу
a{2,4}b = “aab”, “aaab” і “aaaab”
{n,}
Від n повторень попереднього символу
a{2,}b = “aab”, “aaab”, “aaaab” і так далі
^
Початок рядка
^start =, якщо рядок починається з “start”
$
Кінець рядка
end$ =, якщо рядок закінчується на “end”
[]
Набір символів
[aeiou] = будь-якому голосному символу
[^]
Набір символів, які не повинні зустрічатися
[^0-9] = будь-якому символу, крім цифр
A|B
Або
cat|dog = “cat” або “dog”
(...)
Група символів
(ab)+ = “ab”, “abab”, “ababab” і так далі
?:...
Не захоплювати групу
(?:ab)+ = “ab”, “abab”, “ababab” і так далі
Регулярні вирази
Давайте спробуємо переписати нашу програму використовуючи функцію re.search() і регулярний вираз:
Комп’ютер використовує свого роду машину, реалізовану в програмному забезпеченні, відомому як скінченний автомат (англ. finite state machine) або недетермінований скінченний автомат.
Візуально це можна зобразити так:
Вираз: .*@.*
Регулярні вирази
Ми можемо переписати нашу програму з використанням регулярного виразу .+, який означає “один або більше будь-яких символів”:
Зверніть увагу, що ми використовуємо символ \ для екранування крапки, оскільки в іншому випадку крапка буде сприйматися як будь-який символ.
Крім того, слід враховувати, що комбінація символів \n вважається спеціальним символом, який позначає перехід на новий рядок. Тому ми вказуємо Python читати рядок як “сирий” (англ. raw), використовуючи префікс r перед рядком.
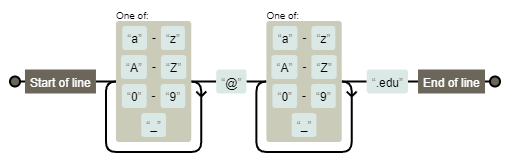
Візуалізація:
Вираз: .+@.+\.edu
Початок та кінець рядка
Наша програма все ще має ряд недоліків. Наприклад, вона не враховує пробіли, які можуть зустрічатися у введеному тексті:
Terminal
python validate.pyВведіть email: Моя пошта potter@hogwarts.eduВалідна адреса електронної пошти
Для таких випадків у світі регулярних виразів існують спеціальні символи початку ^ та кінця рядка $:
Для цього ми можемо використати символи [] для визначення набору символів, які можуть зустрічатися у тексті та [^] для символів, які не повинні зустрічатися у тексті. Оскільки ми не хочемо щоб символ @ зустрічався більше одного разу, то ми можемо використати наступний регулярний вираз [^@]:
У світі стандартів існує багато різних специфікацій для адрес електронної пошти. Наприклад, вони повинні починатися з літери. Нам не потрібно перераховувати всі можливі літери алфавіту у нижньому та верхньому регістрі. Замість цього ми можемо використати спеціальний символ [a-zA-Z], який означає будь-яку літеру англійського алфавіту незалежно від регістру. Якщо ж я хочу також врахувати цифри та символ _, то я можу використати спеціальний символ [a-zA-Z0-9_]. Давайте спробуємо використати цей регулярний вираз:
Будь-яка літера англійського алфавіту незалежно від регістру, цифра або символ _
\d
Будь-яка цифра
\s
Будь-який пробіл
\W
Будь-який символ, крім літер англійського алфавіту незалежно від регістру, цифр та символу _
\D
Будь-який символ, крім цифри
\S
Будь-який символ, крім пробілу
Флаги
Давайте припустимо, що при введені адреси електронної пошти користувач випадково натиснув клавішу Caps Lock і ввів адресу з використанням великих літер.
Якщо ми використаємо наш регулярний вираз, то програма не буде вважати таку адресу валідною:
Наприклад, ми можемо використати функцію lower() для перетворення всіх символів у нижній регістр. Це можна зробити на початку програми або використовуючи метод lower() для об’єкта email:
Припустимо, що адреса користувача містить піддомен gryff.hogwarts.edu. В такому випадку нам слід врахувати варіативність піддоменів. Для цього ми можемо використати спеціальний символ ?, який означає 0 або 1 повторення попереднього символу. Давайте спробуємо використати цей символ:
Запис (\w+\.)? означає, що група записів \w+\. може зустрічатися 0 або 1 раз. Таким чином, ми можемо врахувати варіативність піддоменів.
Приклади з реального світу
Все що ми зробили до цього часу для відстеження адрес електронної пошти, все ще має ряд недоліків. Я наведу приклад регулярного виразу, який використовується в реальному світі для відстеження адрес електронної пошти:
В інтернеті є ряд стандартів, які визначають, якими мають бути адреси електронної пошти. Один з них - це RFC 5322. Згідно цього стандарту 99.99% адрес електронної пошти можна відстежити за допомогою наступного регулярного виразу:
Замість того, щоб просто перевіряти вхідні дані користувача і переконуватися, що вони виглядають так, як ми хочемо, давайте просто припустимо, що користувачі не збираються вводити дані саме так, як ми хочемо. Тому нам доведеться очистити їхні дані.
Створимо програму format.py, яка очищуватиме введене ім’я користувача:
Terminal
code format.py
Деякі користувачі можуть мати звичку вводити спочатку своє ім’я, а потім прізвище через кому: Гаррі, Поттер замість Поттер, Гаррі. Це нормально, тому що обидва варіанти однаково добре читаються людиною. Але для комп’ютера це різні рядки. Тому нам потрібно буде очистити введені дані користувача. Створимо змінну name, яка буде містити введені дані користувача:
name =input("Введіть ім'я: ").strip()print(f'Привіт, {name}!')
Подивимось, як працює програма з різними введеними даними:
Terminal
python format.pyВведіть ім'я: Гаррі ПоттерПривіт, Гаррі Поттер!
Перший варіант нас може задовільнити, а от другий виглядає зовсім не так, як ми очікуємо. Давайте спробуємо виправити цю ситуацію через умовний оператор if:
name =input("Введіть ім'я: ").strip()if','in name: last, first = name.split(', ') name =f'{first}{last}'print(f'Привіт, {name}!')
Terminal
python format.pyВведіть ім'я: Поттер, ГарріПривіт, Гаррі Поттер!
Ми виправили ситуацію, але що якщо користувач введе ім’я без використання пробілів? Наприклад, Поттер,Гаррі?
Це призведе до помилки, оскільки ми використовуємо метод split() для розділення рядка на дві частини.
Для цього нам знадобиться функція re.search(), яка повертає об’єкт Match. Якщо відповідність знайдена, то ми можемо використати метод groups() для отримання відповідного значення, які були записані у дужки.
Очищення тексту
Давайте спробуємо використати регулярний вираз ^(.+), (.+)$, який означає “початок рядка, один або більше будь-яких символів, кома, пробіл, один або більше будь-яких символів, кінець рядка”:
import rename =input("Введіть ім'я: ").strip()matches = re.search(r'^(.+), (.+)$', name)if matches: last, first = matches.groups() name =f'{first}{last}'print(f'Привіт, {name}!')
Якщо ми введемо ім’я користувача без коми, то з умовним оператором if нічого не буде відбуватися, оскільки matches буде None і програма одразу перейде до виведення привітання:
Terminal
python format.pyВведіть ім'я: Гаррі ПоттерПривіт, Гаррі Поттер!
У випадку, коли користувач введе ім’я з комою, то відбудеться відповідність регулярному виразу і ми зможемо використати метод groups() для отримання відповідних значень:
Terminal
python format.pyВведіть ім'я: Поттер, ГарріПривіт, Гаррі Поттер!
Очищення тексту
Якщо ж потрібно повернути конкретні групи замість всіх, то можна використати метод group(), який приймає номер групи:
Ця програма має значний недолік - ми очікуємо, що ім’я та прізвище користувача будуть розділені одним пробілом. Якщо користувач введе ім’я без пробілу або навпаки використає декілька, то програма виведе не те, що ми очікуємо:
Перший варіант, як врахувати таку ситуацію - це додати * до регулярного виразу:^(.+), *(.+)?$.
Це буде означати “початок рядка, один або більше будь-яких символів, кома, нуль або більше пробілів, один або більше будь-яких символів, кінець рядка”:
python format.pyВведіть ім'я: Поттер,ГарріПривіт, Гаррі Поттер!python format.pyВведіть ім'я: Поттер, ГарріПривіт, Гаррі Поттер!
Попередження
Залежно від того, наскільки безладними є дані, ваші регулярні вирази можуть ставати все складнішими і складнішими. Кількість умов напряму впливає на їх складність.
Моржевий оператор
Ми можемо скоротити наш код, використовуючи “моржевий оператор” := (англ. walrus operator), який дозволяє присвоювати значення змінній та одночасно використовувати її у виразі:
Розглянемо варіант програми, де нам потрібно отримати дані з рядка, щоб відповісти на якесь питання. Наприклад, давайте створимо програму twitter.py, яка буде запитувати у користувачів URL-адресу їхнього профілю в Twitter і витягти з неї ім’я користувача:
Terminal
code twitter.py
Розглянемо рядок https://twitter.com/harrypotter. Перше на що звертаємо увагу - це те, адреса сервісу завжди починається з https://twitter.com/. Тому ми можемо замінити цю частину рядка на порожній рядок. Для цього ми можемо використати метод replace():
Але така проста програма не враховує низку ситуацій:
адреса може починатися без https://
адреса може починатися з http://
адреса може містити www.
тощо
Використаємо бібліотеку функцію:
re.sub(pattern, repl, string, count=0, flags=0),
яка замінює всі входження патерну pattern на repl у рядку string.
Використаємо регулярний вираз ^(https?://)?(www\.)?twitter\.com/, який читається як: “початок рядка, група символів https:// або http:// 0 або 1 раз, група символів www. 0 або 1 раз, twitter.com/”:
Ім'я користувача: https://facebook.com/harrypotter
Отримання даних з рядка
В такому випадку ми можемо повернутися до re.search() та використати групи для отримання імені користувача, але для виключення певної групи з переліку можна використати ?::
Якщо ж ознайомитися з документацією Twitter, то можна знайти, що ім’я користувача може містити тільки літери, цифри, символ _, тобто не просто .+, що може бути чим завгодно. Тому ми можемо використати регулярний вираз [a-z0-9_]+ для більш точного пошуку імені користувача, який читається як: “будь-яка літера англійського алфавіту, цифра або символ _ 1 або більше разів”: