03 - Часові ряди та їх візуалізація
Прогнозування часових рядів
КНЕУ::ІІТЕ
оновлено: 2022-09-13
Приклад 2
Пропущені значення
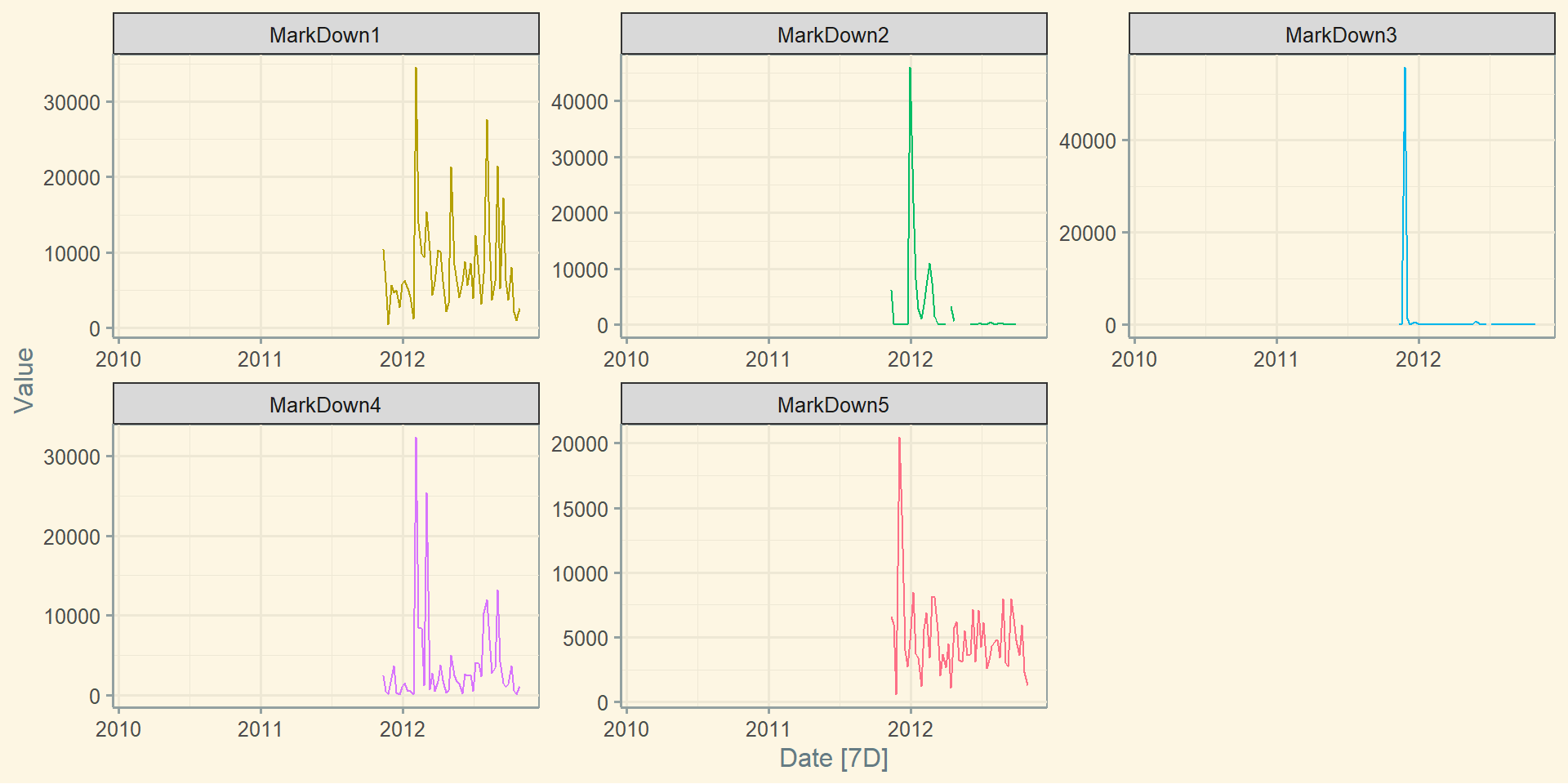
Заповнення пропусків: fill_gaps()
Заповнення NA
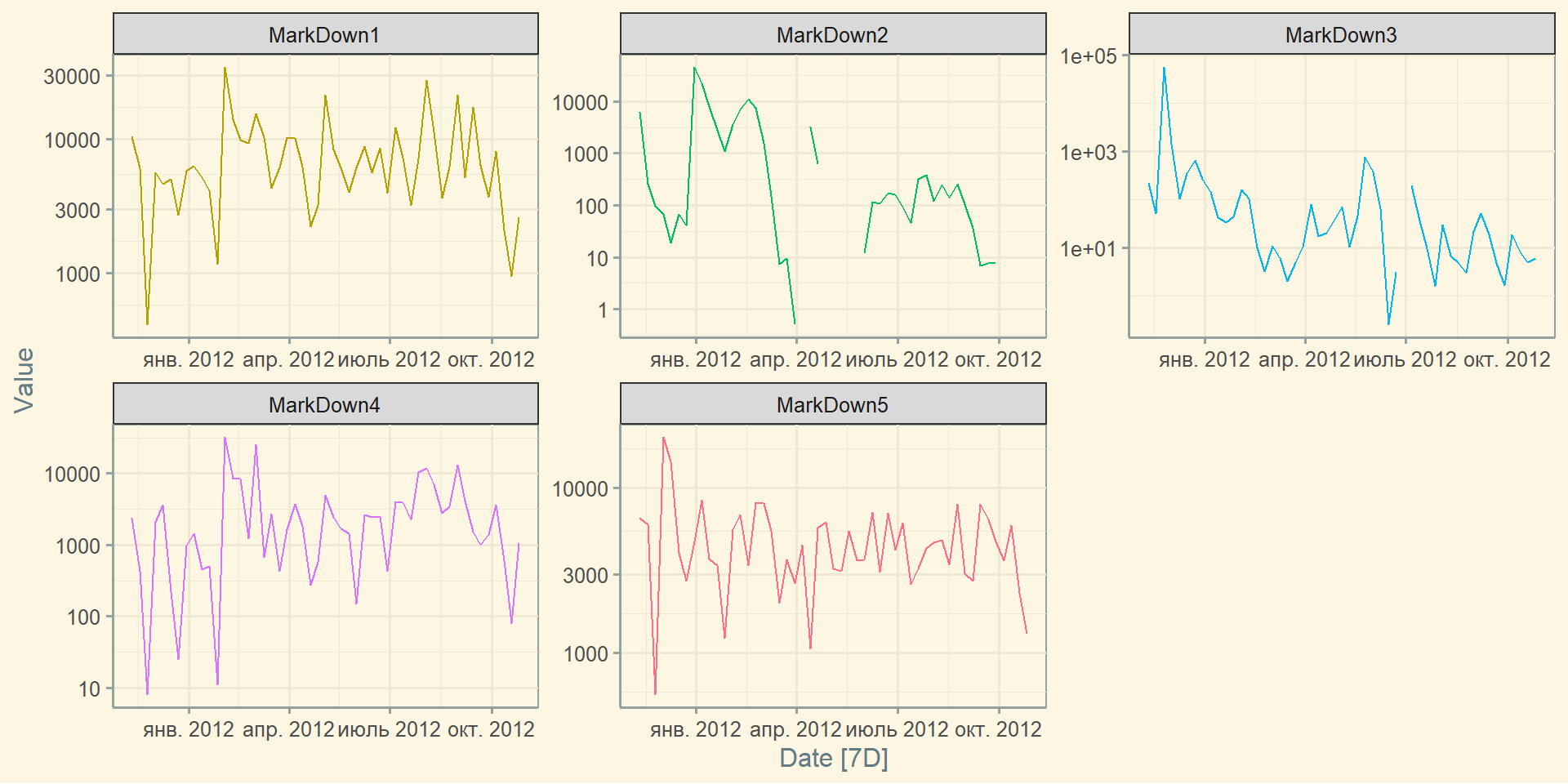
Заповнення пропусків: fill_gaps()
Заповнення сумою значень у кожній групі
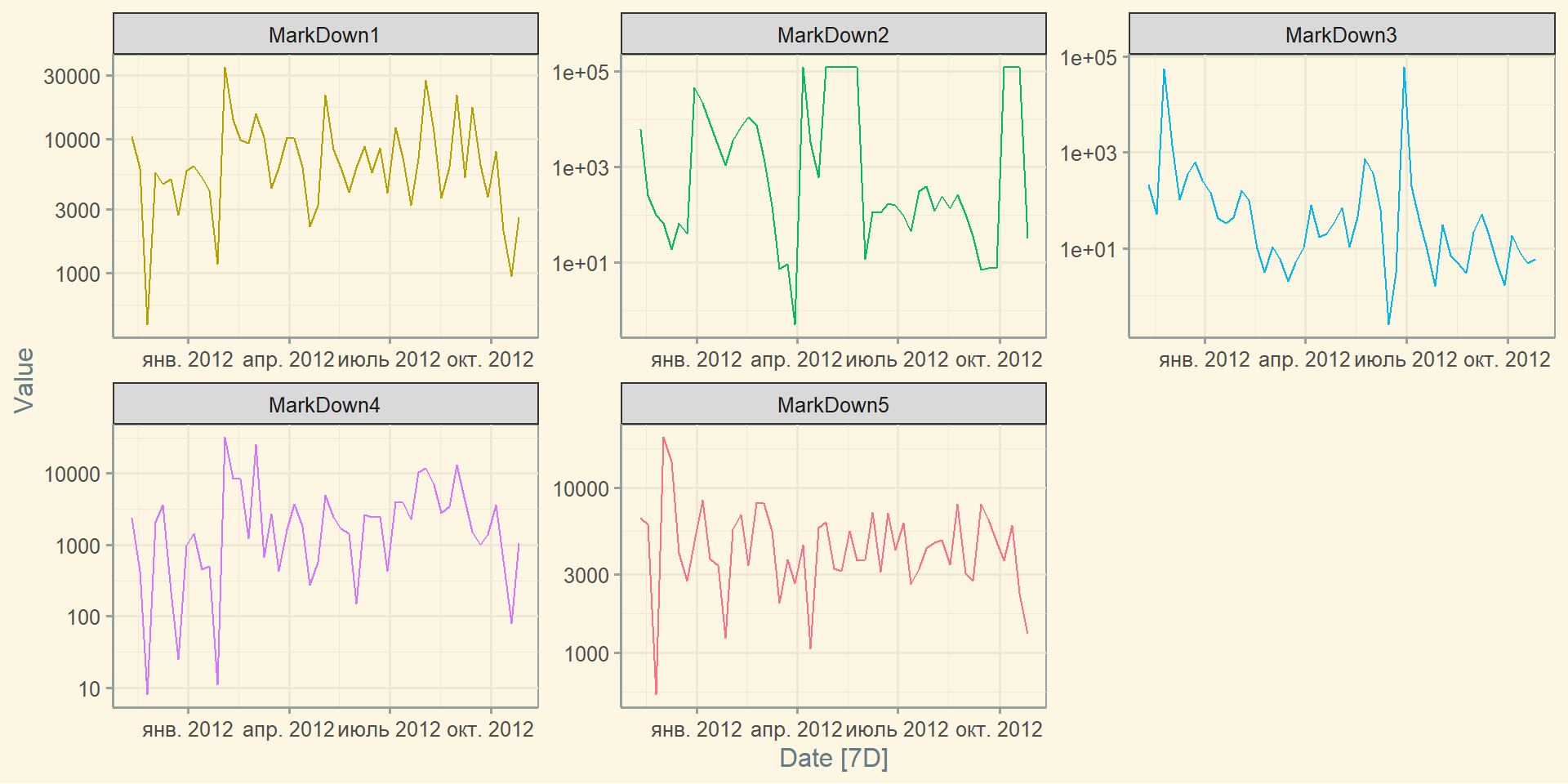
Заповнення пропусків: fill_gaps()
Заповнення середнім по кожній групі
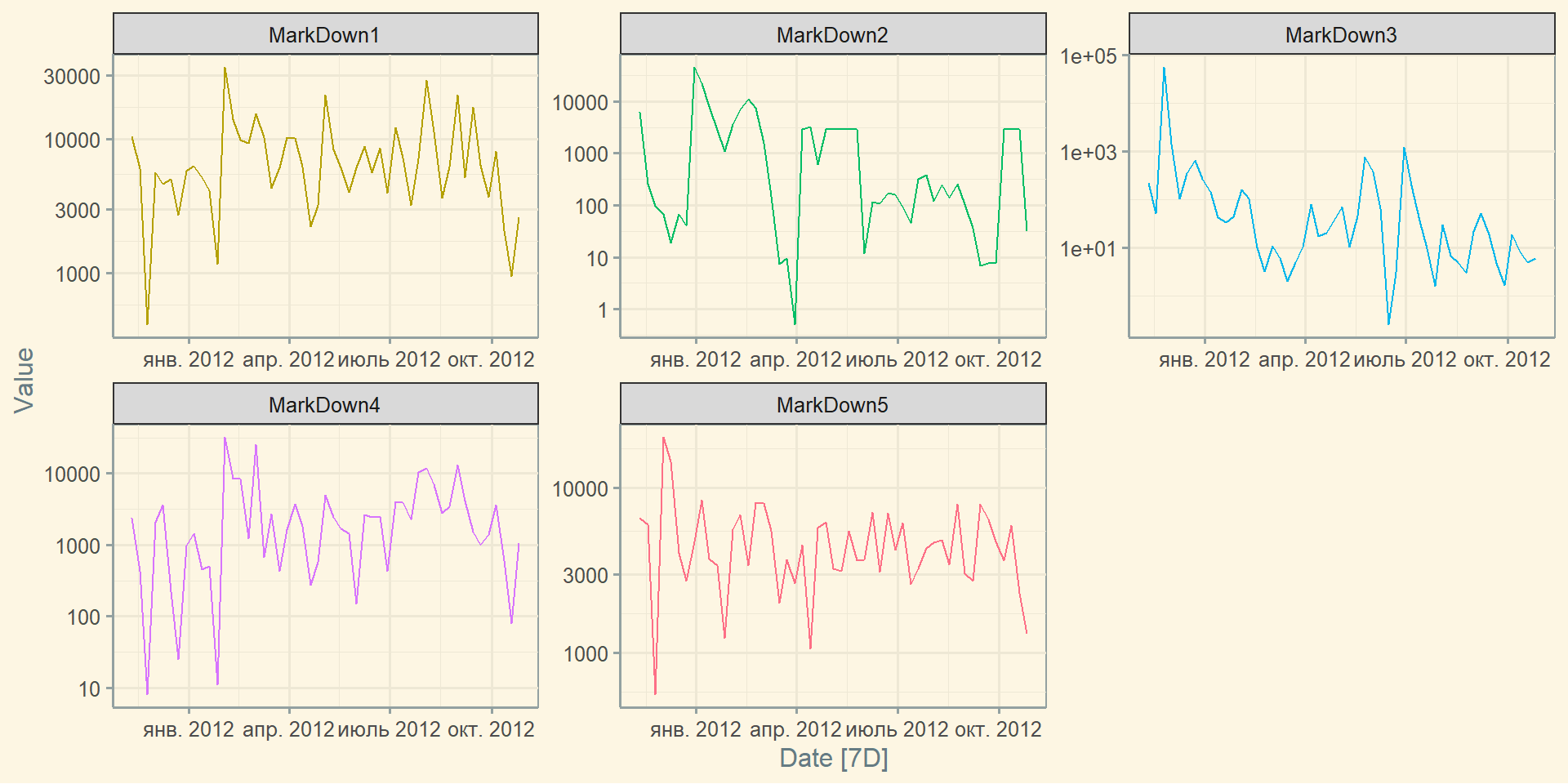
Заповнення пропусків: fill_gaps()
Заповнення медіаною по кожній групі
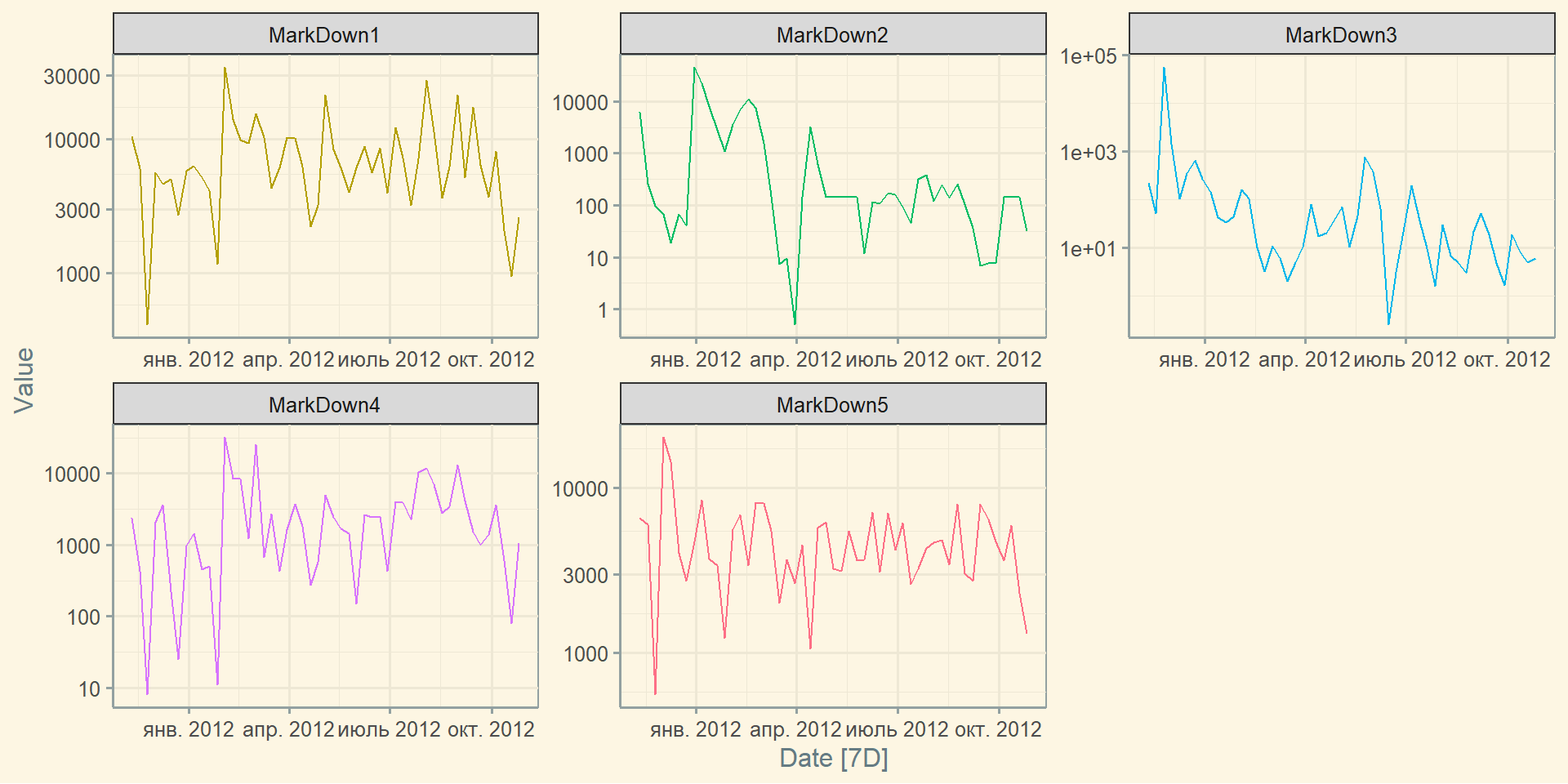
Заповнення пропусків: tidyr::fill()
Заповнення останніми значеннями
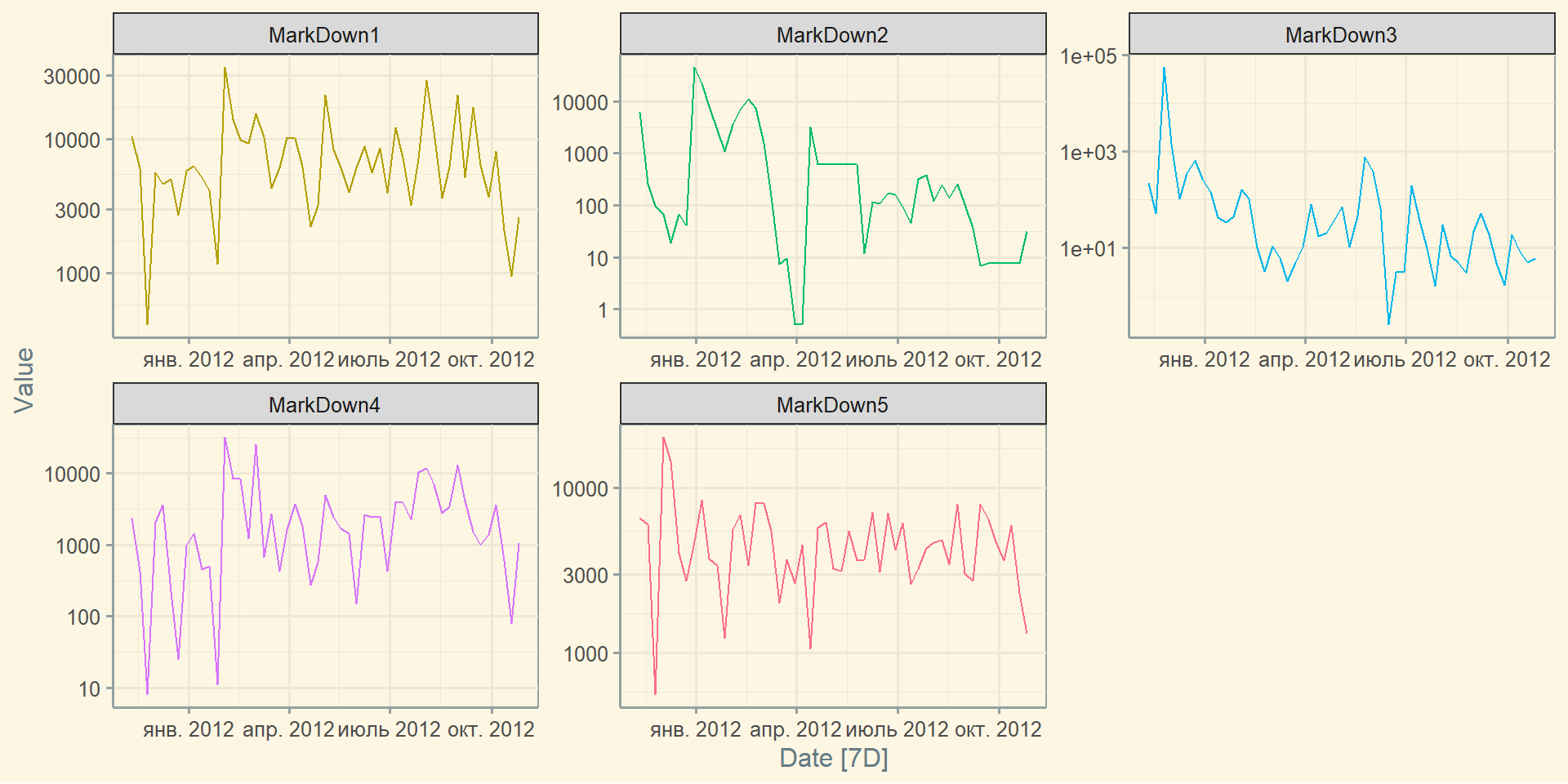
Групування за датою: index_by()
Візуалізація:
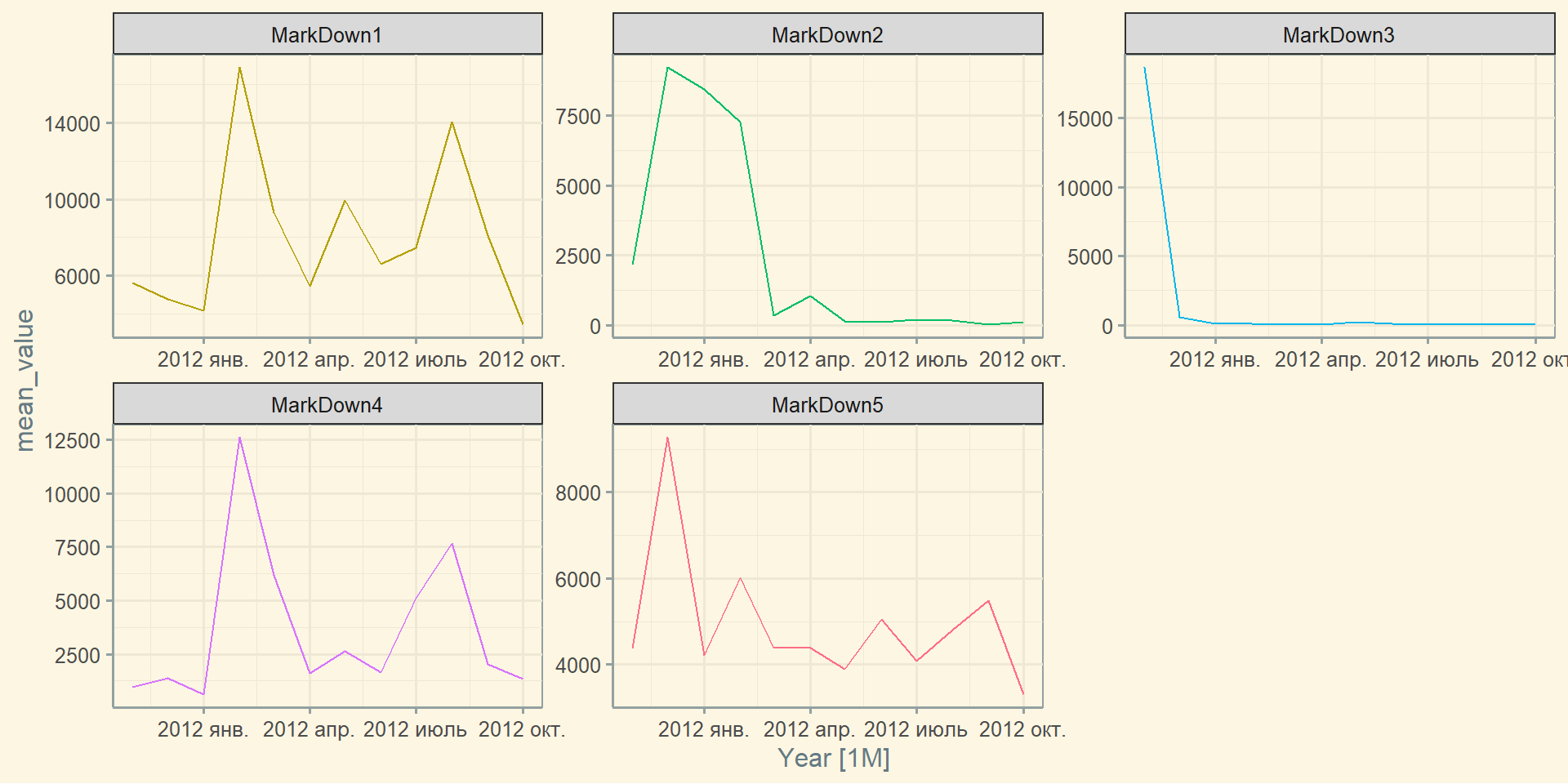
Базова візуалізація: autoplot()
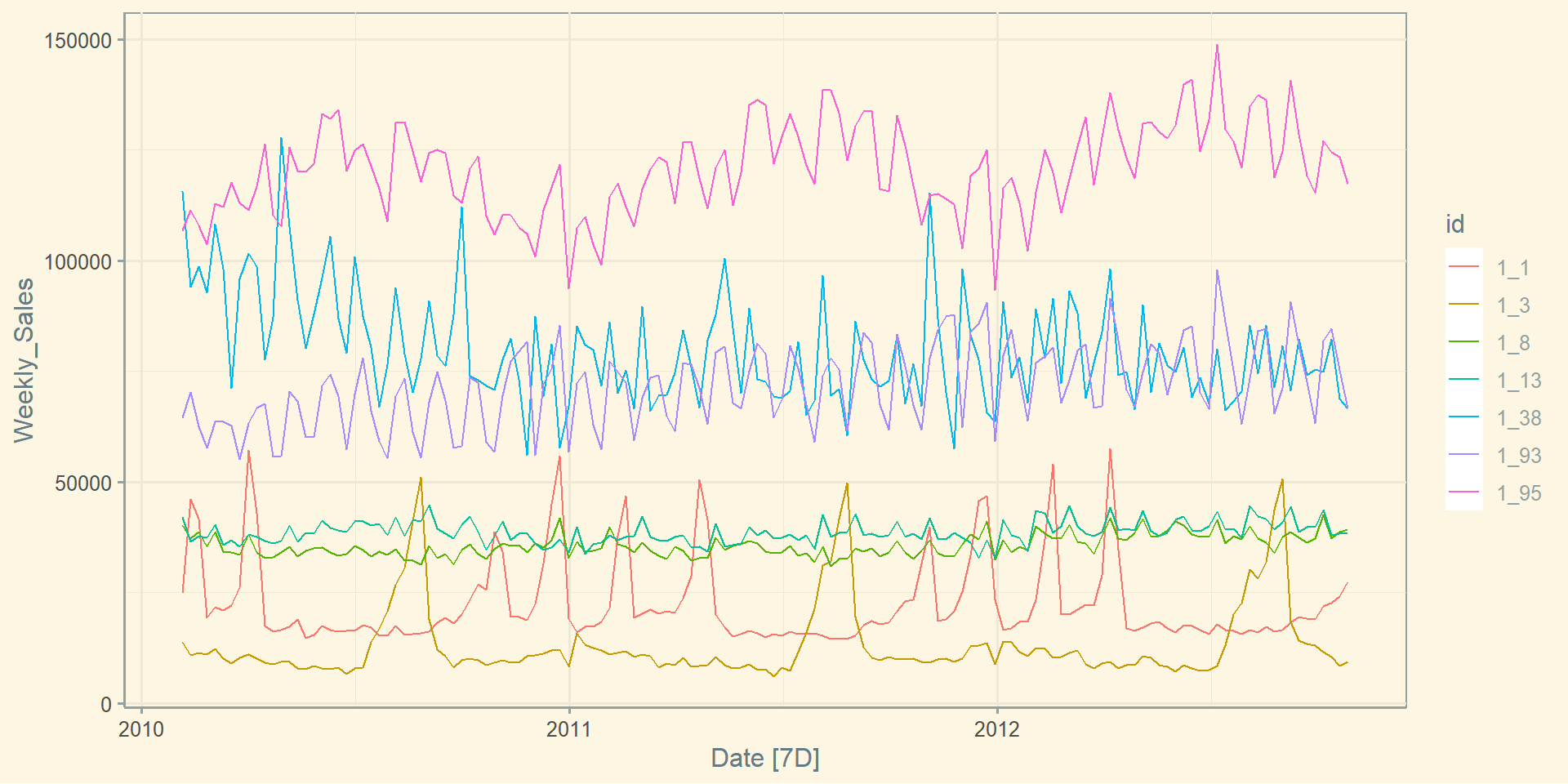
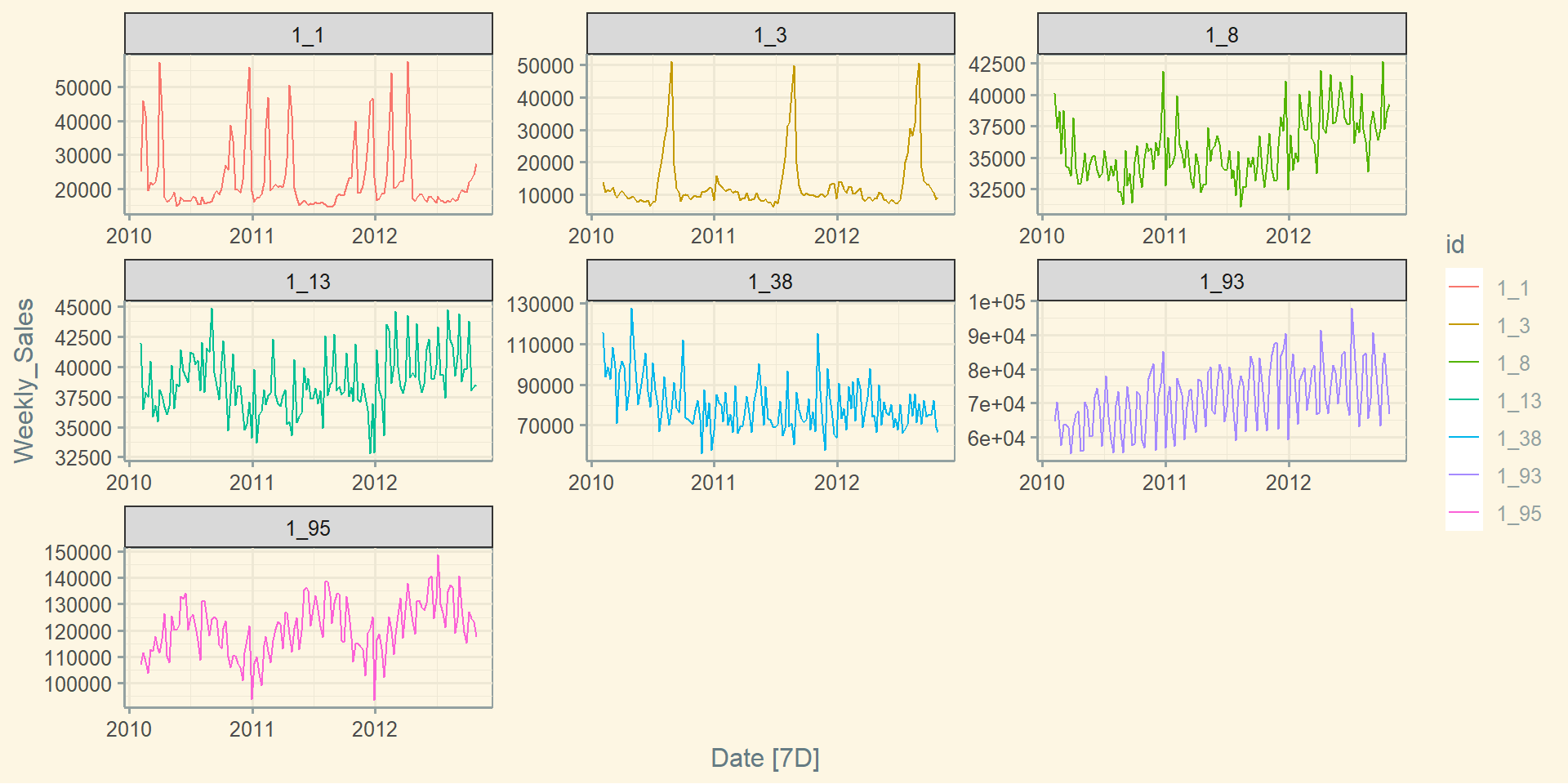
Базова візуалізація: facet_grid()
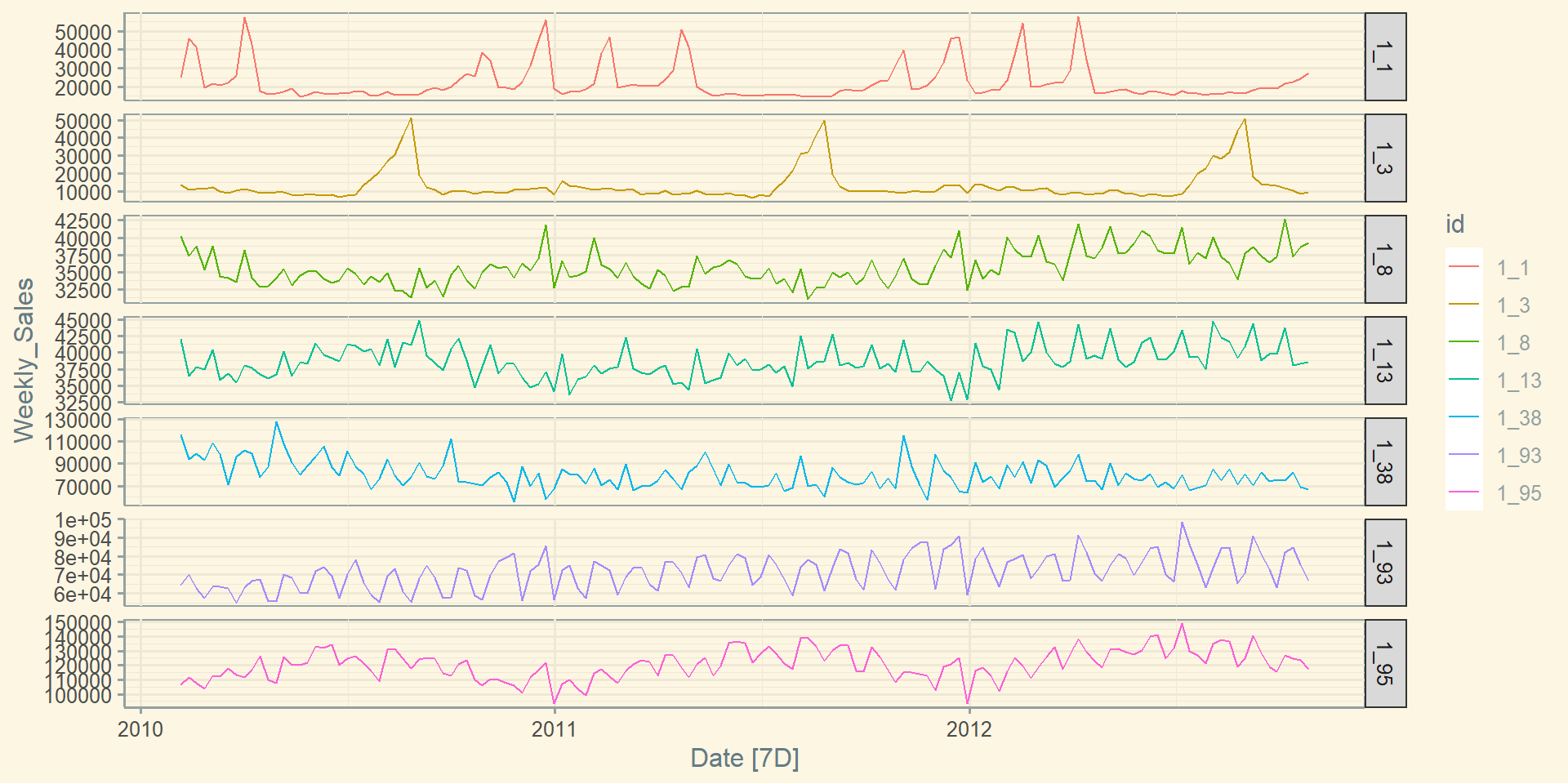
Базова візуалізація: facet_wrap()
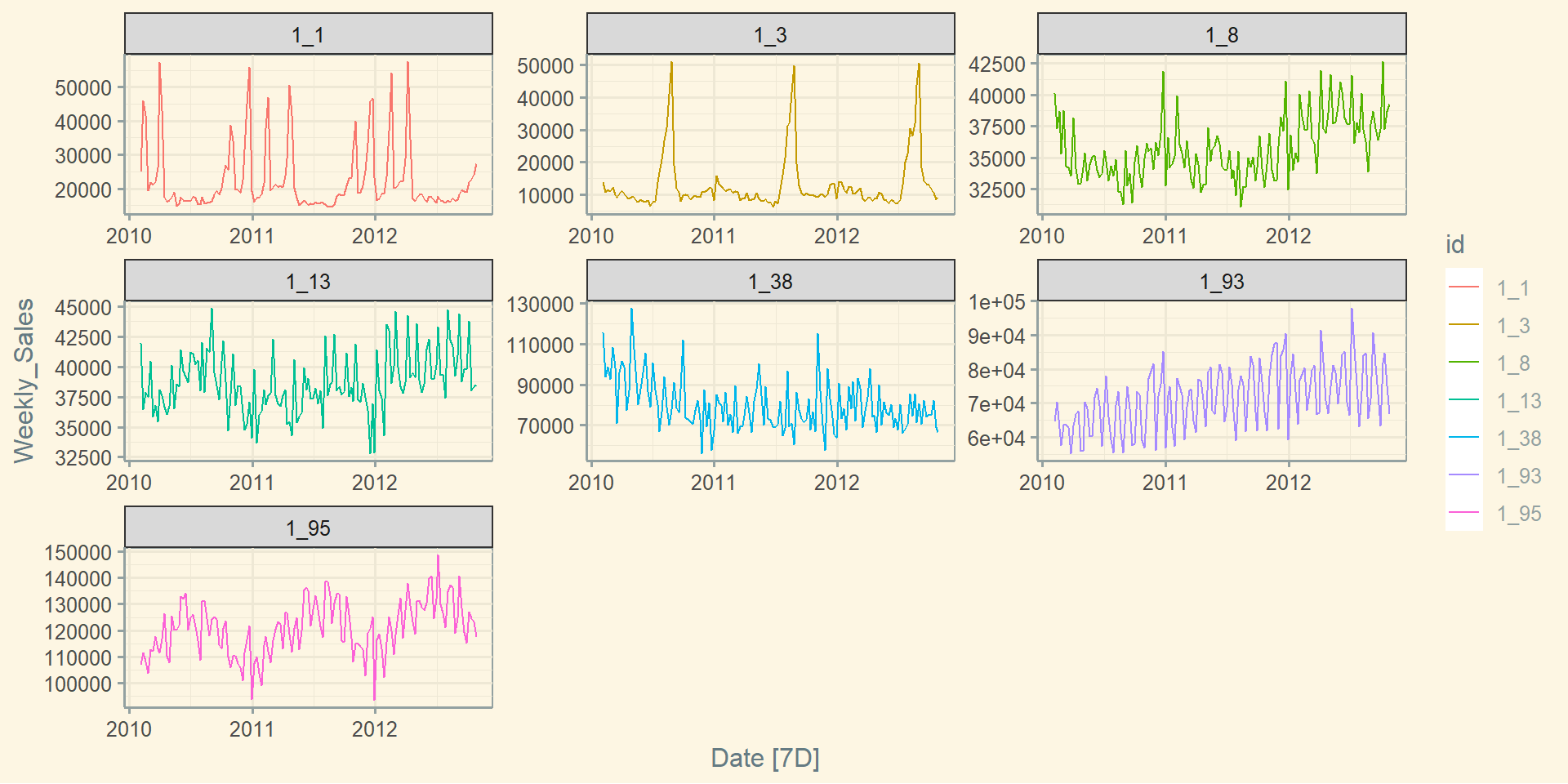
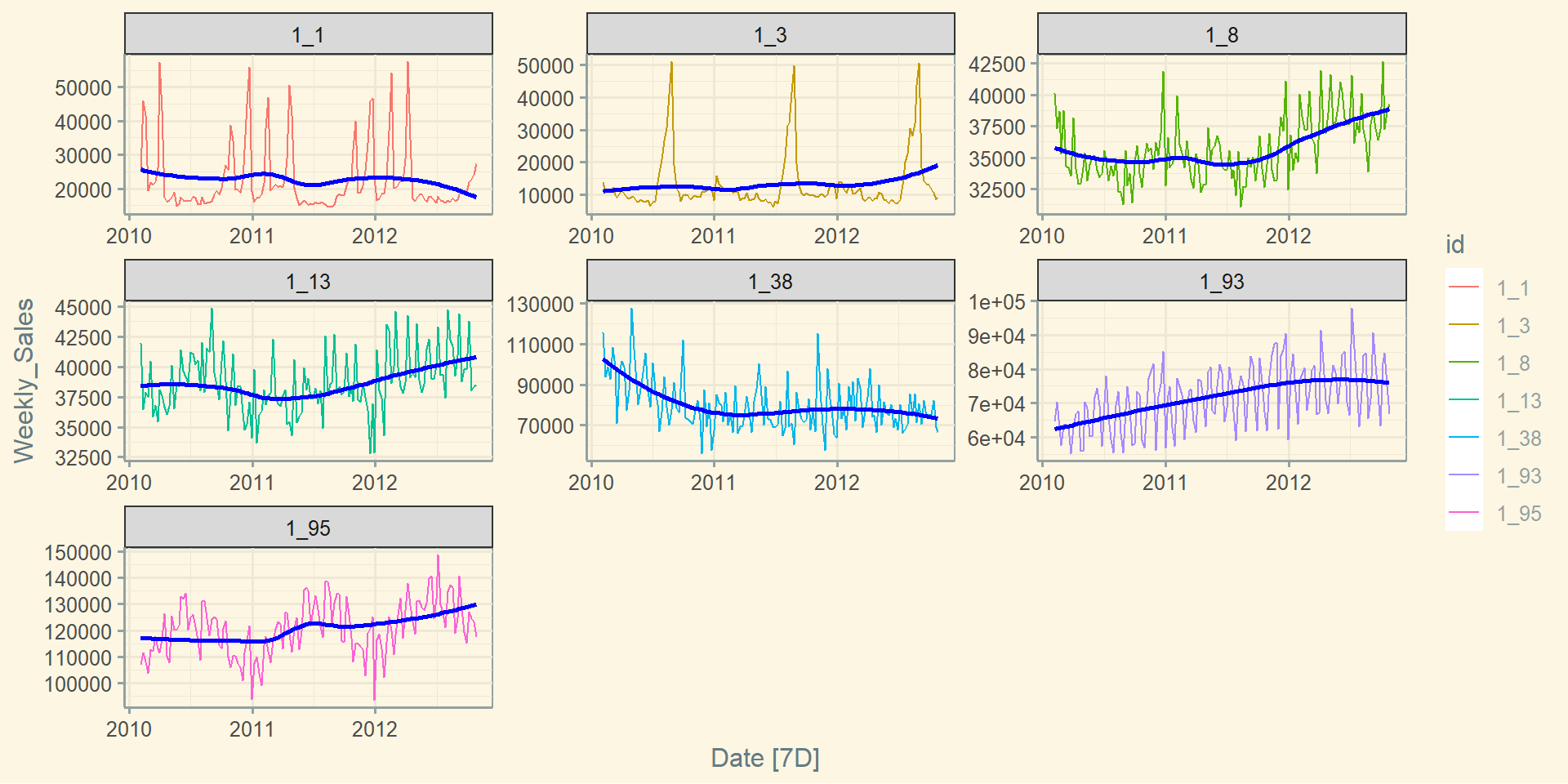
Базова візуалізація: geom_smooth()
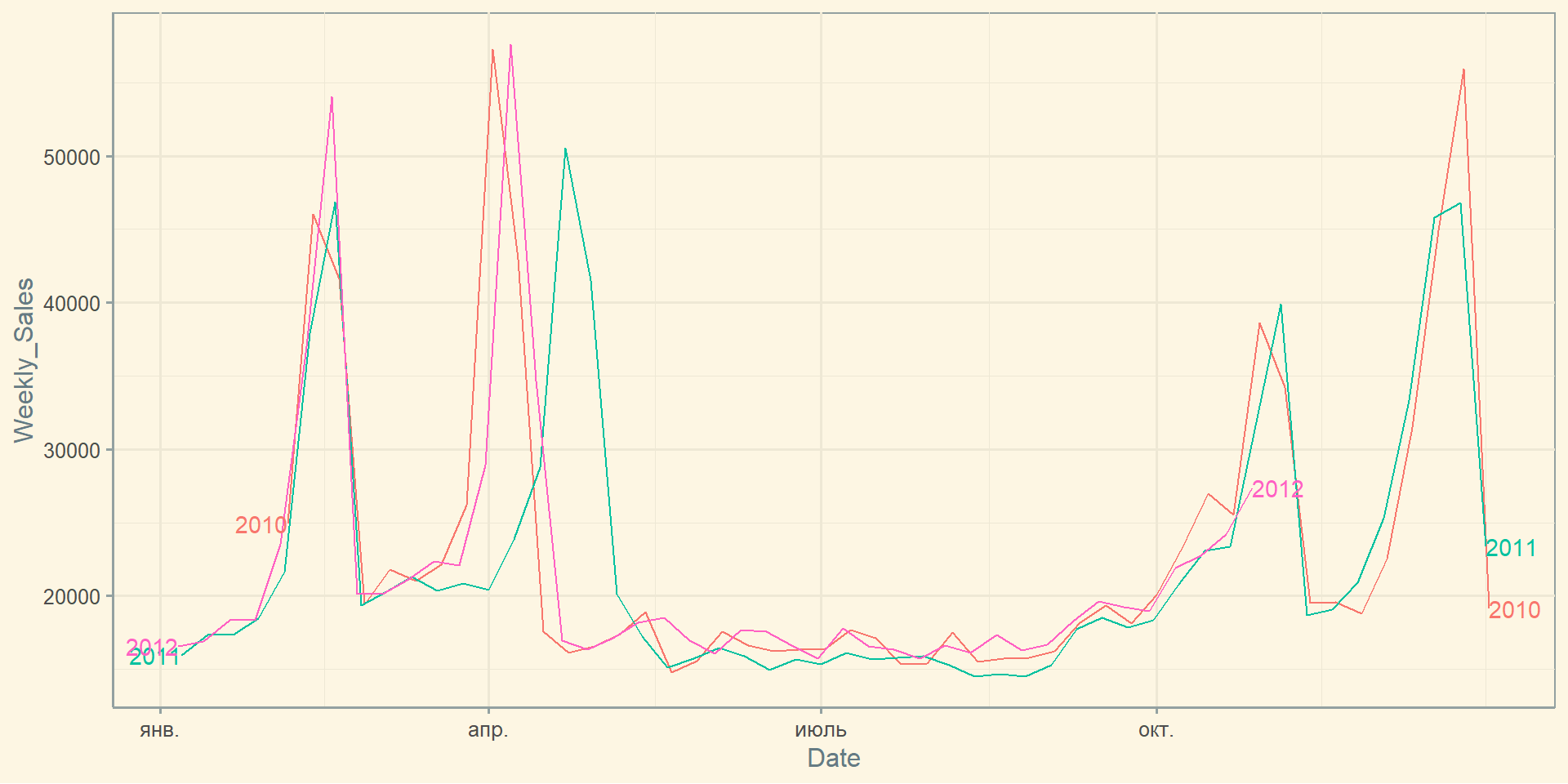
Графік сезонності: gg_season()
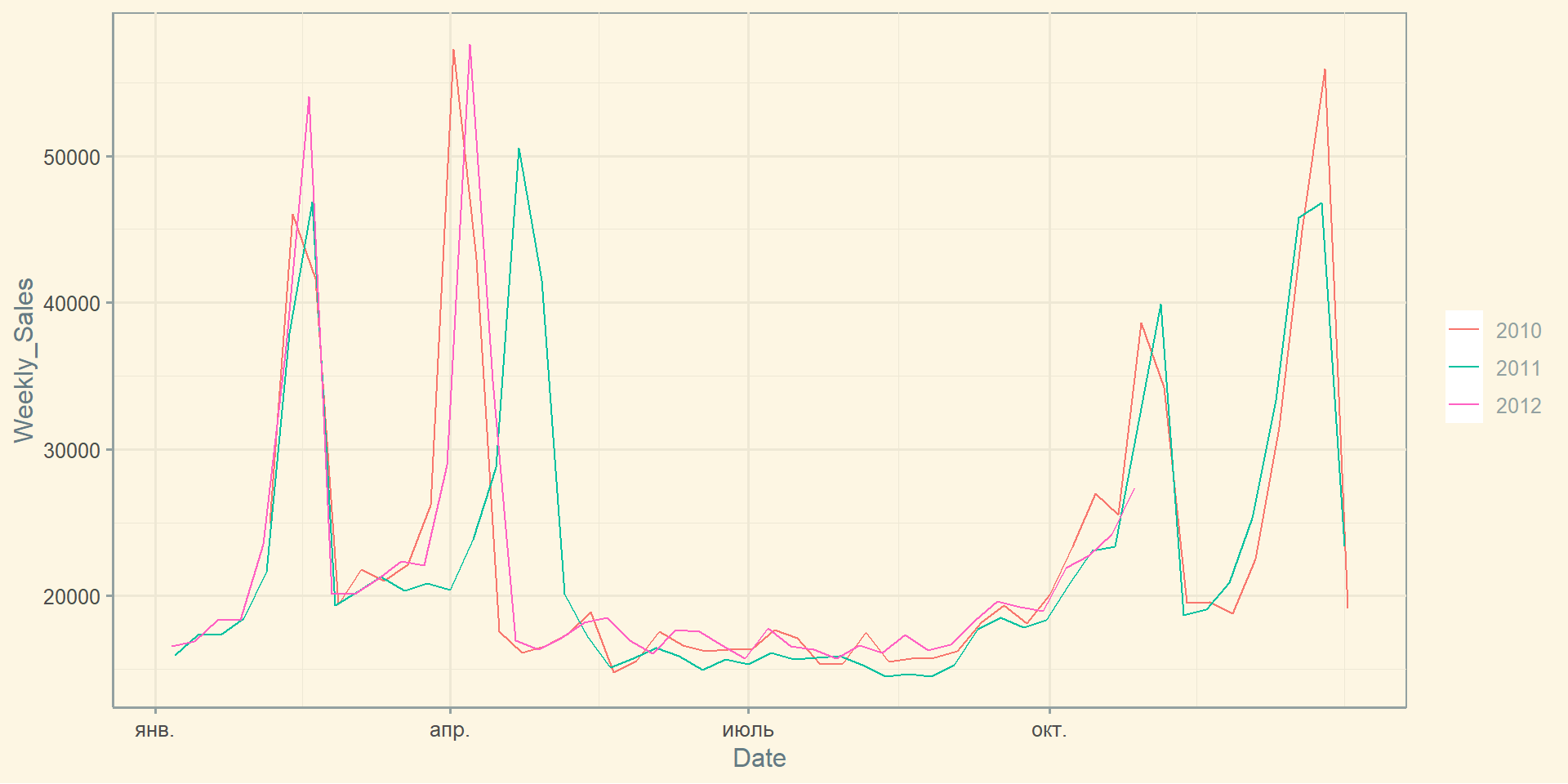
Графік сезонності: gg_season()
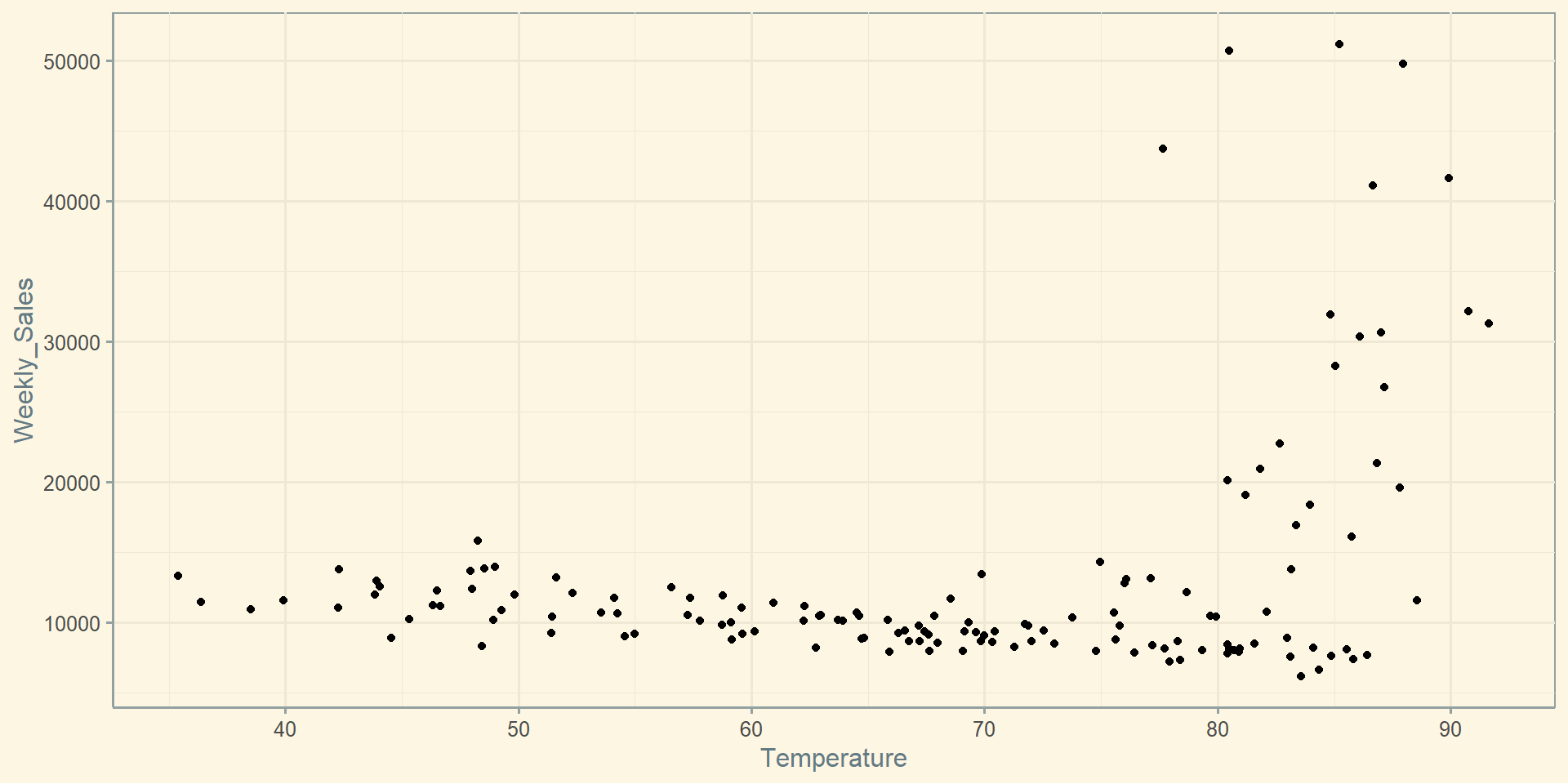
Точковий графік
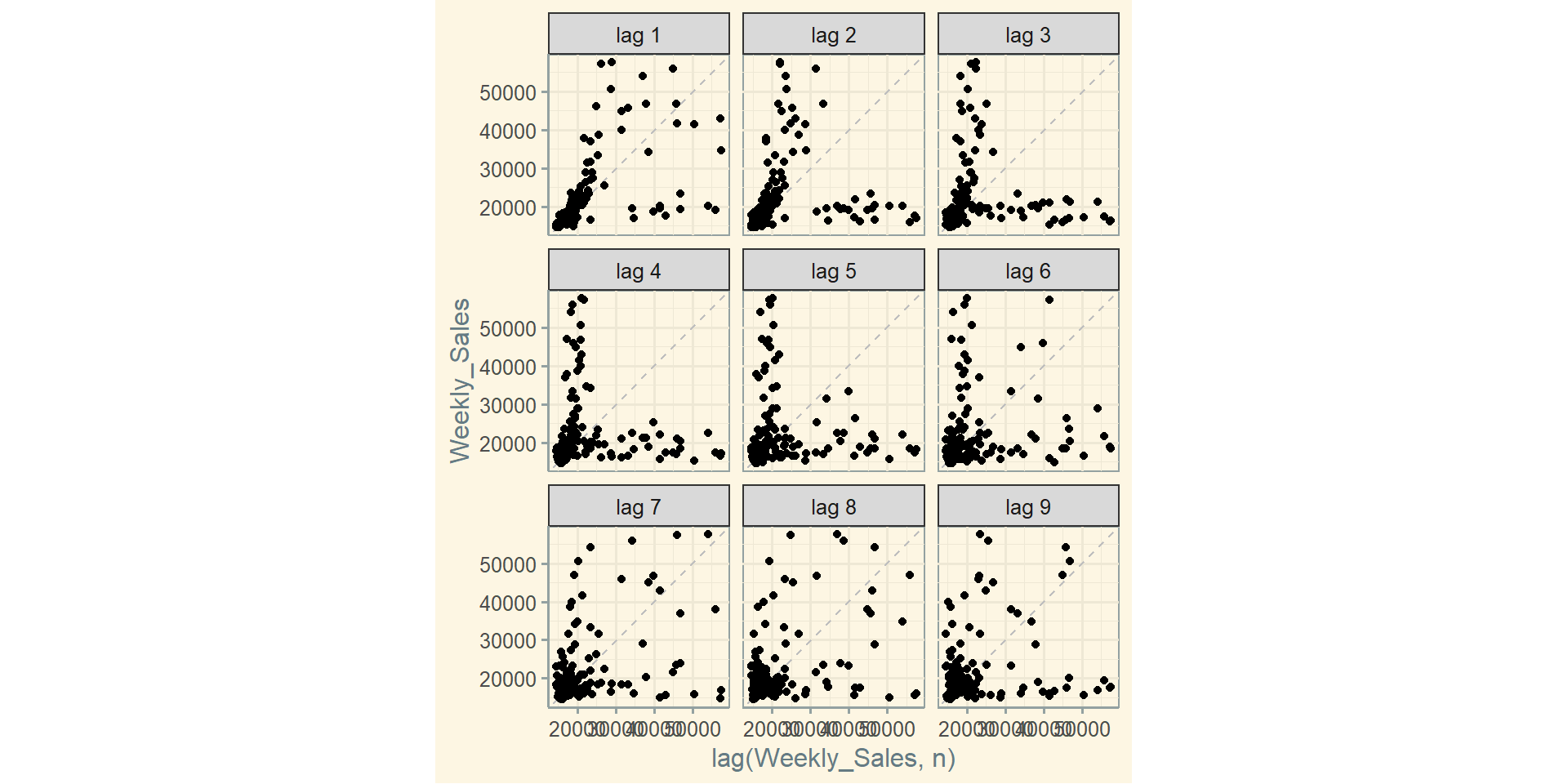
Графік лагів: gg_lag()
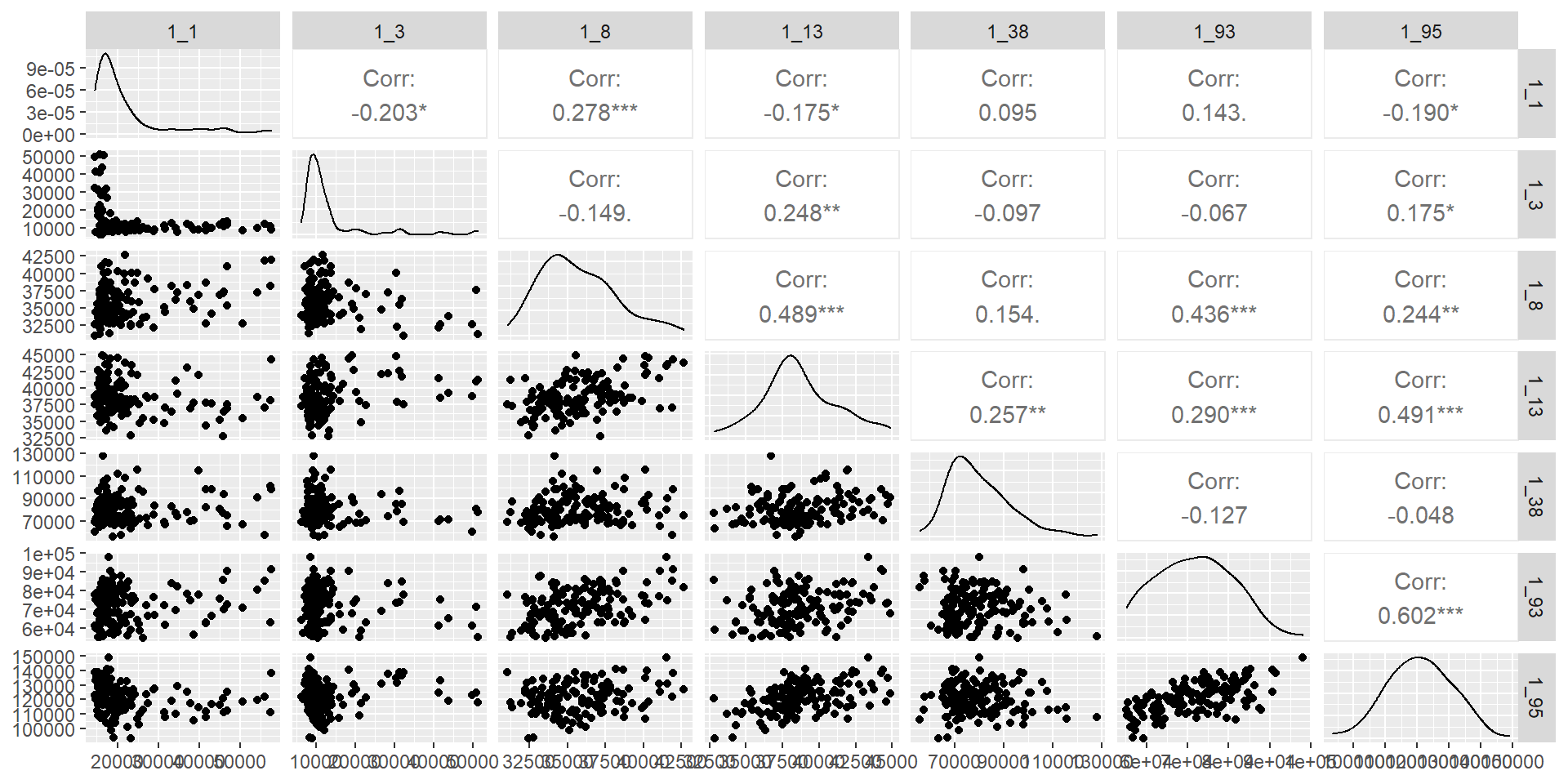
Графік кореляцій: ggpairs()
Корелограма автокореляції: ACF()
\[r_k = \frac{\sum_{t=k+1}^T(y_t - \overline{y})(y_{t-k} - \overline{y})}{\sum_{t=1}^T(y_t - \overline{y})^2}\]
\(T\) - довжина ЧР
# A tsibble: 21 x 3 [7D]
# Key: id [1]
id lag acf
<fct> <lag> <dbl>
1 1_1 7D 0.561
2 1_1 14D 0.120
3 1_1 21D -0.0222
4 1_1 28D -0.0622
5 1_1 35D -0.0390
6 1_1 42D 0.106
7 1_1 49D 0.364
8 1_1 56D 0.363
9 1_1 63D 0.168
10 1_1 70D 0.0327
# ... with 11 more rows
Додаткове оформлення графіків
walmart_sales %>%
autoplot(Weekly_Sales) +
geom_smooth(se = FALSE, colour = "blue") +
facet_wrap(~ id, scales = "free") +
labs(
title = "Sample Time Series Retail Data",
subtitle = "Walmart Recruiting Store Sales Forecasting Competition",
caption = "Ihor Miroshnychenko",
x = "Day",
y = "Weekly Sales"
) +
theme(legend.position = "none")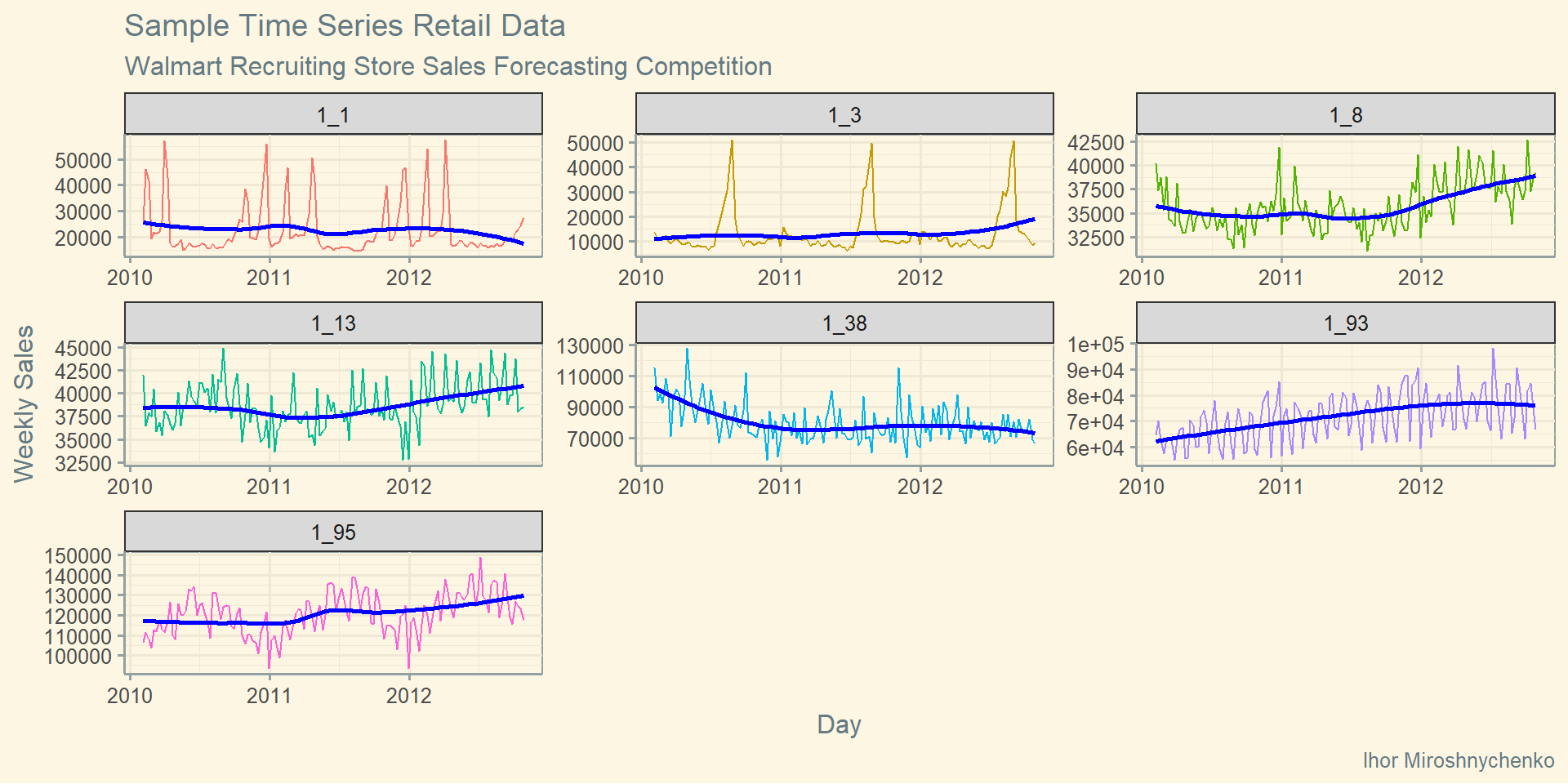
Дякую за увагу!
ihor.miroshnychenko@kneu.ua