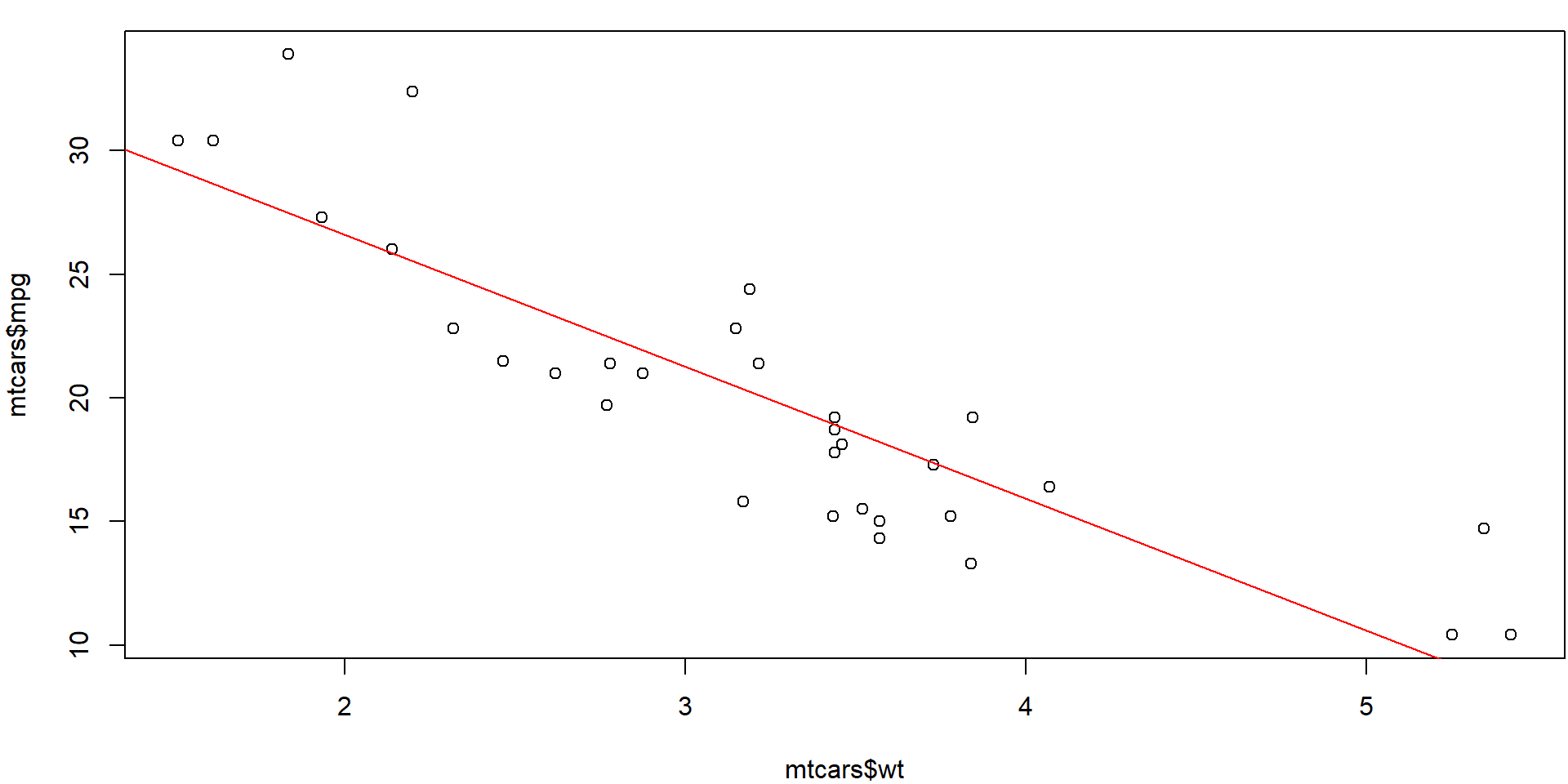
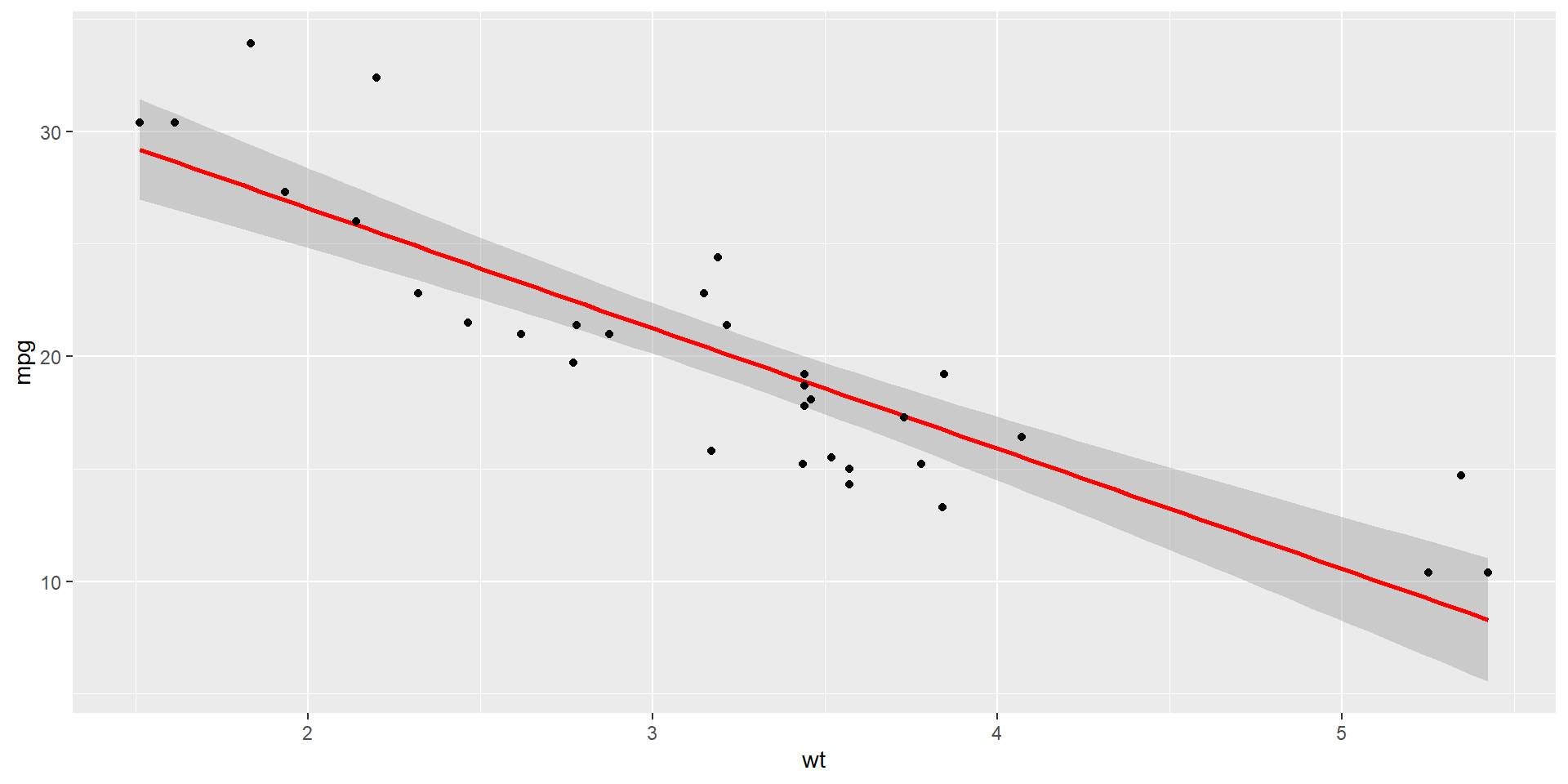
Call:
lm(formula = mpg ~ wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-1001 - Вступ до прогнозування
Прогнозування часових рядів
КНЕУ::ІІТЕ
оновлено: 2022-09-02
Прогнозувати складно
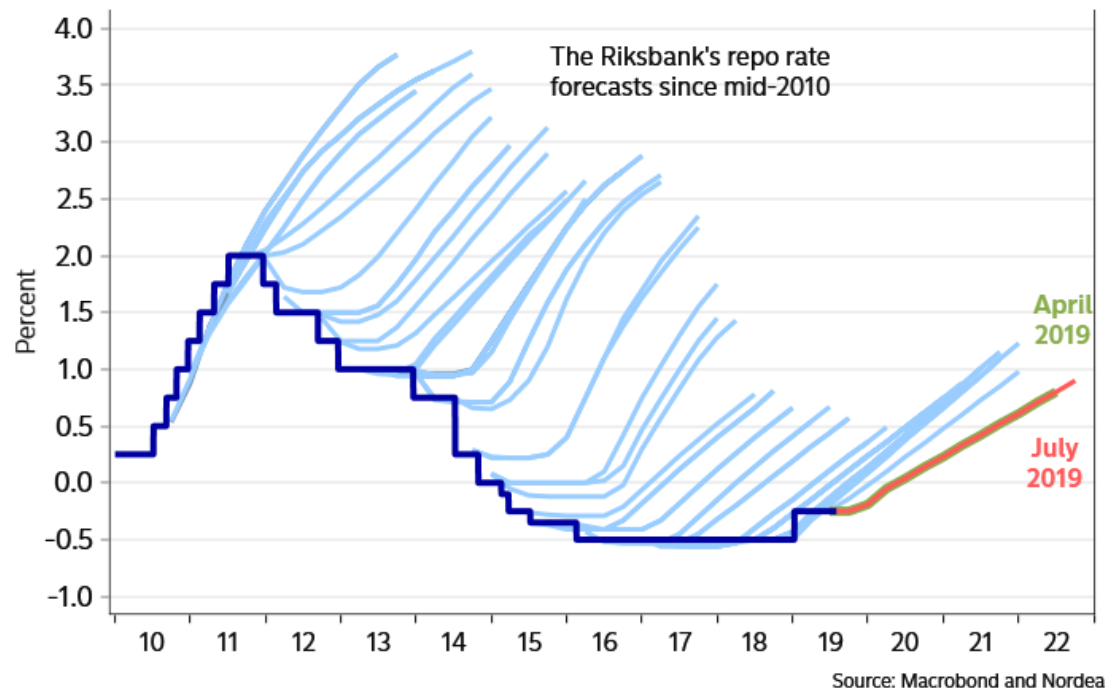
Прогнозувати складно

Що можна прогнозувати?

Що можна прогнозувати?

Що можна прогнозувати?

Що можна прогнозувати?

Що можна прогнозувати?
Що можна прогнозувати?

Що можна прогнозувати?

Щоквартальне виробництво пива
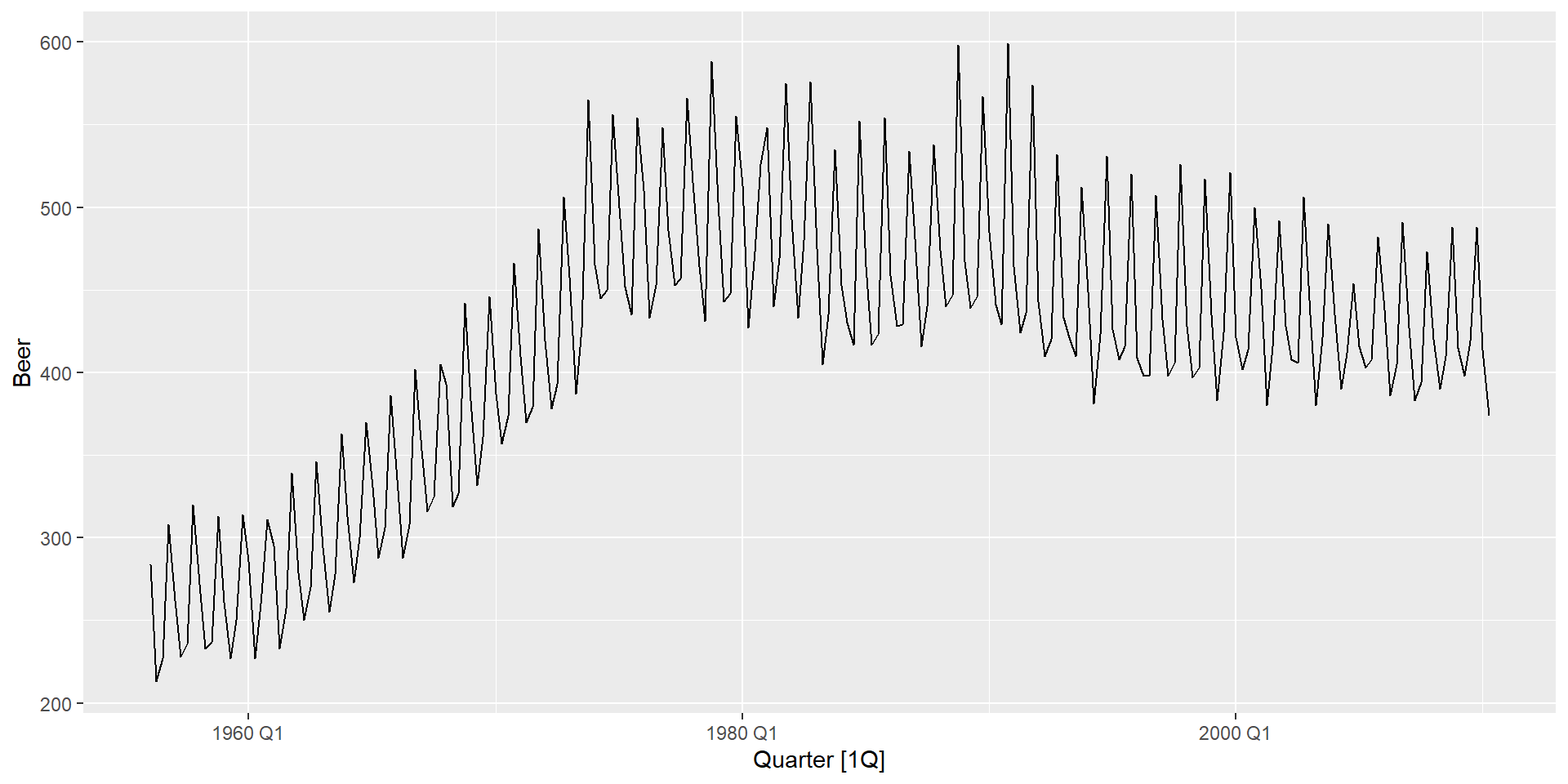
Щоквартальне виробництво пива
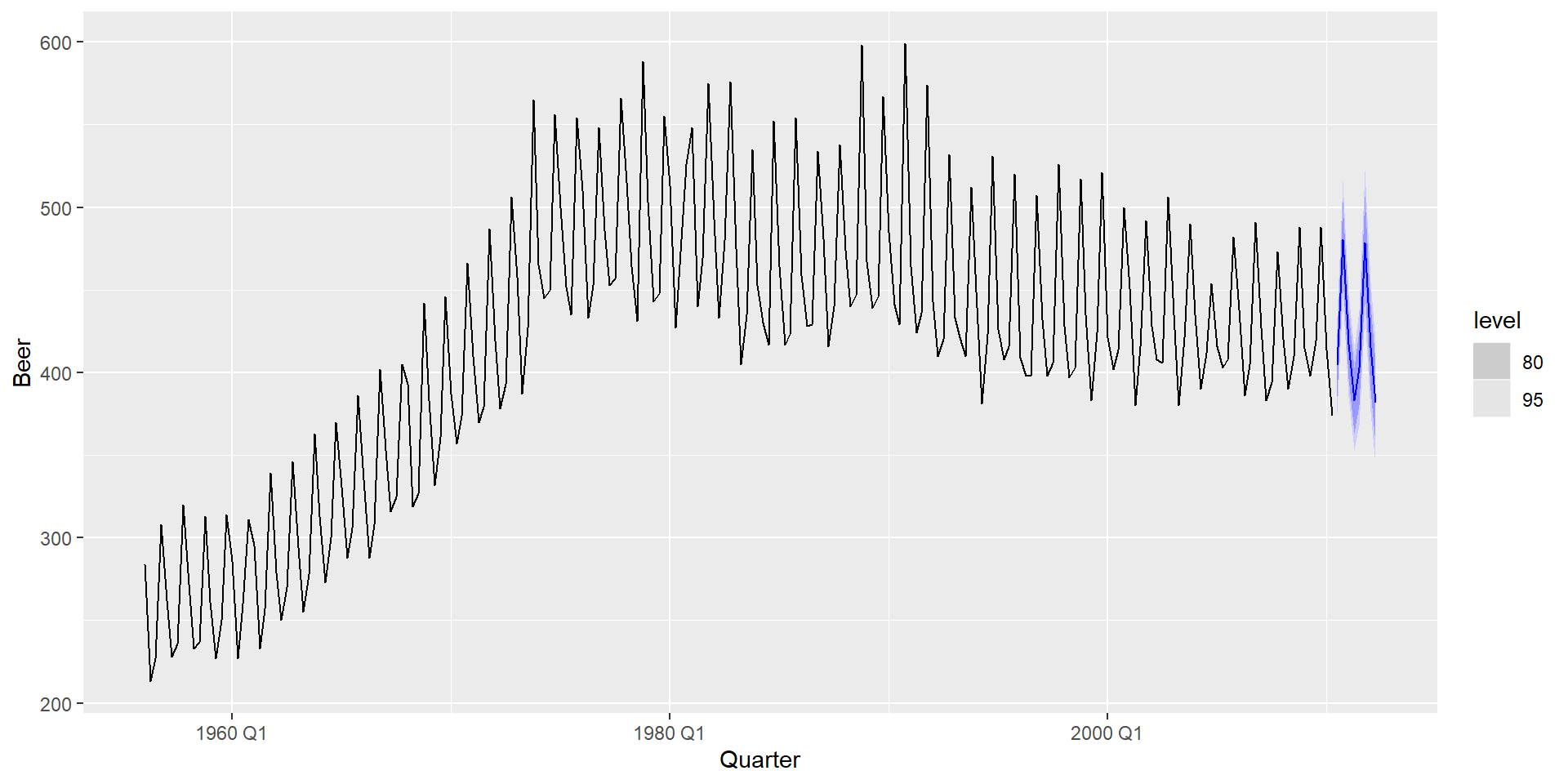
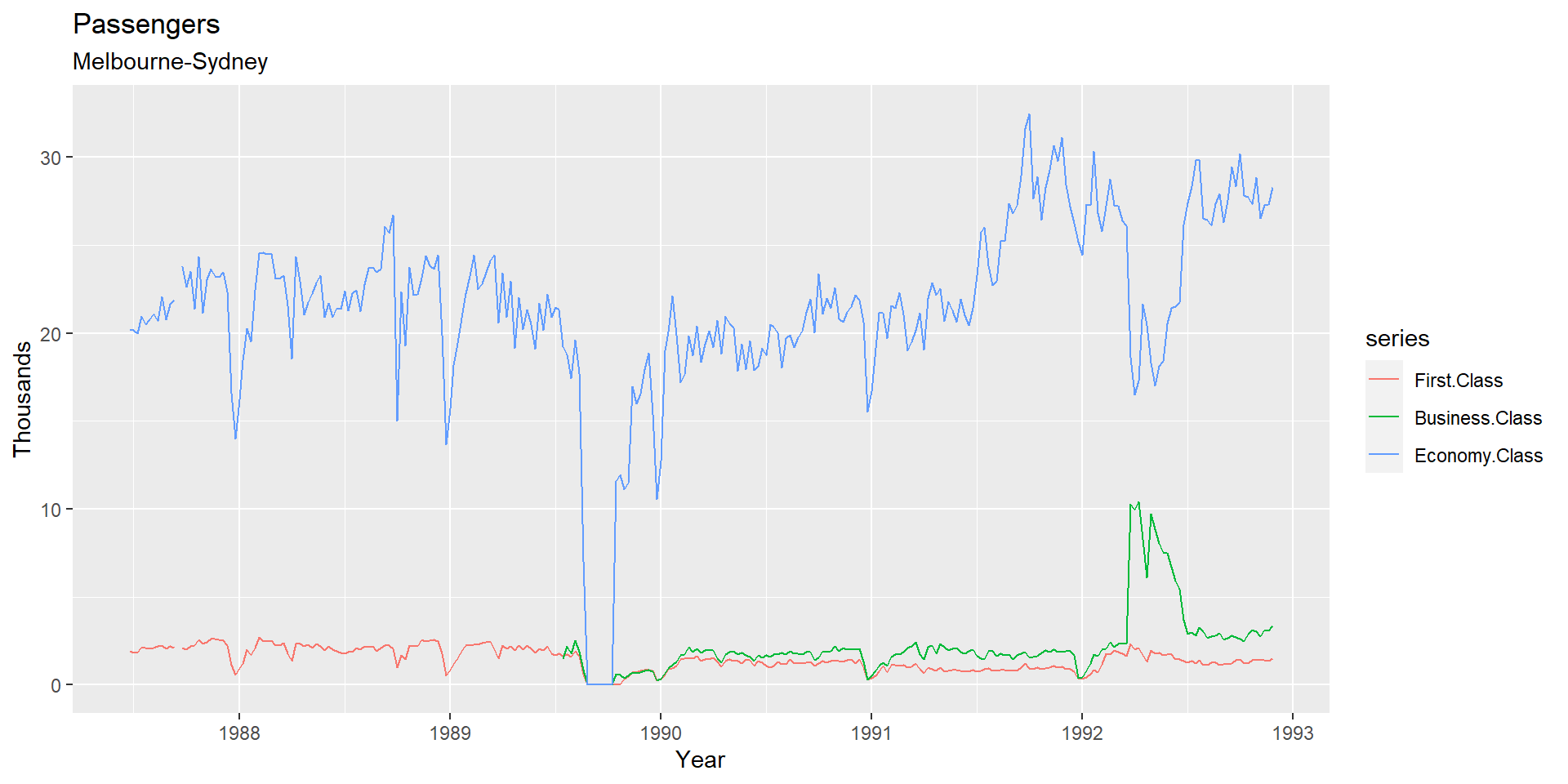
Приклад 3. Авіалінії
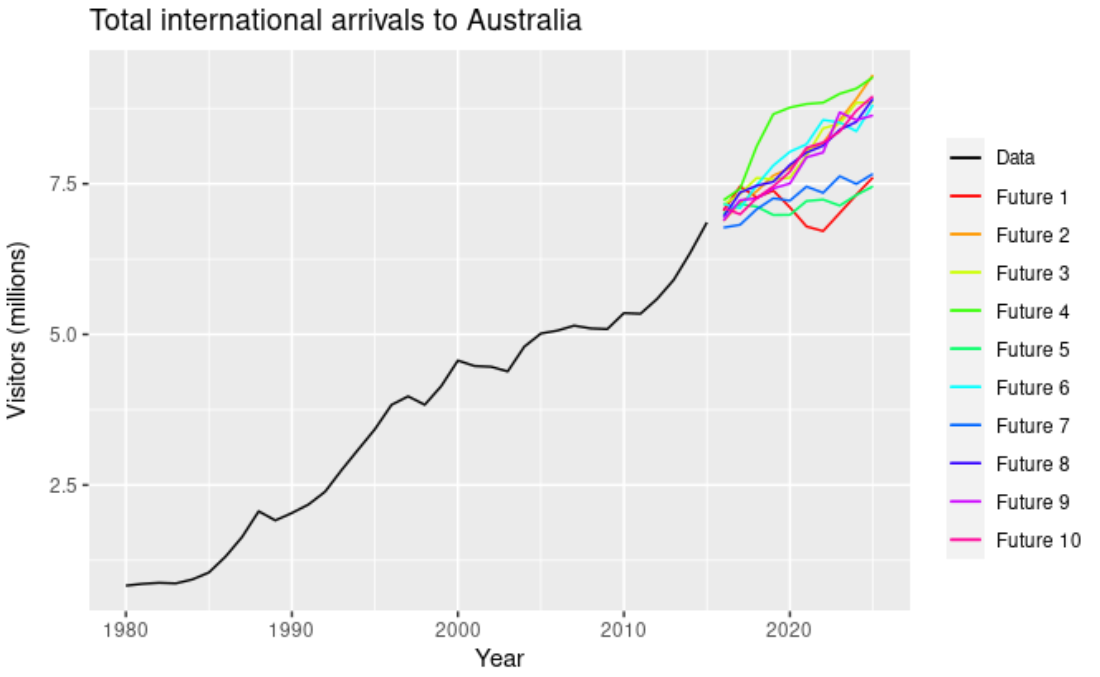
Прості прогнози
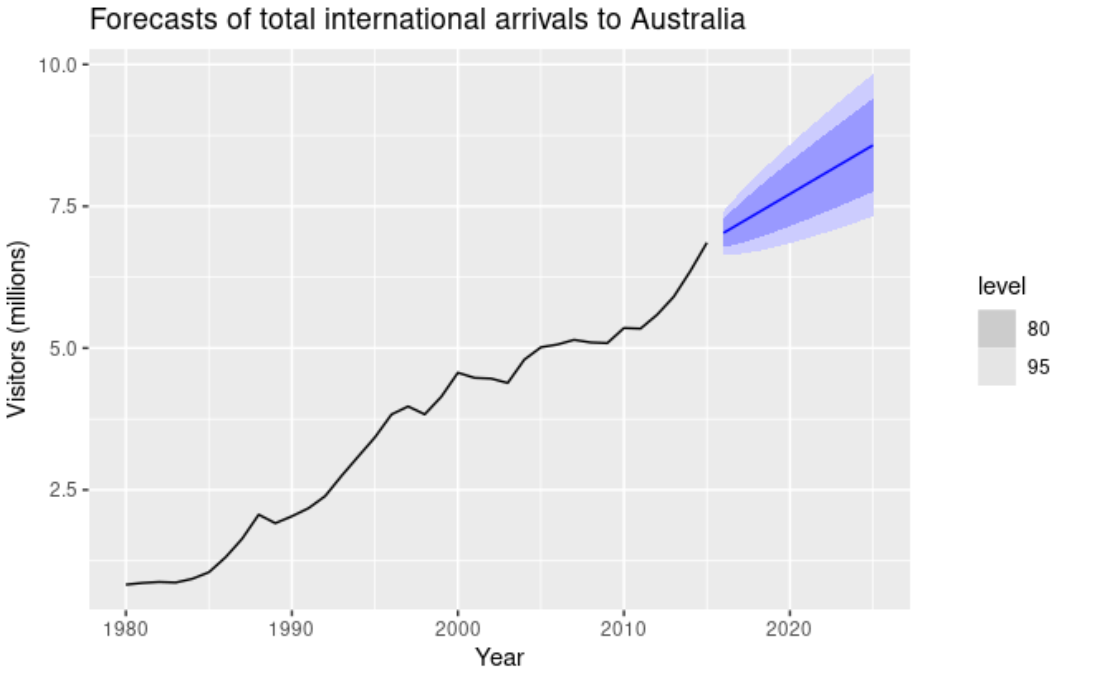
Довірчі інтервали
Чому R та RStudio?

Базова візуалізація R
ggplot2
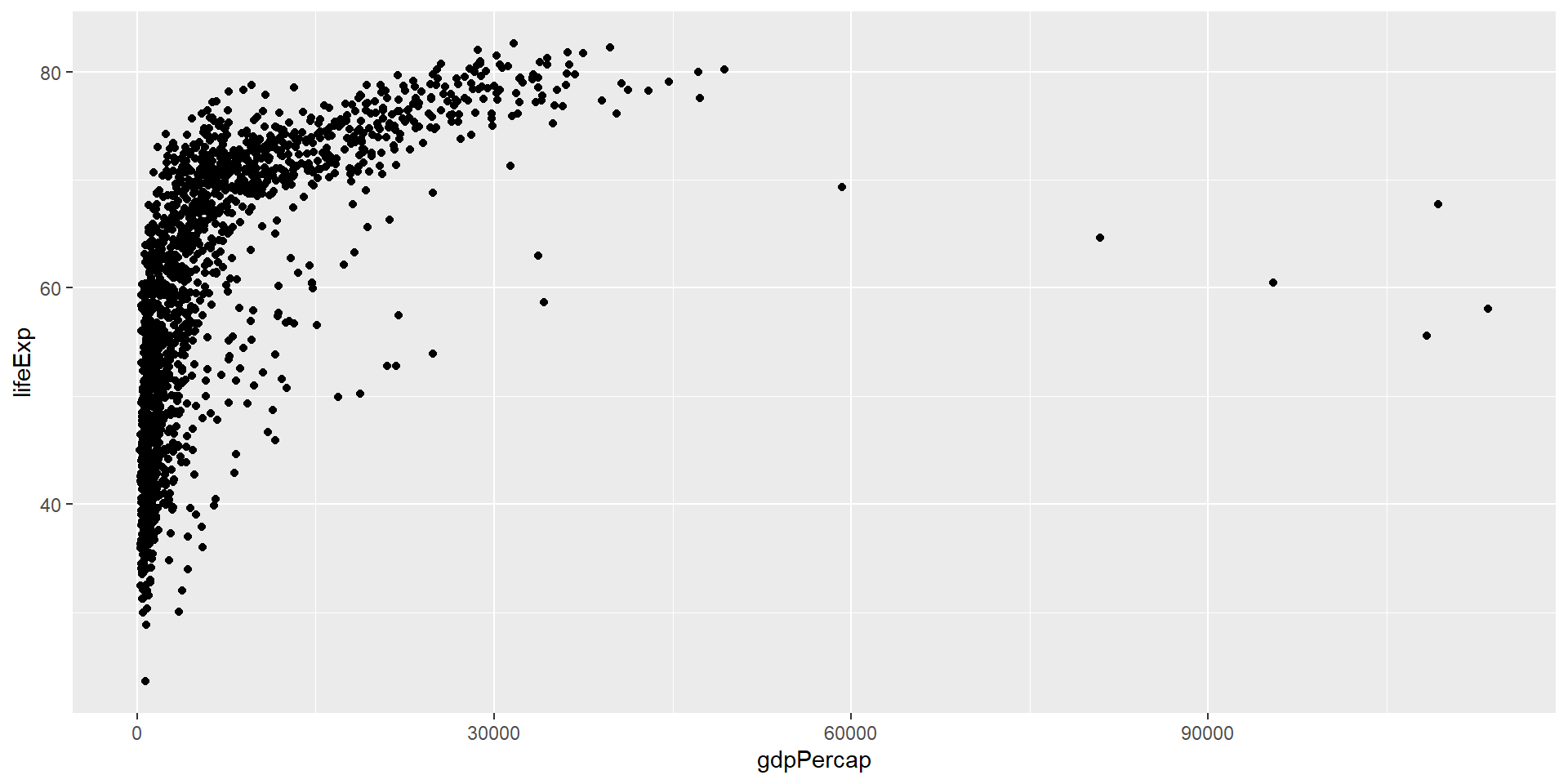
ggplot2: Gapminder
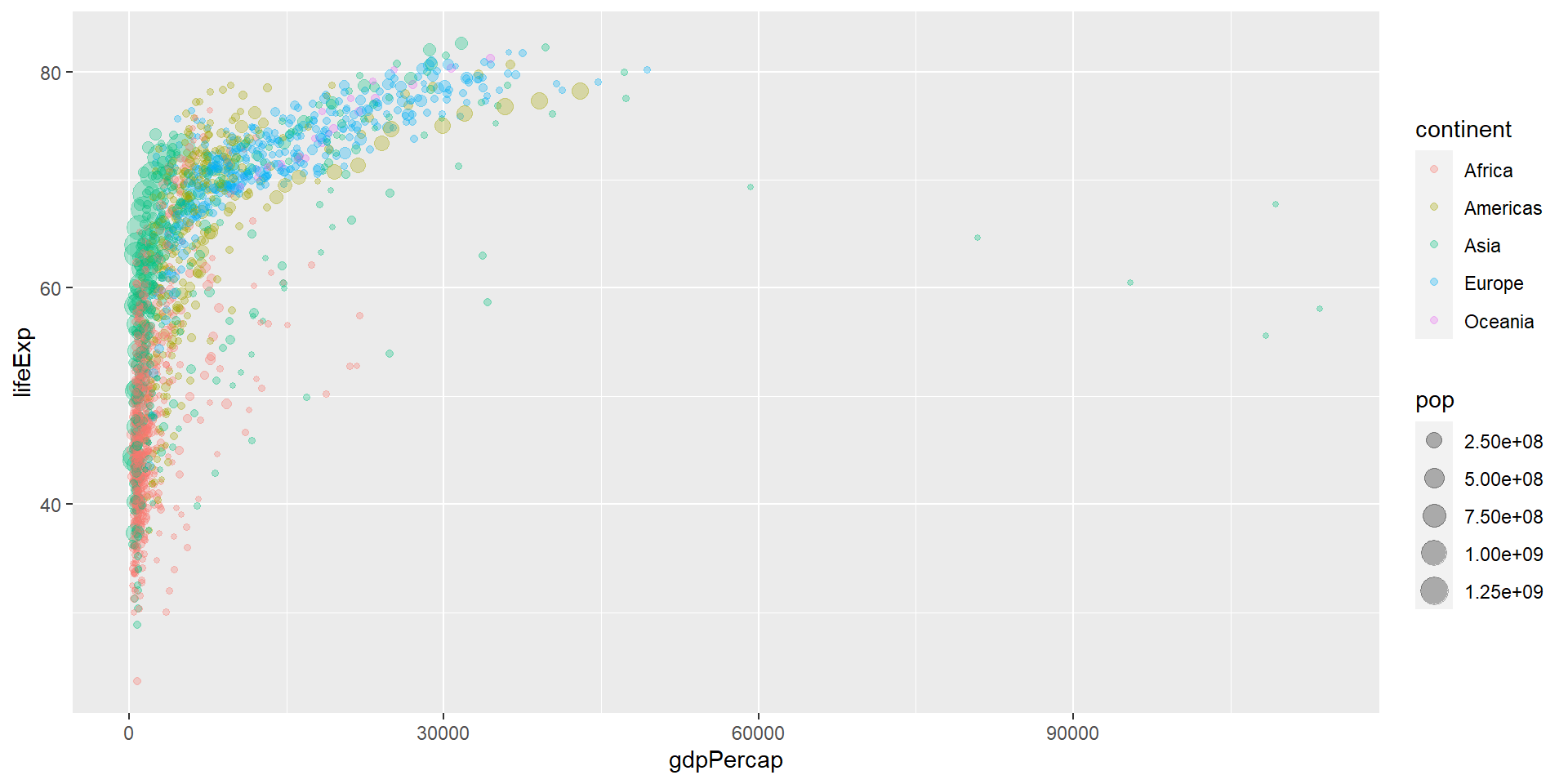
ggplot2: Gapminder
ggplot2: Gapminder
ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp)) +
geom_point(aes(size = pop, col = continent), alpha = 0.3) +
scale_color_brewer(name = "Continent", palette = "Set1") + ## Інша плітра кольорів
scale_size(name = "Population", labels = scales::comma) + ## Інші позначки легенди
scale_x_log10(labels = scales::dollar) + ## Логарифмування на осі х. Використання знаку долара.
labs(x = "Log (GDP per capita)", y = "Life Expectancy") + ## Кращі підписи до осей
theme_minimal() ## Мінімалистична (ч/б) тема рисунку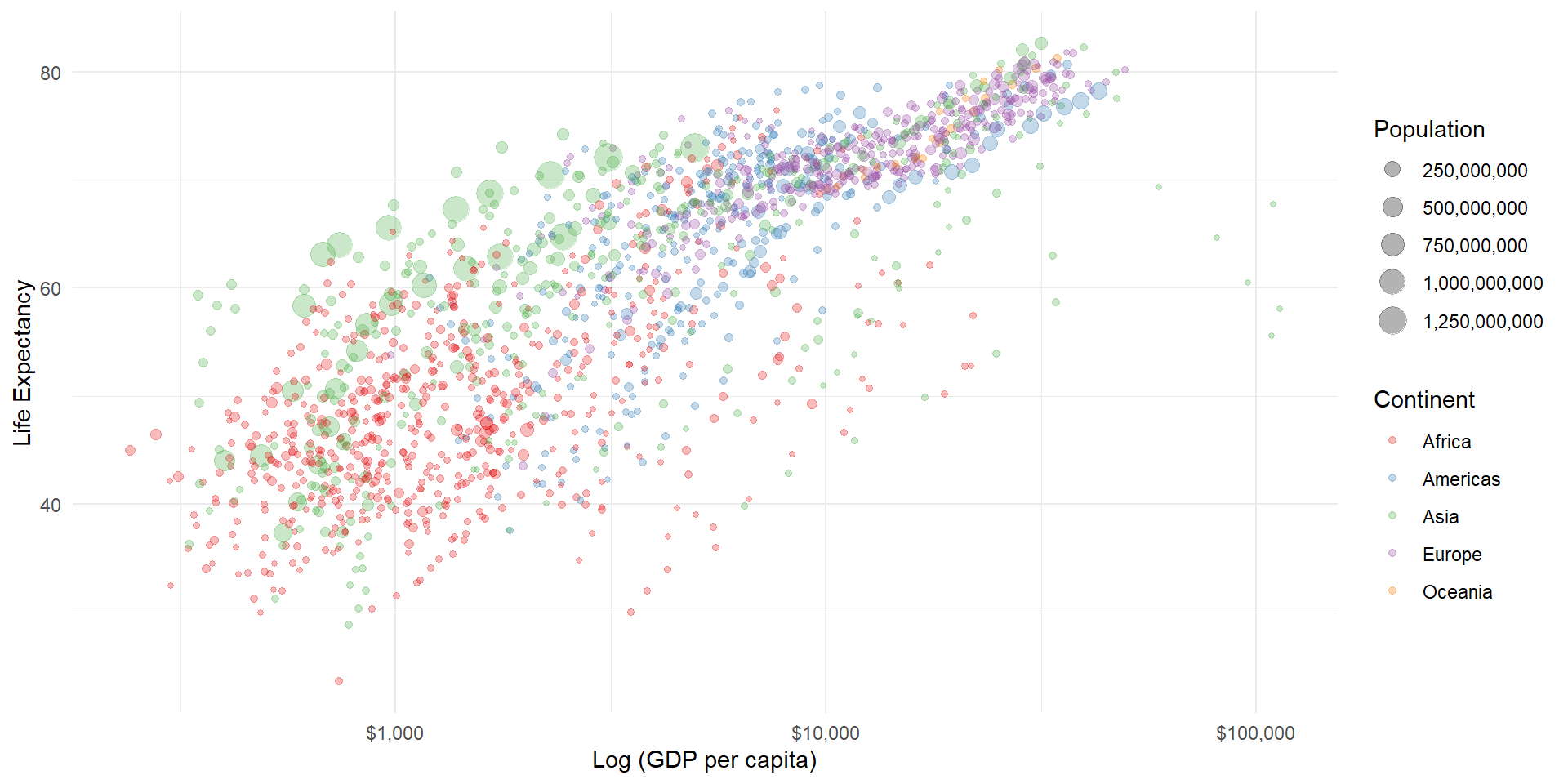
ggplot2: Gapminder
library(hrbrthemes)
ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp)) +
geom_point(aes(size = pop, col = continent), alpha = 0.3) +
scale_color_brewer(name = "Continent", palette = "Set1") +
scale_size(name = "Population", labels = scales::comma) +
scale_x_log10(labels = scales::dollar) +
theme_modern_rc() +
geom_point(aes(size = pop, col = continent), alpha = 0.2)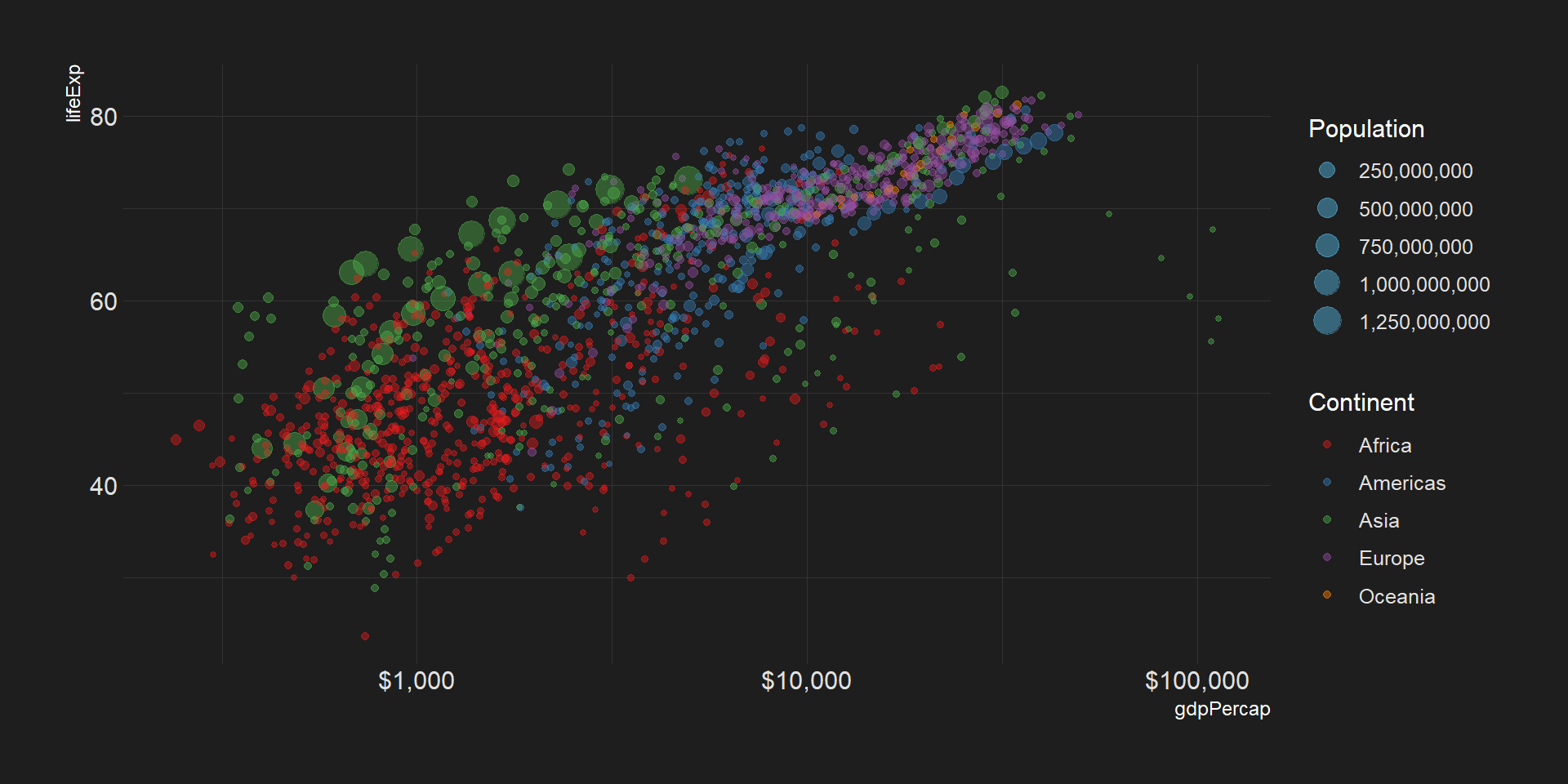
ggplot2: Gapminder
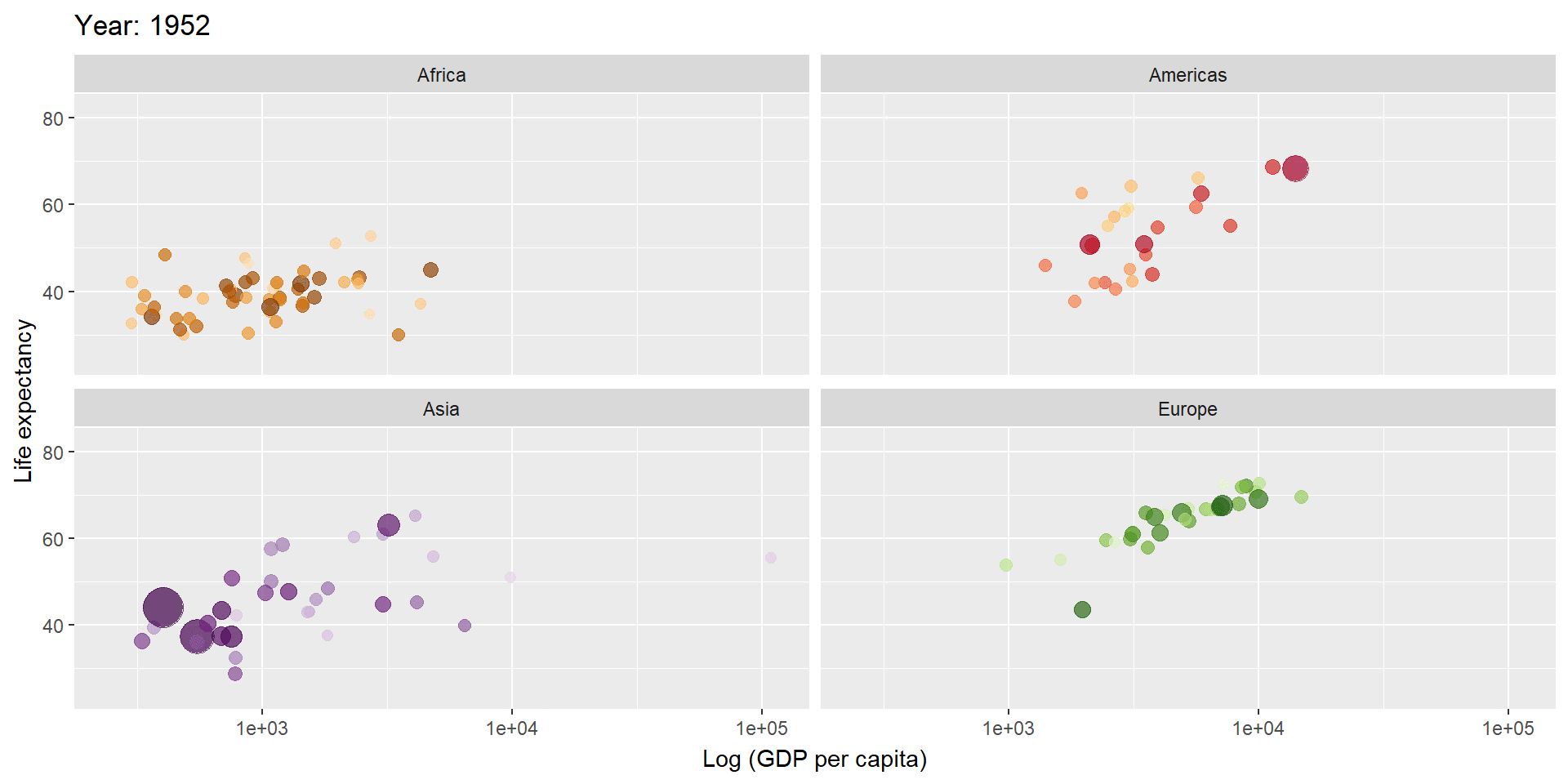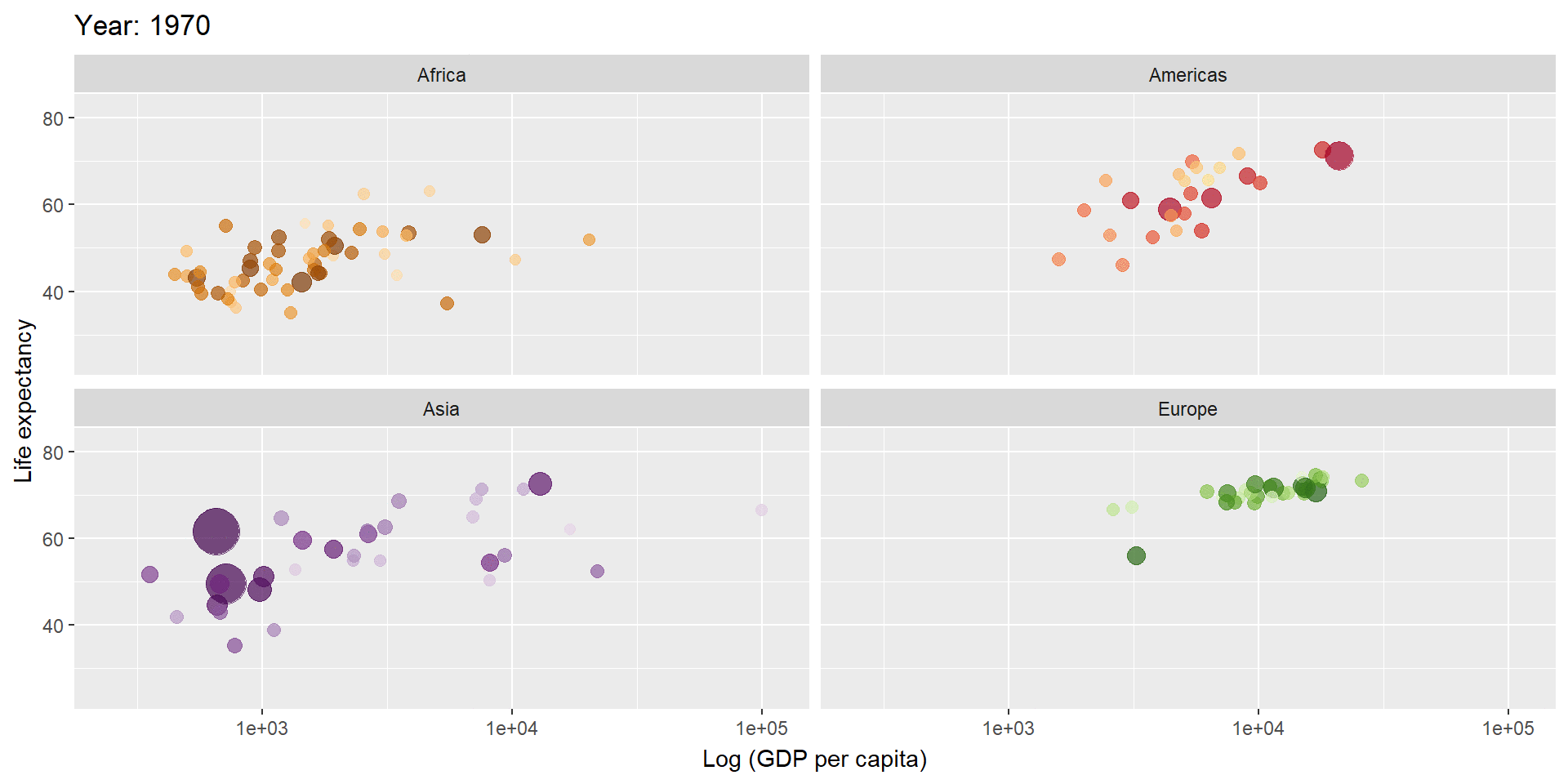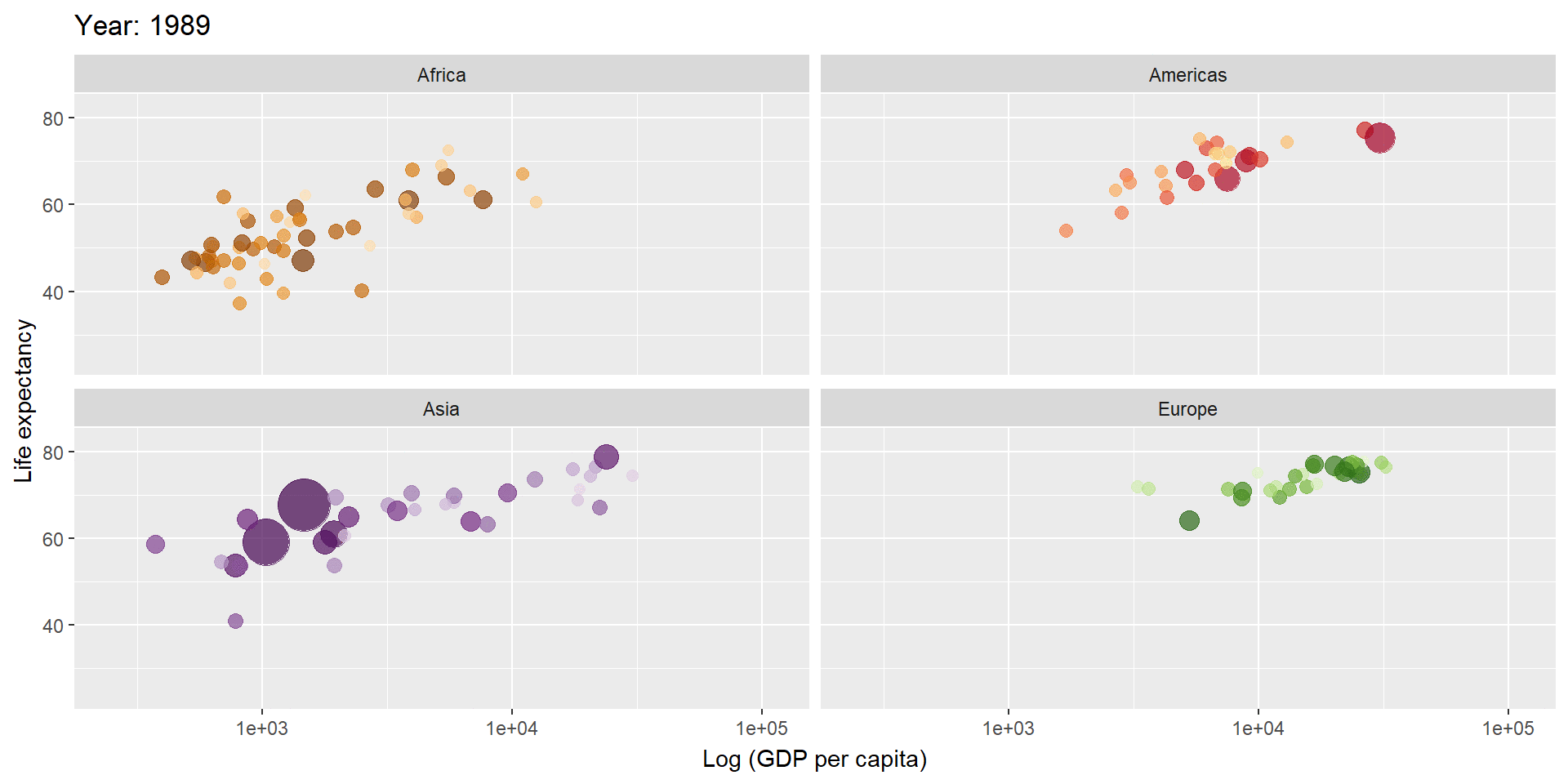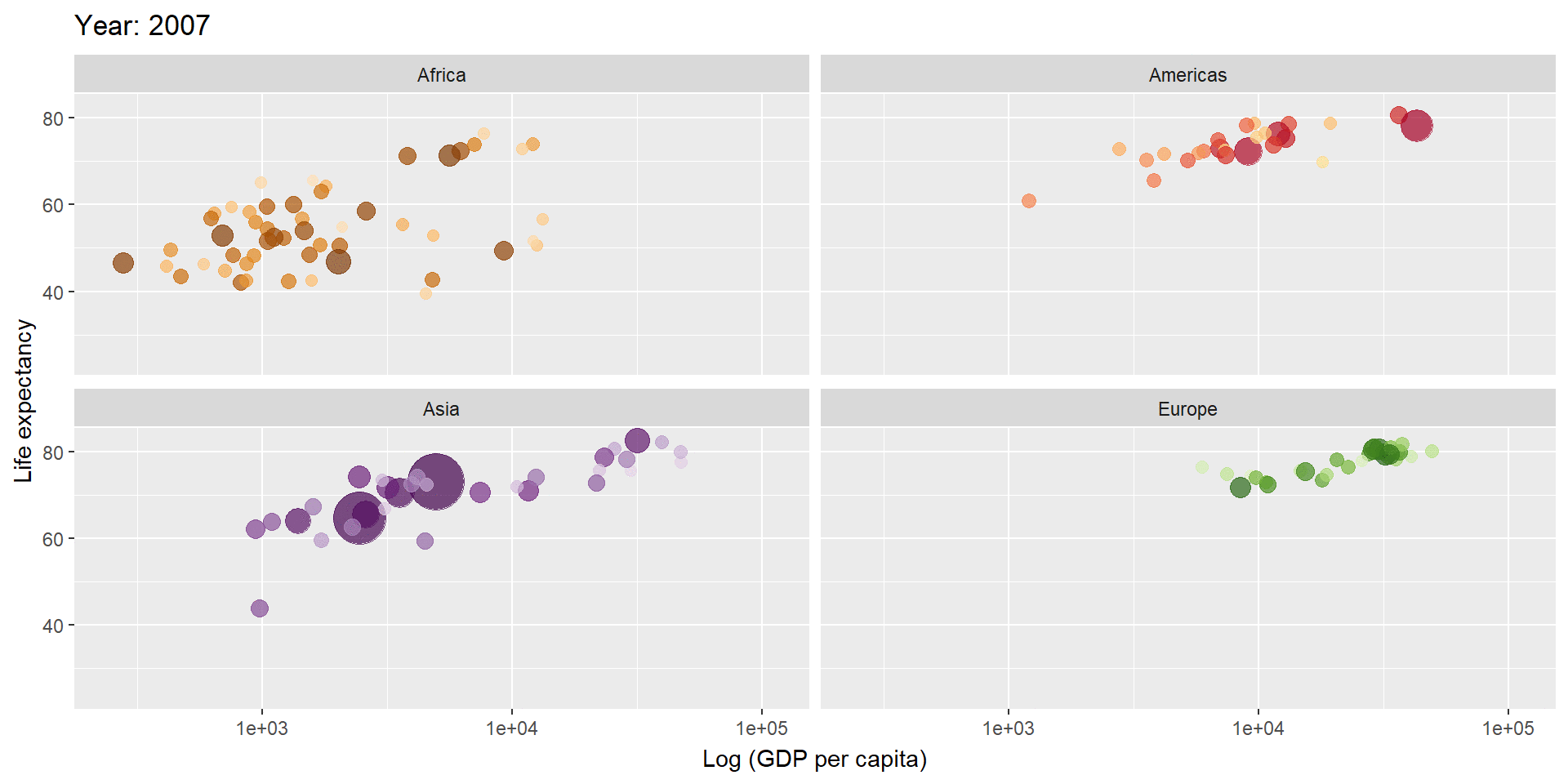
library(gganimate)
gapminder %>%
filter(continent != "Oceania") %>%
ggplot(aes(gdpPercap, lifeExp, size = pop, colour = country)) +
geom_point(alpha = 0.7, show.legend = FALSE) +
scale_colour_manual(values = country_colors) +
scale_size(range = c(2, 12)) +
scale_x_log10() +
facet_wrap(~continent) +
labs(title = 'Year: {frame_time}', x = 'Log (GDP per capita)', y = 'Life expectancy') +
transition_time(year) +
ease_aes('linear')