02 - Статистичне навчання: основи
Machine Learning
КНЕУ::ІІТЕ
2/21/23
Яка мета?
Яка мета?
Ми вже вивчали задачі прогнозування. Знову?
До цього моменту ми зосереджувалися на причинно-наслідкових ідентифікаціях/висновоках \(\beta\), тобто,
\[\color{#6A5ACD}{\text{Y}_{i}} = \text{X}_{i} \color{#e64173}{\beta} + u_i\]
тобто нам потрібна неупереджена (послідовна) і точна оцінка \(\color{#e64173}{\hat\beta}\).
Завдяки прогнозуванню ми зосереджуємося на точному оцінюванні результатів.
Іншими словами, як найкраще побудувати \(\color{#6A5ACD}{\hat{\text{Y}}_{i}}\)?
Яка мета?
Отже, ми хочемо «хороших» оцінок \(\hat y\) замість \(\hat\beta\).
Q: Чи не можемо ми просто використовувати ті самі методи (тобто, МНК)?
A: Все відносно. Наскільки добре ваша лінійна регресійна модель апроксимує базові дані? (І як ви плануєте вибрати свою модель?)
Нагадування Регресія найменших квадратів є чудовою лінійною оцінкою.
blah
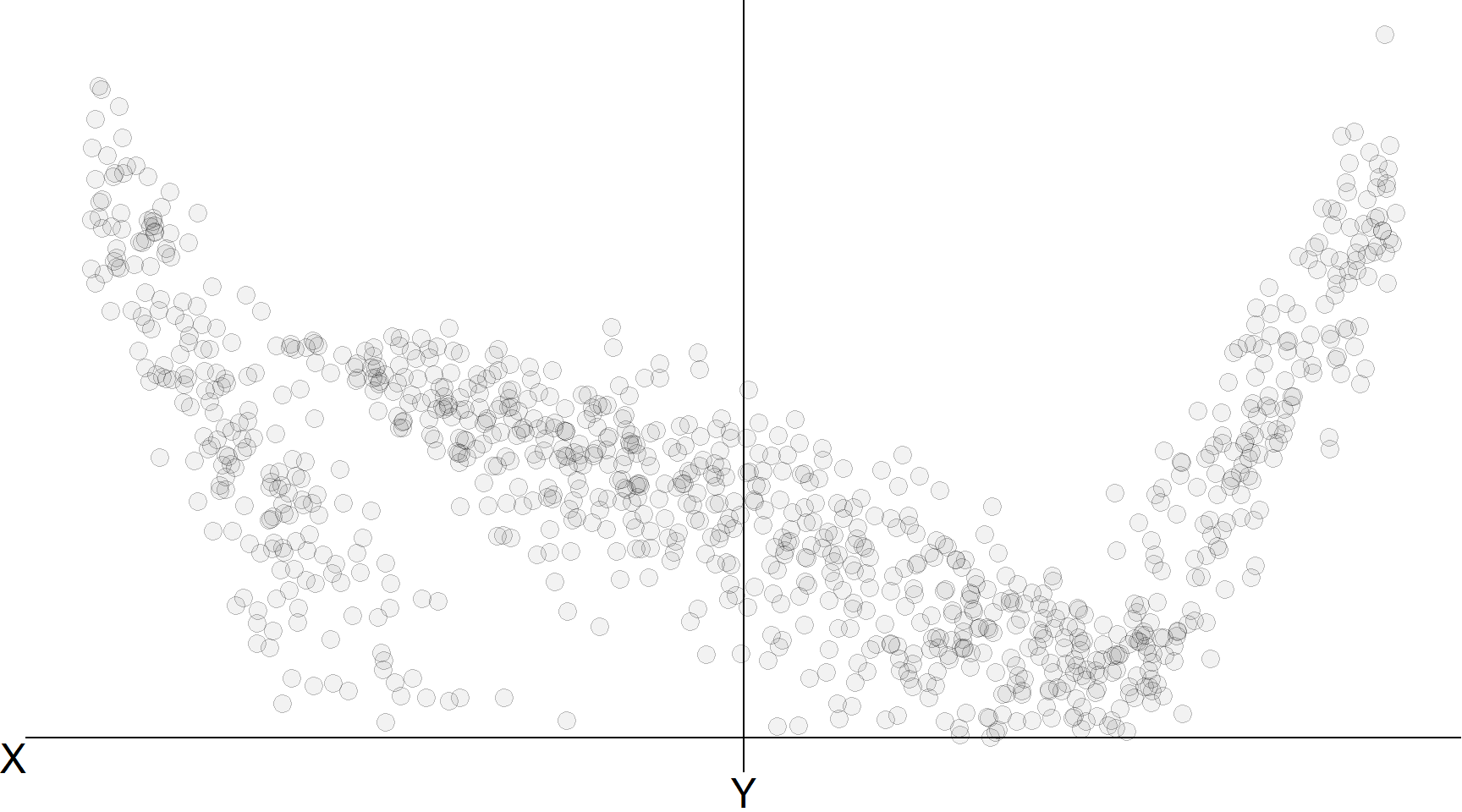
Лінійна регресія
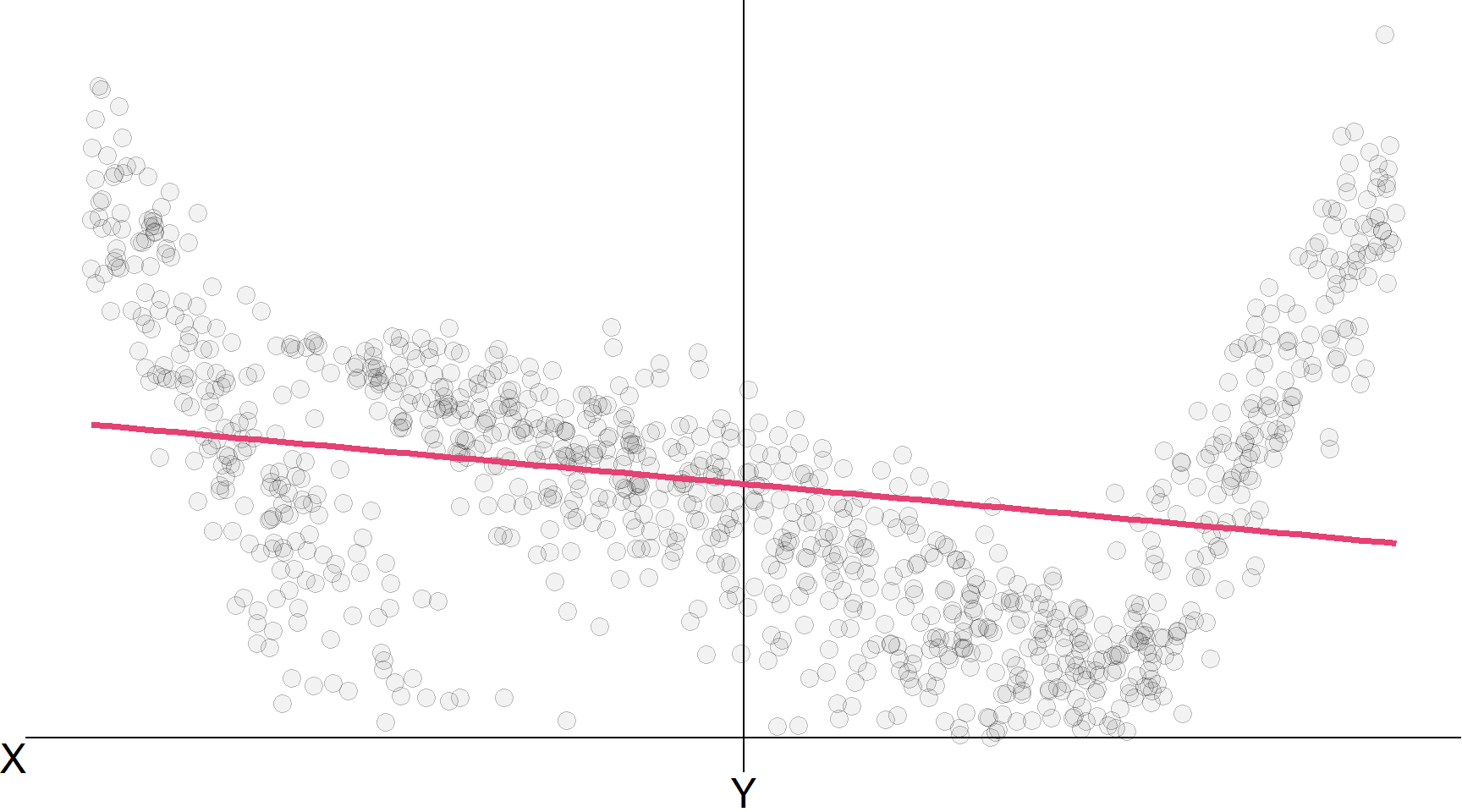
Лінійна регресія, лінійна регресія \(\color{#20B2AA}{\left( x^4 \right)}\)
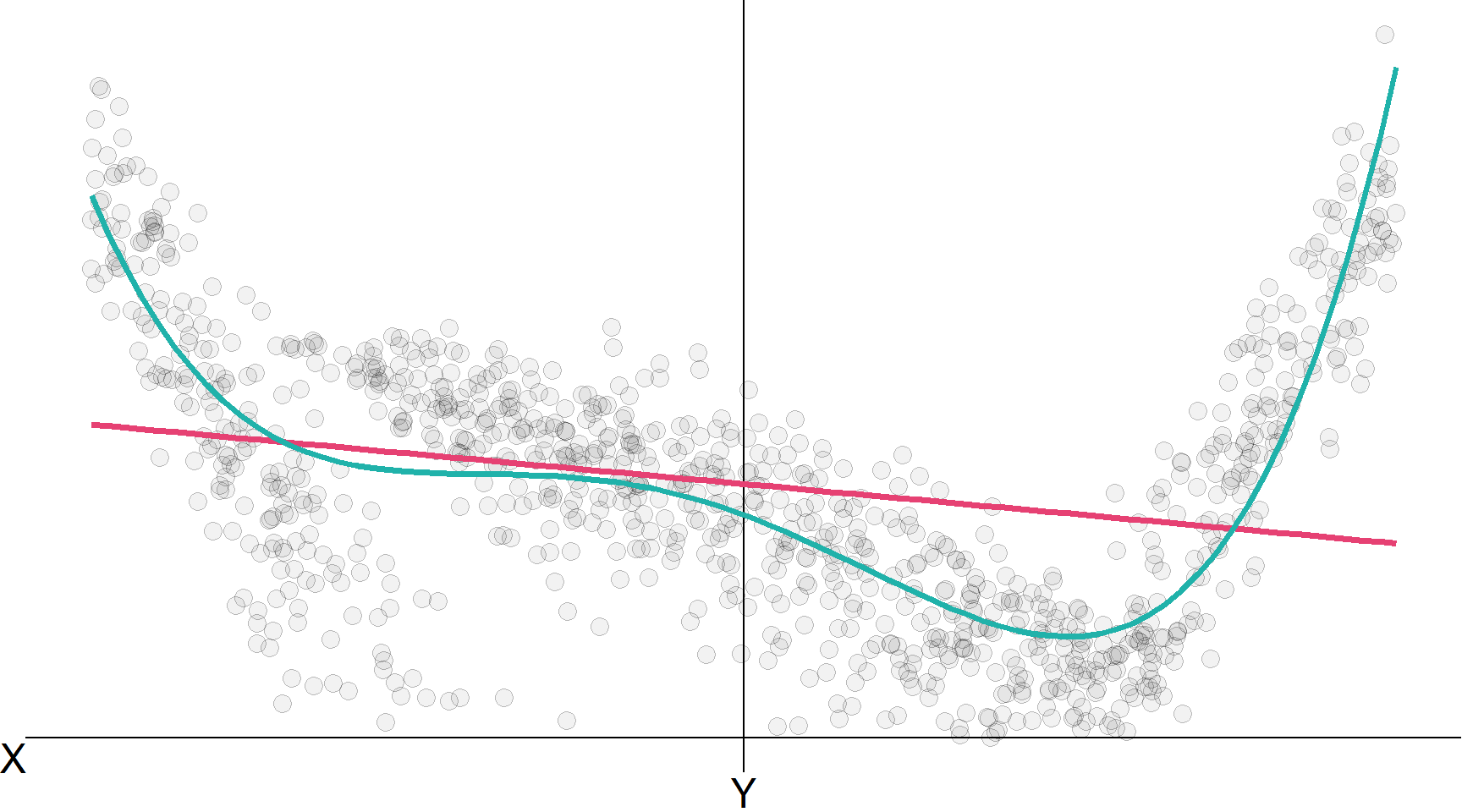
Лінійна регресія, лінійна регресія \(\color{#20B2AA}{\left( x^4 \right)}\), KNN (100)
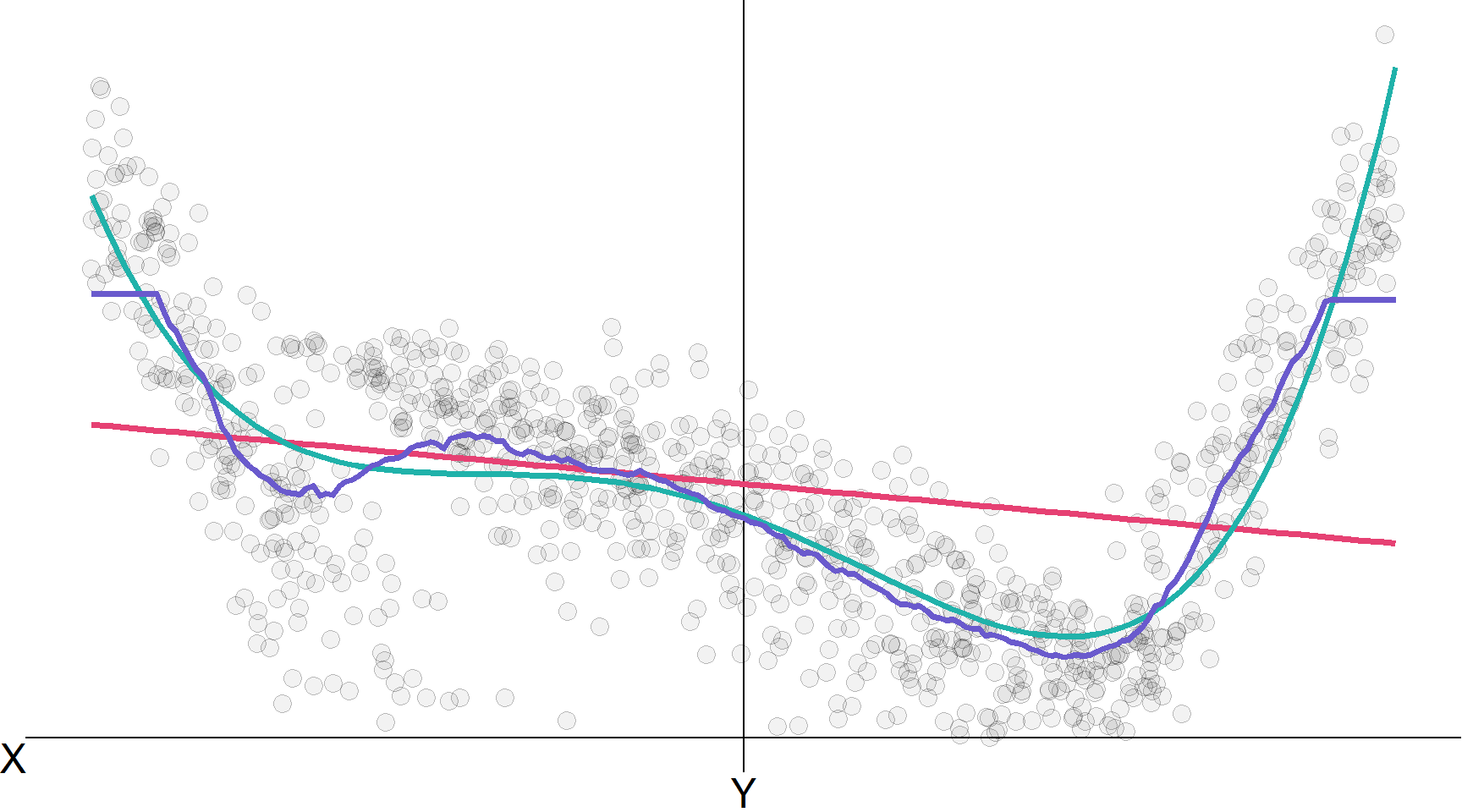
Лінійна регресія, лінійна регресія \(\color{#20B2AA}{\left( x^4 \right)}\), KNN (100), KNN (10)
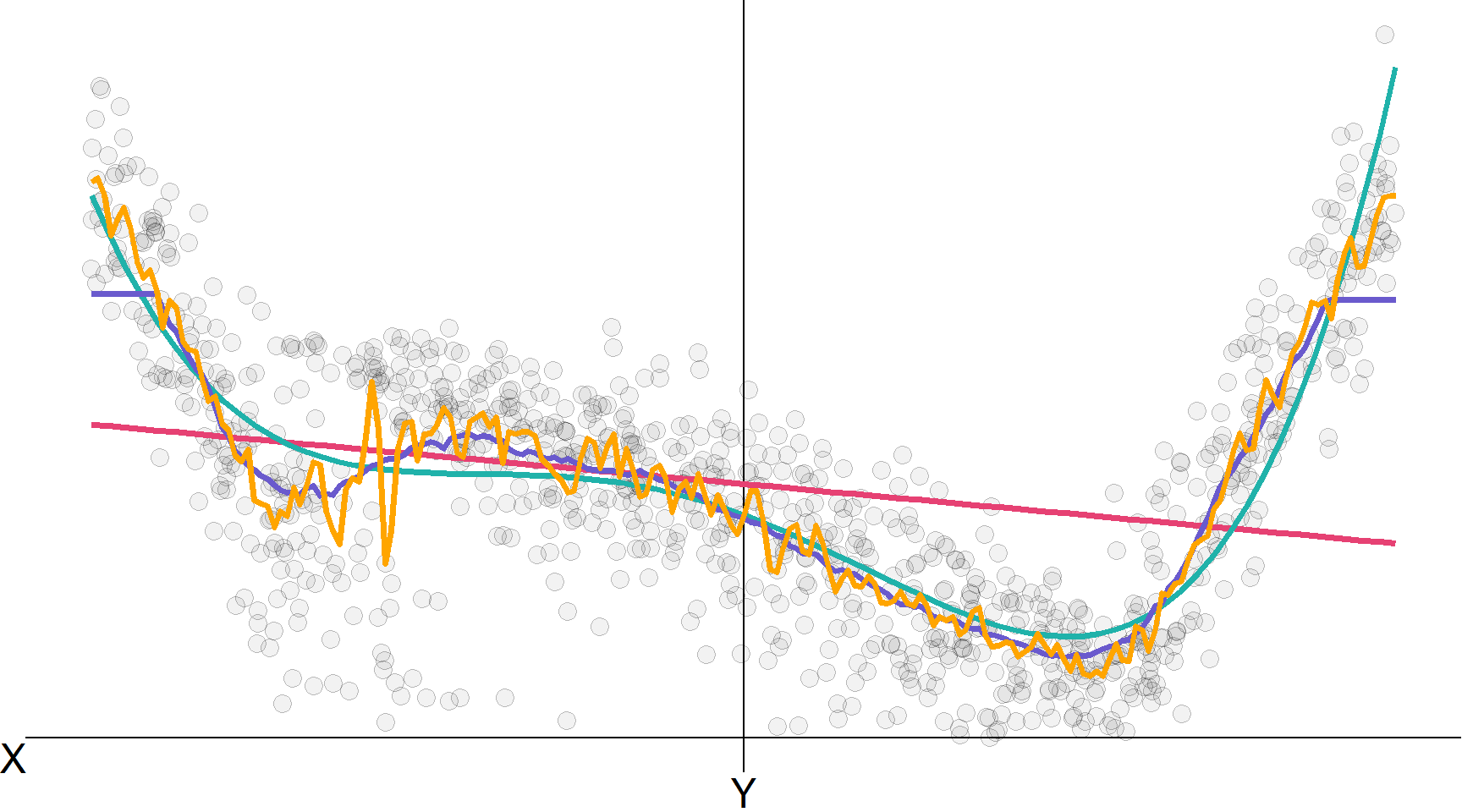
Лінійна регресія, лінійна регресія \(\color{#20B2AA}{\left( x^4 \right)}\), KNN (100), KNN (10), RF
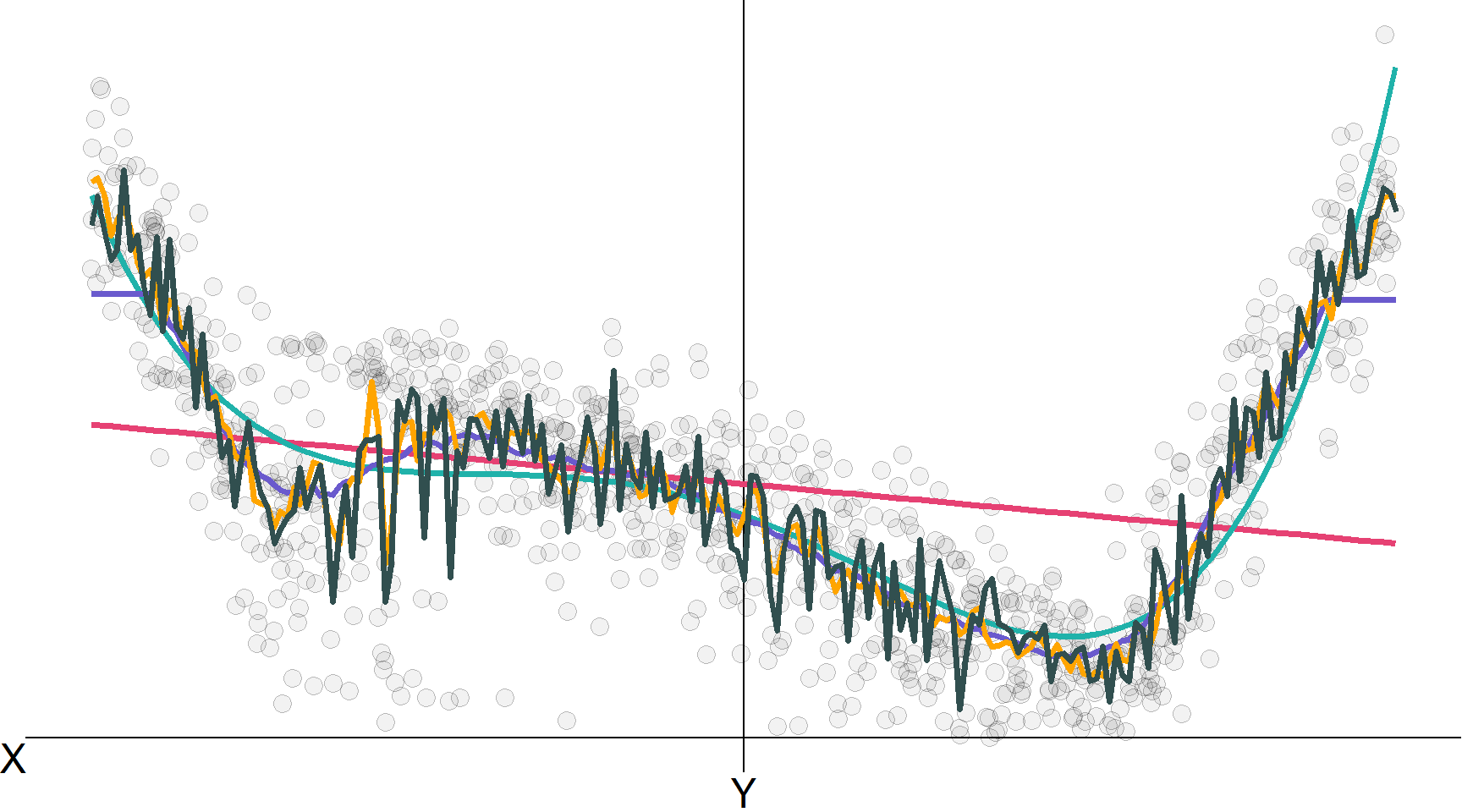
Примітка Цей приклад мав лише один предиктор…
Компроміси
Під час прогнозування ми постійно стикаємося з багатьма компромісами, наприклад,
гнучкість і параметрична структура (і інтерпретація).
ефективність на навчальній та тестовій вибірці.
дисперсія і зміщення
Ваш економічний досвід має підказувати, що у кожній ситуації нам потрібно знайти баланс між доходом та витратами для врахування цих компромісів.
Багато методів/алгоритмів машинного навчання (ML) створено для оптимізації з урахуванням цих компромісів, але практикуючий спеціаліст (ви) все одно має бути обережним.
Статистичне навчання
Статистичне навчання
Статистичне навчання — це набір інструментів, розроблений для розуміння/моделювання даних.
Приклади
- Регресійний аналіз кількісно визначає зв’язок між результатом і набором пояснювальних змінних — найбільш корисно в причинно-наслідкових умовах.
- дослідницький аналіз даних (EDA) — це попереднє, часто графічне, «дослідження» даних для розуміння рівнів, варіацій, недоліків тощо
- Дерева класифікації шукає пояснювальні змінні, розбиваючи за найбільш «передбачуваними» вимірами (випадкові ліси розширюють дерева).
- Дерева регресії вирішують задачі регресії за допомогою дерева рішень.
- Кластеризація K-середніх поділяє спостереження на K груп (кластерів) на основі набору змінних.
Коли це корисно?
В багатьох випадках.
Ми схильні розбивати статистичне навчання на два класи:
- Навчання з вчителем будує (“навчається”) статистичну модель для прогнозування вихіду \(\left( \color{#FFA500}{\mathbf{y}} \right)\) за допомогою набіру входів \(\left( \color{#6A5ACD}{\mathbf{x}_{1}, \dots \mathbf{x}_{p}} \right)\),
тобто, ми хочемо створити модель/функцію \(\color{#20B2AA}{f}\) \[\color{#FFA500}{\mathbf{y}} = \color{#20B2AA}{f}\!\left( \color{#6A5ACD}{\mathbf{x}_{1},\, \dots,\, \mathbf{x}_{p}} \right)\] яка точно описує \(\color{#FFA500}{\mathbf{y}}\) за певних значень \(\color{#6A5ACD}{\mathbf{x}_{1},\, \dots,\, x_{p }}\).
- Навчання без вчителя вивчає зв’язки та структуру, використовуючи лише входи \(\left( \color{#6A5ACD}{x_{1},\, \dots,\, x_{p} } \right)\) прогнозування - дозволяє даним «говорити за себе».
Напівконтрольоване навчання займає щось середнє між цими контрольованим і неконтрольованим навчанням — зазвичай застосовується до контрольованих завдань, коли помічені виходи є неповними.

Дані
Дані
\(\color{#e64173}{n}\) це кількість спостережень
\(\color{#6A5ACD}{p}\) це кількість змінних, доступних для прогнозів
\(\mathbf{X}\) — це наша \(\color{#e64173}{n}\times\color{#6A5ACD}{p}\) матриця предикторів
Інші назви features, вхідні дані, незалежні/пояснювальні змінні, …
\(x_{\color{#e64173}{i},\color{#6A5ACD}{j}}\) – це спостереження \(\color{#e64173}{i}\) (\(\color{#e64173}{1, \ldots,n}\)) по змінній \(\color{#6A5ACD}{j}\) (\(\color{#6A5ACD}{1,...,p}\))
\[ \begin{align} \mathbf{X} = \begin{bmatrix} x_{1,1} & x_{1,2} & \cdots & x_{1,\color{#6A5ACD}{p}} \\ x_{2,1} & x_{2,2} & \cdots & x_{2,\color{#6A5ACD}{p}} \\ \vdots & \vdots & \ddots & \vdots \\ x_{\color{#e64173}{n},1} & x_{\color{#e64173}{n},2} & \cdots & x_{\color{#e64173}{n},\color{#6A5ACD }{p}} \end{bmatrix} \end{align} \]
Розмірність \(\mathbf{X}\)
Тепер давайте розділимо нашу матрицю предикторів \(\mathbf{X}\) за двома вимірами.
Спостереження \(\color{#e64173}{i}\) — вектор довжиною \(\color{#6A5ACD}{p}\) \[ \begin{align} x_{\color{#e64173}{i}} = \begin{bmatrix} x_{\color{#e64173}{i},\color{#6A5ACD}{1}} \\ x_{\color{#e64173}{i},\color{#6A5ACD}{2}} \\ \vdots \\ x_{\color{#e64173}{i},\color{#6A5ACD}{p}} \end{bmatrix} \end{align} \]
Змінна \(\color{#6A5ACD}{j}\) — вектор довжиною \(\color{#6A5ACD}{p}\) \[ \begin{align} \mathbf{x}_{\color{#6A5ACD}{j}} = \begin{bmatrix} x_{\color{#e64173}{1},\color{#6A5ACD}{j}} \\ x_{\color{#e64173}{2},\color{#6A5ACD}{j}} \\ \vdots \\ x_{\color{#e64173}{n},\color{#6A5ACD}{j}} \end{bmatrix} \end{align} \]
В R:
dim(x_df)= \(\color{#e64173}{n}\) \(\color{#6A5ACD}{p}\)nrow(x_df)\(= \color{#e64173}{n}\);ncol(x_df)\(= \color{#6A5ACD}{p}\)x_df[1,]\(\left( \color{#e64173}{i = 1} \right)\);x_df[,1]\(\left( \color{#6A5ACD}{j = 1} \right)\)
Вихід
У навчанні з вчителем ми позначаємо нашу вихідну змінну як \(\color{#FFA500}{\mathbf{y}}\).
Синоніми вихід, результат, мітка, залежна змінна/відповідь, …
Міткою для нашого iго спостереження є \(\color{#FFA500}{y}_{\color{#e64173}{i}}\). Разом \(\color{#e64173}{n}\) розмірна форма:
\[ \begin{align} \color{#FFA500}{\mathbf{y}} = \begin{bmatrix} y_{\color{#e64173}{1}} \\ y_{\color{#e64173}{2}} \\ \vdots \\ y_{\color{#e64173}{n}} \end{bmatrix} \end{align} \]
і наш повний набір даних складається з \(\bigg\{ \left( x_{\color{#e64173}{1}},\color{#FFA500}{y}_{\color{#e64173}{1}} \right),\, \left( x_{\color{#e64173}{2}},\color{#FFA500}{y}_{\color{#e64173}{2}} \right),\, \ldots,\, \left( x_{\color{#e64173}{n}},\color{#FFA500}{y}_{\color{#e64173}{n}} \right) \bigg\}\).
Головна мета
Як визначено раніше, ми хочемо навчити модель для розуміння наших даних.
Візьміть наші (числові) мітки \(\color{#FFA500}{\mathbf{y}}\).
Уявіть, що існує функція \(\color{#20B2AA}{f}\), яка приймає вхідні \(\color{#6A5ACD}{\mathbf{X}} = \color{#6A5ACD} {\mathbf{x}_1}, \dots, \color{#6A5ACD}{\mathbf{x}_p}\)
і складіть їх, а також додайте випадкову помилку з середнім в нулі \(\color {#e64173}{\varepsilon}\).
\[\color{#FFA500}{\mathbf{y}} = \color{#20B2AA}{f} \! \left( \color{#6A5ACD}{\mathbf{X}} \right) + \color{#e64173}{\varepsilon}\]
Q: Що таке \(\color{#20B2AA}{f}\)?
A: ISL: \(\color{#20B2AA}{f}\) являє собою систематичну інформацію, яку \(\color{#6A5ACD}{\mathbf{X}}\) знає про \(\color{#FFA500}{\mathbf{y}}\).
Наша невідома \(f\)
\[\color{#FFA500}{\mathbf{y}} = \color{#20B2AA}{f} \! \left( \color{#6A5ACD}{\mathbf{X}} \right) + \color{#e64173}{\varepsilon}\]
Q: \(\color{#20B2AA}{f}\) невідомий (як і \(\color{#e64173}{\varepsilon}\)). Що нам робити?
A: Використовуйте дані спостереження, щоб дізнатися/оцінити \(\color{#20B2AA}{f}(\cdot)\), тобто, побудувати \(\widehat{\color{#20B2AA}{f}}\)
Q Гаразд. Але як?
A Як оцінити \(\color{#20B2AA}{f}\)? — це один із способів сформулювати всі питання, які лежать в основі статистичного навчання — вибір моделі, перехресна перевірка, оцінка , і т.д.
Всі техніки, алгоритми, інструменти статистичного навчання спрямовані на точне відновлення \(\color{#20B2AA}{f}\) на основі цілей/обмежень налаштувань.
Вам доведеться почекати на реальні/конкретні відповіді…
Навчання \(\hat{f}\)
Є дві основні причини, чому ми хочемо дізнатися про \(\color{#20B2AA}{f}\)
- Інтерпретація Як зміни у \(\color{#6A5ACD}{\mathbf{X}}\) впливають на \(\color{#FFA500}{\mathbf{y}}\)? Згадуйте курс економетрики.
- Прогнозування Передбачити \(\color{#FFA500}{\mathbf{y}}\), використовуючи нашу оцінку \(\color{#20B2AA}{f}\), тобто, \[\hat{\color{#FFA500}{\mathbf{y}}} = \hat{\color{#20B2AA}{f}}\!(\color{#6A5ACD}{\mathbf{X}}) \]
Помилки прогнозів
Як зазвичай буває в житті, ви будете робити помилки, прогнозуючи \(\color{#FFA500}{\mathbf{y}}\).
Точність \(\hat{\color{#FFA500}{\mathbf{y}}}\) залежить від двох помилок:
- Reducible error Помилка через те, що \(\hat{\color{#20B2AA}{f}}\) неточно оцінює \(\color{#20B2AA}{f}\).
- Irreducible error Помилка, яка знаходиться за межами моделі \(\color{#20B2AA}{f}\).
Помилки прогнозів
Чому ми застрягли з Irreducible error.
\[ \begin{aligned} \mathop{E}\left[ \left\{ \color{#FFA500}{\mathbf{y}} - \hat{\color{#FFA500}{\mathbf{y}}} \right\}^2 \right] &= \mathop{E}\left[ \left\{ \color{#20B2AA}{f}(\color{#6A5ACD}{\mathbf{X}}) + \color{#e64173}{\varepsilon} - \hat{\color{#20B2AA}{f}}(\color{#6A5ACD}{\mathbf{X}}) \right\}^2 \right] \\ &= \underbrace{\left[ \color{#20B2AA}{f}(\color{#6A5ACD}{\mathbf{X}}) - \hat{\color{#20B2AA}{f}}(\color{#6A5ACD}{\mathbf{X}}) \right]^2}_{\text{Reducible}} + \underbrace{\mathop{\text{Var}} \left( \color{#e64173}{\varepsilon} \right)}_{\text{Irreducible}} \end{aligned} \]
Менше математики:
- Якщо \(\color{#e64173}{\varepsilon}\) існує, то \(\color{#6A5ACD}{\mathbf{X}}\) не може ідеально пояснити \(\color{#FFA500}{\mathbf{y}}\) .
– Отже, навіть якщо \(\hat{\color{#20B2AA}{f}} = \color{#20B2AA}{f}\), ми все одно маємо irreducible error.
Таким чином, щоб сформувати наш найкращі предиктори, ми будемо мінімізувати reducible error.
Як обрати \(\hat{f}\)?
Отримавши inputs \(\left(\color{#6A5ACD}{\mathbf{X}} \right)\) і output \(\left( \color{#FFA500}{\mathbf{ y}} \right)\), вам все одно потрібно вирішити, наскільки параметричним має бути ваш \(\hat{\color{#20B2AA}{f}}\).
Параметричні методи припускають, що функція зазвичай складається з двох кроків
Виберіть функціональну форму (фігуру) для представлення \(\color{#20B2AA}{f}\)
Навчіть вибрану модель на даних \(\color{#FFA500}{\mathbf{y}}\) і \(\color{#6A5ACD}{\mathbf{X}}\).
Непараметричні методи уникають явних припущень щодо форми \(\color{#20B2AA}{f}\). Спробуйте підігнати дані, одночасно намагаючись уникати перенавчання.
Як обрати \(\hat{f}\)?
Параметричні припущення методів мають компроміси.
Параметричні методи: + Простіше оцінити та інтерпретувати. - Якщо обрана форма залежності погана, продуктивність моделі погіршиться.
Непараметричні методи: + Менше припущень. Більше гнучкості. - Нижча інтерпретація. Схильність до перенавчання. Потребує багато даних.
Приклад
Почнемо з досить дивної, нелінійної функції.
Нелінійний \(f(\mathbf{X})\), який ми хочемо оцінити.
Вибірка: \(n=70\) випадково взятих спостережень для \(\mathbf{y} = f(\mathbf{x}_1,\, \mathbf{x}_2) + \varepsilon\)
Розрахована модель лінійної регресії: \(\hat{\mathbf{y}} = \hat\beta_0 + \hat\beta_1 \mathbf{x}_1 + \hat\beta_2 \mathbf{x}_2 + \hat\beta_3 \mathbf{x}_1 \mathbf{x}_2\)
Помилка моделі з нашої моделі лінійної регресії
k-найближчих сусідів (kNN) з k=5 (непараметричний метод)
k-найближчих сусідів (kNN) з k=10 (зверніть увагу на підвищену гладкість)
k-найближчих сусідів (kNN) з k=1 (зверніть увагу на зменшену гладкість)
Помилки моделі з нашої підігнаної моделі kNN (k=5).
Помилки моделі з нашої підігнаної моделі kNN (k=10).
Помилки моделі з нашої підігнаної моделі kNN (k=1).
Помилки моделі з нашої підігнаної лінійної моделі.
Питання
Який із методів був найбільш гнучким? Негнучкий?
Чому, на вашу думку, kNN з k=1 мала таку низьку помилку передбачення?
Як ми можемо (краще) оцінити ефективність моделі/прогнозування?
Чому ми іноді хочемо вибрати менш гнучку модель?
Оцінювання ефективності
Ймовірно, ви не здивуєтеся, дізнавшись, що в статистичному навчанні не існує універсального рішення.
Q: Як ми вибираємо між конкуруючими моделями?
A: Ми за кілька кроків, але перш ніж щось робити, нам потрібен спосіб визначити ефективність моделі.
Тонкощі
Визначення ефективності насправді може бути досить складним…
Налаштування регресії, 1 Чому ви віддаєте перевагу? 1. Багато маленьких помилок і кілька дійсно великих помилок. 1. Середні помилки для всіх.
Налаштування регресії, 2 Чи помилка в 1 одиницю (наприклад, 1000 доларів США) однаково погана?
Тонкощі
Визначення ефективності насправді може бути досить складним…
Налаштування класифікації, 1 Що гірше? 1. Хибно позитивний (наприклад, неправильне діагностування раку) 1. Хибно негативний (наприклад, відсутність раку)
Налаштування класифікації, 2 Що важливіше? 1. Справді позитивний (наприклад, правильний діагноз раку) 1. Справді негативний (наприклад, правильний діагноз «немає раку»)
MSE
Середня квадратична помилка (MSE) є найпоширенішим способом вимірювання ефективності моделі в задачах регресії.
\[\text{MSE} = \dfrac{1}{n} \sum_{i=1}^n \left[ \color{#FFA500}{y}_i - \hat{\color{#20B2AA}{f }}(\color{#6A5ACD}{x}_i) \right]^2\]
Пам’ятка: \(\color{#FFA500}{y}_i - \hat{\color{#20B2AA}{f}}(\color{#6A5ACD}{x}_i) = \color{#FFA500} {y}_i - \hat{\color{#FFA500}{y}}_i\) – це помилка нашого передбачення.
Дві замітки про MSE:
- MSE буде (відносно) дуже малим, коли помилка прогнозів майже дорівнють нулю.
- MSE штрафує великі помилки більше, ніж маленькі помилки (через використання квадрату).
Навчальна та тестова вибірка
Низькі значення MSE (висока точність) на даних, за допомогою яких навчена модель, насправді не завжди є показником точності моделі — можливо, модель просто “завчила” наші дані.
Що ми хочемо: Наскільки добре модель працюэ на даних, які вона ніколи не бачила?
Це вводить важливу відмінність:
- Навчальна вибірка: спостереження \((\color{#FFA500}{y}_i,\color{#e64173}{x}_i)\), використані для навчання нашої моделі $ $.
- Тестова вибірка: спостереження \((\color{#FFA500}{y}_0,\color{#e64173}{x}_0)\), які наша модель ще має побачити, і які ми можемо використовувати для оцінки ефективності \(\hat{\color{#20B2AA}{f}}\).
Справжня ціль: низькі значення MSE на тестовій вибірці (а не навчальній).