01 - Становлення та розвиток науки про дані
Вступ у Data Science
КНЕУ::ІІТЕ
Що таке наука про дані?
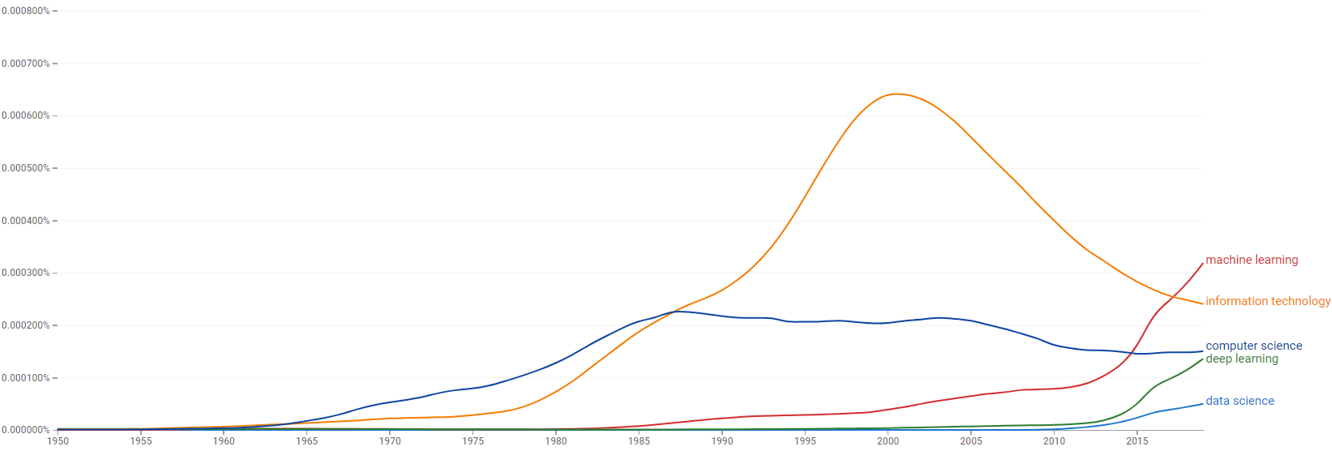
Google Ngram
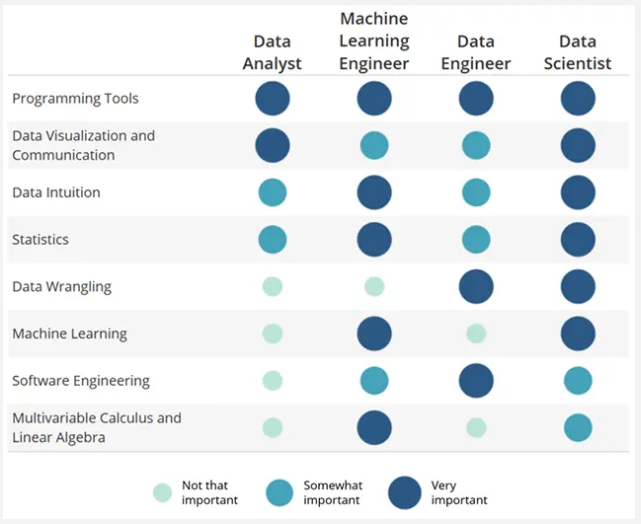
НАВИЧКИ ДЛЯ НАУКИ ПРО ДАНІ
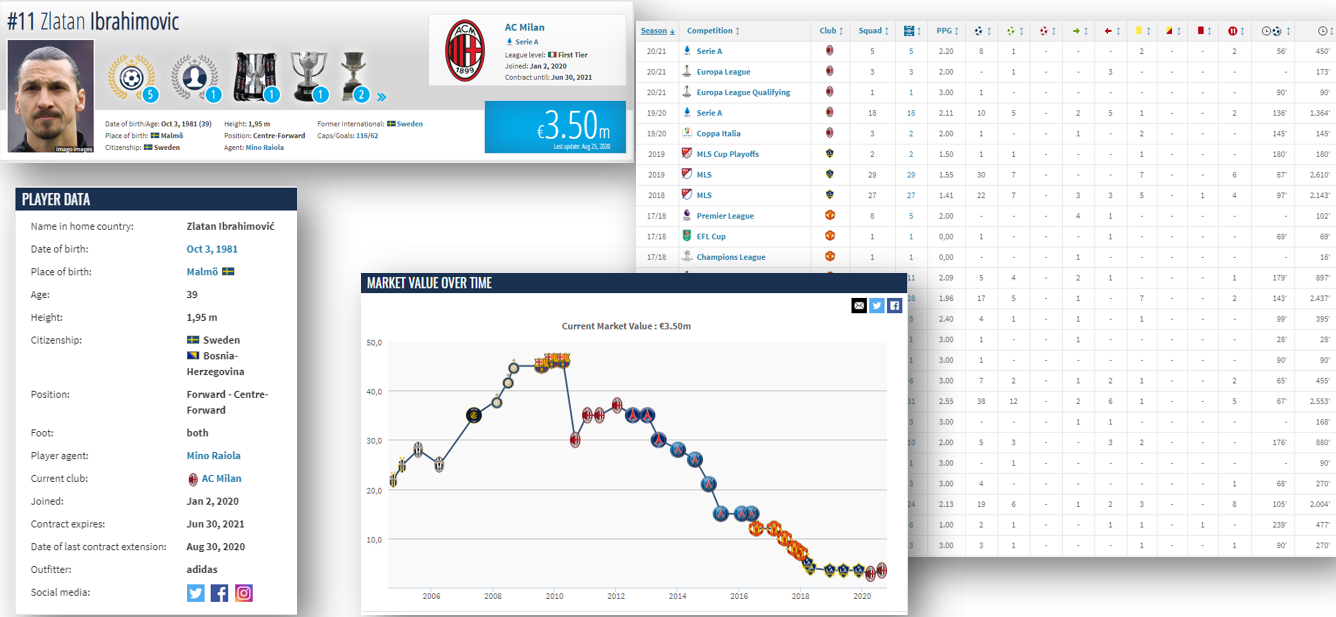
Transfermarkt
IMDb: база даних фільмів
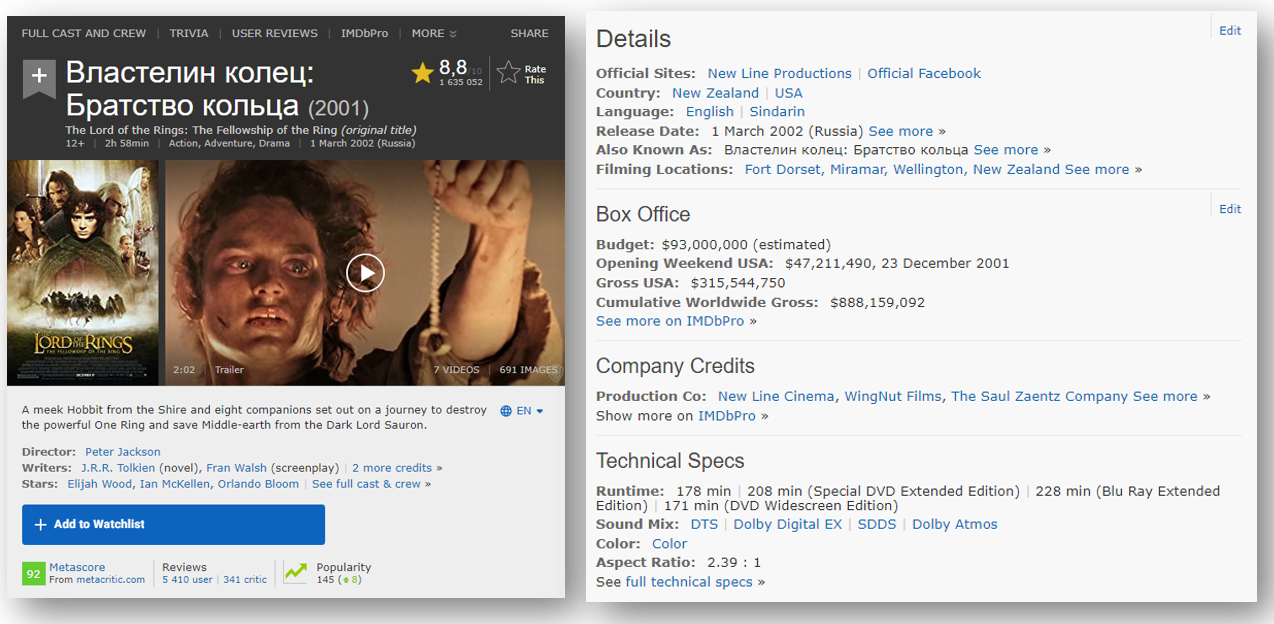
IMDb: база даних акторів
N-ГРАММИ GOOGLE
Щорічні часові ряди кожного популярного слова або словосполучення від 1 до 5 слів, що зустрічається у відсканованих книгах
«Популярне» означає, що зустрічається і більш ніж 40 книгах
Охоплює приблизно 15-20% усіх виданих книг
N-ГРАММИ GOOGLE
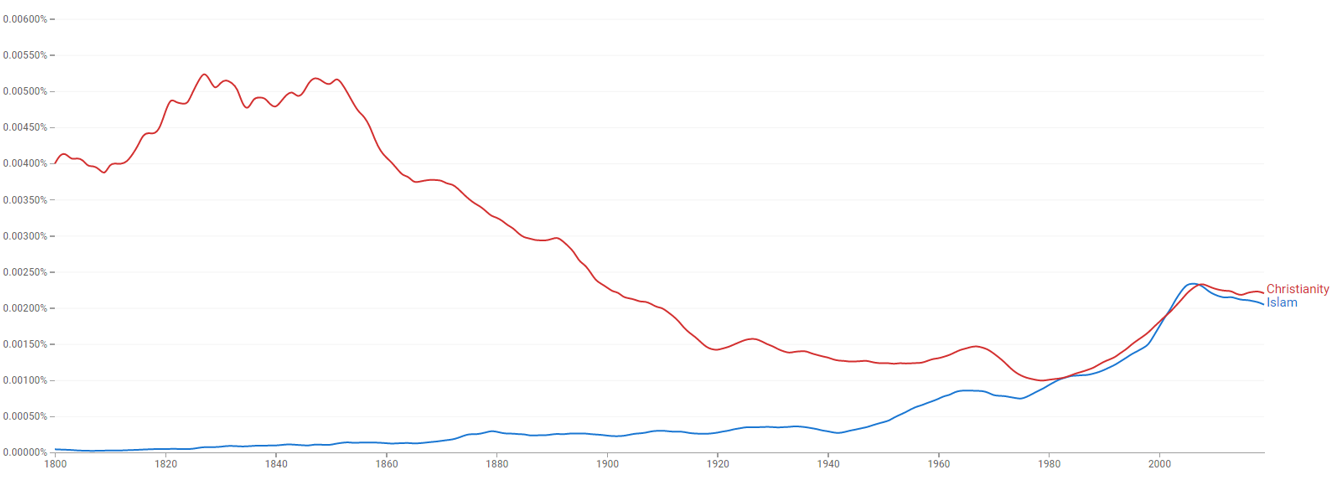
N-ГРАММИ GOOGLE
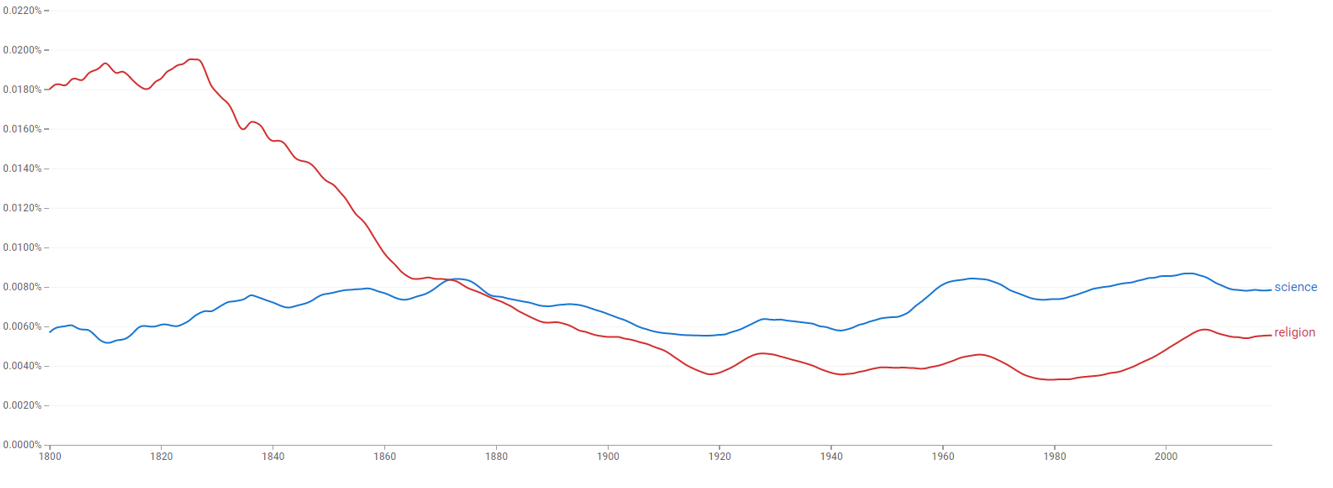
N-ГРАММИ GOOGLE
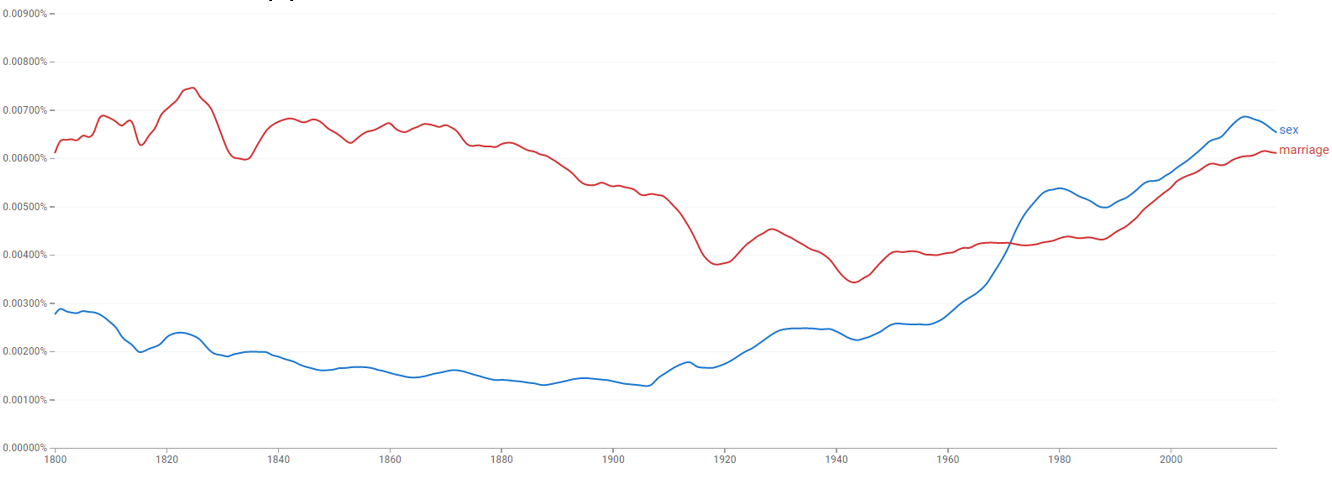
ТАКСІ NY
Дані про водія/власника, місце посадки/висадки та вартість проїздки.
Дані отримані в Нью-Йорку на запит згідно Закону про свободу інформації

ВІЗУАЛІЗАЦІЯ ТАКСІ NY

ТЕРМІНИ НАВКОЛО DATA SCIENCE
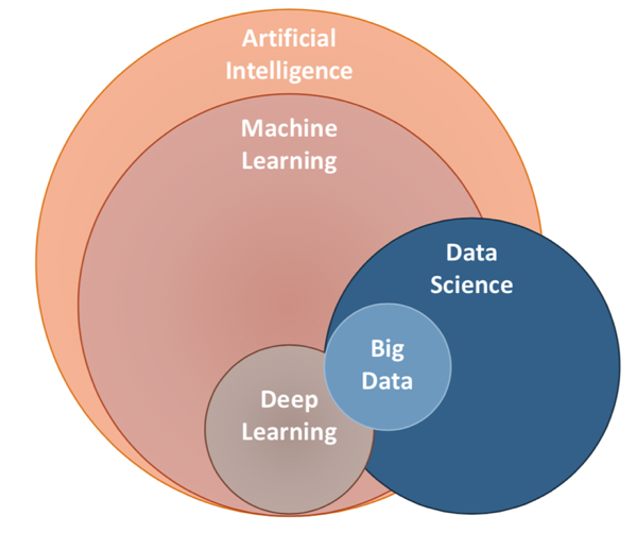
ТЕРМІНИ НАВКОЛО DATA SCIENCE
Штучний інтелект (Artificial Intelligence) - область, присвячена створенню інтелектуальних систем, що працюють і діють як люди. Її виникнення пов’язане з появою машин Алана Тьюринга в 1936 році. Незважаючи на довгу історію розвитку, штучний інтелект поки що не здатний повністю замінити людину в більшості областей. Але є приклади, що демонструють позитивну тенденцію розвитку цього напрямку.
ТЕРМІНИ НАВКОЛО DATA SCIENCE
Машинне навчання (Machine learning) - інструмент для отримання знань з даних. Моделі ML навчаються на даних самостійно або поетапно: навчання з учителем на підготовлених людиною даних і без вчителя - робота зі стихійними, зашумленими даними.
Класичне навчання
1. Класифікація. Намагання поставити мітку на елемент з дискретного набору можливостей: передбачення переможця спортивного змагання (команда А або команда Б) або вибір жанру деякого фільму (комедія, драма, бойовик тощо).
Ціна акції завтра буде вищою чи нижчою за сьогоднішню?
Чи є має сенс продавати страховий поліс даному клієнту?
Яка група клієнтів зреагує на рекламну пропозицію?
Класичне навчання
2. Регресія. Задача передбачення деякого числового значення. Прогноз ваги людини, кількість клієнтів на добу тощо.
Що буде з ціною акції завтра?
Як довго людина буде жити?
Як часто клієнт користується послугою?
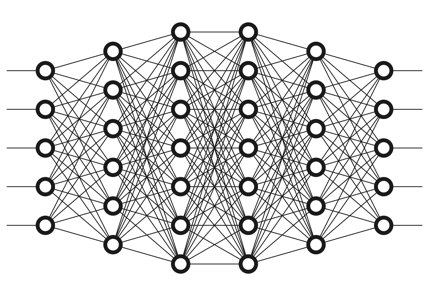
Deep learning
Глибоке навчання (Deep learning)- створення багатошарових нейронних мереж в областях, де потрібно більш просунутий або швидкий аналіз, і традиційне машинне навчання не справляється. «Глибина» забезпечується деякою кількістю прихованих шарів нейронів в мережі, які проводять математичні обчислення.
Big Data
Великі дані (Big Data) - робота з великим об’ємом часто неструктурованих даних. Специфіка сфери - це інструменти і системи, здатні витримувати високі навантаження.

BIG DATA
Проблеми з BIG DATA:
Ріст об’єму даних уповільнює їх аналіз
Великі набори даних складніше візуалізовувати
Прості моделі не потребують великих даних
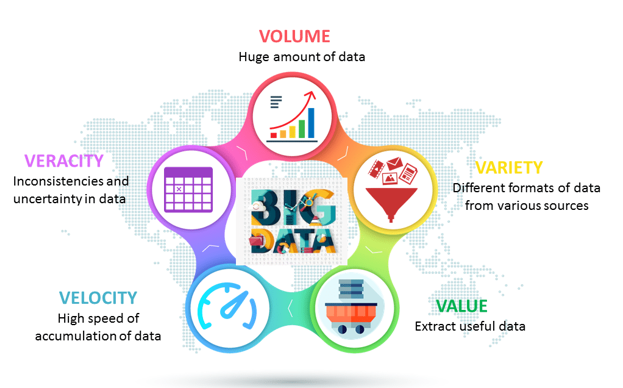
BIG DATA: 5V
Для того щоб масив інформації отримав приставку «BIG», він повинен мати наступні властивості:
Об’єм (volume)
Різноманітність (variety)
Цінність (value)
Швидкість (velocity)
Достовірність (veracity)
ВЛАСТИВОСТІ ДАНИХ
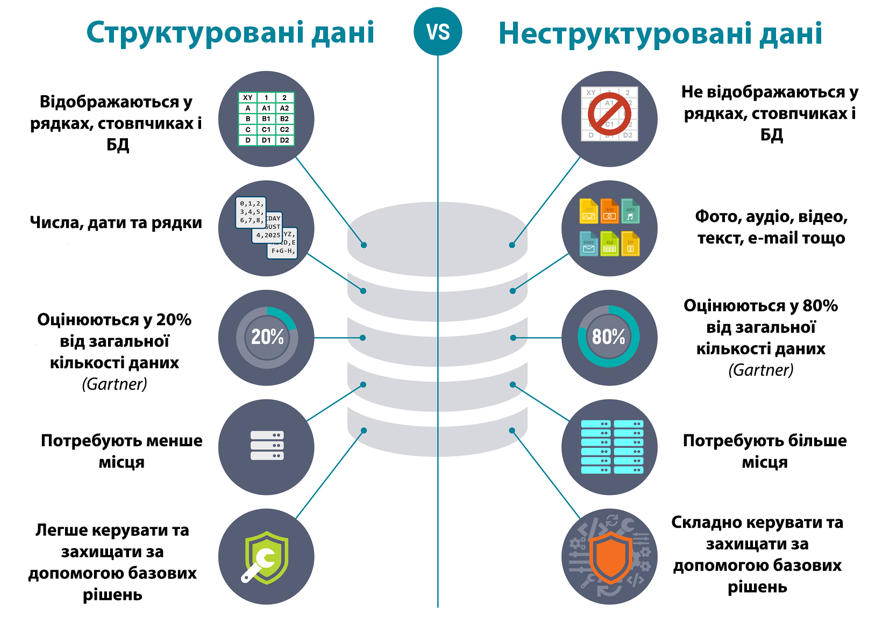
Структуровані
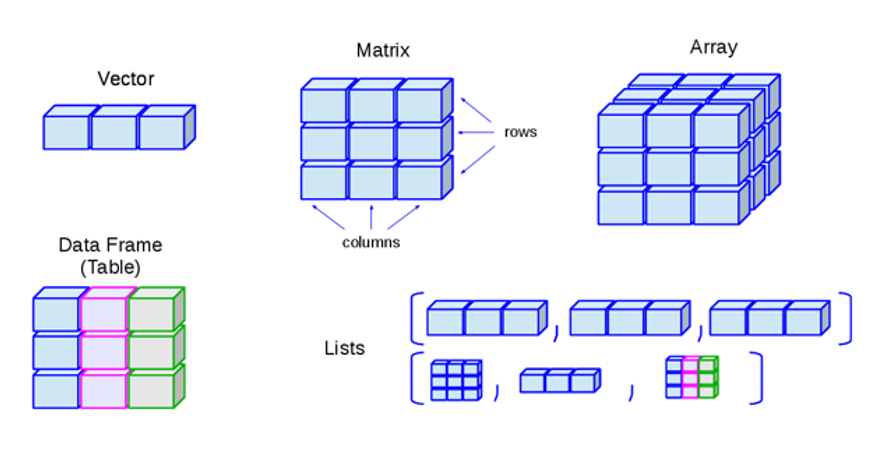
ВЛАСТИВОСТІ ДАНИХ
Неструктуровані
ВЛАСТИВОСТІ ДАНИХ
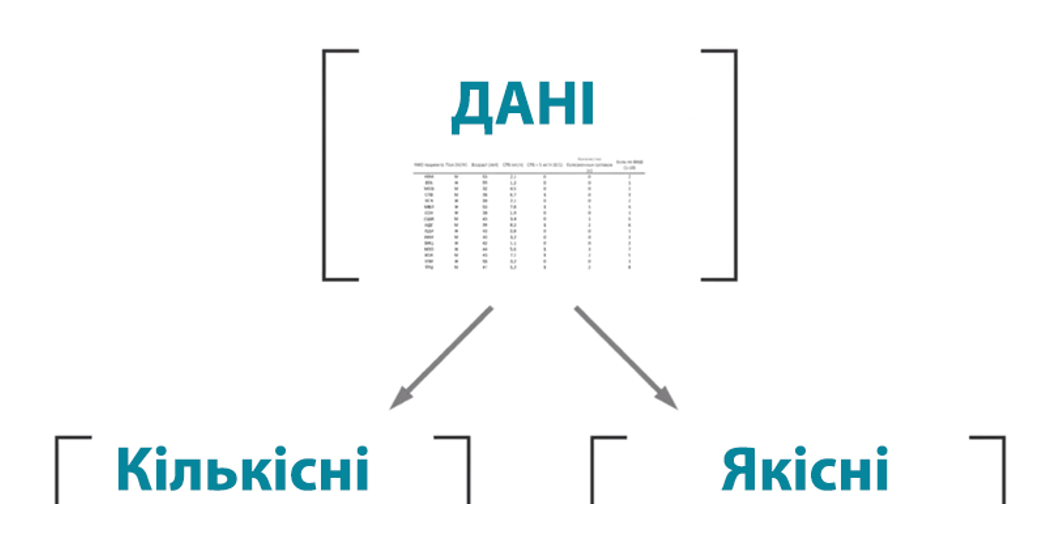
ТИПИ ДАНИХ
ТИПИ ДАНИХ
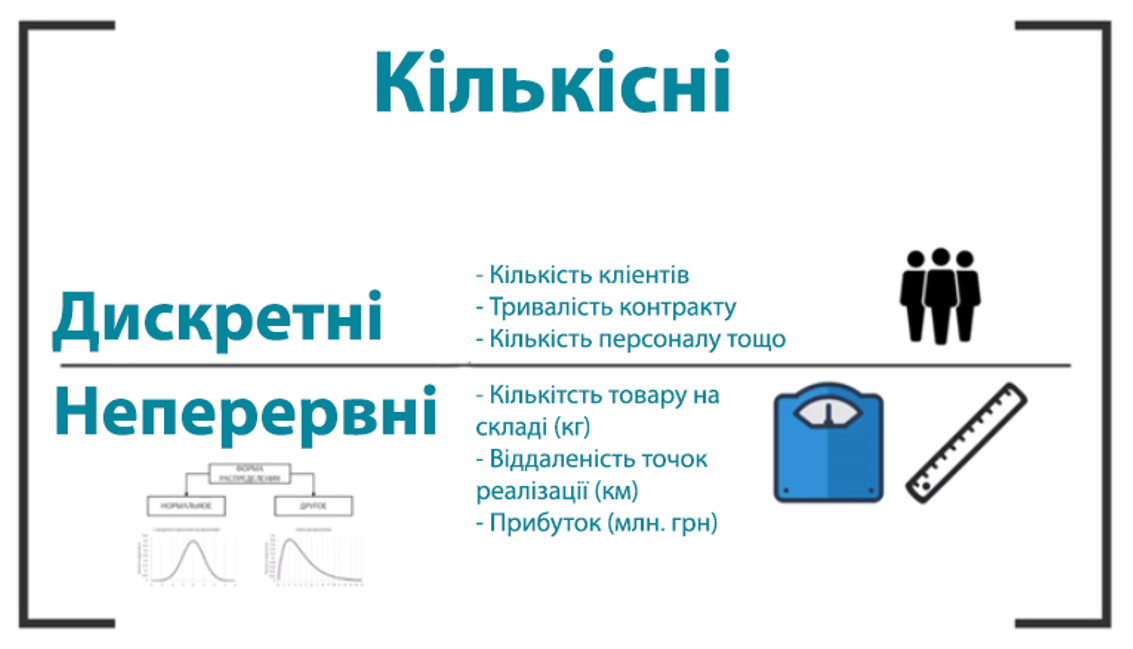
ТИПИ ДАНИХ

ОСНОВНІ ІНСТРУМЕНТИ DATA SCIENCE

ОСНОВНІ ІНСТРУМЕНТИ DATA SCIENCE

ОСНОВНІ ІНСТРУМЕНТИ DATA SCIENCE
ОСНОВНІ ІНСТРУМЕНТИ DATA SCIENCE

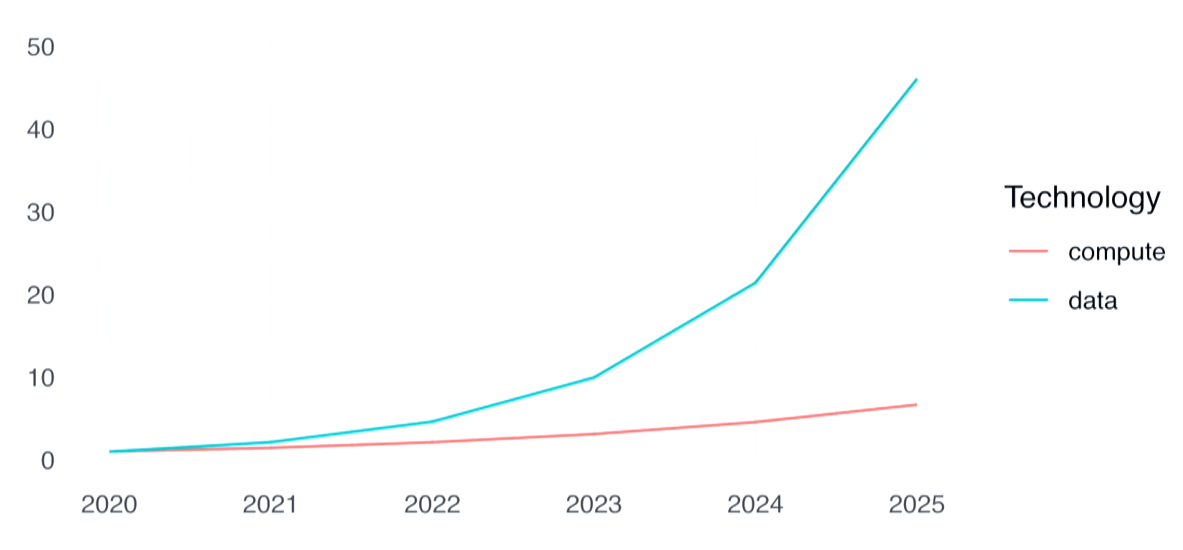
1. Вибух даних
Ми потопаємо у даних!
Howe and Greg Wilson
https://github.com/rstudio/conf20-future-dse

Закон Мура не працює у розрізі зростання даних
2. Невідтворюваність результатів
Довіра до науки занепадає

2. Невідтворюваність результатів
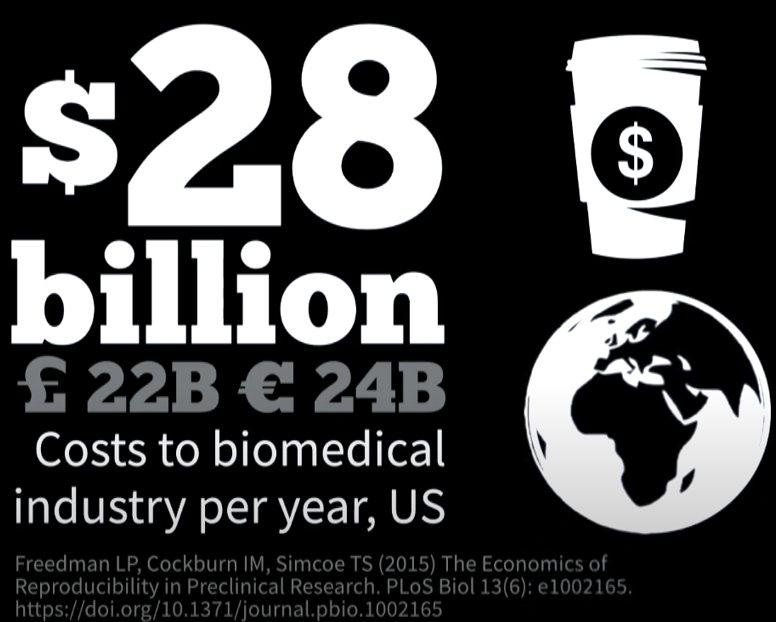
2. Невідтворюваність результатів

Amgen 2012: 6 з 53 значних результатів можна відтворити
2. Невідтворюваність результатів
Психологія

2. Невідтворюваність результатів

2. Невідтворюваність результатів
3. Підроблені дані
Дані стали ще одним засобом брехні

МАЙБУТНЄ DATA SCIENCE

МАЙБУТНЄ DATA SCIENCE
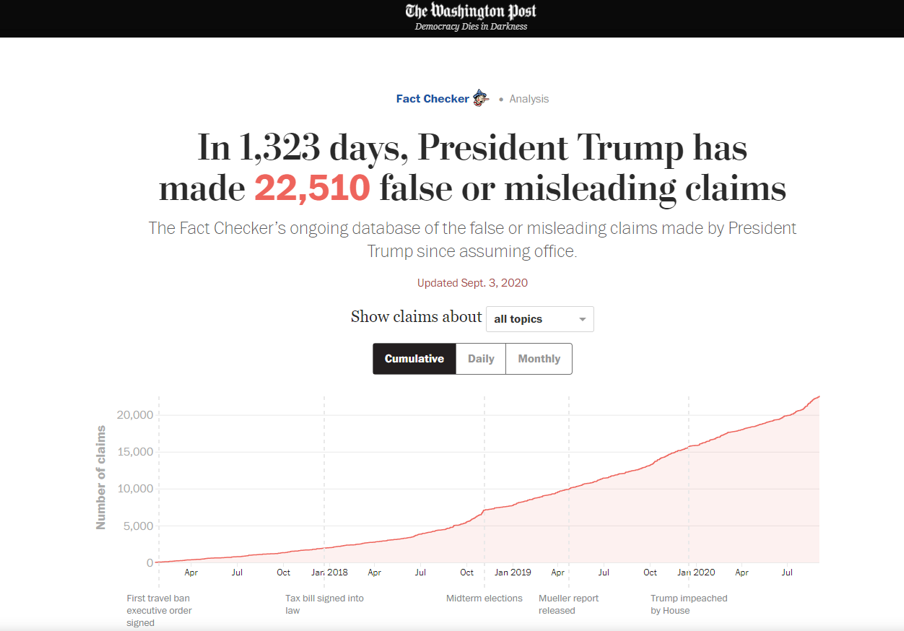
МАЙБУТНЄ DATA SCIENCE

МАЙБУТНЄ DATA SCIENCE

МАЙБУТНЄ DATA SCIENCE

МАЙБУТНЄ DATA SCIENCE

Дякую за увагу!
ihor.miroshnychenko@kneu.ua