Software development
Good practices and tips
Training Material:
Instructors
- Patricia Ternes - p.ternesdallagnollo@leeds.ac.uk
Part 2.1: Introduction to Version Control


The problem

- “Piled Higher and Deeper” by Jorge Cham, http://www.phdcomics.com
Possible Solutions (word processors)
-
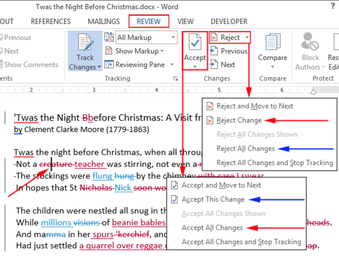
Microsoft Word’s Track Changes
-
Google Docs’ version history
-
LibreOffice’s Recording and Displaying Changes.
The solution: Version Control
Version control systems start with a base version of the document and then save just the changes you made at each step of the way.
-
Better kind of backup.
-
Version control is like an unlimited undo.
-
Review history.
-
Restore older file versions.
-
Ability to undo mistakes.
-
Maintain several versions of the code at a time.
-
Version control also allows many people to work in parallel.
Changes are saved sequentially

You can think of it as a tape: if you rewind the tape and start at the base document, then you can play back each change and end up with your latest version.
Different Versions Can be Saved
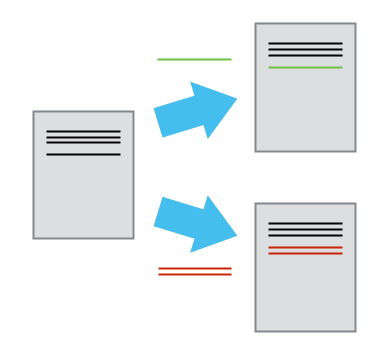
Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes onto the base document and getting different versions of the document.
Multiple Versions Can be Merged
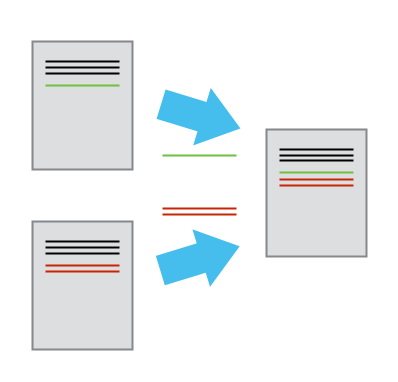
Unless there are conflicts, you can even play two sets of changes onto the same base document.
Version control systems
There are many different version control systems:




Version control systems
There are many different version control systems:
Version control systems
Git is not GitHub
!=
version control system tool
hosting service for Git
repositories
Setting up Git
https://gitforwindows.org/
You’ll know it has worked when you can open a Git Bash terminal (the window should have a title that starts with MINGW32) and get the Git version by running:
$ git --versionBasic configurations
User info
Here is how Jane sets up her new laptop:
$ git config --global user.name "Jane Smith"$ git config --global user.email "jane.smith@university.ac.uk"- You need to do this only once if you pass the --global option.
- If you want to override this with a different name or email address for specific projects, you can run the command without the --global option when you’re in that project.
we’ll be setting up an account on Github so make sure you use the same email address.
Basic configurations
User info
You can check that they have been set correctly by running
$ git config user.name$ git config user.emailBasic configurations
Colours
$ git config --global color.ui "auto"Basic configurations
Default Git branch naming
$ git config --global init.defaultBranch mainCreating a local Git repository
$ mkdir infammation
$ cd inflammation
$ git init- Create an "inflammation" directory (folder)
- Move into "inflammation"
- Then tell Git to make inflammation a Git repository
Using command line:
What happened?
Check your Git repository
$ ls -a
. .. .git- `ls` to list your folder content
- `ls -a` to list your folder content - including hidden files
Git stores information about the project in this special sub-directory.
If we ever delete it, we will lose the project’s history.
Checking our project
git status
$ git statusRemoving a local repository
$ rm -rf .gitBe careful! Running this command in the wrong directory, will remove the entire git-history of a project you might wanted to keep.
Therefore, always check your current directory using the command pwd.
Be careful: Multiple projects
$ git status
fatal: Not a git repository (or any of the parent directories): .gitFirst, lets check the status
Git repositories can interfere with each other if they are “nested” in the directory of another: the outer repository will try to version-control the inner repository. Therefore, it’s best to create each new Git repository in a separate directory.
Summary
-
use pdw to ensure that you are in the correct directory
-
use git init to create a git repository
-
use git status to ensure that git is working
First tracked change
-
Create a file called project.txt
-
Type the text below into the project.txt file:
Some initial data analysis to identify how inflammation changes over time after surgery.- Now, check the status
$ git statusFirst tracked change
Add change to "staging area"
-
The untracked files message means that there’s a file in the directory that Git isn’t keeping track of.
-
We can tell Git to track a file using git add
$ git add project.txt- Now, check the status
$ git statusFirst tracked change
Commit your changes
-
Git now knows that it’s supposed to keep track of project.txt, but it hasn’t recorded these changes as a commit yet.
-
To get it to do that, we need to run one more command: git commit -m "some message"
$ git commit -m "Start notes on the patient inflammation project"- Now, check the status
$ git statusSecond tracked change
-
Now suppose Jane adds more information to the file. Update your text to look like:
Some initial data analysis to identify how inflammation changes over time after surgery.
Jane is a Data Scientist and Samit is a statistician. We'll need to determine
who is responsible for what in this project.- Now, check the status
$ git status- Let's try something new: git diff
$ git diff-
Now commit your change!
$ git commit -m "Add note about project responsibilities"Staging Area
-
Whoops: Git won’t commit because we didn’t use git add first. Let’s fix that:
$ git add project.txt
$ git commit -m "Add note about project responsibilities"- Git has a special staging area where it keeps track of things that have been added to the current changeset but not yet committed.
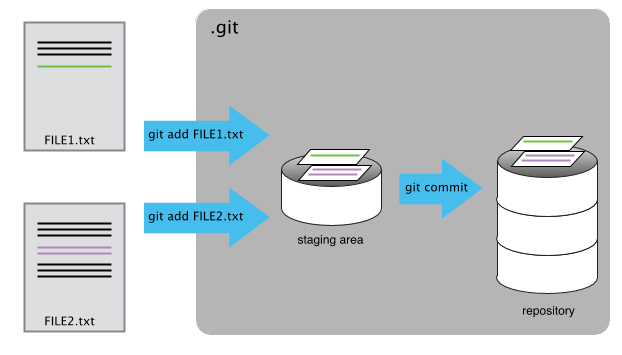
Summary
-
use add to put your changes in the staging area
-
use git diff to check the differences between your last commit and your file
-
use git commit -m to commit the staged changes
Exploring History
Identifying files old versions
- use git log to see the commits that we made
$ git logWe can refer to commits by their identifiers:
- Complete ID: unique 40-character identifier
- Short ID: first few characters (7 by default)
- HEAD ID: The most recent commit
- HEAD~i (i=1,2,3...) (pronounced “head minus i”): HEAD~1: “the previous commit”, HEAD~123 goes back 123 commits from where we are now.
Exploring History
Reviewing changes - diff
-
$ git diff <commitID1> <commitID2>: show you any difference betwenn the commit <commitID1> and <commitID2>
$ git diff HEAD HEAD~1Exploring History
Reviewing changes - show
-
$ git show <commitID>: show the commit log message
$ git show cf53ab40ddc732676c7e7a65063629b5df1c96f5Recovering old versions
checkout
-
As you might guess from its name, git checkout checks out (i.e., restores) an old version of a file.
-
To use this command we need to provide two information, the commit identifier and the file name, e.g.:
$ git checkout da43c77 project.txtAfter restore an old version, you still need to add and commit the change. Now see the log! Note that even when restoring an old version, you do not overwrite/lose commits already made.
Ignoring Things
.gitignore
-
Let’s create a few dummy files in the inflammation directory:
$ mkdir results
$ touch a.dat b.dat c.dat results/a.out results/b.out$ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
a.dat
b.dat
c.dat
results/
nothing added to commit but untracked files present (use "git add" to track)Ignoring Things
.gitignore
-
Let’s create a .gitignore file, and inside this file:
*.dat
results/$ git status
On branch main
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)- Finally, add and commit the .gitignore file
$ git add .gitignore
$ git commit -m "Add the ignore file"Branching
-
Let’s check our branches
$ git branch-
Create a new branch named experimental
$ git branch experimental-
We can switch to a different branch by using the git checkout command.
$ git checkout experimentalBranching
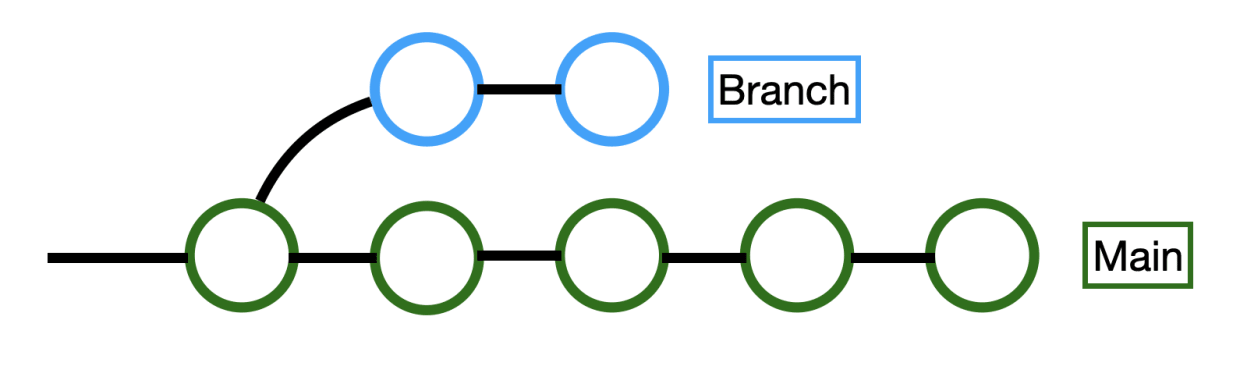
Branching
Changes in experimental branch
-
Create an "experimentalfile.txt"
-
add some text
Our experiment is performed as follows:
1. ....
2. ....
3. ....-
Now add and commit this change
$ git add experimentalfile.txt
$ git commit -m "creating experiment description file"Branching
Changes in main branch
-
First go back to the main branch
$ git checkout main-
Now create a new "mainfile.txt" and add some text on it.
-
Navigate around your folders and files, change branches and do the same. What did you notice?
Branching
Changes in main branch
-
Add changes in the desired branch
$ git checkout main
$ git add mainfile.txt
$ git commit -m "creating the mainfile"-
Again: navigate around your folders and files, change branches and do the same. What did you notice?
Merging branches
Experimental into Main
$ git checkout main
$ git merge experimental-
Again: navigate around your folders and files, change branches and do the same. What did you notice?
Branches: Conflict
-
Open the "project.txt" file in the main branch and delete the entire last sentence. Don’t forget to add/commit the change.
-
Switch to the experimental branch, open the file and instead of deleting the sentence, just make a small change to it. Again be sure to commit the changes
-
Finally, merge experimental into main:
Now we’re going to purposefully provoke a conflict.
$ git checkout main
$ git merge experimentalBranches: Conflict
-
Open the "project.txt" file in the main branch and Fix the conflict.
-
add/commit!
Auto-merging project.txt
CONFLICT (content): Merge conflict in project.txt
Automatic merge failed; fix conflicts and then commit the result.Remove unnecessary branches
It is recommended to delete any secondary branches after merging them with main.
To delete the experimental branch:
$ git branch -D experimental
Deleted branch experimental (was 3099b91).