Software development
Good practices and tips
Training Material:
Instructors
- Patricia Ternes - p.ternesdallagnollo@leeds.ac.uk


Part 1: SOFTWARE DEVELOPMENT IN A NUTSHELL

Software Development Life Cycle (SDLC)
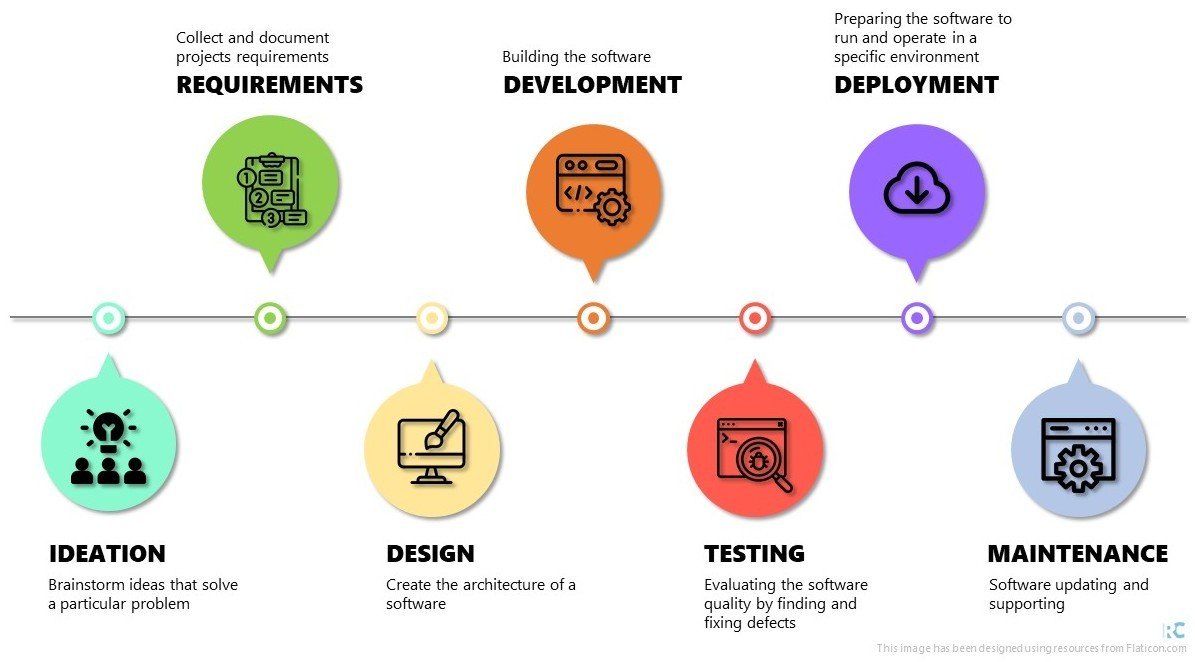
Software Development Life Cycle (SDLC)

SDLC: Ideation
- Brainstorming
- Research
What are we going to do?
SDLC: Requirements
Some topics to help define requirements include:
- final goal
- project scope (how to reach the final goal)
- what is feasible (and how)
- what is priority
- what resources are available
- deadlines
- potential risks
How are we going to do it?

Warning: Each person involved in the project may have a different need.
SDLC: Requirements
Software Requirement Specification
All information regarding the requirements must be organized in a file, the Software Requirement Specification.
Everyone involved in the project should review this document. If any requirement has a problem (is incomplete, unclear, ambiguous, etc.), it must be identified and corrected.
How are we going to do it?
SDLC: Design
What is the software architecture?
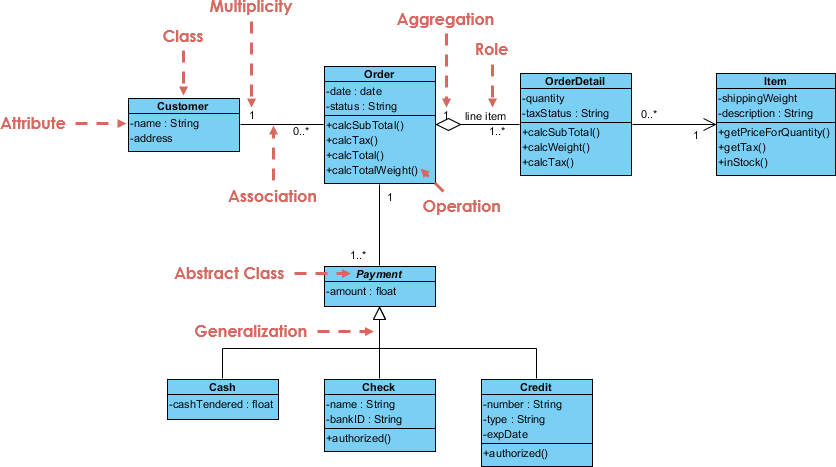
Image from Visual Paradigm - see here for a complete tutorial.
SDLC: Design
What is the software architecture?
When designing software, the object-oriented approach is a common programming paradigm.
Object-oriented components:
-
Classes: A user-defined type
-
Object instances: A particular object instantiated from a class.
-
Methods: A function which is “built in” to a class
-
Constructor: A special method called when instantiating a new object
Some principles: abstraction, encapsulation, decomposition, generalisation
SDLC: Development
Is this where the fun begins?

Take your time!
Development is usually the most time consuming step in a Software Development Life Cycle.
SDLC: Testing
Is this software good?
In this step, errors and failures are identified by exposing the code to an environment similar to the end-user experience.

There are several types of testing, some examples include:
-
Unit testing: are all components working?
-
Integration testing: are all components working when fitted together?
-
Performance testing: how does the software perform against different workloads? It is fast? Stable?
-
Functional testing: is the software aligned with Software Requirement Specification?
SDLC: Deployment
Can other people use my code?
The functionality of the software is linked to several specifications related to the operating system and versions of packages and other software related to the project. Listing these specifications will help others to replicate the environment in which the software was developed.

You can use platforms like GitHub to release your software.
SDLC: Maintenance
Is it over?
We can classify maintenance into a few categories:
-
Corrective: fix reported errors/failures.
-
Preventive: regular checks and fixes.
-
Perfective: optimize implemented features, adding new features.
-
Adaptive: keep the software updated according to changes external to the project (new programming language version, new regulation, etc.).

Software Development Life Cycle (SDLC)
Project management methodologies
Without a design approach, programmers resort to designing as we go, typing in code, trying what works, and making it up as we go along.
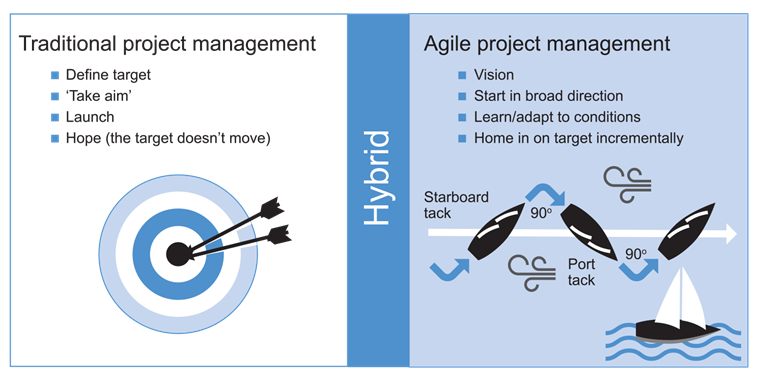
Figure from Association for Project Management
The Agile Manifesto
The Agile principles:
-
Individuals and interactions over processes and tools
-
Working software over comprehensive documentation
-
Customer collaboration over contract negotiation
-
Responding to change over following a plan
- Manifesto for Agile Software Development
Agile is not absence of methodology
The Agile movement is not anti-methodology, in fact, many of us want to restore credibility to the word methodology. We want to restore a balance. We embrace modelling, but not in order to file some diagram in a dusty corporate repository. We embrace documentation, but not hundreds of pages of never-maintained and rarely-used tomes. We plan, but recognize the limits of planning in a turbulent environment.
- Jim Highsmith - The Alan Turing Institute
Elements of an Agile Process
-
Ongoing design
-
Iterative development
-
Continuous delivery
-
Self-organising teams
Agile methodologies
-
DAD (disciplined agile delivery)
-
DSDM (dynamic systems development method)
-
Kanban
-
Lean
-
LeSS (large-scale Scrum)
-
RAD (rapid application development)
-
SAFe (scaled agile framework enterprise)
-
Scaled agile
-
Scrum
-
Scrum of scrums
-
XP (eXtreme Programming)
Kanban
The term Kanban comes from Japanese and translates as “signal card”. Originally, Kanban was used in Toyota’s production facilities, where it also influenced agile development in IT and other departments.
The aim is to establish a constant, orderly workflow. Moreover, Kanban can be combined with other agile methods such as Scrum.
- IONOS
Simple Kanban Board
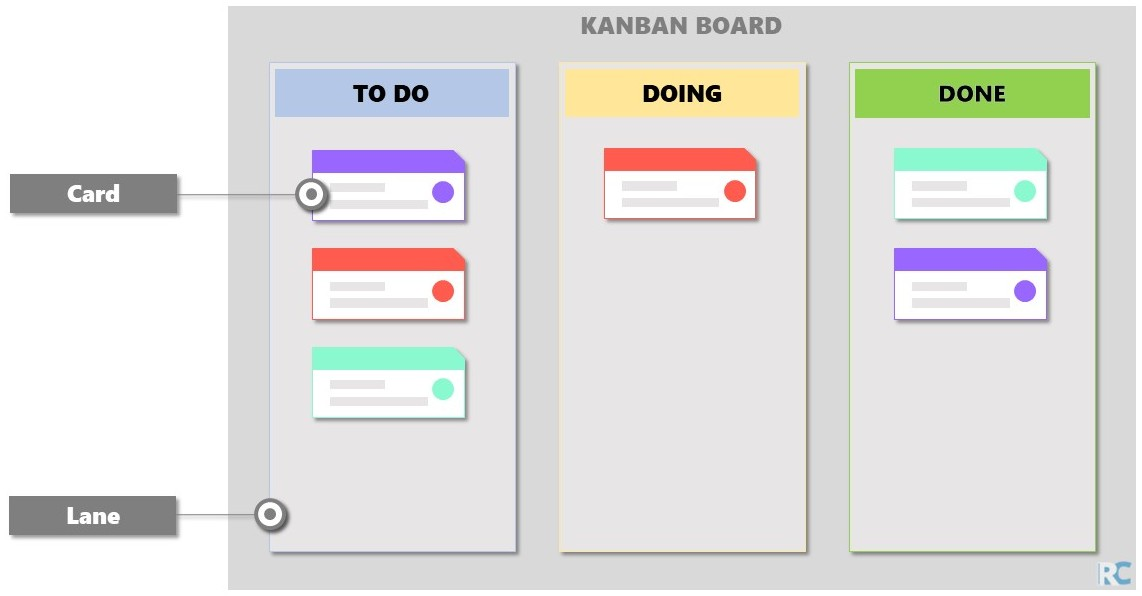
Useful Cards Content
-
Title
-
Description
-
Attachments and links
-
Card type (usually distinguished by color)
-
Assignment
-
Card & comment history
-
Subtasks
-
Due date
Software Development: Useful Lanes
-
Backlog (To Do: Unprioritized)
-
Ready (To Do: Prioritized)
-
Plan
-
Develop (Coding)
-
Testing
-
Pending Final Approval
-
Deployment
-
Done
Useful Improvements
-
Work-in-progress (WIP) limit: number of allowed open cards
-
Include more lanes
-
Priority lanes
-
Swimlanes: horizontal line to divide different groups
Another Kanban Board
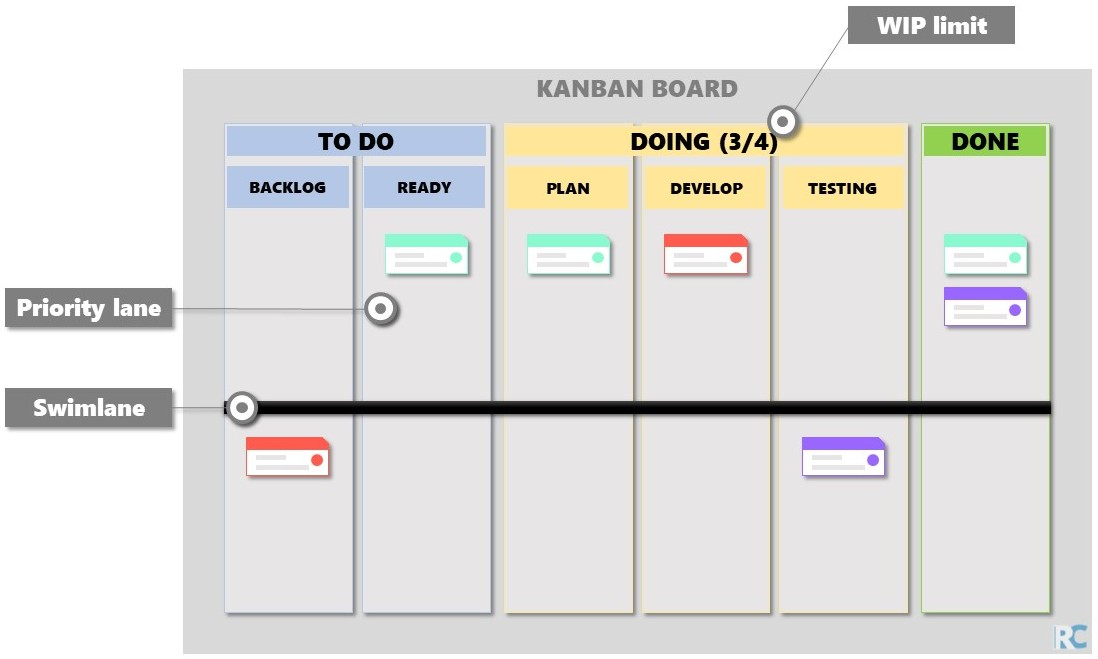
Kanban: Pros & Cons
Pros
-
Easy integration
-
Increased visibility of the workflow
-
Improved delivery speed
-
Increased transparency
Cons
-
absolutely necessary that the work can actually be divided into small steps
Trick
The work-in-progress limits ensure that problems at a station quickly become visible and capacities can be reallocated accordingly. However, this is only possible if capacities can actually be swapped around. Team members must be able to work at different stations. Otherwise, blockages and overstraining will occur for some co-workers, while others will become idle – precisely the opposite of what Kanban is intended to achieve.
- IONOS
Laying out a coding project
Good project layout ensures:
-
Integrity of the data
-
Portability of the project
-
Ease to pick the project back up after a break or change in personnel
There is no single way to organise a project…. but we need to take advantage some conventions.
Basic Structure Suggestion
Suppose you want to create a Python repository called first-model. The most basic structure for this project should look like:
first-model
├── src
│ └── __init__.py
└── tests
| ├── __init__.py
| └── test_first_model.py
├── README.md
├── requirements
└── setupModules & Packages
-
Modules: code files with .py extension
-
Packages: directory to group modules. For a folder with several modules to be recognized as a package it is necessary to include the file __init__.py.
first-model
├── src
│ └── __init__.py
└── tests
| ├── __init__.py
| └── test_first_model.py
├── README.md
├── requirements
└── setupTest & pytest
It’s important to ensure that the code is bug-free and returns the expected results
The test structure:
-
All tests units (files and methods) must be named starting with test_ and placed inside a package (or subpackage) called tests.
-
Tests can be grouped in just one folder for the entire repository or they can be organized within each package/subpackage.
first-model
├── src
│ └── __init__.py
└── tests
| ├── __init__.py
| └── test_first_model.py
├── README.md
├── requirements
└── setupTest & pytest
Naming conventions
- Python conventions are governed largely by a set of documents called Python Enhancement Proposals (PEP). You can see more about PEP index in the official Python website.
- The PEP related with python coding style is the PEP8 – Style Guide for Python Code.
- This file has guidance for all layout related aspects. For instance we are interested in the Package and Module Names section.
Modules should have short, all-lowercase names. Underscores can be used in the module name if it improves readability. Python packages should also have short, all-lowercase names, although the use of underscores is discouraged.
Virtual Environments
Python applications will often use packages and modules that don’t come as part of the standard library. Applications will sometimes need a specific version of a library, because the application may require that a particular bug has been fixed or the application may be written using an obsolete version of the library’s interface.
This means it may not be possible for one Python installation to meet the requirements of every application. If application A needs version 1.0 of a particular module but application B needs version 2.0, then the requirements are in conflict and installing either version 1.0 or 2.0 will leave one application unable to run.
The solution for this problem is to create a virtual environment, a self-contained directory tree that contains a Python installation for a particular version of Python, plus a number of additional packages.
Different applications can then use different virtual environments. To resolve the earlier example of conflicting requirements, application A can have its own virtual environment with version 1.0 installed while application B has another virtual environment with version 2.0. If application B requires a library be upgraded to version 3.0, this will not affect application A’s environment.


Room 1
Room 2

Room 1
Room 2

Room 1
Room 2
env-1
env-2
env-1
env-2
env-1
env-2
every time
Package managers
| conda | poetry | |
|---|---|---|
| audience | research | developers |
| manage python packages | ✅ | ✅ |
| manage non-python packages | ✅ | ❌ |
| choose python version | ✅ | ❌ |
| manage virtual envs | ✅ | ✅ |
| easy interface | ❌ | ❌ |
| fast | ❌ | ✅ |
Environment: Conda example
Create environment from a yml file
The environment.yml file specifies the dependencies that will be installed in your environment.:
name: course
dependencies:
- python>=3.8
- numpy=1.13
- matplotlib=3.*
- pandas$ conda env create -f environment.yml$ conda activate courseConda: Managing packages
$ conda search package-name$ conda install package-name$ conda update package-name$ conda remove package-name$ conda listConda: Managing environments
$ conda env list$ conda remove -n ENVNAME --all$ conda env export --name ENVNAME > file-name.yml$ conda env export --name ENVNAME --no-builds | grep -v "prefix" > file-name.yml$ conda create --clone ENVNAME --name NEWENVCheck this Conda Cheat Sheet!
Creating project structure:
Conda + Cookie cutter
- create an empty repository
- create and activate conda environment
- install cookiecutter
- choose a project template (A good example to be used in scientific projects can be found here.)
- create the project structure by combining the Cookiecutter package with the GitHub repository
$ conda create -n reproPython python=3.9
$ source activate reproPython
$ pip install cookiecutter
$ cookiecutter gh:mkrapp/cookiecutter-reproducible-scienceCreating project structure:
Conda + Cookie cutter
.
├── AUTHORS.md
├── LICENSE
├── README.md
├── bin <- Your compiled model code can be stored here (not tracked by git)
├── config <- Configuration files, e.g., for doxygen or for your model if needed
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
├── docs <- Documentation, e.g., doxygen or scientific papers (not tracked by git)
├── notebooks <- Ipython or R notebooks
├── reports <- For a manuscript source, e.g., LaTeX, Markdown, etc., or any project reports
│ └── figures <- Figures for the manuscript or reports
└── src <- Source code for this project
├── data <- scripts and programs to process data
├── external <- Any external source code, e.g., pull other git projects, or external libraries
├── models <- Source code for your own model
├── tools <- Any helper scripts go here
└── visualization <- Scripts for visualisation of your results, e.g., matplotlib, ggplot2 related.Additional tips: Code formatting
# myscript.py:
x = { 'a':37,'b':42,
'c':927}
y = 'hello '+ 'world'
class foo ( object ):
def f (self ):
return y **2
def g(self, x :int,
y : int=42
) -> int:
return x--y
def f ( a ) :
return 37+-a[42-a : y*3]Additional tips: Black Code Formatter
x = {"a": 37, "b": 42, "c": 927}
y = "hello " + "world"
class foo(object):
def f(self):
return y ** 2
def g(self, x: int, y: int = 42) -> int:
return x - -y$ conda install black
$ black myscript.pyNow Is it all right?
Check the file!
Install and run Black
Additional tips:
Integrated development environment (IDE)
Using an Integrated development environment (IDE) will certainly save you time, but the advantages of using an IDE go beyond that. Below are some IDE advantages
-
Syntax highlighting
-
Text autocompletion
-
Refactoring options
-
Easily Importing libraries
-
Build, compile, or run
Additional tips: Visual Studio Code
Some VSC advantages:
- IntelliSense: Go beyond syntax highlighting and autocomplete
- Run & Debug: Debug code right from the editor
- Built-in Git: Review diffs, stage files, and make commits right from the editor.
- Extensible and customizable: Install extensions to add new languages, themes, debuggers, and to connect to additional services.
To install VS Code follow the instructions here.
Additional tips: Visual Studio Code + Black
Open Settings: Code (or File) > Preferences > Settings
-
Search for python formatting provider and choose black
-
Search for format on save and check the box to enable
Open Command Palette: View > Command Palette.. (or Ctrl+Shift+P)
-
Search for Python: Select Interpreter
-
Choose the correct environment
Now the Black package is going to fix your codes layout every time you save a code file.